Server 구성
| Server | master | slave01 | slave02 | slave03 |
|---|---|---|---|---|
| OS | centos7 | centos7 | centos7 | centos7 |
| Disk Size | 1000G | 1000G | 1000G | 1000G |
| Memory | 32G | 16G | 16G | 16G |
| Processors | 12 | 12 | 12 | 12 |
개인적인 Server 구성으로, 본인 PC환경에 알맞게 구성해주시면 됩니다. Disk Size는 최소 20G이상을 권장드립니다.
전제 조건(Prerequisites)
- 지원되는 플랫폼 (Supported Platforms)
- GNU / Linux
- Windows (https://cwiki.apache.org/confluence/display/HADOOP2/Hadoop2OnWindows)
- 필수 소프트웨어 (Required Software)
- Java
- ssh
- 소프트웨어 설치 (Installing Software)
- Java
- 설치 여부 : javac -version
- 설치 : yum install -y java-1.8.0-openjdk-devel.x86_64
- ssh
- 설치 여부 : ssh -V
- 설치 : yum insatll -y openssh-clients
- Java

- 서버의 접속한 계정에 sudo 권한
- /etc 에 접근할 수 있는 권한
- scp를 사용할 수 있는 권한
- 사용한 hostname들은 (master, slave01, slave02, slave03) 은 예시 입니다.
※ 이 2가지(Javs, ssh) 소프트웨어는 모든 Server에 필히 설치되어 있어야 합니다.
Hadoop 다운로드 (Download)
- Download Url
- Hadoop 홈페이지 : hadoop.apache.org/releases.html
- Hadoop 미러 사이트 : apache.mirror.cdnetworks.com/hadoop/common/
- Version
- 위 2사이트에서 안정적인 버전(stable version) 또는 목록 중에서 다른 Application들과의 호환성을 고려하여 선택합니다.
- 추후 HBase를 설치하실 분은 2.7.7 or 2.8.5 or 3.1.1+ 을 다운로드 합니다. (Hadoop 미러 사이트로 접속)
- Download
- Download 서버 : master
- Download 위치 : ~
cd ~;
wget http://apache.mirror.cdnetworks.com/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz;
tar xzvf hadoop-2.7.7.tar.gz;
rm -rf hadoop-2.7.7.tar.gz;
mv hadoop-2.7.7 hadoop경로 설정 (Path)
- JAVA_HOME
- openjdk는 '/usr/lib/jvm/java--openjdk-.x86_64' 가 경로가 됩니다.
- HADOOP_HOME
- hadoop을 설치한 위치가 경로가 되므로 저의 경우에는 '~/hadoop' 이 경로가 됩니다.
- PATH
- 위에서 지정한 경로들을 PATH에 추가해주면 해당 bin파일로 가지 않아도 해당 명령을 사용할 수 있습니다.
- 적용
- 진행 노드 : master, slave01, slave02, slave03
- 파일 : ~/.bashrc
- 경로 적용
- 재부팅 ( reboot )
- source ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
export PATH=$JAVA_HOME:/bin:$PATH
export CLASSPATH=$CLASSPATH:$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=~/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_CONF_DIR=~/hadoop/etc/hadoop
export HADOOP_YARN_HOME=$HADOOP_PREFIX
export YARN_CONF_DIR=$HADOOP_CONF_DIR
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_LOG_DIR=/hadoop_tmp/hadoop/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export HADOOP_MAPRED_LOG_DIR=$HADOOP_LOG_DIR
export HADOOP_PID_DIR=/hadoop_tmp/hadoop/pids/hadoop
export YARN_PID_DIR=/hadoop_tmp/hadoop/pids/yarn
export HADOOP_MAPRED_PID_DIR=/hadoop_tmp/hadoop/pids/mapred
export HADOOP_SSH_OPTS="-p해당하는 포트번호"
export YARN_SSH_OPTS="-p해당하는 포트번호"Hadoop 구성 (Configuring the Hadoop)
- 진행 노드 : hostname에 등록한 hostname으로 대체 ex) master
- 파일 위치 : ~/hadoop/etc/hadoop
각 파일마다 기본적으로<configuration>...</configuration>이 있으므로 해당 내용을 삭제한 뒤 아래 코드를 각 파일마다 전체 복사한 뒤 붙여넣기하거나<configuration>사이 코드만 복사하여 사용하시면 됩니다.
