지난 시간 복습
- 언어 모델 발전 현황
- Seq2Seq: 인코더, 디코더 개념 도입. 다수 입력 다수 출력 데이터 처리(예: 번역). 고정된 문맥 벡터 사용
- Attention Mechanism: 변경 시점마다의 문맥 벡터 사용
- Transformer
- BERT / GPT 등의 사전학습 모델
- 업스트림 태스크: 빅데이터로 공부하는 과정 → 학생이 시험을 위해 공부하는 것(지식을 채우는 것)이라 생각하기
- 다운스크림 태스크: 학습한 모델이 태스크(task; 업무)를 수행하는 과정 → 시험을 볼 때 머리를 쓰는 과정이라고 생각하기
- 종류
- 문서분류: 문서나 문장을 입력 → 어떤 범주에 속하는지 확률 값 반환
- 자연어 추론: 두 문장 사이의 관계 확률값
- 객체명 인식: 입력 받은 자연어가 단어별로 기관명, 인명, 지명 등 어떤 개체명 범주에 속하는지 확률값 반환 → 의료 데이터, 법률 데이터에 많이 사용 → 특정 용어가 법률용/의료용임을 태깅: 객체명 인식을 먼저 돌리고 이후 데이터 학습하면 더 좋음
- 질의응답: 자연어(질문+지문) 입력 → 각 단어가 정답의 시작일 확률값 & 정답의 끝일 확률값 반환
- 문장 생성: 자연어 입력 → 다음에 올 단어 확률값 반환
- 종류
- 언어 모델의 변화
- 시계열 데이터/텍스트 데이터 가장 기본 모델: RNN
- 장기기억에 대한 손실 문제
- LSTM: 메모리 셀 도입
- 연산량이 많아지는 문제
- GRU: 연산량 문제 해결
- RNN 기반이라 근본적인 장기기억 손실 문제 해결 불가 → Seq2Seq 등장
- Seq2Seq
- 인코더: 입력 문장의 단어를 '순차적으로 받아' 압축 값(context vector) 생성
- 디코더: 압축 값을 입력으로 받아 풀어낸 뒤 '순차적으로' 출력
- 단점: 전체 데이터를 압축해 하나의 고정된 컨텍스트 벡터로 넣기 때문에 정보 손실이 발생
- 모든 문장에 동일하게 고정된 Context vector 사용
- Attention Mechanism
- 모든 문서에 대해 동일한 context vector가 아닌 현재 나의 단어에 집중해 그때 그때 context vector를 만듦 → 분석하고자 하는 단어와 관련된 단어에 가중치를 줌 → 현재 단어 학습 과정에서 중요한 정보에 더 집중해 정보 손실에 대해 가중치로 어느 정도 보완
- 여전히 RNN 알고리즘 기반이기 때문에 가지는 태생적인 문제가 남아 있음 → Sequential 특성으로 인해 순서대로 하나씩 들어가야 함, Vanishing Gradient로 인한 정보 손실
- Transformer
- Positional Vector → 병렬 연산 가능: 속도, 성능 향상
- RNN 기반 모델이 태생적으로 가지는 문제(Sequential한 속성 때문에 연산 시간 많이 소요)를 RNN을 벗어남으로서 해결
- BERT: 인코더만 사용 / GPT: 디코더만 사용
- 시계열 데이터/텍스트 데이터 가장 기본 모델: RNN
- 실습
- 감정분석
- 빈칸 채우기
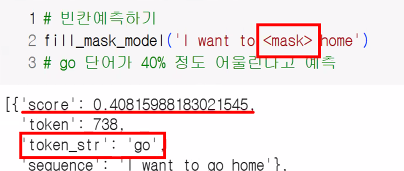
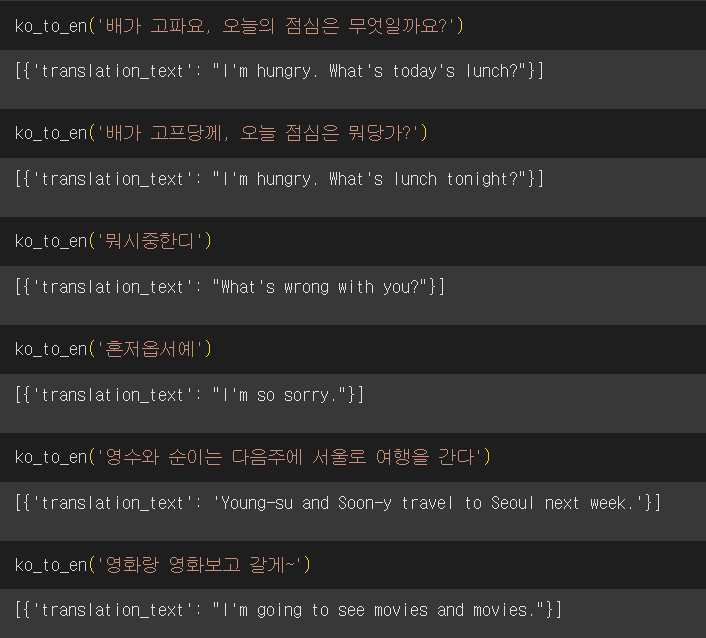
- 번역
- 요약
- 주의사항: 요약 모델이 사용한 바로 그 토크나이저를 가져와 사용해야 함 → AutoTokenizer
- AutoModelForSeq2SeqLM
실습: Vit를 활용한 이미지 분석
- 콩잎 이미지 분류
- 이미지 데이터 결과 확인
- 콩잎의 건강 상태를 알아보는 모델을 만들어보자
ViT (Vision Transformer) 파인튜닝
- 트랜스포머 기반 모델
- 처리 방법
- 원본 이미지를 격자 형태로 쪼개서 서브 이미지를 만듦
- 왜 쪼개서 만드나요? transformer가 자연어 처리 모델이기 때문에 비슷한 원리로 학습시키기 위함
- 쪼개진 이미지를 선형으로 투영
- 투영된 데이터를 자연어 처리하는 것처럼 ViT 모델 입력으로 사용
- 원본 이미지를 격자 형태로 쪼개서 서브 이미지를 만듦
데이터 로딩
# 허깅페이스에 저장된 데이터 로딩
from datasets import load_dataset
data_beans = load_dataset("beans")
# 이미지 확인
data_beans["train"][5]["image"]
- 0번 인덱스: angular_leaf_spot → 모자이크병
- 1번 인덱스: bean_rust → 콩곰팡이
- 2번 인덱스: healthy → 건강
학습할 이미지 데이터와 검증/평가할 이미지 데이터 크기를 꼭 맞춰주어야 합니다!
