| 일수 | 일자 | 교과목 | 내용 | 편성시간 |
|---|---|---|---|---|
| 9 | 24/12/02 | 기반기술 | Database | 8 |
SQL 성능
SQL 성능 체크하는 방법 1 : EXPLAIN
실행 결과를 정리해서 보여준다
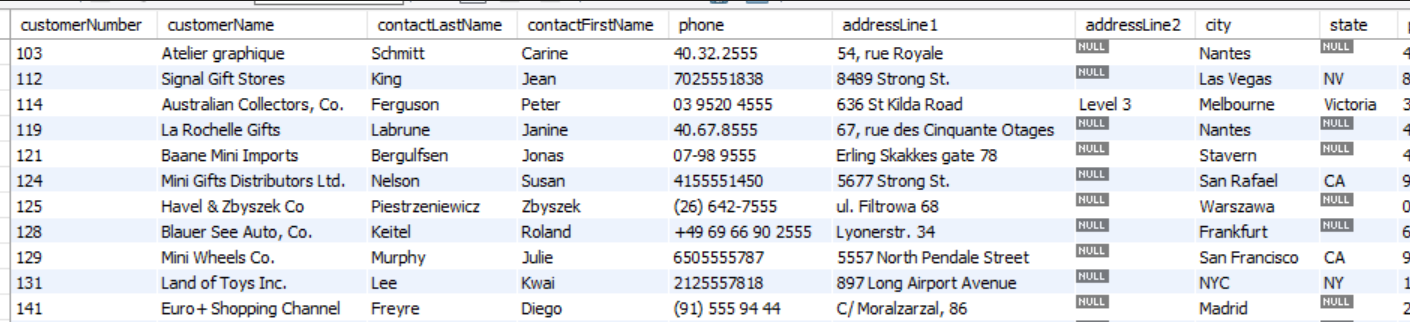
SELECT * FROM customers;
EXPLAIN SELECT * FROM csutomers;간단하게 요약된 정보가 나오는 걸 볼 수 있다.
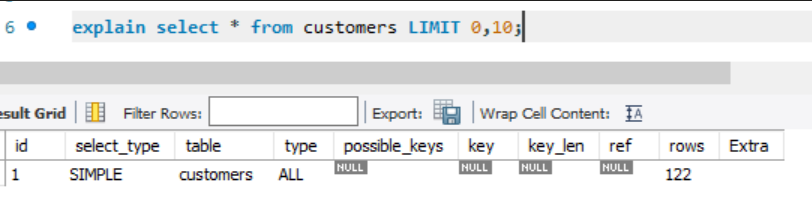
LITMIT을 걸어도 전체 데이터가 요약된 결과가 나온다.
SQL 성능 체크하는 방법 2 : PROFILING
SET PROFILING = 1 ; #profiling 기능 켜는 설정
SELECT * FROM customers WHERE country='USA';
SHOW PROFILES; # profiling 결과 조회
#특정 쿼리의 실행 과정 상세 조회
SHOW PROFILE FOR QUERY 3; #Query_ID가 3번인 데이터의 상세 조회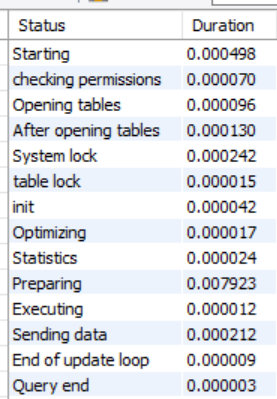
특정한 사용자가 작성한 글 조회
SELECT * FROM post WHERE writerIdx=1;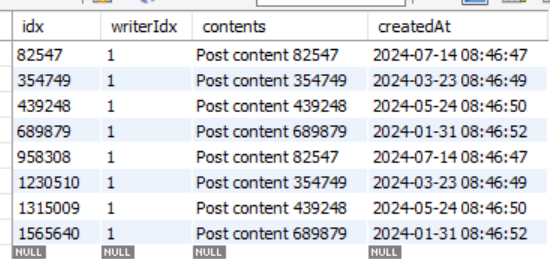
특정한 사용자가 작성한 글 조회
EXPLAIN SELECT * FROM post WHERE writerIdx=1;
인덱스
CREATE INDEX post_index_createdAt ON post(createdAt); #인덱스 생성
EXPLAIN SELECT * FROM post WHERE createAt > '2024-12-02'; #다시 explain을 확인하면 rows의 수가 줄어든다
DROP INDEX post_index_createAt On post; #인덱스 삭제
인덱스 생성 전

인덱스 생성 후
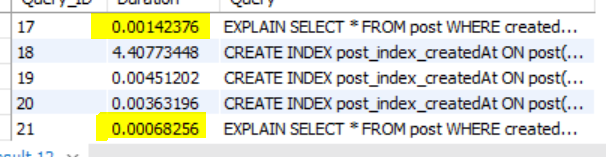
SHOW PROFILES;로 확인해보면 인덱스 만들고 실행 후 더 빨라졌단 걸 확인할 수 있다.
