1. Glue Catalog + External Table (Hive-style partition)
예시 이벤트
{
"event_source": "app",
"event_type": "click",
"server_time_kst": "2026-01-13 12:26:38",
"year": 2026,
"month": 1,
"day": 13,
"hour": 12
}1-1. 테이블 정의
CREATE EXTERNAL TABLE events (
event_source string,
event_type string,
server_time_kst timestamp,
...
)
PARTITIONED BY (
event_source string,
event_type string,
year int,
month int,
day int,
hour int
)
LOCATION 's3://log-bucket/events/';1-2. 실제 S3 디렉토리 구조
s3://log-bucket/events/
└── event_source=app/
└── event_type=click/
└── year=2026/
└── month=1/
└── day=13/
└── hour=12/
├── part-0001.parquet
├── part-0002.parquet-
디렉토리 = 파티션
-
Glue Catalog는 “이 디렉토리가 존재한다”는 메타데이터만 알고 있음
- Glue Catalog External Table의 파티션 정보를 Glue Catalog 자체 메타스토어(DB)에 “파티션 row”로 갖고 있음
-
Glue Metastore에 저장되는 값들
- Glue Metastore 안의 파티션(Partition) 정보는 아주 구체적인 S3 주소를 담고 있는 메타 정보
- 예시) Glue에 저장된 파티션 정보 year=2026/month=01을 뜯어보면 내부는 이렇게 생김 (JSON 형태 비유)
{ "PartitionValues": ["2026", "01"], // 파티션 값 (이름표) "StorageDescriptor": { "Location": "s3://my-bucket/data/year=2026/month=01/", // 👈 여기에 실제 주소가 있습니다! "InputFormat": "org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat", // 파일 형식 "Columns": [...] // 컬럼 정보 } }
1-3. 쿼리 & 스캔 플랜
-
Query
SELECT * FROM events WHERE event_source = 'app' AND event_type = 'click' AND year = 2026 AND month = 1 AND day = 13 AND hour = 12; -
Scan Planning
1. Glue Catalog에서 파티션 목록 조회
2. 조건에 맞는 파티션 디렉토리 1개 선택
3. 해당 디렉토리 아래 모든 parquet 파일 스캔S3 API ListObjects를 호출해서/year=2026/month=01...폴더 아래에 무슨 파일이 있는지 일일이 네트워크 요청을 보내 파일 목록을 가져옴 (파일이 많으면 여기서 시간 엄청 걸림)
1-4. 문제점
- hour=12 디렉토리에 이런 파일이 있다면?
part-0001.parquet (12:00 ~ 12:10)
part-0002.parquet (12:10 ~ 12:20)
part-0003.parquet (12:20 ~ 12:59)- server_time_kst BETWEEN '12:26' AND '12:27' 같은 조건도 모든 파일을 다 열어야 함
2. Iceberg Table
2-1. 테이블 정의
CREATE TABLE iceberg_events (
event_source string,
event_type string,
server_time_kst timestamp,
...
)
USING iceberg
PARTITIONED BY (
event_source,
event_type,
hours(server_time_kst)
);- year/month/day 컬럼 없음
- 파티션은 논리 개념, 디렉토리와 1:1 아님
2-2. 실제 S3 디렉토리 구조
s3://warehouse/iceberg_events/
├── metadata/
│ ├── v1.metadata.json
│ ├── snap-00001.avro
│ └── manifest-list.avro
└── data/
├── 00000-abc.parquet
├── 00001-def.parquet
├── 00002-ghi.parquet- 디렉토리 이름에 파티션 값 없음
- 파티션 정보는 metadata/manifest에만 존재
2-3. Iceberg 메타데이터 내부
| 파일 | event_source | event_type | server_time_kst_hour | min_ts | max_ts |
|---|---|---|---|---|---|
| 00000 | app | click | 491387 | 12:00 | 12:10 |
| 00001 | app | click | 491388 | 12:10 | 12:20 |
| 00002 | app | click | 491389 | 12:20 | 12:59 |
- 파일 단위 통계(min/max)를 Iceberg가 알고 있음
- (min_ts, max_ts) 쌍은 “한 parquet 데이터 파일”을 대표
server_time_kst_hour = floor(epoch_millis / (1000 * 60 * 60))1970-01-01 00:00 UTC = 0 2026-01-13 12:26 KST ≈ 491387
- 구조를 단순화 하면
Snapshot
└── Manifest list
└── Manifest file
├── Data file #1
│ ├── path = s3://.../00001.parquet
│ ├── partition = (event_source=app, event_type=click, hour=491387)
│ ├── min_ts = 2026-01-13T03:26:13
│ ├── max_ts = 2026-01-13T03:26:38
│ └── record_count = 10,234
├── Data file #2
│ ├── path = s3://.../00002.parquet
│ ├── min_ts = ...
