
1. 자연어 처리란
자연어를 컴퓨터에게 이해시키는 데는 무엇보다 단어의 의미를 이해시키는 게 중요하다.
➡️ 이번 장의 주제는 컴퓨터에게 단어의 의미 이해시키기
단어의 의미를 잘 파악하는 표현 방법에 대해 생각해보자!
- 시소러스를 활용한 기법 (이번 장)
- 사람의 손으로 만든 시소러스를 이용
- 통계 기반 기법 (이번 장)
- 통계 정보로부터 단어 표현
- 추론 기반 기법(word2vec) (다음 장)
- 신경망 활용
2. 시소러스 (thesaurus)
: 유의어 사전으로, 동의어나 유의어가 한 그룹으로 분류되어 있다.
모든 단어에 대한 유의어 집합을 만든 다음, 단어들의 관계를 그래프로 표현하여 단어 사이의 연결을 정의
➡️ 이 '단어 네트워크'를 이용하여 컴퓨터에게 단어 사이의 관계를 가르칠 수 있다.
2-1) WordNet
: 자연어 처리 분야에서 가장 유명한 시소러스
WordNet을 사용하면 유의어를 얻거나 '단어 네트워크'를 이용할 수 있다.
또한 단어 네트워크를 사용해 단어 사이의 유사도를 구할 수 있다.
2-2) 시소러스의 문제점
시소러스에는 수많은 단어에 대한 동의어와 계층 구조 등의 관계가 정의돼있다.
하지만 이처럼 사람이 수작업으로 레이블링하는 방식에넌 큰 문제점들이 있다.
- 시대 변화에 대응하기 어렵다.
- 사람을 쓰는 비용이 크다.
- 단어의 미묘한 차이를 표현할 수 없다.
➡️ 이 문제를 피하기 위해, 통계 기반 기법과 추론 기반 기법
이 두 기법에서는 대량의 텍스트 데이터로부터 '단어의 의미'를 자동으로 추출!
3. 통계 기반 기법
말뭉치(corpus)
- 대량의 텍스트 데이터
- 자연어 처리 연구나 애플리케이션을 염두에 두고 수집된 텍스트 데이터
- 자연어에 대한 사람의 '지식'이 충분히 담겨 있다
📌 통계 기반 기법의 목표는 이처럼 사람의 지식으로 가득한 말뭉치에서 자동으로, 그리고 효율적으로 그 핵심을 추출하는 것!
자연어 처리에 사용되는 말뭉치에는 텍스트 데이터에 대한 추가 정보가 포함되는 경우가 있다.
이럴 경우 말뭉치는 컴퓨터가 다루기 쉬운 형태(트리 구조 등)로 가공되어 주어지는 것이 일반적
3-1) 파이썬으로 말뭉치 전처리하기
여기서 말하는 전처리란 텍스트 데이터를 단어로 분할하고 그 분할된 단어들을 단어 ID 목록으로 변환하는 일!
>>> text = 'You say goodbye and I say hello.'
>>> text = text.lower()
>>> text = text.replace('.', ' .')
>>> text
'you say goodbye and i say hello .'
>>> words = text.split(' ')
>>> words
['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.']단어를 분할할 때 마침표 앞에 공백을 넣는 임시변통을 적용했지만, 더 현명하고 범용적인 방법은
정규표현식(regular expression
정규표현식 모듈인 re를 임포터하고re.split('(\W+)?', text)라고 호출하면 단어 단위로 분할 가능!
이제 원래의 문장을 단어 목록 형태로 이용할 수 있다.
➡️ 이제 단어에 ID를 부여하고, ID의 리스트로 이용할 수 있도록 해보자!
이를 위한 사전 준비로 파이썬의 딕셔너리를 이용하여 단어 ID와 단어를 짝지어주는 대응표를 작성해보자.
