Iceberg
1.Icerberg 정리

Iceberg Spec — Overview & Terminology Overview Iceberg 테이블 스펙은 다음과 같은 목적과 기본 특징을 갖습니다: 대규모, 느리게 변하는 파일들의 모음을 분산 파일 시스템 또는 키-값 저장소에 테이블 형태로 관리하기 위해 설계됨. oai_citation:0‡Iceberg 포맷 버전(format version)...
2.Iceberg (partition, scheme evolution)
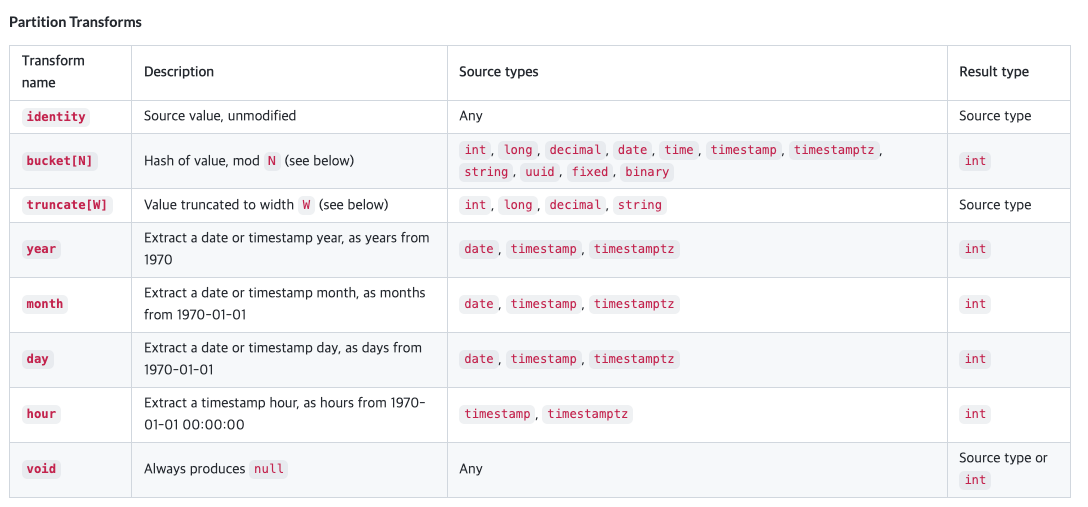
Hive 테이블은 파티셔닝을 변경 X 따라서 파티션을 변경하려면 새로운 테이블을 만들어야하고 그에 따른 쿼리 재작성도 필수로 불편함이 따른다.Iceberg는 Partitioning Evolution 및 Schema Evolution을 제공하여 Hive에서의 불편함을 해
3.Iceberg (hidden partitioning)
hive 테이블은 쿼리 속도를 향상시키기 위해 파티셔닝을 사용"event_date"와 같은 파티션 컬럼이 추가되며 Insert할 때도 변환이 필요해 불필요한 작업이 늘어난다.파티션 컬럼을 적어야만 Full Scan을 하지않고 데이터를 가져온다.쿼리는 파티션에 의존적이고
4.Iceberg (Time Travel)
소개아이스버그 기능인 Time Travel기능에 대해서 살펴보자.데이터를 Create or Delete 시 Snapshot이 만들어지는데 이것을 이용해 과거 데이터로 롤백할 수 있다.Partition이 변경되는 부분은 기록이 안되는 것 같다.간단한 기능 실습을 해보자.
