- 이번 포스트에는 제가 사용하고 있는 LogStash를 포함하지 않은 elk를 설치한 방법을 보여드리겠습니다.
- Elastic Search는 초기 Master만 지정해주고 모든 노드를 Master와 Data node의 역할을 수행할 수 있는 구조의 클러스터로 구성하였습니다.
- 여기서 LogStash를 사용하지 않은 이유는 Log가 이미 코드단에서 정제되어있어 FileBeat으로 수집만 하면 되어서 Transform 할 필요가 없어 이런식으로 구성하였습니다.
1. 전체적인 구조
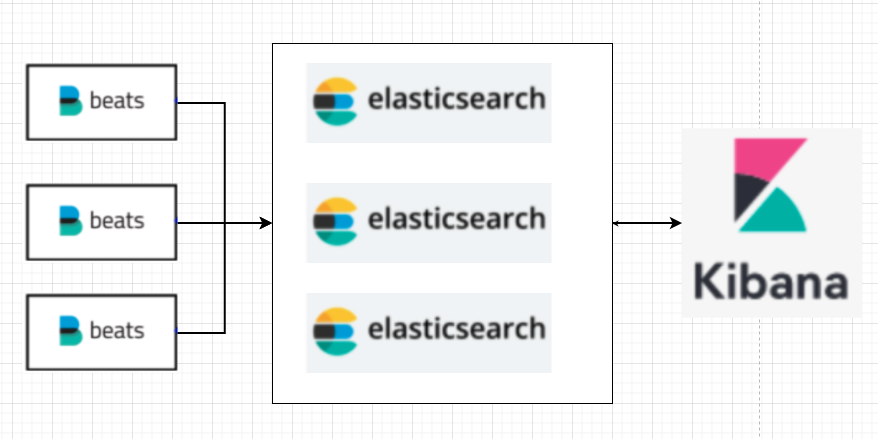
Server 구성
지원되는 버전 확인 : https://www.elastic.co/kr/support/matrix#matrix_os
설치 사이트 : https://www.elastic.co/kr/downloads/past-releases
- 설치된 JDK 버전과 OS를 확인하여 구성할 버전 선택
- 필자는 JDK 1.8과 CenOS7을 사용할 것이라 7.13.13을 선택
- CentOS7 환경
- filebeat 3대
- Elasticsearch node 3대
- Kibana 1대
- FileBeat (7.17.13 v)
- 10.0.8.1
- 10.0.8.2
- 10.0.8.3
- Elastic Search (7.17.13 v)
- 10.0.7.1
- 10.0.7.2
- 10.0.7.3
- Kibana (7.17.13 v)
- 10.0.7.1
2. Java 설치
- 제 포스트의 CentOS 7에 OpenJDK 1.8 설치 를 참고
3. Filebeat 설치
대상 서버
- FileBeat
- 10.0.8.1
- 10.0.8.2
- 10.0.8.3
✅ 3-1. wget으로 설치
$ cd ~
$ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.13-linux-x86_64.tar.gz✅ 3-2. tar 압축 해제
$ tar -xvzf filebeat-7.17.13-linux-x86_64.tar.gz✅ 3-3. filebeat.yml 수정
filebeat.config.inputs:
enabled: true
path: ${path.config}/inputs.d/*.yml
reload.enabled: true
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: true
setup.template.enabled: true
setup.template.name: "template name 적기"
setup.template.pattern: "pattern 적기"
setup.template.overwrite: true
setup.ilm.enabled: false
setup.kibana:
host: "10.0.7.1:8000"
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["10.0.7.1:9200", "10.0.7.2:9200", "10.0.7.3:9200"]
index: "name-app-%{+yyyy.MM.dd}"filebeat.config.inputs: Filebeat의 입력 설정을 정의합니다. path 속성은 inputs.d 디렉토리 안에 있는 모든 .yml 파일을 읽도록 설정합니다. reload.enabled 속성은 입력 설정이 변경될 때마다 Filebeat가 자동으로 재시작하여 설정을 적용하도록 설정합니다.filebeat.config.modules: Filebeat의 모듈 설정을 정의합니다. path 속성은 modules.d 디렉토리 안에 있는 모든 .yml 파일을 읽도록 설정합니다. reload.enabled 속성은 모듈 설정이 변경될 때마다 Filebeat가 자동으로 재시작하여 설정을 적용하도록 설정합니다.setup.template.enabled: Elasticsearch 인덱스 템플릿 설정을 사용할 것인지 여부를 설정합니다. 이 속성을 true로 설정하면 아래 setup.template.name과 setup.template.pattern 속성에 지정된 값을 사용하여 인덱스 템플릿을 생성합니다.setup.template.name: 생성할 인덱스 템플릿의 이름을 설정합니다.setup.template.pattern: 생성할 인덱스 템플릿의 이름 패턴을 설정합니다.setup.template.overwrite: 기본 default로 정의된 엘라스틱서치 기본 인덱스 템플릿을 불러오기때문에 true로 설정해 내가 정의한 템플릿을 사용한다.setup.ilm.enabled: 7.17 버전 특성상 false 안해주면 인덱스네임이 filebeat로 고정 됩니다.setup.kibana: Filebeat가 Kibana와 어떻게 통신할 것인지를 구성합니다. 이 설정은 주로 Filebeat가 Kibana에 대시보드, 비주얼라이제이션, 인덱스 패턴 등을 자동으로 로드할 때 사용됩니다.output.elasticsearch: Filebeat가 수집한 로그를 Elasticsearch에 전송하는 설정을 정의합니다. hosts 속성은 Elasticsearch 노드의 호스트 정보를 지정합니다. index 속성은 Filebeat가 생성하는 인덱스의 이름을 설정합니다. %{+yyyy.MM.dd}는 현재 날짜를 기반으로 인덱스 이름을 생성하는데, yyyy는 연도, MM은 월, dd는 일을 나타냅니다. 따라서 생성되는 인덱스의 이름은 name-app-연도.월.일 형식이 됩니다.
