맵리듀스 (MapReduce)
맵리듀스는 구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 개발한 프레임워크이다. 성능이 낮은 컴퓨터로 구성된 클러스터 환경에서 병렬 처리를 지원하기 위해 개발되었다.
HDFS가 하둡의 저장소를 담당했다면, 맵리듀스는 하둡에서 연산을 담당한다.
정렬된 데이터를 한 줄씩 읽어 데이터를 변형하는 Map 단계와, 그 결과를 집계하는 Reduce 단계로 구성된다.
맵리듀스를 사용하면 대규모 분산 컴퓨팅 환경에서 대량의 데이털르 병렬 처리할 수 있다.
맵리듀스 예시 - WordCount
다음의 텍스트가 있다고 해보자.
I am a boy
You are a girl
We lob each other맵 단계에서는 데이터를 한 줄, 즉 레코드 단위로 입력을 받는다.
맵은 데이터를 <Key, Value> 형태로 변환하는데, 여기서는 단어의 수를 세는 것이 목적이기에 <단어, 빈도수>로 구성된다.
그렇게 맵 단계를 거치면 다음과 같은 데이터가 형성된다.

그리고 리듀스 단계에서는 위의 결과를 집계하여 출력한다.

해당 실습 코드는 다음과 같다.
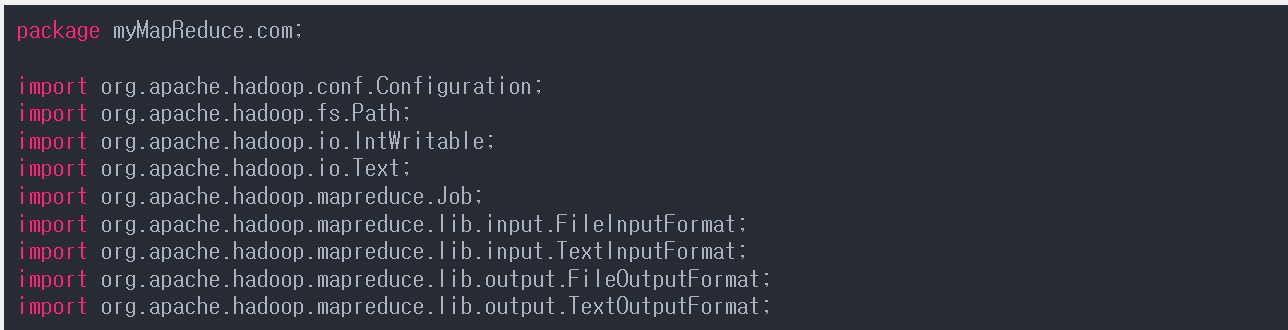