5.Iceberg (Merge on read, Copy on write)
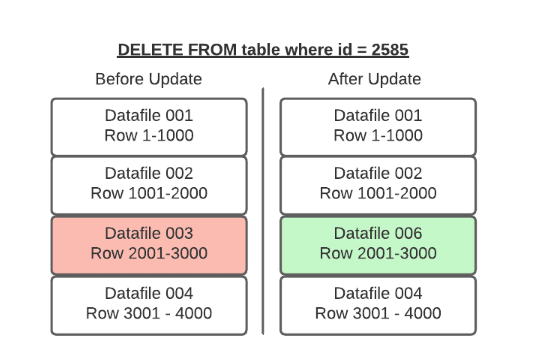
소개아이스버그 마지막으로 볼 기능인 MOR & COW 이다.빅데이터를 다루는데 Update를 지원한다는 건 모든 ACID 트랜잭션을 지원한다는 것이다.물론 OLTP 보다는 성능이 떨어지겠지만 OLAP에서 구현했다는 것에 대한 의미가 있다고 본다.COW는 "읽기가 자주
6.Shuffle-less joins (Storage Partitioned Joins)

https://www.guptaakashdeep.com/storage-partition-join-in-apache-spark-why-how-and-where/
7.Iceberg MERGE 최적화
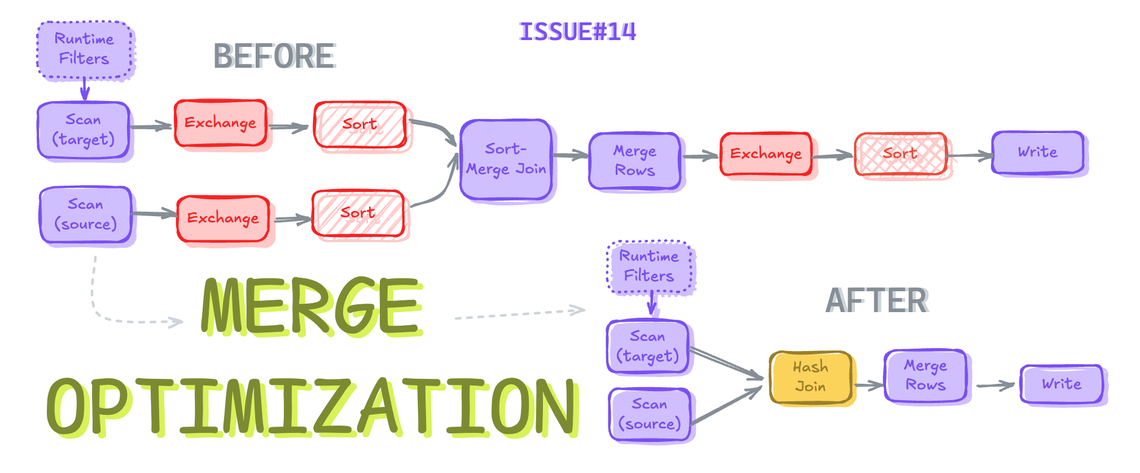
https://www.guptaakashdeep.com/optimizing-iceberg-merge-statements/
8.Kinesis → S3 → Glue 외부 테이블 구조에서의 append-only 방식
S3는 객체 단위로 데이터를 저장하며, 한 번 저장된 객체를 수정하거나 일부만 삭제하는 것이 불가능 따라서 데이터를 수정하려면 전체 객체를 새로 업로드해야함이러한 특성으로 인해 데이터를 추가하는 방식(append-only)이 자연스럽고 효율적Kinesis는 실시간 스트
9.Iceberg Maintenance
Iceberg maintenance——————————————————————————————————————————————————————————————————Snapshot을 retain_last =2 로 지정해야 하는 이유예시 시나리오현재 최신 스냅샷이 CALL syste
10.Iceberg distribution-mode