이미지 전처리
- 이미지 사이즈 맞추기
- 각 이미지의 크기가 다를 수 있음
- 어떤 모델을 쓰냐에 따라 맞게 전처리르 해 주어야 함
- 이미지 분석 모델에 따라 전처리 도구를 다르게 사용 → 동일 전처리 도구 불러다 사용하기
- 허깅페이스에서 제공함
from transformers import ViTFeatureExtractor
# 사전에 만들어 둔 이미지 특징추출기 (이미지 임베딩) 다운로드
model_name = "google/vit-base-patch16-224-in21k" #모델이름
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name)- 높이와 너비 확인: (224, 224)
- 정규화 확인: 평균, 표준편차 0.5 정규화되어 있음
- 사전학습 모델이 사용한 프레임워크인 PyTorch에 맞는 데이터 타입인 Tensor로 변경해야 함
- 사전학습 모델이 사용한 도구를 그대로 사용해 주는 것이 좋음!
# 전처리: 함수 정의
def transform (example_batch):
inputs = feature_extractor([x for x in example_batch["image"]], return_tensors="pt")
inputs["labels"] = example_batch["labels"]
return inputs
# 사용자 정의 함수 적용
prepared_data = data_beans.with_transform(transform)
prepared_data # feature_extractor를 통해 전처리된 결과가 담겨 있음DatasetDict({
train: Dataset({
features: ['image_file_path', 'image', 'labels'],
num_rows: 1034
})
validation: Dataset({
features: ['image_file_path', 'image', 'labels'],
num_rows: 133
})
test: Dataset({
features: ['image_file_path', 'image', 'labels'],
num_rows: 128
})
})# 변환 후 이미지 크기
prepared_data["train"][5]["pixel_values"].shape # torch.Size([3, 224, 224])
# 변환 전 이미지 크기와 비교
data_beans["train"][5]["image"].size # (500, 500)- 변환 전 500, 500 크기였던 이미지가 224, 224로 변환된 것을 확인
학습 및 검증
- 배치 단위로 넣기
- 콩잎 데이터 약 1000장
- 쪼개서 학습: 효율적인 메모리 사용을 위하여
- 평가방법 함수 지정
- 사전 학습 모델 불러오기
- 모델의 하이퍼파라미터 정의 → 클래스(TrainingArguments)
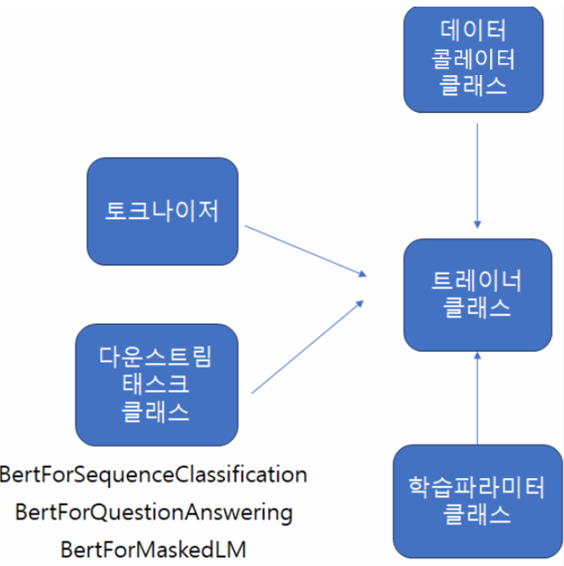
- 위dml 4개를 모두 모아 학습: Trainer 클래스
- 학습 클래스: Trainer
데이터 콜레이터(data collator) 클래스, 데이터 정의, 평가방법 지정, 모델 정의, 모델의 하이퍼파라미터 정의
데이터 콜레이터는 데이터셋 요소들의 리스트를 입력으로 사용하여 배치를 형성하는 객체입니다. 이러한 요소들은 train_dataset 또는 eval_dataset의 요소들과 동일한 타입 입니다. 배치를 구성하기 위해, 데이터 콜레이터는 (패딩과 같은) 일부 처리를 적용할 수 있습니다. DataCollatorForLanguageModeling과 같은 일부 콜레이터는 형성된 배치에 (무작위 마스킹과 같은) 일부 무작위 데이터 증강도 적용합니다.
