1. 전체적인 구조
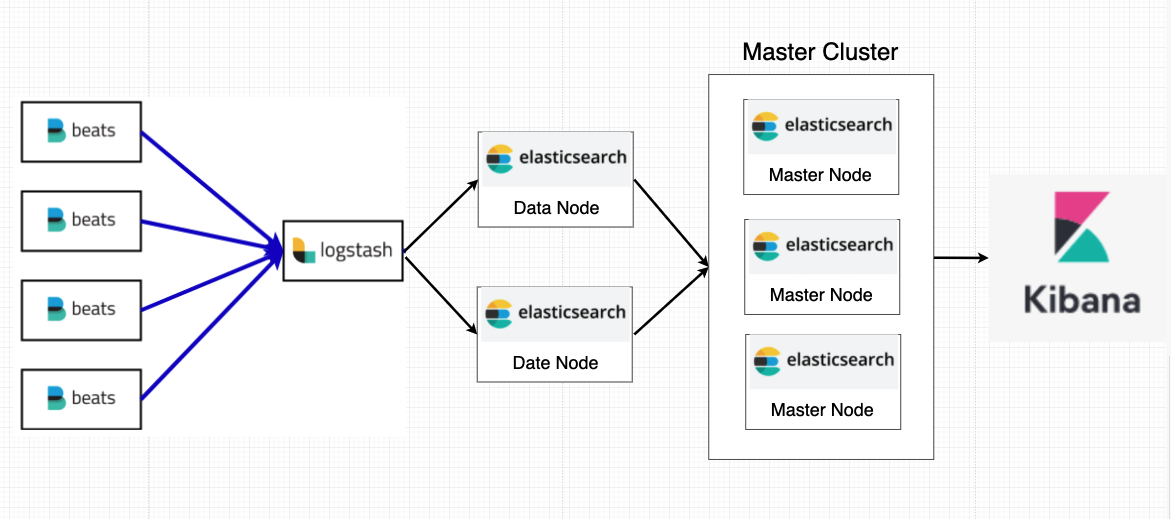
전체적인 구조는 위와 같고 각각의 IP와 환경은 다음과 같다.
Server 구성
- CentOS7 환경
- filebeat 1대
- logstash 1대
- Elasticsearch data node 2대
- Elasticsearch master node 3대
- Kibana 1대
- Master node IP
- 10.0.7.164
- 10.0.7.120
- 10.0.7.77
- Data node
- 10.0.7.152
- 10.0.7.49
- Kibana
- 10.0.7.62
- Logstash
- 10.0.7.158
2. Java 설치
- 제 포스트의 CentOS 7에 OpenJDK 1.8 설치 를 참고
3. Filebeat 설치
✅ 3-1. rpm으로 설치
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch✅ 3-2. install
$ yum install filebeat✅ 3-3. filebeat.yml 수정
$ vi /etc/filebeat/filebeat.yml- enable: false를 true로 수정
enable: true- logstash를 이용해 elasticsearch로 보내고 싶을 때
- output.elasticsearch 부분을 주석
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]- output.logstash 부분 주석 제거
output.logstash:
# The Logstash hosts
hosts: ["Logstash IP(10.0.7.158):5044"]✅ 3-4. system 활성화 및 modules 리스트 확인
$ filebeat modules enable system
$ filebeat modules list4. Logstash 설치
대상 서버
- Logstash
- 10.0.7.158
✅ 4-1. rpm으로 설치
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch✅ 4-2. logstash.repo 수정
# cat >> /etc/yum.repos.d/logstash.repo <<EOF
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF✅ 4-3. install
$ yum install logstash✅ 4-4. filebeat && elasticsearch 연결 설정
$ cd /etc/logstash의 config폴더에 demo-metrics-pipeline.conf를 생성- demo-metrics-pipeline.conf 수정
$ cat > /etc/logstash/config/demo-metrics-pipeline.conf <<EOF
input {
beats {
port => 5044
type => "spring"
}
}
filter {
if [type] == "spring" {
dissect {
mapping => {"message" => "[%{timestamp}][%{level}][%{method}] - %{message}"}
}
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss" ]
target => "@timestamp"
timezone => "Asia/Seoul"
locale => "ko"
