1. Vector DB란?
- 텍스트, 이미지, 오디오 등 임베딩 방식으로 나타낸 데이터를 저장하고, 관리하고, 검색하는 기능을 제공하는 임베딩 벡터 전용 DB.
- 고차원(벡터 차원 수)의 공간(인덱스)에 임베디드 벡터를 인덱싱하여 저장하는 방식.
- 입력 Query와 가장 가까운 이웃을 찾아주는 검색 방식. ANN(Approximate Nearest Neighbor) 검색 알고리즘에 기반한 검색 효율성 도모.
- CRUD(Create, Read, Update, Delete) 지원
- 벡터DB 서비스 제공자 마다 약간씩 다른 인덱싱, 검색 방식을 채택하여 제공.
- 모든 Vector Database는 공통적인 단계들로 (1) Indexing (2) Querying 를 따르며, 앞 뒤 사이사이에 Loading, Transforming, Post-Processing 등 검색 성능을 높이기 위한 처리작업들을 VectorDB 자체적으로 지원하는 것도 있고 따로 해줘야 하는 것들도 있음.
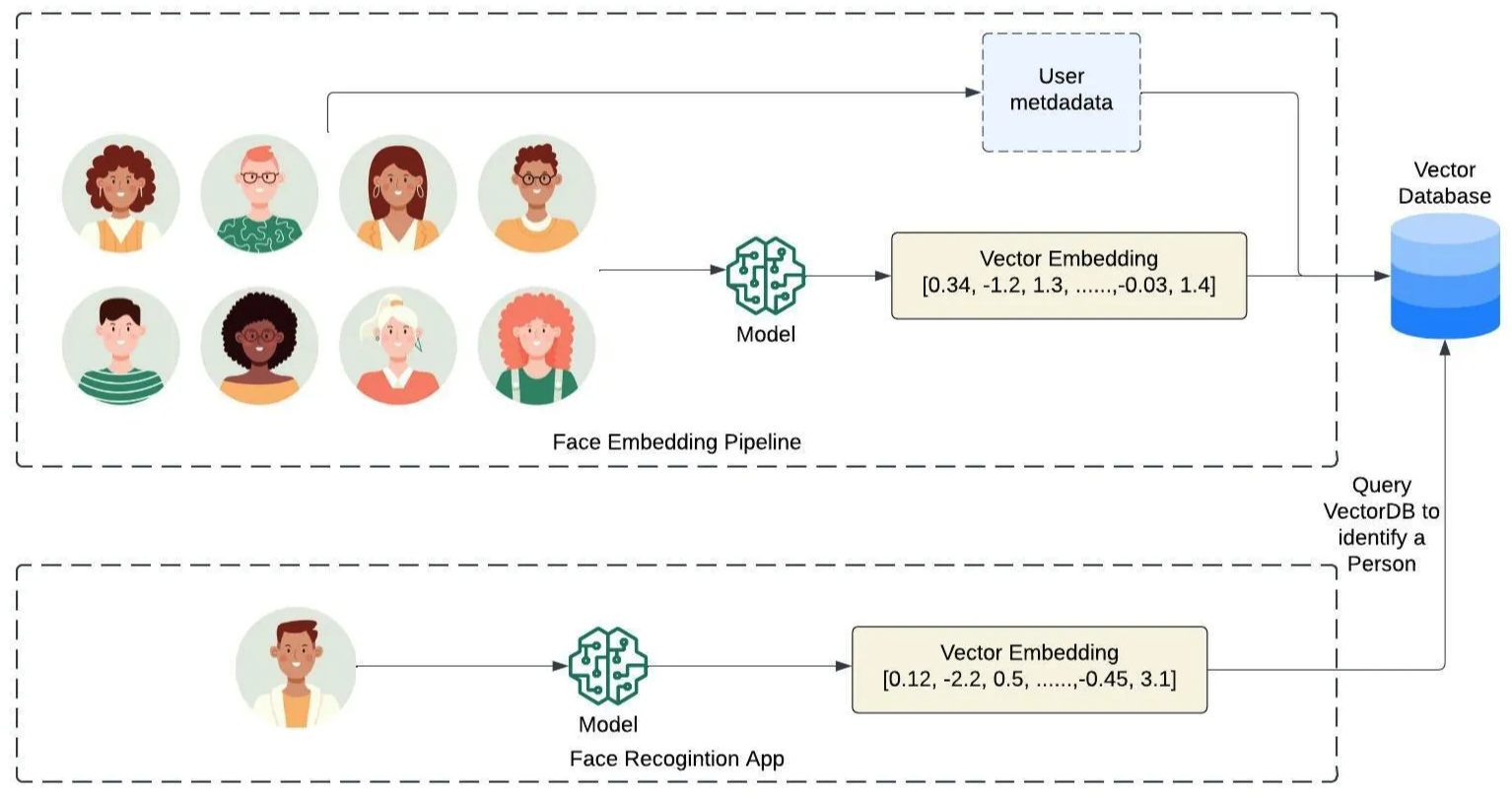
2. RDB vs VectorDB
| 기준 | RDBMS (관계형 데이터베이스) | Vector DB (벡터 데이터베이스) |
|---|---|---|
| 데이터 구조 | 테이블, 행(Row), 열(Column) 기반 | 벡터(임베딩) 기반, 고차원 공간에서 저장 |
| 데이터 타입 | 정형 데이터 (정수, 문자열 등) | 비정형 데이터 (이미지, 텍스트, 오디오의 벡터 표현) |
| 데이터 관계 | 테이블 간의 명확한 관계 (Foreign Key, Join) | 벡터 간 유사성 (코사인, L2 거리)로 관계를 파악 |
| 쿼리 방식 | SQL 사용, 정밀한 쿼리 (정확한 매칭) | 유사성 검색, 근사치 쿼리 (최근접 탐색) |
| 사용 예시 | 고객 정보, 금융 기록, 주문 내역 | 이미지 검색, 추천 시스템, 자연어 처리 모델 결과 저장 |
| 인덱스 구조 | B-Tree, Hash 인덱스 | HNSW, IVF (근사 근접 탐색 인덱스) |
| 확장성 | 수직적 확장 (주로 하드웨어 확장) | 수평적 확장에 유리, 대규모 데이터에 적합 |
