Spark에서 Shuffle이 일어나는 이유, 언제 일어나는 지
1. Shuffle이 일어나는 이유
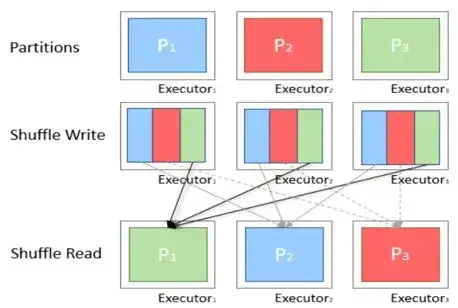
- 파티션 사이에서 데이터가 재배치 되어야 할 때
- 특정 transforamtion 실행 시 다른 파티션에서 정보가 필요하기 때문에 셔플을 함으로써 정보를 찾음
2. shuffle은 언제 일어나는 지
- join, union, groupBy, sort, coalesce, repartition, aggregate 과 같이 파티션과 관련된 조작이 있을 때
- 즉, MapReduce의 reduce()에 해당하는 operation을 실행하기전에 물리적인 데이터의 이동이 있어야 하기 때문에 shuffle이 일어난다.
- ex) 컬럼의 모든 값을 더할 때
shuffle spill(memory)란? shuffle spill(disk)란?
1. shuffle spill이란?
데이터를 직렬화하고 스토리지에 저장, 처리이후에 역직렬화하여 연산 재개하는 행위
data를 shuffle할 때 자원이 충분하지 못할 때 발생
-> partition size는 크지만 연산에 쓰이는 memory가 부족할 때
- shuffle spill(memory):
spill될 때 메모리에서 역직렬화된 형태의 데이터 크기 - shuffle spill(disk):
spill된 이후 디스크에서 직렬화된 형태의 데이터 크기 - 역직렬화된 데이터가 직렬화된 데이터보다 공간을 더 많이 차지하므로 spill된 크기도 큼
- input data가 클 때 spill memory size도 커짐
2. shuffle spill이 성능에 미치는 영향
- Task가 지연되고, 에러가 발생
- Hadoop 클러스터의 사용률이 높다면, 연달아 에러가 발생되고 최악의 경우에는 Spark가 강제종료
3. Shuffle spill을 방지 하는 방법
- 쿼리 최적화(skew 현상 제거),
1) 필요한 쿼리만select or wide transformation 전에 조건 연산자 추가 - Partition 수 증대 -> partition 크기 감소
- core당 메모리 양 증가
Shuffle Partition 수 최적화
관련 config: Spark.sql.shuffle.partitions
- Spark 성능에 가장 크게 영향을 미치는 Partition으로, Join,groupBy 등의 연산을 수행할 때 Shuffle Partition이 쓰임
- join, groupBy와 같은 연산을 수행 시 Partition의 수(Task 수)가 결정
Shuffle Partition은 일반적으로 core 수 = partition 수 라고는 되어 있지만,
1. core의 2~3배 숫자를 지정하는 것이 적합,
2. shuffle Partition 1개당 size를 100Mb ~ 200Mb 사이의 크기로 맞추어 Partition 숫자를 산정
Partition 크기를 아는 방법
Partition의 크기는 shuffle read size와 Partition 수에 따라서 결정
shuffle read size:
모든 executor에 직렬화된 읽기 데이터의 총합
Partition 크기 및 개수 최적화 예시
-
shuffle read size 240GB라 가정 partition 수가 300일 시, Partition당 크기는 800MB(partition당 읽어 들이는 양)
-
spill(memory) size가 없다면, 설정한 partition 수로 자원의 부족함 없이 task가 실행되고 있다고 봄
-
spill(memory) size가 있다면, 예를들면 spill(memory) size가 840GB라 가정하면 Partition당 spill(memory) size는 약 2.8GB~이므로 1core당 2GB 메모리의 자원으로는 수행이 불가
-
Partition당 크기를 160MB가 되도록 설정한다면, 800MB/5 = 160MB ,즉 Partition의 수는 기존 300개 보다 5배 많은 300 * 5 = 1500으로 증가
300개의 partition수 일 때 일어났던 840GB의 spill(memory) size가 Partition당 840G/1500 =약 0.5xGB~정도로 1core당 2GB는 물론, 심지어 놀고 있는 메모리가 생겨 1core당 1GB를 사용해도 가능
메모리 설정 팁
- shuffle read size + shuffle write size < executor 수 * executor당 memory 양
- Shuffle Size가 600GB에 가깝거나 그 이상일 경우, Core당 메모리를 증가시키는 것이 좋음. 또한 1코어당 4GB를 고려하기를 권장
결론:
- 총 코어의 개수보다 적은 수의 파티션 수는 일부 resource가 놀게 되므로 비효율적이다.
- 일반적으로 파티션수를 늘리는 것은 오버헤드가 너무 많아지기 전까지는 성능을 높인다(2~3배가 적당)
- 파티션을 늘리게 되면 파티션의 크기가 작아지고 각 executor에서 spark가 처리하는 partition(task)의 양이 적어지므로 메모리 부족 오류를 줄이게 된다.
- 메모리 부족 오류 및 spill size가 줄어들면 지연이 사라지고 성능이 올라간다.
- 너무 많은 파티션은 driver memory error, driver overhead error를 유발하며, 작은 사이즈의 파일들을 생성하기위한 I/O도 많이 발생한다(특히 block store)
참고
