ML engineer
1.pgVector

Postgres 에서 vector의 similarity search를 하기 위한 오픈소스 vectorDB지원 검색 종류exact and approximate nearest neighbor searchsingle-precision, half-precision, binar
2.VectorDB 정리
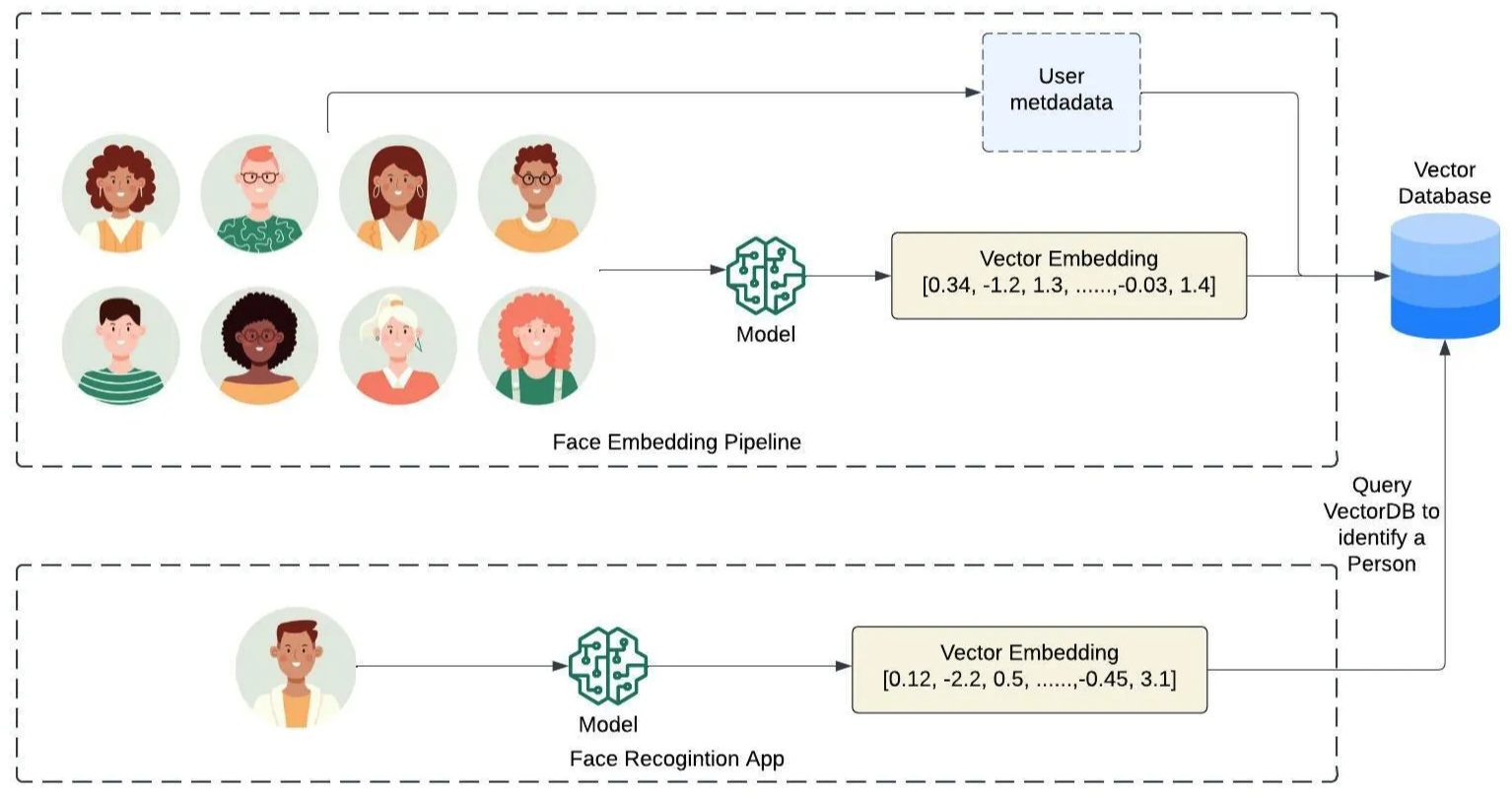
텍스트, 이미지, 오디오 등 임베딩 방식으로 나타낸 데이터를 저장하고, 관리하고, 검색하는 기능을 제공하는 임베딩 벡터 전용 DB.고차원(벡터 차원 수)의 공간(인덱스)에 임베디드 벡터를 인덱싱하여 저장하는 방식.입력 Query와 가장 가까운 이웃을 찾아주는 검색 방식
3.gunicorn, uvicorn

개요 FastAPI를 이용하여 ML 모델을 추론하여 embedding API를 생성하는 프로젝트 진행 이때 gunicorn과 uvicorn를 이용하여 서버를 구축하며 이에 대한 공부 내용 정리 Python Thread의 한계 GIL(Global Interpreter
4.MLOps와 LLMOps
