지난 시간 복습
- 머신러닝
- 인간의 지능을 모방한 컴퓨터가 데이터를 기반으로 스스로 학습하여 새로 들어온 데이터에 대해 예측하는 과정
- 컴퓨터가 지능을 가지고 데이터를 학습해 그에 대한 결과를 예측해내는 과정
- 간단한 문제를 해결할 때 적용
- 주로 테이블 형태의 결과 데이터를 낼 때 사용
- 회귀/이진분류/다중분류
- 인간의 지능을 모방한 컴퓨터가 데이터를 기반으로 스스로 학습하여 새로 들어온 데이터에 대해 예측하는 과정
지능을 모방하기는 했지만 머신러닝은 여전히 기계처럼 학습하기 때문에 '인간처럼 생각하기 위해서' 인간의 신경망을 모방 → 뉴런을 모방한 퍼셉트론을 사용하는 "딥러닝"의 등장
- 딥러닝
- 인간의 신경망 모방: 퍼셉트론
- 데이터 패턴을 스스로 익히는 인공 지능의 한 갈래
- 딥(deep)은 많은 은닉층(hidden layer)을 사용한다는 의미
- 회귀/이진분류/다중분류에 따른 다양한 조합
- 텐서플로우(Tensorflow) 활용
- 1 epoch의 과정: 딥러닝 신경망의 가장 기초
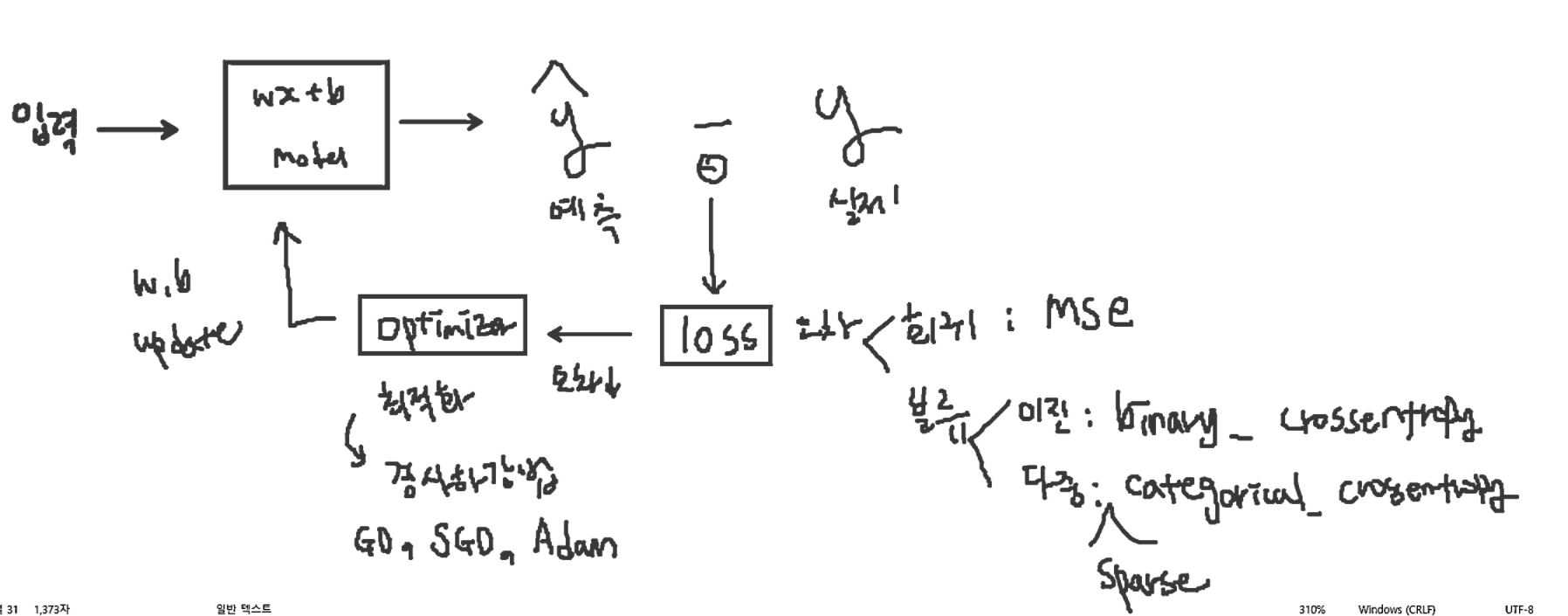
- 회귀 모델
- 출력층 활성화함수: 항등함수 또는 아무것도 쓰지 않기
- compile 시 사용하는 loss 함수: mse
- 이진 분류 모델
- 출력층 활성화함수: 시그모이드
- compile 시 사용하는 loss 함수: binary_cross_entropy
- 다중 분류 모델
- 출력층 활성화함수: 소프트맥스
- compile 시 사용하는 loss 함수: categorical_cross_entropy
- 파이토치(PyTorch) → 회귀/이진분류/다중분류
- 요즘 많이 사용하는 딥러닝 라이브러리
- 자연어 처리에서 요즘 많이 사용되는 Transformer, BERT, GPT 모델 등이 모두 파이토치 기반으로 구성됨
- 요즘 많이 사용하는 딥러닝 라이브러리
- DNN 심층신경망
- CNN 합성곱신경망
- RNN 순환신경망
- Sequential data
- 텍스트 데이터
- 분석 순서: 텍스트 수집 → 텍스트 전터리 → 토큰화 → 특성 추출(벡터화) → 데이터 분석
- 예시: 감성 분석 모델 학습
- 각 문장에 '레이블(label)'을 달아 놓은 자료(학습 데이터training data)가 있어야 함 → 지도 학습
- 모델이 데이터의 패턴(pattern)을 스스로 익히게 해야 함: 학습(train) → 출력이 정답에 가까워지도록 모델을 업데이트하는 과정
- 텍스트 데이터에서 가장 중요한 부분은 토큰화, 벡터화
- 토큰화 → 토크나이저(tokenizer)
- 목적에 맞게 자를 기준 정함: 단어 / 형태소 / 띄어쓰기 등
- 다양한 벡터화 방법들
- 원핫 인코딩: 단순 숫자 변경
- BOW: CounterVectorizer(단순 빈도수), TF-IDF
- 위의 두 방법은 의미성 유사성을 반영하지 못한다는 한계가 존재
- 워드 임베딩: 단어 간 의미적 유사성을 서로 학습 → Word2Vec, Doc2Vec
- 딥러닝 모델에 Embedding Layer 추가해 Embedding Vector 만든 후 학습
- 1번, 2번보다는 개선되었지만 여전히 문맥적 의미는 반영하지 못함
- 실습: RNN, LSTM, GRU, Embedding 층 구성하기
- LSTM
- RNN에 4가지 키워드를 추가: memory cell, input gate, forget gate, output gate
- LSTM
- BERT 기반 임베딩
- 문맥적 의미까지 반영
- 한국어 버전: KoBERT
PLM(Pretrained Language Model)
- LLM(큰 언어 모델, Large Language Model)이라고도 함
- 이미 사전 학습된 모델(대량의 데이터에 대해 학습이 완료된 모델)이라는 뜻
학습 목표
- 자연어 처리를 위한 PLM(Pretrained Language Model) 종류 이해
- PyTorch를 이용한 모델 구성
- 언어모델과 관련된 오픈 소스 사용 환경 구축
딥러닝 기반 자연어 처리 모델
기계의 자연어 처리
- 컴퓨터가 구현하는 '이해'의 본질은 계산(computation), 처리(processing)
- 사람의 자연어 이해(understanding)와는 본질적으로 차이가 있을 수밖에 없음
- 기계가 사람 말을 알아듣는 것처럼 보이게 하려면 어떤 요소가 있어야 할까?
- 모델(model): 입력을 받아 어떤 처리를 수행하는 '함수(function)'
- 모델의 출력은 확률(perobability) → 어떤 사건이 나타날 가능성을 의미하는 수지(0~1 사이의 값)
- 즉, 모델은 어떤 입력을 받아서 해당 입력이 특정 범주일 확률을 반환하는 '확률 함수'임
- 자연어 처리 모델은 자연어를 입력받아서 해당 입력이 특정 범주일 확률을 반환하는 확률 함수
- BERT, GPT → 딥러닝 기반 자연어 처리 모델
- 후처리(post processing)
- 사람이 쉽게 이해할 수 있도록 출력된 확률을 자연여 형태로 변환
PLM을 이용한 성능 향상 방법
- Feature-based Approach
- 더 좋은 입력 representation을 갖게 하여 성능을 개선하는 방법
- Word Embedding
- Frequency Based: BOW, TF-IDF
- Prediction Based: Word2Vec, GloVe, FastText
발전 단계:
입력 representation 개선 → PLM 활용(but, fine-tuning 전): "PLM 자체를 전부 사용하는 fine-tuning 방식 이전"의 feature 활용법 → full PLM fine-tuning
➡ 예전에는 주로 Frequency-based(빈도 기반)나 Prediction-based(예측 기반) 방법들로 입력 텍스트를 벡터화(embedding)했음 → 이런 전통적 representation이 downstream task에 한계가 있었기 때문에, "PLM을 하기 전에 더 좋은 입력 벡터를 만들자"는 접근이 중요해짐
➡ PLM 이전 시대의 representation 강화법: 기존의 단어나 문장 표현 방식(예: BOW, TF-IDF, Word2Vec 등)만 사용하던 시점과 대비해서 PLM이 본격적으로 fine-tuning 등으로 강력하게 쓰이기 전, 즉 기존 feature engineering 관점에서 더 좋은 feature(입력 벡터)를 확보하기 위한 시도들이 있었음
➡ Feature-based Approach는 pretrained language model(PLM)으로부터 더 좋은 입력 representation을 얻어서 기존 모델(word embedding 등)이 갖는 한계를 극복하려는 방식
➡ PLM이 본격적으로 fine-tuning 등으로 강력하게 쓰이기 전, 즉 기존 feature engineering 관점에서 더 좋은 feature(입력 벡터)를 확보하기 위한 시도 존재
➡ 실제로는 ELMo나 BERT 기반 feature-based 방식도 넓은 의미의 PLM 활용이지만, 모델 전체를 fine-tuning하는 full PLM 활용 이전 단계로 구분해서 설명) → ELMo 기반 feature-based 방식: pretrained representation을 feature로 추가해서 downstream task의 입력(feature)에 포함시킴
- Fine-tuning Approach
- 더 좋은 weight parameter를 갖게 하여 성능을 개선하는 방법
- ELMo, BERT, GPT
