
데이터 레이크하우스의 등장
2010년대까지 기업이 데이터 활용을 위해 관리하던 방식은 크게 데이터 웨어하우스(Data Warehouse, DW)와 데이터 레이크(Data Lake)로 나눌 수 있다. 두 개념 모두 데이터를 중앙적으로 관리하기 위해 등장한 개념으로 DW는 정형 데이터를 중심으로 데이터의 저장, 관리, 검색, 분석이 가능하다는 점에서 비즈니스 인사이트 도출에 중요한 역할을 담당했다.
하지만 정형 데이터 중심이라는 한계점으로 인해 비정형, 반정형 데이터 처리가 필요한 머신러닝 데이터 페르소나(Data Persona)의 요구사항을 충족하지 못하고 여전히 데이터 사일로(Data Silo) 문제가 발생한다는 문제점으로부터 우선 한곳에 모두 수집하고, 오브젝트 스토리지 형태로 정형을 비롯한 비정형, 반정형 데이터 처리가 가능한 데이터 레이크가 인기를 얻었다.
데이터 레이크는 많은 장점이 있었지만 DW와 달리 데이터의 관리, 접근이 용이하지 않아 쌓기는 하지만 정작 활용을 하지 못하는 데이터 늪(Data Swamp)이 되는 문제가 발생했다. 이런 배경에서 데이터 레이크 처럼 확장 가능한 오브젝트 스토리지 기반으로 저장하면서도 데이터의 관리 및 분석이 가능한 관리 방식의 필요성이 대두하면서 데이터 레이크하우스가 등장했다.
데이터 레이크하우스의 장점
데이터 레이크하우스는 데이터 웨어하우스와 데이터 레이크의 장점을 결합한 형태로 아래와 같은 장점이 있다.
- 다양한 데이터 형태(정형, 반정형, 비정형)로 수집 및 저장이 가능하다.
- 데이터의 관리 및 분석이 가능하기 때문에 데이터 늪이 되는 문제를 줄일 수 있다.
- 다양한 데이터 페르소나의 요구사항을 충족할 수 있다(분석, 머신러닝 등).
- Batch와 Streaming 워크로드의 결합이 가능하다.
Delta Lake
데이터 레이크하우스의 구현을 위해 개발된 여러 데이터 포맷이 있다. 대표적으로 Delta Lake와 Apache Iceberg가 있으며 이 글에서는 Delta Lake를 중심으로 살펴본다.

데이터레이크 구축의 핵심은 메타데이터 관리라고 생각한다. 잘못된 데이터가 계속 유입되거나 필요한 데이터가 어느 경로에 어떤 구조로 저장되어있는지 관리되지 않으면, 비용만 차지하는 데이터 늪이 되기 쉽다.
Delta Lake는 데이터 레이크 위에 Lakehouse 아키텍처를 구축할 수 있는 오픈소스 스토리지다. Spark를 개발한 UC버클리대학 AMP랩에서 설립한 Databricks라는 회사에서 주도하는 프로젝트로서, 데이터 레이크의 문제점과 데이터 웨어하우스의 문제점을 보완해줄 수 있다.
Delta Lake 특징
- Delta Lake에서 모든 연산은 Append
- ACID
- Schema enforcement
- Time travel
- 성능
- 비용
Delta Lake에서 모든 연산은 Append
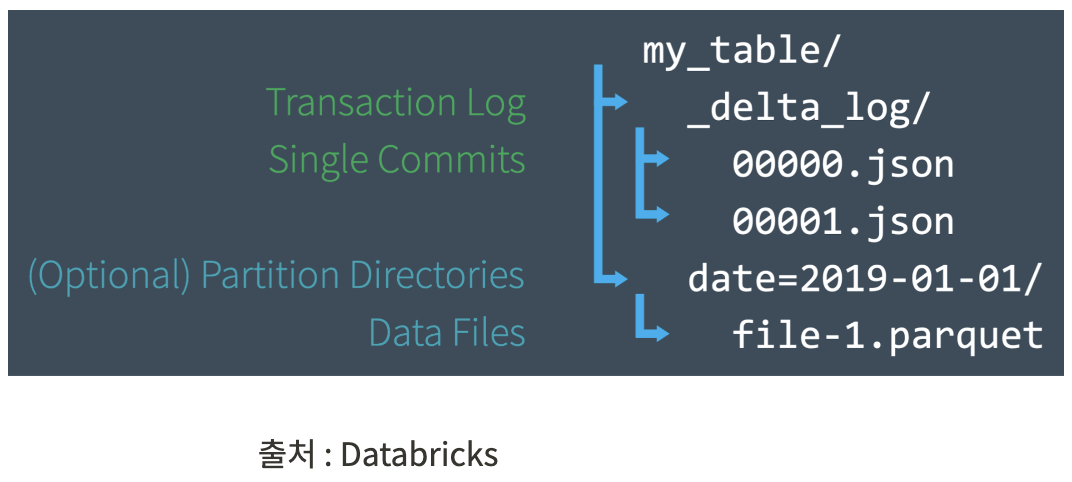
Delta Lake는 모든 연산을 append로 동작한다. 연산마다 매번 새로운 오브젝트를 생성하는 방식으로 데이터가 저장된 경로를 살펴보면, 실제 데이터는 parquet 포맷으로 저장되며 트랜잭션 로그도 함께 저장된다. 데이터에 연산을 수행할 때마다 parquet 파일이 추가되며 트랜잭션 로그도 같이 append가 된다.