# 데이터 준비
import torch
def coll_fn(batch): # 배치 단위 함수
return {
"pixel_values": torch.stack([x["pixel_values"] for x in batch])
, "labels": torch.stack([x["label"] for x in batch])
}
# 평가방법 지정
!pip install evaluate
import evaluate
metric = evaluate.load("accuracy")
import numpy as np
def compute_metrics(p):
return metric.compute(
predictions=np.argmax(p.predictions, axis=1)
, references=p.label_ids
)
data_beans["train"].features["labels"].names['angular_leaf_spot', 'bean_rust', 'healthy']# 사전학습된 모델 불러오기
from transformers import ViTForImageClassification
label_names = data_beans["train"].features["labels"].names
model = ViTForImageClassification.from_pretrained(
model_name
, num_labels=len(label_names)
, id2label = {str(i): c for i, c in enumerate(label_names)}
, label2id = {c: str(i) for i, c in enumerate(label_names)}
)- 학습에 사용되는 파라미터 작성
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./vit-base-beans-demo-v5" # 출력 디렉토리
, per_device_train_batch_size=16 # 학습 배치 크기
, per_device_eval_batch_size=16 # 평가 배치 크기 (생략 가능하지만 명시 권장)
, num_train_epochs=4 # 전체 학습 에폭 수
, learning_rate=2e-4 # 학습률
, eval_strategy="steps" # 평가 전략 ("no", "epoch", "steps") → 버전에 따라 'evaluation_strategy="steps"'로 적어야 할 수도 있음
, eval_steps=100 # 평가 주기 (steps 단위)
, save_steps=100 # 체크포인트 저장 주기
, logging_steps=10 # 로그 출력 주기
, save_total_limit=2 # 체크포인트 최대 개수
, fp16=True # GPU가 A100, V100 등이면 True (없으면 False)
, remove_unused_columns=False # Trainer가 col 삭제 방지
, report_to="tensorboard" # 로깅 백엔드 설정 ("none", "wandb", "tensorboard")
, load_best_model_at_end=True # 가장 좋은 모델 저장
, metric_for_best_model="accuracy" # 가장 좋은 모델 기준 metric
, greater_is_better=True # metric 클수록 좋다고 간주 (예: accuracy)
, push_to_hub=False # 🤗 Hub에 업로드 안 함
)# 학습 클래스(Trainer)
from transformers import Trainer
trainer = Trainer(
model=model # 사전에 학습된 모델
, args=training_args # 학습 파라미터(속성 값)
, data_collator=coll_fn # 배치 크기만큼 데이터를 모아서 넣어주는 역할
, compute_metrics=compute_metrics # 정확도를 계산하는 함수
, train_dataset=prepared_data["train"] # 훈련용 데이터
, eval_dataset=prepared_data["validation"] # 검증용 데이터
, tokenizer=feature_extractor # 전처리 정보연결
)
# 학습 실시
train_result = trainer.train() # 학습 결과를 변수에 저장
trainer.save_model() # 학습된 모델을 자동으로 저장
trainer.log_metrics("train", train_result.metrics) # 학습 결과(accuracy)를 로깅
trainer.save_metrics("train", train_result.metrics) # 학습 결과를 저장
trainer.save_state() # 최종 trainer 상태 저장[260/260 01:40, Epoch 4/4]
Step Training Loss Validation Loss Accuracy
100 0.081400 0.212509 0.909774
200 0.012700 0.027433 0.992481
***** train metrics *****
epoch = 4.0
total_flos = 298497957GF
train_loss = 0.1211
train_runtime = 0:01:44.21
train_samples_per_second = 39.687
train_steps_per_second = 2.495모델 평가
pred = trainer.evaluate(prepared_data["test"])
trainer.log_metrics("test", pred)
trainer.save_metrics("test", pred)[8/8 00:01]
***** test metrics *****
epoch = 4.0
eval_accuracy = 0.9375
eval_loss = 0.2048
eval_runtime = 0:00:01.55
eval_samples_per_second = 82.171
eval_steps_per_second = 5.136모델 활용
- huggingface에 업로드하기 → 토큰 발급 필요
- Write 모드로 발급받기
- 우측 상단 프로필 → Settings → Access Tokens
# 허깅페이스 저장소에 모델 업로드
import huggingface_hub
huggingface_hub.login()
# 저장소에 업로드 시 함께 기입할 정보 작성
kwargs = {
"finetuned_from": model.config._name_or_path # 파인튜닝에 활용한 사전학습 모델
, "tasks": "image-classification" # task 종류
, "dataset": "beans" # 활용한 데이터셋
, "tags": ["image-classification","ViT"]
}- 이후 trainer.push_to_hub("허깅페이스 유저명", **kwargs) 입력하면 아래와 같은 실행 결과 출력
Processing Files (4 / 4) : 100%
343MB / 343MB, 39.0MB/s
New Data Upload : 100%
343MB / 343MB, 39.0MB/s
...ase-beans-demo-v5/model.safetensors: 100%
343MB / 343MB
...vents.1754014146.0edff376c966.531.0: 100%
11.5kB / 11.5kB
...vents.1754014254.0edff376c966.531.1: 100%
411B / 411B
...ase-beans-demo-v5/training_args.bin: 100%
5.37kB / 5.37kB
CommitInfo(commit_url='https://huggingface.co/허깅페이스 유저명/vit-base-beans-demo-v5/commit/★', commit_message='{허깅페이스 유저명}', commit_description='', oid='★', pr_url=None, repo_url=RepoUrl('https://huggingface.co/{허깅페이스 유저명}/vit-base-beans-demo-v5', endpoint='https://huggingface.co', repo_type='model', repo_id='{허깅페이스 유저명}/vit-base-beans-demo-v5'), pr_revision=None, pr_num=None)# 내 저장소에 있는 모델 불러와 사용하기
from transformers import pipeline- my_beans_model = pipeline(task = "image-classification", model = "허깅페이스 유저명/vit-base-beans-demo-v5") 하면 아래와 같이 불러올 수 있음
config.json: 100%
796/796 [00:00<00:00, 39.5kB/s]
model.safetensors: 100%
343M/343M [00:06<00:00, 90.9MB/s]
preprocessor_config.json: 100%
353/353 [00:00<00:00, 6.14kB/s]
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Device set to use cuda:0data_beans["test"][0]["image"]
- 모자이크병 콩잎을 정확히 예측할까?
my_beans_model(data_beans["test"][0]["image"])[{'label': 'angular_leaf_spot', 'score': 0.9849727153778076},
{'label': 'bean_rust', 'score': 0.011132474057376385},
{'label': 'healthy', 'score': 0.003894711844623089}]→ 잘 예측했음
# 인터넷 검색한 이미지 url로 예측
my_beans_model("https://search.pstatic.net/common/?src=http%3A%2F%2Fblogfiles.naver.net%2FMjAyNDA3MjJfMTE5%2FMDAxNzIxNjMwODc1MTQ3.0L10f5D9EynxZVJKGdriOXUl5C3wNSwK8DBQZ7l_nHkg.lYmapjDiAYb28yKCRGTqPrj-7TcSaw5uOWi-t5YNH1Ag.JPEG%2Fimage_%25A3%25A813%25A3%25A9.jpeg&type=a340")[{'label': 'angular_leaf_spot', 'score': 0.9862239360809326},
{'label': 'healthy', 'score': 0.006900676526129246},
{'label': 'bean_rust', 'score': 0.006875277031213045}]- url 이미지:

my_beans_model("https://search.pstatic.net/common/?src=http%3A%2F%2Fblogfiles.naver.net%2FMjAyNDAzMzFfNDAg%2FMDAxNzExODc3OTk4Njcz.5lxBBH1JHqzrFl26uamEudTD0YAPityV2tB0sKQaj_cg.ab_eF5Ij3z7HXC2mGbamsSStLLmsevvoQh4aWPfmuKcg.PNG%2F1.png&type=a340")[{'label': 'bean_rust', 'score': 0.7370878458023071},
{'label': 'healthy', 'score': 0.24851727485656738},
{'label': 'angular_leaf_spot', 'score': 0.014394894242286682}]- url 이미지:

my_beans_model("https://search.pstatic.net/common/?src=http%3A%2F%2Fblogfiles.naver.net%2FMjAyMjA3MjNfMjA3%2FMDAxNjU4NTYwODU0MTQ1.IHAQwON7jFfUwJi-eSwBHbqdamBI1t8Nr2Aojdh1ABog.ntqcZlMw8zoWllRn-LZ9TXlXX5BnSM4bOmuizRfrrx8g.JPEG.ghskal%2F20220723%25A3%25DF160903.jpg&type=a340")[{'label': 'healthy', 'score': 0.8771871328353882},
{'label': 'bean_rust', 'score': 0.08200732618570328},
{'label': 'angular_leaf_spot', 'score': 0.04080557823181152}]- url 이미지:

# 사실 학습한 데이터 수가 적어서(1000장) 그렇게 잘 예측하지는 못할수도 있음
data_beans.shape{'train': (1034, 3), 'validation': (133, 3), 'test': (128, 3)}실제 프로젝트 때는 훨씬 더 많은 데이터를 학습시키는 것을 추천!