}
}
}
output {
if [type] == "spring" {
elasticsearch {
# hosts에 배열이 주어지면 hosts매개변수에 지정된 호스트 간에 요청을 로드 밸런싱한다.
hosts => [ "elasticsearch-data-node-1-ip(10.0.7.152):9200","elasticsearch-data-node-2-ip(10.0.7.49):9200" ]
index => "spring-%{+YYYY.MM.dd}"
}
}
}
EOFInput: Beats Input Plugin
수집 대상: Spring 로그
수집 방식: Beats 프로토콜을 사용하는 포트 5044
로그 유형: "spring"
Filter: Dissect & Date Filter Plugin
로그 유형: "spring"
분석 대상: "message" 필드
분석 방식: "[%{timestamp}][%{level}][%{method}] - %{message}" 형식의 로그 메시지를 분해하여 추출
날짜/시간 추출: "timestamp" 필드에서 "yyyy-MM-dd HH:mm:ss" 형식의 날짜/시간 정보 추출하여 "@timestamp" 필드에 저장
Output: Elasticsearch Output Plugin
로그 유형: "spring"
저장 대상: Elasticsearch 클러스터의 "spring-YYYY.MM.dd" 인덱스
Elasticsearch 클러스터: "elasticsearch-data-node-1-ip"와 "elasticsearch-data-node-2-ip" 노드
Elasticsearch 호스트 포트: 9200✅ 4-5. logstash 재실행
$ systemctl restart logstash => 오류 발생

위와 같은 오류가 발생했을때 아래 방법을 따라하면 됨 (참고)
4-5-1. logstash service status를 확인
Unit logstash.service could not be found. 이런 메시지가 뜰 것이다.
4-5-2. 아래 커멘드 입력
/usr/share/logstash/bin/system-install /etc/logstash/startup.options systemd
4-5-3. logstash status 확인
service logstash status
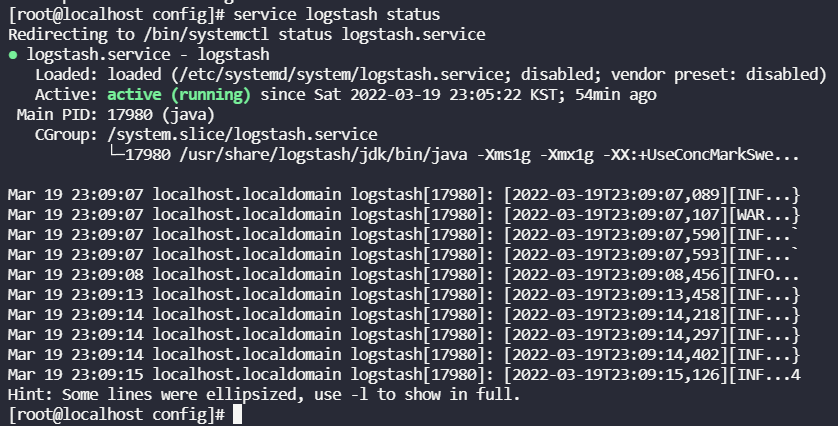
5. Elasticsearch 설치
대상 서버
- Master Node
- 10.0.7.164
- 10.0.7.120
- 10.0.7.77
- Data Node
- 10.0.7.152
- 10.0.7.49
✅ 5-1. rpm으로 설치
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch✅ 5-2. elasticsearch.repo 수정
$ cat >> /etc/yum.repos.d/elasticsearch.repo <<EOF
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md
EOF✅ 5-3. install
$ yum install --enablerepo=elasticsearch elasticsearch✅ 5-4. Elasticsearch Data Node 의 elasticsearch 설정
대상 서버
- Data Node
- 10.0.7.152
- 10.0.7.49
5-4-1. elasticsearch.yml 수정
$ vi /etc/elasticsearch/elasticsearch.yml
cluster.name: gjgs
node.master: false
node.data: true
node.ingest: false
node.ml: false
node.name: data-1
bootstrap.memory_lock: true
network.host: [_site_]
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["10.0.7.164", "10.0.7.120","10.0.7.77"]
cluster.initial_master_nodes: ["10.0.7.164", "10.0.7.120","10.0.7.77"]- cluster.name : 클러스터 이름을 지정합니다. 같은 클러스터로 묶기 위해서는 반드시 같은 클러스터명을 사용해야 하며, 다른 클러스터와의 간섭을 방지하기 위해 고유 명칭을 지정해줍니다.