- ELMo: 기존 임베딩은 주변 단어만 고려하기 때문에 동음이의어(e.g., 눈, 배, 밤 등)에 취약 → 문맥을 고려하면서 임베딩하는 구조를 가진 언어모델(양방향 순환) → 임베딩 벡터, 각 층별 히든 스테이트의 가중합을 이용해 다운스트림 태스크 진행
- 정리:
- Feature-based Approach에서는 PLM이 만들어낸 representation(문맥·의미를 담은 벡터)을 입력 feature로 추가하여 성능을 높임
- Fine-tuning Approach는 PLM의 전체 weight와 representation을 downstream task에 맞춰 재학습하여 최적화함
- 즉, representation 자체는 “텍스트 의미와 문맥 정보를 풍부하게 담은 벡터 표현”이고, 이것을 어떻게 활용하는지(입력 feature vs 모델 전체 파라미터 업데이트)가 접근 방식의 차이임
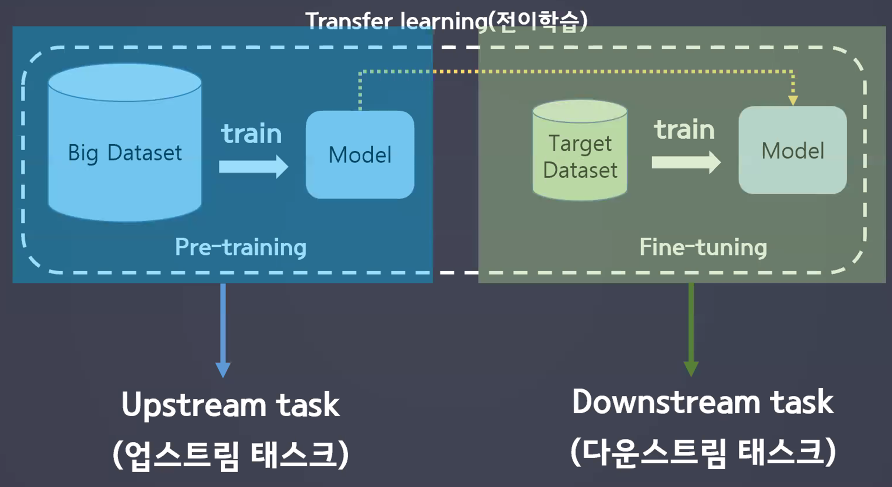
트랜스퍼 러닝(Transfer Learning)
- 자연어 처리 모델의 학습 방법 중 하나
- 특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법 → 지식 전이(knowledge transfer)
- 사람에 비유하자면 새로운 지식을 배울 때 평생 쌓아왔던 지식을 요긴하게 다시 써먹는 것과 같음
- 트랜스퍼 러닝을 적용하면 기존보다 모델의 학습 속도가 빠라지고 새로운 태스크를 더 잘 수행하는 경향
- 트랜스퍼 러닝 적용 이전의 기존 모델은 테스크를 처음부터 학습(from scratch)
- 사람의 학습에 비유하면 아무런 사전 지식 없이 새로운 지식을 배우는 것과 동일
- '업스트림 태스크'와 '프리트레인' 덕분에 트랜스퍼 러닝이 주목받게 됨
- 자연어의 풍부한 문맥(context)을 모델에 내재화하고 이 모델을 다양한 다운스크림 태스크에 적용해 성능을 대폭 향상시켰기 때문
업스트림 태스크(Upstream Task)
- 모델이 일반적인 언어 능력을 학습하는 과정
- 언어를 배우는 단계
- 공부하는 단계
- 똑똑한 모델을 만드는 단계
- 대규모 말뭉치를 이용해 학습을 진행하는 작업: 대규모 말뭉치의 문맥을 이해하는 과제
- 다음 단어 맞추기, 빈칸 채우기 등
- 좋은 weight parameter가 구성된 사전학습 모델이 됨
- 임베딩 파라미터, 예측을 위한 파라미터 등
- 자기지도학습 방식으로 진행되기 때문에 비용이 적게 들어감
- 프리트레인(pretrain): 업스트림 태스크를 학습하는 과정
- 다운스트림 태스크를 본격적으로 수행하기에 앞서(pre) 학습(train)한다는 의미인 듯
다음 단어 맞히기
- 대표적인 업스트림 태스트 중 하나
- GPT 계열 모델이 바로 이 태스크로 프리트레인을 수행함
- 예:
- '티끌 모아'라는 문맥이 주어졌고 학습 데이터에 "티끌 모아 태산"이라는 구(Phrase)가 많음 → 모델이 이를 바탕으로 다음에 올 단어를 '태산'으로 분류하도록 학습 → 모델이 대규모 말뭉치를 가지고 이런 과정을 반복 수행하면 이전 문맥을 고려했을 때 어떤 단어가 그 다음에 오는 것이 자연스러운지 알 수 있게 됨
- 언어 모델(Language Model): 다음 단어 맞히기로 업스트림 태스크를 수행한 모델
- 감성 분석 모델의 학습 과정과 별반 다르지 않음 → 분류해야 할 범주의 수가 학습 대상 언어의 어휘 수만큼 늘어났을 뿐임(보통 수만 개 이상)
빈칸 채우기
- 또 다른 업스크림 태스크
- BERT 계열 모델이 이 태스크로 프리트레인을 수행
- 문장에서 빈칸을 만들고 해당 위치에 들어갈 단어가 무엇인지 맞히는 과정에서 학습:
티끌 <mask> 태산
- 문장에서 빈칸을 만들고 해당 위치에 들어갈 단어가 무엇인지 맞히는 과정에서 학습:
- 모델이 많은 양의 데이터를 가지고 빈칸 채우기를 반복 학습하면 앞뒤 문맥을 보고 빈칸에 적합한 단어를 알 수 있음
- 마스크 언어 모델(Masked Language Model): 빈칸 채우기로 업스트림 태스크를 수행한 모델
- 언어 모델과 마찬가지로 해당 언어의 풍부한 모델을 내재화할 수 있음
<mask>의 정답이 '모아'라면 '모아'라는 단어에 해당하는 확률은 높이고 나머지 단어와 관계된 확률은 낮추는 방향으로 모델 전체를 업데이트
감성 분석 모델 학습 → 사람이 일일이 정답(레이블)을 만들어 학습 데이터 제작: 지도학습(supervised learning) → 데이터를 만드는 데 비용이 많이 들뿐만 아니라 사람이 실수로 잘못된 레이블을 줄 수도 있음
업스트림 태스크 → 뉴스, 웹 문서, 백과사전 등 글만 있으면 수작업 없이도 다량의 학습 데이터를 아주 싼값에 만들어 낼 수 있음: 자기지도 학습(self-supervised learning)
다운스트림 태스크(Downstream Task)
- 이미 사전학습된 모델(업스트림 태스크를 진행한 모델)을 가져다가 추가적으로 특정 테스크를 수행하도록 하는 과정
- 특정 테스크: 텍스트 분류, 번역, 질의응답, 문서 분류, 개체명 인식 등 → 우리가 풀고자 하는 자연어 처리의 구체적인 문제(과제)
- 우리가 모델을 업스트림 테스크로 프리트레인한 근본 이유는 다운스트림 태스크를 잘 하기 위해서임
- 문제를 푸는(해결하는) 과정
- 시험 보는 단계
- 업스트림 태스크로 구성된 모델을 구조 변경 없이 사용하거나 새로운 태스크 모델을 붙여 학습하는 작업: 파인튜닝(Fine-Tuning)
- 문서 분류, 자연어 추론, 개체명 인식, 질의응답, 문장 생성
- 문서 분류(document classification): 자연어(문서나 문장)을 입력 받아 해당 입력이 어떤 범주(긍정, 중립, 부정 등)에 속하는지 그 확률 값을 반환
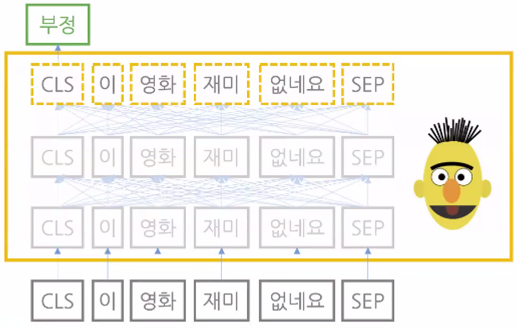
→ 프리트레인을 마친 마스크 언어 모델(노란색 실선) 위에 작은 모듈(초록색 실선)을 하나 더 쌓아 문서 전체의 범주를 분류(Classification) → 자연어를 입력 받아 해당 입력이 어떤 범주에 해당하는지 확률 형태로 반환 - 자연어 추론: 문장 2개를 입력 받아 두 문장 사이의 관계가 참, 거짓, 중립 등 어떤 범주인지 그 확률값을 반환 → 문장 쌍 분류(sentence pair classification)라고도 함
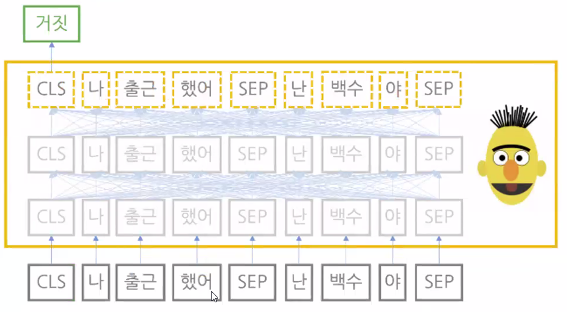
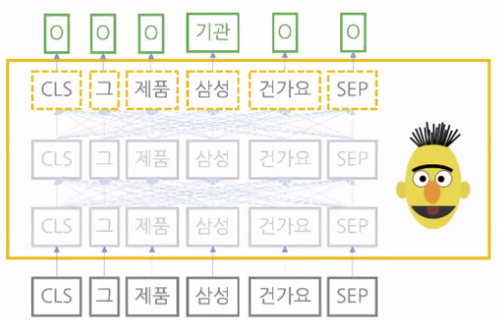
- 개체명 인식(named entity Recognition): 자연어(문서나 문장)를 입력 받아 단어별로 기관명, 인명, 지명 등 어떤 개체명 범주에 속하는지 그 확률값을 반환
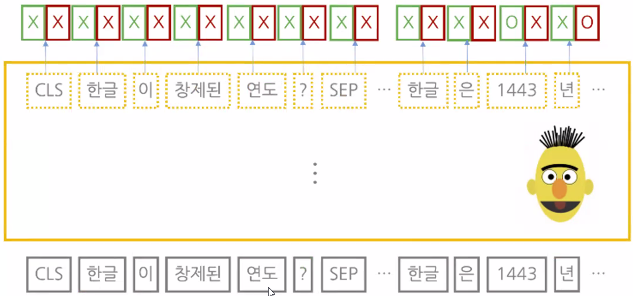
- 질의응답(question answering): 자연어(질문+대답)를 입력 받아 각 단어가 정답의 시작일 확률값과 끝값일 확률값을 반환
- 문장 생성(setence generation): 자연어(문장)를 입력 받아 다음에 올 단어의 확률 값을 반환
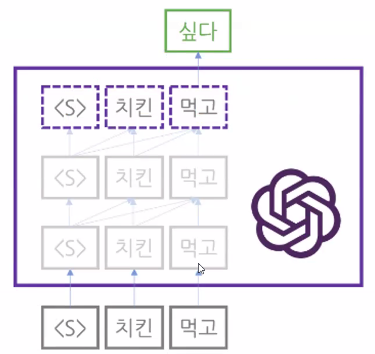
→ 문장 생성 모델은 자연어를 입력 받아 어휘 전체에 대한 확률 값(입력된 문장 다음에 올 단어로 얼마나 적절한지를 나타내는 점수)을 반환
- 문서 분류(document classification): 자연어(문서나 문장)을 입력 받아 해당 입력이 어떤 범주(긍정, 중립, 부정 등)에 속하는지 그 확률 값을 반환
- 문서 분류, 자연어 추론, 개체명 인식, 질의응답, 문장 생성
- 우리가 모델을 업스크림 태스크로 프리트레인한 근본 이유: 다운스트림 태스크를 잘하기 위해!