✅ 3-4. inputs.d 생성
$ mkdir ~/filebeat-7.17.13-linux-x86_64/input.d
$ cd ~/filebeat-7.17.13-linux-x86_64/input.d
$ sudo vim filebeat.yml- type: log
tail_files: true
paths:
- Log Path 경로
json.keys_under_root: true
json.ignore_decoding_error: true✅ 3-5. filebeat 초기 설정 등록
$ ~/filebeat-7.17.13-linux-x86_64/filebeat setupfilebeat setup 명령어는 Filebeat의 초기 설정을 담당합니다. 이 명령어를 실행하면 다음과 같은 여러 작업이 수행될 수 있습니다.
-
Elasticsearch의 Index Template 설치: Filebeat는 Elasticsearch에 적절한 매핑과 설정을 가진 인덱스 템플릿을 설치합니다. 이 템플릿은 Filebeat가 Elasticsearch에 데이터를 색인할 때 적절한 필드 타입과 설정을 적용하기 위해 사용됩니다.
-
Kibana Dashboards 설치: Filebeat는 자체 모듈에 대한 대시보드와 시각화를 Kibana에 로드합니다. 이 기능은 Kibana가 실행 중이고 접근 가능해야 합니다.
-
Ingest Pipelines 설치: 일부 Filebeat 모듈은 Elasticsearch의 Ingest Node를 사용하여 로그 데이터를 전처리합니다. filebeat setup 명령은 이러한 Ingest Pipelines를 Elasticsearch에 설치합니다.
-
ILM (Index Lifecycle Management) 설정: Filebeat는 Elasticsearch의 ILM 기능을 사용하여 인덱스의 라이프사이클을 관리할 수 있습니다. setup 명령은 필요한 ILM 정책을 Elasticsearch에 설정할 수 있습니다.
-
Machine Learning Job 설정 (선택적): 일부 Filebeat 모듈은 Elasticsearch의 Machine Learning 기능과 통합될 수 있습니다. setup 명령을 사용하면, 이러한 Machine Learning 작업을 설정할 수 있습니다.
-
추가 설정: 명령어는 filebeat.yml 설정 파일에 기반하여 실행됩니다. 이 파일 내의 setup 관련 옵션들은 명령어의 동작을 미세하게 조절할 수 있게 해줍니다.
filebeat setup 명령어는 일반적으로 Filebeat를 처음 설치한 후, 그리고 Filebeat의 구성 파일을 수정한 후에 실행합니다. 이렇게 하면 모든 구성 요소가 올바르게 설치되고 업데이트됩니다.
✅ 3-6. filebeat 실행 스크립트 생성
$ mv ~/filebeat-7.17.13-linux-x86_64 ~/filebeat
$ sudo vim ~/startFilebeat.shnohup ~/filebeat/filebeat run \
--strict.perms false \
-c ~/filebeat/filebeat.yml \
--path.logs "~/filebeat/logs" \
--path.data "~/filebeat/logs" \
-e > ~/filebeat/logs/slave.log 2>&1&- 위 명령어는 nohup 명령어를 사용하여 filebeat 실행 파일을 실행하는 것입니다.
- 실행 옵션으로 run을 사용하며, --strict.perms false로 권한 오류를 무시합니다.
