Airflow란?
Airflow는 Python 코드로 워크플로우(workflow)를 작성하고, 스케쥴링, 모니터링 하는 플랫폼입니다. Airflow를 통해서 데이터엔지니어링의 ETL 작업을 자동화하고, DAG(Directed Acyclic Graph) 형태의 워크플로우 작성이 가능합니다. 이를 통해 더 정교한 dependency를 가진 파이프라인을 설정할 수 있습니다. 또한 AWS, GCP 모두 Airflow managed service를 제공할 정도로 전세계 데이터팀들에게 널리 사용되고 있으며 그만큼 넓은 커뮤니티를 형성하고 있습니다.
Airflow 동작 원리
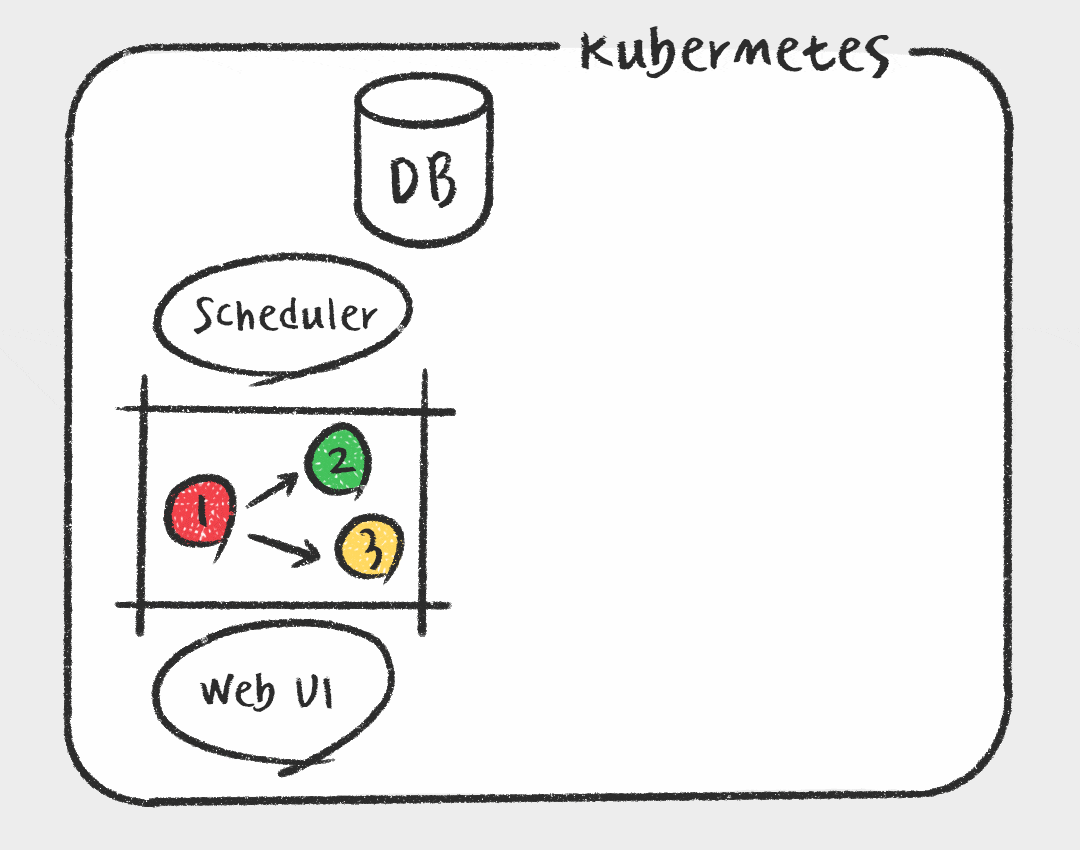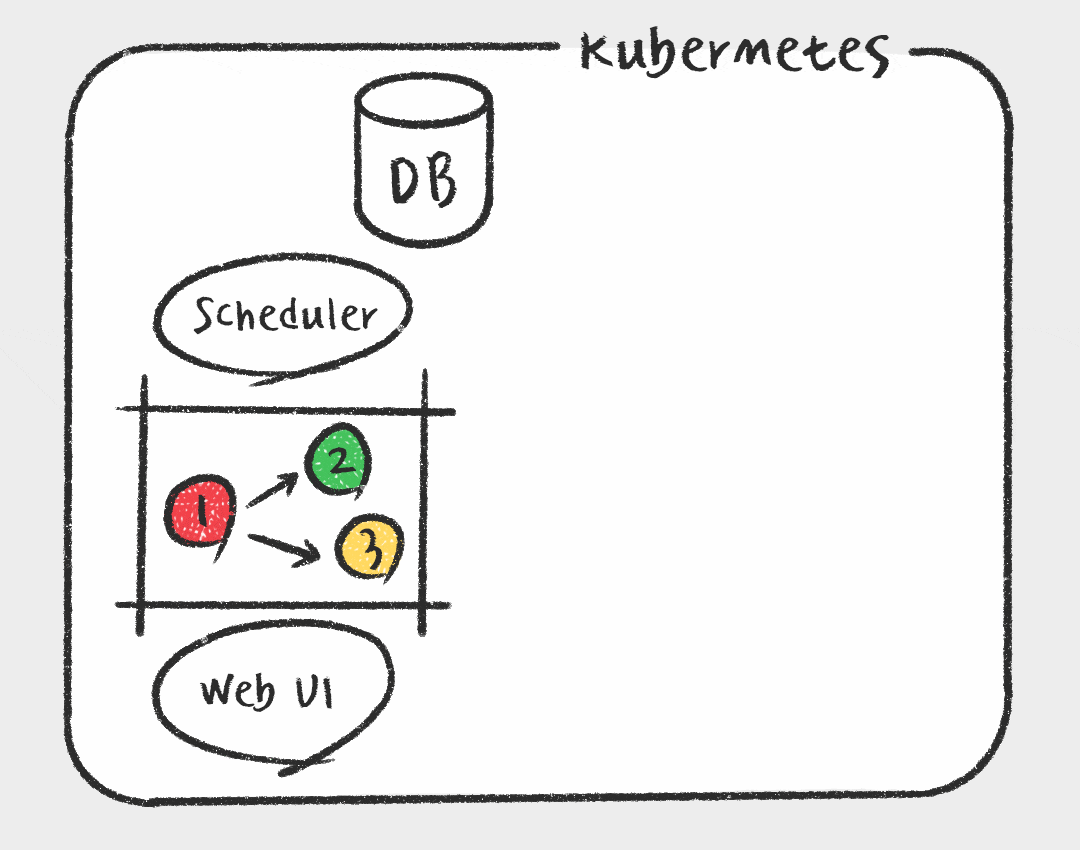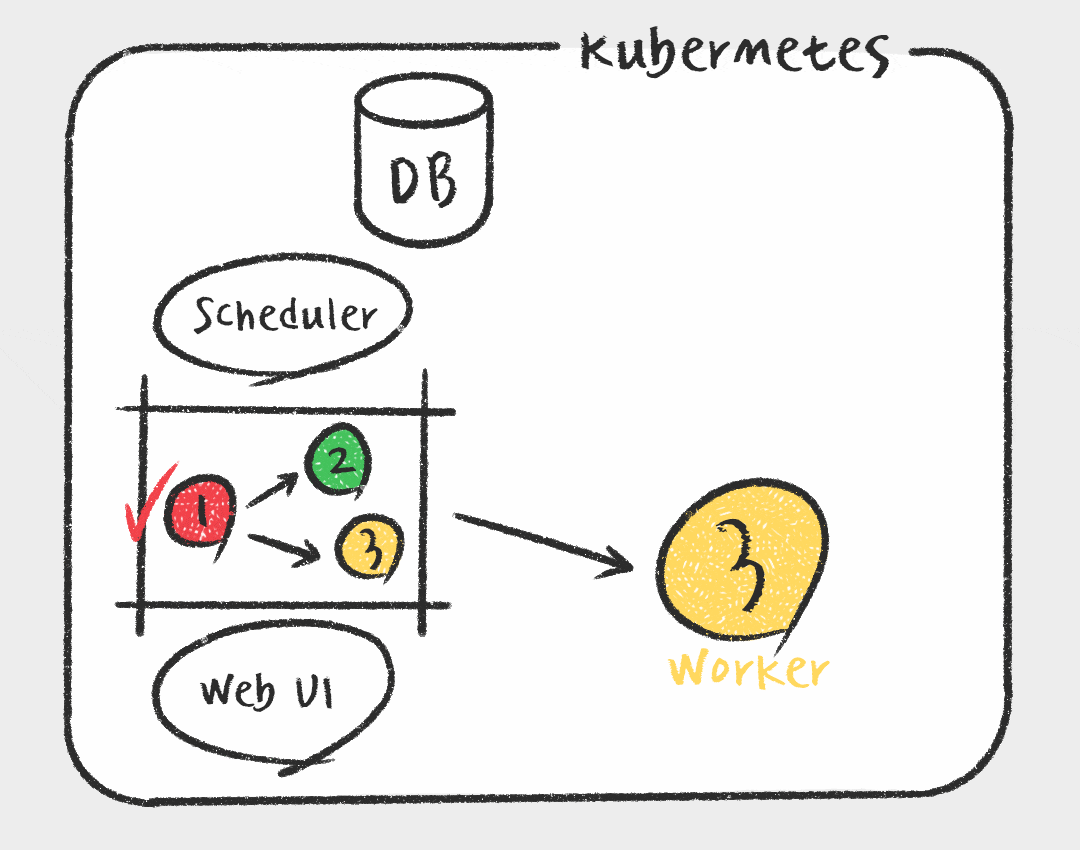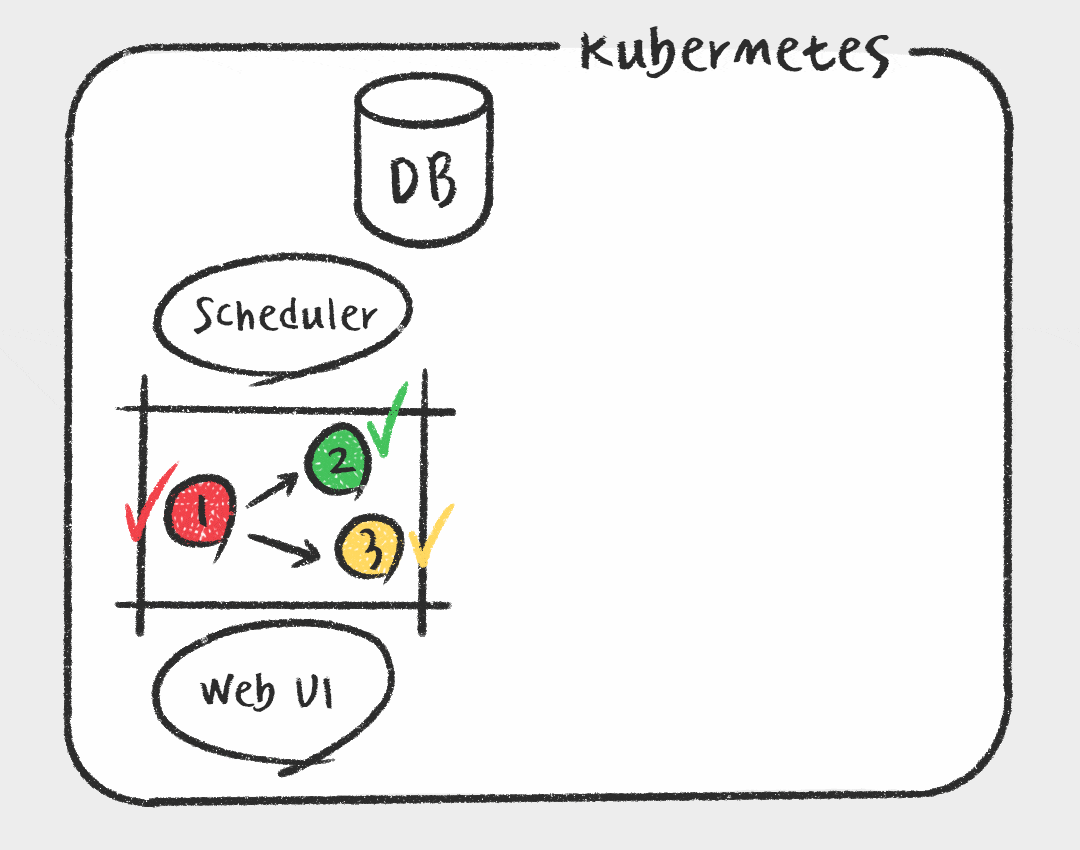
Airflow는 여러가지 구성요소를 가지고 있습니다.
