HDFS 데이터 블록 복제
HDFS는 기본적으로 블록을 3개씩 복제한다. 복제시 아래와 같은 순서로 블록을 저장할 데이터노드를 선정한다.
Node local > Rack local > off switch
- Node local : 작업하는 노드가 데이터노드의 일부라면, 여기에 블록을 저장한다.
- Rack local : 작업하는 노드와 동일한 랙에 있는 노드에 블록을 저장한다.
- off switch : 작업하는 노드와 다른 랙에 있는 노드에 블록을 저장한다.
근데 하둡이 어떻게 노드의 위치를 알 수 있을까?
- 하둡의 Rack Awareness 설정을 통해 노드의 위치를 파악하는 것이다.
- 만약 namenode가 topology를 알아오지 못하면 무조건 /default-rack 으로 보낸다.
Rack Awareness(랙 인식)
하둡에는 Rack Awareness(랙 인식)이라는 개념이 있다. 하둡의 관리자가 수동으로 클러스터의 각 슬레이브 데이터 노드의 Rack number(랙 번호)를 정의할 수 있다. 데이터 복제시 Rack을 선택하는 문제는 데이터의 손실을 방지하는 것과 네트워크의 성능을 높이는 측면에서 아주 밀접한 관계가 있다.
데이터를 여러곳에 복제해 놓지 않으면, 데이터를 가지고 있는 노드가 고장날 경우에 서비스가 중단이 된다. 또한 데이터의 복사본들이 동일한 Rack에 저장이 되면, 스위치(Switch) 장비의 고장이나 정전으로 인하여 복제를 했는데도 마찬가지로 서비스를 받지 못하게 된다. 이러한 문제를 미연에 방지하기 위해서 데이터 복제본이 클러스터의 어느 장소에 위치시켜야 하는지에 대한 결정을 해야 하는데, 바로 네임 노드(Name Node)에서 담당을 한다.
네트워크 성능면에서 비교
- 동일한 Rack안에 존재하는 두 노드가 서로 다른 랙에 각각 존재하는 두 노드보다
대역폭(Bandwidth)이 크고,낮은 지연시간(Lower latency)을 가집니다. 이러한 사실을 토대로 네트워크 성능만을 고려한다면, 데이터 손실이 일어났을때는 지속적인 서비스 제공이 어렵게 된다.
네임노드의 역할
- 복사본들이 어떤 랙의 어느 위치에 저장되는 것이
네트워크 성능 측면과데이터 손실 측면에서 가장 합리적인지에 대한 결정을 해야 한다. - 이는 클라우드에 있는 전체 데이터 노드(Data Node)에서 서비스 가능한 데이터 노드들에 대한 정보를 최신으로 유지해야 가능하다.
- 오픈플로우(OpenFlow)를 사용할 경우에는 오픈플로우 컨트롤러(Controller)에게 물어본 후에 결정할 수도 있으며, 언제든지 컴퓨터를 통해서 수동으로 정보를 갱신할 수도 있습니다.
Preparing HDFS writes(HDFS write 준비)
- 예제 데이터를 'File.txt'라 가정
클라이언트(Client)는 'File.txt'를 여러 개의 블록으로 나누고, 블록들을 저장하기 위해서 네임 노드(Name Node)에게 블록들이 저장될 데이터 노드(Data Node)들의 위치를 묻습니다. 네임 노드는 'Rack Awareness' 데이터를 사용하여 합리적인 데이터 노드의 리스트를 클라이언트에게 보낸다. 네임 노드(Name Node)에서 데이터를 저장할 데이터 노드(Data Node)를 선택하는 가장 중요한 규칙은 하나의 랙(Rack)안에 두개의 복사본을 저장하고, 다른 랙에 나머지 복사본을 저장하는 방법.
