
UCB
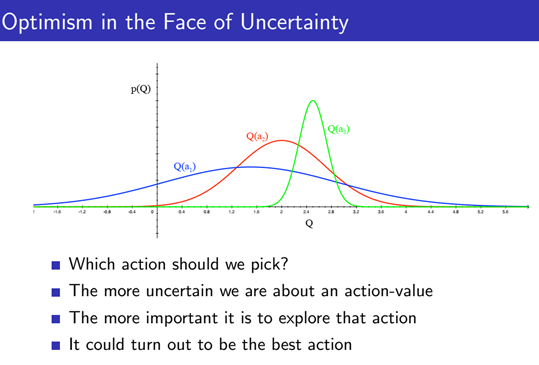
그림 1.은 3개의 밴딧 머신 (Bandit Machine=슬롯 머신)이 있을때, 각 밴딧 머신의 손잡이 (arm)를 눌러 얻을 수 있는 reward (Q)의 분포를 나타냅니다 (a_1: 파란색 , a_2: 빨간색, a_3:초록색).
그림에 대해 간단하게 예를 들면 a_3는 매번 누를 때마다 30만원에서 50만원사이의 돈을 받을 수 있다고 보고, a_1의 경우 어떨때는 돈을 잃거나 또는 200만원을 받아 일확천금할 수 있다고 받을 수 있다고 생각하시면 됩니다.
직관적으로 a_3 의 신뢰구간 (Confidence Interval)이 매우 짧은 것을 볼 수 있으며, 불확실환 상황 속에서도 a_3를 선택하면 높은 reward (Q) 를 어느정도 보장 받을 수 있음을 볼 수 있습니다.

그러나 그림 2와 같이 a_1과 a_2을 선택하면 a_3의 우측에 더 높은 reward을 받을 수 있는 확률이 있다는 것을 할 수 있습니다.
만약 이와 같은 상황에서 Exploitation, 즉 현재 time step에서 좋아 보이는 (cumulative sum of future reward 가 높은) 머신을 선택하게 되고, 이와 같은 과정을 반복하면, 더 높은 포텐셜을 갖고 있는 a_1을 탐험해 보지 못하고, 결국 sub optimal에 도달 할 수 밖에 없습니다. 이와 같은 문제를 해결하기 위해 UCB를 사용해 exploration을 장려합니다.
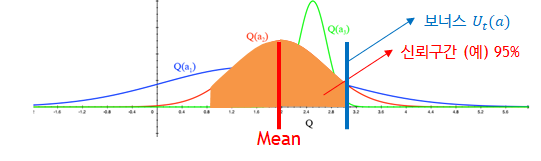
그림 3.과 같이 이와 같은 확률 분포는 정 가운데를 평균 (mean)으로 볼 수 있으며, 신뢰 구간을 어떻게 설정 하느냐에 따라 Upper confidence bound (UCB) U(a) 를 설정할 수 있습니다.
신뢰구간이 X% 라고 가정 하면, 보너스 구간 포함에서 리워드 Q(a) + U(a) 를 예측 할 수 있습니다.
reward 평균 100만원, 신뢰구간 X%의 보너스 구간 (+50만원) = 150만원
즉, 그림2와 같이 a_1 (파란색)은 평균이 a_3 (초록색) 비해 작지만, 같으면서 넓은 신뢰구간 (예: 95%)를 사용했을 때의 UCB가 더 크므로, 불확실성에 기대 더 높은 리워드를 받을 수 있다고 생각해 a_1을 선택합니다.
위와 같은 방법론을 기반으로 여러 가능한 action (어떤 bandit machine을 선택) 중 하나를 선택 하고자 할 때에는 그 action이 UCB를 최대화 하는 것을 선택하도록 합니다.
