Hadoop 완벽 가이드
1.하둡과의 만남

Big Data의 출현뉴욕증권 거래서 하루 1테라페이스북 대략 10억개의 사진, 1페타비이트의 저장소인터넷 보관소(The Internet Archive)는 대략 2페타바이트의 데이터를 저장, 매달 20테라 바이트 증가..좋은 소식은 Big Data는 우리 주변에 널려
2.맵리듀스
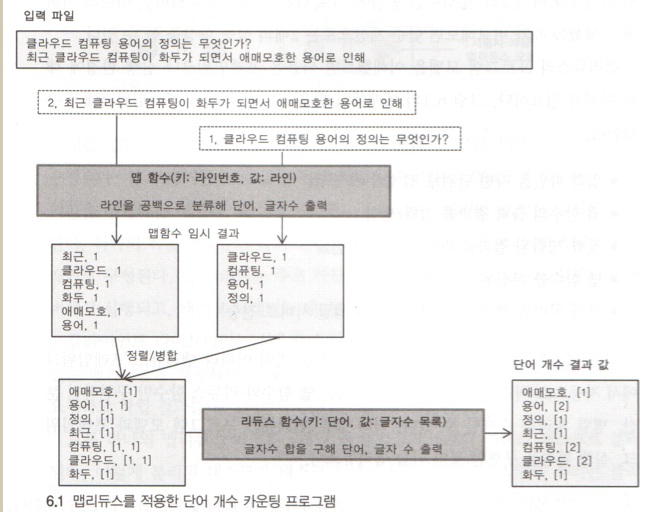
MapReduce는 구글에서 개발한 소프트웨어 프레임워크(방법론)이다.who 구글이what 페타바이트 이상의 대용량 데이터를(기가<테라<페타... 꺄악)where 신뢰 할 수 없는 컴퓨터로 구성된 클러스터 환경에서why 병렬처리를 지원하기 위해서개발되었다.=
3.하둡 분산 파일시스템
분산파일 시스템 : 네트워크로 연결된 서버들의 스토리지를 관리하는 파일 시스템. 일반 디스크 파일시스템보다 복잡함HDFS 는 범용 하드웨어로 구성된 클러스터에서 실행되고 데이터 액세스 패턴을 스트리밍 방식으로 지원하여 매우 큰 파일들을 저장할 수 있도록 설계된 파일시스
4.하둡 IO
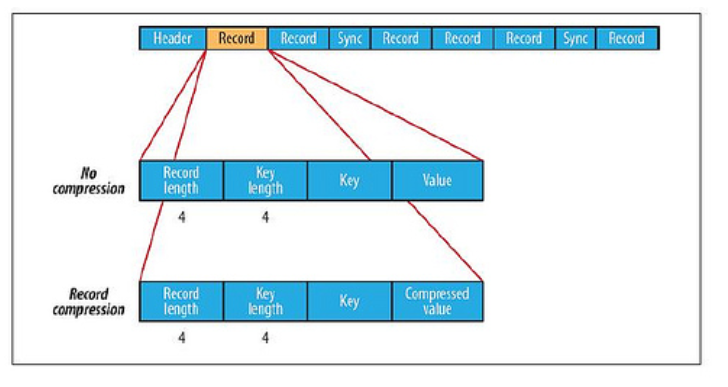
HDFS 는 데이터쓰기와 읽는 과정에서 체크섬을 계산하고 검증io.bytes.per.checksum 에서 설정된 바이트마다 데이터에 대한 별도의 체크섬 생성체크섬의 크기는 512byteCRC-32데이터노드 : 클라이언트에게 데이터 수신, 다른 데이터노드에게 데이터 복제
5.맵리듀스 프로그래밍
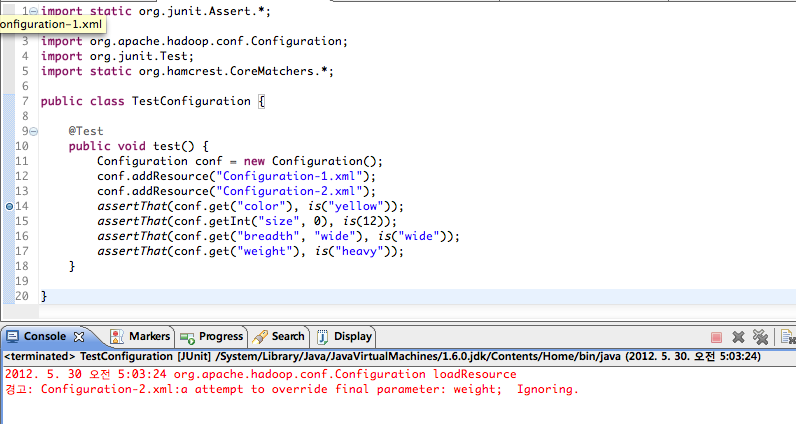
