Vacuum
Delta Lake는 논리적으로 파일을 삭제하는 작업을 위해 저장소에서 파일을 물리적으로 제거하지 않으며 삭제로 표시되었고 보존 기간보다 오래된 파일을 저장소에서 물리적으로 제거하려면 vacuum 명령을 사용해야 한다.
Delta Table 생성
df = spark.createDataFrame([("bob", 3), ("sue", 5)]).toDF("first_name", "age")
df.repartition(1).write.format("delta").saveAsTable("some_people")데이터 추가
df = spark.createDataFrame([("ingrid", 58), ("luisa", 87)]).toDF("first_name", "age")
df.repartition(1).write.format("delta").mode("append").saveAsTable("some_people")현재 Delta Table 내용
spark.table("some_people").show()
+----------+---+
|first_name|age|
+----------+---+
| ingrid| 58|
| luisa| 87|
| bob| 3|
| sue| 5|
+----------+---+Delta Table은 현재 두 개의 Parquet 파일로 구성되어 있으며, 둘 다 Delta Table의 최신 버전을 읽을 때 사용된다. 두 Parquet 파일 모두 Delta 트랜잭션 로그에서 제거하도록 표시되지 않았으므로(일명 "tombstoned"), vacuum으로 제거되지 않는다. Tombstoned 파일은 트랜잭션 로그에서 제거하도록 표시되며 Vacuum 명령은 tombstoned된 파일만 저장소에서 삭제한다.
some_people
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
├── part-00000-0e9cf175-b53d-4a1f-b132-8f71eacee991-c000.snappy.parquet
└── part-00000-9ced4666-4b26-4516-95d0-6e27bc2448e7-c000.snappy.parquet기존 델타 테이블을 새로운 데이터로 Overwrite하면 트랜잭션 로그에서 제거할 모든 기존 데이터를 표시한다. (모든 기존 파일을 삭제 표시)
df = spark.createDataFrame([("jordana", 26), ("fred", 25)]).toDF("first_name", "age")
df.repartition(1).write.format("delta").mode("overwrite").saveAsTable("some_people")Overwrite 후 Delta Talbe의 내용은 다음과 같으며
spark.table("some_people").show()
+----------+---+
|first_name|age|
+----------+---+
| jordana| 26|
| fred| 25|
+----------+---+이미지에서 볼 수 있듯이 Overwrite 작업으로 새 파일이 추가되고 기존 파일은 삭제 마크가 되어있는 것을 볼 수있으며
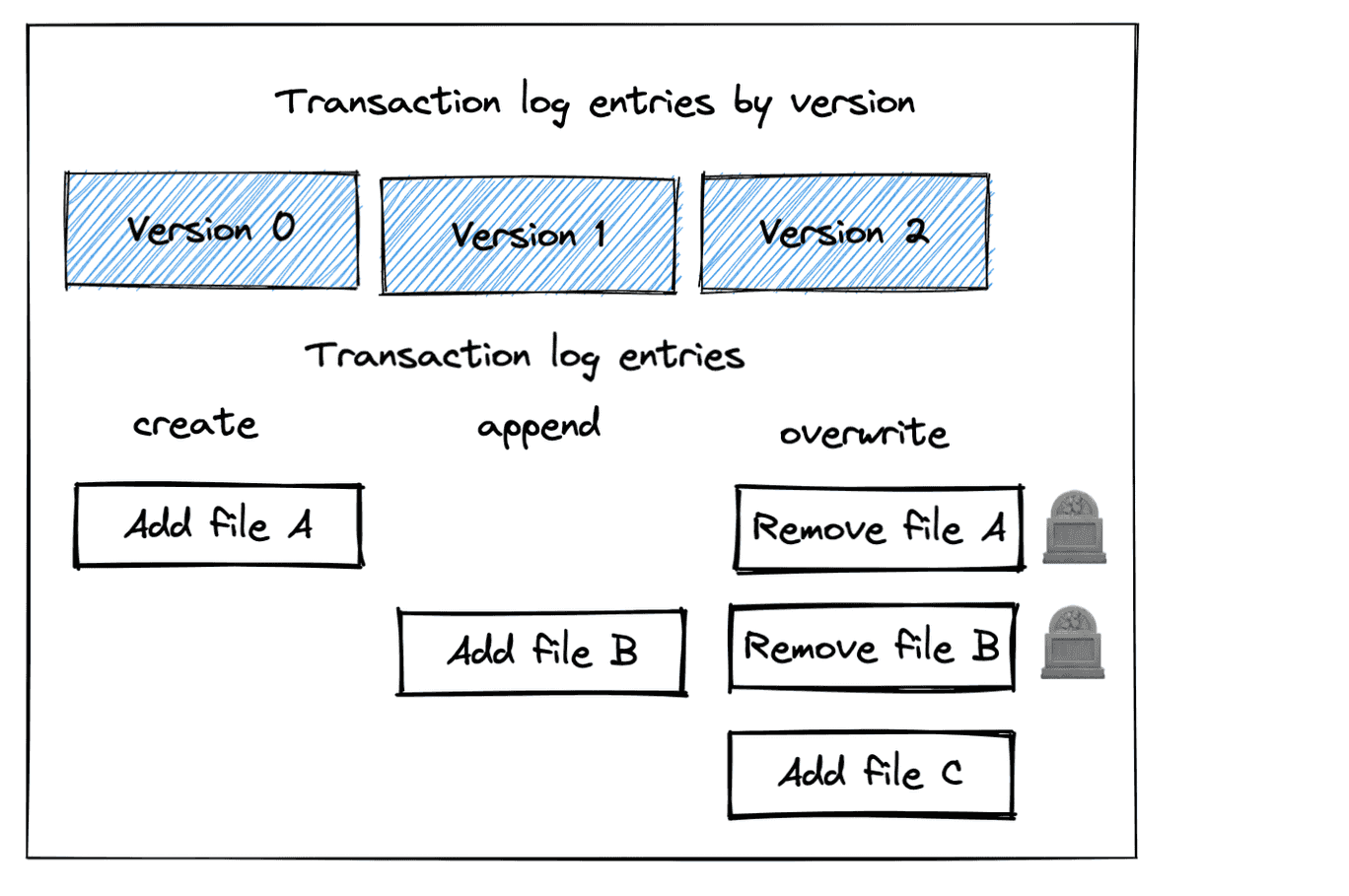
세 개의 파일이 모두 아직 저장되어 있는 것을 볼 수 있다.