WordCount.java
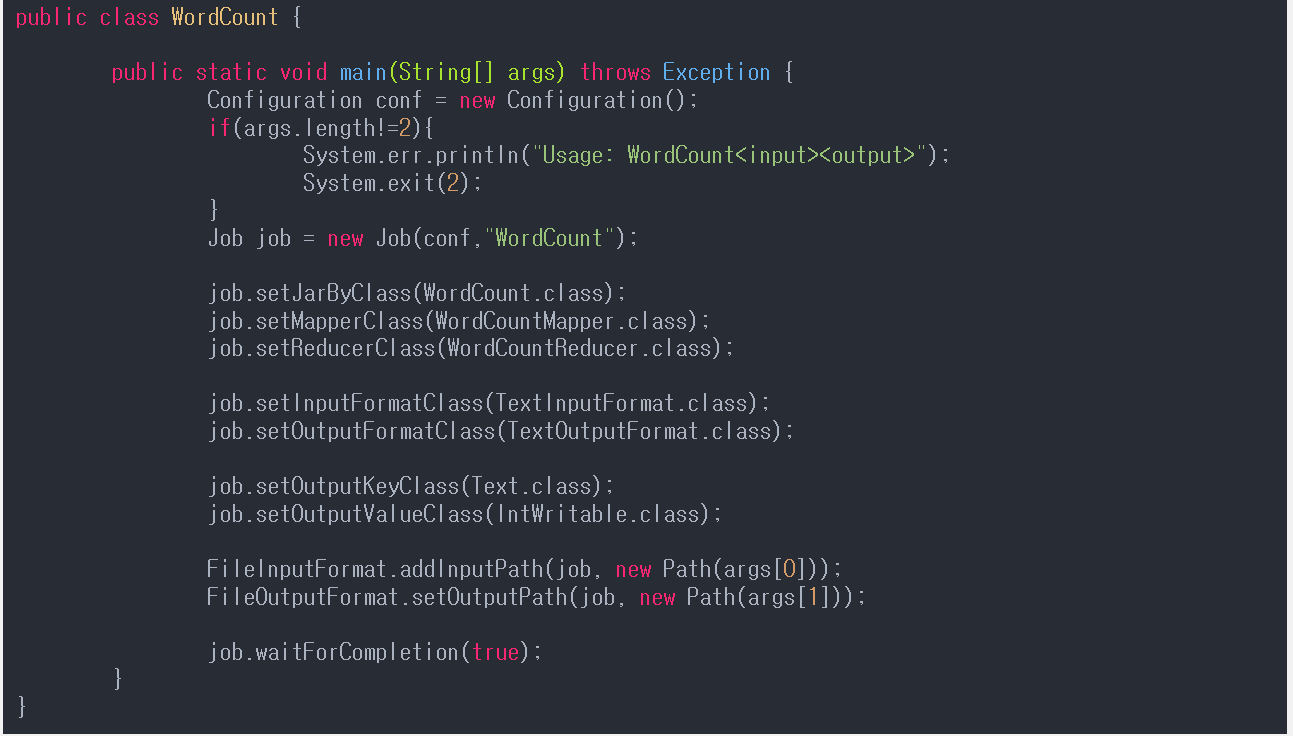
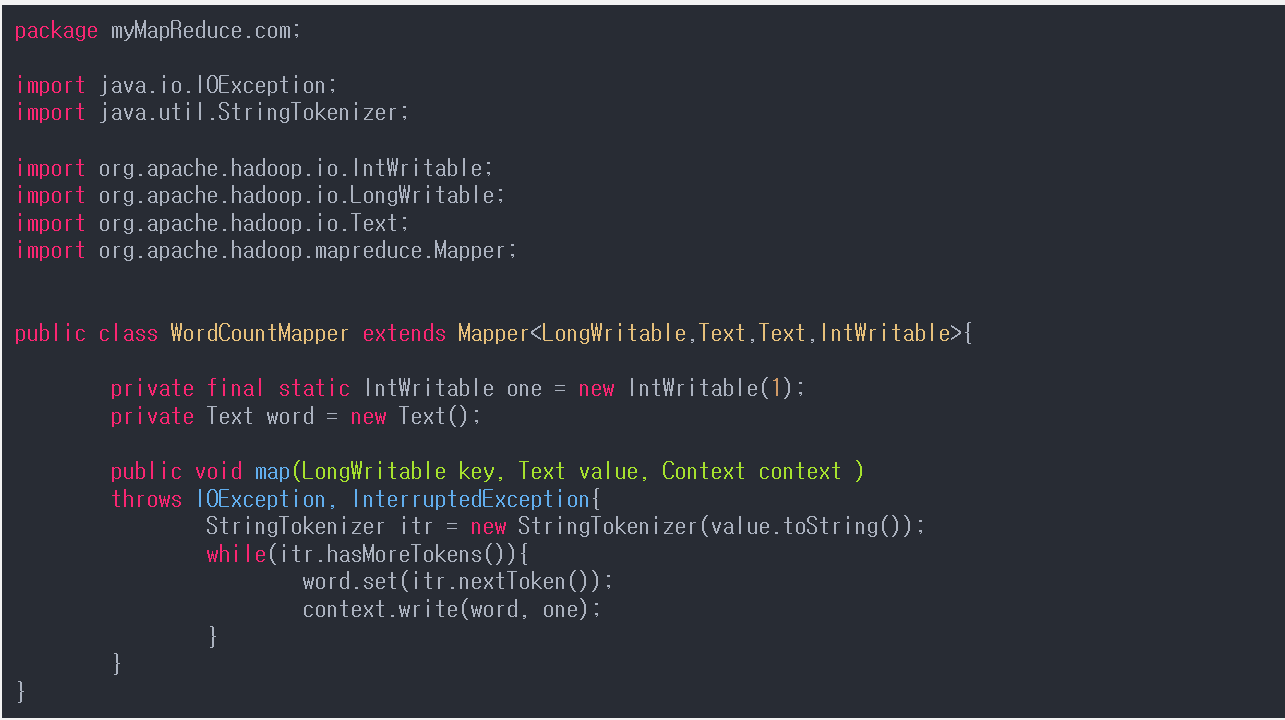
WordCountMapper.java
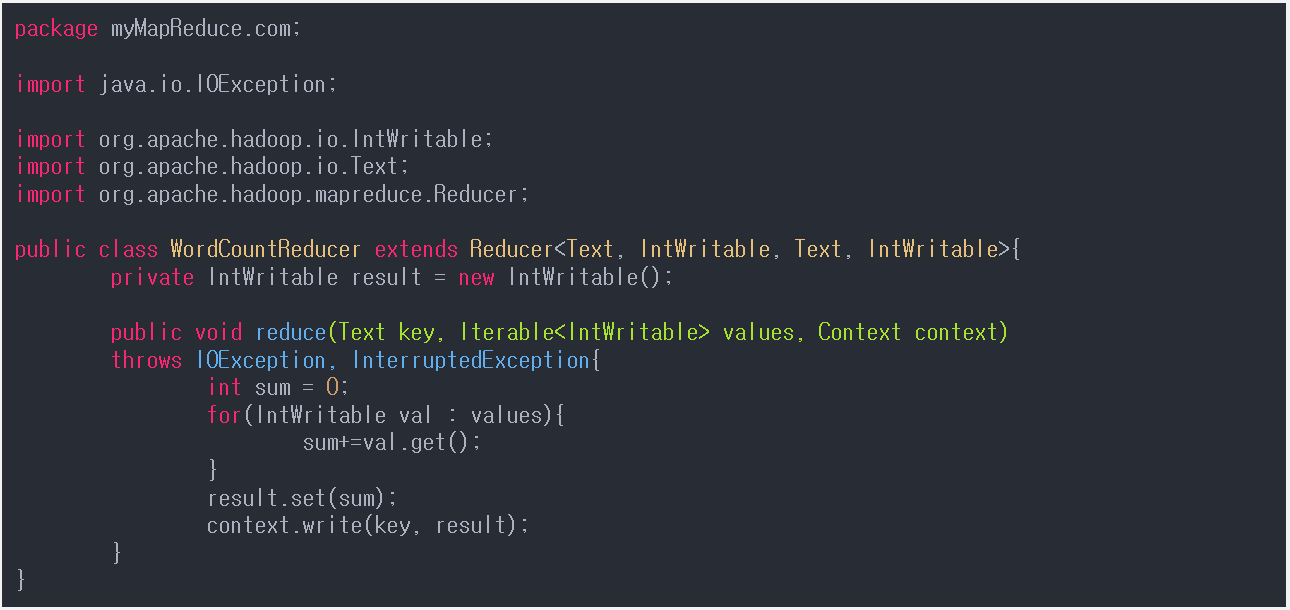
WordCountReducer.java
맵리듀스 아키텍처
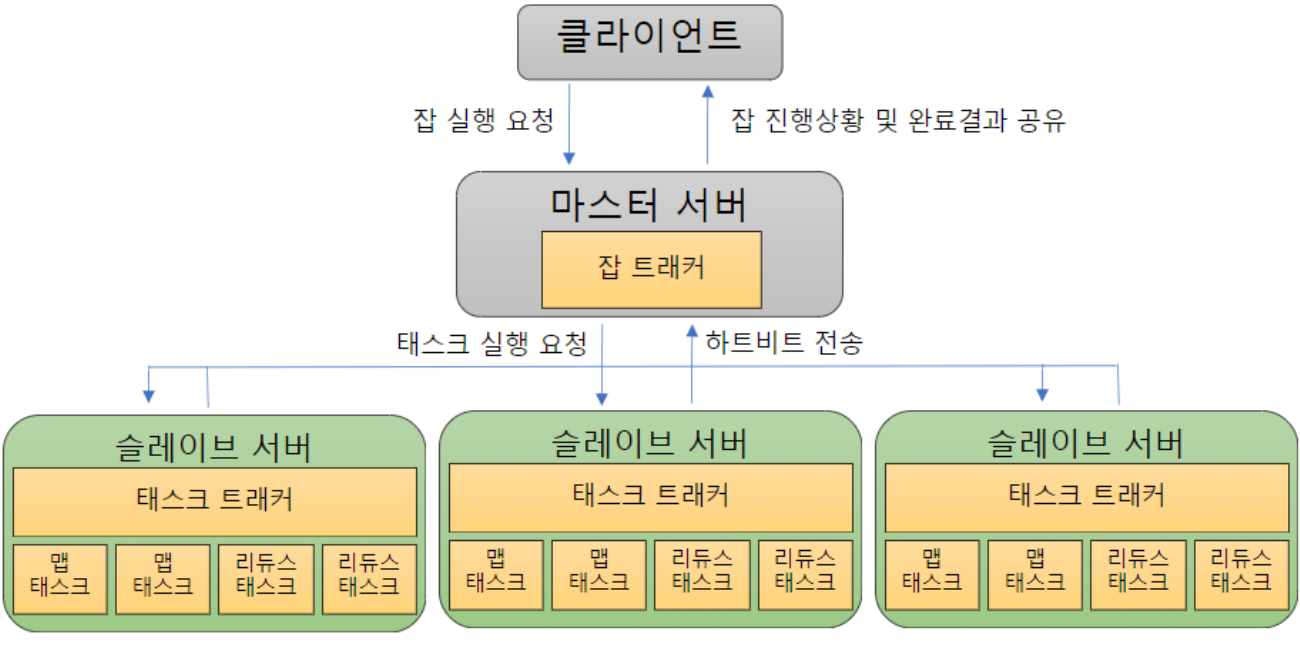
맵리듀스 프레임워크는 개발자로 하여금 분석 로직을 구현하는 데에만 집중하게 해주고, 데이터에 대한 분산과 병렬 처리는 프레임워크가 전담한다.
