Zookeeper
Hadoop Eco System의 분산 코디네이션 서비스(Distributed Coordination Service)인 주키퍼에 대해서 간단히 알아보자.

주키퍼는 Yahoo에서 처음 개발되어 Apache License로 오픈소스 된 프로젝트이다.
이름의 유래가 조금 재미있다. 빅데이터 생태계에는 코끼리(Hadoop), 범고래(Hbase), 벌(Hive), 타조, 등등등 동물 모양 로고가 유난히 많은데, 이런 동물들의 사육사 같은 역할로서 이름을 Zookeeper로 정했다고 한다.
실제로 Zookeeper는 Hbase, Kafka등 많은 분산 처리 프로그램의 분산 코디네이션 서비스로 활용되고 있다.
분산 코디네이션 서비스
다수의 노드에서 수행되는 분산 처리 어플리케이션은 단일 노드에서 수행되는 어플리케이션보다 매우 고려해야할 요소가 많은데, 그 중 가장 주요한 것은 부분 실패(Partial Failure) 다. 한 노드 안에서 프로그램이 수행될 때는 걱정하지 않아도 될 요소인 네크워크를 통해서 메시지가 전송되는 부분이 종종 문제가 된다. 특히 메세지를 전송하고 네트워크가 끊겼을 때 송신자는 수신자가 메세지를 성공적으로 수신했는지조차 알 수 없게 된다. 어쩌면 메시지를 받고 처리를 하고 나서 응답을 못준 것일 수도 있고, 메세지 전송 자체가 실패된 것일 수도 있다. 작업이 성공한 것인지 실패한 것인지 여부조차 알 수 없는 것이다.
주키퍼는 이러한 부분 실패를 안전하게 처리하기 위한 분산 처리 도구를 제공한다.
주키퍼의 특징과 장점
-
단순하다
사용자는 몇가지 추상화된 기능을 통해서 분산처리를 위한 주키퍼 파일시스템을 활용할 수 있다. -
기능이 풍부하다
대규모 데이터 구조와 프로토콜의 코디네이션에 사용되는 구성요소를 제공한다. -
고가용성을 제공한다
다수의 머신에서 실행되며 고가용성을 보장하도록 설계되었다. -
느슨하게 연결된 상호작용을 할 수 있도록 해준다.
주키퍼가 동작할 때 참여자들은 서로에 대해 몰라도 상관 없다. -
오픈소스 라이브러리다
일반적인 코디네이션 패턴에 대한 구현체와 구현 방법을 오픈소스로 제공한다. 공통 프로토콜을 직접 개발(보통 제대로 하기 어렵다)하는 부담에서 벗어날 수 있다.
주키퍼 데이터 모델
주키퍼는 내부적으로 데이터를 znode라 불리는 노드에 계층적 트리 형태로 관리한다.
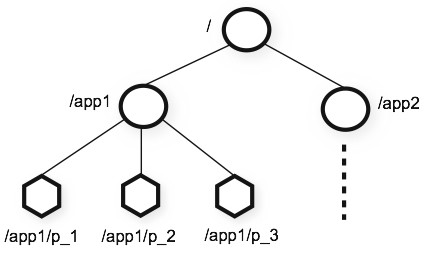
주키퍼의 znode 경로는 ‘/’로 구분된 유니코드 문자열 namespace 구조로 유닉스의 파일시스템 구조와 같다. 상대경로를 지원하지 않고 절대경로만 지원한다.
데이터 접근은 원자성(성공 또는 실패)를 가진다. 클라이언트가 znode에 저장된 데이터를 읽을 때 데이터 전체가 전달되지 않으면 읽기는 실패한다. 쓰기도 마찬가지로 전체를 갱신한다. 즉 append 기능을 지원하지 않는다.
주키퍼 클러스터: 앙상블
주키퍼는 테스트 용도가 아닌 이상 기본적으로 다수의 노드를 가진 클러스터구조에서 replicated mode로 수행되어야 한다. 주키퍼의 이러한 클러스터 구조를 앙상블이라 한다.
고가용성
주키퍼는 복제를 통해 고가용성을 달성하는데, 앙상블 내에서 과반수의 컴퓨터가 운영 중인 동안에만 서비스를 제공할 수 있다. 예를 들면 5노드 앙상블에서 두 대의 컴퓨터에 장애가 생기더라도 서비스는 여전히 동작한다. 과반수인 세 대가 남아있기 때문이다.
이러한 이유로 앙상블에는 일반적으로 홀수의 노드를 둔다.
주키퍼의 개념은 간단한 편이다.
znode 트리에 대한 모든 수정이 앙상블의 과반수 노드에 복제되도록 보장하는 것이다. 만약 소수(minority) 노드에 장애가 생기면 최소 한대의 컴퓨터는 가장 최신 상태를 간직한 채 살아있을 것이다. 결국 남은 복제 노드가 점차적으로 최신 상태를 복제해갈 수 있다.
Zab
주키퍼는 Zab이라는 두 단계로 동작하는 프로토콜로 앙상블의 장애 상황을 복구해낸다.
-
대표 선출
앙상블 내의 서버들은 리더(leader)라는 특별한 멤버를 선출한다. 나머지 다른 서버는 팔로워(follower)가 된다. 과반수(정족수=쿼럼(quorum)) 팔로워의 상태가 리더와 동기화 되면 대표 선출 단계가 끝난다. -
Atomic Broadcast
모든 쓰기 요청은 리더에게 forward 되고,
리더는 팔로워에게 업데이트를 broadcast 한다.
과반수 노드에서 변경을 저장하면 리더는 업데이트 연산을 commit하고, 클라이언트는 업데이터가 성공했다는 응답을 받게 된다.
합의를 위한 포로토콜은 원자적으로 설계되었으므로 변경 결과는 성공, 실패 둘 중 하나다.
리더 재선출 소요시간
만약 리더에 문제가 발생하면 남은 서버들은 재빠르게 새로운 리더를 선출하고 서비스를 계속한다. 리더가 다시 복구되어 돌아오면 팔로워로 시작한다. 이 리더 선출 과정은 매우 빨라서 대략 200ms가 걸릴 뿐이다.
따라서 리더 재선출이 수행되더라도 눈에 띄는 성능 저하는 거의 없다고 봐도 좋다.
메모리 활용을 통한 빠른 검색 속도 제공
앙상블의 모든 서버는 업데이트 사항을 znode 트리의 메모리 복사본에 기록하기 전에 디스크에도 기록해둔다.
읽기는 모든 서버에 요청하여 응답을 받을 수 있고, 오로지 메모리에서만 검색하므로 속도가 매우 빠르다.
