Parquet에서 append와 overwrite
-
append
df를 생성하고 parquet으로 저장columns = ["singer", "country"] data1 = [("feid", "colombia")] rdd1 = spark.sparkContext.parallelize(data1) df1 = rdd1.toDF(columns)df1.repartition(1).write.format("parquet").save("tmp/singers1")tmp/singers1 ├── _SUCCESS └── part-00000-ffcc616b-4009-462a-a60d-9e2bd7130083-c000.snappy.parquet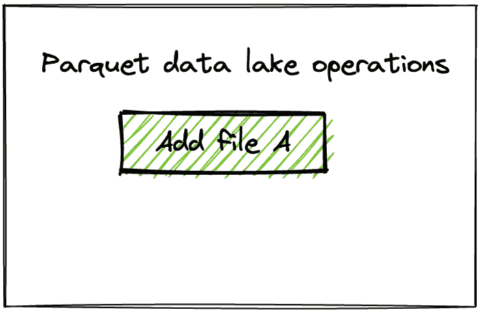
이후 또 다른 df를 만들어 parquet 테이블에 추가했을때
```python data2 = [("annita", "brasil")] rdd2 = spark.sparkContext.parallelize(data2) df2 = rdd2.toDF(columns) ``` ```python df2.repartition(1).write.mode("append").format("parquet").save("tmp/singers1") ``` ``` tmp/singers1├── _SUCCESS
├── part-00000-49da366f-fd15-481b-a3a4-8b3bd26ef2c7-c000.snappy.parquet
└── part-00000-ffcc616b-4009-462a-a60d-9e2bd7130083-c000.snappy.parquet```
-
overwrite
df를 생성하고 overwrite로 저장했을때data3 = [("rihanna", "barbados")] rdd3 = spark.sparkContext.parallelize(data3) df3 = rdd3.toDF(columns)df3.repartition(1).write.mode("overwrite").format("parquet").save("tmp/singers1")+-------+--------+ | singer| country| +-------+--------+ |rihanna|barbados| +-------+--------+tmp/singers1 ├── _SUCCESS └── part-00000-63531918-401d-4983-8848-7b99fff39713-c000.snappy.parquet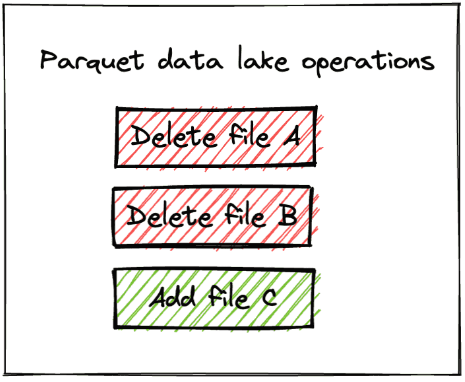
savemode가 overwrite일때 paquet에서는 새 파일을 쓰고 기존 파일을 전부 삭제하는 것을 확인할 수 있다.
Delta lake에서 append와 overwrite
-
append
위의 parquet과 동일하게 df를 생성하고 Delta table을 생성df1.repartition(1).write.format("delta").save("tmp/singers2")+------+--------+ |singer| country| +------+--------+ | feid|colombia| +------+--------+tmp/singers2 ├── _delta_log │ └── 00000000000000000000.json └── part-00000-946ae20f-fa5a-4e92-b1c9-49322594609a-c000.snappy.parquet이후 또 다른 df를 만들어 parquet 테이블에 추가했을때
df2.repartition(1).write.mode("append").format("delta").save("tmp/singers2")+------+--------+ |singer| country| +------+--------+ |annita| brasil| | feid|colombia| +------+--------+tmp/singers2 ├── _delta_log │ ├── 00000000000000000000.json │ └── 00000000000000000001.json ├── part-00000-946ae20f-fa5a-4e92-b1c9-49322594609a-c000.snappy.parquet └── part-00000-adda870a-83a2-4f5c-82a0-c6ecc60d9d2e-c000.snappy.parquet -
overwrite
df3.repartition(1).write.mode("overwrite").format("delta").save("tmp/singers2")+-------+--------+ | singer| country| +-------+--------+ |rihanna|barbados| +-------+--------+tmp/singers2 ├── _delta_log │ ├── 00000000000000000000.json │ ├── 00000000000000000001.json │ └── 00000000000000000002.json ├── part-00000-2d176e2d-66e0-44b6-8922-6bc3a15a6b96-c000.snappy.parquet ├── part-00000-946ae20f-fa5a-4e92-b1c9-49322594609a-c000.snappy.parquet └── part-00000-adda870a-83a2-4f5c-82a0-c6ecc60d9d2e-c000.snappy.parquet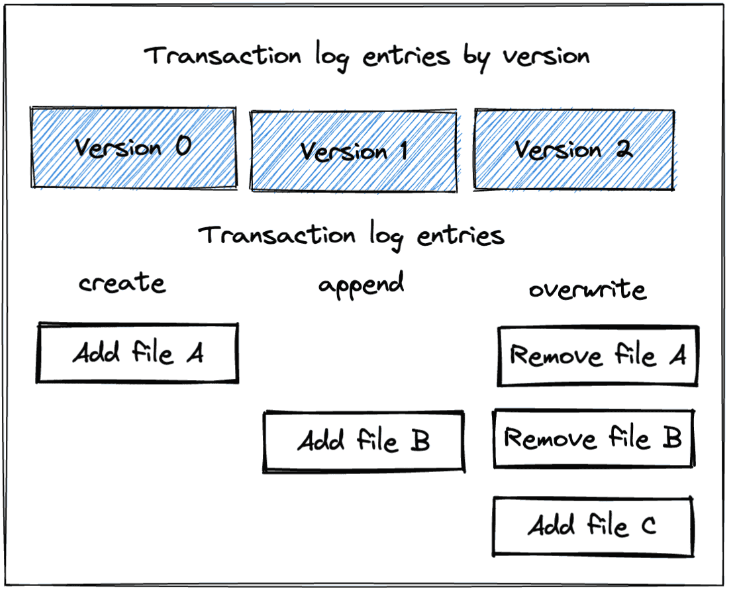
Delta Lake의 overwrite 작업은 기본 Parquet 파일을 삭제하지 않으며 기존 파일을 무시하기 위해 트랜잭션 로그에 항목을 추가하고(논리적 삭제) 실제로 파일을 제거하지는 않는다(물리적 삭제).
참고 자료

Data Engineer