목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. request 활용하기
3. response 활용하기
B. 2교시
1. response 활용하기 (cont.)
2. 파일 활용
C. 3교시
1. form 태그로 데이터 주고받기
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
2. 메모리를 가진 챗봇 구현
B. 5교시
1. ConversationChain 클래스가 더 이상 권장되지 않는 문제
2. RunnableWithMessageHistory
C. 6교시
1. RAG (Retrieval - Argumented Generation)
2. PDF를 학습한 나만의 챗봇 만들기
Ⅲ. CAREER UP
A. 현직자 특강
Ⅳ. 하루 돌아보기Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
- Node.js
- JS를 웹 브라우저가 아닌 외부에서 쓸 수 있도록 해 주는 운영 환경/런타임 환경 (서버 아님)
- 웹 엔진을 밖으로 빼온 것
- JS를 웹 브라우저가 아닌 외부에서 쓸 수 있도록 해 주는 운영 환경/런타임 환경 (서버 아님)
- 서버의 등장
- web2.0: 사용자가 모든 데이터를 생성하는 시대 → 기존 방식처럼 모든 페이지를 개발자가 만들 수 없음 → template만 사람이 만들고 알맹이는 서버가 채워넣게 하고 싶어~ → 서버 & 서버 프로그래밍 등장
- Node.js 특징
- 이벤트 기반
- 비동기 통신 지향
- non-blocking 통신 형태
- single thread
- 하나지만 빠르고 능률 좋고 유능함 → 한 번에 업무를 받아 빨리 끝나는 것부터 처리해줌
- 빨리 끝난다의 기준은 컴퓨터가 알아서 정함 → 주의점: 코드끼리 연관되어 있을 떄 오류날 수 있음(3번 줄 코드를 4번 줄에서 써야 하는데 3번 줄 처리가 오래 걸리면 컴퓨터가 3번 줄 건너뛰고 4번 줄 처리해버려서 오류 발생)
| blocking(동기) | non-blocking(비동기) |
|---|---|