- 인덱스를 만든다고 성능이 무조건 좋아지는 건 아님
- PROFILES로 성능을 확인하면서 쓰기
역색인
ElasticSearch, 역색인 기반으로 데이터를 검색
스토어드 프로시저 (Stored Procedure)
SQL이 실행될 때 진행하는 일련의 과정을 미리 실행해서 저장해두고 나중에 저장된 걸 사용하는 기능
- SQL은 인터프리터 언어이지만(한 줄씩 실행) 스토어드 프로시저는 컴파일 언어처럼 바꾸어 조금 더 빠르게 실행 (준 컴파일 언어처럼 바꾼다.)
DELIMITER $$ #쿼리가 시작될 곳 지정
CREATE PROCEDURE SP이름 (IN 또는 OUT 속성)
BEGIN
END $$ #쿼리가 끝나는 곳실습
DELIMITER $$
CREATE PROCEDURE SP_SELECT_MEMBER ()
BEGIN
SELECT * FROM member;
END $$
CALL SP_SELECT_MEMBER(); # 스토어드 프로시저 사용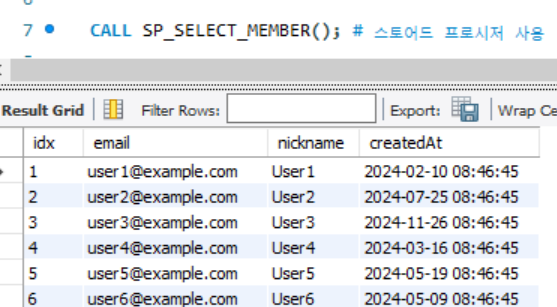
뷰(VIEW)
가상 테이블
CREATE VIEW view_post_join_member
AS
SELECT post.idx, post.contents, member.email FROM member LEFT JOIN post
ON member.idx = post.writerIdx
ORDER BY post.idx DESC;
SELECT * FROM view_post_join_member;위와 같은 형식으로 사용할 수 있으나, 뷰는 사용하는 걸 딱히 추천하지는 않는다.
실습
CREATE TABLE member
(
idx INT auto_increment primary KEY,
email varchar(30),
nickname varchar(20),
createdAt DATETIME
);
CREATE TABLE post
(
idx INT auto_increment primary key,
writerIdx INT,
contents varchar(100),
createdAt datetime,
foreign key (writerIdx) references member(idx)
);
CREATE TABLE likes(
idx INT AUTO_INCREMENT PRIMARY KEY,
memberIdx INT,
postIdx INT,
FOREIGN KEY (memberIdx) REFERENCES member(idx),
FOREIGN KEY (postIdx) REFERENCES post(idx)