- c 옵션을 사용하여 ~/filebeat/filebeat.yml 파일을 사용하도록 설정합니다. 이 파일은 filebeat 설정 파일의 경로와 파일을 재로드할 때 필요한 옵션을 지정합니다.
- -path.logs 옵션은 로그 파일이 저장될 경로를 지정하는 옵션입니다. filebeat은 실행 중에 생성되는 로그 파일을 저장하기 위해 이 경로를 사용합니다.
- -path.data 옵션은 filebeat이 실행 중에 생성하는 임시 파일 및 레지스트리 파일이 저장될 경로를 지정하는 옵션입니다. 이 경로는 filebeat의 실행 중에 발생하는 모든 데이터가 저장되는 공간이며, 기본값은 /var/lib/filebeat입니다. 이 옵션을 사용하여 이 경로를 변경할 수 있습니다.
- e 옵션은 파일비트를 실행할 때 특정 이벤트에 대한 로그를 표시하는 모드입니다.
- 마지막으로 > ~/filebeat/logs/slave.log 2>&1&를 사용하여 로그 파일 ~/filebeat/logs/slave.log에 실행 로그를 기록하도록 설정하고, 실행 중 백그라운드에서 실행됩니다.
$ ~/startFilebeat.sh4. Elasticsearch 설치
대상 서버
- Elasticsearch
- 10.0.7.1
- 10.0.7.2
- 10.0.7.3
✅ 4-1. wget으로 설치
$ cd ~
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.13-linux-x86_64.tar.gz✅ 4-2. tar 압축 해제
$ tar -xvzf elasticsearch-7.17.13-linux-x86_64.tar.gz✅ 4-3. elasticsearch.yml 수정
$ sudo vim ~/elasticsearch-7.17.13-linux-x86_64/config/elasticsearch.ymlcluster.name: cluster-name 적기
node.name: ${HOSTNAME}
path.data: 데이터 디렉토리 경로
path.logs: 로그 디렉토리 경로
bootstrap.memory_lock: true
network.host: ${HOSTNAME}
http.port: 9200
thread_pool.write.queue_size: 1000
discovery.zen.ping.unicast.hosts: ["10.0.7.1", "10.0.7.2", "10.0.7.3"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.fd.ping_timeout: 60s
discovery.zen.fd.ping_retries: 5
bootstrap.system_call_filter: false
cluster.routing.allocation.disk.threshold_enabled: true
cluster.routing.allocation.disk.watermark.low: "65%"
cluster.routing.allocation.disk.watermark.high: "75%"
cluster.routing.allocation.disk.watermark.flood_stage: "85%"
cluster.initial_master_nodes:
- 10.0.7.1cluster.name: 클러스터의 이름node.name: 노드의 이름. ${HOSTNAME}으로 지정되어 있어 호스트의 이름을 사용합니다.path.data: 데이터 디렉토리 경로. ,로 구분된 여러 경로를 지정할 수 있습니다.path.logs: 로그 디렉토리 경로bootstrap.memory_lock: 메모리 락 기능 활성화 여부network.host: 네트워크 호스트http.port: HTTP 포트 번호thread_pool.write.queue_size: 쓰기 스레드 풀 큐 사이즈discovery.zen.ping.unicast.hosts: 클러스터에서 사용하는 호스트 목록discovery.zen.minimum_master_nodes: 최소 마스터 노드 개수discovery.zen.fd.ping_timeout: 플로팅 디스커버리 ping timeoutdiscovery.zen.fd.ping_retries: 플로팅 디스커버리 ping 재시도 횟수bootstrap.system_call_filter: 시스템 콜 필터링 활성화 여부cluster.routing.allocation.disk.threshold_enabled: 디스크 용량 기준을 활성화하거나 비활성화합니다.cluster.routing.allocation.disk.watermark.low: 로우 워터마크, 이 수치를 넘으면 새로운 샤드 할당을 중지합니다.cluster.routing.allocation.disk.watermark.high: 하이 워터마크, 이 수치를 넘으면 샤드를 다른 노드로 이동합니다.cluster.routing.allocation.disk.watermark.flood_stage: 플러드 스테이지, 이 수치를 넘으면 새로운 색인 작업을 중지합니다.cluster.initial_master_nodes: 클러스터 초기 마스터 노드 목록
✅ 4-4. elasticsearch 실행
$ cd ~/elasticsearch-7.17.13-linux-x86_64/bin
$ ./elasticsearch✅ 4-5. elasticsearch 실행 확인
$ curl -X GET "hostname:9200/_cluster/health?pretty"이 명령이 반환하는 JSON 응답에서 status 필드를 주의 깊게 봐야합니다.
- green: 모든 것이 정상입니다.