| 설계가 매우 간단하고 직관적 | 결과가 주어지는데 시간이 걸리더라도 그 시간 동안 다른 작업 가능 |
| 결과가 주어질 때까지 대기 → 시간 효율 좋지 않음 | 동기보다 코드 짜기 복잡함 |
- 모듈
- 서버 만들 때 가장 기본이 되는 단위
- 여러 개의 모듈을 조합해 하나의 서버를 만듦
- 필요한 기능별로 모아둔 퍼즐
- 파이썬 라이브러리와 상응하는 개념
- 장점: 불러다 쓰기만 하면 됨
- 단점: 자동 완성 지원 안 함. 기본 틀이란 게 없음
require로 불러와야 함const {result} = require("./0_더하기모듈");const http = require("http");
- 내장 모듈 / 자체 제작 모듈 / 외장 모듈
- 모듈은 상수에 담아서 활용 → 이름이 중복될 수 없게 만듦
- 서버 만들 때 가장 기본이 되는 단위
- 간단한 서버, 간단한 통신, 짧은 단방향 통신에 사용 (채팅 등)
- 대규모 서버/큰 서비스는 JAVA 언어 베이스 서버 사용해야 함 (매우 어려움)
- 자체 제작 모듈 작성 시 주의 사항
- 내가 직접 모듈을 만들 때는 반드시 마지막 줄에 수출 진행해야 함:
module.exports = {result};
- 내가 직접 모듈을 만들 때는 반드시 마지막 줄에 수출 진행해야 함:
- HTTP 모듈
- 로컬에 간단한 서버 제작
- 현재는 거의 사용되지 않음
- 할 수 있는 역할이 매우 적기 때문
- cf. flask, FastAPI
- req, res: 서버 만들면 반드시 넣어야 하는 두 개의 매개 변수
- req → 사용자(client)가 보낸 모든 데이터가 담기는 공간 (ip, data, 환경, …)
- res → 서버가 사용자에게 보낼 데이터를 담는 공간
- 이름은 자유롭게 적어도 순서는 반드시 지켜야 함
- request-ip 모듈
- 접속한 사용자의 ip를 받아오는 모듈
- NPM으로 받아와야 함
- 내 컴퓨터에 접속한 사람의 ip 확인
- 접속한 사용자의 ip를 받아오는 모듈
2. request 활용하기
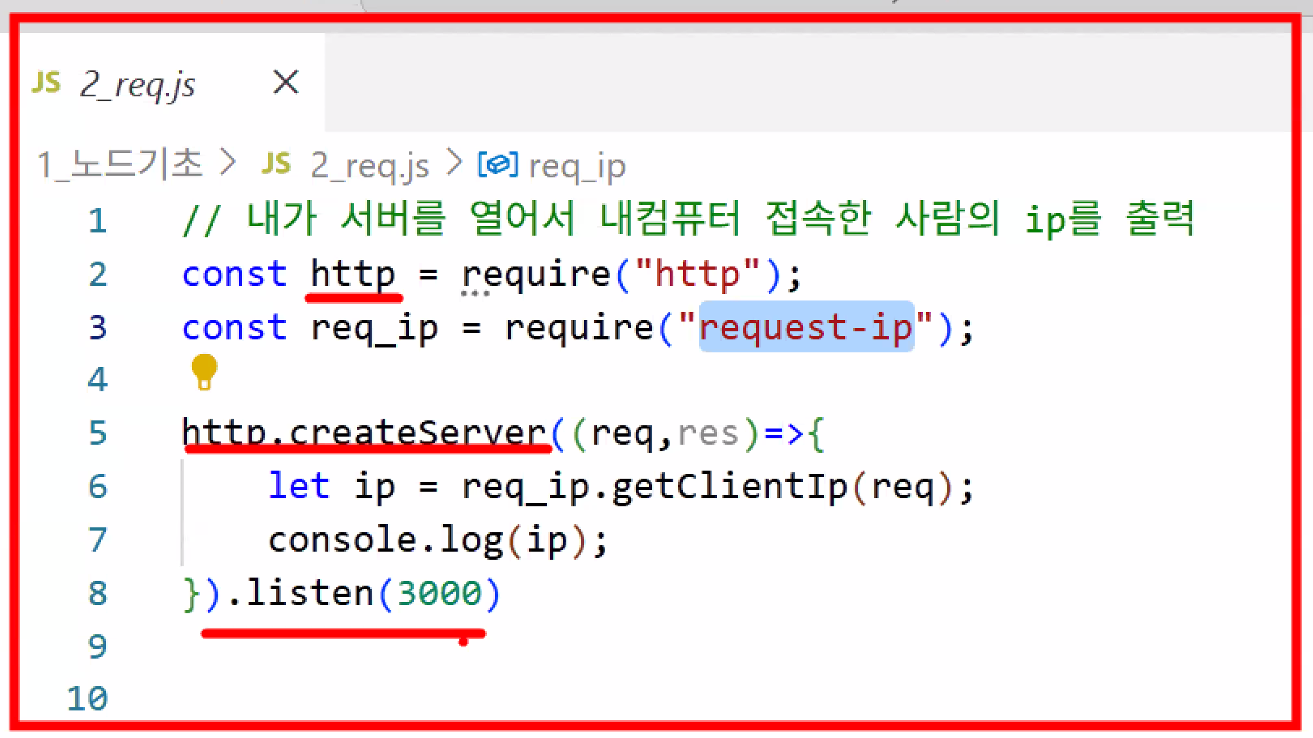
- 서버 켜기
- ctrl + ` : 터미널 창 켜기
- 항상 경로 조심!