| 성능 최적화 대상 | 트랜잭션 처리, 데이터 무결성 유지 | 대규모 벡터 데이터의 빠른 검색 |
| 데이터 크기 | 일반적으로 중소규모 데이터 처리 | 대규모 벡터 데이터 (수백만 ~ 수십억 차원의 벡터) |
| 주요 목적 | 데이터 정확성, 트랜잭션 관리 | 유사성 기반 검색, 대규모 비정형 데이터 관리 |
3. Vector DB vs Vector Index
3-1. Vector DB
- Vector DB는 벡터 데이터를 저장하고 검색하는 전체 시스템
- 비정형 데이터(이미지, 텍스트, 오디오 등)를 벡터로 변환하여 저장하고, 벡터 간의 유사성을 기반으로 검색 수행
- Vector DB는 벡터 데이터를 효율적으로 저장하고 빠른 검색을 가능하게 하며, 그 내부에서 Vector Index를 사용해 검색 성능을 최적화
Vector DB의 예시
- Pinecone, Weaviate, Milvus
- 추천 시스템
- 온라인 쇼핑몰에서 사용자가 상품을 클릭하면, 이 상품과 유사한 다른 상품들을 추천
- 상품의 이미지와 설명을 벡터화하여 Vector DB에 저장하고, 유사성을 기준으로 다른 상품 벡터들을 검색하여 추천
3-2. Vector Index
- Vector Index는 벡터 데이터를 효율적으로 검색하기 위한 인덱싱 기법 - Vector DB는 벡터 데이터를 저장할 뿐만 아니라, 검색 시 성능을 높이기 위해 내부적으로 Vector Index를 사용
- 벡터 간의 거리를 계산해, 가장 유사한 벡터를 빠르게 찾을 수 있게 해준다.
Vector Index의 예시
- Faiss, Annoy, ScaNN
- Faiss: Facebook AI에서 만든 라이브러리로, 대규모 벡터 데이터를 GPU로 가속해 빠르게 검색
- Annoy: Spotify에서 개발한 라이브러리로, 메모리 기반 트리 구조를 사용하여 벡터 간 유사성을 빠르게 검색
- 음악 추천 시스템
- 사용자가 좋아하는 노래와 유사한 노래를 찾고 싶을 때, 노래의 특징을 벡터로 변환하여 Vector Index를 사용해 유사한 벡터들을 검색
- Annoy는 Spotify의 음원 추천 시스템에서 사용되었으며, 노래의 벡터 간 유사성을 빠르게 계산한다.