>>> word_to_id = {}
>>> id_to_word = {}
>>>
>>> for word in words:
... if word not in word_to_id:
... new_id = len(word_to_id):
... word_to_id[word] = new_id
... id_to_word[new_id] = word
>>>
>>> id_to_word
{0: 'you', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello', 6: '.'}
>>> word_to_id
{'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5, '.': 6}마지막으로 '단어 목록'을 '단어 ID 목록'으로 변경해보자.
파이썬의 내포(comprehension) 표기를 사용하여 단어 목록에서 단어 ID 목록으로 변환한 다음, 다시 넘파이 배열로 변환한다.
내포: 리스트나 딕셔너리 등의 반복문 처리를 간단하게 쓰기 위한 기법
>>> import numpy as np
>>> corpus = [word_to_id[w] for w in words]
>>> corpus = np.array(corpus)
>>> corpus
array([0, 1, 2, 3, 4, 1, 5, 6])preprocess()
이상의 처리를 한 데 모아 preprocess()라는 함수로 구현해보자!
def preprocess(text):
text = text.lower()
text = text.replace('.', ' .')
words = text.split(' ')
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word다음 목표: 말뭉치를 사용해 '단어의 의미'를 추출해보자!
3-2) 단어의 분산 표현
색을 예로 들어보자.
우리는 색을 고유한 이름(코발트블루, 싱크레드...)으로 표현할 수도 있고, RGB라는 세 가지 성분이 어떤 비율로 섞여 있느냐로도 표현할 수 있다.
❗RGB 같은 벡터 표현이 색을 더 정확하게 명시할 수 있다. 모든 색을 단 3개의 성분으로 간결하게 표현할 수 있고, 어떤 색인지 짐작하기도 쉽다. 색끼리의 관련성도 벡터 표현 쪽이 더 쉽게 판단할 수 있고, 정량화하기도 쉽다.
🤔 '단어'도 벡터로 표현하면 좋지 않을까?
이제 우리가 원하는 것은 '단어의 의미'를 정확하게 파악할 수 있는 벡터 표현
➡️ 이를 자연어 처리 분야에서는 단어의 분산 표현(distributional representation)
단어의 분산 표현은 단어를 고정 길이의
밀집벡터(dense vector)로 표현
밀집벡터: 대부분의 원소가 0이 아닌 실수인 벡터
3-3) 분포 가설
자연어 처리에서 이뤄진 단어를 벡터로 표현하는 많은 연구들은 거의 모두가 단 하나의 간단한 아이디어에 기반한다.
➡️ 분포 가설(distributional hypothesis): '단어의 의미는 주변 단어에 의해 형성된다.'
즉, 단어 자체에는 의미가 없고, 그 단어가 사용된 맥락(context)이 의미를 형성한다는 것!
'맥락': 특정 단어를 중심에 둔 그 주변 단어
윈도우 크기(window size): 맥락의 크기(주변 단어를 몇 개나 포함할지)
3-4) 동시발생 행렬
'통계 기반(statistical based)' 기법
: 어떤 단어에 주목햇을 때, 그 주변에 어떤 단어가 몇 번이나 등장하는지를 세어 집계하는 방법
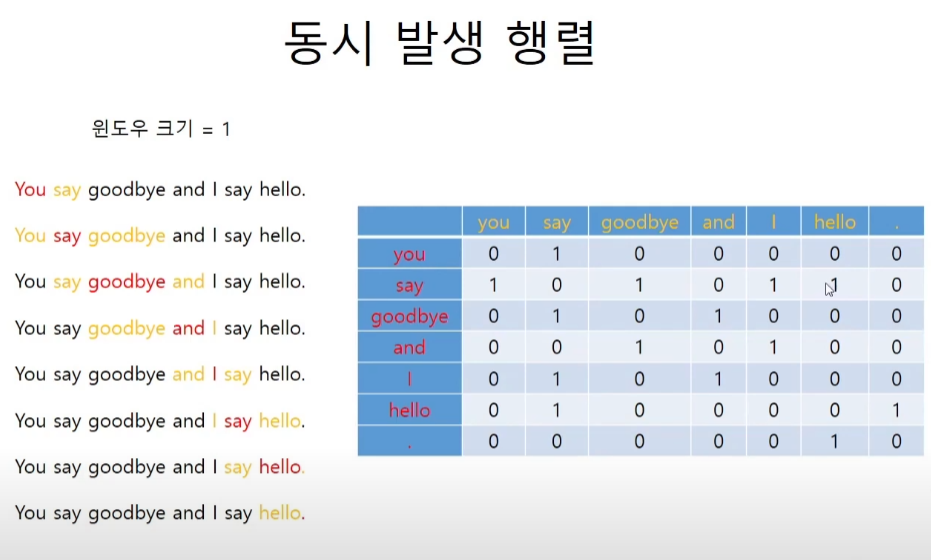
위는 모든 단어에 대해 동시발생하는 단어를 표에 정리한 것.