- 다운스트림 태스크: 우리가 풀어야 할 자연어 처리의 구체적인 과제들
- 보통 프리트레인을 마친 모델을 구조 변경 없이 그대로 사용하거나 여기에 태스크 모듈을 덧붙인 형태로 사용
그림 속 CLS, SEP은 각각 문장의 시작과 끝에 붙이는 특수한 토큰(token)
다운스트림 태스크를 학습하는 방식
- 파인튜닝(Fine-tuning)
- 다운스트림 태스크 데이터 전체를 사용
- 다운스트림 데이터에 맞게 모델 전체를 업데이트
- 문서 분류, 자연어 추론, 질의응답, 문장 생성 모델은 모두 파인튜닝 방식으로 학습
- 프롬프트 튜닝(Prompt tuning)
- 다운스트림 태스크 데이터 전체를 사용
- 다운스트림 데이터에 맞게 모델 일부만 업데이트
- 인컨텍스트 러닝(in-context learning)
- 다운스트림 태스크 데이터의 일부만 사용
- 모델을 업데이트하지 않음
a. 제로샷 러닝(Zero-shot learning): 다운스트림 태스크 데이터를 전혀 사용하지 않음. 모델이 바로 다운스트림 태스크를 수행
b. 원샷 러닝(one-shot learning): 다운스트림 태스크 데이터를 1건만 사용. 모델은 1건의 데이터가 어떻게 수행되는지 참고한 위 다운스트림 태스크를 수행
c. 퓨샷 러닝(few-shot learning): 다운스트림 태스크 데이터를 몇 건만 사용. 모델은 몇 건의 데이터가 어떻게 수행되는지 참고한 뒤 다운스트림 태스크를 수행
비용과 성능 때문에 파인튜닝 이외의 방식이 주목받고 있음:
최근 언어 모델의 크기가 기하급수로 증가해 파인튜닝 방식으로 모델 전체를 업데이트하려면 많은 비용이 들게 됨
또한 프롬프트 튜닝, 인컨텍스트 러닝으로 학습한 모델이 경쟁력 있는 태스크 수행 성능을 보일 때가 많음
언어 모델의 변화
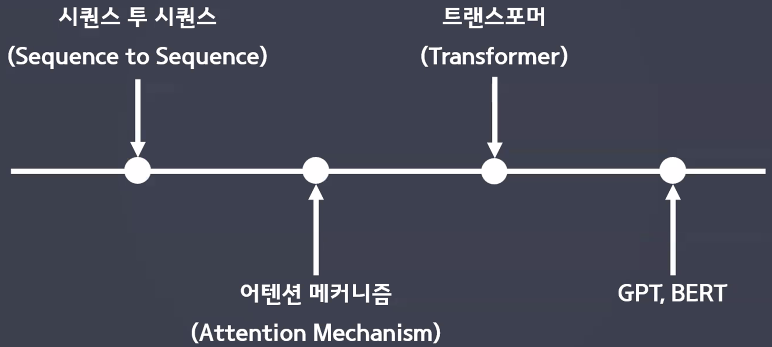
시퀀스 투 시퀀스(Sequence to Sequence)
- RNN 모델 기반 알고리즘
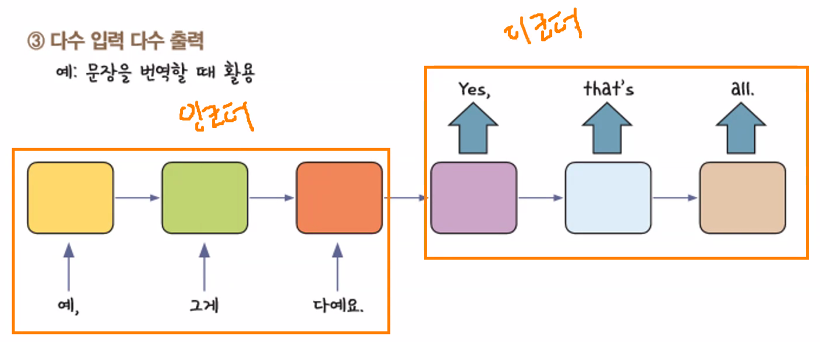
- RNN 활용 구조: 다수 입력 다수 출력
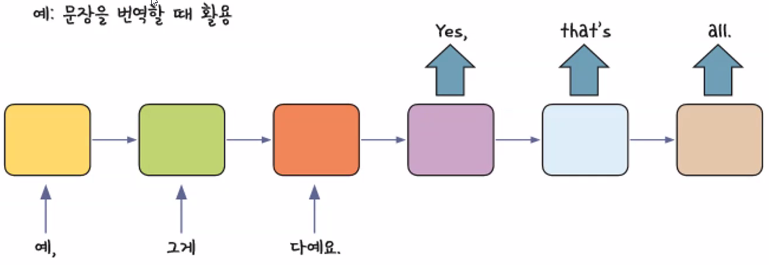
- RNN은 장기기억 손실(기울기 소실) 문제가 존재 → 보완: LSTM → memory cell 추가로 인해 연산 시간이 오래 걸림 → 통역/번역에서 문제 발생 → "시퀀스 투 시퀀스" 등장
- RNN 활용 구조: 다수 입력 다수 출력
- RNN 구조를 활용하기는 하는데 "셀을 2개" 사용: 인코더, 디코더 → 각자 순환
(각자의 순환 횟수를 가짐: 번역은 1대 1 대응이 아니기 때문 → 그림에서는 인코더, 디코더가 각각 3회의 순환 횟수를 가지고 있지만 I am a student → Je suis étudiant은 순환 횟수가 인코더 4, 디코더 3임)
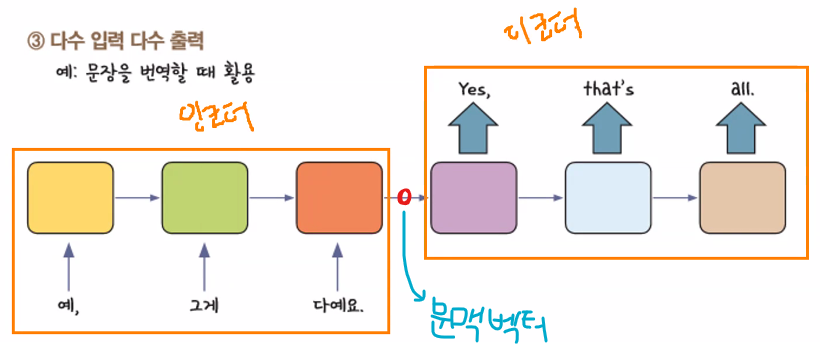
- 인코더: 자연어 → 압축된 숫자
- 문맥 벡터(Context Vector): 압축된 숫자
- 입력된 숫자와 출력된 숫자가 같지 않아도 출력이 가능한 이유
- 고정된 한 개의 컨텍스트 벡터 → 단점
- 디코더: 압축된 숫자 → 자연어
- 순차적인 데이터가 들어가서 순차적인 데이터가 나옴
- 챗봇과 기계번역 등의 태스크에서 널리 활용되는 구조
- RNN의 활용 방법 중 하나인 인코더 디코더 구조의 모델
- 인코더: 입력 문장의 단어를 순차적으로 받아 압축 값(Context Vector)을 만듦
- 디코더: 압축 값을 입력으로 받아 풀어낸 뒤 순차적으로 출력
- 인코더의 입력 시퀀스의 길이와 디코더의 출력 시퀀스 길이를 다르게 설정 가능: 문맥 벡터 덕분임
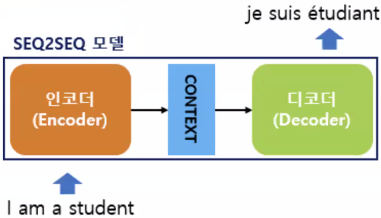
- 단점: 입력 데이터를 한정된 메모리 안에서 압축하는 과정에서 정보 손실 발생
- 입력 시퀀스를 고정된 크기의 압축된 벡터로 표현하기 때문에 정보 손실이 발생하는 단점이 있음
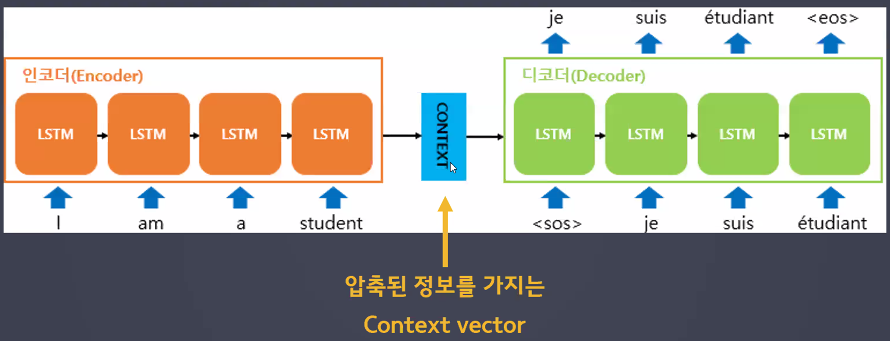
- 입력 시퀀스를 고정된 크기의 압축된 벡터로 표현하기 때문에 정보 손실이 발생하는 단점이 있음
어텐션 메커니즘(Attention Mechanism)
- 단어 가중치를 계산해서 중요한 단어에 가중치 부여
- 현재 단어를 출력할 때 조금 더 중요한 단어에게 가중치를 줌
- 출력하고자 하는 순환 시점에서 중요한 단어에만 집중: 출력 당시의 단어와 더 밀접한 단어에 주목
- 매 시점마다 컨텍스트 벡터를 만들어 성능 개선, 정보 손실 약간 개선
- 하지만 여전히 정보 손실 있음: RNN 기반 순차 처리 → 병렬 계산 불가
- 어텐션의 기본 아이디어: 디코더에서 출력 단어를 예측하는 매 시점(time step)마다 인코더에서의 전체 입력 문장을 다시 한번 참고하자
- 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것은 아님
- 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 봄
위 두 방법은 여전히 RNN을 사용하고 문맥 벡터가 핵심이기 때문에 정보 손실에서 자유롭지 못함 → 새로운 모델 등장: 트랜스포머 (RNN에서 탈피)
트랜스포머
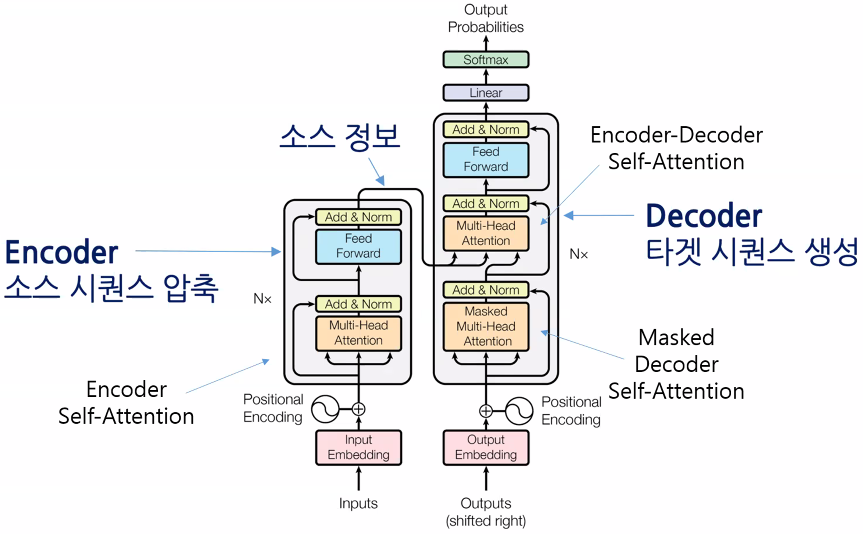
- 2017년 논문 발표: Attention is All You Need
- RNN은 정보 손실을 극복할 수 없음 → RNN에서 벗어나자!