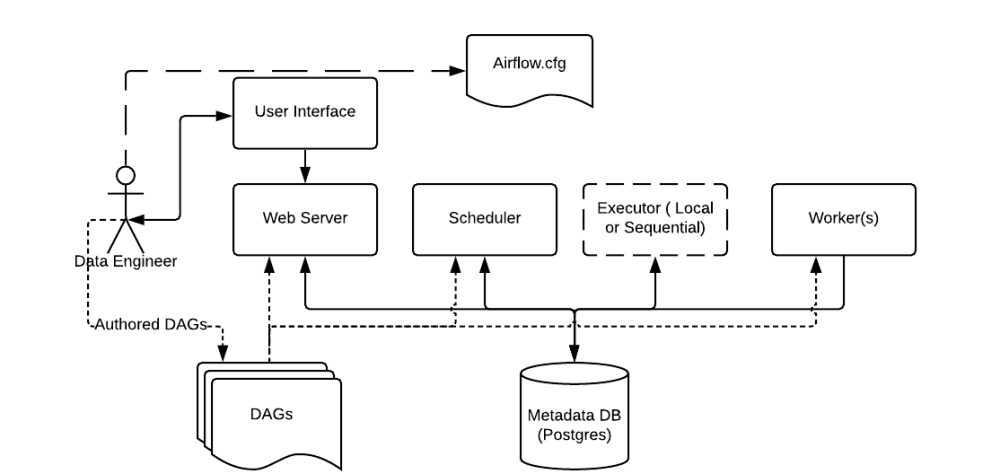
- Scheduler : 모든 DAG와 Task에 대하여 모니터링 및 관리하고, 실행해야할 Task를 스케줄링 해줍니다.
- Web server : Airflow의 웹 UI 서버 입니다.
- DAG : Directed Acyclic Graph로 개발자가 Python으로 작성한 워크플로우 입니다. Task들의 dependency를 정의합니다.
- Database : Airflow에 존재하는 DAG와 Task들의 메타데이터를 저장하는 데이터베이스입니다.
- Worker : 실제 Task를 실행하는 주체입니다. Executor 종류에 따라 동작 방식이 다양합니다.
Airflow는 개발자가 작성한 Python DAG를 읽고, 거기에 맞춰 Scheduler가 Task를 스케줄링하면, Worker가 Task를 가져가 실행합니다. Task의 실행상태는 Database에 저장되고, 사용자는 UI를 통해서 각 Task의 실행 상태, 성공 여부 등을 확인할 수 있습니다.
Airflow DAG(Directed Acyclic Graph)
Airflow의 DAG는 실행하고 싶은 Task들의 관계와 dependency를 표현하고 있는 Task들의 모음입니다. 어떤 순서와 어떤 dependency로 실행할지, 어떤 스케줄로 실행할지 등의 정보를 가지고 있습니다. 따라서 DAG를 정확하게 설정해야, Task를 원하는 대로 스케쥴링할 수 있습니다.