이 표의 각 행은 해당 단어에 대한 벡터가 된다.
이 표가 행렬의 형태를 띈다는 뜻에서 동시발생 행렬(co-occurrence matirx)라고 한다.
# 동시발생 행렬 구현
C = np.array([
[0, 1, 0, 0, 0, 0, 0],
[1, 0, 1, 0, 1, 1, 0],
[0, 1, 0, 1, 0, 0, 0],
[0, 0, 1, 0, 1, 0, 0],
[0, 1, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 1, 0],
], dtype=np.int32)
print(C[0]) # ID가 0인 단어의 벡터 표현
# [0 1 0 0 0 0 0]
print(C[4]) # ID가 4인 단어의 벡터 표현
# [0 1 0 1 0 0 0]
print(C[word_to_id['goodbye']]) # "goodbye"의 벡터 표현
# [0 1 0 1 0 0 0]동시발생 행렬을 활용해 단어를 벡터로 나타냈다.
위에서는 동시발생 행렬을 수동으로 만들었지만, 이를 자동화할 수 있다!
말뭉치로부터 자동으로 동시발생 행렬을 만들어주는 함수를 구현해보자!
create_co_matrix()
def create_co_matrix(corpus, vocab_size, window_size=1):
corpus_size = len(corpus)
co_matrix = np.zeros((vocab_size, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
for i in range(1, window_size + 1):
left_idx = idx - i
right_idx = idx + i
if left_idx >= 0:
left_word_id = corpus[left_idx]
co_matrix[word_id, left_word_id] += 1
if right_idx < corpus_size:
right_word_id = corpus[right_idx]
co_matirx[word_id, right_word_id] += 1
return co_matrix3-5) 벡터 간 유사도
단어 벡터의 유사도를 나타낼 때는 코사인 유사도(cosine similarity)를 자주 이용한다.

분자에는 벡터의 내적, 분모에는 각 벡터의 norm
norm은 벡터의 크기를 나타낸 것으로, 여기에서는 'L2 norm'을 계산(L2 norm은 벡터의 각 원소를 제곱해 더한 후 다시 제곱근을 구해 계산)
📌 핵심은 벡터를 정규화하고 내적을 구하는 것
cos_similarity()
def cos_similarity(x, y, eps=1e-8):
nx = x / (np.sqrt(np.sum(x**2)) + eps) # x의 정규화
ny = y / (np.sqrt(np.sum(y**2)) + eps) # y의 정규화
return np.dot(nx, ny)인수 x,y로 제로 벡터가 들어오면 0으로 나누기 오류가 발생하므로 분모에 작은 값 eps(엡실론의 약어)를 더해줬다.
여기에서 작은 값으로 1e-8을 사용했는데, 이 정도 작은 값이면 일반적으로 부동소수점 계산 시 '반올림'되어 다른 값에 '흡수'
위의 구현에서는 이 값이 벡터의 norm에 '흡수'되기 때문에 최종 계산 결과에는 영향을 주지 않는다.
