Hadoop, HBase, Spark 클러스터 구축 및 운영
1.Hadoop 완전분산모드(Fully-Distributed) Cluster 구성

개인적인 Server 구성으로, 본인 PC환경에 알맞게 구성해주시면 됩니다. Disk Size는 최소 20G이상을 권장드립니다.지원되는 플랫폼 (Supported Platforms)GNU / LinuxWindows (https://cwiki.apache.org
2.HBase 구성 ( Full-distributed )
JavaJDK8 권장HBase 버전 1.2+인 경우 JDK7도 지원JDK9, 10, 11은 확실하지 않음운영체제 유틸리티sshDNSNTPZookeeperZookeeper 3.4.x 이상Hadoop (앞의 Hadoop 완전분산모드(Fully-Distributed) Clu
3.Hadoop 운영을 위한 설정 정보 상세분석( Crawl )
해당 설정 정보는 Crawl한 Web Document를 저장 하는 용도의 Hadoop서버를 기준으로 운영을 하기위한 설정 정보 입니다. 앞의 Hadoop Cluster 구성이 되어 있어야 합니다. hdfs, mapred 공통 설정hdfs 설정yarn 설정mapred 설
4.Hbase 운영을 위한 설정 정보 상세분석( Crawl )
해당 설정 정보는 Crawl한 Web Document를 저장 하는 용도의 Hbase서버를 기준으로 운영을 하기위한 설정 정보 입니다. 앞의 Hadoop 및 Hbase의 Cluster 구성이 되어 있어야 합니다. Hbase 환경 설정hbase 실행 정보 설정을 위한 sh
5.HDFS 데이터 블록 복제와 Rack Awareness 설정
HDFS는 기본적으로 블록을 3개씩 복제한다. 복제시 아래와 같은 순서로 블록을 저장할 데이터노드를 선정한다.Node local > Rack local > off switchNode local : 작업하는 노드가 데이터노드의 일부라면, 여기에 블록을 저장한다.Rack
6.Snappy 압축 설명 및 설치
Hadoop, HBase를 이용하여 작업을 처리할 때 저장장치를 효율적으로 이용하기 위해서 데이터 파일을 압축할 때 사용하는 압축 알고리즘인 snappy에 대해서 알아보겠습니다.Snappy는 구글에서 자체 개발한 압축 라이브러리이며, 최고의 압축률 보다는 적정 수준의
7.Spark Cluster 구성
소프트웨어 설치 (Installing Software)Hadoop Cluster 설치 Spark의 설치는 Master와 Slave 모든 서버에서 동일하게 수행해야 합니다.Download UrlSpark 홈페이지 : https://spark.apache.org/
8.Spark Job을 실행시켰는데 offset의 sink가 맞지 않아서 실행되지 않은 문제
스파크 스트리밍에서 Checkpoint는 스트리밍 애플리케이션의 상태를 주기적으로 저장하여 고장 복구를 도울 수 있는 메커니즘이다. 체크포인트는 다음 두 가지 정보를 저장한다.1\. 메타데이터: 스트리밍 애플리케이션의 설정, DStream 연산, 그리고 작업 진행 상황
9.HBase 데이터 삭제
운영하는 하둡 클러스터에 디스크가 모두 90% 이상 차는 일이 발생했다.따라서 과거 데이터 부터 삭제, 각 서버 용량이 80%가 확보되는 시점까지 데이터를 삭제를 하도록 지시가 내려졌으면 데이터 삭제후 노드를 살펴보고 디스크 교체해야하는 노드들 산정하기로 했다.대규모의
10.HBase 데이터 삭제2
이전에 개발한 HBase 데이터 삭제는 테이블의 모든 row데이터를 scan하고 Timestamp를 기준으로 이전의 데이터들을 삭제하는 단순한 코드였다.하지만 역시 대규모의 데이터를 하나의 프로세스로 scan하고 삭제하기까지는 시간이 너무 오래 걸렸다.그래서 이번에는
11.Ambari에 연결하여 hdfs 평균 디스크 사용률 계산
hdfs 리밸런싱을 하기전에 각 노드의 디스크 사용률과 전체 디스크 평균 사용률을 보려고 했는데Ambari나 어디에도 전체 디스크 평균 사용률을 보여주는 곳이 없다.그래서 내가 만들었다.