Airflow Operator
각 Airflow DAG는 여러 Task로 이루어져있습니다. operator나 sensor가 하나의 Task로 만들어집니다. Airflow는 기본적인 Task를 위해 다양한 operator를 제공합니다.
- BashOperator : bash command를 실행
- PythonOperator : Python 함수를 실행
- EmailOperator : Email을 발송
- MySqlOperator : sql 쿼리를 수행
- Sensor : 시간, 파일, db row, 등등을 기다리는 센서
Airflow에서 기본으로 제공하는 operator 외에도 커뮤니티에서 만든 수많은 operator들이 Data Engineer의 작업을 편하게 만들어 주고 있습니다.
Airflow Executor
위에서 Worker의 동작이 Airflow Executor의 종류에 따라 달라진다고 설명드렸는데요. Executor는 Task를 실행하는 주체로, 다양한 종류가 있고 각각 다른 특징을 가지고 있습니다.
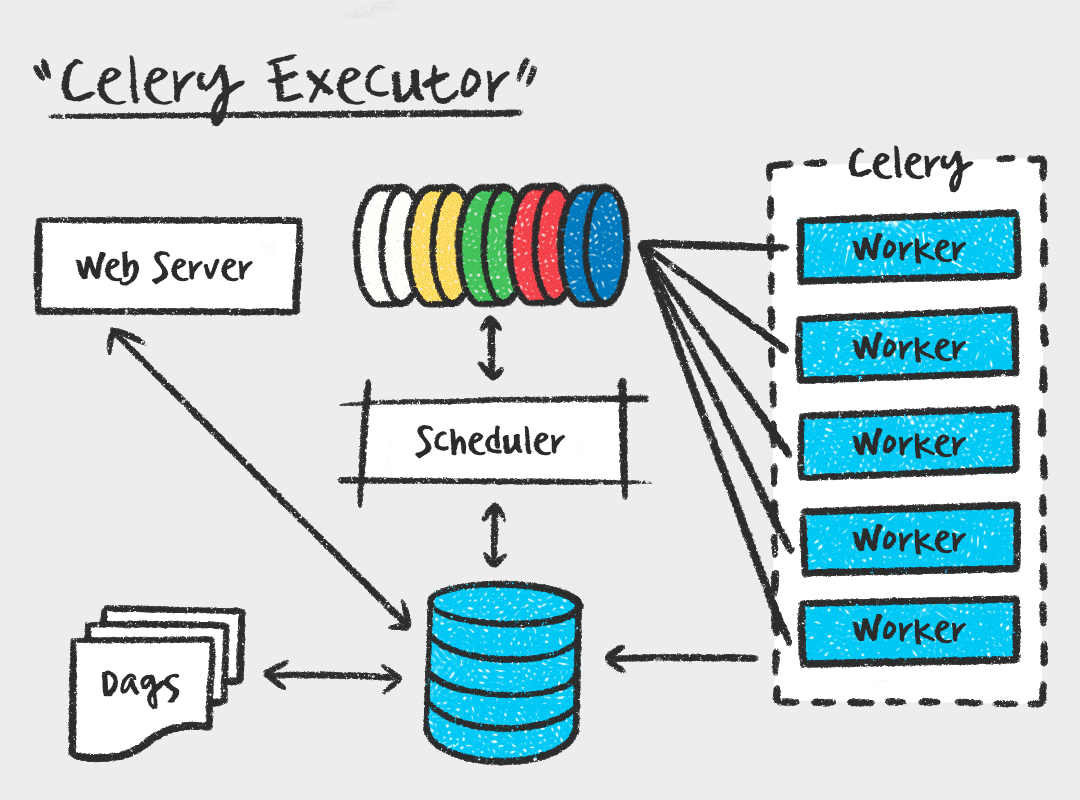