실습: Transformer(Bert, KoBert, KoElectra, KoBart)
- 네이버 영화 리뷰 데이터 활용
학습목표
- 영화리뷰 데이터 감성분류
- Transformer, BERT 기반 모델 활용
3가지 타입의 한국어 언어모델
Encoder 중심 모델 : BERT 계열
| 모델명 | 개발자 | 학습데이터 | Tokenizer | 단어수 | 파라미터수 |
|---|---|---|---|---|---|
| KorBERT | ETRI | 뉴스/백과사전 23GB | Mophologpy WordPiece | 30,349 (Mophologpy) 30,797 (WordPiece) | 110M |
| KoBERT | SKT | 위키피디아 20M | Sentencce-Piece | 8,002 | 92M |
| HanBERT | 투블럭AI | 일반/특허문서 70GB | Moran | 54,000 | 128M |
| KoreALBERT | 삼성SDS | 위키피디아 나무위키 뉴스 책 줄거리 요약 등 43GB | Sentencce-Piece | 32,000 | 12M, 18M |
| KLUE-BERT | Klue project | 모두의말뭉치 CC-100-Kor 나무위키 뉴스/청원 등 63GB | Morpheme -basedsubword | 32,000 | 111M |
| KRBERT | 서울대 | 위키피디아 뉴스 | WordPiece | 16,424 (Character) 12,367 (Subcharacter) | 99M (Character) 96M (Subcharacter) |
| DistillKoBERT | 개인 (박장원) | 위키피디아 나무위키 뉴스 등 | Sentence-Piece | 30,522 | 27.8M |
| KcBERT | 개인 (이준범) | 네이버뉴스 댓글 대댓글 | Word-Piece | 30,000 | 109M |
| KcELECTRA | 개인 (이준범) | 네이버뉴스 댓글 대댓글 | Word-Piece | 30,000 | 124M |
| KoBigBird | 개인 (박장원) | 위키피디아 뉴스 모두의말뭉치 Common Crawl 등 | Word-Piece | 32,500 | 113.8M |
Decoder 중심 모델 : GPT 계열
| 모델명 | 개발자 | 학습데이터 | Tokenizer | 단어수 | 파라미터수 |
|---|---|---|---|---|---|
| KoGPT2 | SKT | 위키피디아 뉴스 나무위키 네이버영화리뷰 한국어 Common Crawl 152M | Character BPE | 51,200 | 125M |
| KoGPT-Trinity | SKT | Ko-DATA dataset 1.2B | - | 51,200 | 1.2B |
| HyperCLOVA | NAVER | 뉴스 카페/블로그/지식in 웹문서 네이버수집문서 (댓글 등) 모두의 말뭉치 위키피디아 등562B | Morpheme-aware byte-level BPE | - | 82.0B |
| KoGPT | Kakaobrain | 200B | - | 64,512 | 6.0B |
Encoder-Decoder 모델 : Seq2Seq 계열
| 모델명 | 개발자 | 학습데이터 | Tokenizer | 단어수 | 파라미터수 |
|---|---|---|---|---|---|
| KoBART | SKT | 위키피디아 뉴스 모두의말뭉치 청와대 국민청원 등 0.27B | Character BPE | 30,000 | 124M |
| KE-T5 | KETI | 한국어와 영어 데이터가 7:3의 비율인 데이터 30GB | Sentence-Piece | 64,000 | 247M |
| ET5 | ETRI | 위키피디아 뉴스 방송대본 영화 드라마 대본 등 136GB | Sentence-Piece | 45,100 | 60M |
| EXAONE | LG AI연구원 | 말뭉치 600B 이미지,텍스트 Pair 데이터 250M이상 | - | - | 300B |
Naver sentiment movie corpus
- GitHub
- 각 파일은 id, document, label 세 개의 열로 구성
- id: 네이버에서 제공하는 리뷰 아이디
- document: 실제 리뷰
- label: 리뷰의 감정 클래스(0: 부정적, 1: 긍정적)
# 데이터 불러오기
import numpy as np
import pandas as pd
train_data = pd.read_csv("./data/ratings_train.txt", sep="\t")
test_data = pd.read_csv("./data/ratings_test.txt", sep="\t")
train_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150000 entries, 0 to 149999
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 150000 non-null int64
1 document 149995 non-null object
2 label 150000 non-null int64
dtypes: int64(2), object(1)
memory usage: 3.4+ MB# 결측치 제거
train_data.dropna(inplace=True)
test_data.dropna(inplace=True)
train_data.head() id document label
0 9976970 아 더빙.. 진짜 짜증나네요 목소리 0
1 3819312 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 1
2 10265843 너무재밓었다그래서보는것을추천한다 0
3 9045019 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 0
4 6483659 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 ... 1텍스트 전처리
- 한글, 띄어쓰기만 두고 나머지는 삭제
- 전처리 후 공백만 남아 있는 리뷰 삭제
- 정규표현식 규칙
^: 부정(NOT)가-힣: 한글 전체 범위\s: 공백 문자(스페이스, 탭, 줄바꿈 등)
- replace 함수
.replace("바꾸고 싶은 내용", "바꿀 내용", regex=True)
=regex=True: 정규표현식 기반으로 치환하겠다는 의미
# 한글과 공백을 제외한 나머지 전부 삭제: 영어, 숫자, 특수문자 등
# 라이브러리를 불러오지 않고도 정규표현식 사용 가능: .replace 이용
train_data["document"] = train_data["document"].str.replace("[^가-힣\s]", "", regex=True)
# 정제 후 아무 내용이 없는 문장들은 제거: '공백이 아니면 담아주세요'를 코드로 작성하기
train_data = train_data[train_data["document"].str.strip() !='']