12.On-heap memory 와 Off-heap memory
spark-submit을 돌리던 중 옵션에서 driver-memory, executor-memory 는 on-heap memory를 설정하며spark.executor.memoryOverhead는 Spark 익스큐터 프로세스에 대해 off-heap memory를 설정한다
13.HBase 필수 지식
HBase에서 특정 로우 값을 읽어오는 기본 메커니즘은 다음과 같습니다:로우 키로 리전 결정: 클라이언트가 요청한 로우 키를 기반으로 hbase:meta 테이블이 검색됩니다. hbase:meta는 각 리전의 시작 및 종료 로우 키를 가지고 있으므로, 이 테이블을 통해
14.HDFS 및 HBase 리밸런싱
Hadoop Cluster의 상태를 모니터링 시스템을 통하여 플랫폼의 slave 서버들을 확인한 결과 일부 서버간의 현재 저장된 디스크 용량의 차이가 존재한다는 것을 확인한쪽 서버에 write requests count가 압도적으로 높다면, 데이터와 요청이 한쪽에 집중
15.On Premise 환경에서 Hadoop Cluster Scale Out 하기전 서버 검토
운영하던 Hadoop Cluster의 메모리, 디스크 용량 등의 리소스 부족으로 신규 서버를 추가해야하는 상황이 발생하였다.On Premise 환경에서 어떻게 추가할 서버의 성능을 검토하는지 자세하게 알아본다. 하드웨어(cpu, disk, network) 의 성능을 측
16.Spark( RDD vs DataFrame vs Dataset)