- node.master : 마스터 노드 역할 부여 여부
- node.data : 데이터 노드 역할 부여 여부
- node.name : 노드의 이름을 지정합니다. 단일 클러스터 안에서 반드시 노드마다 다른 명칭이 부여되야 합니다.
- bootstrap.memory_lock : 노드 실행 시 시스템의 물리 메모리를 미리 할당받아 스왑 영역을 사용하지 않도록 방어하는 설정입니다. 메모리 부족으로 인해 디스크의 스왑 영역을 참조할 경우 심각한 성능 저하가 발생할 수 있기 때문에 필수적으로 설정해줘야 합니다.
- network.host : 노드가 배포될 네트워크 호스트를 지정합니다. 일반적인 IPv4, IPv6 주소 외에도 local, site, global 값을 이용해 각각 로컬, 내부, 외부 네트워크를 자동으로 지정할 수 있습니다.
- http.port : http 통신에 사용할 포트를 지정합니다.
- discovery.seed_hosts : 클러스터 구성을 위해서는 다른 노드를 발견해야 합니다. seed_hosts는 이때 사용되는 상대 노드 주소들인데, 단지 클러스터 구성을 위한 시드(seed)일 뿐이므로 모든 노드의 주소를 등록할 필요는 없습니다. 어차피 마스터 노드가 없다면 클러스터링이 이뤄지지 않으므로 마스터 후보 노드들만 등록해주어도 충분합니다.
- cluster.initial_master_nodes : 클러스터 최초 구성시에만 사용되는 설정으로, 여기 명시된 초기 마스터 후보 노드들이 클러스터를 이루면 이후 노드가 추가/이탈됨에 따라 내부적으로 마스터 후보 노드 정보를 관리하게 됩니다.
yml에 없는 설정들은 그냥 빈곳에 추가로 작성하면 됩니다.
5-4-2. es 재시작 및 설치 확인
# systemctl restart elasticsearch
# curl http://127.0.0.1:9200아래와 같이 나오면 제대로 설치 된 것
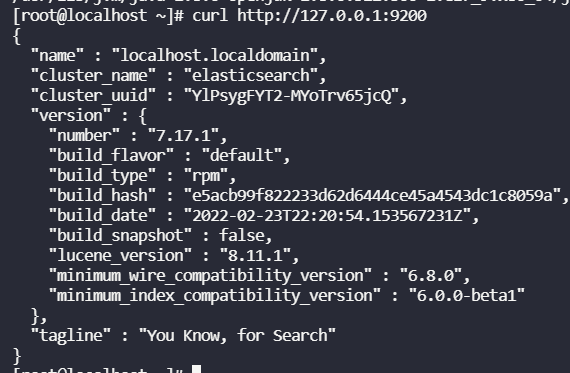
✅ 5-5. Elasticsearch Name Node 의 elasticsearch 설정
대상 서버
- Master Node
- 10.0.7.164
- 10.0.7.120
- 10.0.7.77
5-5-1. elasticsearch.yml 수정
$ vi /etc/elasticsearch/elasticsearch.yml
cluster.name: gjgs
node.master: true
node.data: false
node.ingest: false
node.ml: false
node.name: master-1
bootstrap.memory_lock: true
network.host: [_site_]
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["10.0.7.164", "10.0.7.120","10.0.7.77"]
cluster.initial_master_nodes: ["10.0.7.164", "10.0.7.120","10.0.7.77"]5-5-2. es 재시작 및 설치 확인
# systemctl restart elasticsearch
# curl http://127.0.0.1:9200아래와 같이 나오면 제대로 설치 된 것
✅ 5-6. 운영 모드 설정
5-6-1 jvm.options
힙 크기
엘라스틱서치를 설치하고 /etc/elasticsearch 위치에 보면 jvm.options 파일이 있다. 자바 가상 머신 관련 설정들이 포함되어 있다. 이 파일에서 눈여겨봐야할 부분은 힙 메모리 관련 설정으로 Xms, Xmx 라는 이름의 설정이다. Xms는 최소 힙 크기이며, Xmx는 최대 힙 크기이다. 힙 메모리 설정은 다음 세 가지 부분을 주의하며 설정한다.