- yellow: 모든 데이터는 사용 가능하지만, 일부 복제본이 아직 할당되지 않았습니다.
- red: 일부 데이터가 사용 불가능합니다.
✅ 4-6. 트러블 슈팅
elasticsearch 실행 시 아래와 같은 에러가 발생
- memory locking requested for elasticsearch process but memory is not locked
- max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
1. Memory Locking:
- Elasticsearch에서는 swap을 사용하는 것을 권장하지 않습니다. 따라서, 메모리 잠금 설정을 사용하여 Elasticsearch 프로세스가 swap에 사용되지 않게 하는 것이 좋습니다. 위의 설정했던 아래의 elasticsearch.yml 설정이 swap을 사용하지 않게 하는 설정입니다.
bootstrap.memory_lock: true - 위의 설정이 되어있다면 Elasticsearch를 실행하는 사용자에 대해 메모리 잠금 권한을 허용해야 합니다. 이를 위해 limits.conf 또는 해당하는 limits.d 파일에 다음을 추가합니다.
$ sudo vim /etc/security/limits.confelasticsearch soft memlock unlimited elasticsearch hard memlock unlimited - 여기서 elasticsearch는 Elasticsearch를 실행하는 사용자 이름입니다.
- 위의 설정을 등록한 이후 서버를 한번 나갔다 다시 접속하여 잘 설정이 되었는지 확인합니다.
$ ulimit -l - 결과로
unlimited라는 값이 출력되어야 합니다.
2. vm.max_map_count 설정:
-
Elasticsearch는 JVM(Java Virtual Machine)에서 실행되며, 고성능 워크로드에서는 많은 양의 메모리 매핑을 필요로 합니다.
vm.max_map_count는 프로세스가 가질 수 있는 메모리 맵 영역의 최대 수를 설정하는 것입니다. -
따라서 Elasticsearch는
vm.max_map_count설정을 높게 유지하는 것을 권장합니다. 이 설정은 시스템에서 동시에 존재할 수 있는 VMAs(가상 메모리 영역)의 최대 수를 제어합니다. -
기본값은 65530입니다. Elasticsearch는 이 값을 적어도 262144로 설정하는 것을 권장합니다.
-
현재 세션에 대해 설정 값을 즉시 변경하려면
sudo sysctl -w vm.max_map_count=262144 -
이 변경 사항을 시스템 재부팅 후에도 유지하려면
$ sudo vim /etc/sysctl.confvm.max_map_count=262144- 변경 사항을 적용
sudo sysctl -p
5. Kibana 설치
대상 서버
- Elasticsearch
- 10.0.7.1
✅ 5-1. wget으로 설치
$ cd ~
$ wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.13-linux-x86_64.tar.gz✅ 5-2. tar 압축 해제
$ tar -xvzf kibana-7.17.13-linux-x86_64.tar.gz✅ 5-3. kibana.yml 수정
$ sudo vim ~/kibana-7.17.13-linux-x86_64/config/kibana.ymlserver.port: 8000
server.host: "hostname"
server.maxPayloadBytes: 1048576 (1MB 라는 뜻)
server.name: "Monitoring System"
elasticsearch.hosts: ["http://10.0.7.1:9200", "http://10.0.7.2:9200", "http://10.0.7.3:9200"]
elasticsearch.preserveHost: true
path.data: "path 적기"
elasticsearch.pingTimeout: 120000
elasticsearch.requestTimeout: 120000
elasticsearch.startupTimeout: 5000server.port: Kibana 서버가 사용할 포트를 설정합니다.server.host: Kibana 서버를 실행할 호스트를 설정합니다.server.maxPayloadBytes: 클라이언트가 전송할 수 있는 최대 페이로드 크기를 바이트 단위로 설정합니다.server.name: Kibana 서버의 이름을 설정합니다.elasticsearch.hosts: Kibana에서 사용할 Elasticsearch 호스트의 URL을 배열로 설정합니다.elasticsearch.preserveHost: Kibana에서 Elasticsearch 호스트를 요청할 때 호스트 이름을 유지할지 여부를 설정합니다.path.data: Kibana에서 사용할 데이터 디렉토리 경로를 설정합니다.elasticsearch.pingTimeout: Elasticsearch와의 연결을 확인하기 위해 사용되는 핑 타임아웃을 설정합니다.elasticsearch.requestTimeout: Elasticsearch에 대한 요청에 대한 타임아웃을 설정합니다.elasticsearch.startupTimeout: Kibana가 Elasticsearch에 연결하는 데 사용되는 시작 타임아웃을 설정합니다.
✅ 5-4. Kibana 실행
$ cd ~/kibana-7.17.13-linux-x86_64/bin
$ ./kibana6. 참고