3-3. 온라인 쇼핑몰에서의 이미지 검색
Vector DB의 역할
- 쇼핑몰에서 사용자가 이미지를 업로드해 유사한 제품을 찾고 싶다고 가정
- 사용자가 업로드한 이미지는 이미지 임베딩 모델을 통해 벡터로 변환
- 변환된 임베딩 벡터로 Vector DB에 저장되어 있는 다른 상품 이미지 벡터와 비교되어 유사한 이미지를 찾는다.
- Vector DB는 벡터 데이터를 저장하고, 이를 효율적으로 검색할 수 있게 관리
Vector Index의 역할
- Vector DB에서 검색할 때, 모든 벡터와 비교하면 시간이 너무 오래 걸리기 때문에 Vector Index를 사용해 검색 속도를 높인다.
- 예를 들어, Faiss는 IVF(Inverted File Index)를 사용해 데이터셋을 여러 클러스터로 나누고, 사용자가 찾고자 하는 이미지 벡터와 가장 가까운 클러스터에서만 검색을 수행해 속도를 극대화.
- Annoy는 트리 기반 인덱스를 사용해, 트리를 빠르게 탐색하며 가까운 벡터를 찾는다.
4. Indexing 이란?
- 데이터베이스에 벡터 데이터를 구조화된 인덱스에 담는 행위
- 추후 검색 성능을 고려하여 KNN이 아닌, ANN(Approximate Nearest Neighbor) 가능한 구조로 보통 설계
- GOAL : 검색 정확도 <-> 검색 속도 tradeoff 관계 최적화
5. Indexing Structure
- Vector Embedding을 어떤 구조로 저장할 것인지
5-1. Hash Index
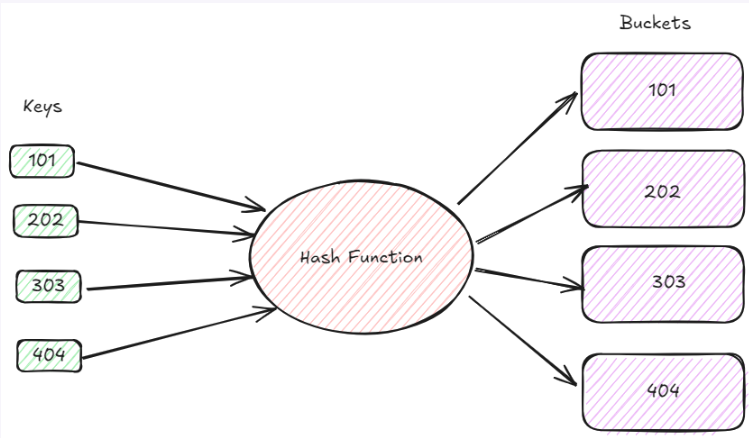
- 고차원 데이터를 저차원 해시코드로 변환하여 서칭컴플렉시티 개선을 노리는 방식
- 일반적 해싱과 반대로, 벡터 인덱싱 시 비슷한 데이터끼리 해시충돌이 나도록 하는 구조
- 이때 사용되는 해싱함수를 그대로 쿼리 벡터에 대해서도 적용시켜 동일한 해시버킷에 위치한 벡터들에 대해서만 거리계산 수행
- LSH(Locally Sensitive Hashing) 등이 여기에 해당
장점: 검색 속도가 매우 빠르다
단점: 검색 정확도가 좋지 않다
5-2. Tree Index
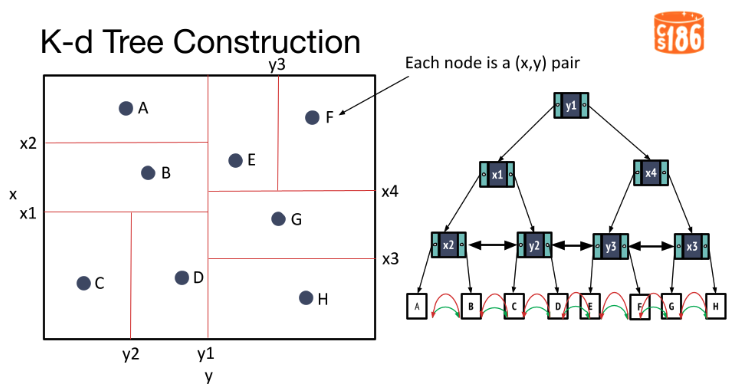