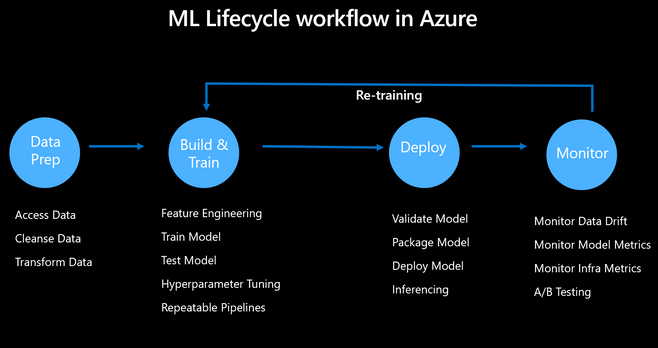
ML(Machine Learning, 머신 러닝)과 Ops(Operations, 운영)의 합성어머신 러닝 모델을 안정적이고 효율적으로 배포 및 유지 관리하는 것을 목표머신 러닝 프로그램의 개발, 배포, 관리 및 모니터링을 위한 연속적인 작업 프로세스 LLMOps는 "L
5.신경망 (1) (Neural Network)의 기초 개념 정리
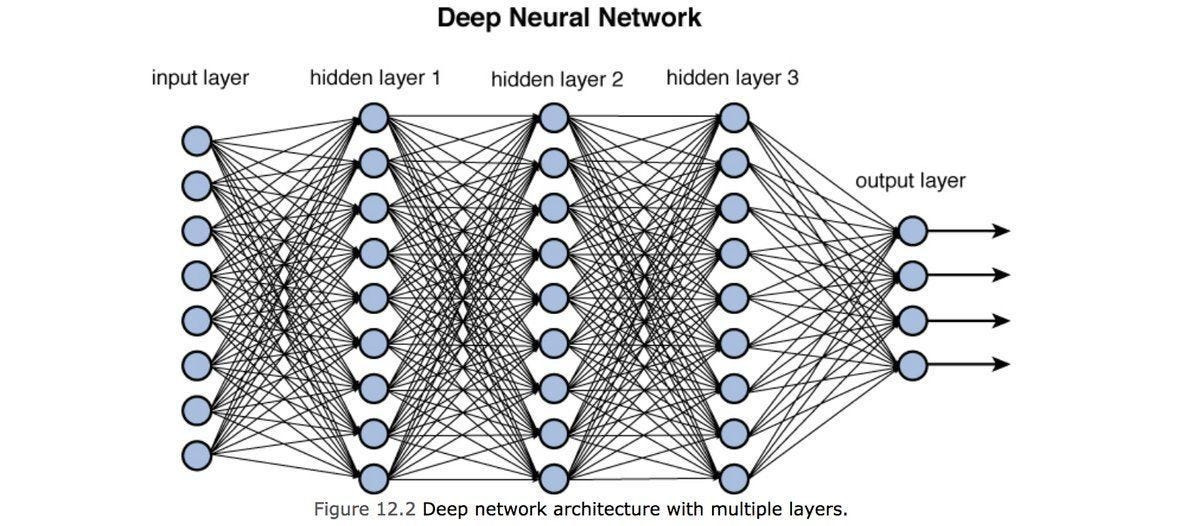
정의/구조: 입력층–은닉층–출력층으로 이루어진 다층 구조. 이전 층의 출력을 다음 층이 받아 점차 더 추상적인 표현(특징) 을 학습한다. 신경망은 오늘날 딥러닝 모델의 뼈대이고, 글은 이 기본 개념을 시작으로 CNN/RNN 등으로 확장한다.1차 AI 겨울 원인: 퍼셉트
6.신경망 (2) (Neural Network) 구조의 주요 유형
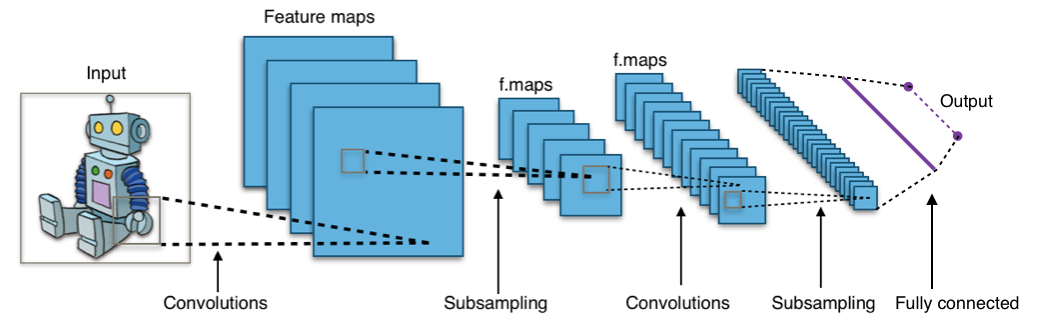
적용 분야: 이미지, 영상 등의 공간적 구조가 있는 데이터에 특화된 신경망.기존 방식의 한계: 1D로 펴는 방식(flattening)은 픽셀 간 공간 관계를 없애버려 정보 손실 유발.해결책: 위 그림은 Fully Connected Layer 이다. 기존의 Fully C