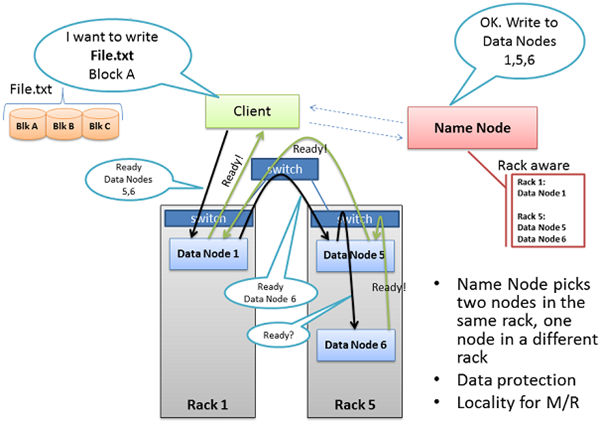
클라이언트는 File.txt에서 분할된 블록들을 클러스터로 복사하기전에 관련된 모든 데이터 노드들에게 블록을 받을 준비가 되었는지 확인하는 작업을 진행한다. 먼저 클라이언트는 ‘Data Node 1’ 에게 TCP의 50010(Port)를 통해서 블록을 받을 준비가 되었는지 물어본다. 마찬가지로 ‘Data Node 1’ 은 TCP를 통해서 ‘Data Node 5’에게 데이터를 수신할 준비가 되었는지 물어본다. 동일한 방법으로 ‘Data Node 5’ 역시 ‘Data Node 6’에게 물어본다.
준비 요청에 대한 승인 여부는 마지막 노드에서 처음 노드로 역순으로 ‘Ready’ 메시지를 보내준다. ‘Data Node 6’에서 ‘Data Node 5’와 연결되어 있는 TCP의 파이프라인을 통해서 ‘Ready’ 메시지를 보내고, ‘Data Node 5’는 ‘Data Node 1’에게 보내고, 최종적으로 ‘Data Node 1’은 클라이언트에게 ‘Ready’ 메시지를 보내면 블록을 복사할 준비가 끝나게 된다.
HDFS Write Pipeline
블록을 클러스터에 복사하기 위해서 이미 데이터 노드들간에 연결된 TCP 통신을 통해서 이루어진다. 즉, 데이터 노드가 블록을 받자 마자 다음 데이터 노드에게 블록을 바로 전송한다는 말이다. 다음 그림은 클러스터 성능을 향상시키기 위해서 네임 노드가 ‘Rack Awareness’ 데이터를 활용하는 방법을 나타낸 것이다.
‘Data Node 5’와 ‘Data Node 6’은 같은 ‘Rack 5’에 위치하고 있다. 이 말은 ‘Data Node 1’이 ‘Data Node 5’로 데이터를 전송하기 위해서는 하나의 스위치(Switch)만 거치면 되며, 두개의 데이터 노드들이 동일한 랙을 횡단할 필요가 없으며, 동일한 랙에 있기 때문에 높은 대역폭과 낮은 대기 시간으로 네트워크 성능을 높일 수 있다. 또한 현재 블록의 복사 작업이 완료가 되지 않으면 다음 블록에 대한 작업은 시작하지 않는다.
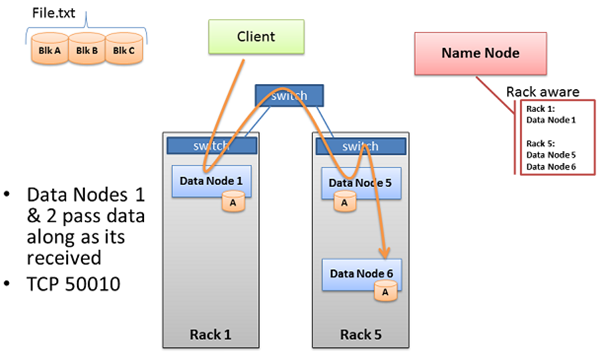
Pipelined Write
세개의 데이터 노드들이 성공적으로 블록을 받게 되면, 메시지를 성공적으로 받았다고 네임 노드에게 ‘Block Received” 메시지를 보낸다. 마찬가지로 “Success” 메시지를 TCP 통신을 통해서 클라이언트에게도 보낸후에 기존에 연결된 TCP 세션을 닫습니다. 클라이언트는 “Success” 메시지를 받으면 네임 노드에게도 “Success” 메시지를 보냅니다. 네임 노드는 “Success” 메시지를 받으면 블록의 노드 위치와 정보를 자신의 메타 데이터에 반영합니다. 이러한 절차가 완료가 되면 클라이언트는 다음 블록에 대한 작업을 진행합니다.