│ └── max_ts = ...- 실제 데이터
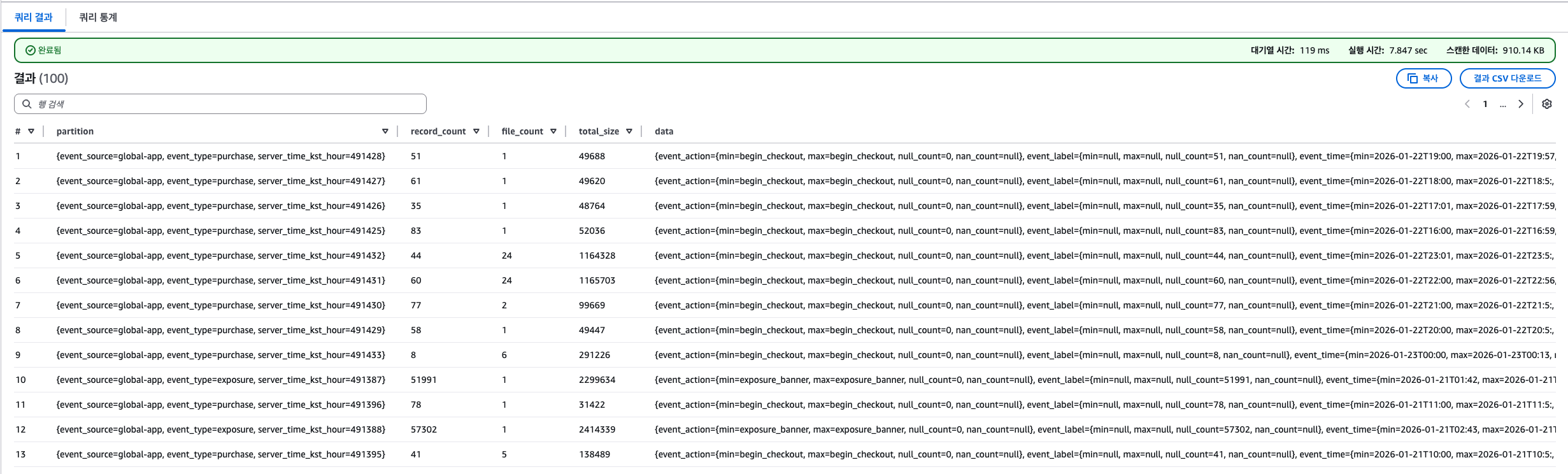
- record_count: 해당 파티션에 존재하는 전체 레코드(row) 수
- fire_count: 해당 파티션에 포함된 data file(= parquet 파일) 개수
- iceberg는 쓰기 단위 = 파일
- 병렬 처리 + streaming merge 때문에 같은 파티션에 여러 파일이 생길 수 있음
2-4. 동일 쿼리 실행
SELECT *
FROM iceberg_events
WHERE
event_source = 'app'
AND event_type = 'click'
AND server_time_kst BETWEEN
'2026-01-13 12:26:00'
AND '2026-01-13 12:27:00';2-5. Iceberg 스캔 플랜
1. Snapshot 선택
2. Manifest 파일 스캔
3. 조건에 맞는 파일만 선택
플래너의 분석
→ 사용자가 server_time_kst 컬럼을 14시 범위로 조회했네?
→ 메타데이터를 보니, 파티션 키가 HOUR(server_time_kst)로 정의되어 있군
범위 변환 (Transform)
→ 오케이, 2026-01-22 14:00은 Iceberg 시간 ID로 **491405**번이야.
→ 그럼 나는 partition.server_time_kst_hour = 491405인 파일만 찾으면 돼.
메타데이터 조회 (Manifest Scan)
→ 매니페스트 파일(Metadata) 조회
→ 매니페스트 파일 안에는 min_value, max_value 등의 통계 정보가 있어서,
해당 파티션 ID(491405)를 가진 파일 목록(0001-xyz.parquet)을 즉시 리턴
4. 결과
→ 사용자가 쿼리를 복잡하게(year=...) 쓸 필요 없음.
→ S3 ListObjects 비용 발생 안 함.- 파티션 프루닝 (논리 파티션)
- 파일 프루닝 (min/max 통계)
- 디렉토리 구조와 무관

Data Engineer