1. core-site.xml
<configuration>
<property>
<name>fs.default.name</name> # HDFS의 기본이름을 의미, URL형태로 사용, 데이터노드는 여러 작업을 진행하기 위해 반드시 네임노드의 주소를 알고 있어야 한다.
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> # 하둡에서 발생하는 임시 데이터를 저장하기 위한 공간
<value>/hadoop_tmp/hadoop/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>서버의 계정 이름</value>
</property>
<property>
<name>io.native.lib.available</name>
<value>true</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>2. hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name> # HDFS의 저장될 데이터의 복제본 개수, 이 값을 1로 하면 가상 분산 모드로 하둡을 실행, 완전 분산 모드로 하려고 하기 때문에 3으로 설정
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data1/hadoop/namenode,/data2/hadoop/namenode,/data3/hadoop/namenode</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/data1/hadoop/secondarynamenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data1/hadoop/datanode,/data2/hadoop/datanode,/data3/hadoop/datanode</value>
</property>
<property>
<name>dfs.namenode.http-address</name> # 네임노드용 웹서버의 주소값
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>200</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
<property>
<name>dfs.block.size</name>
<value>268435456</value>
</property>
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>10485760</value>
</property>
</configuration>3. yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>master:8081</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>6</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>3</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx3276m</value>
</property>
</configuration>4. mapred-site.xml
mapred-site.xml 파일은 mapred-site.xml.template 파일을 복사하여 생성합니다. 생성한 mapred-site.xml 파일에 아래 코드를 추가합니다.
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/mapred</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1638m -Xms512m -server -XX:NewRatio=8 -Djava.net.preferIPv4Stack=true</value>
<final>ture</final>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx3276m -Xms512m -server -XX:NewRatio=8 -Djava.net.preferIPv4Stack=true</value>
<final>ture</final>
</property>
<property>
<name>mapreduce.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
</configuration>- hadoop-env.sh
JAVA_HOME은 필수적으로 설정하고 그외에는 선택적인 부분입니다. Hadoop버전에 따라서 라인 번호는 다를 수 있습니다.
export JAVA_HOME=${JAVA_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_IDENT_STRING=$USER
export HADOOP_NAMENODE_OPTS="$HADOOP_NAMENODE_OPTS -Xmx24576m"
export HADOOP_DATANODE_OPTS="$HADOOP_DATANODE_OPTS -Xmx4096m"Hadoop Folder 생성
