Partition Prunning 이란?
- prunning이란 '가지치기' 라는 뜻으로 데이터 시스템에서는 얻고자 하는 데이터를 가지고 있지 않은 파일은 스킵하고 얻고자 하는 파일만 스캔하는 최적화 기법
- RDBMS의 Partition prunning과 개념적으로 동일
- Spark가 HDFS나 S3와 같은 저장소에 디렉토리와 파일을 읽을 때 지정된 파티션의 파일만 읽을 수 있도록 성능 최적화를 가능하게 함
- 파일을 파티션구조로 만드는 것이 선행되어야 함
Static Partition Prunning
아래의 사진과 같이 모든 데이터를 Scan하여 filter하는 것이 아닌, 특정 원하는 데이터만 Filter 후 데이터를 scan하는 것이 pushdown filter 혹은 predicate pushdown이라고 불림
이렇게 원하는 데이터를 선 filter후 scan하게 되면, I/O에서 좋은 성능으로 이어지게 됨
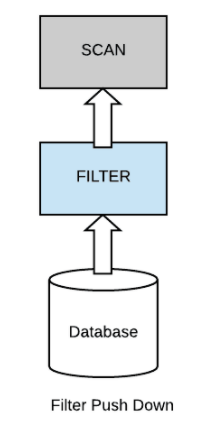
위와 같은 단일한 형태라면 static partition prunning이 사용