"you"와 "i"의 유사도를 구해보자!
import sys
sys.path.append('..')
from common.util import preprocess, create_co_matrix, cos_similarity
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
c0 = C[word_to_id['you']] # "you"의 단어 벡터
c1 = C[word_to_id['i']] # "i"의 단어 벡터
print(cos_similarity(c0, c1))
# 0.707167691154799코사인 유사도 값은 -1에서 1 사이이므로, 비교적 유사성이 크다고 말할 수 있다.
3-6) 유사 단어의 랭킹 표시
어떤 단어가 검색어로 주어지면, 그 검색어와 비슷한 단어를 유사도 순으로 출력하는 함수를 구현해보자!
most_similar(query, word_to_id, id_to_word, word_matrix, top=5)
| 인수명 | 설명 |
|---|---|
| query | 검색어(단어) |
| word_to_id | 단어에서 단어 ID로의 딕셔너리 |
| id_to_word | 단어 ID에서 단어로의 딕셔너리 |
| word_matix | 단어 벡터들을 한 데 모은 행렬. 각 행에는 대응하는 단어의 벡터가 저장되어 있다. |
| top | 상위 몇 개까지 출력할지 설정 |
- 검색어의 단어 벡터를 꺼낸다.
- 검색어의 단어 벡터와 다른 모든 단어 벡터와의 코사인 유사도를 각각 구한다.
- 계산한 코사인 유사도 결과를 기준으로 값이 높은 순서대로 출력한다.
most_similar()
def most_similar(query, word_to_id, id_to_word, word_matix, top=5):
# 1. 검색어를 꺼낸다.
if query not in word_to_id:
print('%s(을)를 찾을 수 없습니다.' % query)
return
print('\n[query] ' + query)
query_id = word_to_id[query]
query_vec = word_matrix[query_id]
# 2. 코사인 유사도 계산
vocab_size = len(id_to_word)
similarity = np.zeros(vocab_size)
for i in range(vocab_size):
similarity[i] = cos_similarity(word_matrix[i], query_vec)
# 3. 코사인 유사도를 기준으로 내림차순으로 출력
count = 0
for i in (-1 * similarity).argsort():
if id_to_word[i] == query:
continue
print(' %s: %s' % (id_to_word[i], similarity[i]))
count += 1
if count >= top:
returnargsort() 메서드는 넘파이 배열의 원소를 오름차순으로 정렬한다. (단, 반환값은 배열의 인덱스)
우리는 유사도가 '큰' 순서로 정렬하고 싶으므로 넘파이 배열의 각 원소에 마이너스를 곱한 후 argsort() 메서드를 호출한 것이다.
"you"를 검색어로 지정해 유사한 단어들을 출력해보자!
import sys
sys.path.append('..')
from common.util import preprocess, create_co_matrix, most_similar
text = `You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
most_similar('you', word_to_id, id_to_word, C, top=5)
"""
[query] you
goodbye: 0.707167691154799
i: 0.7071067691154799
hello: 0.7071067691154799
say: 0.0
and: 0.0
"""4. 통계 기반 기법 개선하기
동시발생 행렬의 문제점
앞에서 본 동시발생 행렬의 원소는 두 단어가 동시에 발생한 횟수를 나타냈다.
❗'발생'횟수라는 것은 그리 좋은 특징이 아니다!
"the"와 "car"의 동시발생을 생각해보면 두 단어의 동시발생 횟수는 아주 많을 것이다.
"car"와 "drive"는 관련이 깊은데도 불구하고, 단순히 등장 횟수만을 본다면 "car"는 "drive"보다 "the"와의 관련성이 훨씬 강하다고 나올 것이다.
"the"가 고빈도 단어라서 "car"와 강한 관련성을 갖는다고 평가되기 때문!