- 진행 노드 : master
- 위치
/data1/hadoop/datanode, /data1/hadoop/namenode, /data1/hadoop/secondarynamenode/data2/hadoop/datanode /data2/hadoop/namenode/data3/hadoop/datanode /data3/hadoop/namenode/hadoop_tmp/hadoop/logs /hadoop_tmp/hadoop/pids /hadoop_tmp/hadoop/tmp
cd /
sudo mkdir -p /data1/hadoop/datanode, /data1/hadoop/namenode, /data1/hadoop/secondarynamenode
sudo mkdir -p /data2/hadoop/datanode /data2/hadoop/namenode
sudo mkdir -p /data3/hadoop/datanode /data3/hadoop/namenode
sudo mkdir -p /hadoop_tmp/hadoop/logs /hadoop_tmp/hadoop/pids /hadoop_tmp/hadoop/tmp
sudo chmod -R 777 /data1/hadoop/
sudo chown -R zumse.root /data1/hadoop/
sudo chmod -R 777 /data2/hadoop/
sudo chown -R zumse.root /data2/hadoop/
sudo chmod -R 777 /data3/hadoop/
sudo chown -R zumse.root /data3/hadoop/
sudo chmod -R 777 /hadoop_tmp/hadoop/암호가 없는 SSH 설정(Setup passphraseless ssh)
- 진행 노드 : master
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa; \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys; \
chmod 0600 ~/.ssh/authorized_keys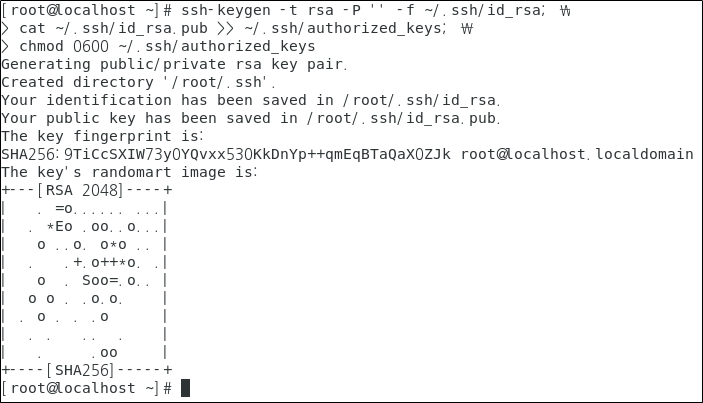
배포
- 진행 노드 : master
배포를 진행하기 전에 배포할 서버의 IP를 체크합니다. 그 후 scp를 사용하여 파일 및 폴더를 해당 서버에 전송합니다.
- scp
master에서 slave01,slave02,slave03으로 전송하는 것으로 master에서 둘 다 실행하시면 됩니다.
# slave01 ~/로 전송
scp -r ~/.ssh (계정)@slave01:~/
# slave02 ~/로 전송
scp -r ~/.ssh (계정)@slave02:~/
# slave03 ~/로 전송
scp -r ~/.ssh (계정)@slave03:~/ - Hadoop
master에서 slave01,slave02,slave03로 전송하는 것으로 master에서 둘 다 실행하시면 됩니다.
# slave01 ~/로 전송
scp -r ~/hadoop (계정)@slave01:~/
scp -r /data1 (계정)@slave01:/
scp -r /data2 (계정)@slave01:/
scp -r /data3 (계정)@slave01:/
scp -r /hadoop_tmp (계정)@slave01:/
# slave02 ~/로 전송
scp -r ~/hadoop (계정)@slave02:~/
scp -r /data1 (계정)@slave02:/
scp -r /data2 (계정)@slave02:/
scp -r /data3 (계정)@slave02:/
scp -r /hadoop_tmp (계정)@slave02:/
# slave03 ~/로 전송
scp -r ~/hadoop (계정)@slave03:~/
scp -r /data1 (계정)@slave03:/
scp -r /data2 (계정)@slave03:/
scp -r /data3 (계정)@slave03:/
scp -r /hadoop_tmp (계정)@slave03:/
Hostname 설정
- 진행 노드 : master, slave01, slave02, slave03
- 명령어 : hostnamectl set-hostname [변경할 Hostname]
각 서버에서 Hostname을 변경해줍니다. 변경된 호스트 이름은 'hostname'을 입력하시면 출력됩니다.
# master 서버에서 실행
hostnamectl set-hostname master
# slave01 서버에서 실행
hostnamectl set-hostname slave01
# slave02 서버에서 실행
hostnamectl set-hostname slave02
# slave03 서버에서 실행
hostnamectl set-hostname slave03 Host 설정
- 진행 노드 : master, slave01, slave02, slave03
- 파일 : /etc/hosts
- 형식 : [IP Address][Hostname]
Hadoop을 실행할 모든 서버를 설정합니다. 각 서버에서 작성하거나 한 서버에서 작성 후 scp를 이용하여 전송해도 됩니다.
