Filebeat의 사용 여부
요즘 ELK를 구축하는 방법을 찾아보면 각 서버에 Filebeat를 통해 로그 데이터를 수집하고 logstash로 보내 데이터를 가공하고, ES로 보내는 방법을 많이 사용하고 있다.
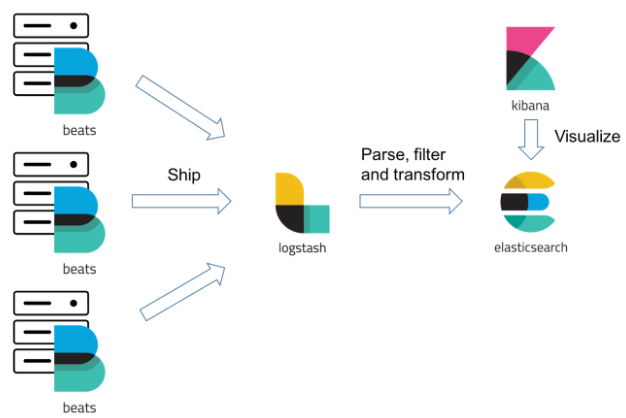
로그 수집하는 역할을 logstash 대신 beats를 쓰는 이유
- logstash는 자원이나 메모리 부분에서 무겁다. 각 서버마다 Logstash를 사용한다면 각 서버에 리소스나 메모리가 소모 될 것이다. 이를 FIlebeat를 통해 서버의 성능을 유지하며 데이터를 수집하고, 하나의 logstash가 데이터 가공을 하는 구성이다.
logstash 하나로 많은 로그 데이터를 견딜 수 있나?
엄청난 로그 데이터가 쌓이면 logstash가 당연히 버틸 수 없다. 그렇기 때문에 beat와 logstash 사이에 kafka를 사용한다.
Kafka
- Pub-Sub 모델을 가지는 분산 메시징 플랫폼
- 기존 메시징 시스템처럼 Broker 가 Consumer 에게 직접 메시지를 전송하는 방식이 아니다.
- Kafka 는 Consumer 가 Broker 로부터 직접 메시지를 가져가는 방식이다.
- Producer - 메시지 발행 ex) filebeat
- Consumer - 메시지 구독 ex) logstash
- Broker - Kafka 서버
결론
docker을 이용한 ELK를 구축하여 로그데이터를 수집했을 때 Logstash의 역할은 데이터를 Json으로 변환하여 ES에 전송하는 역할 뿐이였다.
이러한 역할만 한다면 Logstash보다 경량화된 로그 수집 프로그램인 Filebeat가 더 최적화 된다고 생각하였다. 그러나 동접 모니터링, 에러 알람 서비스, 패치 시 에러 필터링 등을 구현하려면 로그 데이터의 가공이 필요한데 이러한 부분은 Filebeat로 할 수 없는 기능이였다.
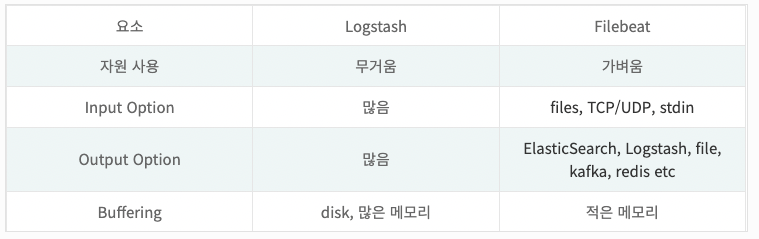
만약 단순 로그 수집 시스템을 구축한다면 logstash보다 Filebeat가 더 효율적이다.
그러나 데이터의 가공이 필요하다면 Logstash가 더 좋은 대안이 될 것이다.
참고

Data Engineer