cd .\1_노드기초\node .\2_req.js
- ctrl + ` : 터미널 창 켜기
- cmd 창 열기
ipconfig입력
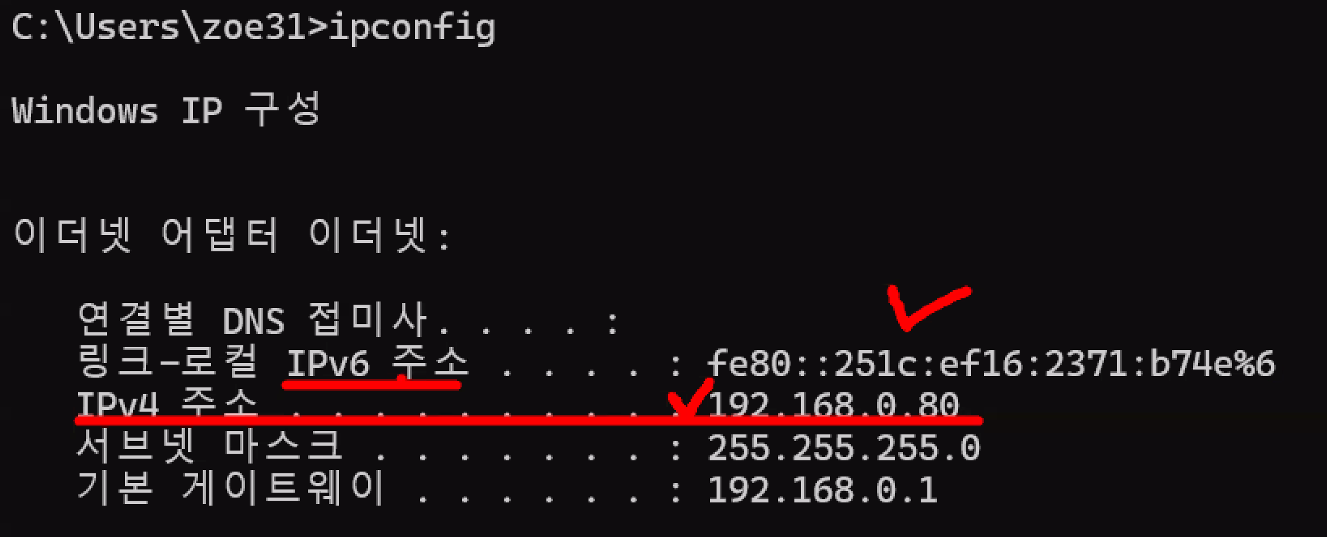
- IPv4와 IPv6: 컴퓨터가 많아져서 기존 IP 개수에 조금씩 한계가 찾아옴 → v6로 확장 (아직 상용화까진 아님)
- IPv4 주소 아이피 복사하고 웹 브라우저에 붙여넣기 →
:3000포트 붙이기 → 터미널 확인
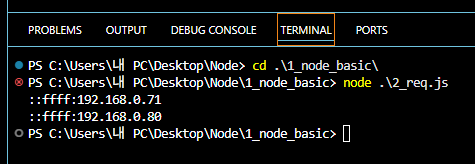
- 포트가 같은 사람(같은 대역대인 사람)끼리만 소통 가능 → 개인 IP/로컬 IP/사설 IP → 유동 IP라 일정 기간마다 바뀜
- request에는 사용자의 모든 정보가 담겨 있기 때문에
let ip = req_ip.getClientIp(req);로 ip 정보를 가져올 수 있음
3. response 활용하기
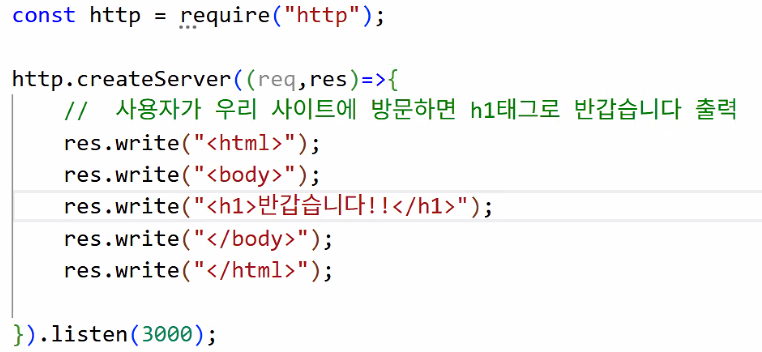
- 사용자가 우리 사이트에 방문하면 h1 태그로 '반갑습니다' 출력해주기
- 간단하게 아래 태그만 보낼 것

- 간단하게 아래 태그만 보낼 것
- 아래와 같이 작성하기
- 웹 브라우저에
localhost:3000입력
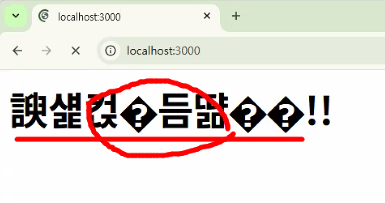
- 문제점 두 가지
- 한글 인코딩이 안 됨 (한글 지원 x)
- 정보를 담고 있는 head 태그가 없어서
- 계속 로딩이 돌고 있음 (코드가 무한반복 실행) → 다음 작업으로 넘어갈 수 없음
- 아직 업무가 끝나지 않았다는 뜻!