192.168.137.130 master
192.168.137.131 slave01
192.168.137.132 slave02
192.168.137.132 slave03slaves
- 진행 노드 : master
- 파일 : ~/hadoop/etc/hadoop/slaves
slaves에 등록된 host는 datanode로 실행됩니다.
slave01
slave02
slave03Hadoop 시작
- 진행 노드 : master
- 파일시스템 포맷
# 네임노드 초기화
hadoop namenode -format- Hadoop 시작
시작하면 진행 과정이 출력되는데 이 때, namenode / datanode / secondarynamenode / resourcemanager / nodemanager 등 이 잘 실행되는지 확인합니다.
cd ~/hadoop/sbin
./start-all.sh- 확인
서버마다 역할을 어떻게 나눠서 구성했는지에 따라 다르지만, 이 글을 보고 구성한 경우 아래와 같이 확인되면 됩니다.
jps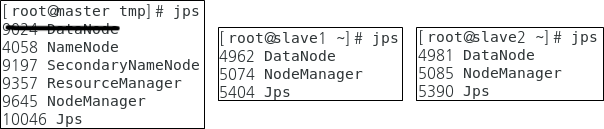
Hadoop 종료
- 진행 노드 : master
start-all.sh 실행 중 오류가 발견되었거나 종료하고 싶은 경우 아래 명령을 통해 Hadoop을 종료합니다.
stop-all.shHadoop 오류
ssh: connect to host master port 22: No route to host
- /etc/hosts 파일 수정을 잘못한 경우 ( master, slave01, slave02, slave3 모두 해당 )
NameNode / DataNode가 올라오지 않는 경우
- 모든 서버에 namenode, datanode를 삭제한 뒤 재생성 후 Hadoop 시작
sudo rm -rf /data1/hadoop/datanode /data1/hadoop/namenode /data1/hadoop/secondarynamenode
sudo mkdir /data1/hadoop/datanode /data1/hadoop/namenode /data1/hadoop/secondarynamenode
sudo chmod -R 777 /data1/hadoop/
sudo chown -R (계정).root /data1/hadoop/
sudo rm -rf /data2/hadoop/datanode /data2/hadoop/namenode
sudo mkdir /data2/hadoop/datanode /data2/hadoop/namenode
sudo chmod -R 777 /data2/hadoop/
sudo chown -R (계정).root /data2/hadoop/
sudo rm -rf /data3/hadoop/datanode /data3/hadoop/namenode
sudo mkdir /data3/hadoop/datanode /data3/hadoop/namenode
sudo chmod -R 777 /data3/hadoop/
sudo chown -R (계정).root /data3/hadoop/
sudo rm -rf /hadoop_tmp
sudo mkdir /hadoop_tmp
sudo mkdir /hadoop_tmp/hadoop
sudo mkdir /hadoop_tmp/hadoop/logs /hadoop_tmp/hadoop/pids /hadoop_tmp/hadoop/tmp
sudo chmod -R 777 /hadoop_tmp/hadoop
# Hadoop 시작
start-all.shmain class information unavailable
- /tmp 경로아래 hsperfdata_root/ 폴더를 삭제한뒤 Hadoop 재시작
부록
Jobhistoryserver 기동
hadoop2는 yarn을 위한 Web interface 외에도 mapreduce job의 이력만 별도로 볼수 있는 서버를 제공하고 있습니다. 하둡의 mapreduce 의 job history 를 web UI 에서 볼 수 있는 19888 포트에 접속하기 위해선 job history process 를 실행시켜야 합니다.
cd $HADOOP_HOME/sbin
./mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /home/hadoop/hadoop-2.10.1/logs/mapred-hadoop-historyserver-hdoop1.out WebAppProxyServer 기동
그 다음에는 WebAppProxyServer를 실행 합니다. ProxyServer가 실행되고 있지 않으면 Web interface에서 Application Master 관련 페이지에 접근할 수 없습니다.
cd $HADOOP_HOME/sbin
./yarn-daemon.sh start proxyserver
starting proxyserver, logging to /home/hadoop/hadoop-2.10.1/logs/yarn-hadoop-proxyserver-hdoop1.out
Data Engineer