- Binary Search Tree 구조를 사용하여 고차원 벡터 공간에서의 검색 속도 향상을 도모하는 방식
- 유사한 벡터들이 같은 서브트리 노드(혹은 공간)에 속하도록 하는 구조
- 검색 시 해시버킷과 유사하게 쿼링 벡터가 속하는 서브트리 노드에 존재하는 다른 벡터들간의 거리만 계산하여 검색 속도 최적화가 이루어짐
- Spotify Annoy 알고리즘이 여기에 해당
장점: 검색 속도가 매우 빠르다
단점: 고차원 벡터에 대해서는 검색 정확도가 좋지 않다
5-3. Inverted File(IVF) Index
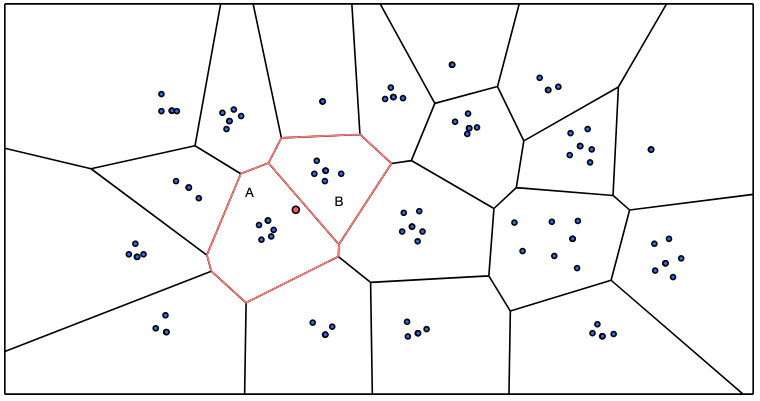
- 벡터 공간을 보로노이 다이어그램이라고 하는 n개의 공간으로 나누어서 서칭스페이스를 줄이는 효과를 도모하는 방식
- 군집화 하는 효과와 유사
- 쿼리 벡터에 대해 유사 벡터 검색 시, 벡터 to 벡터 대신 보로노이 다이어그램별 Centroid 포인트들의 좌표와 거리 계산을 하여 가장 가까운 centroid가 해당하는 공간 내 임베딩 벡터들과 거리계산을 하는 구조
장점: 검색 속도가 매우 빠름
단점: 공간을 형성하는 벡터가 많을수록 공간 나누는 작업의 속도가 느려짐
5-4. Graph Index
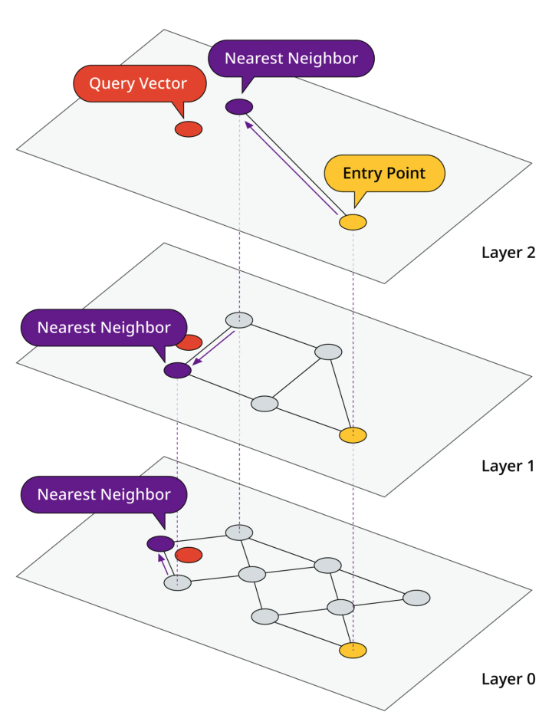
- 임베딩 벡터들을 그래프 구조로 구조화하여 임베딩 벡터를 노드로, 연결되는 엣지를 벡터간(노드간) 거리로 표현
- 유사한 벡터끼리 엣지 커넥션이 더 잘 이루어 지도록 설계
- HNSW(Hierarchical Navigable Small World)와 같은 알고리즘들이 여기에 해당
- 여러 계층으로 그래프 제작
- 가장 밀도가 낮은 계층에서 랜덤한 노드로 시작하여, 해당 계층에서 가장 가까운 노드를 찾은 후 다음 계층으로 이동
- 최종적으로 원래 쿼리 벡터노드와 가장 가까운 이웃을 찾을 때 까지 계층 탐색
장점: 검색 속도도 빠르고 검색 성능도 빠르다
단점: 검색 그래프를 구성하는 방식에 따라 검색 성능 의존적 (파라미터 튜닝 필요)
6. Compression
- 벡터 임베딩을 어떤 형태로 저장할 것인지
6-1. Flat
- 임베딩 벡터를 원 형상 그대로의 형태로 두는 방식.
