Kibana란?
키바나를 사용하는 이유는 시각화를 통해 유저에게 직관적인 데이터의 상태 정보를 제공하기 위함이다.
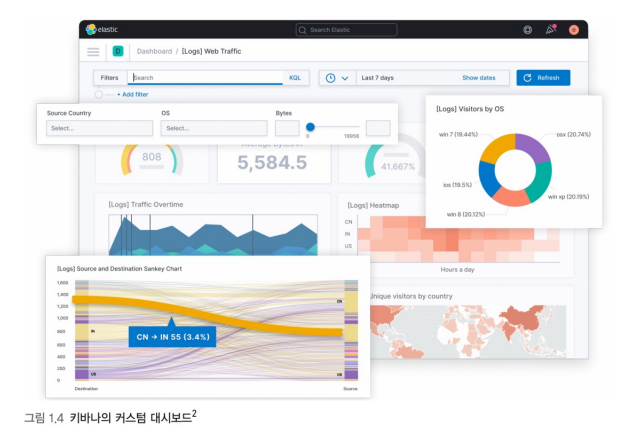
키바나(Kibana)는 브라우저 인터페이스를 이용, 많은 데이터를 쉽게 검색, 시각화, 탐색 할 수 있는 오픈소스 분석 및 시각화 도구다. 또한 키바나는 엘라스틱서치(Elasticsearch), 로그스태시(Logstash), 비츠(Beats)와 함께 엘라스틱스택의 핵심 구성요소다.
✅ 첨언
- Kibana는 Elasticsearch와 함께 작동하도록 설계된 시각화 플랫폼
- Kibana와 Elasitcsearch의 버전은 반드시 동일해야함
- Kibana를 사용하여 Elasticsearch 색인에 저장된 데이터를 검색 및 조회
- 고급 데이터 분석을 쉽게 수행하고 다양한 차트, 엑셀 및 맵(지도)에서 데이터 시각화
- 실시간 Elasticsearch 쿼리의 변경 사항을 표시하는 대시보드 존재