7.CNN (1)
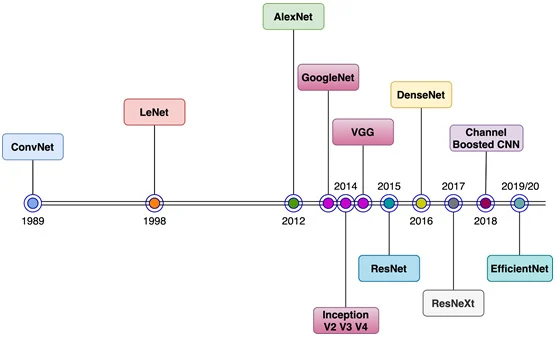
CNN의 시작점: 1989년 이전에도 개념은 있었지만, 실질적인 시초는 LeNetLeNet은 Yann LeCun이 만든 모델로 (위 그림이 LeNet),$11 \\times 11 \\times 3$ 크기의 필터 48개로 합성곱(convolution) 연산을 수행,$55
8.CNN(2)
기울기 소실(Vanishing Gradient)은 역전파(backpropagation) 과정에서, 출력층에서 입력층으로 갈수록 기울기(gradient)가 점점 작아지는 현상을 말한다 ( 미분이 계속 되니까 계속 작은 값(특히 sigmoid/tanh의 미분 값)이 곱해져
9.CNN (3)
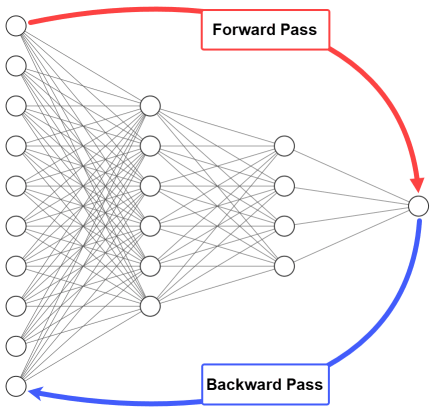
CNN은 점점 더 깊은 구조로 발전해왔고, 깊이(layer 수)가 증가할수록 모델의 표현력과 성능이 커졌다.하지만 깊이가 깊어질수록 Gradient Vanishing Problem(기울기 소실)이 심화되어, 입력층 근처의 가중치 학습이 원활하게 이루어지지 않았다.Gra