Resilient: 분산되어 있는 데이터에 에러가 생겨도 복구할 수 있는 능력Distributed: 클러스터의 여러 노드에 데이터를 분산해서 저장Dataset: 분산된 데이터의 모음SparkContext를 통해 만들어지며 보통 sc=spark.SparkContext를
17.Spark의 Partition 개념, spark.sql.shuffle.partitions, coalesce()
Partition은 RDDs나 Dataset를 구성하고 있는 최소 단위 객체이며, 스파크의 성능과 리소스 점유량을 크게 좌우할 수 있는 RDD의 가장 기본적인 개념입니다.데이터 파티셔닝은 데이터를 여러 클러스터 노드로 분할하는 메커니즘을 의미합니다.각 Partition
18.Spark partition pruning
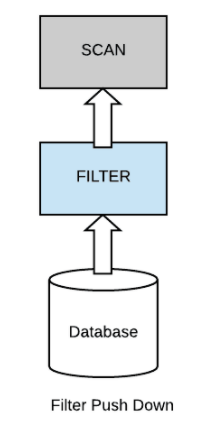
prunning이란 '가지치기' 라는 뜻으로 데이터 시스템에서는 얻고자 하는 데이터를 가지고 있지 않은 파일은 스킵하고 얻고자 하는 파일만 스캔하는 최적화 기법RDBMS의 Partition prunning과 개념적으로 동일Spark가 HDFS나 S3와 같은 저장소에 디
19.Spark (yarn container, spark core, executor 개수 Memory 용량) 계산법 및 최적화
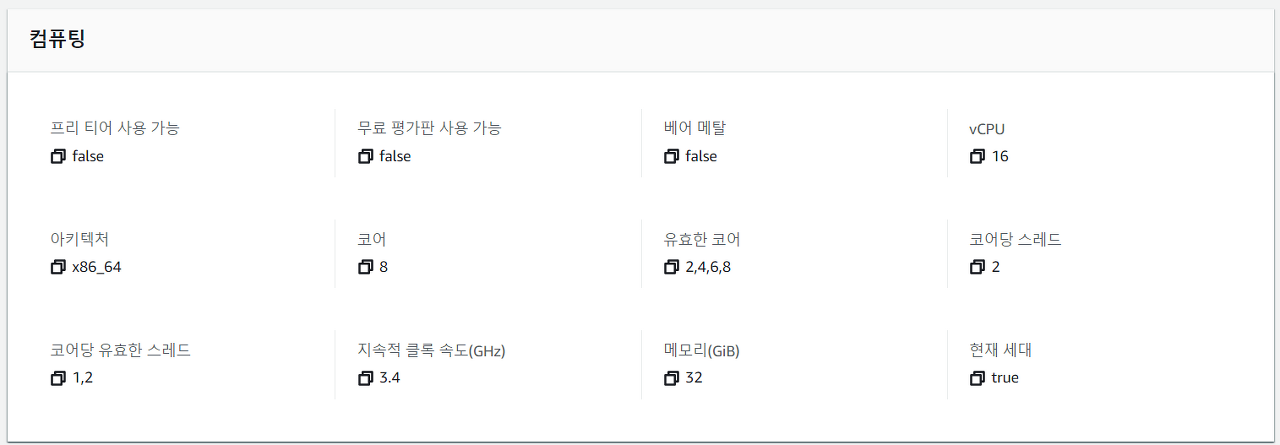