- 한글 인코딩이 안 됨 (한글 지원 x)
- 문제점 두 가지
서버 수정할 때는 항상 서버를 먼저 끄자! → CTRL + C
- 문제점 해결하기
- 한글 미지원: head를 만들지 않았기 때문에 인코딩 정보가 없음 → 해결책: head 정보를 생성
- 서버가 무한으로 돌아간다 → 응답 작성 후에는 반드시 응답이 종료됐다고 알려 주는 명령이 필요함
B. 2교시
1. response 활용하기 (cont.)
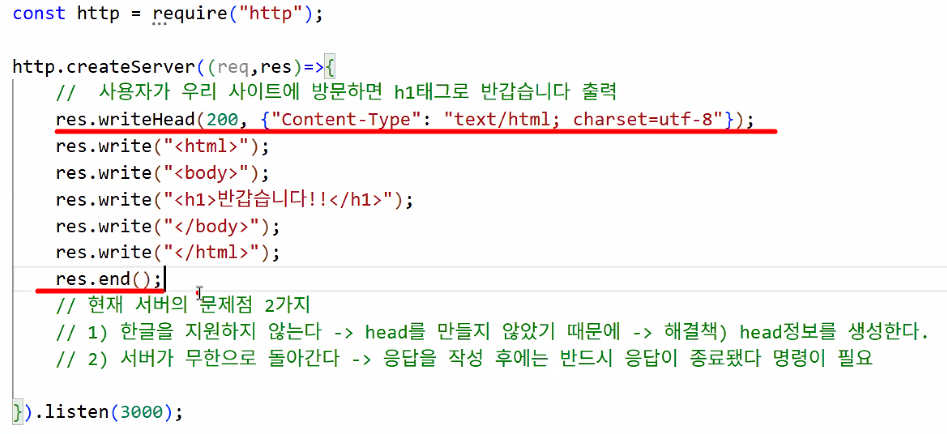
- head 만들기:
.writeHead();res.writeHead(200,{"Content-Type":"text/html;charset=utf-8"});- 200이 의미하는 것: 응답 성공하면 헤드를 만들겠다는 뜻
- text/html →
