1. grok plugin
- Logstash 에서 제공하는 filter 플러그인중 grok 플러그인에 대해 설명해보겠습니다.
- grok 을 좀더 쉽게 이해하려면 문자열 포맷개념을 생각하면 됩니다.
test = "STR:%s,INT:%d" % ("Hello", 10)
print(test)
=========================
STR:Hello,INT:10- 이 예제는 파이썬에서 문자열 포맷을 이용하는 방식입니다. 그렇다면 우리는 "STR:Hello,INT:10" 이라는 내용의 로그를 분석하는것이 Logstash 에서 할일입니다.
- 이제 문자열 포맷 작업을 반대로 한다고 생각해봅시다. "STR", "INT" 는 고정 된 필드이고 각각의 정보는 쉼표로 구분되있습니다.
Logstash 에서 input 으로 들어온 로그데이터가 "STR:Hello INT:10" 이라고 해보겠습니다.
input {
tcp {
port => 9900
}
}
filter {
grok {
match => {
"message" => "STR\:%{WORD:str_field} INT\:%{WORD:int_field}"
}
}
}
output {
stdout {
codec => rubydebug
}
}- 파이썬처럼 편하게 "STR:%s INT:%d" 처럼 썻으면 좋겠지만 grok 필터의 규칙은 다릅니다.
${정규 패턴명:사용자정의 필드}
STR\:%{WORD:str_field} INT\:%{WORD:int_field}STR 은 로그상의 STR 과 같은 자리를 나타냅니다. 그다음에 오는 : 는 특수문자인 콜론을 표현하기 위해 역슬래시와 같이 쓰인것입니다.
그리고 %{WORD:str_field} 에서 WORD 는 단어를 구별하는 패턴이고 str_field 는 해당 패턴에 맞는 데이터를 저장할 필드명입니다.
즉 STR: 이후에 오는 단어 하나를 str_field 라는 사용자 정의 필드에 저장합니다.
뒤에 오는 INT 부분 역시 같은 원리로 동작합니다. 이러한 grok 패턴은 https://github.com/elastic/logstash/blob/v1.4.0/patterns/grok-patterns 사이트에서 확인가능합니다.
2. grok 정규표현식
위에서 grok 패턴을이용해서 로그를 분석해보았는데 패턴으로 표현하기 복잡한 로그들도 많이 있을것입니다. 그럴때는 패턴이아닌 정규 표현식을 이용할수 있습니다.
위에서 같은내용인 "STR:Hello INT:10" 에 대해 정규표현식으로 구현 해보겠습니다.
(?<필드명>정규 표현식)
grok {
match => {
"message" => "STR\:(?<str_field>\w+) INT\:(?<int_field>\d+)"
}
}WORD 라는 패턴대신에 \w 와 \d 를 사용하였습니다. 각각 단어와 숫자를 구분할수있는 표현식입니다. 뒤에 붙은 플러스 기호는 두글자 이상이라는 뜻입니다.
grok 패턴을 이해하려면 정규 표현식을 정확히 알아야 패턴이 어떤 형태의 데이터를 구별할수 있는지 알수있기에 처음엔 패턴 사용보단 정규 표현식으로만 해보는것을 추천합니다.