요즘은 하이퍼스레딩이라 하여 1코어에 2개의 스레드를 지원하는 instance들이 많습니다.core든 vCore든 가상화의 차이만 있을 뿐 같은 코어입니다.여기서 중요한건 코어당 스레드가 1이냐 2이냐 차이인데,아래의 instance는 8코어이지만 vCPU(vCore,
20.Spark (RDD action & transformation) + Dataframe의 연산(operation) 분류

Spark Transformation 는 기존의 RDD에서 새로운 RDD를 생성하는 function이다.Lazy 처리방식이라서 action을 호출할 때 transformation이 실제로 실행된다.\->transformation을 수행할 때 query plan만 만들고
21.Spark job에 따른 최적의 Partition 크기, 개수 조정하기
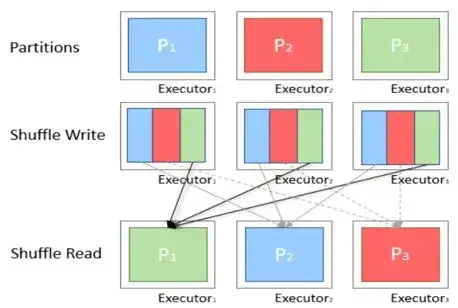
1\. Shuffle이 일어나는 이유파티션 사이에서 데이터가 재배치 되어야 할 때특정 transforamtion 실행 시 다른 파티션에서 정보가 필요하기 때문에 셔플을 함으로써 정보를 찾음2\. shuffle은 언제 일어나는 지join, union, groupBy, s
22.Spark (PartitionFilters vs PushedFilter 비교), (predicate pushdown vs projection pushdown)
PartitionFilters란특정 파티션에서만 데이터를 가져오고 관련 없는 파티션은 모두 생략합니다. 데이터 스캔 생략은 성능의 큰 향상을 가져다 줍니다.PushedFilters 보다 선행된다.PartitionFilter기술은 조건에 사용된 컬럼이 파티션되어 있고 스