- Xms와 Xmx 수치를 동일하게 할당 - 최소와 최대 힙 크기를 동일하게 할당하지 않으면 힙 메모리 할당량을 확장하는 과정에서 노드가 일시적으로 멈출 수 있다. 기본값은 1기가로 되어 있다.
- 힙 크기는 최대 시스템 물리 메모리의 절반으로 한다. - 엘라스틱서치는 힙 메모리 외에도 빠른 검색과 인덱싱 성능을 위해 파일 시스템 캐시를 적극적으로 활용한다. 이 또한 상당한 메모리를 사용하므로 충분한 여유 메모리를 확보하지 않으면 성능상 문제가 생길 수 있다.
- 힙 크기는 최대 30 ~ 31GB 수준을 넘기지 않는다. - 자바에는 힙 메모리를 빠르고 효율적으로 활용할 수 있도록 Compressed Ordinary Object Pointers 기술이 적용되어 있는데 이는 시스템마다 차이가 있지만 일반적으로 힙 메모리가 최대 32GB를 넘기면 비활성화가 된다. 이 경우 충분히 큰 힙 메모리를 할당했음에도 오히려 성능이 급격히 저하되는 현상을 겪을 수 있다. 예를 들어, 물리 장비당 단일 노드만 실행한다는 가정하에 물리 메모리가 32GB인 장비라면 16GB 힙 크기를 할당하고, 물리 메모리가 64GB인 장비라면 30~31GB수준의 힙 크기를 할당하는 것이 적정하다.
임시 파일과 덤프 파일 경로 설정
$ sudo vi /etc/elasticsearch/jvm.options
## JVM temporary directory
-Djava.io.tmpdir=${ES_TMPDIR}
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/lib/elasticsearch- -Djava.io.tmpdir : 임시 디렉토리 루트를 설정한다. 운영체제에서 기본으로 /tmp 임시 디렉토리의 경우 리눅스에서 주기적으로 정리하며 파일이 소실되어 문제가 발생하는 경우가 있으니 사용하지 않는 편이 좋다. 임시 디렉토리의 경우 리눅스 패키지 매니저를 이용해 설치했을 때는 별도로 설정할 필요가 없지만, 아카이브 파일을 해제하고 설치했을 때는 노드를 실행하는 계정에서 읽기/쓰기가 가능한 디렉토리를 확보해 해당 경로를 입력해주는 것이 좋다.
- -XX:HeapDumpPath : 힙 덤프 파일이 생성되면 저장되는 경로이다. 힙 덤프 파일 경로가 제대로 설정되어 있지 않다면 OutOfMemory 오류가 발생했을 때 원인 분석을 위한 덤프파일을 찾는 데 문제가 발생할 수 있다.
5-6-2 limits.conf
리눅스 시스템 수준에서 걸려있는 제한들을 해제해줄 필요가 있다. 이 파일은 리눅스에만 있는 파일이므로 그 밖의 운영체제에서는 신경쓰지 않아도 된다.
sudo vi /etc/security/limits.conf
ubuntu - nofile 65535
ubuntu - nproc 4096
ubuntu soft memlock unlimited
ubuntu hard memlock unlimitedubuntu는 엘라스틱서치를 실행하는 사용자 계정명이다. 엘라스틱서치를 사용하는 리눅스 계정을 적으면 된다. 설명은 다음과 같다.