# test 데이터에도 동일한 과정 진행
test_data["document"] = test_data["document"].str.replace("[^가-힣\s]", "", regex=True)
test_data = test_data[test_data["document"].str.strip() != '']
train_data.head()id document label
0 9976970 아 더빙 진짜 짜증나네요 목소리 0
1 3819312 흠포스터보고 초딩영화줄오버연기조차 가볍지 않구나 1
2 10265843 너무재밓었다그래서보는것을추천한다 0
3 9045019 교도소 이야기구먼 솔직히 재미는 없다평점 조정 0
4 6483659 사이몬페그의 익살스런 연기가 돋보였던 영화스파이더맨에서 늙어보이기만 했던 커스틴 던... 1train_data.shape(148385, 3)→ 1,610개의 데이터가 전처리 후 공백만 남아 있어 삭제됨
형태소 분석 후 다시 연결
- BERT는 알아서 토큰화 진행: 띄어쓰기 기준(영어 모델이기 때문)
- BERT는 코퍼스를 받아서 처리하는 모델(코퍼스 형태로 입력 받기를 원함)
- 한글은 교착어 특성 상 단순 띄어쓰기 기준으로 토큰화를 진행하면 정확도가 떨어짐: 조사, 어미 등의 특성 → 형태소 분석을 진행해야 정확도가 올라가게 된다
- 이대로 넣으면 정규화가 적용되지 않은 날것의 단어들이 들어감 → 어떻게 할까?
- 형태소 분석 후 다시 문장으로 만들어 BERT에 입력
- BERT가 기대하는 것은 한 줄의 문자열이기 때문에 다시 문장으로 합쳐야 함
- 형태소 분석 후 다시 문장으로 만들어 BERT에 입력
# 형태소 분석: KoNLPy 형태소 분석기 도구 → Okt
# Okt는 리뷰, Social Media, 댓글 등에서 사용하는 인터넷 용어 및 신조어에 강함
!pip install konlpy
import konlpy
from konlpy.tag import Okt
from tqdm import tqdm
# tqdm을 pandas에 연결
tqdm.pandas()
# 형태소 분석기 생성
okt = Okt()
# 토큰화 수행, 어간추출(Stemming) 후 다시 합쳐주기: 람다 함수 사용
train_data["document"] = train_data["document"].progress_map(
lambda x: ' '.join(okt.morphs(x, stem=True)) # 형태소로 분리하고 어간 추출 후 합쳐주는 코드
)
# GPU 기준 5분 소요됨 → 주석으로 실행 시간을 적어주면 좋다고 함100%|██████████| 148385/148385 [04:30<00:00, 549.40it/s]- tqdm의 기존 사용 방법:
for i in tqdm(range()) - for 문을 사용하지 않을 때는 어떻게 쓰나요?
- tqdm을 Pandas에 등록하여 사용:
tqdm.pandas()
- tqdm을 Pandas에 등록하여 사용:
progress_map(): 전체 데이터에 대해 lambda 함수를 적용해줄 때 사용- 쪼개주는 것은 형태소 분석을 위함
- 다시 합쳐주는 건 딥러닝 모델이 원하는 모양으로 만들어주기 위함
- BERT 모델이 문장을 띄어쓰기 기준으로 토큰화하기 때문
- 정규화(norm=True) 사용하는 것도 좋아요
- normalization: 표현 방법이 다른 단어들을 같은 단어로 변경
- '됬다'(됐다의 오기) → '됐다'로 수정될 수 있다고 함
- normalization: 표현 방법이 다른 단어들을 같은 단어로 변경
전처리 결과 파일로 저장하기
- 목적: 재학습 시 전처리 시간을 절약하기 위함
- 토큰화 과정, join 작업은 시간이 오래 걸림
- 나중에 재학습 할 때 전처리 된 데이터를 불러와서 재사용할 수 있음
- pickle
- 파이썬 전용 저장기: save + load 기증을 담당
- DataFrame, list, dict, model 등 파이썬용 객체들을 '그대로' 저장
# 전처리 된 데이터를 구글 드라이브에 저장
import pickle
with open("./data/bert_train_data_rating.pkl", "wb") as f:
pickle.dump(train_data, f)# 저장된 파일 불러오기
import pickle
with open("./data/bert_train_data_rating.pkl", "rb") as f:
train_data = pickle.load(f)
train_data.head()id document label
0 9976970 아 더빙 진짜 짜증나다 목소리 0
1 3819312 흠 포스터 보고 초딩 영화 줄 오버 연기 조차 가볍다 않다 1
2 10265843 너 무재 밓었 다그 래서 보다 추천 한 다 0
3 9045019 교도소 이야기 구먼 솔직하다 재미 는 없다 평점 조정 0
4 6483659 사이 몬페 그 의 익살스럽다 연기 가 돋보이다 영화 스파이더맨 에서 늙다 보이다 하... 1- 데이터 일부만 사용해 학습
- 데이터가 많아 학습 시간이 오래 걸림
- 자원 사용량 많음
# 앞 1만 개, 뒤 1만 개 추려서 사용
train_data2 = pd.concat([train_data[:10000], train_data[-10000:]], ignore_index=True)
train_data2.tail()id document label
19995 6222902 인간 이 문제 지 소 는 뭔 죄인 가 0
19996 8549745 평점 이 너무 낮다 1
19997 9311800 이 게 뭐 요 한국인 은 거들다 먹거리 고 필리핀 혼혈 은 착하다 0
19998 2376369 청춘 영화 의 최고봉 방황 과 우울하다 날 들 의 자화상 1
19999 9619869 한국 영화 최초 로 수간 하다 내용 이 담기다 영화 0훈련용, 검증용 데이터 분리
from sklearn.model_selection import train_test_split
from datasets import Dataset # HuggingFace 전용 데이터셋 포맷
# 훈련용:검증용 = 8:2
train_df, val_df = train_test_split(train_data2, test_size=0.2, random_state=1)
# 문제와 정답으로 분리
# Dataset 클래스는 외부 라이브러리인 Pandas 형태를 받지 않음 → 파이썬 리스트로 변환 후 작업
train_texts = train_df["document"].astype(str).tolist() # pandas.Series → python.list
train_labels = train_df["label"].tolist()
val_texts = val_df["document"].astype(str).tolist()
val_labels = val_df["label"].tolist()