✅ 키바나 메인 페이지 접근
http://localhost:5601/ # 로컬 접근
https://yourdomain.com:5601/ # 도메인 접근- Kibana는 포트 5601을 통해 엑세스하는 웹 응용 프로그램
- Kibana에 액세스하면 기본적으로 검색 페이지 로드
- 시간 필터는 지난 15분으로 설정, 검색 쿼리는 완전 일치로 설정
✅ 키바나를 통해 서버 상태 확인
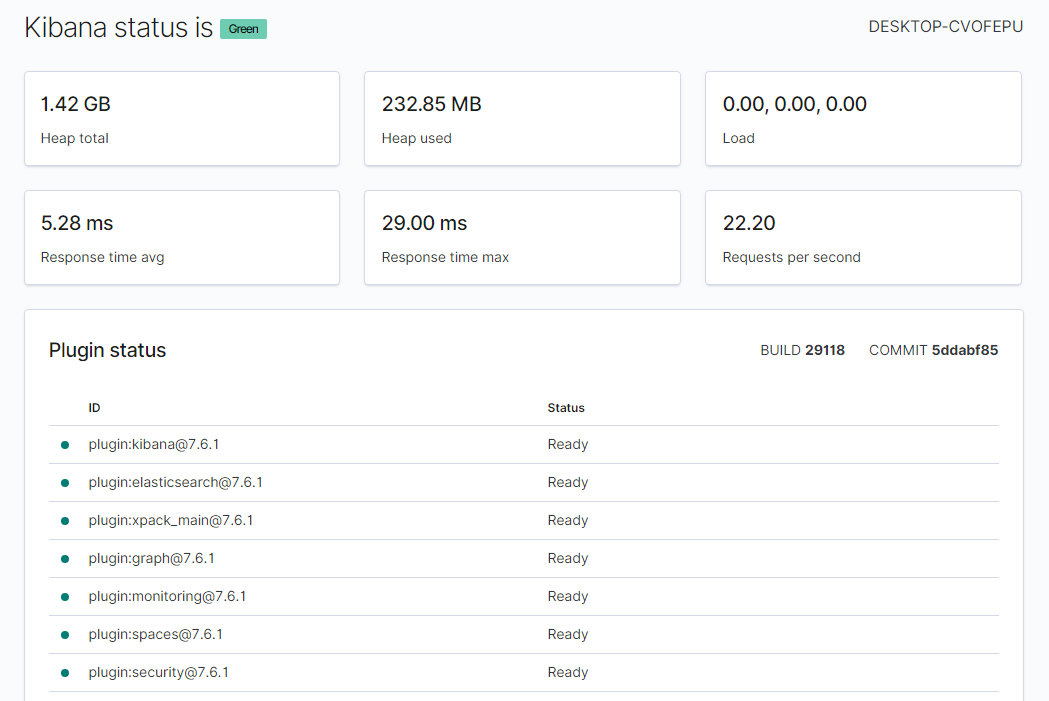
http://localhost:5601/status- 상태 페이지는 서버의 자원 사용에 대한 정보를 표시
- 기본적으로 설치가 되어있는 플러그인 나열
✅ 키바나와 엘라스틱서치 연결
Management > Kibana > Index Patterns
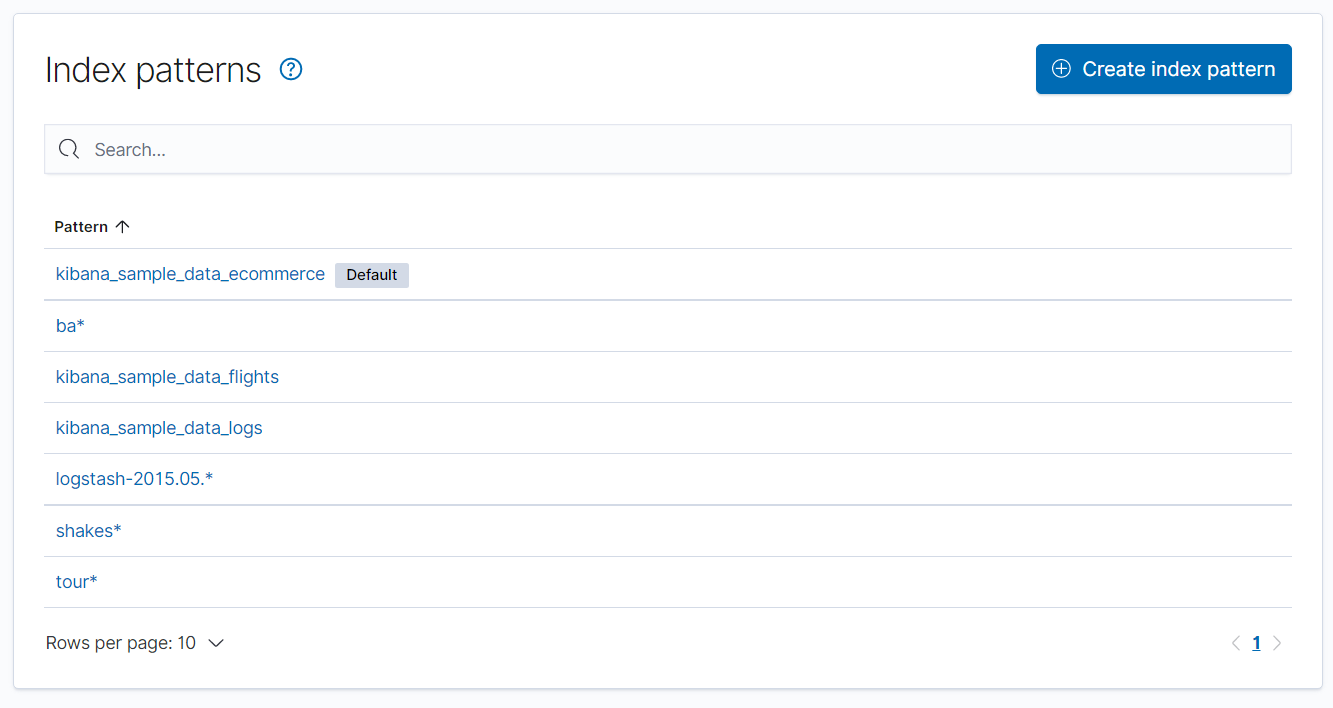
- 기본적으로 Kibana는 localhost에서 실행중인 Elasticsearch 인스턴스에 연결한다.
