6장 맵리듀스 작동 방법
맵리듀스 프로그래밍 개발절차
- 데이터의 흐름설계
- InputFormat / OutputFormat 구현
- Mapper 구현
- Partitioner 구현
- Reducer 구현
- Driver 구현 및 공통데이터 배포설정
- $HADOOP_HOME/lib에 등록
- bin/hadoop -jar 실행시 -libjars 옵션
- DistributedCache 사용
1. 맵리듀스 잡 실행 상세 분석
이미지출처 : Hadoop Map Reduce Introduction - socurites
잡 제출
- JobClient 는 JobTracker 와 서로 커뮤니케이션 하기 위한 주요 인터페이스 이다.
- JobClient 는 job 제출(submit), job 수행 진도 체크, 태스크의 리포트와 로그 확인, MapReduce 클러스터 상태 정보 체크 등 많은 기능을 가지고 있다.
JobClient.runJob()
- bin/hadoop 명령을 이용해서 Job을 수행하면 사용자가 만든 main() 메소드가 수행되면서 JobClient 클래스의 runJob()이 호출된다.
- JobClient 인스턴스를 생성하고 submitJob 메소드를 호출 한다.// step1
jobClient.submitJob()
- job ID요청
- JobTracker.getNewJobId() // step2
- Job 필요한 리소스를 HDFS로 복사// step3
- jobConf에 설정된 정보를 이용하여 job.xml을 구성한 다음 HDFS에 저장
- 사용자의 Job 클래스 또는 Job 클래스가 있는 jar 파일을 job.jar로 묶어 HDFS에 저장
- InputFormat의 getSplit() 메소드를 호출하여 반환되는 값을 이용하여 job.split 파일을 HDFS에 저장
- job이 실행될 준비가 됐다는 것을 JobTracker에게 알린다.
- JobTracker.submitJob()호출 // step4
이미지출처 : How MapReduce Works
이미지출처 : Hadoop 세부 사항 및 로그
잡 초기화
- JobTracker.submitJob() 메소드 호출받음
- Job queue에 추가
- submitJob()이 호출되면 HDFS의 job.xml, job.split 정보를 이용하여 map/reduce task를 생성한 후 job queue에 추가한다.
- 캡슐화 = 해당Job + 부가정보 // step 5
- ( 부가정보 : Task 상태, 진행 과정 확인 )
- 수행할 Task 목록 생성을 위해, job 스케쥴러는 우선 공유된 파일 시스템으로부터 JobClient에 의해 계산된 입력 split을 가져온다. // step 6
- 각 split에 대해 하나의 맵 Task를 생성한다.
- 리듀스 Task의 수는 JobConf에 mapred.reduce.tasks 속성에 의해 결정된다.
Task 할당
- TaskTrasker는 주기적으로 JobTracker에 heartbeat() 메세지를 보내는데 이 heartbeat 메세지를 이용하여 JobTracker는 TaskTracker의 상태 정보를 파악한다.
- heartbeat() 호출의 return 값에 TaskTracker가 수행할 Task의 목록이 전달된다. // step 7
- 따라서 Hadoop는 JobTracker가 직접 TaskTracker에 Task를 할당하는 것이 아니라 queue에 넣어 두면 TaskTracker가 가져가는 방식이다.
- 잡 스케줄러는 잡 우선순위나 스케줄링 알고리즘에 따라 선택된 잡에서 태스크를 할당함
- TaskTracker는 다수의 맵/리듀스 태스크를 동시에 수행 가능하며, 일반적으로 맵 태스크 슬롯을 채운 뒤, 리듀스 태스크 슬롯을 채움
- 리듀스 태스크는 데이터의 지역성이 고려되지 않고 순차적으로 할당됨
- 맵 태스크에 대해서는 TaskTracker의 네트워크 위치를 고려하고 TaskTracker에게 가능한 가까운곳에 있는 입력 조각의 태스크를 선택한다
Task 실행
- TaskTracker는 Task를 받으면 HDFS로 부터 job.jar 파일을 읽어 로컬 디스크에 저장한 다음 Task를 fork한다.
- Distributed cache(분산 캐쉬)로부터 필요한 파일을 Local 파일 시스템으로 복사
- TaskRunner 인스턴스를 생성하고 새 JVM을 실행하여 Task를 수행
- Task 진행 과정을 부모에게 몇 초 간격으로 보고
- 스트리밍 또는 파이프를 이용하여 사용자가 제공하는 프로그램을 시작하고 통신하기 위한 목적으로 맵과 리듀스 외부 프로세스와 통신
- 스트리밍 태스크는 표준 입력과 출력 스트립을 사용하여 프로세스와 통신한다.