- 인코더, 디코더 개념은 유지
- 인코더: 입력 전체를 동시에 받아들이고, 각 토큰(단어)이 문장 내 다른 모든 토큰들과 상호작용할 수 있게 “셀프 어텐션(self-attention)” 연산을 반복적으로 수행
- 디코더: 번역/생성 등에서 주로 사용, 이미 생성된 토큰까지만 정보를 참고하며, 미래 토큰은 마스킹해서 볼 수 없음
- 핵심: Self Attention 개념 도입
- 순서를 중요하게 가져감: Positional Encoding → 문맥과 순서 정보까지 고려
- Positional 값을 가지고 들어가기 때문에 순차적으로 들어가지 않아도 됨 → 병렬 계산 가능
- BURT: 트랜스포머의 encoder 부분만 사용(디코더 구조를 아예 쓰지 않)
- 트랜스포머 구조 전체(인코더–디코더 모두)를 쓰는 대신 인코더(encoder)만을 여러 번 쌓아 모델을 구성한다는 뜻
- 인코더는 셀프 어텐션(Self-Attention) 구조여서 입력 문장의 모든 단어가 서로의 정보를 양방향(왼쪽-오른쪽, 오른쪽-왼쪽) 모두 참고할 수 있어 “양방향 문맥” 정보를 효과적으로 얻을 수 있음 → 입력 전체를 동시에 참고(“bidirectional self-attention”)
- GPT: 트랜스포머의 decoder 부분만 사용
- 트랜스포머의 디코더 구조만 사용하며, 미래 단어를 보지 못하도록 마스킹(“causal-attention”)함
- 디코더의 기능: 마스킹과 조건부 생성
- BURT: 트랜스포머의 encoder 부분만 사용(디코더 구조를 아예 쓰지 않)
Hugging Face
- Main Page
- 인공지능 관련 데이터셋, 모델, 테스팅 공간 등을 공유하는 커뮤니티 웹 서비스
모델링 개발 방식과 실행 환경 비교
Open API 활용 vs 직접 AI 개발
| 방법 | 장점 | 단점 |
|---|---|---|
| Open API 활용 | - 빠른 개발 - 비용 절감 - 높은 신뢰성 | - 제한된 커스터마이징 - 사용량에 따른 비용 증가 - 데이터 보안 이슈 |
| 직접 AI 개발 | - 커스터마이징 가능 - 장기적인 비용 절감 - 데이터 보안 강화 | - 많은 시간과 전문 지식 필요 - 지속적인 유지보수 필요 |
노코드 모델링 vs 코딩 활용 AI 개발
| 방법 | 장점 | 단점 |
|---|---|---|
| 노코드 모델링 | - 접근성 - 빠른 프로토타이핑 - 직관적 사용 | - 제한된 기능 - 유연성 부족 - 성능 저하 가능 |
| 코딩 활용 AI 개발 | - 유연성 - 고성능 모델 - 확장성 | - 전문 지식 필요 - 시간 소요 - 복잡성 |
- 노코드 모델링 예
- 오렌지3(Orange3): 코딩이 필요없는 데이터 마이닝 도구
바닥부터 훈련(from scratch) vs 전이 학습(Transfer learning)
- 'from scratch'
- 영어에서 자주 쓰이는 구어체
- 재료를 하나하나 손질해서 밑바닥부터 요리 → "cooking from scratch", "made from scratch"
- 모래 위에 막대기로 선을 그어(scratch) 달리기 시작 지점으로 활용하던 것에서 유래했다고 함
- 딥러닝에서는 초기화된 상태의 parameter에서 train하기 시작하는 것을 의미
- 영어에서 자주 쓰이는 구어체
- 전이 학습(Transfer learning)
- 한 분야의 문제를 해결하기 위하여 얻은 지식과 정보를 다른 문제를 푸는 데 사용하는 방식
- 딥러닝에서는 다른 문제를 해결했을 때 사용했던 네트워크(예: 이미지 분류 문제 해결에 사용한 DNN)를 다른 데이터셋 또는 다른 문제(task)에 적용시켜 푸는 것
- 네트워크가 다양한 이미지의 보편적인 특징 혹은 피쳐(feature)들을 학습했기 때문에 가능
| 방법 | 장점 | 단점 |
|---|---|---|
| Make an AI from scratch | - 완전한 커스터마이징 - 최적화 - 모델 이해도 | - 시간·비용 많이 소요 - 많은 데이터 필요 |
| Transfer learning | - 시간 절약 - 적은 데이터로도 높은 성능 - 사전 학습된 모델 활용 | - 제한된 커스터마이징 - 적용 범위 제한 - 복잡성 |
웹 서버, 클라우드 환경 vs 엣지 컴퓨팅(Edge Computing)
- 엣지 컴퓨팅(Edge Computing)
- 클라우드 컴퓨팅과 반대되는 개념
- 인터넷이 아닌 로컬 장치(예: 스마트폰, 태블릿, IoT 장치 등)에서 데이터를 처리하는 기술
| 방법 | 장점 | 단점 |
|---|---|---|
| 웹 서버·클라우드 환경 | - 확장성 - 유지보수 용이 - 접근성 | - 비용 증가 - 네트워크 지연 - 보안 이슈 |
| Edge Computing | - 지연 감소 - 데이터 보안 강화 - 네트워크 독립성 | - 제한된 자원 - 개별 관리 필요 - 초기 비용 높음 |
Local 환경 구축 vs 클라우드 기반 환경 구축
| 방법 | 장점 | 단점 |
|---|---|---|
| Local 환경구축 | - 완전한 통제 - 보안 강화 - 고성능 하드웨어 사용 | - 초기 설치·유지보수 비용 높음 - 확장성 제한 |
| 클라우드 기반 환경구축 | - 확장성 - 비용 효율성 - 접근성 | - 제공자 의존 - 보안 이슈 - 네트워크 지연 |
언어 모델 발전 현황
Seq2Seq
RNN(기본 개념)에서부터 인코더, 디코더 개념을 가져옴
고정된 문맥 벡터 사용한다는 단점
↓
Attention Mechanism
현재 출력 상태에 따라 변경 시점마다 다른 문맥 벡터 생성
소프트맥스 사용
↓
※ 여기까지는 여전히 RNN 알고리즘 기반이라 순차 처리만 가능 & 너무 길면 정보 손실 발생
↓
Transformer
Positional Encoding을 통해 위치 정보를 가지고 병렬 처리를 하기 때문에 훨씬 빠르고 성능이 좋음
↓
BERT / GPT 등의 사전학습 모델
BERT는 Transformer의 인코더 부분만 쌓아서 만듦
GPT는 Transformer의 디코더 부분만 사용
실습: Hugging Face
라이브러리 설치
# transformers 라이브러리
!pip -q install transformers[torch]- transformers: HuggingFace에서 제공하는 Transformer 모델을 일관성 있게 사용할 수 있도록 해주는 라이브러리
- 모델명 뒤
[torch]: 선택적(익스트라) 의존성(extra dependency)을 의미하며, transformers 라이브러리를 PyTorch(토치) 환경에서 사용하기 위해 필요한 추가 패키지(torch 관련 패키지들)를 함께 설치하도록 지정함[]: 선택적으로 추가 패키지(옵션 의존성, extra dependencies)를 설치할 수 있도록 표준화된 파이썬 패키지 설치 방식- 위의 명령어는 transformers와 PyTorch 관련 필수 의존성을 한 번에 설치
- 다른 딥러닝 프레임워크용 익스트라 의존성도 존재
transformers[torch]→ transformers + PyTorch용 추가 패키지 설치transformers[tf-cpu]→ transformers + TensorFlow용 추가 패키지 설치transformers[flax]→ transformers + Flax용 추가 패키지 설치
- 환경에 따라 불필요한 패키지 설치를 막으면서도, 필요한 프레임워크를 편리하게 설치할 수 있음
- 모델명 뒤
!pip install 명령어에서 -q 옵션은 "quiet"의 약자로, 설치 과정에서 출력되는 메시지(로그)를 최소화하여 터미널에 거의 아무런 정보도 출력하지 않도록 만드는 역할
일반적으로 패키지를 설치할 때 나오는 다운로드, 설치 경과, 경고 등의 메시지가 보이지 않고, 필요 최소한의 안내나 에러만 출력됨
주로 자동화된 환경, 로그 출력을 줄이고 싶을 때, 혹은 노트북 등에서 불필요한 출력 없이 조용하게 패키지 설치를 진행하고 싶을 때 사용
# transformers 안에 있는 pipeline 가져오기
from transformers import pipeline- pipeline
- HuggingFace에서 제공하는 Transformers 라이브러리가 제공하는 함수 중 하나
- 감정분석, 번역, 요약 등 다양한 Task를 한 줄로 수행할 수 있게 도와줌
파이프라인(pipeline) Task 종류
| 파이프라인 | 설명 |
|---|---|
feature-extraction | 특징 추출 (텍스트에 대한 벡터 표현 추출) |
fill-mask | 마스크 채우기 |
ner | 개체명 인식 (Named Entity Recognition) |
question-answering | 질의 응답 |
sentiment-analysis | 감정 분석 |
summarization | 요약 |
text-generation | 텍스트 생성 |
translation | 번역 |
zero-shot-classification | 제로샷 분류 (레이블 분류) |
1. 감성분석
- 글 내에서 사람의 감정, 기분, 의도 등을 파악하는 기술
# 감성분석 모델 불러오기 → 객체 생성
sentiment_model = pipeline(task="sentiment-analysis")
# 모델 사용하기
result = sentiment_model(["I am happy", "I hate this so much"])
# 결과 확인
result[{'label': 'POSITIVE', 'score': 0.9998801946640015},
{'label': 'NEGATIVE', 'score': 0.9995144605636597}]- label: 학습 결과
result[0]["label"]→ POSITIVE
- score: 해당 label의 확률
2. 문장 빈칸 채우기(fill-mask)
- 문장 중 비어있는 부분(mask)을 채워주는 기능: 빈칸 예측
# 모델을 불러올 때 내가 원하는 모델을 사용할 수 있음
fill_mask_model = pipeline(task="fill-mask", model = "FacebookAI/xlm-roberta-base")
# 빈칸 예측하기
fill_mask_model("I want to go <mask>")[{'score': 0.15739087760448456,
'token': 5,
'token_str': '.',
'sequence': 'I want to go.'},
{'score': 0.13985183835029602,
'token': 38,
'token_str': '!',
'sequence': 'I want to go!'},
{'score': 0.06600414961576462,
'token': 5368,
'token_str': 'home',
'sequence': 'I want to go home'},
{'score': 0.06487954407930374,
'token': 27,
'token_str': '...',
'sequence': 'I want to go...'},
{'score': 0.0581800639629364,
'token': 1810,
'token_str': 'out',
'sequence': 'I want to go out'}]fill_mask_model("I want to <mask> home.")[{'score': 0.5523189306259155,
'token': 738,
'token_str': 'go',
'sequence': 'I want to go home.'},
{'score': 0.12350067496299744,
'token': 1380,
'token_str': 'come',
'sequence': 'I want to come home.'},
{'score': 0.10094839334487915,
'token': 24765,
'token_str': 'stay',
'sequence': 'I want to stay home.'},
{'score': 0.037752747535705566,
'token': 186,
'token_str': 'be',
'sequence': 'I want to be home.'},
{'score': 0.02713177539408207,
'token': 31358,
'token_str': 'leave',
'sequence': 'I want to leave home.'}]- 'go' 단어가 55% 정도 어울린다고 예측
- 강사님은 40%인데?