- 또한, Kibana는 Logstash가 Elasticsearch에 입력하는 데이터가 있다고 추측한다. (logstash-*)
- 설정이 안되있는 경우, 인덱스 중 하나 이상의 이름과 일치하는 색인 패턴을 정의하라는 메시지를 표시한다.
- 관리 탭에서 언제든지 Index Patterns(인덱스 패턴)을 추가해 사용할 수 있다.
Kibana Index PatternsPermalink
✅ Kibana Index Patterns과 와일드카드
Kibana에 등록하는 Index Patterns은 wildcard(*)로 사용할 수 있다. 이유는 한 가지 패턴으로 관리하다 보면 과부하가 발생할 수 있기 때문에 과부하를 피하기 위해 일/월 단위로 나누어 index를 생성한다.
만약 index를 나누어 생성하는데 wildcard로 되어있지 않으면 매번 index pattern을 등록해야 하기 때문에 kibana에서는 편의를 위해 wildcard(*)를 제공한다. 👍
Kibana 튜토리얼 준비하기Permalink
들어가기에 앞서 Kibana를 사용하기 위해서는 Elasticsearch에 대한 연결을 설정했는지 먼저 확인 후 진행해야 한다. 또한 이번 장에서 진행할 Kibana 실습은 아래 사진과 같다.
✔ Elasticsearch에 샘플 데이터 세트 로드
데이터 매핑을 위해 해당 사이트를 참고해주세요 😎
✅ shakespeare.json 데이터Permalink
{
"line_id": INT,
"play_name": "String",
"speech_number": INT,
"line_number": "String",
"speaker": "String",
"text_entry": "String",
}- 윌리엄 셰익스피어의 전체 작품은 적절하게 필드로 파싱
✅ logs.jsonl 데이터Permalink
{
"memory": INT,
"geo.coordinates": "geo_point",
"@timestamp": "date"
}- 임의로 생성 된 로그 파일 세트
✅ accounts.json 데이터Permalink
{
"account_number": INT,
"balance": INT,
"firstname": "String",
"lastname": "String",
"age": INT,
"gender": "M or F",
"address": "String",
"employer": "String",
"email": "String",
"city": "String",
"state": "S
}- 무작위로 생성 된 데이터로 구성된 가상 계좌 집합
데이터를 로드하기 전에는 매핑을 먼저 수행해야 한다.
✔ 매핑?
인덱스의 문서를 논리적 그룹으로 나누고 필드의 검색 가능성, 토큰화되었는지, 별도의 단어로 분리되는지와 같은 필드의 특성을 지정하는것을 의미한다.
✅ shakespeare 데이터 매핑
PUT /shakespeare
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "keyword" },
"play_name" : {"type": "keyword" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}✅ logstash 데이터 매핑
PUT /logstash-2015.05.18
#18~20까지 세개의 인덱스 구성 필요
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {"type": "geo_popint"}
}
}
}
}
}
}위 데이터에서 geo type은 위도, 경도의 데이터 타입을 결정할 때 사용이된다. 만약 위도, 경도의 데이터 로드 하는 경우에 데이터 타입을 geo type으로 지정해주지 않는다면 float형 type이 데이터 타입으로 매핑되는 경우가 발생할 수 있다.
✅ 윈도우용 샘플 데이터 로드
• Invoke-RestMethod "http://localhost:9200/bank/account/_bulk?pretty" -Method Post -ContentType 'application/x-ndjson' -InFile "accounts.json"
• Invoke-RestMethod "http://localhost:9200/shakespeare/doc/_bulk?pretty" -Method Post -
ContentType 'application/x-ndjson' -InFile "shakespeare_6.0.json"
• Invoke-RestMethod "http://localhost:9200/_bulk?pretty" -Method Post -ContentType 'application/xndjson' -InFile "logs.jsonl"데이터의 경우 해당 사이트를 참고 하시면 됩니다. 😎
- 벌크 데이터를 사용하여 Elasticsearch에 데이터 세트를 로드
- power shell을 이용하여 데이터 세트를 밀어 넣으면 된다
참고