➡️ 이 문제를 해결하기 위해 점별 상호정보량(PMI; Pointwise Mutual Information)이라는 척도를 사용!
4-1) 상호정보량


위의 식에서 볼 수 있듯이 동시발생 행렬로부터 PMI를 구할 수 있다!
PMI를 이용하면 "car"는 "the"보다 "drive"와의 관련성이 강해진다.
➡️ 단어가 단독으로 출현하는 횟수가 고려되었기 때문!
그러나 PMI는 두 단어의 동시발생 횟수가 0이면 log₂0 = -∞가 된다는 문제점이 있다.
➡️ 양의 상호정보량(PPMI; Positive PMI)
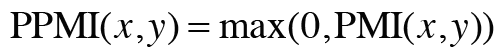
PPMI는 PMI가 음수일 때는 0으로 취급하기 때문에, 이제 단어 사이의 관련성을 0이상의 실수로 나타낼 수 있다.
ppmi()
동시발생 행렬을 PPMI 행렬로 변환하는 함수를 구현해보자!
def ppmi(C, verbose=False, eps=1e-8):
M = np.zeros_like(C, dtype=np.float32)
N = np.sum(C)
S = np.sum(C, axis=0)
total = C.shape[0] * C.shape[1]
cnt = 0
for i in range(C.shape[0]):
for j in range(C.shape[1]):
pmi = np.log2(C[i, j] * N / (S[j]*S[i]) + eps)
M[i, j] = max(0, pmi)
if verbose:
cnt += 1
if cnt % (total//100 + 1) == 0:
print('%.1f%% 완료' % (100*cnt/total))
return M인수 C는 동시발생 행렬, verbose는 진행상황 출력 여부를 결정하는 플래그
동시발생 행렬을 PPMI로 변환해보자!
import sys
sys.path.append('..')
import numpy as np
from common.util import preprocess, create_co_matrix, cos_similarity, ppmi
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
W = ppmi(C)
np.set_printoptions(precision=3) # 유효 자릿수를 세 자리로 표시
print('동시발생 행렬')
print(C)
print('-'*50)
print('PPMI')
print(W)
"""
동시발생 행렬
[[0 1 0 0 0 0 0]
[1 0 1 0 1 1 0]
[0 1 0 1 0 0 0]
[0 0 1 0 1 0 0]
[0 1 0 1 0 0 0]
[0 1 0 0 0 0 1]
[0 0 0 0 0 1 0]]
--------------------------------------------------
PPMI
[[ 0. 1.807 0. 0. 0. 0. 0. ]
[ 1.807 0. 0.807 0. 0.807 0.807 0. ]
[ 0. 0.807 0. 1.807 0. 0. 0. ]
[ 0. 0. 1.807 0. 1.807 0. 0. ]
[ 0. 0.807 0. 1.807 0. 0. 0. ]
[ 0. 0.807 0. 0. 0. 0. 2.807]
[ 0. 0. 0. 0. 0. 2.807 0. ]]
"""PPMI 행렬의 문제점
-
→말뭉치의 어휘 수가 증가함에 따라 벡터의 차원 수도 증가
(ex. 말뭉치의 어휘 수가 10만 개라면 그 벡터의 차원 수도 똑같이 10만) -
원소 대부분이 0이다. → 벡터의 원소 대부분이 중요하지 않다는 뜻
- 각 원소의 '중요도'가 낮다 → 이런 벡터는 노이즈에 약하고 견고하지 못함
➡️ 벡터의 차원 감소로 대처
4-2) 차원 감소
(dimensionality reduction)
📌 '중요한 정보'는 최대한 유지하면서 벡터의 차원을 줄이는 게 핵심!
차원 감소의 예) 데이터의 분포를 고려해 중요한 '축'을 찾는다.