- 원본 그대로를 사용하기 때문에 Brute-force한 거리계산이 벡터간 수행됨
- Approximate이 아닌, kNN Full Search가 들어가기 때문에 데이터의 크기에 따라 계산 Complexity도 선형적으로 증가
6-2. Quantized
- 임베딩 벡터에 대해 더 작은 단위의 바이트로 구성된 청크들로 변환시키는 작업
- 양자화라고 부르며, 보통 float을 int로 변환
- 메모리 효율화를 통한 검색성능 개선
- 크게 두가지 유형으로 사용됨: Scalar Quantization(SQ), Product Quantization(PQ)
Scalar Quantization(SQ)
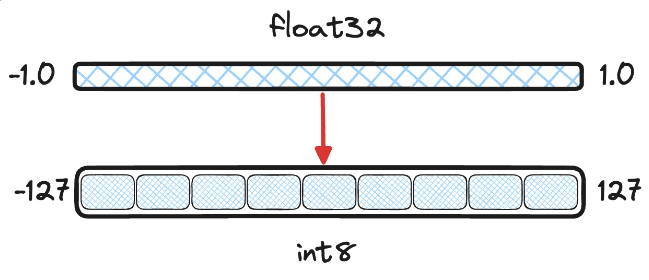
- 데이터 컴프레션 테크닉 중 하나로, float 형식으로 구성된 데이터 포인트를 Integer로 변환시키는 방식.
- 단순히 소수점을 정수로 Rounding하는 것에서 그치는 것은 아님
- 우리가 인덱싱 하려는 벡터들의 값 분포를 토대로 값이 자주 등장하는 구간을 정의하고(보통 95퍼센타일, 99퍼센타일 등), 해당 분포구간 내의 값들을 int8이나 uint8 범위로 매핑시켜 변환하는 방식
- 인터벌 바깥의 Outlier 값들은 각각의 인터벌 민맥스 값으로 클리핑 시키게됨
- 메모리 최적화 용도이기 때문에 4바이트 float을 1바이트 integer로 변환 시 속도 대폭 개선 가능
Product Quantization(PQ)
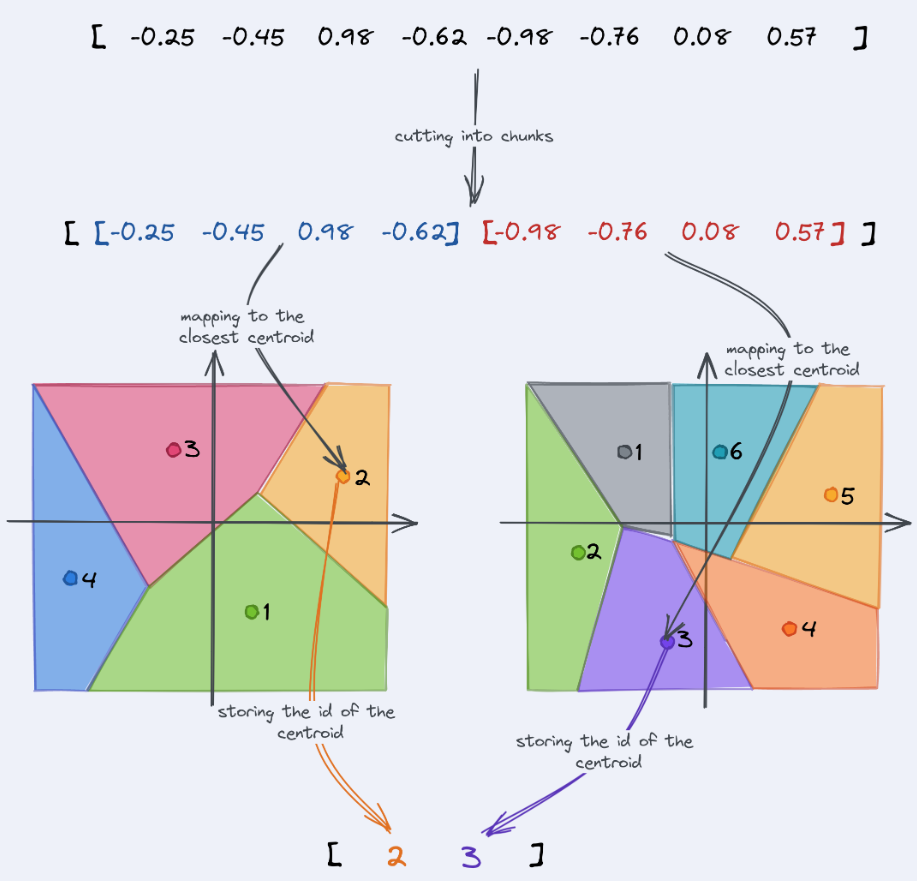
- Scalar Quantization 기법과 마찬가지로 임베딩 벡터의 floating 포인트들을 8비트 integer로 변환시켜 메모리 효율성을 증진시키는 기법
- 여기에 몇가지 추가적인 기술이 가미된 기법이 PQ