);위와 같은 테이블이 주어졌을 때, 각 게시글 별 좋아요의 수를 확인하는 SQL과 게시글 조회 화면에 게시글 번호 게시글 작성자 게시글 내용 게시글 작성 시간 게시글의 좋아요 수가 나오는 SQL을 만들자
# 각 게시글별 좋아요의 수를 확인하는 SQL
SELECT postIdx, count(idx) from likes
group by postIdx;
# 게시글 조회 화면에 다음과 같이 나올 수 있는 SQL
# [게시글 번호] [게시글 작성자] [게시글 내용] [게시글 작성 시간] [게시글의 좋아요 수]
select post.idx, member.nickname , post.contents, post.createdAt, count(likes.idx) from post
inner join member on post.writerIdx = member.idx
left join likes on post.idx = likes.postIdx
group by postIdx
order by post.idx asc;반정규화
이미 정규화된 데이터베이스에서 성능을 개선하기 위해 사용
Alter TABLE post ADD COLUMN likesCount Int default 0;
Insert into likes(memberIdx, postIdx) values (1,1);
update post set likescCount = likesCount + 1 WHERE idx = 1;- 일부 쓰기 성능의 손실을 감수하고 데이터를 묶거나 데이터의 복제 사본을 추가함으로써 데이터베이스의 읽기 성능을 개선
- 반 정규화할 때 반드시 데이터 일관성을 유지할 수 있는 장치가 필요
DB 서버 부하 테스트
JMeter
실습 준비
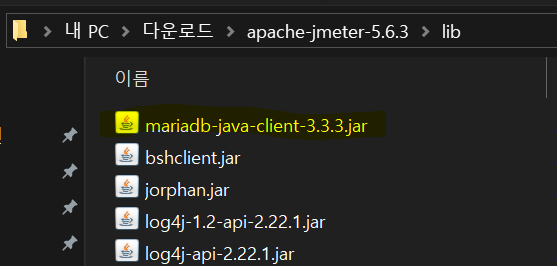
DB 컨넥터 추가
apache-jmeter-5.6.3\lib폴더에mariadb-java-client-3.3.3jar파일 추가하기
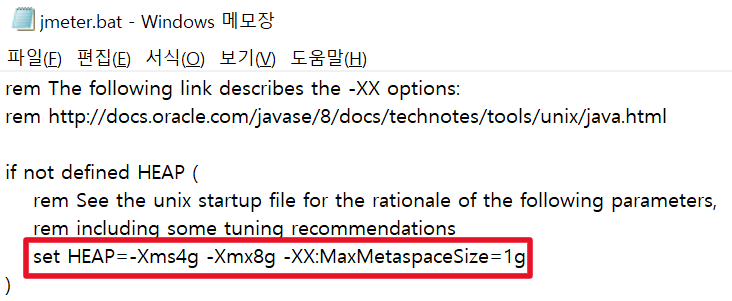
원활한 실습 환경을 위해 jmeter.bat파일 수정
set HEAP=-Xms1g -Xmx1g -XX:MaxMetaspaceSize=256m
-> `set HEAP=-Xms4g -Xmx8g -XX:MaxMetaspaceSize=1g
apache-jmeter-5.6.3\bin 폴더에서 jmeter.bat파일을 찾아 실행
설정
-
Test Plan 우클릭 -> Add -> Threads -> Thread Group