XML 파일들로 부터 속성을 읽어 환경 설정 속성과 값의 집합을 표현각 속성은 String, 값은 자바 프리미티브(int,long)과 Class, String과 같이 다양한 타입을 사용할 수 있음리소스들을 순차적으로 Configuration에 추가할 수 있음속성이 중복
6.맵리듀스 작동 방법
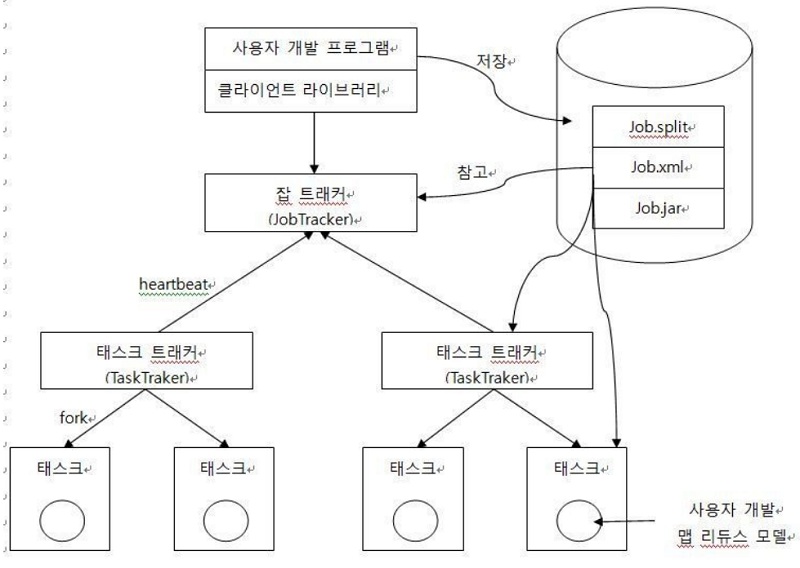
데이터의 흐름설계InputFormat / OutputFormat 구현Mapper 구현Partitioner 구현Reducer 구현Driver 구현 및 공통데이터 배포설정$HADOOP_HOME/lib에 등록bin/hadoop -jar 실행시 -libjars 옵션Distri
7.맵리듀스 타입과 포맷
Map & Reduce 함수 형식은 다음과 같다.입력 -> 중간 -> 출력맵 입력키와 값 타입은 맵 출력 타입과 다르다.리듀의 입력 타입은 맵의 출력 타입과 같아야 한다.combine함수출력타입은 맵과 리듀스의 중간 키와 값에 해당하는 타입(K2, V2) 이 되어 리뷰
8.맵리듀스 기능

잡에 대한 통계를 수집하는 유용한 채널로서 품질 통계, 또는 응용프로그램 수준 통계를 제공.문제 진단에 유용카운터는 연관있는 태스크에 의해서 관리되며, 주기적으로 태스크트래커에 보내지고 잡트래커에도 보내진다.전역적으로 수집내장된 잡 카운터는 실제로 잡트래커가 관리하기
9.하둡 클러스터 설정
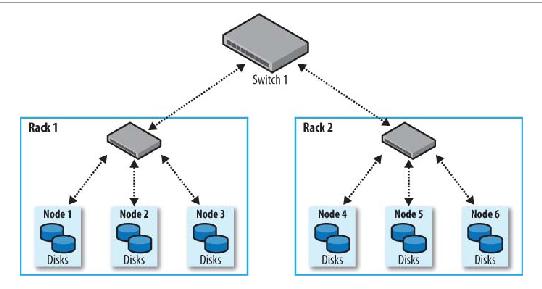