Dynamic Partition Prunning
- 실제 여러 기업의 데이터 환경에서는 여러 테이블간에 얽힌 관계가 많아, join이 자주 사용되는데 이럴 때 Dynamic Partition Prunning이 사용
- 런타임 시에 동적으로 생성된 Partition Prunning이 적용되도록 하는 기능
- Spark 3.0의 주요 특징중 하나
- star schema 구조에서 Broadcast Hash Join이 가능한 사이즈의 작은 dimension 테이블과 fact 테이블의 JOIN연산일 때 가장 효과적으로 적용 됨
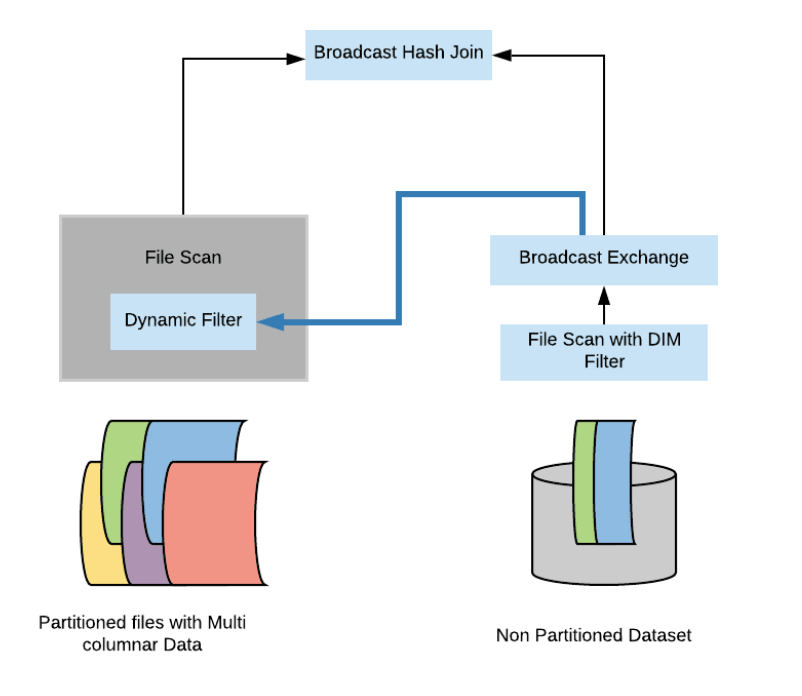
Broadcast Hash Join이란
- dimension 테이블이 충분히 작다면(충분히 작다는건 대체로 fact테이블과 비교하여 작은 것을 의미),spark는 Broadcast hash join 형태로 join을 수행하게됨
- dimension 테이블로부터 hash 테이블이 생성되고 각 노드로 distribute 됨(broadcast exchange)