- 원본 벡터를 n개의 청크, 혹은 서브벡터 단위로 분할시키게 됨.
- 분할된 서브벡터 단위로 각각 K-Means 클러스터링을 진행 (K = 256)
- 클러스터링 결과로 나온 256개의 Centroid들을 서브벡터별의 representation으로 매핑시켜 양자화 완료
- 신규 쿼리 벡터가 들어오면 해당 벡터를 사전에 정의한 서브벡터 개수로 나누고, 각 서브벡터별 매핑되는 센트로이드 형태로 변환하게 되면 8비트 integer의 형태가 되고, 이후 거리계산 수행 시 메모리 효율성과 검색 정확도 둘다 챙기는 방식
- 덜 쪼갤수록 압축율은 올라가지만 정확도가 내려가는 트레이드오프 관계
- faiss indexes 참고
7. Querying
7-1. Keyword Search
- 전통적 방식의 키워드 기반 검색.
- 문서의 의미적 유사성을 구하는 것이 아닌, 단어의 등장 빈도가 비슷한 문서를 검색하거나, 등장여부를 필터링하여 검색하는 방식
- Attribute Filter, Spare vector search로 나누어짐
Keyword Search - Attribute Filtering
- 입력 키워드에 등장하는 단어가 DB 내의 데이터들에서 exact match 방식으로 단순 등장여부를 기준으로 검색
- 벡터 데이터베이스가 아닌 컨텍스트에서는 일반적으로 키워드 필터 기반 검색이라고도 함
- 벡터 데이터베이스 컨텍스트에서는 해당 키워드 필터를 수행하기 위해 메인 데이터인 임베딩 벡터가 아닌, 해당 벡터를 기준으로 하는 부수적인 정보로써 인덱싱되고, 그걸 기반으로 필터링 하기 때문에 Attribute Filtering이라고 함.
장점: 직관적이다. 빠르다. 검색 요건의 자율성이 제한될수록 정확해진다. 고유명사가 서칭 키워드일 시 훨씬 정확하다.
단점: 일반적으로 부정확하다. 유저의 검색실력에 결과품질이 좌우된다.