10.Regularization (1)
딥러닝 모델의 목표는 학습 데이터뿐만 아니라, 보지 못한 새로운 데이터에서도 잘 동작하는 것 — 이를 일반화 능력이라고 한다.기대 위험(Expected Risk)인 $\\mathbb{E}\_{(x,y)\\sim D}\\ell(x,y)$를 최소화하는 것이 목표지만, 분포
11.Regularization(2)
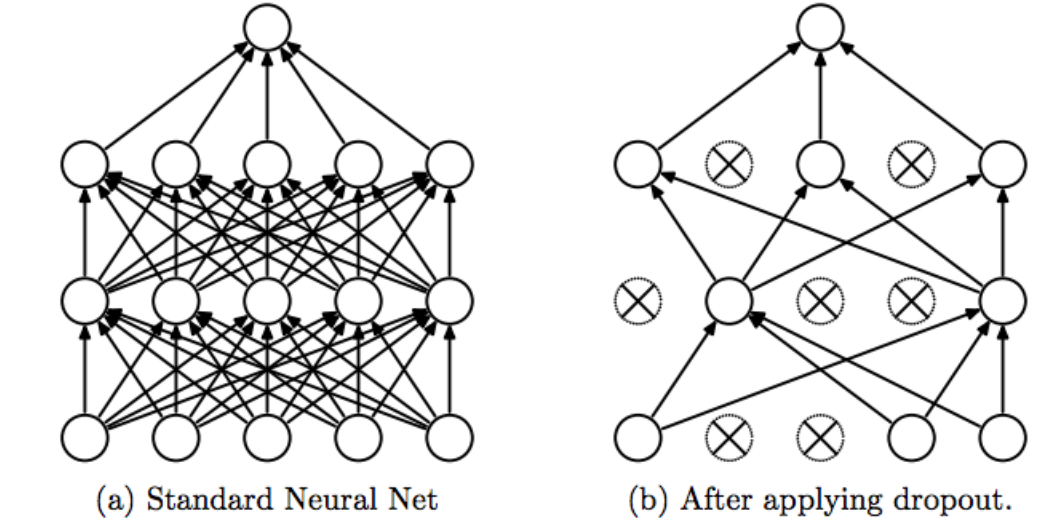
개념손실 함수에 가중치들의 절댓값 합을 추가하는 방식.$\\mathcal{L}(w) = \\text{Train Loss}(w) + \\alpha \\sum |w_i|$효과: 불필요한 가중치를 0으로 만들어버림 → 희소성(Sparsity), Feature Selectio
12.RNN (1)
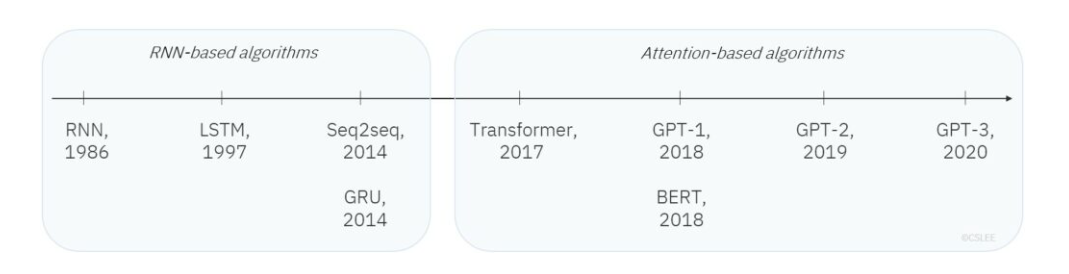
Image Data: 고정된 길이(shape)를 가짐 (예: 28×28 픽셀 MNIST).Sequence Data: 가변 길이를 가짐.입력이 time step 에 따라 순차적으로 들어옴.문장의 경우 단어 단위(token)로 들어오며, 단어 길이도 다르고 문장 길이도 다