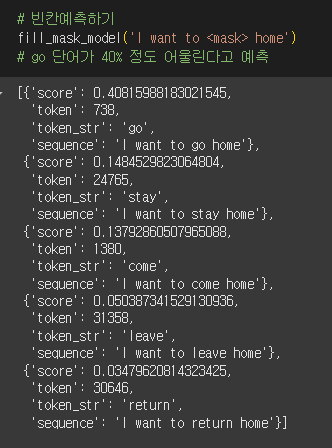
→ 마침표 하나가 이런 차이를 불러온 걸까?
- 강사님은 40%인데?
추가: 강사님과 내 결과가 다른 이유
Huggingface의 transformers 라이브러리에서 pipeline의 fill-mask task를 사용할 때, 마침표(특수기호) 하나 차이만으로도 score가 달라질 수 있습니다.
이는 transformers의 토크나이저(tokenizer)와 모델이 입력 문장의 토큰화 방식을 다르게 처리하기 때문입니다. 예를 들어, "home"과 "home."은 서로 다른 토큰 시퀀스로 변환되고, 이로 인해 마스크 토큰이 문장 내에서 배치되는 위치, 모델이 해당 문맥을 인식하는 방식, softmax가 적용되는 지점 등 여러 요소가 달라집니다. 이 때문에 점 하나만 달라도 유사한 결과가 아닐 수 있습니다.
특히 RoBERTa, BERT 등의 모델은 문장 내 마스킹 위치, 앞뒤 공백 및 문장 부호에 민감하게 반응합니다. 실제로 공식 이슈 트래커에서도 마침표, 스페이스, 위치 등에 따라 fill-mask pipeline score가 다를 수 있음이 보고되었습니다. 즉, "I want to home"과 "I want to home."처럼, 마스킹된 단어 뒤에 마침표가 있느냐 없느냐에 따라 모델의 해석과 상대 확률(score)이 달라집니다.
- 정리:
- 마침표(혹은 다른 특수문자) 하나로 토큰화가 달라져 score가 다를 수 있음
- 마스킹 위치, 점/공백 포함 등 입력 형식이 모델의 score에 영향
- 정확한 비교를 위해서는 항상 입력 포맷(문장부호, 공백 등)을 동일하게 맞추는 것이 중요합니다.
- 예측한 단어를 호출하고 싶다면:
fill_mask_model("I want to <mask> home.")[0]["token_str"]→ go
# 빈칸 예측하기(2)
fill_mask_model("I want to go to <mask>")[{'score': 0.1025170311331749,
'token': 152363,
'token_str': 'university',
'sequence': 'I want to go to university'},
{'score': 0.08955895155668259,
'token': 40466,
'token_str': 'college',
'sequence': 'I want to go to college'},
{'score': 0.05323364585638046,
'token': 10696,
'token_str': 'school',
'sequence': 'I want to go to school'},
{'score': 0.028274009004235268,
'token': 27,
'token_str': '...',
'sequence': 'I want to go to...'},
{'score': 0.025998597964644432,
'token': 4488,
'token_str': 'work',
'sequence': 'I want to go to work'}]3. 번역하기
ko_to_en = pipeline(task="translation", model="Helsinki-NLP/opus-mt-ko-en")
ko_to_en("배가 고파요. 오늘의 점심은 무엇일까요?")[{'translation_text': "I'm hungry. What's today's lunch?"}]ko_to_en("영수와 순이는 다음 주에 서울로 여행을 간다.")[{'translation_text': 'Young-su and Soon-y travel to Seoul next week.'}]
4. 문장 요약
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import nltk
nltk.download("punkt")
nltk.download("punkt_tab")
model_dir = "lcw99/t5-base-korean-text-summary" # 모델명
tokenizer = AutoTokenizer.from_pretrained(model_dir) # 파이토치 기반 모델
model = AutoModelForSeq2SeqLM.from_pretrained(model_dir)
# 요약을 진행할 텍스트
text = """
성기훈은 이혼한 뒤 도박에 빠져 사는 무직의 남성이다.
빚더미에 몰린 그는 우연히 의문의 남자를 만나 수상한 게임에 참여하게 된다.
깨어난 곳에는 자신처럼 인생에 실패한 456명의 참가자들이 있었고, 상금은 무려 456억 원이다.
하지만 게임은 단순한 놀이가 아니라, 패배하면 즉사하는 생존 게임이었다.
첫 번째 게임 '무궁화 꽃이 피었습니다'에서는 움직이면 총에 맞아 죽는다.
수백 명이 목숨을 잃자 참가자들은 현실로 돌아가지만, 대부분은 다시 지옥 같은 삶을 피해 자발적으로 게임장으로 돌아온다.
이후 줄다리기, 달고나, 구슬치기, 유리다리 등의 게임이 이어지고, 참가자들은 점점 서로를 속이고 죽여야만 살아남는 구조에 내몰린다.
성기훈은 어린 시절 친구였던 조상우와 결승에 진출한다.
결국 상우는 자살하고 기훈은 우승자가 된다.
하지만 현실로 돌아온 그는 상금조차 쓰지 못하고 방황한다.
그러던 중, 죽은 줄 알았던 노인 참가자 오일남이 이 게임의 설계자였다는 사실을 알게 되고, 충격에 빠진다.
마지막에는 또 다른 게임이 시작되는 걸 막기 위해 기훈은 비행기를 타지 않고 돌아선다.
"""
# 위에서 불러온 모델은 텍스트 앞에 "summarize: "의 명령 프롬프트를 붙여줘야 동작함!
input = ["summarize: " + text]
# 토크나이저 만들기
input = tokenizer(
input
, max_length=512 # 최대 길이 제한
, return_tensors="pt" # PyTorch용 텐서로 변환
)
# 요약문 생성
output = model.generate(**input, do_sample=True)
# 디코드
decode = tokenizer.batch_decode(output)[0]
nltk.sent_tokenize(decode.strip())[0]<pad>도박에 빠져 자살하고 우승자가 된 기훈은 수상한- AutoTokenizer: 토큰화 도구
- 내가 사용할 모델이 쓴 토큰화 도구를 가져다가 알아서 새로 들어온 데이터에도 동일하게 적용해 줌
- 입력한 텍스트를 모델 입력용으로 만듦
- AutoModelForSeq2SeqLM: 데이터를 학습할 모델
- 동일한 시퀀스로 만들어 줄 변환 모델
- NLTK: 자연어 처리를 위한 파이썬 패키지
- punkt: 문장/단어 분리용 규칙 기반 토크나이저
- 랜덤성 있음: 돌릴 때마다 요약 내용 변함
# 요약문 생성 (2)
output = model.generate(
**input
, do_sample=True
, num_beams=8 # 여러 개 돌리고 그중 가장 나은 것 출력
, min_length=20
, max_length=100
)
# 디코드
decode = tokenizer.batch_decode(output)[0]
nltk.sent_tokenize(decode.strip())[0]<pad>빚더미에 몰린 그는 우연히 의문의 남자를 만나 수상한 게임에 참여하게 되고 깨어난 곳에는 456명의 참가자들이 있었고 상금은 무려 456억 원이다.</s># 뉴스 기사로 해 보기
model_dir = "lcw99/t5-base-korean-text-summary" # 모델명
tokenizer = AutoTokenizer.from_pretrained(model_dir) # 파이토치 기반 모델
model = AutoModelForSeq2SeqLM.from_pretrained(model_dir)
# 요약을 진행할 텍스트
text = """
President Donald Trump says the US will charge a 15% tariff on imports from South Korea, in what he called a "full and complete trade deal".
It comes just a day before a 1 August deadline for countries to reach agreements with the US or be hit with higher tariffs. South Korea had been facing a 25% levy if it had not struck a deal.
Pressure on Seoul had been mounting after Japan, a key competitor in the car and manufacturing industries, secured a 15% tariff rate with the US this week.
The deal, which will also see Seoul invest $350bn (£264.1bn) in the US, has been touted as a success in South Korea - especially given the record trade surplus of at least $56bn with the US last year.
"""
# 위에서 불러온 모델은 텍스트 앞에 "summarize: "의 명령 프롬프트를 붙여줘야 동작함!
input = ["summarize: " + text]
# 토크나이저 만들기
input = tokenizer(
input
, max_length=512 # 최대 길이 제한
, return_tensors="pt" # PyTorch용 텐서로 변환
)
# 요약문 생성
output = model.generate(
**input
, do_sample=True
, num_beams=8 # 여러 개 돌리고 그중 가장 나은 것 출력
, min_length=20
, max_length=100
)
# 디코드
decode = tokenizer.batch_decode(output)[0]
nltk.sent_tokenize(decode.strip())[0]<pad>Trump says the US will charge a 15% tariff on imports from South Korea or be hit with higher tariffs.</s>- 강사님 뉴스 기사 예제
text = '''한국이 미국에 3천500억달러를 투자하는 등의 조건으로 한국에 대한 상호관세를 기존 25%에서 15%로 낮추기로 했다고 도널드 트럼프 미국 대통령이 30일(현지시간) 밝혔습니다.
트럼프 대통령은 이날 사회관계망서비스(SNS) 트루스소셜에 올린 글에서 미국이 한국과 무역 합의를 체결하기로 했다면서 이같이 밝혔습니다.