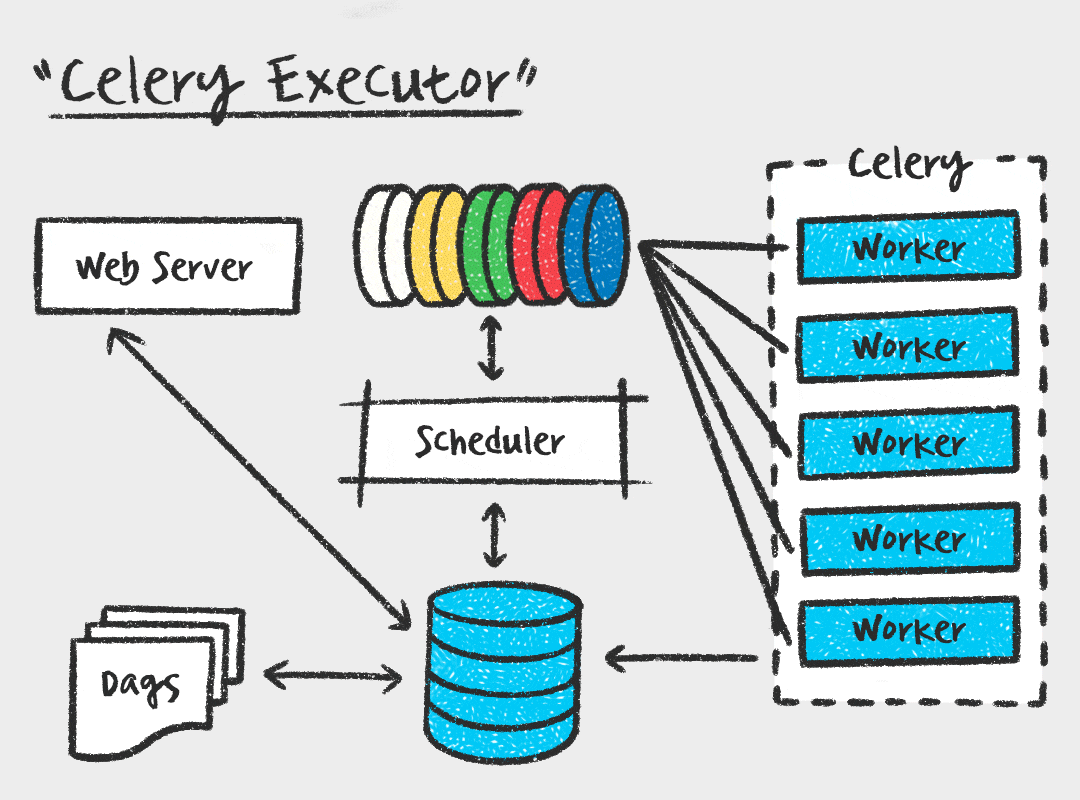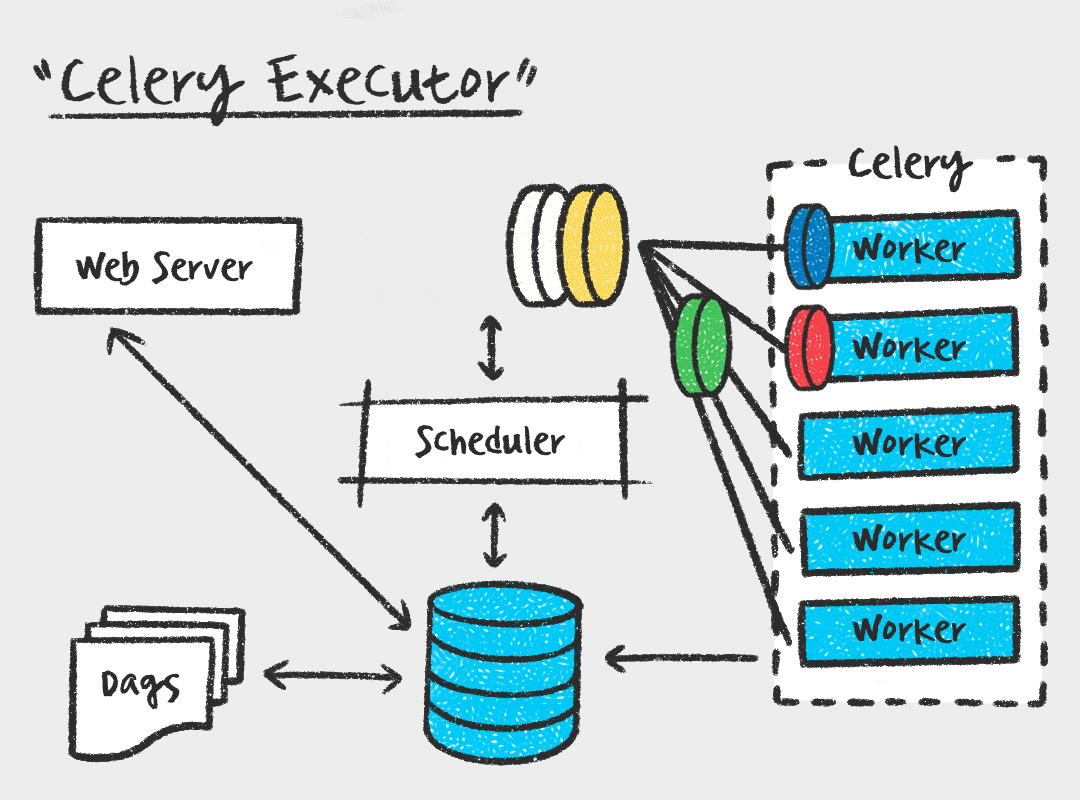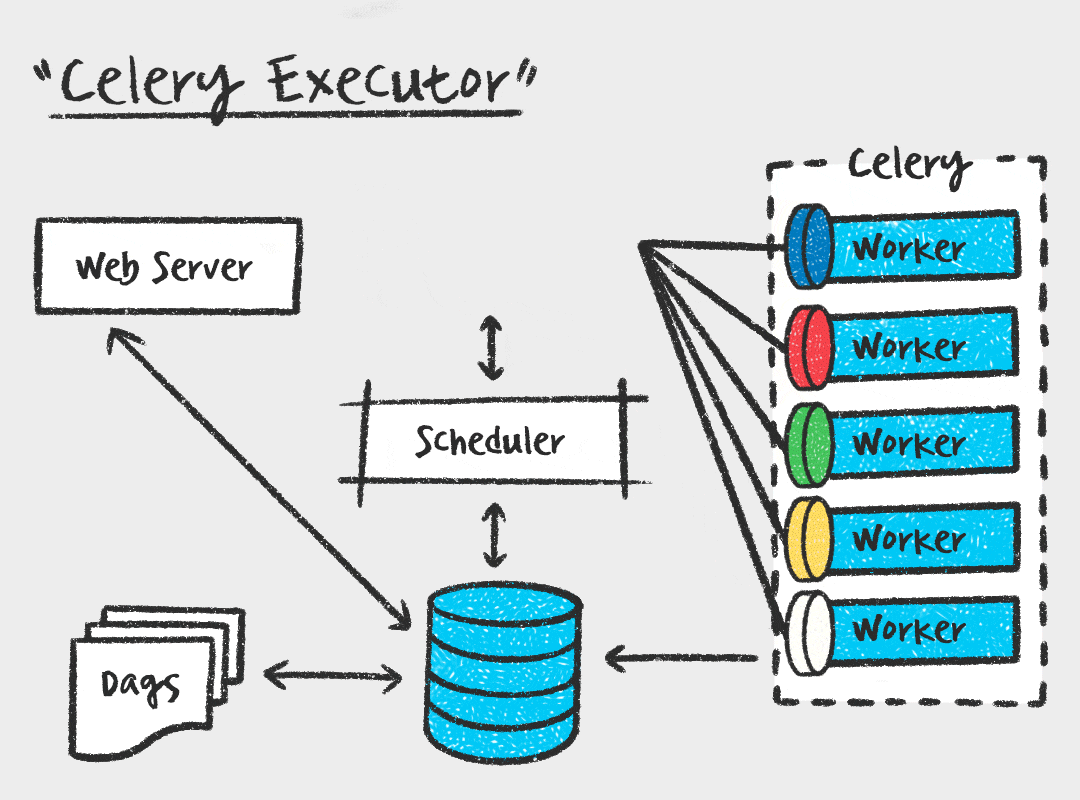
Celery Executor
먼저, Celery Executor는 Task를 메시지 브로커에 전달하고, Celery Worker가 Task를 가져가서 실행하는 방식입니다. Worker 수를 스케일아웃 할 수 있다는 장점이 있지만, 메시지 브로커를 따로 관리해야하고 워커 프로세스에 대한 모니터링도 필요하다는 단점이 있습니다.