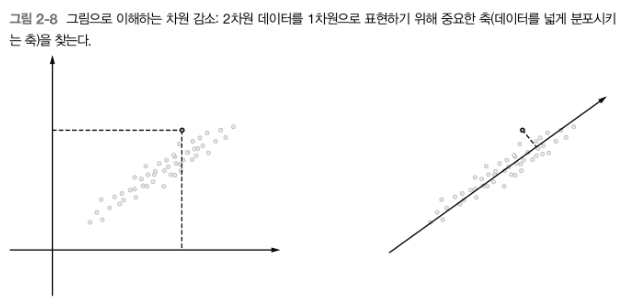
-
왼쪽: 데이터점들을 2차원 좌표에 표시
-
오른쪽: 새로운 축을 도입해 똑같은 데이터를 좌표축 하나만으로 표시
- 새로운 축을 찾을 때는 데이터가 넓게 분포되도록 고려
- 이때 각 데이터점의 값은 새로운 축으로 사영된 값
❗ 중요한 것은 가장 적합한 축을 찾는 것!
→ 1차원 값만으로도 데이터의 본질적인 차이를 구별할 수 있어야 한다!
희소행렬(sparse matrix)or희소벡터(sparse vector): 원소 대부분이 0인 행렬 or 벡터📌 차원 감소의 핵심은 희소벡터에서 중요한 축을 찾아내어 더 작은 차원으로 다시 표현하는 것
➡️ 차원 감소의 결과로 원래의 희소벡터는 원소 대부분이 0이 아닌 값으로 구성된밀집벡터로 변환
특잇값분해 (SVD)
차원을 감소시키는 방법 중 하나는 특잇값분해(SVD; Singular Value Decomposiiton)
SVD는 임의의 행렬을 세 행렬의 곱으로 분해
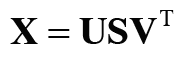
U와 V는 직교행렬(orthogonal matrix)이고, 그 열벡터는 서로 직교
S는 대각행렬(diagonal matrix; 대각성분 외에는 모두 0인 행렬)
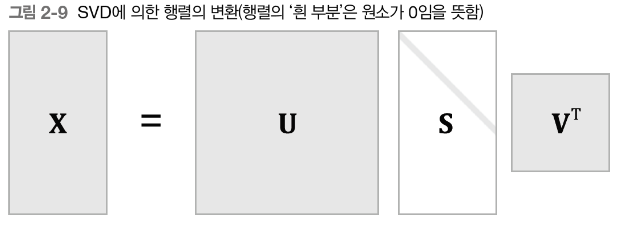
직교행렬인 U는 어떠한 공간의 축(기저)을 형성한다.
우리의 맥락에서는 이 U 행렬을 '단어 공간'으로 취급할 수 있다.
대각행렬인 S의 대각성분에는 '특잇값(singular value)'이 큰 순서로 나열되어 있다.
특잇값: '해당 축'의 중요도
→ 중요도가 낮은 원소(특잇값이 작은 원소)를 깍아내는 방법 (아래 그림)
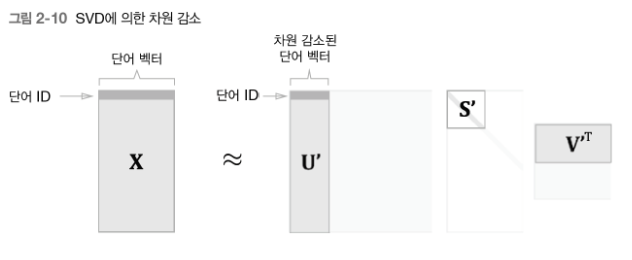
행렬 S에서 특잇값이 작다면 중요도가 낮다는 뜻이므로, 행렬 U에서 여분의 열벡터를 깎아내어 원래의 행렬을 근사할 수 있다.