# Hugging Face Dataset으로 변환!
train_dataset = Dataset.from_dict({"document": train_texts, "label": train_labels})
val_dataset = Dataset.from_dict({"document": val_texts, "label": val_labels})
train_datasetDataset({
features: ['document', 'label'],
num_rows: 16000
})KoBERT
- 2019년 SKT Brain 공개
- 한국어 자연어 처리를 위하여 최적화된 BERT 기반 모델
- BERT 모델을 한국어 데이터로 사전 학습하여, 한국어의 미묘한 문맥과 의미를 더 잘 파악할 수 있도록 만들어진 라이브러리
토큰화
# KoBERT 모델을 위한 토큰화 작업
from transformers import BertTokenizer
# huggingface에 등록된 KoBERT 모델 이름 가져오기
checkpoint = "monologg/kobert" # monologg라는 유저가 공개한 KoBERT 모델을 사용하겠다는 뜻
# KoBERT 모델이 사용하는 토큰화 도구 가져오기
tokenizer = BertTokenizer.from_pretrained(checkpoint)
# 토큰화 함수: 데이터셋에 한 줄씩 적용하기 위함
def tokenizer_function (example):
return tokenizer(
example["document"]
, max_length = 128 # 문장의 최대 길이 지정
, padding = "max_length" # 최대 길이보다 짧을 경우 → 0으로 패딩
, truncation = True # 최대 길이보다 길 경우 → 잘라주세요
)tokenizer_config.json: 100%
263/263 [00:00<00:00, 28.1kB/s]
vocab.txt:
77.8k/? [00:00<00:00, 7.18MB/s]
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'KoBertTokenizer'.
The class this function is called from is 'BertTokenizer'.# 토큰화 수행
train_dataset = train_dataset.map(tokenizer_function, batched=True) # map이 인덱싱(한 줄씩 가져옴), 토큰화
val_dataset = val_dataset.map(tokenizer_function, batched=True)Map: 100%
16000/16000 [00:03<00:00, 4390.01 examples/s]
Map: 100%
4000/4000 [00:00<00:00, 4437.25 examples/s]모델 훈련
# 모델 불러오기
from transformers import AutoModelForSequenceClassification # 자연어 분류에 특화된 모델
# 비교용: 지난 번 콩잎에서 쓴 모델
from transformers import AutoModelForImageClassification # 이미지 분류에 특화된 모델
# 모델 로딩: 리뷰 감성분석 → 긍정/부정
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels = 2) # 클래스 2개 (이진분류)config.json: 100%
426/426 [00:00<00:00, 40.5kB/s]
model.safetensors: 100%
369M/369M [00:06<00:00, 19.5MB/s]
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at monologg/kobert and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.학습을 위한 클래스
- Tokenizer(Model에 맞는): 토큰화 도구
- DataCollator: 자동 패딩 도구 묶어서 사용 가능
- Model(Task에 맞는)
- TrainerArguments: 학습 파라미터
- Trainer: 위 4개를 모두 모아 학습시키는 도구
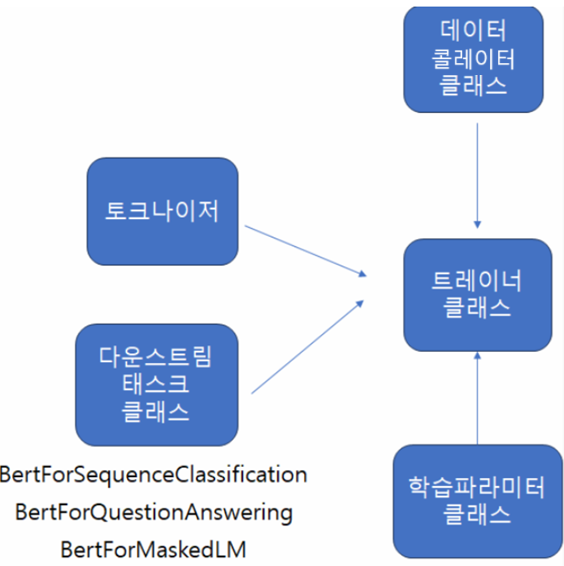
→ 나에게 맞는 모델을 알아서 가져와 처리하고 싶을 때(다양한 모델을 써 보고 싶을 때)는 AutoModelForSequenceClassification
<모델종류>For<태스크종류>형태로 쓴다:- 태스크 종류: SequenceClassification, QuestionAnswering, MaskedLM, ImageClassification 등
from transformers import TrainingArguments, Trainer
from transformers import DataCollatorWithPadding
# 토큰화 결과에 패딩 수행
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 동적 패딩이 가능함
# 우리는 앞에서 이미 패딩을 해서 사실 여기서는 추가 패딩 X
# 여기에서도 패딩이 가능하다는 걸 보여주려고 일부러 가져온 거
# 학습 파라미터 설정
training_args = TrainingArguments(
output_dir='./results/kobert_naver' # 모델 저장 폴더: 훈련된 모델을 어느 폴더에 저장할지 지정 → huggingface에 올리면 사람들이 보니까😅
, learning_rate=2e-5 # 학습률
, weight_decay=0.01 # 학습률 감쇄: 과적합 방지를 위한 weight → 점수가 잘 안 나올 경우 해당 파라미터 없애도 됨
, per_device_train_batch_size=16 # 훈련/검증 데이터 배치 사이즈
, per_device_eval_batch_size=16
, num_train_epochs=1 # 학습 반복 수
, eval_strategy="epoch" # 검증/저장 시기,주기
, save_strategy="epoch" # 매 에폭(epoch)마다 모델을 저장
, load_best_model_at_end=True # 베스트 모델 저장 여부
)
# Trainer: 위에서 만든(준비한) 내용을 하나로 묶어서 실행을 도와줌
trainer = Trainer(
model=model # 모델
, args=training_args
, train_dataset=train_dataset
, eval_dataset=val_dataset
, data_collator=data_collator
, # tokenizer는 이미 해서 collater에 묶었기 때문에 생략
)
# 학습
trainer.train()[1000/1000 06:10, Epoch 1/1]
Epoch Training Loss Validation Loss
1 0.620100 0.602294
TrainOutput(global_step=1000, training_loss=0.6546764831542968, metrics={'train_runtime': 387.5466, 'train_samples_per_second': 41.285, 'train_steps_per_second': 2.58, 'total_flos': 1052444221440000.0, 'train_loss': 0.6546764831542968, 'epoch': 1.0})trainer.train()실행하면 중간에 API 키를 입력하라고 나옴

- wandb는 온라인 대시보드에 훈련 로그를 기록하려면 인증이 필요함
- 안내된 주소에서 로그인 후 API 키를 복사해서 터미널에 붙여 넣으면 됨
- https://wandb.ai/authorize?ref=models 실행 후 로그인하여 API 키 붙여넣기
WandB는 Weights & Biases의 약자로, 머신 러닝 모델 학습 과정을 추적하고 관리하는 데 사용되는 도구입니다. 모델 학습 과정에서 발생하는 다양한 지표(메트릭)들을 시각화하고, 하이퍼파라미터 튜닝을 자동화하며, 실험 결과를 문서화하여 협업을 용이하게 하는 기능을 제공합니다. 쉽게 말해, 머신 러닝 실험을 더 효율적으로 관리하고 더 나은 모델을 더 빠르게 만들 수 있도록 도와주는 플랫폼입니다. 다양한 블로그 글들이 설명하고 있습니다.