맵리듀스 프로그램은 잡이라는 하나의 작업 단위로 관리되며, 하나의 잡에는 맵과 리듀스 과정이 포함되어 있다.
맵리듀스는 프로그램은 한 번에 실행되는 태스크들의 묶음으로 클러스터에서 실행할 수 있는 태스크의 개수를 관리한다. 이러한 수행 단위는 슬롯이라 하며, 한정된 리소스를 용도에 따라 구분한 것이다. 슬롯은 맵 슬롯과, 리듀스 슬롯으로 구분되며 슬롯의 개수는 고정되어 있으나 개수 수정은 가능한다. 만약 모든 맵 슬롯이사용중이라면 리듀스 슬롯이 남아있더라도 맵 슬롯을 실행할 수 없다. 이러한 비효율성을 극복하기 위해 하둡2에서 도입된 것이 YARN이다.
맵리듀스에서 클라이언트는 사용자가 실행한 맵리듀스 프로그램과 하둡에서 제공하는 맵리듀스 api를 의미한다.
잡트래커는 하둡 클러스터에 등록된 전체 잡의 스케줄링 관리 및 모니터링을 실행한다.
보통 네임노드에서 실행되지만, 반드시 그럴 필요까지는 없다.
태스크 트래커는 하둡의 데이터 노드에서 실행되는 데몬이다.
잡트래커가 요청한 맵과 리듀스 개수만큼 맵 태스크와 리듀스 태스크를 생성하고, 태스크들을 새로운 JVM으로 구동해 실행한다.
하나의 데이터노드를 구성했더라도 여러 개의 JVM을 실행해 데이터를 동시에 분석하므로 병렬 처리가 가능하다.
맵리듀스의 실행 단계
1) 잡 실행 요청
클라이언트가 잡 트래커에 잡 id를 요청하고, HDFS에 공통 파일을 복사한 후 다시 잡 트래커에 잡 실행을 요청한다.
이 때 잡 실행은 org.apache.hadoop.mapreduce.job의 waitForCompletion 메서드로 잡 실행을 요청할 수 있다.
2) 잡 초기화
잡 트래커는 잡의 상태와 진행 과정을 모니터링할 수 있는 JobInProgress를 생성하고, 이는 스플릿 정보를 이용해 맵 태스크 개수와 리듀스 태스크 개수를 계산한다.
JonInProgress는 내부 큐인 jobs에 등록되고 스케줄러에 의해 소비된다.
3) 태스크 할당
태스크 트래커는 3초마다 잡 트래커에 하트비트를 전송하여 실행 준비가 완료되었음을 알린다.
잡 트래커는 이러한 태스크 트래커 중 하나에 큐에 있는 잡을 선택하여 HeartbeatResponse에 맵 태스크와 리듀스 태스크를 구분하여 태스크 실행을 요청한다.
4) 태스크 실행
태스크 트래커는 JVM을 생성해 (굳이 생성하지 않고 기존의 것 재사용 가능) HeartbearResponse의 태스크 정보를 꺼내 태스크의 상태와 진행 과정을 모니터링 할 TaskInProgress를 생성한다. 그 후 결과를 저장할 디렉터리 생성 후 job jar 파일을 풀어놓는다.
그리고 태스크 완료 시까지 진행 과정을 주기적으로 jvmManager에 알려준다.
5) 태스크 완료
하트비트 전송에 완료된 태스크 정보를 포함하여 전송한다. 클라이언트는 최종 결과를 출력하고 잡 실행을 종료한다.
셔플 (Shuffle)
셔플은 맵 태스크의 결과를 리듀스 태스크로 전달하는 과정이다.
셔플은 메모리에 저장된 매퍼의 출력 데이터를 파티셔닝 및 정렬 처리 후, 이를 로컬 디스크에 저장한다.
리듀서는 HTTP를 통해 맵 태스크 결과를 복사한다.