<!DOCTYPE html> - charset=utf-8 →
<meta charset="UTF-8">
- 응답 종료:
.end();
- 수정 후 서버 다시 열고 확인
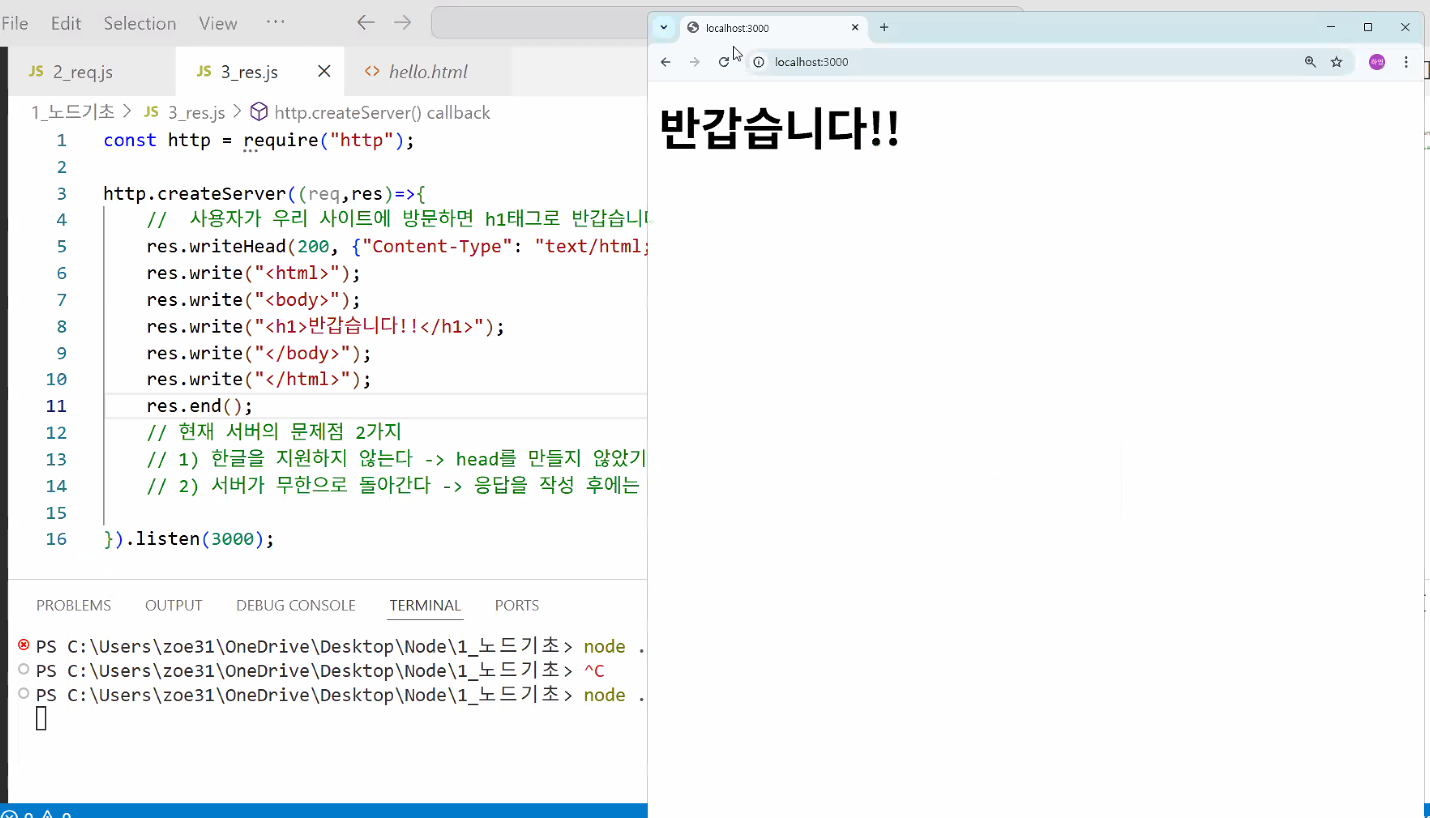
- 추가: write 함수가 계속 반복됨 → 줄일 수 있음
- 변수에 저장하기

- 변수에 저장하기
사실 위에서 쓴 기법들은 실제로는 잘 사용하지 않아요~
2. 파일 활용
- 미리 제작해 둔 HTML 파일을 사용자에게 보내주는 실습
- 정적 페이지를 활용한다 → 사용자마다 모두 똑같은 화면을 볼 때
- 모듈: fs모듈(filesystem) → 파일을 넘길 때 활용하는 모듈(내장모듈)
const fs = require("fs").promises;
- 포인트: 사용자에게 응답을 담당하는 변수는 res → html 파일을 넘겨준다.
