Optimize
작은 파일들은 쿼리 읽기 속도를 늦추기 때문에 문제가 될 수 있으며 많은 작은 파일을 나열하고, 열고, 닫으면 비용이 많이 드는 오버헤드가 발생한다. 이를 Small File Problem 이라고 하며 데이터를 더 크고 효율적인 파일에 결합하면 이 오버헤드를 줄일 수 있다.
아래 코드는 200만 개의 행이 있는 Delta 테이블에 대한 쿼리를 실행한다. education Column에 따라 Partition 되어 있으며 Partition당 1440개의 파일이 있다.
%%time
df = spark.read.format("delta").load("test/delta_table_1440")
res = df.where(df.education == "10th").collect()
CPU times: user 175 ms, sys: 20.1 ms, total: 195 ms
Wall time: 16.1 s그리고 2백만 행의 데이터를 가지고, 각 파티션에 대해 단 하나의 최적화된 파일로 저장된 Delta 테이블에서 동일한 쿼리를 실행해보면
%%time
df = spark.read.format("delta").load("test/delta_table_1")
res = df.where(df.education == "10th").collect()
CPU times: user 156 ms, sys: 16 ms, total: 172 ms
Wall time: 4.62 s이 쿼리가 훨씬 빠르게 실행되는 것을 볼 수 있다.
small file 발생 이유
- 사용자 오류: 사용자가 데이터 세트를 다시 분할하고 여러 개의 작은 파일로 데이터를 쓸 수 있다.
- 불변 파일 작업: Parquet과 같은 불변 파일 형식은 덮어쓸 수 없다. 즉, 이러한 Data Set을 업데이트하면 새 파일이 생성되어 작은 파일 문제가 발생할 수 있다.
- 파티셔닝: 높은 카디널리티 열에 테이블을 파티셔닝하면 많은 작은 파일로 구성된 디스크 파티션이 생성될 수 있다.
- 빈번한 증분 업데이트: 빈번한 증분 업데이트가 있는 테이블은 많은 작은 파일을 가질 가능성이 높다. 2분마다 업데이트되는 테이블은 한 주당 5040개의 파일들을 생성한다.
Delta Lake Optimize
- Manual Optimize
매일 일부 데이터를 수집하는 ETL 파이프라인이 있다고 가정하고 매일 작업이 끝나면 파티션당 1,440개의 파일이 생성된다고 했을때
> # get n files per partition
> !ls test/delta_table/education\=10th/*.parquet | wc -l
1440위에서 보았듯이, 많은 작은 파일이 있는 Delta 테이블에 대해 쿼리를 실행하는 것은 효율적이지않다.
이 Delta Table을 Delta OPTIMIZE 명령을 수동으로 실행하여 파일 수를 최적화할 수 있다.
이 작업 후 각 파티션에 기록되는 기본 파일 크기는 1GB이다.
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "test/delta_table")
deltaTable.optimize().executeCompaction()- Optimized Write ( Delta 3.1.0 부터 사용가능 )
Optimized Write은 실행하기 전에 동일한 파티션에 대한 모든 작은 쓰기를 단일 쓰기 명령으로 결합한다.
이는 여러 프로세스가 동일한 분할된 델타 테이블에 쓸 때, 즉 분산 쓰기 작업일 때 매우 유용하다.
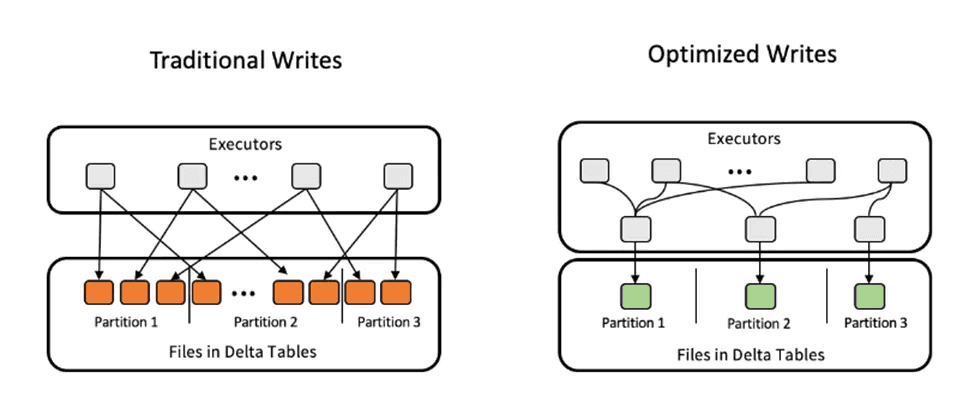
Optimized Write는 파일을 테이블에 쓰기 전에 데이터 셔플을 사용하여 데이터를 재조정한다.
이렇게 하면 작은 파일의 수가 줄어든다.
