공식사이트) https://cs231n.github.io/assignments2020/assignment1/
KNN을 통한 image classification & cross-validation
Setup
https://cs231n.github.io/assignments/2021/assignment1_colab.zip
-
위의 링크를 통해 Starter code가 담긴 폴더를 다운받는다.
-
개인 Google Drive에 cs231n/assignments 폴더를 생성 후, 위에서 다운 받은 폴더를 넣는다.
-
앞으로 Google Colab을 사용해서 실습을 진행한다.
Python Numpy 튜토리얼
Jupyter나 Colab을 사용할 수 있다.
cs231n에서는 Colab을 사용하는 것을 권장하고 있다.
https://colab.research.google.com/github/cs231n/cs231n.github.io/blob/master/python-colab.ipynb
위의 링크는 파이썬과 넘파이 튜토리얼을 진행할 수 있는 Colab이다. 한 cell씩 따라해보면서 실습하면 된다!
이제 K-Nearest Neighbor classifier 실습을 본격적으로 진행해보자!
구글 드라이브에서 cs231n/assignments/assignment1 폴더에 있는 knn.ipynb을 실행시켜서 진행하면 된다.
1. dataset 다운로드
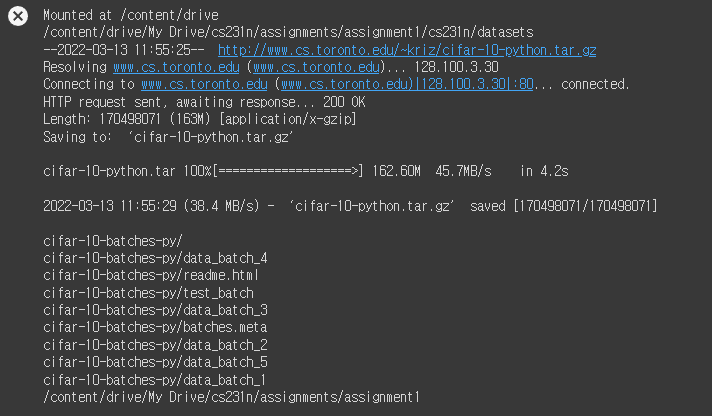
첫 번째 셀은 과제에 필요한 dataset이 다운받기 위한 코드이다. 실행시키면 아래와 같은 결과 화면이 나온다.
실행결과
2. 모듈 import & 데이터 load
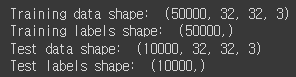
두 번째 셀에서 필요한 모듈을 import하고 세 번째 셀에서 데이터를 로드한다.
결과창은 아래와 같다.
실행결과
3. Data Visualizing

num_classes는 classes의 길이인 10이다.
idxs = np.flatnonzero(y_train == y)은 train data의 class 값 중 같은 class를 가지는 data의 인덱스들을 저장하는 코드이다. 여기서 flatnonzero()는 0이 아닌 요소의 인덱스를 반환한다.
idxs = np.random.choice(idxs, samples_per_class, replace=False는 idxs에서 samples_per_class 수 만큼 랜덤으로 추출하는 코드이다. 여기서 replace=False는 비복원추출(같은 원소가 2번 이상 뽑힐 수 없음)을 의미한다.
plt_idx = i * num_classes + y + 1은
1, 11, 21, 31, 41, 51, 61, 2, 12, 22, 32, 42, 52, 62, 3, 13, 23 ...으로 진행된다.
plt.subplot(nrows, ncols, index)
여기서 nrows는 행의 수, ncols는 열의 수, index는 위치를 의미한다.
셀을 실행시키면 아래와 같은 결과를 확인할 수 있다.
실행결과

plt.axis('off')가 없으면 아래와 같은 결과가 나온다.