추가: 허깅페이스 관련 공부
Dataset.map() 메서드
- 데이터셋 내의 각 예제(또는 배치 단위 예제)에 사용자 정의 함수를 적용하여 데이터를 가공하거나 변환하는 데 매우 유용한 도구
- 머신러닝 데이터 전처리 및 피처 엔지니어링에 핵심적으로 사용됨
- 주요 특징 및 기능:
- 변환 적용
- 데이터셋 예제별로 어떤 파이썬 함수를 적용할 수 있음
- 예: 텍스트 토크나이징, 이미지 크기 조정, 데이터 타입 변환, 새로운 컬럼 추가 등
- 캐싱 기능
map()은 기본적으로 처리된 결과를 캐시 파일로 저장하여, 같은 변환을 반복 실행하지 않고 빠르게 재사용할 수 있어 개발 및 학습 시간 절약에 도움이 됨
- 배치 처리 지원
batched=True옵션과batch_size조절을 통해 여러 예제를 한 번에 처리할 수 있음- 이는 특히 병렬 처리가 가능한 토크나이저 등에서 속도 향상 효과가 큼
- 데이터셋 크기 조절 가능
- 배치 단위로 받아 처리 후 출력 배치 크기를 입력과 달리 조절할 수 있어, 긴 텍스트 분할, 예제 필터링, 데이터 증강 등 데이터셋 크기 변화가 가능
- 메모리 관리
batch_size,writer_batch_size등의 파라미터로 처리 시 메모리 사용량을 제어할 수 있음
- 변환 적용
- 언제 사용하나요?
- 데이터셋 전체에 단 한 번 적용하는 전처리 작업(예: 클리닝, 피처 엔지니어링, 토크나이징, 이미지 리사이징) 시 적합
- 중간 결과를 캐싱해서 중복 계산을 막고 싶을 때
- 데이터셋 크기를 조절하거나 새로운 컬럼/열을 추가하는 변환이 필요할 때
Dataset과IterableDataset의 차이도 중요Dataset.map()은 전체 데이터를 메모리에 올려 한꺼번에 처리 후 새로운Dataset을 반환하지만,IterableDataset.map()은 데이터가 메모리에 다 올라가기 힘든 매우 큰 데이터에 대해 반복(iterate)하며 실시간(on-the-fly)으로 변환을 적용하는 방식
- 추가로 알아두면 좋은 점:
map()함수에 넘기는 처리 함수는 반드시 딕셔너리 형태의 데이터를 입력받고 반환해야 함- 반환 딕셔너리의 각 필드는 같은 길이의 리스트여야 함
- 위의 두 가지 조건을 만족하지 않으면 결과 데이터셋을 생성할 수 없음
map()함수 내부에서 컬럼 삭제도 가능- 이 경우 자동으로 해당 컬럼의 feature 정보도 제거됨
- 출력된 배치의 크기가 입력 배치 크기와 달라도 문제없어, 데이터 증강이나 긴 텍스트를 여러 조각으로 나누는 변환에 유용함
Hugging Face
Dataset.map()은 복잡한 데이터 전처리 작업을 간결하고 효율적으로 수행할 수 있게 해주는 핵심 기능이며, 특히 NLP나 이미지 처리 파이프라인에서 널리 쓰입니다.
"each example" or "batch of examples" within a Dataset object
"Hugging Face datasets"에서 말하는 "each example"과 "batch of examples"은 뭘 말하는 걸까?
- each example (각 예제)
- 데이터셋에 담긴 하나하나의 데이터 항목
- 텍스트 분류용 데이터셋이라면 하나의 문장과 그에 대응하는 라벨이 하나의 example(예제)
- 이미지 데이터셋이면 하나의 이미지와 관련 정보 한 세트가 하나의 example
- batch of examples (예제들의 배치)
- 여러 개의 example을 모아 한 단위로 처리하는 묶음
- 예를 들어, 32개의 문장과 라벨을 한 번에 처리한다면, 이 32개의 example 묶음이 하나의 batch
- Hugging Face
Dataset.map()함수에서batched=True옵션을 주면, 함수가 "하나씩 example마다"가 아니라 "batch 단위로 여러 example들을 모아서" 처리- 이렇게 하면 병렬 처리나 토크나이저 등에서 처리 속도를 크게 높일 수 있음
즉,
- each example은 데이터셋의 개별 행(row) 한 줄,
- batch of examples은 여러 행들을 모아 한꺼번에 처리하는 묶음 단위입니다.