ACID
하나의 데이터 저장소에 동시에 여러 작업이 수행될 때 delta lake에서 데이터 일관성을 보장해준다.
예를 들어 사용자 A가 읽기 작업을 하면, 최근 트랜잭션 로그를 확인하여 최신 버전의 파일 블록들을 사용자 A에게 전달한다. 동시에 사용자 B가 쓰기 작업을 하고 있어도 이는 새로운 파일을 append하기 때문에 사용자 A의 읽기에는 영향이 없다. 사용자 B의 쓰기가 모두 완료된 시점에서 새로운 트랜잭션 로그가 추가되고 그 이후에 다른 사용자가 데이터를 조회할 때 새로운 버전의 파일이 제공된다.
만약 사용자 A와 사용자 B가 동시에 같은 파일 블록에 수정 작업을 하면 어떨까? Delta Lake는 먼저 작업이 종료된 작업을 트랜잭션 로그에 추가하며, 수정 작업을 뒤늦게 완료하고 트랜잭션 로그를 추가하려는 순간 기존 버전이 변경된 것을 인식하여 새로운 작업을 실패 처리해 준다. 분산 스토리지 시스템에서 언제나 일관된 데이터를 보장해주기 때문에 신뢰도가 높은 데이터를 유지 할 수 있다.
Spark에서 overwrite를 하는 과정은 아래와 같은 순서대로 수행된다.
- 데이터를 저장소에서 메모리로 읽기
- 데이터 메모리에서 수정
- 데이터를 저장소에서 삭제
- 메모리에서 수정된 데이터를 저장소에 저장
여기서 만약 데이터가 저장소에서 삭제된 순간 오류가 발생하여 작업이 종료된다면, 모든 데이터가 유실되게 된다. 그러나 Delta Lake를 사용하면, 작업이 중간에 종료된다 해도 기존 버전의 데이터가 계속 유지되기 때문에 안정적으로 overwrite를 사용할 수 있다.
Schema enforcement
Delta Lake는 스키마 enforcement 기능도 제공해준다. 데이터 소싱 시 데이터를 전달해주는 주체는 대부분 외부이다. 따라서 오염된 데이터가 입력된다고 해도 데이터 파이프라인 단계의 마지막 단계에서 데이터 정합성 문제가 확인되거나 최악의 경우에는 이러한 오류가 확인되지 못하고 지표에 반영되는 경우도 있을 수 있다.
# type mismatch error
>>> df.write.format("delta").mode("append").save("/tmp/delta-table") # 실패
# type casting
>>> df = df .withColumn("id", col("id").cast("integer"))
>>> df.write.format("delta").mode("append").save("/tmp/delta-table") # 성공Delta Lake에서 schema enforcement를 사용하면 기존과 다른 스키마의 데이터가 append 되는 순간 에러를 발생시키기 때문에 데이터 유입 초기 단계에서 데이터 구조 변화를 확인할 수 있고 빠른 대응이 가능해진다.
Time travel
데이터가 바뀔 때마다 버저닝을 하는 특징을 활용해서, 데이터를 예전 버전으로 되돌릴 수 있다. 데이터를 잘못 처리하거나 실수로 데이터를 지웠어도 간단하게 아래와 같이 예전 데이터를 불러올 수 있다.
df = spark.read.format("delta").option("timestampAsOf", "2022-03-07 09:08:45.333").load("/tmp/delta-table")데이터를 날짜별로 Dataframe에 불러와서 통계 분석 하는 방식으로 time travel을 활용할 수도 있다.
데이터 버전의 보존 기간은 직접 수동으로 설정할 수 있으며, vacuum 명령어를 사용하여 명시적으로 오래된 버전의 데이터를 영구 삭제해주는 기능도 제공하고 있다.
성능
Delta Lake는 압축, 데이터 스키핑, 캐싱 등을 활용해서 더욱더 빠른 쿼리 성능을 낼 수 있도록 시스템을 발전시키고 있다.
비용
AWS의 RDS는 저장 용량이 클수록 비용이 늘어나며, 시스템의 수평 확장이 어렵기 때문에, 데이터 증가에 따른 쿼리 비용 또한 크게 증가한다. Delta Lake로 전환 시 분산 저장 스토리지인 AWS S3를 사용하였는데, S3는 상대적으로 저장 비용이 저렴하며 네트워크 사용량에 따라 비용을 청구한다. 따라서 사용자 쿼리 레이어에는 시계열 쿼리에 최적화된 쿼리 엔진에 최종 집계된 데이터를 적재하여 이를 대시보드에 연결하는 방식으로 비용을 절감할 수 있다.
Delta VS Parquet
Delta Format과 Parquet Format의 차이는 무엇일까? Parquet는 많은 장점이 있지만 아래와 같은 단점이 있다.
-
데이터 처리가 중간에 멈춘 경우 데이터의 일관성을 보장할 수 없다(참고 ACID).
-
스트리밍 데이터 처리에 부적합하다. 스트리밍 워크로드의 경우 읽기 보다는 쓰기 성능이 중요한데, Parquet 포맷의 경우 읽기 성능이 최적화된 포맷이다.
참고자료