Number of Thread : 접속자 수 100
Ramp-up period : 접속자가 접속하는 시간 1
Loop Count : 반복 횟수 1 -
Thread Group 우클릭 -> Add -> Config Element -> JDBC Connection Configuration
Variable Name for created pool : dbpool
Validation Query : select 1
Database URL : jdbc:mariadb://[DB 서버 IP 주소]:3306/[DB 이름]
JDBC Driver class : org.mariadb.jdbc.Driver
Username : DB 서버에 접속할 ID
Password : DB 서버에 접속할 PW -
Thread Group 우클릭 -> Add -> Sampler -> JDBC Request
Variable Name of Pool declared in JDBC Connection Configuration : dbpool
Query Type : Select Statement
Query : SELECT * FROM member; -
Test Plan 우클릭 -> Listener -> View Result Tree
-
Test Plan 우클릭 -> Listener -> Summary Report
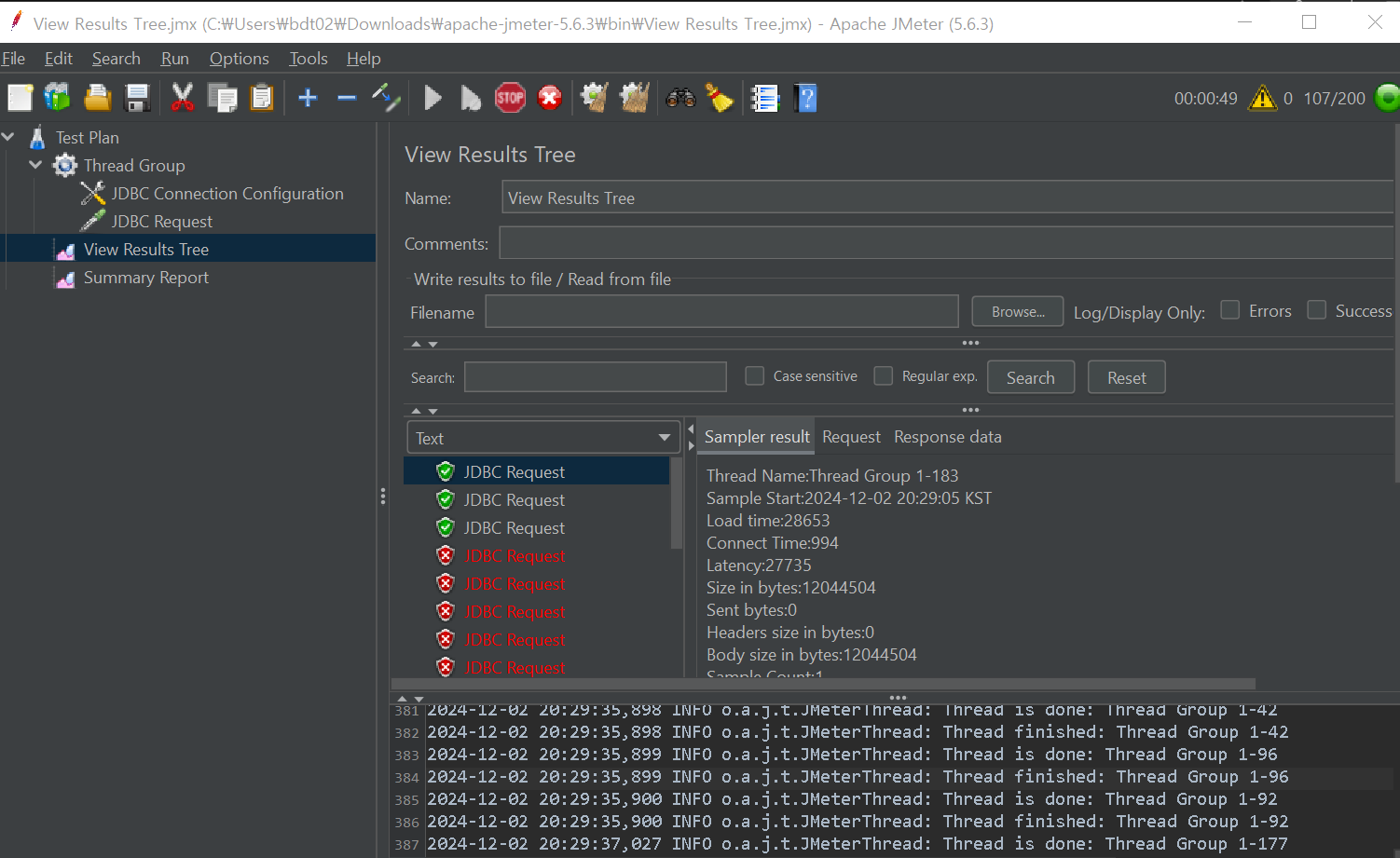
실습 화면
Thread Group의 Number of Threads (users)를 바꿔가면서 실험해보자
서버 최대 접속자 수 설정 확인
SHOW variables LIKE 'max_connections';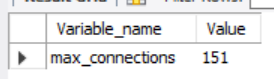
#서버 최대 접속자 수 설정
SET global max_connections = 100;서버의 설정은 sql로 하기보다는 서버 설정 파일을 수정할 것(나중에 서버를 재시작했을 떄 설정값이 달라질 수 있으므로)
/etc/mysql/mariadb.conf.d/50-server.cnf #해당 파일을 통해서 수정 가능
max_connections = 200 #맨 앞에 주석을 제거하고 숫자 변경해서 저장
systemctl restart mariadb #설정을 바꾸면 적용하는 것 잊지 않기
3-way Handshake
(나중에 내용 추가)
TCP 상태전이도 (TCP 연결 상태의 변화) - 중요
소켓 통신
파일 입출력 스트림 : 하드디스크와 프로그램 사이의 통로를 만들어서 데이터를 주고받는 것