- join은 셔플 없이 각 노드가 받은 hash 테이블을 가지고 fact 테이블에 대한 스캔과 처리를 진행
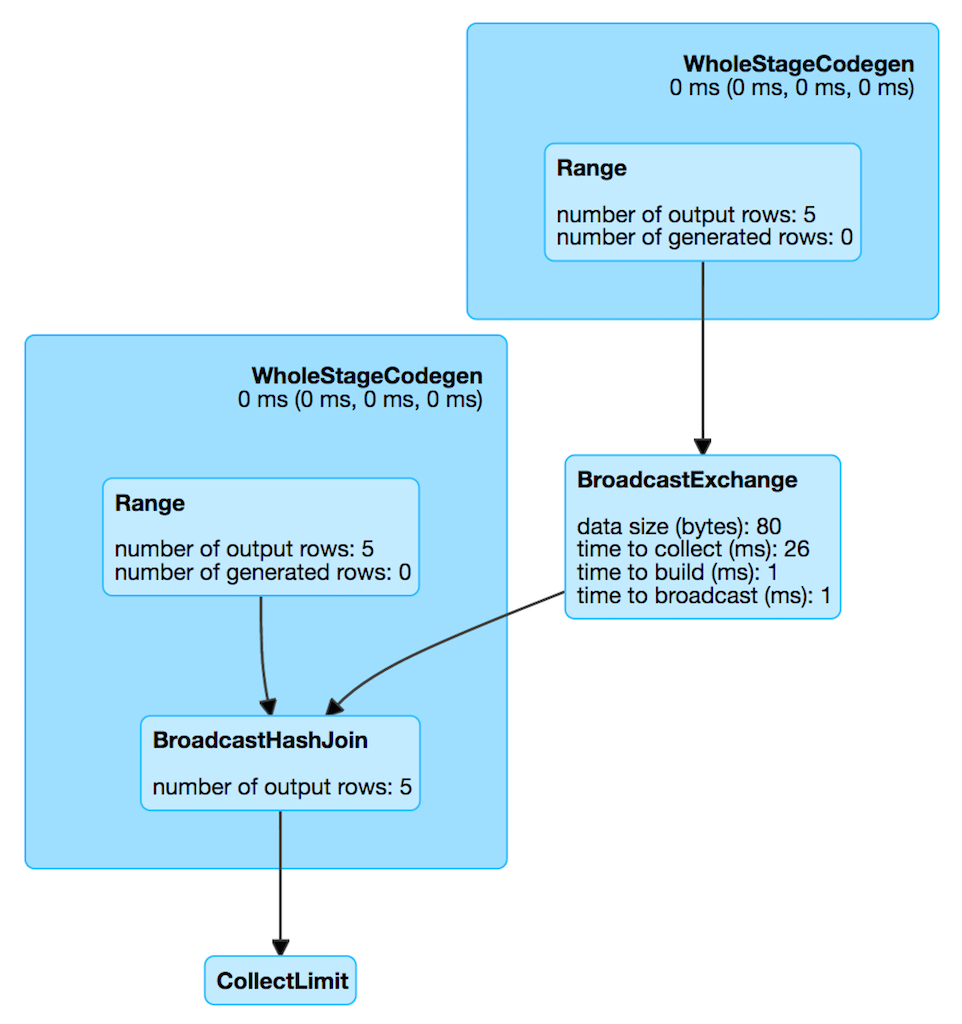
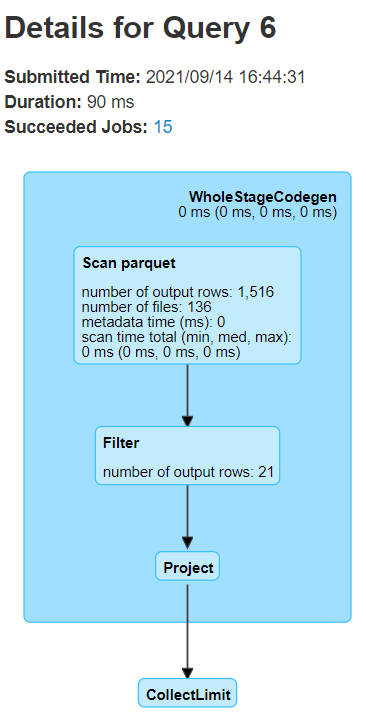
Partition Prunning 확인
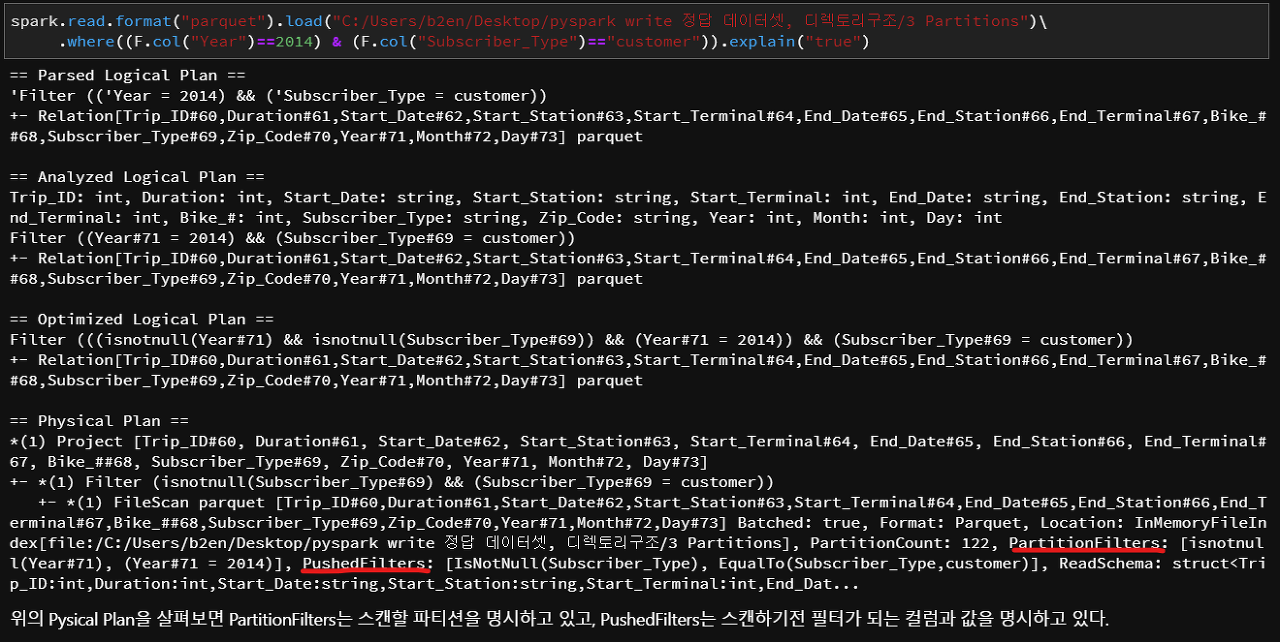
Spark에서 Partition Prunning 확인 방법
1) .explain("true") 로 physical plan을 확인
2) spark ui를 통해 확인
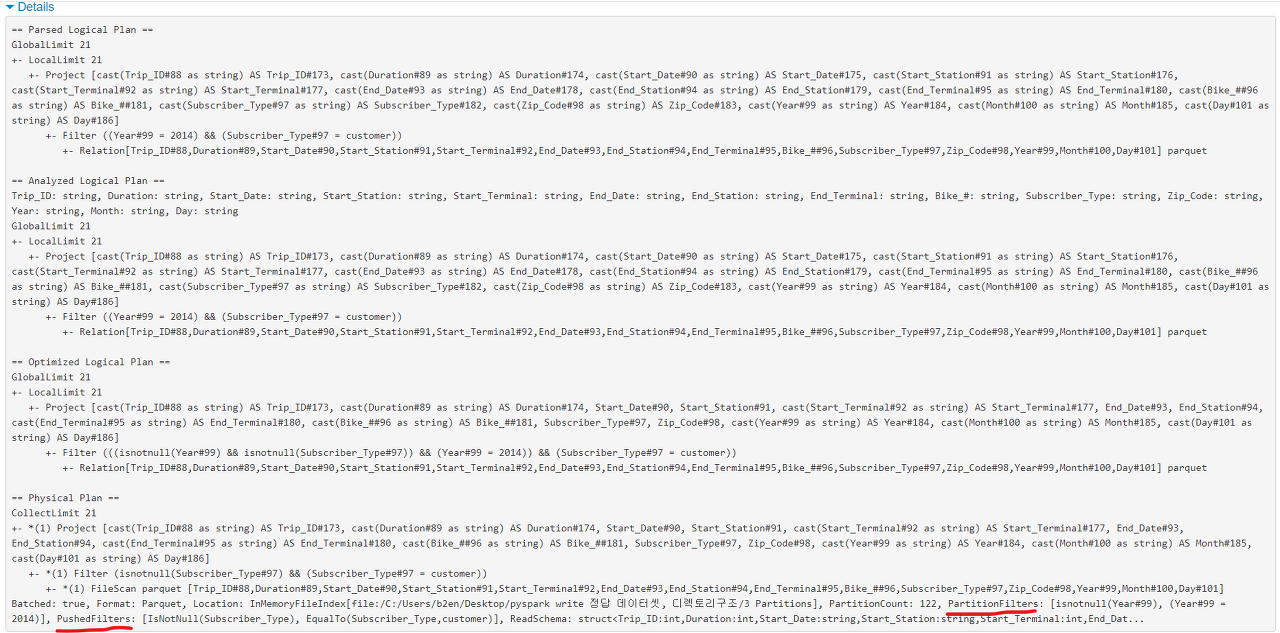
PartitionFilters
Hive Metastore에서 가져온 파티션 정보를 통해 어디에 어떤 Partition 데이터가 들어있는지 모든 디렉토리나 파일을 읽는 수고 없이 바로 지정된 파티션만 읽는데, 그 때 사용되는 파티션 정보.
PushedFilters
file에서 필요한 데이터를 filtering 하여 read하는데 partition pruning 된 것을 알 수 있는 정보
참고

Data Engineer