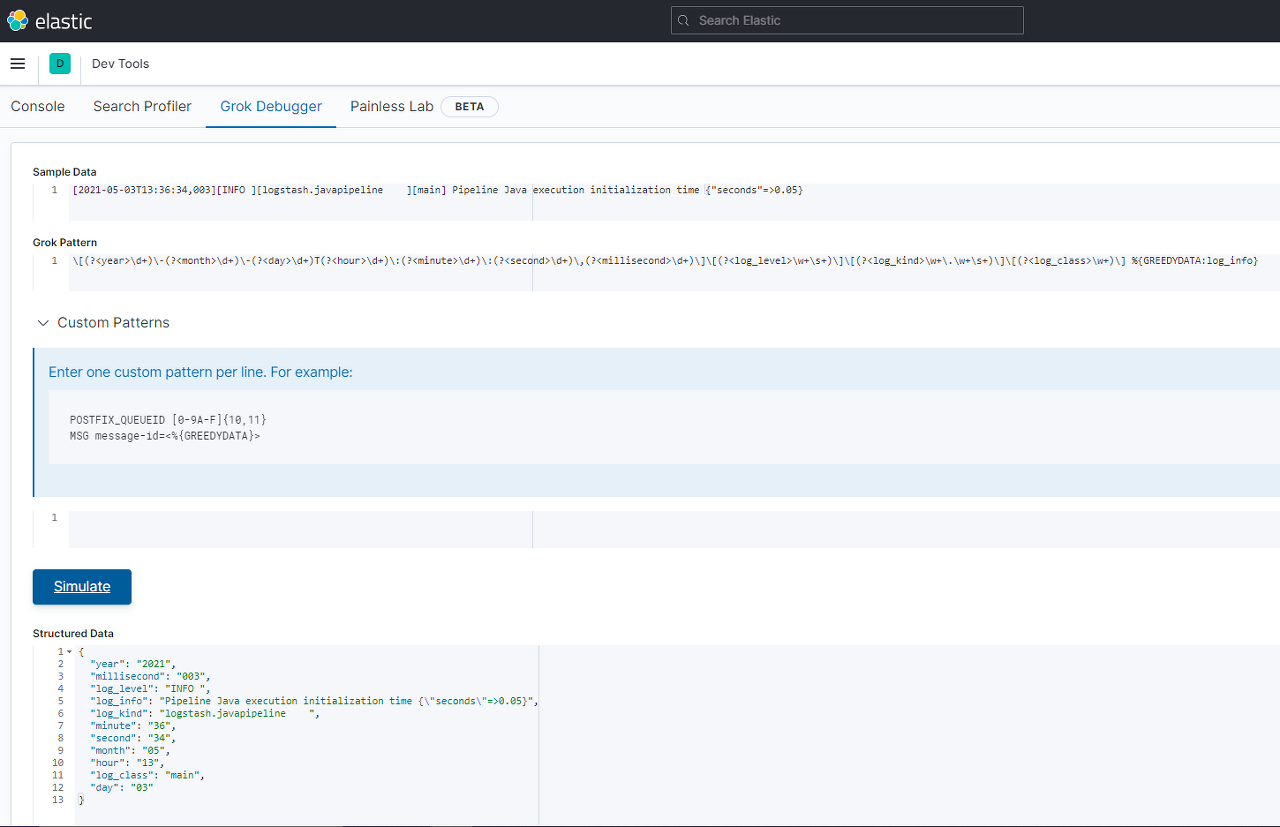
예제로 Logstash 를 실행시킬때 나오는 로그를 정규표현식을 사용해 필드를 나누어보겠습니다.
[2021-05-03T13:36:34,003][INFO ][logstash.javapipeline ]
[main] Pipeline Java execution initialization time {"seconds"=>0.05}grok {
match => {
"message" => "\[(?<year>\d+)\-(?<month>\d+)\-(?<day>\d+)T(?<hour>\d+)\:(?<minute>\d+)\:(?<second>\d+)\,(?<millisecond>\d+)\]\[(?<log_level>\w+\s+)\]\[(?<log_kind>\w+\.\w+\s+)\]\[(?<log_class>\w+)\] %{GREEDYDATA:log_info}"
}
}꽤 복잡해보이긴 하지만 사용한 정규식은 \w , \d, \s 세가지밖에 없습니다.
| 정규 필터식 | 의미 |
|---|---|
| \w | 한 글자 |
| \w+ | 한 단어 |
| \d | 정수 1자리 |
| \d+ | 정수 전체 |
| \s | 공백 한칸 |
| \s+ | 공백 전체 |
| \특수문자 | 특수문자 구분 |
[2021-05-03T13:36:34,003]\[(?<year>\d+)\-(?<month>\d+)\-(?<day>\d+)T(?<hour>\d+)\:(?<minute>\d+)\:(?<second>\d+)\,(?<millisecond>\d+)\]시간 부분은 year, month, day, hour, minute, second, millisecond 라는 필드로 구분하고 연월일 사이의 "-" 특수문자는 백슬래시와 함께 사용하여 구분하고 콜론 특수문자 역시 백슬래시와 함께 사용하여 구분하고 있습니다.