23.Spark Memory 정리
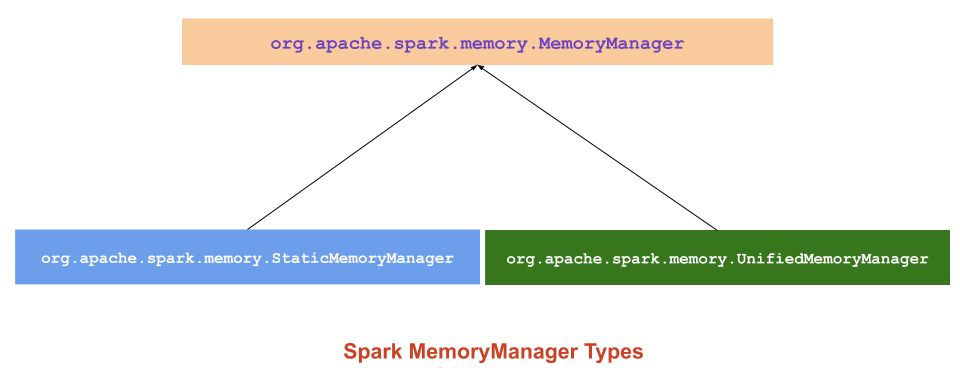
종류Static Memory Manager (Static Memory Management) 정적Unified Memory Manager (Unified memory management) 통합spark 1.6.0부터 통합 메모리 관리자가 Spark의 기본 메모리 관리자로
24.Spark deploy mode (Cluster/Client)
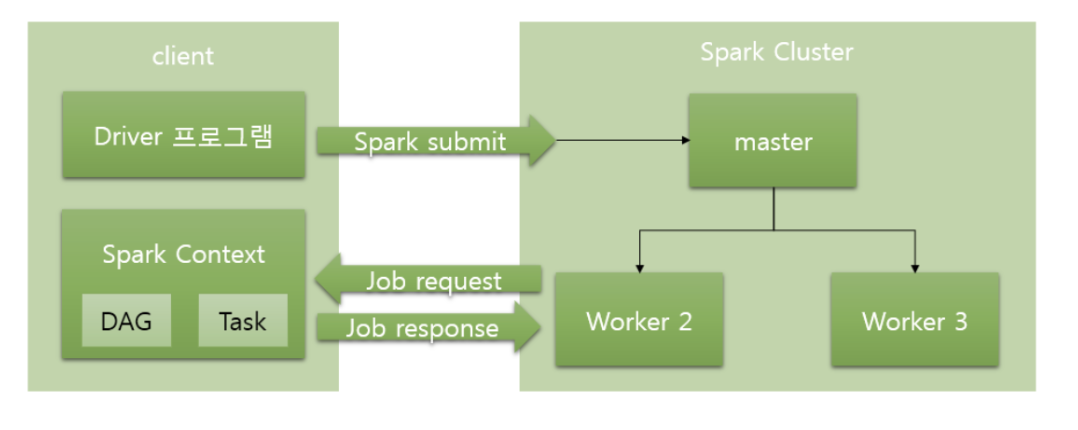
driver가 클러스터 외부에 있다. 즉, spark-submit이 드라이버를 자신이 실행되는 머신 위에서 실행된다. Application Master는 단순히 노드 매니저에게 자원 요청만 하고 Spark 애플리케이션에서 사용 중인 리소스를 표시하기 때문에, 주로 개발
25.Spark Scheduler
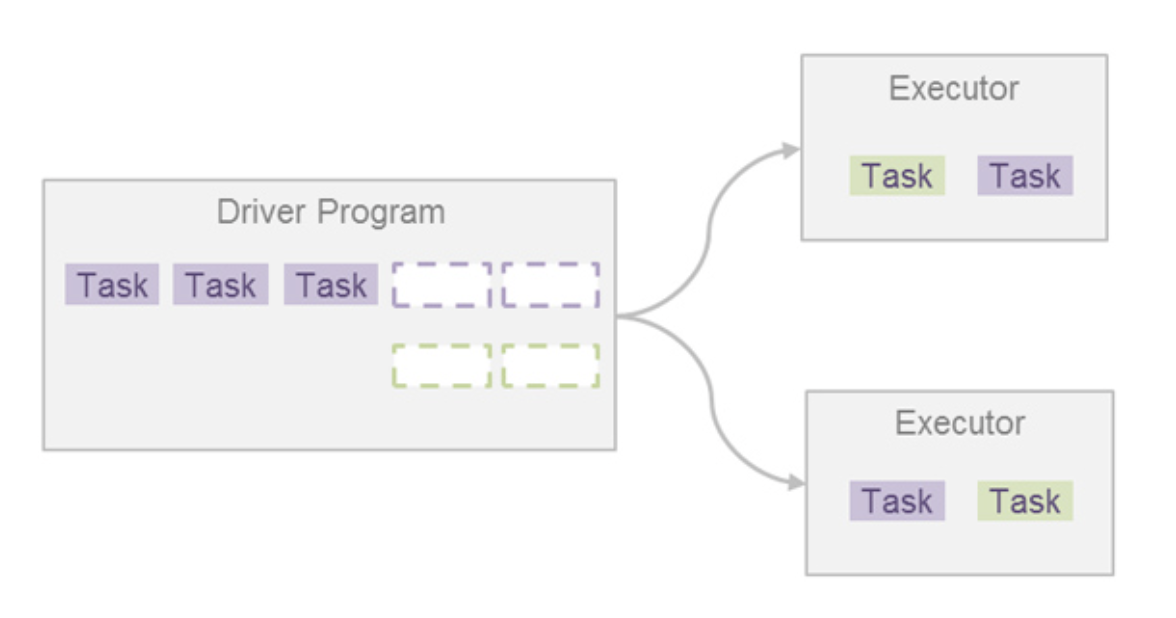
스파크 애플리케이션은 여러 잡을 실행시켜 원하는 바를 달성한다.스파크 잡은 태스크라고 하는 더 작은 실행 단위로 나뉜다.이 태스크는 여러 익스큐터에게 작업 실행을 요청함으로써 병렬 처리가 가능하다.태스크가 종료되면 결과를 받고 다른 태스크를 실행 요청하며, 잡의 모든
26.Spark FlatMap
Apache Spark에서 flatMap 함수는 복잡한 데이터 구조를 단순화하여 분석과 쿼리 작업을 용이하게 만드는 핵심 기능 중 하나이다. flatMap은 각 입력 요소를 여러 출력 요소로 변환할 수 있으며, 주로 중첩된 컬렉션을 단일 수준의 컬렉션으로 평탄화하는 데