spark-warehouse/some_people
├── _delta_log
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ └── 00000000000000000002.json
├── part-00000-0e9cf175-b53d-4a1f-b132-8f71eacee991-c000.snappy.parquet
├── part-00000-1009797a-564f-4b0c-8035-c45354018f21-c000.snappy.parquet
└── part-00000-9ced4666-4b26-4516-95d0-6e27bc2448e7-c000.snappy.parquetvacuum command 에서 DRY RUN 모드로 제거될 파일 목록을 조회 해보면
spark.sql("VACUUM some_people DRY RUN")Found 0 files and directories in a total of 1 directories that are safe to delete.(총 1개의 디렉토리에서 삭제해도 안전한 0개의 파일과 디렉토리를 찾았습니다.) 라는 message를 return 한다. 이 이유는 기본적인 파일 보존 기간이 7일 이므로 기간이 지난 파일이 없기 때문이다.
따라서 만약 보존 기간을 0시간으로 설정하고 제거될 파일 목록을 조회 해보면
spark.sql("VACUUM some_people RETAIN 0 HOURS DRY RUN")IllegalArgumentException: requirement failed: Are you sure you would like to vacuum files with such a low retention period?(IllegalArgumentException: 요구 사항 실패: 보존 기간이 이렇게 짧은 파일을 정말 청소하시겠습니까?) 라는 message를 return 한다. 왠만해서 데모가 아니라면 보관 기간을 0으로 설정하면 안된다.
만약 vacuum 설정을 하려는 테이블이 insert/upsert/delete/optimize와 같은 작업이 수행되지 않는다고 확신하는 경우 spark.databricks.delta.retentionDurationCheck.enabled = false 설정을 하여 이 검사를 끌 수 있다. 확실하지 않는 경우 기본 값인 "168시간" 이상의 값을 사용하는 것을 권장한다.
보존 기간을 0으로 설정할 수 있도록 구성을 업데이트하는 방법은 다음과 같다.
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")이제 구성이 업데이트되었으므로 보관 기간을 0시간으로 설정하여 진공 작업을 실행할 수 있다.
spark.sql("VACUUM some_people RETAIN 0 HOURS").show(truncate=False)위 쿼리를 실행하면 저장소에서 제거된 파일을 보여주는 DF를 반환한다.
.../part-00000-0e9cf175-b53d-4a1f-b132-8f71eacee991-c000.snappy.parquet
...//part-00000-9ced4666-4b26-4516-95d0-6e27bc2448e7-c000.snappy.parquet저장소에서 제거되었는지 확인
spark-warehouse/some_people
├── _delta_log
│ ├── 00000000000000000000.json
│ ├── 00000000000000000001.json
│ └── 00000000000000000002.json
└── part-00000-1009797a-564f-4b0c-8035-c45354018f21-c000.snappy.parquet- Vacuum은 Time Travel을 제한한다.
Vacuum은 최신 Delta 테이블 버전에서 사용하는 파일을 제거하지 않지만, 이전 버전의 Delta 테이블에서 사용하는 삭제된 파일은 제거한다.
만약 Vacuum 후 Delta Table 버전 1을 읽으려고 한다면
spark.sql("SELECT * FROM some_people VERSION AS OF 1").show()다음과 같은 오류 메시지가 나타난다.
ERROR Executor: Exception in task 0.0 in stage 237.0 (TID 113646)
java.io.FileNotFoundException:
File: .../some_people/part-00000-0e9cf175-b53d-4a1f-b132-8f71eacee991-c000.snappy.parquet does not exist
It is possible the underlying files have been updated. You can explicitly invalidate the cache in Spark by running 'REFRESH TABLE tableName' command in SQL or by recreating the Dataset/DataFrame involved.이 에러가 발생한 이유는 Vacuum으로 버전 1의 Parquet 파일이 물리적으로 제거되었기 때문이다.
- Vacuum은 성능 최적화가 아니다
Delta Lake 사용자는 Delta Table을 Vacuum 하면 query가 더 빨리 실행될 것이라고 잘못 생각할 수 있지만 잘못된 생각이다.
Delta Table을 query할 때 query engine은 먼저 트랜잭션 로그를 구문 분석하여 읽어야 할 파일을 결정한 다음 query에 필요한 관련 파일을 CherryPick 한다.
query SELECT * FROM some_people VERSION AS OF 2예로 들어 보자.
이 query는 트랜잭션 로그를 구문 분석하고 버전 2의 모든 데이터를 얻기 위해 어떤 파일을 읽어야 하는지 파악한다. 그런 다음 query engine은 쿼리를 실행하는 데 필요한 파일을 읽는다.
Delta Lake는 필요한 파일만 읽는다. 저장소에 삭제된 파일이 있어도 쿼리 성능에 영향을 미치지 않는다. 삭제된 파일은 단순히 무시된다.
이것이 Delta Table을 Vacuum 성능이 향상되지 않는 이유이다. Vacuum은 보관 비용을 절약하는 데 도움이 될 뿐이다.
참고 자료