배치 단위로 함수가 입력을 받을 때는, 보통 입력이 딕셔너리 형태이고, 각각의 key(컬럼명)마다 리스트가 값으로 들어있습니다. 예를 들어, {'text': ['문장1', '문장2', ...], 'label': [0, 1, ...]} 이런 식입니다. 함수는 이 딕셔너리를 받고 변환 후 다시 딕셔너리를 반환합니다.
동적 패딩(Dynamic padding)
- 콜레이트 함수(collate function)
- 샘플들을 함께 모아서 지정된 크기의 배치(batch)로 구성하는 역할을 하는 함수
- 이 함수는
DataLoader를 빌드(build)할 때 전달할 수 있는 매개변수임 - 기본값: 단순히 샘플들을 PyTorch 텐서로 변환하고 결합
- 만일 대상 샘플들이 리스트, 튜플 혹은 딕셔너리면 재귀적으로 이 작업이 수행됨
- 입력값이 모두 동일한 크기(길이)가 아니면 해당 작업이 불가능
- 전체 데이터셋이 아닌 개별 배치(batch)에 대해서 별도로 패딩(padding)을 수행하여 과도하게 긴 입력으로 인한 과도한 패딩(padding) 작업을 방지하고 싶은 경우 배치(batch)로 분리하려는 데이터셋의 요소 각각에 대해서 정확한 수의 패딩(padding)을 적용할 수 있는 콜레이트 함수(collate function)를 정의해야 함 →
DataCollatorWithPadding- 트랜스포머 모델에서 패딩(padding)은 입력 시퀀스 길이가 서로 다를 때 배치 내에서 길이를 맞추기 위해 필요
- 전체 데이터셋 최대 길이로 한꺼번에 패딩하지 않고, 배치 단위로 동적 패딩(dynamic padding)을 해서 불필요하게 긴 길이로의 과도한 패딩을 줄이면 처리 속도가 빨라진다 == 학습 속도가 상당히 빨라진다
→ 동적 패딩 기법을 써서 배치별 불필요한 패딩을 줄이면 고정 길이 패딩에 비해 학습 속도를 개선할 수 있다는 뜻 - 하지만 TPU에서 학습하는 경우 문제가 발생할 수 있음 → TPU는 추가적인 패딩(padding)이 필요한 경우에도 전체 데이터셋이 고정된 형태를 선호
→ TPU 같은 하드웨어에서는 배치 내 입력 길이가 모두 같고 고정되어야 하므로, 동적 패딩 대신 고정 길이 패딩을 선호하기도 한다는 의미TPU(텐서 처리 장치)는 머신 러닝 모델 학습을 가속화하도록 설계된 하드웨어로 행렬 연산에 특화된 구조를 가지고 있어, GPU나 CPU보다 훨씬 빠르게 머신 러닝 모델을 학습시킬 수 있음 (특히 딥러닝 작업에 최적화)
DataCollatorWithPadding- 토크나이저를 입력으로 받아 사용하려는 패딩 토큰(padding token)이 무엇인지와 모델이 입력의 왼쪽 혹은 오른쯕 중 어느 쪽에 패딩(padding)을 수행할지를 파악
트랜스포머는 패딩 없이는 학습이 안 되나요?
패딩을 전혀 하지 않고 트랜스포머를 학습하는 것은 일반적이지 않고 문제를 일으킬 수 있습니다. 트랜스포머는 입력을 고정 길이 텐서 형태로 받아야 하기 때문에, 길이가 서로 다른 입력에는 필수적으로 패딩이 필요합니다. 다만, 패딩 토큰에 대해서는 주의(attention) 마스크를 적용하여 학습 시 모델이 패딩 토큰을 무시하도록 합니다.
인증 토큰
The secret
HF_TOKENdoes not exist in your Colab secrets.
To authenticate with the Hugging Face Hub, create a token in your settings tab (https://huggingface.co/settings/tokens), set it as secret in your Google Colab and restart your session.
You will be able to reuse this secret in all of your notebooks.
Please note that authentication is recommended but still optional to access public models or datasets.
이 메시지는 Google Colab에서 Hugging Face 라이브러리를 사용할 때 인증(로그인) 토큰이 없다는 경고입니다.
즉, Hugging Face Hub(모델, 데이터셋 등 클라우드 서비스)와 안전하게 연결하려면 본인 인증용 Access Token이 필요하다는 뜻입니다.
의미 요약:
HF_TOKEN이라는 비밀 키(Access Token)를 Colab에 등록하지 않았기 때문에, Hugging Face 서비스에 인증되지 않은 상태라는 의미입니다.- Public(공개) 리소스는 인증 없이도 쓸 수 있지만, Private(비공개) 모델이나 데이터, 업로드 등은 인증이 필요합니다.
- "Authentication is recommended but optional": 인증이 권장되지만, 꼭 필요한 것은 아닙니다(일부 공개 자원 접근은 로그인 없이도 가능).
해결 방법(따라하기):
1. Hugging Face 웹사이트에 로그인합니다.
2. https://huggingface.co/settings/tokens 페이지로 이동합니다.
3. "New Token"을 생성(권장: read 권한)해서 복사합니다.
4. Colab에서 왼쪽 메뉴의 "Secrets" 또는 환경변수에 HF_TOKEN으로 토큰 값을 저장합니다.
- 또는 아래 코드 입력:
from huggingface_hub import login login() # 실행 후 복사한 토큰 입력
- Colab 런타임을 재시작합니다.
간단 요약:
- Hugging Face 사이트에서 내 토큰을 만들어서 Colab의 비밀키(Secrets)나 환경 변수에
HF_TOKEN이름으로 등록하면 인증됩니다. - 공개 모델은 인증 없이 쓸 수도 있지만, 비공개나 특정 서비스는 꼭 인증이 필요합니다.
하루 돌아보기
👍 잘한 점
- 허깅페이스에 대해 추가 공부 진행
👎 아쉬웠던 점
- 반 대표로 나가 발표하는 거니까 그래도 좀 잘 해보고 싶었는데 너무 못해서 속상함
🔬 개선점
- 다음 프로젝트 때도 발표를 하게 된다면(그런 일이 없어야 개인적으로는 가장 행복하겠지만) 주어진 시간에 맞춰서 필요한 말만 하는 연습을 많이 하자