➡️ 이를 우리 문제로 가져와서 '단어의 PPMI 행렬'에 적용하면, 행렬 X의 각 행에는 해당 단어 ID의 단어 벡터가 저장되어 있으며, 그 단어 벡터가 행렬 U'라는 차원 감소된 벡터로 표현되는 것!
단어의 동시발생 행렬은 정방행렬이지만 그림[2-10]에서는 그림[2-9]와 통일시키기 위해 직사각형으로 표시
4-3) SVD에 의한 차원 감소
SVD는 넘파이의 linalg 모듈이 제공하는 svd 메서드로 실행
(linalg는 선형대수(linear algebra)의 약어)
동시발생 행렬을 만들어 PPMI 행렬로 변환한 다음 SVD를 적용해보자!
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from common.util import preprocess, create_co_matrix, ppmi
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(id_to_word)
C = create_co_matrix(corpus, vocab_size, window_size=1)
W = ppmi(C)
# SVD
U, S, V = np.linalg.svd(W)이제 SVD를 수행할 수 있다.
SVD에 의해 변환된 밀집벡터 표현은 변수 U에 저장된다.
단어 ID가 0인 단어 벡터를 봐보자!
print(C[0] # 동시발생 행렬
# [0 1 0 0 0 0 0]
print(W[0]) # PPMI 행렬
# [ 0. 1.807 0. 0. 0. 0. 0. ]
print(U[0]) # SVD
# [ 3.409e-01 -1.110e-16 -1.205e-01 -4.441e-16 0.000e+00 -9.323e-01 2.226e-16]희소벡터인 W[0]가 SVD에 의해서 밀집벡터 U[0]으로 변했다.
이 밀집벡터의 차원을 감소시키려면, 예를 들어 2차원 벡터로 줄이려면 단순히 처음의 두 원소를 꺼내면 된다.
print(U[0, :2])
# [ 3.409e-01 -1.110e-16]이제 각 단어를 2차원 벡터로 표현한 후 그래프로 그려보자!
for word, word_id in word_to_id.items():
plt.annotate(word, (U[word_id, 0], U[word_id, 1]))
plt.scatter(U[:,0], U[:,1], alpha=0.5)
plt.show()plt.annotate(word, x, y) 메서드는 2차원 그래프상에서 좌표 (x,y) 지점에 word에 담긴 텍스트를 그린다.
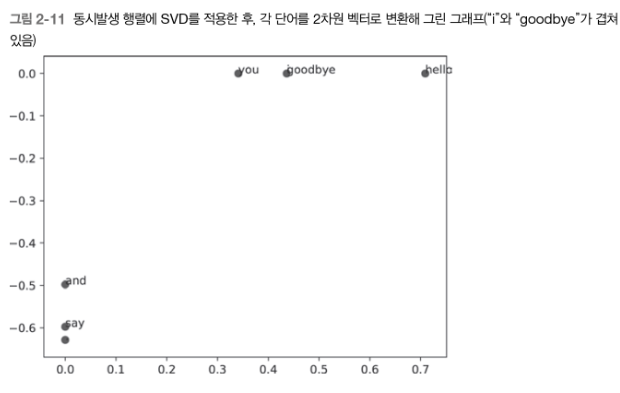
"goodbye"와 "hello", "you"와 "i"가 제법 가까이에 있는 것을 볼 수 있다.
행렬의 크기가 N이면 SVD 계산은 O(N³)이 걸린다.
계산량이 현실적으로 감당하기 어려운 수준이므로 Truncated SVD 같은 더 빠른 기법을 이용한다.
Truncated SVD: 특잇값이 작은 것은 버리는(truncated) 방식으로 성능 향상
다음 절에서도 옵션으로 사이킷런(scikit-learn) 라이브러리의 Truncated SVD 이용!
4-4) PTB 데이터셋 평가
지금까지는 아주 작은 텍스트 데이터를 말뭉치로 사용했다.
이제 펜 트리뱅크(PTB; Penn Treebank)을 사용해보자!