네트워크 입출력 스트림 : 소켓 통신, 랜카드와 프로그램 사이의 통로를 만들어 데이터를 주고받는 것
실습
haproxy로 DB 서버 부하분산
가상머신 3대 준비
| 가상 머신 | cpu | ram | |
|---|---|---|---|
| 1대 | 1 | 1 | haproxy 설치 |
| 2대 | 1 | 1 | mariadb-server 설치 |
mariadb 서버
-
mariadb 여러대 설정할 때 문제점
-> mariadb 바인드 주소 설정vi /etc/mysql/mariadb.conf.d/50-server.cnf
27번 라인에 있는 설정을 다음처럼 변경
bind-address = 0.0.0.0
-
mariadb 실행
systemctl restart mariadb
-
mariadb 실행 확인
systemctl status mariadb
apt install -y net-tools
netstat -anlp | grep :3306 -
DB 서버 초기화
mysql_secure_installation
엔터
엔터
엔터
qwer1234
qwer1234
엔터
엔터
엔터
엔터 -
데이터 베이스 생성
mariadb -u root -p 클라이언트 프로그램을 실행하는 것
qwer1234
CREATE DATABASE sjb;
exit -
원격 접속용 사용자 추가
mariadb -u root -p
CREATE USER 'sjb'@'%' IDENTIFIED BY 'qwer1234';
GRANT ALL PRIVILEGES ON sjb.* TO 'sjb'@'%';
FLUSH PRIVILEGES;
haproxy 서버
- haproxy 설정
vi /etc/haproxy/haproxy.cfg
listen stats
bind *:9000
mode http
option dontlog-normal
stats enable
stats realm Haproxy\ Statistics
stats uri /stats
frontend mariadb_frontend
bind *:3306
default_backend mariadb_backend
backend mariadb_backend
balance roundrobin
option tcp-check
server mariadb1 10.10.10.12:3306 check
server mariadb2 10.10.10.13:3306 check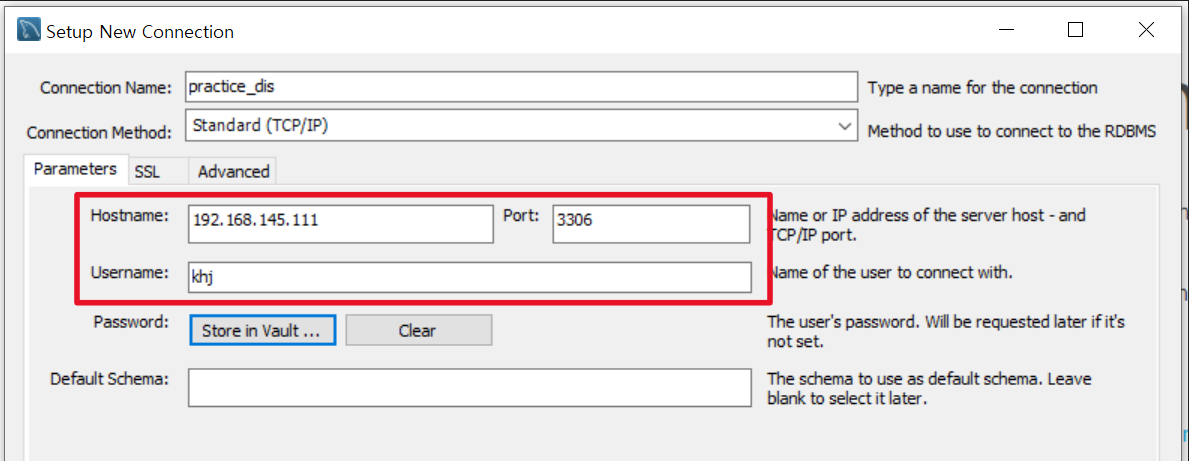
MySQL Workbench의 Hostname에는 haproxy 서버의 IP를 적어야한다.