/*
실습 목표: 미리 제작해 둔 HTML 파일을 사용자에게 보내주는 실습
* 정적 페이지를 활용한다 → 사용자마다 모두 똑같은 화면을 볼 때
* 모듈: fs모듈(filesystem) → 파일을 넘길 때 활용하는 모듈(내장모듈)
* 키 포인트: 사용자에게 응답을 담당하는 변수는 res → html 파일을 넘겨준다.
실습 핵심: node는 기본적으로 비동기로 코드를 처리 → 작업이 오래 걸리지 않는 업무를 먼저 처리
* 주의점: 오래 걸리는 코드의 결과를 활용하는 코드는 오류가 발생
* 해결책: 개발자가 임의로 코드의 순서를 지정한다.
* async/await → await를 만나면 해당 코드가 끝날 때까지 밑의 코드를 실행하지 않는다.
*/
const http = require("http");
const fs = require("fs").promises;
http.createServer(async (req,res)=>{
let html = await fs.readFile("./return.html");
res.writeHead(200, {"Content-Type": "text/html; charset=utf-8"});
res.write(html);
res.end();
}).listen(3000);node:_http_outgoing:950
throw new ERR_INVALID_ARG_TYPE(
^
TypeError [ERR_INVALID_ARG_TYPE]: The "chunk" argument must be of type string or an instance of Buffer or Uint8Array. Received an instance of Promise
at write_ (node:_http_outgoing:950:11)
at ServerResponse.write (node:_http_outgoing:905:15)
at Server.<anonymous> (C:\Users\내 PC\Desktop\Node\1_node_basic\4_file.js:13:9)
at Server.emit (node:events:519:28)
at parserOnIncoming (node:_http_server:1168:12)
at HTTPParser.parserOnHeadersComplete (node:_http_common:117:17) {
code: 'ERR_INVALID_ARG_TYPE'
}
Node.js v22.19.0- 헉 오류 → 13번째 줄:
res.write(html);에서 왜 오류가 날까?- Node.js는 non-blocking 방식 & 비동기 & single thread 기법 → 파일 불러오는 부분이 오래 걸리니까 컴퓨터가 놔두고 빨리 끝나는 것부터 실행: 파일을 읽어들이는 행위가 글자(문자열) 그냥 쓰는 것보다 훨씬 더 업무의 크기가 큼
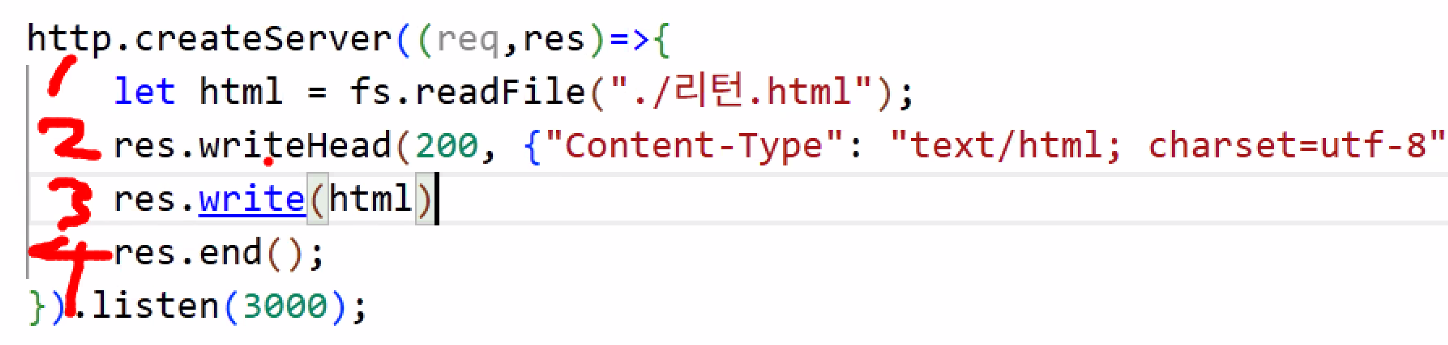
- 1번 오래걸림 → 건너뛰고 2, 3, 4 먼저 실행 (node는 non-blocking 비동기 방식이니까) → 그런데 3 실행하려면 1이 필요함 → html 어디 있어? 아직 파일 없는데요 → 오류 발생!