Delta Table을 write할때 optimizeWrite 옵션을 설정하면 활성화 할 수 있다.
df.write.format("delta").option("optimizeWrite", "True").save("path/to/delta")만약 Delta Table 전체에 대해 Optimized Write를 활성화 하고 싶다면 delta.autoOptimize.optimizeWrite 속성을 설정하면 되며 Spark SQL에서도 spark.databricks.delta.optimizeWrite.enabled를 설정하면 Optimized Write를 활성화 할 수 있다. 하지만 SQL에서는 데이터가 쓰여지기 전에 수행되는 데이터 셔플 때문에 실행하는 데 약간 더 오래걸려 이 기능이 기본적으로 활성화되지 않는다.
import pyspark
from delta import *
builder = pyspark.sql.SparkSession.builder.master("local[4]").appName("parallel") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()df = spark.read.csv("data/census_2M.csv", header=True)여러개의 작은 파일이 있는 상황을 시뮬레이션 하기 위해 repartitioning
df = df.repartition(1440)이후 Delta Table에 데이터를 education을 기준으로 병렬로 write
df.write.format("delta").partitionBy("education").save("delta/census_table_many/")partition당 디스크에 1440개의 파일이 있는 것을 확인
> # get n files per partition
> !ls delta/census_table_many/education\=10th/*.parquet | wc -l
1440여러 개의 작은 파일이 있는 이 Delta 테이블에 대한 쿼리 실행
> df_small = spark.read.format("delta").load("delta/census_table_many")
> %%time
> df_10th = df_small.where(df_small.education == "10th").collect()
CPU times: user 175 ms, sys: 20.1 ms, total: 195 ms
Wall time: 16.1 s이제 최적화된 쓰기를 사용하여 동일한 데이터를 써보면 write 작업 전에 데이터 셔플을 실행하여 작은 파일 문제를 피할 수 있다.
df.write.format("delta").partitionBy("education").option("optimizeWrite", "True").save("delta/census_table_optimized/")모든 데이터가 Partition당 1개의 파일로 결합되어있는 것을 확인
> # get n files per partition
> !ls delta/census_table_optimized/education\=10th/*.parquet | wc -l
1최적화된 Delta Table에 대한 쿼리 실행 결과 성능이 4.5배 향상된 것을 확인
> df_opt = spark.read.format("delta").load("delta/census_table_optimized")
> %%time
> df_10th = df_opt.where(df_opt.education == "10th").collect()
CPU times: user 146 ms, sys: 30.3 ms, total: 177 ms
Wall time: 3.66 s- Auto Compaction ( Delta 3.1.0 부터 사용가능 )
Optimized Write으로도 Small File Problem을 해결하기에 충분하지 않을때가 있다.
예를 들어, table에 자주 작은 업데이트를 write할때 파일은 Optimized Write 후에도 여전히 작은 파일로 남아있게된다.
Auto Compaction은 특정 임계값 크기 미만의 파일 데이터는 자동으로 더 큰 파일로 결합하여 다운스트림 쿼리는 더 최적의 파일 크기의 이점을 얻을 수 있게 한다.
Delta 테이블(delta.autoOptimize.autoCompact)이나 전체 Spark 세션(spark.databricks.delta.autoCompact.enabled)에 대해 자동 압축을 활성화할 수 있으며 최소한 특정 수의 작은 파일이 있는 파티션이나 테이블에 대해서만 하는 자동 압축을 트리거하는 데 필요한 최소 파일 수는 (spark.databricks.delta.autoCompact.minNumFiles.)을 사용하여 구성할 수 있다.
간단한 예시를 위해 위에서 사용한 동일한 200만 행 데이터 세트로 시작하여 매분 쓰기가 수행되는 상황을 시뮬레이션하기 위해 다시 Partition한다.
df = spark.read.csv("data/census_2M.csv", header=True)
df = df.repartition(1440)Auto Compaction 활성화
spark.sql("SET spark.databricks.delta.autoCompact.enabled=true")Delta Table write
df.write.format("delta").partitionBy("education").save("delta/census_table_compact/")쿼리 수행을 해보면 최적화 후에 성능이 향상되는 것을 확인할 수 있다.
df_comp = spark.read.format("delta").load("delta/census_table_compact")
%%time
df_10th = df_comp.where(df_comp.education == "10th").collect()
CPU times: user 205 ms, sys: 39.2 ms, total: 244 ms
Wall time: 4.69 s- Optimized Write vs Auto Compaction
Optimized Write는 동일한 파티션에 대한 여러 작은 쓰기를 하나의 더 큰 쓰기 작업으로 결합 다. 이는 데이터가 Delta 테이블에 쓰여지기 전에 수행되는 최적화이다.
Auto Compaction은 많은 작은 파일을 더 크고 효율적인 파일로 결합한다. 이는 데이터가 Delta 테이블에 기록된 후 수행되는 최적화이다. 이 후 나머지 작은 파일을 정리하기 위해 그 후에 VACUUM 작업을 수행을 권장 한다.
- Delta Lake Optimize maxFileSize
spark.databricks.delta.optimize.maxFileSize 옵션을 사용하여 최대 파일크기를 조정할 수 있다. 기본 옵션은 1GB이며 굳이 이걸 벗어날 필요는 없다.
- Delta Lake Optimize: Tradeoffs
낮은 쓰기 지연 시간이 필요한 경우 Delta Lake 최적화는 적합하지 않을 수 있으며 더 빠른 읽기 성능으로부터 이익을 얻을 수 있는 다운스트림 쿼리가 많은 경우 최적화를 실행하는 것이 일반적으로 합리적이다.
참고 자료