트럼프 대통령은 "한국과 전면적이고 완전한 무역에 합의했다"며 "상호관세는 기존 25%에서 15%로 낮추기로 했다"고 밝혔습니다. 그는 "한국이 미국산 자동차, 트럭, 농산물 시장을 완전 개방키로 했다"며 "1천억달러 미국산 LNG도 수입키로 했다"고 밝혔습니다.
트럼프 대통령은 향후 2주 내로 백악관에서 이재명 대통령과 정상회담을 개최하고 이번 무역 합의 내용을 발표할 계획이라고 말했습니다 '''
# 위에서 불러온 모델은 앞에 "summarize: "의 명령프롬프트를 붙여줘야 동작함!
input = ['summarize: ' + text]
# 입력데이터 토큰화
input = tokenizer(input, max_length = 512, return_tensors = 'pt' ) # Pytorch 용 텐서로 변환
# 요약문 생성
output = model.generate(**input, do_sample = True, num_beams = 8, min_length = 20, max_length = 100)
# 디코드
decode = tokenizer.batch_decode(output)[0]
nltk.sent_tokenize(decode.strip())[0]<pad>트럼프 대통령은 한국이 미국에 3천500억 달러를 투자하는 등의 조건으로 한국에 대한 상호관세를 기존 25%에서 15%로 낮추기로 했다고 SNS 트루스소셜에 올렸다.</s>5. TTS(Text To Speech)
# 소스코드 다운로드
!git clone https://github.com/myshell-ai/MeloTTS.git
%cd MeloTTS
!pip install -e . # 설치 후 세션 재시작 필요추가: pip install -e의 의미
참고한 글
오픈소스 핸들링 과정에서 레포지토리를 clone하고 해당 레포지토리로 이동하여requirements.txt에 따라 설치하면서pip intall -e .명령어를 자주 볼 수 있음
→ 로컬 상에 존재하는 패키지(폴더)를 editable하게 설치하겠다는 의미
→ 해당 패키지를 "내 프로젝트에 fit하게 변경해 주기 위해" 패키지를 편집하는 것
- 패키지의 본질적인 목적은 여러 프로젝트에서 사용되는 기능을 구현해 모아두는 것(e.g., numpy, matplotlib 등)
- 즉, 패키지에서 개발되거나 편집되는 코드는 좀 더 범용적 사용을 위한 것 → 이에 따라 패키지 편집은 패키지 자체의 더 범용적인 기능을 생각하며 들어가야 함
- 패키지를 업데이트 혹은 편집한다는 것은 프로젝트를 넘어 더 큰 그림을 봐야 함
- 패키지를 편집한다는 것의 목적을 알고 있는 상태에서 행동하기
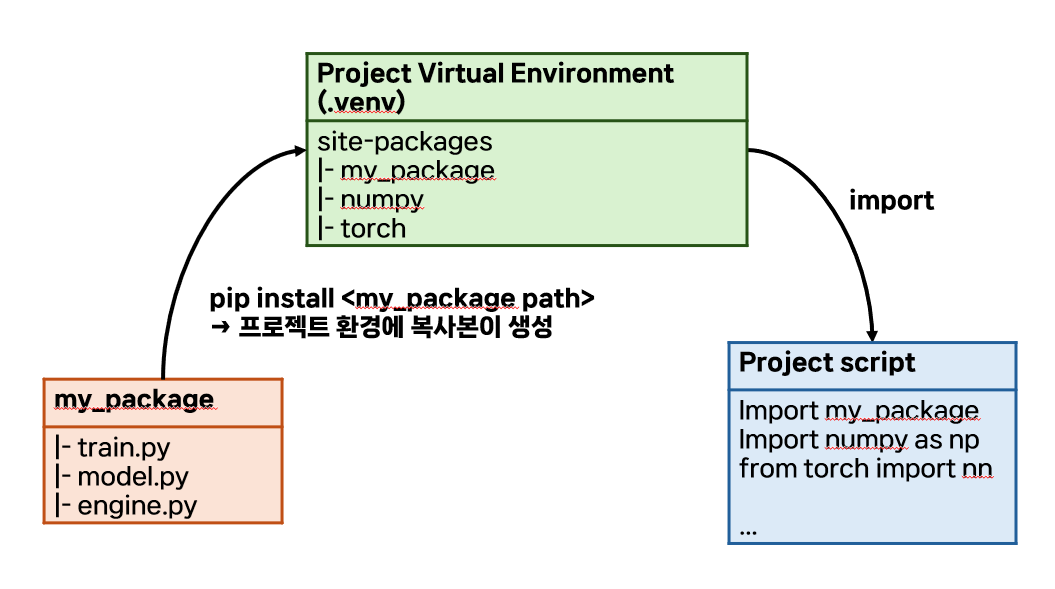
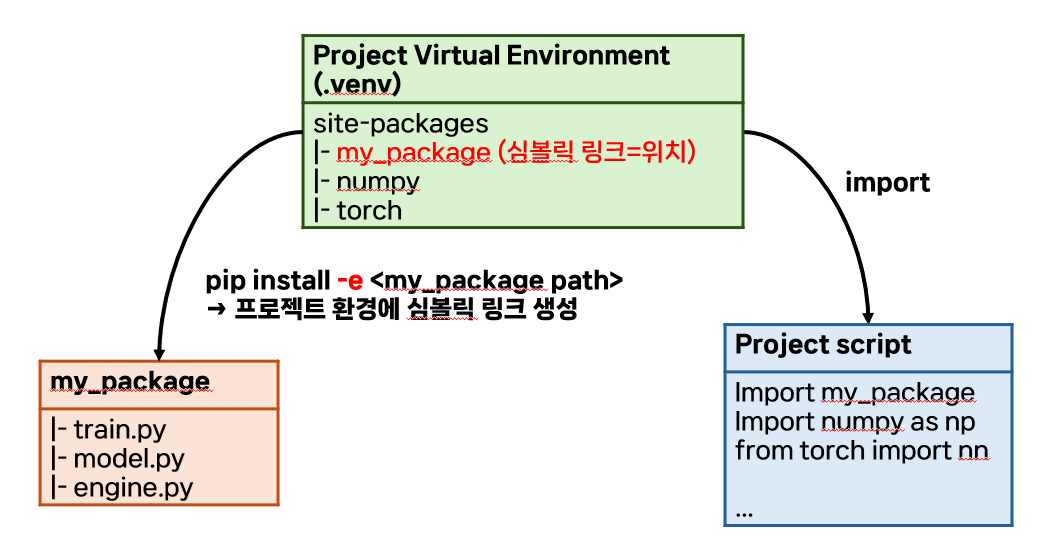
pip install <package 경로>실행 시 패키지가 가상 환경에 생기는 방법:
-e | --editable옵션은 프로젝트 가상 환경에 패키지를 설치할 때 site_packages로 패키지의 복사본을 가져오는 것이 아니라 해당 패키지의 심볼릭 링크를 생성시킴
- 심볼릭 링크: 파일 시스템에서 특정 파일 혹은 디렉토리를 가리키는 특별한 종류의 파일
- 즉, 해당 옵션으로 패키지를 가상 환경에 설치하면 패키지를 설치하는 것이 아니라 "패키지의 위치를 가리키는 파일"을 설치하는 것과 같음
- 즉, 아래 그림처럼 패키지에 접근:
- 프로젝트 가상 환경에서 sys.path(패키지 위치를 탐색하는 경로)를 출력해 보면 패키지가 로컬에서 위치한 경로까지 담고 있음
- editable 옵션은 편집할 패키지를 번거롭게 여러 번 설치해야 하는 상황을 없애거나 패키지 자체에 대한 작업을 독립적인 관점으로 바라볼 수 있게 하는 것
- 예시
- Hugging Face의
transformers라이브러리를git clone하여, 각 가상 환경에 따라 옵션 유무를 정하여 설치하고, 내부에 임의의 스크립트(doby_hello.py,doby_hi.py)를 만들어 확인한 결과, -e 옵션을 사용해야 패키지를 독립적으로 편집해도 심볼릭 링크에 의해서 패키지 업데이트가 추적이 가능합니다.
- pip install로 하고 라이브러리에 doby_hello.py 추가 시: 라이브러리 복사본
- pip install -e로 하고 라이브러리에 doby_hi.py 추가했을 때: 라이브러리 심볼릭 링크
- 해당 옵션의 대상이 되는 패키지에는
setup.py니pyproject.toml같은 파일이 필요

!python -m unidic download
from melo.api import TTS
speed = 1.0
device = "cpu"
text = "우리 반~ 점심 맛있게 먹고 오셨나요? 점심 후 첫 시간은 늘 졸리죠! 그래도 파이팅~"
model = TTS(language="KR", device=device)
speaker_ids = model.hps.data.spk2id
output_path = "kr.wav"
model.tts_to_file(text, speaker_ids["KR"], output_path=output_path, speed=speed)# Speaker 목록 확인
from pprint import pprint
pprint(speaker_ids){'KR': 0} # 0번 인덱스만 있음- 한국어 Speaker는 한 개만 존재 → 목소리 바꿀 수 없음...
다른 사람이 만들어 둔 모델 활용하기
이진 감정 분석
- daekeun-ml/koelectra-small-v3-nsmc
- 한국어 특화 모델: KoBERT, KoElectra
- koelectra: 한국어에 특화된 ELECTRA 모델
- 초기 BERT 모델보다 학습 효율 측면에서 향상된 모델
classifier = pipeline(
task="sentiment-analysis"
, model="daekeun-ml/koelectra-small-v3-nsmc"
, framework="pt"
, device=-1 # -1: cpu, 0: gpu
# CPU 사용 → -1, GPU 사용 → 0 (0번째 위치의 GPU를 사용하겠다는 뜻)
)추가: transformers 라이브러리의 pipeline 함수에서 framework="pt" (PyTorch) 옵션을 명시하지 않으면 오류가 발생하는 이유
- pipeline 함수에서 사용할 모델의 프레임워크(Pytorch 또는 TensorFlow)를 자동으로 추론하려고 시도하지만, 일부 환경에서는 이를 올바르게 판단하지 못해 에러가 발생할 수 있습니다.
- 대표적으로 두 프레임워크(torch, tensorflow)가 모두 설치되어 있거나, 모델 저장 파일의 포맷(.bin, .h5 등)과 프레임워크가 서로 일치하지 않는 경우 추론이 실패할 수 있습니다.
- 특히 koelectra, koelectra-base-finetuned-nsmc 같은 모델은 주로 PyTorch(.bin)로 배포되므로, transformers pipeline이 자동으로 TensorFlow로 인식하려다가 불일치로 인해 오류가 날 수 있습니다. 이럴 때 framework="pt" 옵션을 명시하면 PyTorch를 강제로 사용하게 되어 오류가 해결됩니다.
- 즉, pipeline이 내부적으로 프레임워크를 확실히 알지 못할 때 명시적으로 framework="pt"를 통해 어떤 백엔드를 사용할지 지정해줘야 합니다.
- 만약 framework 옵션을 생략할 때 오류가 난다면, 환경(설치된 프레임워크)이나 모델 포맷과 관련된 이슈일 수 있으니 framework="pt"로 지정하는 것이 안전합니다.