- 파이프 태스크는 소켓을 리슨하고 C++ 프로세스에게 포트넘버를 전달한다.
그래서 시작하고, C++ 프로세스는 부모 자바 파이프 태스크에 지속적 소켓 연결을 수행할 수 있다.
이미지출처 : How MapReduce Works
진행 상황과 상태 갱신
- 맵리듀스 job들은 일괄 작업으로 오랫동안 수행하기 때문에 사용자가 job이 어떻게 진행되고 있는지에 대한 피드백을 얻는것이 중요하다.
- job과 각 태스크들은 다음과 같은 상태 (status)를 가지고 있다
- running, successfully completed, failed
- 태스크의 진행상황을 구성하는 요소
- 매퍼 또는 리듀서 내의 입력/출력 레코드 읽기
- 리포터의 setStatus() 호출 - 상태 설정
- 리포터의 ncrCounter() 호출 - 카운터 증가
- 리포터의 progress() 호출
- 태스크는 상태 변화를 태스크 트래커에게 보고
- 태스크 트래커는 하트비트를 통해 태스크들의 상태를 전송
- 잡 트래커는 태스크들의 상태를 전역적으로 결합하여 JobClient에게 보고
잡 완료
- 잡 트래커가 마지막 태스크의 완료 보고를 수신 후 '성공'으로 상태를 변경
- JobClient가 잡 완료를 확인하면 runJob()이 종료됨
- job.end.notification.url 속성 - HTTP로 통지
- 잡 트래커와 태스크 트래커의 상태 정보 정리 (중간 출력 삭제 등)
2. 실패
Task 실패
- Task 내 에러 발생시 자식 JVM는 부모인 TaskTracker에게 에러 보고
- TaskTracker가 mapred.task.timeout 속성에 설정된 시간 내에 태스크의 진행 상황을 보고 받지 못하면 실패로 인식
- JobTracker의 Task 재스케줄링
- 실패한 TaskTracke에게는 실패한 태스크를 재할당하지 않음
- 기본적으로 어떤 태스크가 4번 이상 실패하면, 전체 잡 실패 처리
- 최대 시도 회수 설정 (기본 4) : mapred.map.max.attempts, mapred.reduce.max.attemps에
- 태스크 실패 허용 최대 비율 설정 : mapred.max.map.failures.percent, mapred.max.reduce.failures.percent
TaskTracker 실패
- 기본적으로 태스크 트래커가 10분 동안 하트비트를 전송하지 않으면 잡 트래커는 태스크 트래커 풀에서 해당 태스크 트래커에서 제외시킨다.
- 잡 트래커는 완료되지 않은 맵태스크에 대해서만 새 태스크 트래커에게 배치 시켜 재실행
- 평균 태스크 실패율보다 높은 실패율을 보이는 태스크 트래커는 블랙리스트에 등록
JobTracker 실패
- 가장 심각한 실패유형이며 잡 전체가 실패
- 다수의 잡 트래커 실행시 주키퍼에 의해 잡 트래커들의 순위가 조정됨
3. 잡 스케줄링
- 기본적으로 FIFO 스케줄러로 지정되어 있으나, 다중 사용자 스케줄러를 제공함
페어(fair) 스케줄러
- 각 사용자의 큐마다 Job을 공평하게 공유할 수 있도록 하는데 목적이 있음
- 단일 잡만 수행 중이라면 전체 클러스터를 사용
- 스케줄러 설정하는 방법
- contrib/fairscheduler 디렉토리에서 JAR를 lib 디렉토리로 복사
- mapred.jobtracker.taskScheduler 속성의 값을 org.apache.hadoop.mapred.FairScheduler로 설정
커패시티(capacity) 스케줄러
- 각 사용자의 큐는 할당된 수용량이 있음
- 각 큐에서 Job 우선순위에 따라서 FIFO 스케줄링 할 수 있음
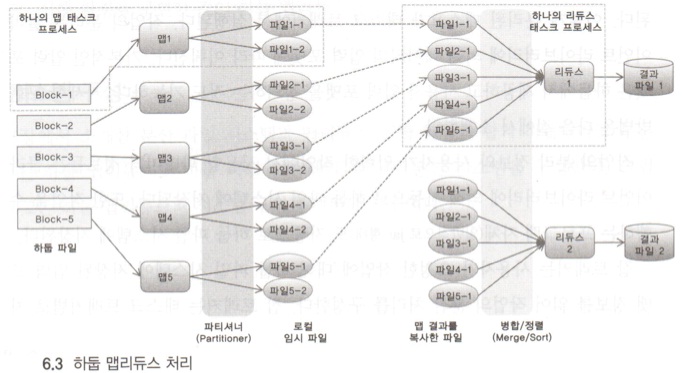
4. 셔플과 정렬
- 맵의 출력들을 키에 따른 정렬을 보장해 리듀서의 입력으로 전달해 주는데 이를 셔플이라고 한다.