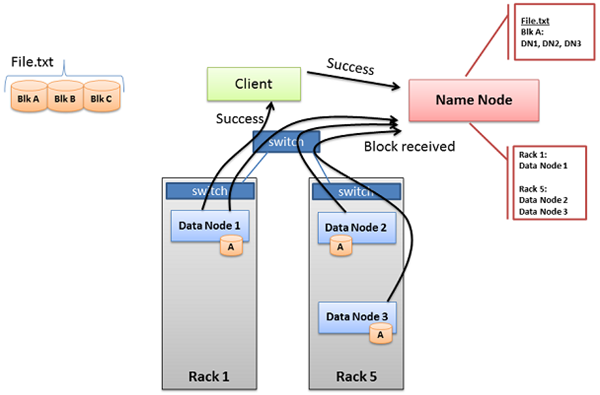
Multi-block Replication Pipeline
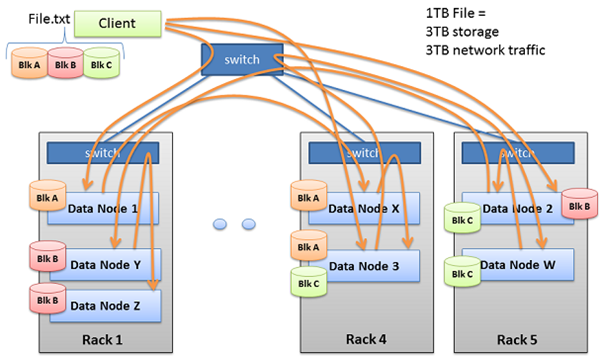
하둡은 빅데이터와 같은 대규모의 데이터를 저장하는데 사용되며, 이 때문에 네트워크 대역폭 또한 많이 사용한다.일반적으로 테라 바이트(TB, Tera Byte) 크기의 파일들을 다루고 있으며, 기본적으로 3번의 복제가 이루어진다. 만약1TB의 파일이 있는 경우에는 3TB의 네트워크 대역폭과 3TB의 디스크 공간이 필요하다.
Name Node
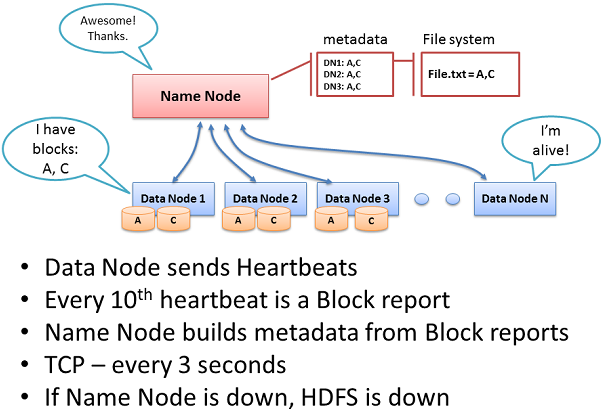
네임 노드는 클러스터의 모든 파일 시스템 메타데이터(File System metadata)를 보유하고, 데이터 노드를 관리하며, 데이터에 대한 접근을 조정한다. 네임 노드는 하둡 분산 파일 시스템(HDFS)의 중앙 컨트롤러(Central Controller) 이다. 이 말은 네임 노드가 정상적으로 동작하지 않으면, 하둡 분산 파일 시스템은 서비스를 멈추게 된다. 네임 노드는 파일들이 어떤 블록들로 구성되어져 있고, 그 블록들이 클러스터의 어느 위치에 저장되어 있는지에 대한 정보를 알고 있다.
데이터 노드는 네임 노드에게 TCP 핸드쉐이크(handshake)를 통해서 매 3초마다 ‘heartbeat’를 보낸다. TCP 핸드쉐이크는 보통 9000포트를 사용한다. 매번 10번째 ‘heartbeat’는 데이터 노드들이 보유한 블록들의 정보를 네임 노드에게 보고한다. 네임 노드는 이를 통해서 메타 데이터를 구축하고, 블록들의 사본들이 저장되어 있는 랙(Rack)과 노드(Node) 정보를 수집한다.
네임 노드는 하둡 분산 파일 시스템의 핵심 컴포넌트이다. 네임 노드가 없으면 하둡 분산 파일 시스템에 블록을 작성하거나 읽을 수 없으며, 스케쥴(Schedule)이 불가능하며, 맵-리듀스 작업을 할 수 없다. 이 때문에 네임 노드는 엔터프라이즈급(Enterprise class) 서버에 구성하는 것이 좋다.