[INFO ][logstash.javapipeline ][main]\[(?<log_level>\w+\s+)\]\[(?<log_kind>\w+\.\w+\s+)\]\[(?<log_class>\w+)\]log_level 에 해당하는 INFO 는 2글자 이상이므로 \w 에 플러스기호를 같이 사용하고 공백도 있으므로 \s 와 플러스기호를 사용했습니다.
사실 INFO 에 붙은 공백은 한칸이지만 공백이 몇칸이나 붙을지는 로그레벨마다 예측할수 없으므로 플러스기호를 사용했습니다.
log_kind 에는 두 단어 사이에 점자가 들어갔으므로 구분하기위해 백슬래시와 함께 점을 사용했습니다. log_class 도 같은 방법으로 표현식을 작성했습니다.
Pipeline Java execution initialization time {"seconds"=>0.05}%{GREEDYDATA:log_info}주요 필드들에 대한 작업이 끝나고 로그 내용을 담아야 합니다. 로그 내용은 길이도 내용도 각각 모두 다르므로 표현식으로 일일히 표현하기가 어렵습니다. 이때 grok 패턴에서 제공하는
GREEDYDATA 패턴이 있습니다.
GREEYDATA 패턴은 뒤에 패턴이나 정규표현식이 오지않는이상 로그데이터의 끝까지 인식합니다.
Kibana 를 실행중이라면 Dev Tools 메뉴에서 Grok Debugger 기능을 통해 정규표현식을 검사할수있습니다.
3. 정규 표현식
.
점 표시, 사용자가 지정한 문자 뒤에 오는 어떠한 문자든지 하나만 매칭합니다.
Data : abc
(?<field>ab.) => "field":"abc"
Data : ab-
(?<field>ab.) => "field":"ab-"
Data : ab3
(?<field>ab.) => "field":"ab3"?
사용자가 지정한 문자열의 마지막 글자가 있거나 없을때에 대해 매칭합니다. 마지막 문자와 동일한 문자가 있으면 지정한 문자 전체를 매칭하고 없다면 그 이전까지만 매칭합니다.
해당 문자가 2개 이상이더라도 한개까지만 매칭합니다.
Data : abc
(?<field>abc?) => "field":"abc"
Data : abcc
(?<field>abc?) => "field":"abc"
Data : ab1
(?<field>abc?) => "field":"ab"
Data : ab
(?<field>abc?) => "field":"ab"+
사용자가 지정한 문자열의 마지막글자가 연속으로 나열된만큼 매칭합니다. \w, \d 의 경우 문자나 숫자를 전부 읽어서 매칭하고 \s는 연속된 공백 1개이상에대해 매칭합니다.
Data : abcccc
(?<field>abc+) => "field":"abcccc"
Data : abcccd
(?<field>abc+) => "field":"abccc"
Data : abcdef
(?<field>\w?) => "field":"abcdef"
Data : 123456
(?<field>\d+) => "field":"123456"
Data : abc 345
(?<field>\w+\s+\d+) => "field":"abc 345"*
? 표현식과 비슷한데 ? 는 마지막문자가 존재시 하나만 매칭시킨다면 ***** 는 마지막 문자가 반복되는만큼
모두 매칭시킵니다. \w, \d, \s 의 경우 + 와 동일하게 동작합니다.
Data : abccccd
(?<field>abc*) => "field":"abcccc"
Data : ab
(?<field>abc*) => "field":"ab"
Data : abcdef
(?<field>\w?) => "field":"abcdef"
Data : 123456
(?<field>\d?) => "field":"123456"
Data : abc 345
(?<field>\w*\s*\d*) => "field":"abc 345"{}
사용자가 지정한 문자에 대해 반복횟수를 지정하여 매칭합니다.