- 추가 설명:
- PyTorch 미설치, TensorFlow 단독 환경에서는 "tf"로, 반대로 TensorFlow 미설치, PyTorch 단독 환경에서는 "pt"가 자동으로 선택되지만, 두 프레임워크가 모두 설치된 환경에서는 혼동이 잦아 framework 옵션 지정이 필요합니다.
- 따라서, framework="pt"를 지정하지 않으면 pipeline이 내부적으로 적절한 백엔드를 자동으로 정하지 못해 오류가 발생하는 것이 원인입니다.
# 예측 수행: 0 → 부정, 1 → 긍정
classifier("넌 정말 좋은 사람이야, 고마워.")[{'label': '1', 'score': 0.9948970675468445}]classifier("너 미워! 너랑 다시는 안 볼 거야.")[{'label': '0', 'score': 0.9966574907302856}]# 여러 개 예측 가능
classifier(["오늘 수업 너무 재미있어요!", "별로인데?", "잘들 한다", "잘한다", "자~알 한다"])[{'label': '1', 'score': 0.9981163740158081},
{'label': '0', 'score': 0.9993563294410706},
{'label': '0', 'score': 0.8508732318878174},
{'label': '1', 'score': 0.9685253500938416},
{'label': '0', 'score': 0.9448397159576416}]- "자~알 한다" 텍스트만 보면 긍정이지만 사실 부정
- 부정으로 잘 분류됨 → 성능이 좋은 것을 확인
- 해당 모델의 성능이 뛰어남을 알 수 있음
번역 모델
ko_to_en = pipeline(
task="translation"
, model="Helsinki-NLP/opus-mt-ko-en"
, framework="pt"
)
ko_to_en("집에 가고 싶어요 오늘은 7시에 퇴근할 거에요.")[{'translation_text': "I want to go home. I'm going home at 7:00 today."}]ko_to_en("집에 가고 싶어요. 오늘은 7시에 퇴근할 거에요.")[{'translation_text': 'I want to go home.'}]- 온점이 들어가면 문장이 끝났다고 인식하는 듯하다.
ko_to_en("집에 가고 싶어요 오늘은 7시에 칼퇴근 할 거에요.")[{'translation_text': "I want to go home. I'm going back to work at 7:00 today."}]- 칼퇴근이라는 단어는 학습하지 못한 상태로 보임
제로샷 분류(Zero-shot Classification) ★
-학습할 때 한 번도 본 적 없는 레이블(클래스)에 대해 사전 학습된 모델이 알아서 의미적으로 분류 수행
- 사전 학습된 모델이 새로운 클래스에 대한 학습을 하지 않고 분류를 수행
- 장점:
- 학습 데이터가 없거나 부족한 경우 즉시 분류 사용 가능
- 유연하게 레이블을 추가/변경 가능
- 단점:
- 모델이 다루지 못하는 복잡한 task일 경우 성능 저하
- 제로샷 모델 예시
# 모델 로딩하기
zero_model = pipeline(
task="zero-shot-classification"
, model="joeddav/xlm-roberta-large-xnli"
, framework="pt"
, device=0 # 모델들이 GPU 기반에서 만들어진 거라 CPU로 하면 오류 발생하는 듯
)# 분류할 문장 정의
seq = [
# 폭싹 속았수다(드라마) 리뷰
"요즘 '폭싹속았수다' 보는 재미로 산다ㅠ 나 보는 거 엄마가 옆에서 보고는 아이유 연기 잘한다고 재밌게 보더니 나 없을 때 정주행하심ㅋㅋ"
# 정치 관련 뉴스 내용 일부분
, "최근 대선 후보에 대한 논쟁이 뜨겁습니다. 중앙선거관리위원회는 대부분의 후보가 오늘자로 후보자 등록 서류를 제출했다고 밝혔습니다."
, "리그 오브 레전드를 넘어 e스포츠의 상징으로 자리매김한 '페이커' 이상혁 선수가 2029년까지 T1과 함께하게 되었다."
]
# 후보 레이블 목록
can_labels = ["드라마/영화", "정치", "사회", "경제", "음식", "스포츠"]
result = zero_model(
seq
, can_labels
, multi_label=True
, hypothesis_template="이 문장은 {}와 관련이 있다."
)
# 결과 출력
for re in result:
print(f"입력문장: {re['sequence']}")
print(f"카테고리: {re['labels'][0]}")
print(f"확신도: {re['scores'][0]}")
print()입력문장: 요즘 '폭싹속았수다' 보는 재미로 산다ㅠ 나 보는 거 엄마가 옆에서 보고는 아이유 연기 잘한다고 재밌게 보더니 나 없을 때 정주행하심ㅋㅋ
카테고리: 드라마/영화
확신도: 0.9987292885780334
입력문장: 최근 대선 후보에 대한 논쟁이 뜨겁습니다. 중앙선거관리위원회는 대부분의 후보가 오늘자로 후보자 등록 서류를 제출했다고 밝혔습니다.
카테고리: 정치
확신도: 0.9994070529937744
입력문장: 리그 오브 레전드를 넘어 e스포츠의 상징으로 자리매김한 '페이커' 이상혁 선수가 2029년까지 T1과 함께하게 되었다.
카테고리: 스포츠
확신도: 0.9979007840156555- zero_model: 자연어 학습을 통해 문장 간의 관계를 학습
- 클래스를 직접적으로 학습한 것이 아니라 의미적 관계를 파악하는 능력을 학습한 것
추가: hypothesis_template의 의미와 역할
- 역할 및 의미
- hypothesis_template은 zero-shot classification(제로샷 분류)에서 사용되는 문장 템플릿
- zero-shot classification은 미리 정의된 레이블(label)마다 자연어로 hypothesis(가설) 문장을 구성해서, 입력 문장과 이 가설이 "참/거짓(entailment/contradiction)" 관계에 가까운지를 평가하는 원리
- hypothesis_template은 레이블을 자연스럽게 한국어 문장에 끼워 넣기 위한 서식
- 예시:
- hypothesis_template="이 문장은 {}와 관련이 있다."
- can_labels = ["정치", "사회", "경제"]
- 입력 문장이 "부동산 가격이 급등하고 있다."라면, 내부적으로 다음과 같은 세 문장이 생성됨:
- "이 문장은 정치와 관련이 있다."
- "이 문장은 사회와 관련이 있다."
- "이 문장은 경제와 관련이 있다."
- 모델은 각각의 "가설 문장(hypothesis)"과 입력 문장(이 경우 'premise')의 의미적 관련성(자연언어추론; NLI)을 판별
- 각각에 대해 "참(entailment)"일 확률, "거짓(contradiction)"일 확률 등을 예측합니다.
- 이 예측값들을 종합해 어떤 레이블이 가장 관련 있는지, 혹은 여러 개가 관련 있는지를 반환
- 어떻게 쓸 수 있나 – 사용자화
- hypothesis_template은 한국어 분류 작업에서 레이블을 자연스런 문장으로 녹여내는 데 필수적
- 템플릿 내의 중괄호
{}에 각 레이블값이 들어감
즉,hypothesis_template="이 문장은 {}와 관련이 있다." # -> "이 문장은 정치와 관련이 있다." (정치가 레이블일 때)
- 다른 식으로도 변형할 수 있음:
- "이 글의 주제는 {}이다."
- "{}에 대한 내용이다."
- "이 텍스트는 {}에 속한다."
- 이렇게 템플릿을 상황에 맞게 바꿔쓸 수 있음 → 자연스러운 문장일수록 모델의 성능이 잘 나올 수 있음
- 참고
- 영어에서는 기본값이 "This example is about {}." 형태
- 한국어에서는 자연스럽게 번역하여 사용
- 템플릿은 반드시
{}부분이 있어야 하고, 여기서 레이블이 대입됨- 정리:
- hypothesis_template은 입력 문장과 각 레이블이 얼마나 관련 있는지 평가하기 위해 "자연어 추론(NLI) 식 분류"를 가능하게 하는 문장 생성 서식
- 한국어로 쓸 때는 각 작업/데이터셋에 맞게 의미가 자연스러운 문장으로 바꿔서 사용
실습: ViT
이미지 데이터 결과 확인
- ViT (Vision Transformer): 트랜스포머 기반 모델
- 처리 방법
- 원본 이미지를 격자 형태로 쪼개서 서브 이미지를 만듦
- 왜 쪼개서 만드나요? transformer가 자연어 처리 모델이기 때문에 비슷한 원리로 학습시키기 위함
- 쪼개진 이미지를 선형으로 투영
- 투영된 데이터를 자연어 처리하는 것처럼 ViT 모델 입력으로 사용
- 원본 이미지를 격자 형태로 쪼개서 서브 이미지를 만듦
- 콩잎의 건강 상태를 알아보는 모델을 만들어보자
# 버전 차이 나는 라이브러리 업데이트
!pip install accelerate -U
# 업데이트 후 세션 다시 시작# 허깅페이스에 저장된 데이터 로딩
from datasets import load_dataset
data_beans = load_dataset("beans")
data_beansDatasetDict({
train: Dataset({
features: ['image_file_path', 'image', 'labels'],
num_rows: 1034
})
validation: Dataset({
features: ['image_file_path', 'image', 'labels'],
num_rows: 133
})
test: Dataset({
features: ['image_file_path', 'image', 'labels'],
num_rows: 128
})
})# 이미지 확인
data_beans["train"][5]["image"]
data_beans["train"][5]["labels"]0# 정답 종류 확인
data_beans["train"].features{'image_file_path': Value('string'),
'image': Image(mode=None, decode=True),
'labels': ClassLabel(names=['angular_leaf_spot', 'bean_rust', 'healthy'])}- 0번 인덱스: angular_leaf_spot → 모자이크병
- 1번 인덱스: bean_rust → 콩곰팡이
- 2번 인덱스: healthy → 건강
학습할 이미지 데이터와 검증/평가할 이미지 데이터 크기를 꼭 맞춰주어야 합니다!