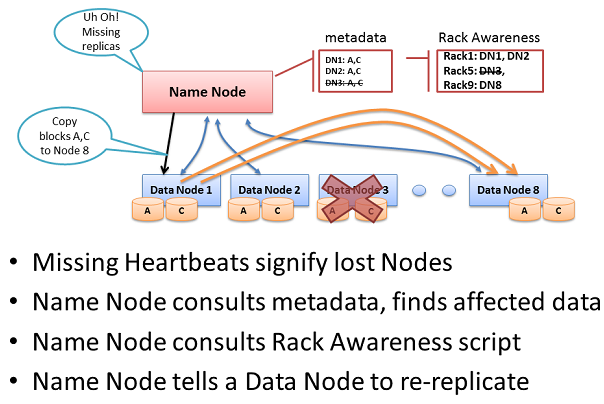
Re-replicating missing replicas
네임 노드는 데이터 노드에서 ‘heartbeat’를 수신받지 못하면, 그 데이터 노드는 죽은것으로 가정한다. 네임 노드는 죽은 데이터 노드가 이전에 보냈던 블록 리포트(Block Report) 정보를 참조하여 다른 데이터 노드에 복제를 결정할 수 있다.
네임 노드는 블록의 사본을 새로운 데이터 노드에 복제하기 위해서 ‘Rack Awareness’ 데이터를 참조하여 결정을 한다. 결정시, 하나의 랙(Rack)에 두개의 복사본을 저장하고, 또 다른 랙에 나머지 하나의 복사본을 복제해야 하며, 랙 스위치의 장애 또는 전원 장애로 인한 문제시에도 시스템이 정상적으로 작동되도록 고려한다.
Rack Awareness 설정
/(하둡 설치한 경로)/conf/core-site.xml
<property>
<name>net.topology.script.file.name</name>
<value>/(하둡 설치한 경로)/conf/topology.sh</value>
</property>/(하둡 설치한 경로)/conf/topology.sh
- 해당 shell 스크립트는 하둡 위키에 참조!
#!/bin/sh
# Supply appropriate rack prefix
RACK_PREFIX="default"
# To test, supply a hostname as script input
if [ $# -gt 0 ]; then
HADOOP_CONF=${HADOOP_CONF:-"/(하둡 경로)/etc/hadoop/conf"}
while [ $# -gt 0 ] ; do
nodeArg=$1
exec< ${HADOOP_CONF}/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ] ; then
result="${ar[1]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/$RACK_PREFIX/rack"
else
echo -n "/$RACK_PREFIX/rack_$result"
fi
done
else
echo -n "/$RACK_PREFIX/rack"
fi/(하둡 설치한 경로)/conf/topology.data
# Add hostnames to this file. Format <host ip> <rack name>
# 여기에 나오는 IP와 rack name은 가상입니다.
10.10.10.11 rack-B01
10.10.10.12 rack-B01
10.10.10.13 rack-B01
10.10.10.14 rack-B01
10.10.10.15 rack-B01
10.10.10.16 rack-B02
10.10.10.17 rack-B02
10.10.10.18 rack-B02
10.10.10.19 rack-B02
10.10.10.20 rack-B02-
모든 노드는 같은 데이터 센터에 있다고 가정했고, rack은 B01,B02로 나누었다.
-
앞서 네임노드, 리소스 매니저의 HA 구성을 11, 16 노드로 했기 때문에 둘은 각 노드를 rack B01, B02로 나뉘었다.
-
rack에 대한 정보는
logs/에네임노드 로그에서 확인할 수 있다.2019-02-21 11:12:30,861 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /dc_1/rack_1/192.168.56.191:50010 ... 2019-02-21 11:12:30,917 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /dc_1/rack_1/192.168.56.194:50010 ... 2019-02-21 11:12:31,015 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /dc_1/rack_2/192.168.56.193:50010 ... 2019-02-21 11:12:31,056 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /dc_1/rack_2/192.168.56.192:50010 ... 2019-02-21 11:12:31,130 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /dc_1/rack_1/192.168.56.195:50010 -
Yarn의 리소스 매니저가 동작중이면 Yarn UI에서도 확인이 가능하다.
리소스 매니저IP:8088 -> Cluster -> Nodes
HDFS 확인
- rack-awareness 설정 후 실제 HDFS에 데이터를 put하면 block이 다른 rack에 배치되는 것을 확인할 수 있다.
bin/hdfs dfs -put file.txt /user/hadoop/
보통 리플리케이션이 3이라면 아래 순서로 복사본 배치를 진행한다.
- 같은 노드
- 다른 랙(무작위) 노드
- 두번 째 랙과 같은 랙의 다른 노드
위 기본 전략은 신뢰성 (블록을 여러 랙에 저장), 쓰기 대역폭 (하나의 네트워크 스위치만 통과), 읽기 대역폭 (두 랙에서 가까운 렉을 선택), 클러스터 전반에 걸친 블록의 분산(클라이언트는 로컬 랙에 하나의 블록만 저장) 사이의 균형을 전체적으로 잘 맞추고 있다.