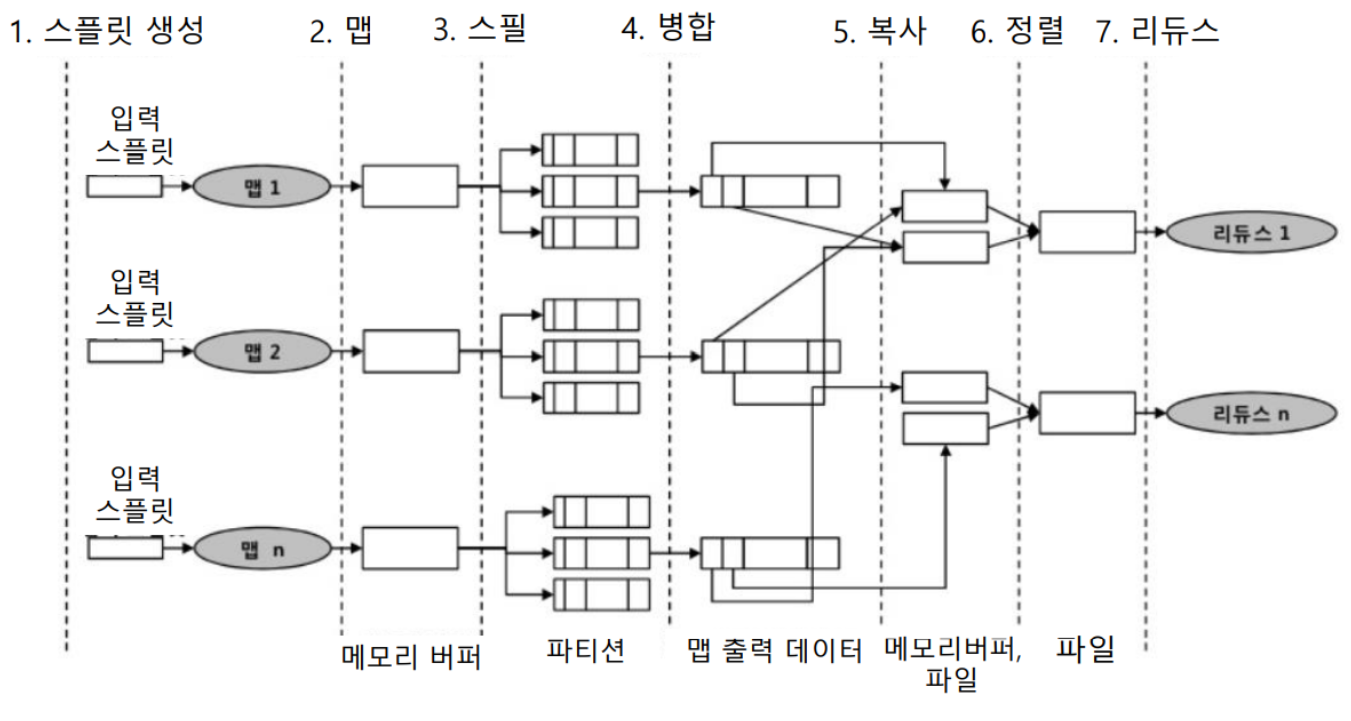
1) 스플릿 생성 : 블록을 논리적인 처리 단위인 스플릿으로 분류
2) 맵 : 메모리 버퍼 생성 후 맵의 출력 데이터를 버퍼에 기록
3) 스필 : 로컬 디스크에 데이터를 저장하기 전에 데이터를 분리하여 파티션 생성 및 정렬 (compareTo 메서드 사용)
4) 병합 : 스필된 파일들을 하나의 정렬된 출력 파일로 병합
5) 복사 : 리듀서는 맵 태스크 완료 시 필요한 출력 데이터를 네트워크를 통해 복사. 이 때 서버는 하트비트로 알려줌
6) 정렬 : 복사된 맵 출력 데이터를 라운드 단위로 진행하며 병합
7) 리듀스 : 정렬된 출력 내의 각 키에 대해 집계
파티셔너
맵 태스크의 출력 데이터가 어떤 리듀스 태스크로 전달될 지 결정
가본적으로 HasPartitioner를 사용하고, 다른 파티셔닝 전략 필요 시 Partitioner을 상속받아 (extends) getPartition 재정의
맵리듀스의 성능 개선 방법
1) 하둡 클러스터 증설
2) 맵리듀스 튜닝
3) 셔플의 각 속성을 응용의 특성에 맞게 수정 => 맵 출력 데이터 압축, JVM 재사용, 콤바이터 클래스 사용 등
참조자료