Kubernetes Executor
그에 비해 Kubernetes Executor는 Task를 스케줄러가 실행가능 상태로 변경하면 메시지 브로커에 전달하는게 아니라 Kubernetes API를 사용하여 Airflow 워커를 pod 형태로 실행합니다. 매 Task마다 pod가 생성되므로 가볍고, Worker에 대한 유지 보수가 필요없다는 장점이 있습니다. 또한 Kubernetes를 활용하여 지속적으로 자원을 점유하지 않기 때문에 효율적으로 자원을 사용할 수 있습니다. 하지만 짧은 Task에도 pod을 생성하는 overhead가 있으며, celery executor에 비해 자료가 적고 구성이 복잡하다는 단점이 있습니다.
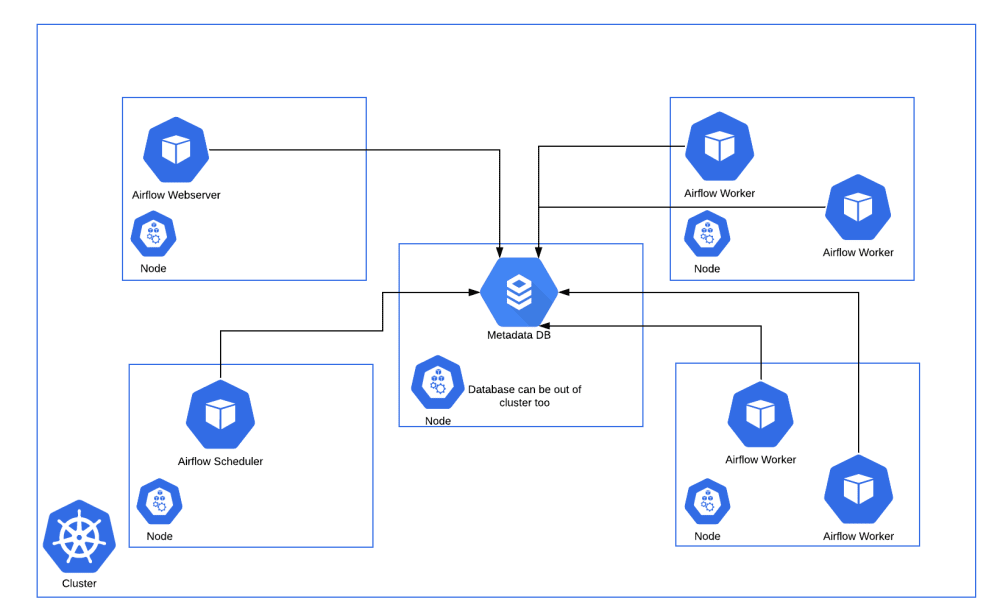
데이터 플랫폼 개선 작업을 할때 가장 중요하게 고려한 점이 안정성과 확장성이기 때문에 Kubernetes Executor가 회사에서 선호됩니다. 또한 필요에 따라 Kubernetes API를 활용하여 추후에 Data Scientist를 위한 GPU 인스턴스를 사용하거나, Kubernetes Pod Operator를 사용하여 Python 말고도 R이나 SAS 로 된 Task를 컨테이너 환경에서 지원이 가능할 것으로 예상됩니다.
참고