- shuffle : 맵 출력은 키/값 쌍으로 파티션되는데 이 파티션은 정렬되어 있다. 이 상태를 shuffle이라고 한다.
- spill : 각 정렬 파티션으로 생성한 파일을 spill이라고 한다.
맵과정
- 맵 출력은 버퍼에 기록되며, 버퍼 내의 데이터를 스레드가 파티셔닝하고 파티션 별 정렬을 수행함
- 각각의 맵 Task는 환형 구조의 메모리 버퍼를 가지고 있으며 이 메모리에 데이터를 기록한다.
- 버퍼가 스필(spill) 한계(기본 80%)에 도달하면 디스크에 기록하며, 마지막 출력 레코드가 기록되는 직후에 스필된 파일들은 하나의 출력 파일로 병합되고 정렬됨
- 맵 출력의 전송 데이터 량을 줄이기 위해 압축을 수행할 수 있음
리듀스 관점
- 맵 Task가 끝나는대로 리듀서는 그 출력들을 복사해 온다.
- 리듀서는 어떤 TaskTracker가 맵 출력을 인출했는지 어떻게 알까?
- 맵 Task 성공완료
- 부모 TaskTracker에게 상태 갱신 알림
- JobTracker 에게 통지(heartbeat)
- 리듀서내의 스레드가 주기적으로 JobTracker에게 맵 출력 위치를 물어봄
- 리듀서가 맵 출력을 가져갔다고 해서 맵 출력들을 삭제하지 않는다. 리듀서가 실패할 수도 있어서
- 모든 맵 출력이 복사되면 리듀스 Task는 병합 단계로 이동한다.
- 리듀스 출력은 HDFS에 기록되됨
환경설정 튜닝
- 셔플에 가능한 한 많은 메모리를 할당
- 맵/리듀스 함수들이 동작하는 데 있어 충분한 메모리를 확보하도록 보장해줘야 한당.
- 맵리듀스 동작 시 최소한의 메모리 사용
- 맵 태스크의 최소한의 스필 파일 수 유지
- 속성 표 참조 (256P~257P)
5. 태스트 실행
투기적 실행
- 단 하나의 느린 Task 때문에 전체 작업 속도가 느려질 수가 있다
- 최소 1분이 경과되고 평균 속도보다 느린Task를 감지하면, 또 다른 동일한 예비 Task를 실행함
- 이것을 Task의 투기적 실행이라고 함
- 투기적 실행은 두 개의 복제 태스크들을 동시에 실행하여 서로를 경합시키려는 것이 아니다.
- 원래 태스크가 투기적 실행보다 먼저 완료되면 투기적 실행은 종료되고,
- 투기적 태스크가 먼저 완료되면 원래 태스크는 강제 종료된다.
*투기적 실행은 기본적으로 활성화되어 있으며 설정에서 비활성화 가능함 - mapred.map.tasks.speculative.execution (boolean)
- mapred.reduce.tasks.speculative.execution (boolean)
태스크 JVM 재사용
- 새로운 JVM을 시작하는데 드는 overhead(약 1초)를 줄이기 위해 사용
- 어떤 잡에 대하여 각 JVM이 수행할 최대 태스크 수 설정 가능
- mapred.job.reuse.jvm.num.tasks (기본값 1)
비정상 레코드 생략
- 매퍼나 리듀서 코드 내에서 비정상 레코드의 예외 처리
- 비정상 레코드 생략모드는 기본적으로 꺼져 있다.
- SkipBadRecords 클래스를 사용하여 맵과 리듀스 태스크들에 대해 각각 활성화 시킬 수 있다.
태스크 실행 환경
- 하둡은 수행되는 환경에 대한 정보를 맵 또는 리듀스 태스크에 제공한다.
- 잡 ID, 태스크 ID, 태스크 시행 ID, 잡 내의 태스크 ID 등
- 262 표 참고
- 맵리듀스 프로그램 내에서 환경 속성을 참조할 수 있음
- FileOutputFormat의 getWorkOutputPath() 등..
참고
- Hadoop 세부 사항 및 로그
- 6장 대용량 데이터 분석 프레임워크 맵리듀스
- How MapReduce Works
- http://wiki.gurubee.net/pages/viewpage.action?pageId=23232538

Data Engineer