PTB 말뭉치는 주어진 기법의 품질을 측정하는 벤치마크로 자주 이용된다.
PTB 말뭉치에서는 한 문장이 하나의 줄로 저장되어 있다.
이 책에서는 각 문장을 연결한 '하나의 큰 시계열 데이터'로 취급! 이때 각 문장 끝에 <eos>라는 특수 문자를 삽입한다.
PTB 데이터셋에 통계 기반 기법을 적용해보자!
큰 행렬에 SVD를 적용해야 하므로 고속 SVD를 이용할 것을 추천!
import sys
sys.path.append('..')
import numpy as np
from common.util import most_similar, create_co_matrix, ppmi
from dataset import ptb
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
print('동시발생 수 계산...')
C = create_co_matrix(corpus, vocab_size, window_size)
print('PPMI 계산...')
W = ppmi(C, verbose=True)
print('SVD 게산...')
try:
# truncated SVD (빠름!)
from sklearn.utils.extmath import randomized_svd
U, S, V = randomized_svd(W, n_components=wordvec_size, n_iter=5, random_state=None)
except ImportError:
# SVD (느리고 메모리 훨씬 많이 사용!)
U, s, V = np.linalg.svd(W)
word_vecs = U[:, wordvec_size]
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)plt.load_data()는 데이터를 읽어 들인다. 이때 인수로는 'train', 'test', 'valid' 중 하나를 지정 가능!
SVD를 수행하는 데 sklearn의 randomized_svd() 메서드를 이용했다.
➡️ 이 메서드는 무작위 수를 사용한 Truncated SVD로, 특잇값이 큰 것들만 계산하여 기본적인 SVD보다 훨씬 빠르다.
아래는 실행결과이다.
"""
[query] you
i: 0.702039909619
we: 0.699448543998
've: 0.554828709147
do: 0.534370693098
else: 0.512044146526
[query] year
month: 0.731561990308
quarter: 0.658233992457
last: 0.622425716735
earlier: 0.607752074689
next: 0.601592506413
[query] car
luxury: 0.620933665528
auto: 0.615559874277
cars: 0.569818364381
vehicle: 0.498166879744
corsica: 0.472616831915
[query] toyota
motor: 0.738666107068
nissan: 0.677577542584
motors: 0.647163210589
honda: 0.628862370943
lexus: 0.604740429865
"""이제 '단어의 '의미'를 벡터로 잘 인코딩하는 데 성공했다!
📑정리) 말뭉치를 사용해 맥락에 속한 단어의 등장 횟수를 센 후 PPMI 행렬로 변환하고, 다시 SVD를 이용해 차원을 감소시킴으로써 더 좋은 단어 벡터를 얻어냈다.
➡️ 이것이 단어의 분산 표현이고, 각 단어는 고정 길이의 밀집벡터로 표현되었다.
5. 정리
"컴퓨터에게 '단어의 의미' 이해시키기"가 목표였다.
-
시소러스 기반 기법
: 단어들의 관련성을 사람이 수작업으로 하나씩 작업하기 때문에 힘들고 표현력에 한계 -
통계 기반 기법
: 말뭉치로부터 단어의 의미를 자동으로 추출하고, 그 의미를 벡터로 표현- 구체적으로는 단어의 동시발생 행렬을 만들고, PPMI 행렬로 변환한 다음, 안전성을 높이기 위해 SVD를 이용해 차원을 감소시켜 각 단어의 분산 표현을 만들어낸다.
- 분산 표현에 따르면 의미가 (그리고 문법적인 용법면에서) 비슷한 단어들이 벡터 공간에서도 서로 가까이 모여 있다.
또한 말뭉치의 텍스트 데이터를 다루기 쉽게 해주는 전처리 함수를 몇 개 구현 했다.
- 벡터 간 유사도를 측정하는
cos_similarity()함수 - 유사 단어의 랭킹을 표시하는
most_similar()함수