13.RNN (2)
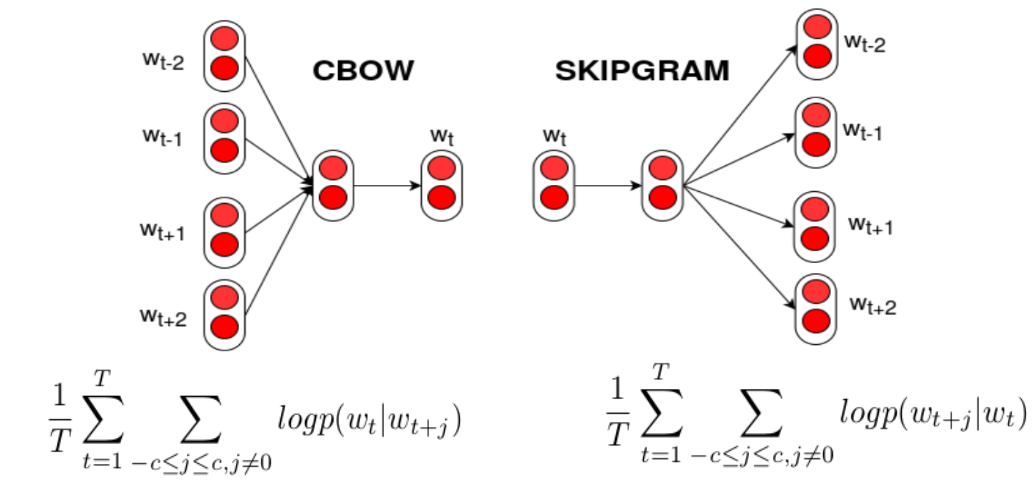
기본 개념단어를 Dense vector(실수 벡터)로 변환하는 방법.과거에는 Sparse vector(One-hot encoding) 사용:“고양이”가 10개 클래스 중 하나라면 0,0,1,0,0,0,0,0,0,0대부분 0 → 차원이 커질수록 비효율적.Dense vec
14.RNN (3)
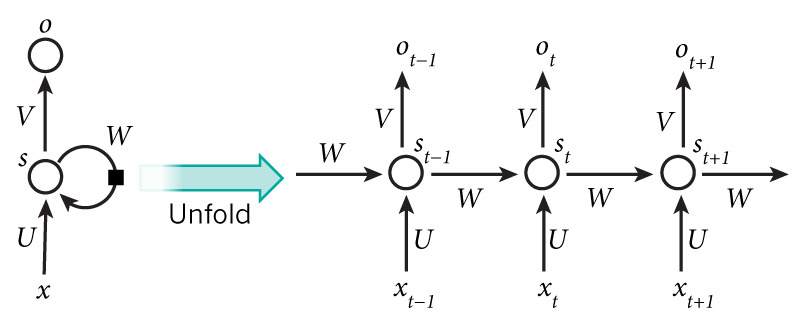
개념순환 구조: Hidden node가 방향을 가진 edge로 연결되어 이전 상태 정보를 다음 state로 전달.입력: 시점 $t$의 단어 $x_t$Hidden State: $st = \\sigma(W s{t-1} + U x_t)$출력: $o_t = V s_t$Shar
15.RNN(4)

개념기계 번역과 같이 입력과 출력이 모두 시퀀스인 Task에 쓰이는 대표적 모델.Encoder-Decoder 구조로 이루어짐.Encoder: 입력 문장을 읽어 고정된 길이의 Context Vector로 요약.Decoder: Context Vector를 입력받아 출력 문