4. Data Preprocessing
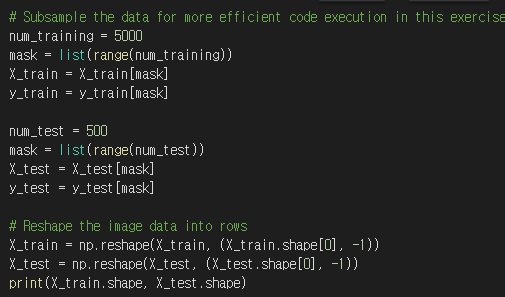
train data는 5000개, test data는 500개를 취한 후, 열 기준으로 데이터를 reshape한다.
또한 32x32x3 크기의 이미지를 모두 vector로 변환한다.
실행결과

5. KNN
이제 KNN classifier를 통해 test data를 classify 해보자!
이는 아래의 두 단계로 이루어진다.
- 모든 text exmaples와 train examples 간 거리를 계산한다.
- 계산한 거리를 가지고 각 test exmaple마다 k nearest examples를 찾고, label을 정한다.
Ntr개의 training examples가 있고 Nte개의 test examples가 있을 때, 결과는 (i,j) Nte x Ntr 행렬이다.
이 행렬의 각 요소인 (i, j)는 i번째 test와 j번째 train exmaple 사이의 거리이다.
먼저, cs231n/assignments/assignment1/cs231n/classifiers 폴더에 있는 k_nearest_neighbor.py 파일을 연다.
그리고 compute_distances_two_loops을 수행한다. (test, train) examples의 모든 pairs에 대해 매우 비효율적인 이중 반복문을 사용하고, 한 번에 하나의 distance matrix를 계산한다.
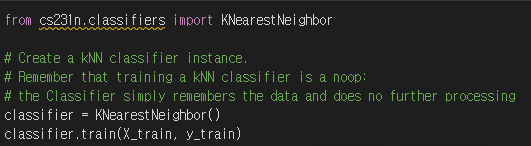
먼저, train을 진행한다. KNN classifier은 단순히 데이터를 기억하기만 하고, processing은 하지 않는다.
1) distances_two_loops
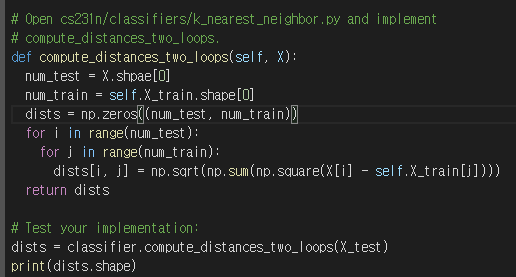
기존 k_nearest_neighbors.py에 있는 compute_distances_two_loops의 TODO 부분에 dists[i, j] = np.sqrt(np.sum(np.square(X[i] - self.X_train[j])))를 추가해줬다.
실행결과