이미지 전처리
- 이미지 사이즈 맞추기
- 각 이미지의 크기가 다를 수 있음
- 어떤 모델을 쓰냐에 따라 맞게 전처리르 해 주어야 함
- 이미지 분석 모델에 따라 전처리 도구를 다르게 사용 → 동일 전처리 도구 불러다 사용하기
- 허깅페이스에서 제공함
from transformers import ViTFeatureExtractor
# 사전에 만들어 둔 이미지 특징추출기 (이미지 임베딩) 다운로드
model_name = "google/vit-base-patch16-224-in21k" #모델이름
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name)
feature_extractor # 정규화 과정까지 이미 다 거쳐준 상태ViTFeatureExtractor {
"do_convert_rgb": null,
"do_normalize": true,
"do_rescale": true,
"do_resize": true,
"image_mean": [
0.5,
0.5,
0.5
],
"image_processor_type": "ViTFeatureExtractor",
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"rescale_factor": 0.00392156862745098,
"size": {
"height": 224,
"width": 224
}
}- 높이와 너비 확인: (224, 224)
- 정규화 확인: 평균, 표준편차 0.5 정규화
# 이미지 한 장을 전처리해 봅시다:
feature_extractor(data_beans["train"][0]["image"], return_tensors="pt"){'pixel_values': tensor([[[[-0.5686, -0.5686, -0.5608, ..., -0.0275, 0.1843, -0.2471],
[-0.6078, -0.6000, -0.5765, ..., -0.0353, -0.0196, -0.2627],
[-0.6314, -0.6314, -0.6078, ..., -0.2314, -0.3647, -0.2235],
...,
[-0.5373, -0.5529, -0.5843, ..., -0.0824, -0.0431, -0.0902],
[-0.5608, -0.5765, -0.5843, ..., 0.3098, 0.1843, 0.1294],
[-0.5843, -0.5922, -0.6078, ..., 0.2627, 0.1608, 0.2000]],
[[-0.7098, -0.7098, -0.7490, ..., -0.3725, -0.1608, -0.6000],
[-0.7333, -0.7333, -0.7569, ..., -0.3647, -0.3255, -0.5686],
[-0.7490, -0.7490, -0.7725, ..., -0.5373, -0.6549, -0.5373],
...,
[-0.7725, -0.7804, -0.8196, ..., -0.2235, -0.0353, 0.0824],
[-0.7961, -0.8118, -0.8118, ..., 0.1922, 0.3098, 0.3725],
[-0.8196, -0.8196, -0.8275, ..., 0.0824, 0.2784, 0.3961]],
[[-0.9922, -0.9922, -1.0000, ..., -0.5451, -0.3569, -0.7255],
[-0.9922, -0.9922, -1.0000, ..., -0.5529, -0.5216, -0.7176],
[-0.9843, -0.9922, -1.0000, ..., -0.6549, -0.7569, -0.6392],
...,
[-0.8431, -0.8588, -0.8980, ..., -0.5765, -0.5529, -0.5451],
[-0.8588, -0.8902, -0.9059, ..., -0.2000, -0.2392, -0.2627],
[-0.8824, -0.9059, -0.9216, ..., -0.2549, -0.2000, -0.1216]]]])}- 사전학습 모델이 사용한 프레임워크인 PyTorch에 맞는 데이터 타입인 Tensor로 변경
- 사전학습 모델이 사용한 도구를 그대로 사용해 주는 것이 좋음!
# 모든 데이터 전처리 → 함수 정의
def transform (example_batch):
inputs = feature_extractor([x for x in example_batch["image"]], return_tensors="pt")
inputs["labels"] = example_batch["labels"]
return inputs
# 사용자 정의 함수 적용
prepared_data = data_beans.with_transform(transform)
prepared_data # feature_extractor를 통해 전처리된 결과가 담겨 있음DatasetDict({
train: Dataset({
features: ['image_file_path', 'image', 'labels'],
num_rows: 1034
})
validation: Dataset({
features: ['image_file_path', 'image', 'labels'],
num_rows: 133
})
test: Dataset({
features: ['image_file_path', 'image', 'labels'],
num_rows: 128
})
})prepared_data["train"].features{'image_file_path': Value('string'),
'image': Image(mode=None, decode=True),
'labels': ClassLabel(names=['angular_leaf_spot', 'bean_rust', 'healthy'])}추가: 이미지 크기 확인
prepared_data["train"].features에서 'image'는 일반적으로 datasets.Image feature 형식이기 때문에, 각 이미지의 크기를 확인하려면 데이터셋의 샘플에서 이미지를 추출해서 해당 이미지의 shape 또는 size를 확인해야 합니다.from PIL import Image def get_image_size(dataset, index): """ dataset: prepared_data["train"] 등 데이터셋 객체 index: 이미지 확인할 샘플 인덱스 반환: (width, height) 튜플 형태 이미지 크기 """ sample = dataset[index] img = sample['image'] if isinstance(img, Image.Image): return img.size # (width, height) elif hasattr(img, 'shape'): # numpy array 형태인 경우 (height, width, channels) shape = img.shape return (shape[1], shape[0]) # (width, height) elif hasattr(img, 'size'): return img.size # 텐서 등 다른 타입 size 반환 (일부러 포괄적으로) else: raise ValueError("이미지 크기를 확인할 수 없는 타입입니다.") # 사용 예 # width, height = get_image_size(prepared_data["train"], 0) # print(width, height)또는 torchvision transforms를 사용할 경우, 다음 함수도 활용할 수 있습니다:
- torchvision.transforms.functional.get_image_size(img) 함수: PIL Image 또는 Tensor에서도 [width, height] 값을 반환
- 즉, prepared_data에서 개별 샘플(예: prepared_data["train"])을 얻고, 그 안의 'image' 필드의 size, shape, 혹은 get_image_size(img)를 사용
prepared_data["train"][0]{'pixel_values': tensor([[[-0.5686, -0.5686, -0.5608, ..., -0.0275, 0.1843, -0.2471],
[-0.6078, -0.6000, -0.5765, ..., -0.0353, -0.0196, -0.2627],
[-0.6314, -0.6314, -0.6078, ..., -0.2314, -0.3647, -0.2235],
...,
[-0.5373, -0.5529, -0.5843, ..., -0.0824, -0.0431, -0.0902],
[-0.5608, -0.5765, -0.5843, ..., 0.3098, 0.1843, 0.1294],
[-0.5843, -0.5922, -0.6078, ..., 0.2627, 0.1608, 0.2000]],
[[-0.7098, -0.7098, -0.7490, ..., -0.3725, -0.1608, -0.6000],
[-0.7333, -0.7333, -0.7569, ..., -0.3647, -0.3255, -0.5686],
[-0.7490, -0.7490, -0.7725, ..., -0.5373, -0.6549, -0.5373],
...,
[-0.7725, -0.7804, -0.8196, ..., -0.2235, -0.0353, 0.0824],
[-0.7961, -0.8118, -0.8118, ..., 0.1922, 0.3098, 0.3725],
[-0.8196, -0.8196, -0.8275, ..., 0.0824, 0.2784, 0.3961]],
[[-0.9922, -0.9922, -1.0000, ..., -0.5451, -0.3569, -0.7255],
[-0.9922, -0.9922, -1.0000, ..., -0.5529, -0.5216, -0.7176],
[-0.9843, -0.9922, -1.0000, ..., -0.6549, -0.7569, -0.6392],
...,
[-0.8431, -0.8588, -0.8980, ..., -0.5765, -0.5529, -0.5451],
[-0.8588, -0.8902, -0.9059, ..., -0.2000, -0.2392, -0.2627],
[-0.8824, -0.9059, -0.9216, ..., -0.2549, -0.2000, -0.1216]]]),
'labels': 0}# 변환 후 이미지 크기
prepared_data["train"][5]["pixel_values"].shapetorch.Size([3, 224, 224])# 변환 전 이미지 크기와 비교
data_beans["train"][5]["image"].size(500, 500)- 변환 전 500, 500 크기였던 이미지가 224, 224로 변환된 것을 확인
학습 및 검증
- 배치 단위로 넣어 줄 예정
- 콩잎 데이터 약 1000장
- 쪼개서 학습: 효율적인 메모리 사용을 위하여
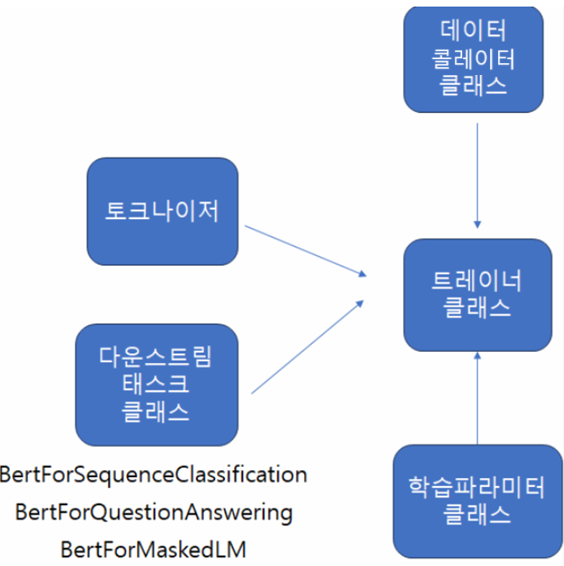
- 평가방법 함수 지정
- 사전 학습 모델 불러오기
- 모델의 하이퍼파라미터 정의 → 클래스(TrainingArguments)
- 위dml 4개를 모두 모아 학습: Trainer 클래스
- 학습 클래스: Trainer
data_collator 클래스 정의, 평가방법 지정, 모델 정의, 모델의 하이퍼파라미터 정의
# 데이터 준비
import torch
def coll_fn(batch): # 배치 단위 함수
return {
"pixel_values": torch.stack([x["pixel_values"] for x in batch])
, "labels": torch.stack(x["label"] for x in batch)
}
# 평가방법 지정
!pip install evaluate
import evaluate
metric = evaluate.load("accuracy")
import numpy as np
def compute_metrics(p):
return metric.compute(predictions=np.argmax(p.predictions, axis=1), references=p.label_ids)
data_beans["train"].features["labels"].names['angular_leaf_spot', 'bean_rust', 'healthy']# 사전학습된 모델 불러오기
from transformers import ViTForImageClassification
label_names = data_beans["train"].features["labels"].names
model = ViTForImageClassification.from_pretrained(
model_name
, num_labels=len(label_names)
, id2label = {str(i): c for i, c in enumerate(label_names)}
, label2id = {c: str(i) for i, c in enumerate(label_names)}
)
# 학습에 사용되는 파라미터 작성
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./vit-base-beans-demo-v5" # 출력 디렉토리
, per_device_train_batch_size=16 # 학습 배치 크기
, per_device_eval_batch_size=16 # 평가 배치 크기 (생략 가능하지만 명시 권장)
, num_train_epochs=4 # 전체 학습 에폭 수
, learning_rate=2e-4 # 학습률
, eval_strategy="steps" # 평가 전략 ("no", "epoch", "steps") → 버전에 따라 'evaluation_strategy="steps"'로 적어야 할 수도 있음
, eval_steps=100 # 평가 주기 (steps 단위)
, save_steps=100 # 체크포인트 저장 주기
, logging_steps=10 # 로그 출력 주기
, save_total_limit=2 # 체크포인트 최대 개수
, fp16=True # GPU가 A100, V100 등이면 True (없으면 False)
, remove_unused_columns=False # Trainer가 col 삭제 방지
, report_to="tensorboard" # 로깅 백엔드 설정 ("none", "wandb", "tensorboard")
, load_best_model_at_end=True # 가장 좋은 모델 저장
, metric_for_best_model="accuracy" # 가장 좋은 모델 기준 metric
, greater_is_better=True # metric 클수록 좋다고 간주 (예: accuracy)
, push_to_hub=False # 🤗 Hub에 업로드 안 함
)하루 돌아보기
👍 잘한 점
- hugging face transformers 공식 문서 찾아보면서 공부함
- 수업 중 대답 열심히 했음
- 자연어 처리 교재 진도 맞춰서 학습 진행
👎 아쉬웠던 점
- 오늘 수업 내용이 조금 어려워서 수업 시간에 집중을 잘 못했음
🔬 개선점
- 강의 녹화본 올라오면 바로 복습하고 내용 추가 정리하기