- nofile : 최대 파일 디스크립터 수를 의미하며 시스템에서 최대로 열 수 있는 파일 수를 제한합니다. 엘라스틱서치는 샤드 하나당 몇 개씩의 파일들을 열어놓고 사용하며, 인덱스가 늘어남에 비례해 이 숫자가 증가하기 때문에 운영 초기에는 문제가 없다가도 시간이 지남에 따라 샤드가 늘어나 파일 디스크립터 수 제한에 의해 문제가 발생하는 경우가 종종 있기 때문에 최소 65535 이상의 값으로 넉넉하게 잡아준다.
- nproc : 최대 프로세스 수를 제한하는 설정입니다. 검색, 인덱싱, 머지 등 많은 작업들을 실행하다 보면 프로세스가 많이 생성됩니다. 별도의 스레드 풀을 통해 처리하는 엘라스틱서치 특성상 넉넉히 잡아주는 것이 좋다.
- memlock unlimited : 메모리 내 주소 공간의 최대 크기를 지정하는데, 엘라스틱 가이드에 따라 무한대로 잡아준다.
- soft, hard : 프로그램 시작 시 적용하는 기본 한도와 최대 한도이며, -(대시)는 soft와 hard를 동시에 적용한다.
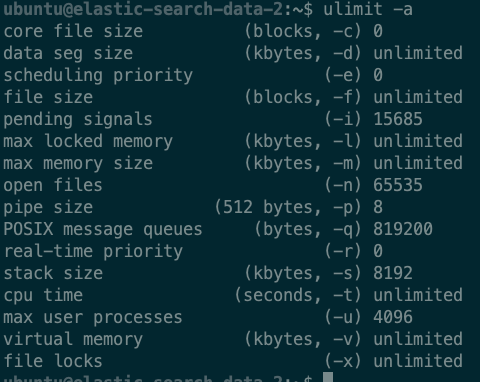
위를 적용하고 reboot를 해준다. 그리고 ulimit -a 명령으로 적용됬는지 확인해본다.
5-6-3 sysctl.conf
sudo vi /etc/sysctl.conf
# 최대 가상 메모리 개수 변경
vm.max_map_count = 262144
# 변경 적용
sudo sysctl -w vm.max_map_count=262144엘라스틱서치는 기본적으로 파일 입출력 성능 향상을 위해 파일을 메모리에 매핑하는 mmap 파일 시스템을 사용하는데, 이는 가상 메모리 공간을 사용하므로 충분한 공간을 확보할 필요가 있다.
5-6-4 Sysconfig file
[1] bootstrap checks failed
[1]: memory locking requested for elasticsearch process but memory is not locked위 에러가 뜨면 이 설정을 하지 않아서 뜨는 에러 이다.
sudo systemctl edit elasticsearch
# 작성 -> ^x -> y -> enter
# service도 작성하는 것입니다.
[Service]
LimitMEMLOCK=infinity
# 적용
sudo systemctl daemon-reload6. Kibana 설치
대상 서버
- Kibana
- 10.0.7.62
✅ 6-1. rpm으로 설치
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch✅ 6-2. kibana.repo 수정
$ cat >> /etc/yum.repos.d/kibana.repo <<EOF
[kibana-7.x]
name=Kibana repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF✅ 6-3. install
$ yum install kibana✅ 6-4. kibana.yml 수정
$ vi /etc/kibana/kibana.yml
# 포트
server.port: 5601
# 서버이름
server.name: "kibana"
# 키바나의 호스트 주소로 0.0.0.0 입력시 자동으로 외부 ip를 바인딩
server.host: "0.0.0.0"
# http 붙여야합니다.
elasticsearch.hosts: ["http://10.0.7.164:9200", "http://10.0.7.120:9200", "http://10.0.7.77:9200"]✅ 6-5. kibana 재시작 및 설치 확인
$ systemctl restart kibana아래와 같이 나오면 제대로 설치 된 것
참고