실행결과


2) predict_labels

실행결과


실행결과


3) distance with one loop

실행결과

no loops
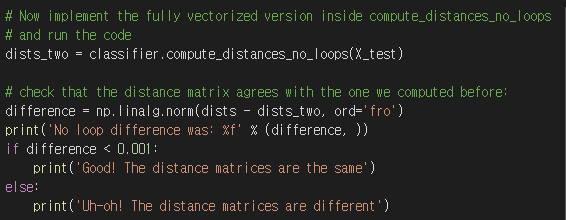
실행결과

세 알고리즘 속도 비교
실행결과
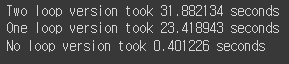
4) distance by fully vectorized code
5) cross validation
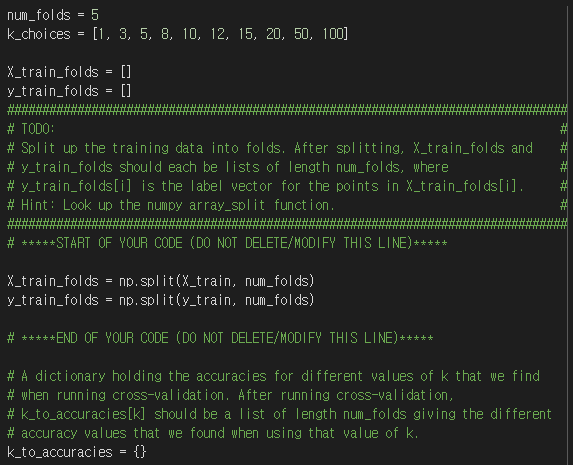
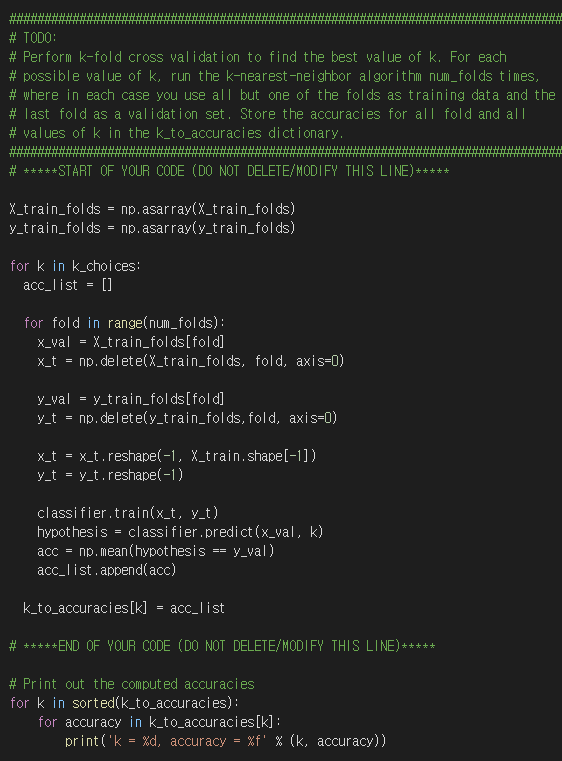
실행결과
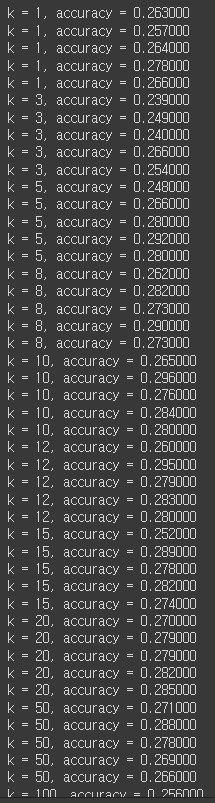

실행결과
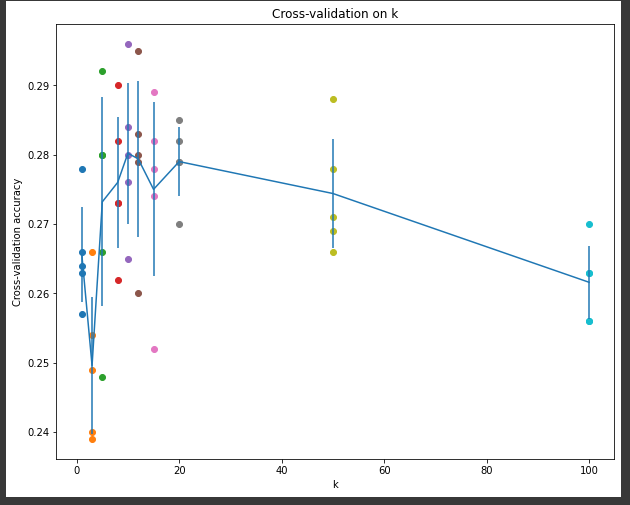

실행결과


참고)
https://yun905.tistory.com/2
https://bookandmed.tistory.com/42
https://rchoi-19-4-2.tistory.com/129
https://vstylestdy.tistory.com/30