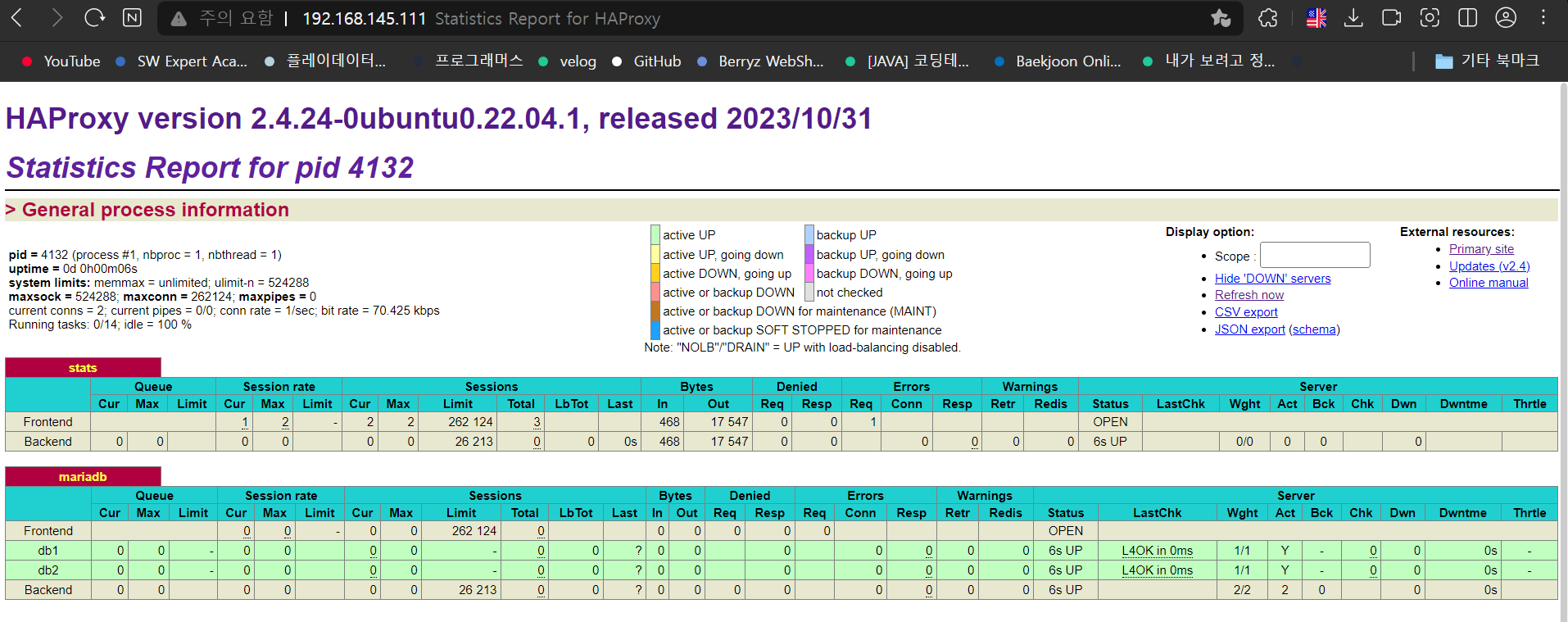
haproxy서버 IP:9000/stats 에 접속했을 때 모습
+)
데이터베이스 import 하는 방법
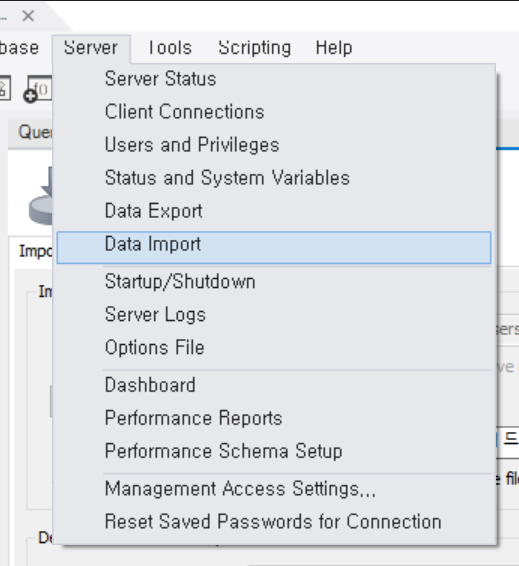