Partition과 write.distribution-mode은 많이들 헷갈리기 쉬운 개념이라 이 둘의 차이와 실제 동작 방식을 Spark 예시와 함께 정리Partition은 테이블 데이터를 어떤 키 기준으로 나눌지를 정의위와 같이 정의하면 Iceberg는 ts를 일(
11.Iceberg Scan Planning, Optimistic Concurrency, Sequence Numbers
Iceberg에서 스캔 계획은 현재 스냅샷의 매니페스트 파일(manifest file)을 읽는 것으로 시작 여기서 status = DELETED로 표시된 엔트리는 스캔에서 사용되지 않는다.Manifest 필터링매니페스트에 조건에 맞는 파일이 없으면 (파일 개수나 파티
12.Iceberg delete mode
Iceberg v3에서 새로 추가된 방식으로, 특정 데이터 파일의 삭제된 행을 비트맵(bitmap)으로 표현데이터 파일 내부에서 어떤 행이 삭제되었는지 0/1 형태로 표시하므로, 쿼리 시 해당 비트맵만 확인하면 삭제 여부를 빠르게 판별할 수 있다.Puffin 파일 포맷
13.Fan-out
하나의 입력(source) 을 여러 개의 출력(destination) 으로 나누는 동작입력하나의 Kinesis Stream출력Firehose AFirehose BLambda CStream 하나에서 여러 소비자(Consumer)로 데이터를 나눠주는 동작이 바로 fan-o
14.Iceberg compaction
https://justkode.kr/data-engineering/iceberg-table-optimization-1/
15.Iceberg Scan & Pruning 구조 정리
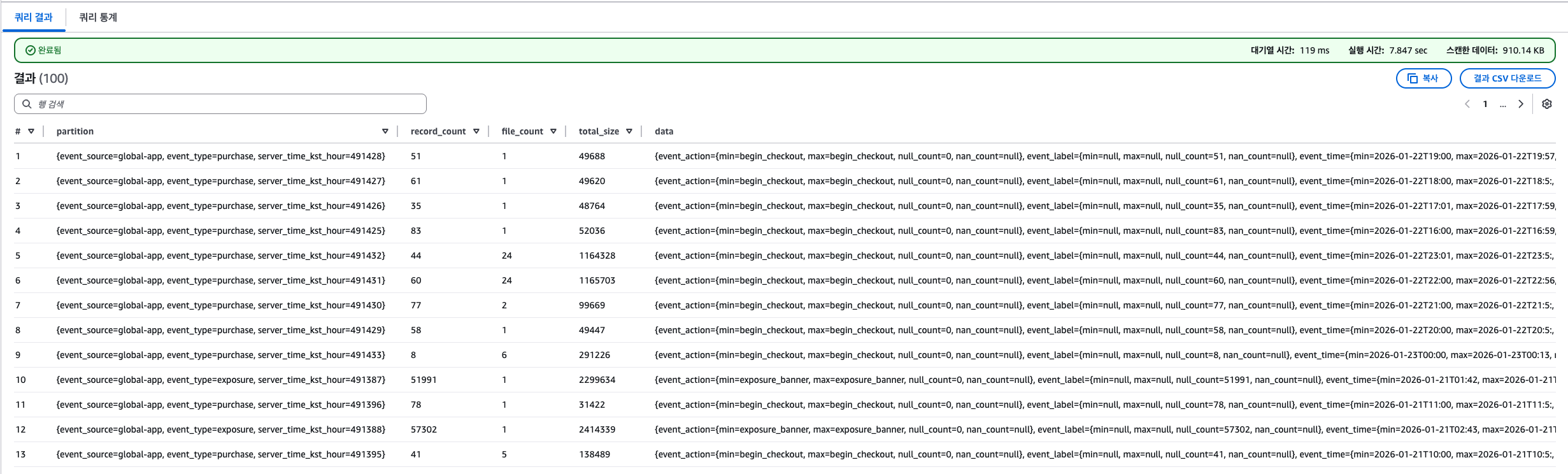
예시 이벤트디렉토리 = 파티션Glue Catalog는 “이 디렉토리가 존재한다”는 메타데이터만 알고 있음Glue Catalog External Table의 파티션 정보를 Glue Catalog 자체 메타스토어(DB)에 “파티션 row”로 갖고 있음QueryScan Pl