Keyword Search - Sparse Vector Search
- 단순 키워트 필터 기반의 검색에서 한단계 더 나아간 키워드 기반 검색 방식
- 키워드를 단순히 등장하면 결과로 주고, 등장하지 않으면 결과로 안주는 키워드 필터와는 다르게, 대상 문서들에 대해 단어 은행을 만들고, 해당 단어 은행에 기반한 n-gram 형태로 문서들을 벡터로 나타냄
- sparse하다고 표현하는 이유는 실제 문서를 이 방식으로 표현 시 1 이상의 숫자값을 가진 차원보다 0값이 훨씬 많기 때문.
- 단어은행 상의 단어들이 스파스 벡터 차원별로 매핑되어 등장 빈도가 표현되기 때문에 의미적 유사성까진 아니더라도 기본적인 수준으로 문서의 토픽을 모델링하는 효과를 가져가는 것이 가능
- 대표적인 스파스 벡터 서칭 모델로는 BM25와 SPLADE 가 있음
Keyword Search - Sparse Vector Search : BM25
- TF-IDF 메커니즘 활용하는데, TF(Term Frequency)는 위 설명한 n-gram기반 단어등장빈도에 대해 문서레벨로 표현
- IDF(Inverse Document Frequency)는 해당 문서의 단어가 다른 문서들에서 얼마나 등장하지 않는 단어인지에 따라 가중치를 부여하며 조정
-> 사용자가 물어보는 단어가 가지고 있는 문서 내에서도 언급하는 문서가 몇개 없을 시, 그 중 그럼에도 불구하고 해당 단어를 가장 많이 언급하는 문서가 그만큼 높은 확률로 사용자의 질문과 연관성이 높을 것이라는 가정 - 이후 사용자의 입력 쿼리를 모든 문서들에 대조시켜 BM25 스코어를 계산하고, 높은 스코어를 가진 문서를 결과로 출력
- Dense Vector를 이용하지 않기 때문에 벡터 데이터베이스가 아닌 컨텍스트에서 사용 가능하며, 벡터 데이터베이스에서 활용 시 sparse vector를 따로 인덱싱시켜서 활용 필요
장점: 필터기반 대비 단어 언급 수에 기반하므로 더욱 연관성 있는 문서 발췌 가능, 고유명사가 서칭 키워드일 시 훨씬 정확하다.
단점: 필터기반과 마찬가지로 유연성 떨어짐(오타에 취약), 이에 따른 사용자 검색 실력에 따라 결과 성능 달라짐
Keyword Search - Sparse Vector Search : SPLADE
- Sparse Vector Search의 단점인 유연성을 개선하기 위해 Sparse Vector 생성 시 BERT모델을 활용하는 방식.
- 중요도에 따른 가중치 부여: 단어의 단순 등장 빈도가 아닌, 해당 단어가 문서에서 차지하는 중요도를 스코어로 표현하여 스파스하게 표현.
- Term Expansion : BERT모델과 결합한 구조로 단어나 단어의 조합들이 의미적으로 유사한 표현들로 포괄적으로 확장
-> 오타, 간접적 표현 등도 term expansion을 통해 캐치 가능해짐에 따라 어이없는 mismatch 상황 방지 가능
-> 단순 빈도가 아니라 중요도 가중치로 문서 표현함으로 쿼리벡터와 문서간 토큰단위 중요도가 동일하게 높은 문서를 찾는 것이 가능
단점: 다른 sparse vector search 방식 대비 현저히 느림
7-2. Semantic Search
"문맥상 비슷한 위치에 등장하는 단어는 비슷한 의미를 가진다"
- 벡터 데이터베이스에서 다루는 메인 검색 기능.
- 문서의 의미적 유사성을 거리계산 함수를 이용하여 벡터간 거리를 계산하여 결과 출력을 하는 방식
- 검색하고자 하는 기반 인덱스에서 구축 시 사용한 인덱싱 알고리즘에 따라 거리 계산이 수행되는 지점이 달라짐.
(Ex. LSH 기반 인덱스 -> 해싱함수 통과 이후 유클리디안 거리계산 사용)
(Ex. HNSW+PQ 기반 인덱스 -> PQ 선 진행 이후 graph traverse 시 거리계산 함수 반복 사용) - 자주 사용되는 거리계산 식은 총 세가지가 있는데 각각 Euclidean Distance, Cosine similarity, Dot product Similarity이다.