16.Transformer (1)
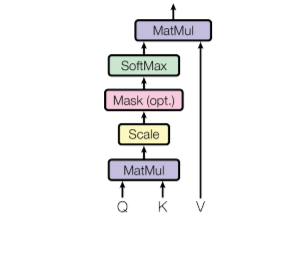
Transformer 개요Transformer는 현재 딥러닝의 backbone 아키텍처.시작: NLP의 기계 번역(Seq2Seq의 한계 극복)현재: NLP뿐만 아니라 Vision, Graph, Generative Model까지 확장.첫 논문: Attention is a
17.Transformer (2)
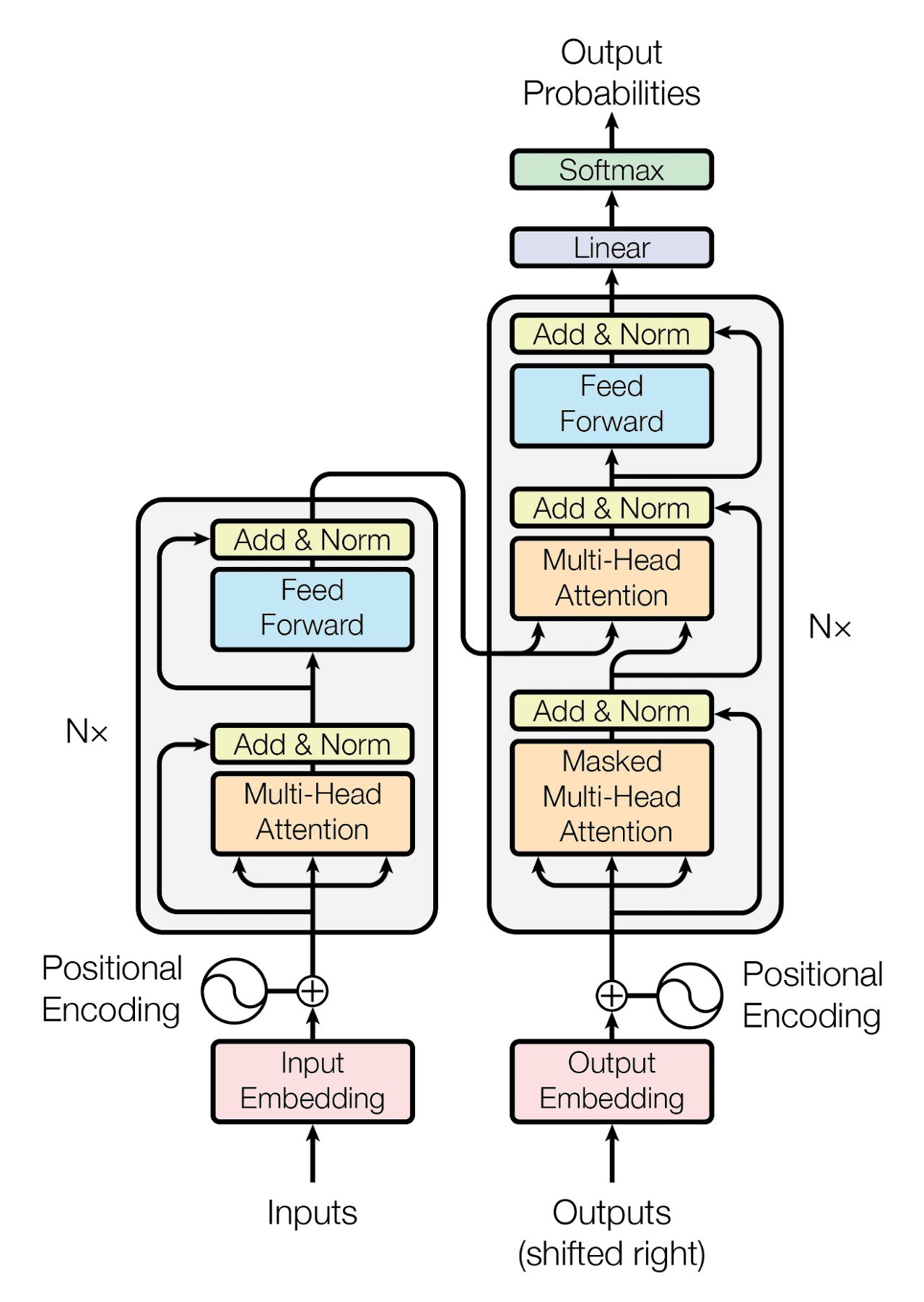
Transformer = Encoder N개 + Decoder N개 (논문 기준 Nx=6).Encoder: 입력 문장을 representation vector로 변환.Decoder: 이 representation vector + 정답 문장(label)을 활용해 번역 결
18.1. ML 기초
Entropy는 어떤 확률 분포에서 사건이 일어났을 때 이들이 가지는 '정보량의 기대값불확실성(uncertainty)의 정도를 수학적으로 표현하는 개념확률 분포에서 "얼마나 예측하기 어려운지"를 측정한다고 보면 된다.공정한 동전 (앞면 50%, 뒷면 50%)결과를 예측