Data : aabb
(?<field>a{2}) => "field":"aa"
Data : aabb
(?<field>a{1}) => "field":"a"
Data : aabb
(?<field>a{3}) => error|
OR 연산자입니다. 지정한 문자열들에 대해 일치하는것과 매칭합니다.
Data : aa123
(?<field>aa|bb) => "field":"aa"()?
괄호 내부의 데이터는 부분집합처럼 사용할수있습니다.
Data : aabb
(?<field>aa(bb)) => "field":"aabb"
Data : aab
(?<field>aa(bb)) => "field":"aa"
Data : bb
(?<field>aa(bb)) => error데이터가 "aabb" 이고 정규표현식이 aa(bb) 이면 aa는 기본으로 매칭하는 문자이고 bb는 존재하면 같이 매칭되고 없다면 aa 만 매칭됩니다.
[]
대괄호 내부의 문자들을 매칭합니다. - (대시) 기호가 문자 사이에 있을경우 범위를 나타낼수있습니다.
| 정규 표현식 | 의미 |
|---|---|
| [0123] | 0, 1, 2, 3 |
| [0-9] | 0 ~ 9 |
| [abcd] | a, b, c, d |
| [a-z] | a, b, c..... z |
| [A-Z] | A, B, C....Z |
| [a-zA-Z] | a,b,c.....z,A,B,C....Z |
| [^abc] | a,b,c 제외 |
Data : abcde
(?<field>[a-z]) => "field":"a"
Data : abcde
(?<field>[a-z]+) => "field":"abcde"
Data : abcde
(?<field>[abcd]+) => "field":"abcd"
Data : 123
(?<field>[0-9]) => "field":"1"
Data : 123
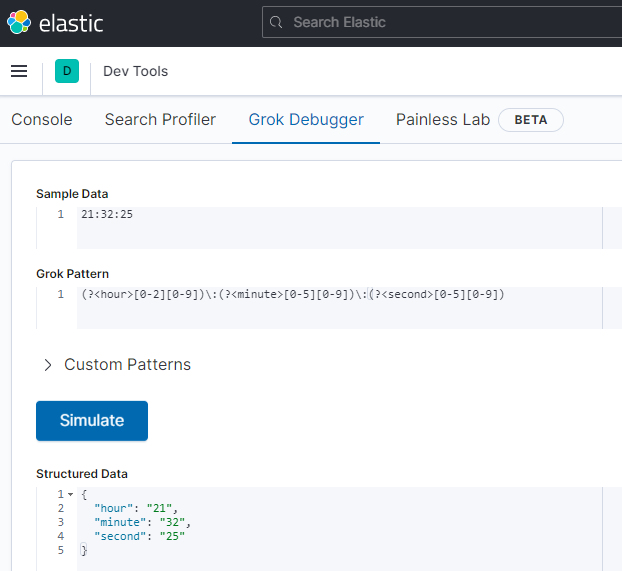
(?<field>[0-9]+) => "field":"123"4. 시간정보 정규표현식
로그데이터에서 숫자로 표현가능한 의미는 여러가지가 있을것입니다. IP, Port, 시간 등등.. 각각의 의미를 가진 숫자 데이터들은 종류에 따라 일정한 규칙이 있습니다. 그중에서 시간정보에 대해 정규표현식을 만드는 예제를 확인해보겠습니다.
(?<hour>[0-2][0-9])\:(?<minute>[0-5][0-9])\:(?<second>[0-5][0-9])시(hour) 단위의 경우 앞자리는 0 9 범위로 표현합니다. 분(minute), 초(second) 는 앞자리는 0 9 범위로 표현합니다. 시,분,초 모두 2자리씩 존재하므로 각 자릿수에서 표현가능한 숫자를 지정하면 됩니다.