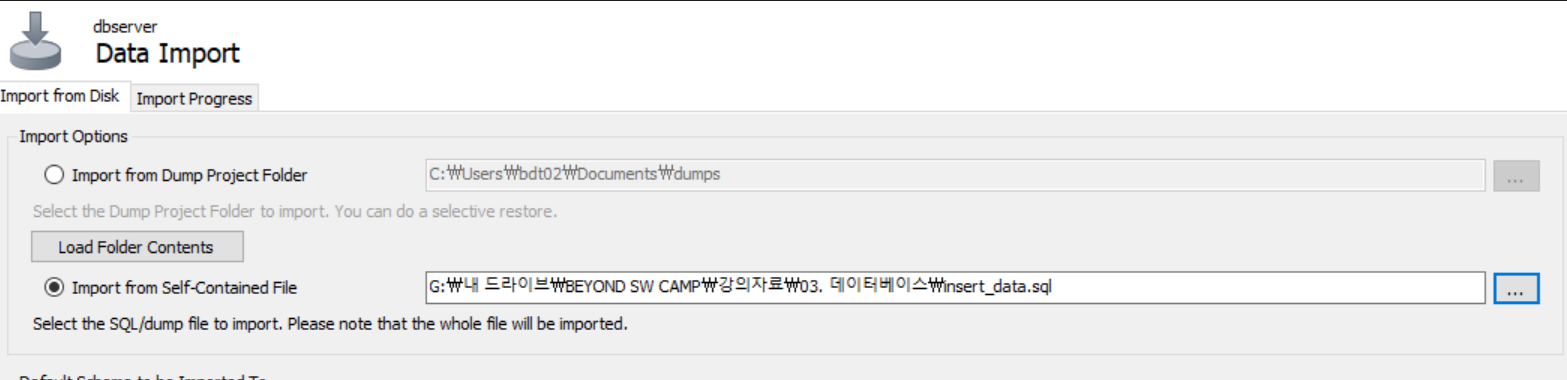
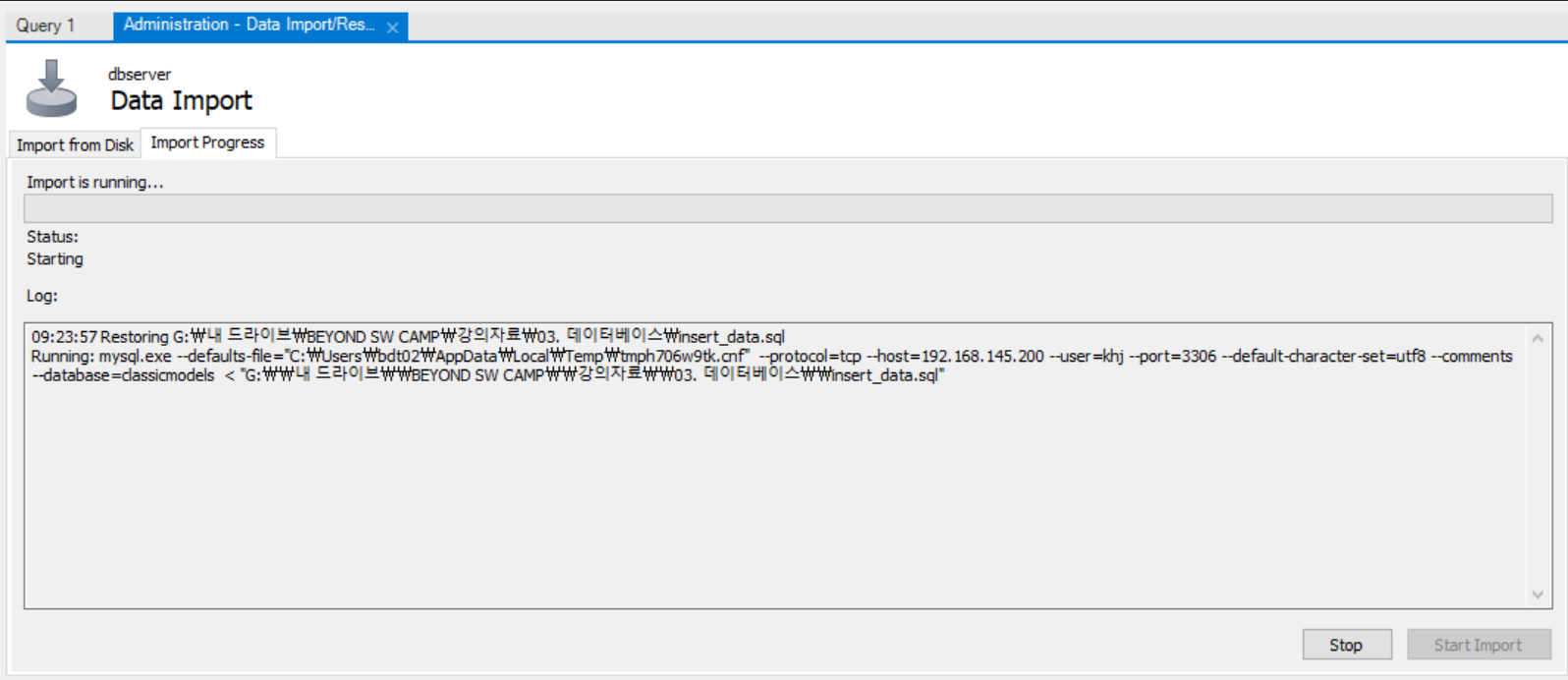
server > Data Import > Import from Self-Contained File > Import Progress > Start Import