비싼 하드웨어 필요 없음. 비싼 컴퓨터로 하드웨어 갯수를 줄일 수 있지만, 하드웨어 하나가 전체 클러스터에 미치는 영향은 늘어난다. 마치 주식의 리스크를 분산하는 것 처럼 리스크를 줄인다.데이타 노드에 RAID 사용할 필요 없다. 네임노드는 사용할만 하다.작은 클러스터
10.하둡 관리
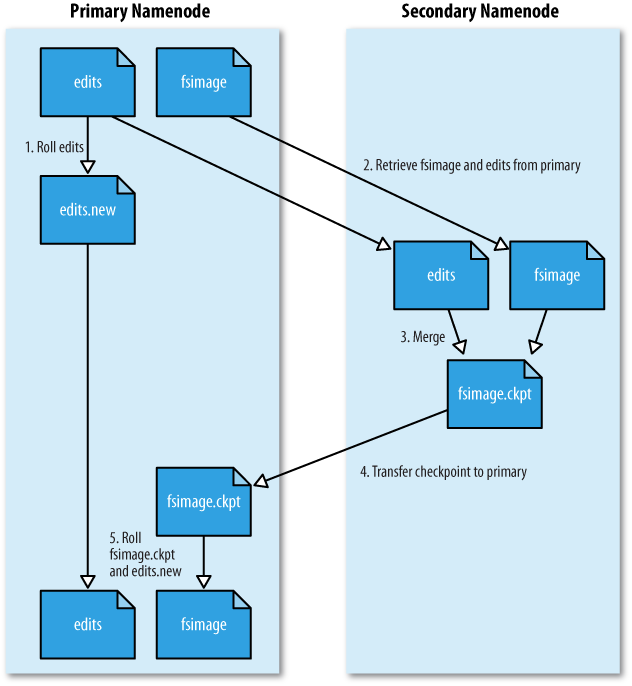
주 네임 노드의 디렉토리 구조보조 네임노드는 주 네임노드에 edits 파일을 순환 사용하도록 요청한다. 그 때문에 새로운 edits 로그는 새로운 파일을 저장된다.보노 네임노드는 HTTP GET을 이용해서 주 네임노드의 fsimage와 edits를 가져온다.보조 네임노
11.피그
http://pig.apache.org/피그는 대용량 데이터셋을 좀 더 고차원적으로 처리할 수 있게 해주는 스크립트 언어이다.대규모 데이터셋을 좀 더 쉽게 분석하려고 야후의 연구원과 엔지니어들이 만들었다.피그는 두 부분으로 이루어져있다.피그 라틴 : 데이터의
12.하이브
하이브는 하둡 기반의 데이터 웨어하우징 프레임워크다페이스북의 급증하는 소셜네트워킹에서 매일 생성되는 대량의 데이터를 관리 하고, 학습 하기 위해 개발되었다.페이스북에서는 대량의 데이터를 HDFS에 저장한 후, HiveQL (하이브가 제공하는 SQL)을 이용해서 데이터를
13.HBase
HBase는 HDFS에 구현한 분산 컬럼 기반(distributed column-oriented) 데이터베이스.클러스터 관리는 주키퍼를 이용한다.대규모 데이터셋을 실시간으로 랜덤 엑서스가 필요할 때 사용할 수 있는 하둡 응용프로그램.대표적인 사례: 웹테이블(Webtab