- 인덱스 내 인덱싱된 두 벡터를 어떤 거리 계산식을 이용하는지에 따라 그 거리가 다르게 나올 수 있음
- 어떤 거리계산 식을 사용할 것인지에 대한 결정은 항상 해당 임베딩 벡터의 벡터화를 진행한 임베딩 모델이 학습 시 사용한 계산식을 그대로 사용하는 것이 Best.
Euclidean Distance
- 벡터의 차원별 대응값들의 거리를 구해서 합산하여 표현하는 방식
- 스케일에 민감하며 방향성과 거리감을 둘다 표현가능
- 단, 벡터 간 길이가 다를 시 사용하면 안됨
- 딥러닝 기반 임베딩에는 잘 안쓰이며, 빈도수 같은 스파스 벡터 형태에 활용하기 적합
Dot Product
- 두 벡터간의 내적.
- 벡터간 각도가 90도 이하일 시 양수, 90도 이상일 시 음수, 90도일 시 0
- 방향성 거리감 둘다 표현 가능
- 다수 LLM모델들이 내적으로 학습시켰기 때문에 내적 사용을 추천
Cosinde Similarity
- 내적 결과에서 magnitude를 나눈 2차적 결과
- magnitude를 상쇄시키기 때문에 거리감은 알려주지 않지만 방향성을 알려줌
- -1 부터 1의 스케일로 표현되며, 1에 가까울수록 유사한 방향성, -1에 가까울수록 반대
- 픽셀 인텐시티와 같은 강도 관련 요소가 임베딩 될 시 활용하면 안됨
7-3. Keyword Search(Attribute Filter / Sparse Vector) vs Semantic Search (Dense Vector)
Keyword Search(Attribute Filter / Sparse Vector)
- 장점
- 속도가 빠르다
- 비용 효율적이다
- 제한적 검색 요건을 가질 때 정확하다
- 의미보다 단어의 생김새가 중요할 때 정확하다(고유명사)
- 단점
- 유연성이 떨어진다
- 간접적 표현에 대한 인지력이 떨어진다
- 검색 쿼리의 디테일에 검색 성능이 의존적이다
Semantic Search (Dense Vector)
- 장점
- 정확한 표현이 아니어도 잘 알아먹을 수 있다
- 오타로부터 자유롭다
- 유사함에 기반한 결과 소팅이 가능하다
- 멀티모달을 지원한다(이미지, 텍스트, 오디오 등)
- 단점
- 속도가 느리다
- 리소스 헤비하다
- 고유명사 등 제한적 컨텍스트에서나 많이 쓰는 단어에 대해 약하다
7-4. Hybrid Search
- 벡터 데이터베이스로부터 정보 검색을 할 때 키워드 서칭 방식과 Semantic 서칭 방식을 조합하여 상호 간의 장점만 취하는 방향으로 더욱 안정적인 성능을 노리는 방식. (이외 멀티모달 컨텍스트에서는 텍스트 + 이미지 조합으로 하는 서칭도 해당)
- 굉장히 자유로운 방식의 서칭 조합 사용 가능
-> “OO일보에서만 한 달 전 발간한 금리 관련 내용을 찾아줘” -> Attribute Filter(발간지, 발행일) + Semantic Search
“축구 관련 기사를 찾는데, 그 중에서도 해외파 선수들의 소속팀에서의 성적과 관련된 부분을 찾아줘” -> SPLADE(해외파 선수들 -> 손흥민, 김민재 등) + Semantic Search
- intermediate 결과를 토대로 하나의 서칭결과로 합치는 퓨전 알고리즘 필요
- Sparse + Dense 서칭 결과를 토대로 최종 결과를 생성하기 위해 Fusion 스코어링 필요
- Naive weighted score : 0.3 sparse 스코어 + 0.7 Dense 스코어
- Reciprocal Ranked Fusion(RRF) : 두 결과리스트에서의 순위적 위치만을 가지고 결과 스코어로 퓨젼하는 방식
- Relative Score Fusion(RSF) : 두 결과를 normalize시킨 후 줄세워서 결과를 통합시키는 방식
- Distribution-based score Fusion(DBSF) : 두 결과를 뽑은 엔진의 분포가 서로 상이해도 유의미한 score fusion이 가능하도록 분포 기반 스케일링을 추가한 방식

Data Engineer