27.Spark JDBC와 Aurora DB
단순 SELECT 쿼리Aurora DB의 메모리를 비교적 적게 사용쿼리 결과는 디스크에서 읽어오고, 필요한 데이터만 Spark에 전송복잡한 SELECT 쿼리 (JOIN, GROUP BY, ORDER BY)Aurora DB는 쿼리를 실행하는 동안 메모리를 사용하여 정렬이
28.Spark Shuffle Partition 최적화
https://tech.kakao.com/posts/461
29.어떻게 spark job에서 withColumn이 성능 저하를 유발할 수 있을까?
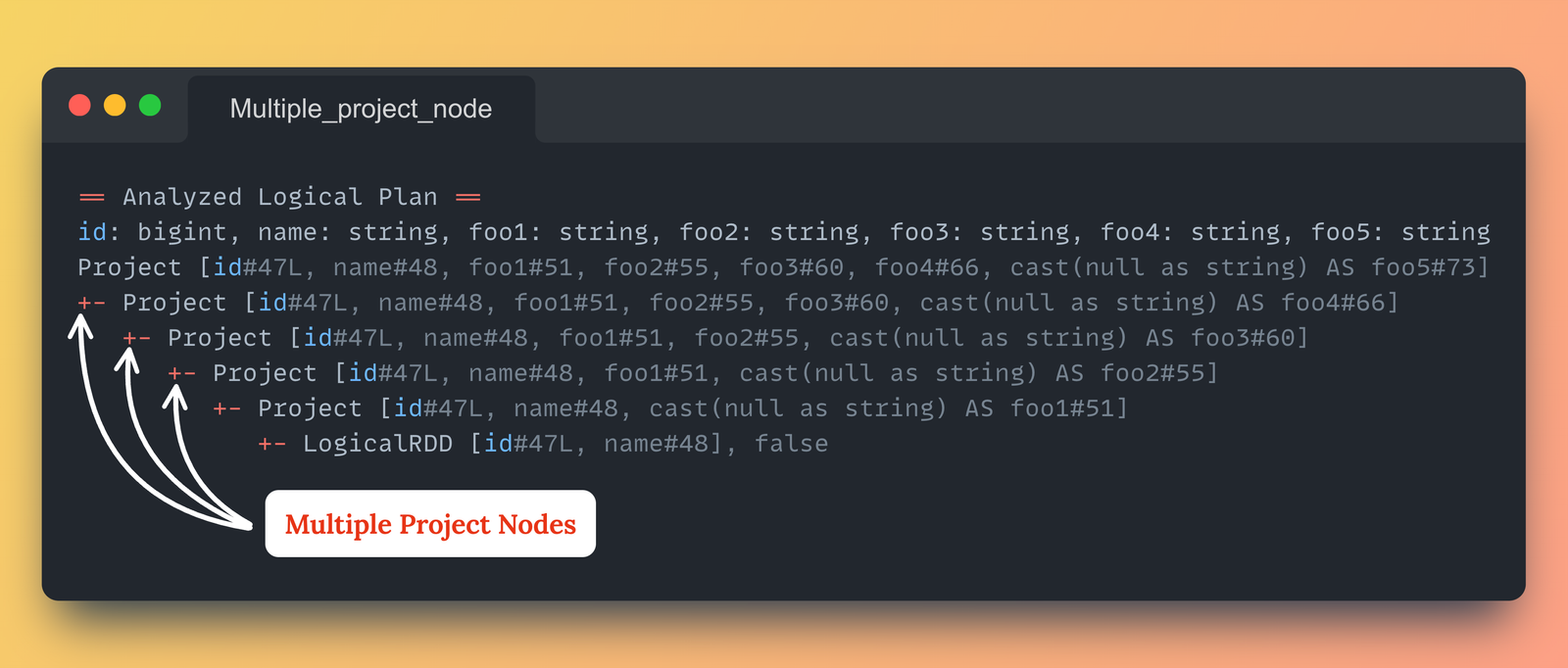
데이터프레임에 여러 개의 열을 추가하거나 형변환해야 하는 상황에서, 일반적으로 .withColumn() 메서드를 for문과 같은 문법을 이용하여 반복적으로 사용하는 방법을 선택한다. 이 방법은 코드를 간결하게 작성하는 것이 가능하지만 .withColumn() 메서드를
30.멀티스레딩을 사용한 Spark 성능 향상
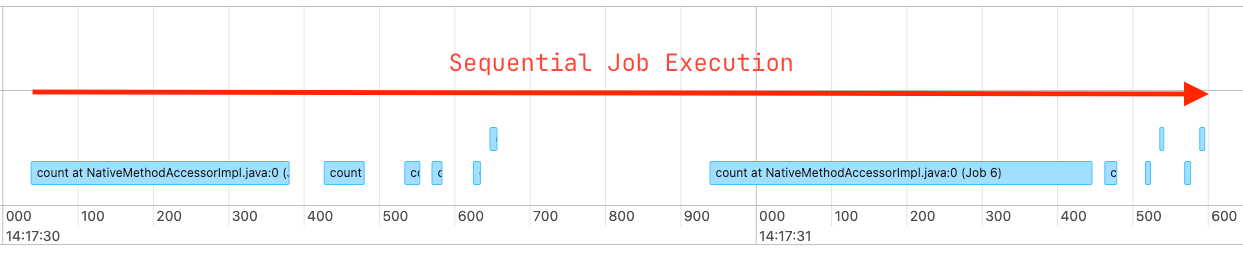
Spark 작업을 수행할 때 다음과 같은 상황이 자주 발생여러 테이블의 데이터를 읽어서 통계나 레코드 수를 계산하는 작업 모든 작업이 서로 의존하지 않는 독립적인 쿼리일 경우, Spark는 이를 순차적으로 처리즉, 병렬 처리를 제대로 활용하지 못하는 상황이 많음위 방