- 실행 순서 결정을 내가 아니라 컴퓨터가 하기 때문에 코드 순서 짜는 게 어렵다
- Node.js는 non-blocking 방식 & 비동기 & single thread 기법 → 파일 불러오는 부분이 오래 걸리니까 컴퓨터가 놔두고 빨리 끝나는 것부터 실행: 파일을 읽어들이는 행위가 글자(문자열) 그냥 쓰는 것보다 훨씬 더 업무의 크기가 큼
- ★ 실습 핵심: node는 기본적으로 비동기로 코드를 처리 → 작업이 오래 걸리지 않는 업무를 먼저 처리 ★
- 주의점: 오래 걸리는 코드의 결과를 활용하는 코드는 오류가 발생
- 해결책: 개발자가 임의로 코드의 순서를 지정한다. → async/await
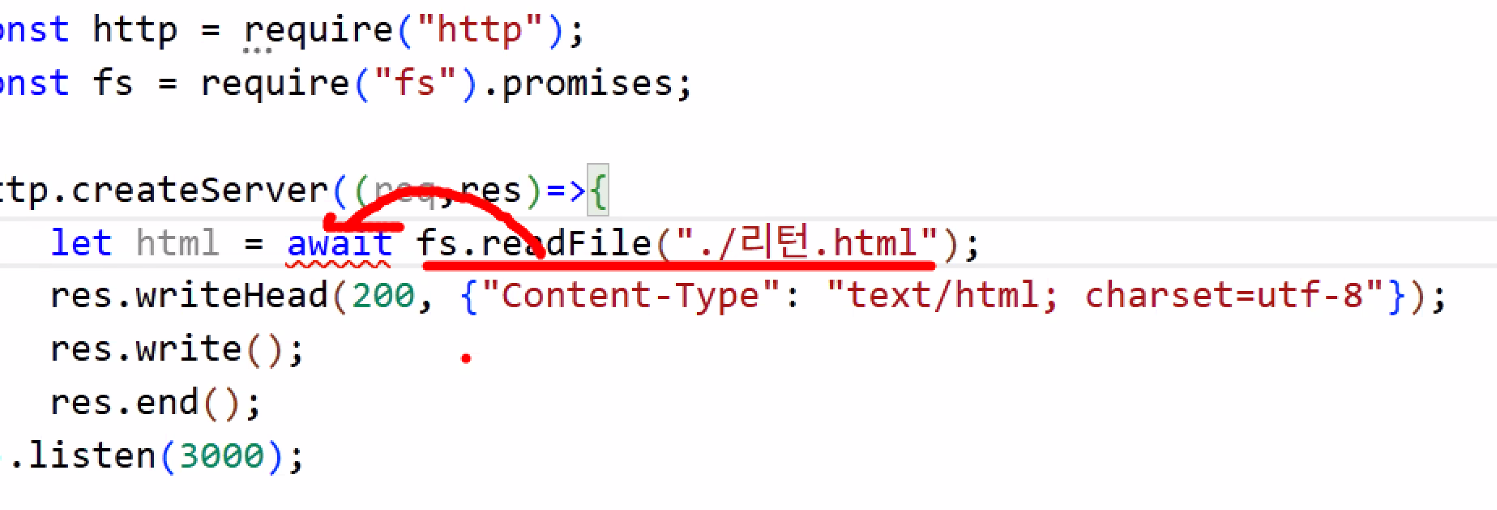
- await의 특징 알아두기: 혼자서는 못 씀. 꼭 앞에 async 있어야 함.

- await의 특징 알아두기: 혼자서는 못 씀. 꼭 앞에 async 있어야 함.
- async/await
- await를 만나면 해당 코드가 끝날 때까지 밑의 코드를 실행하지 않는다.
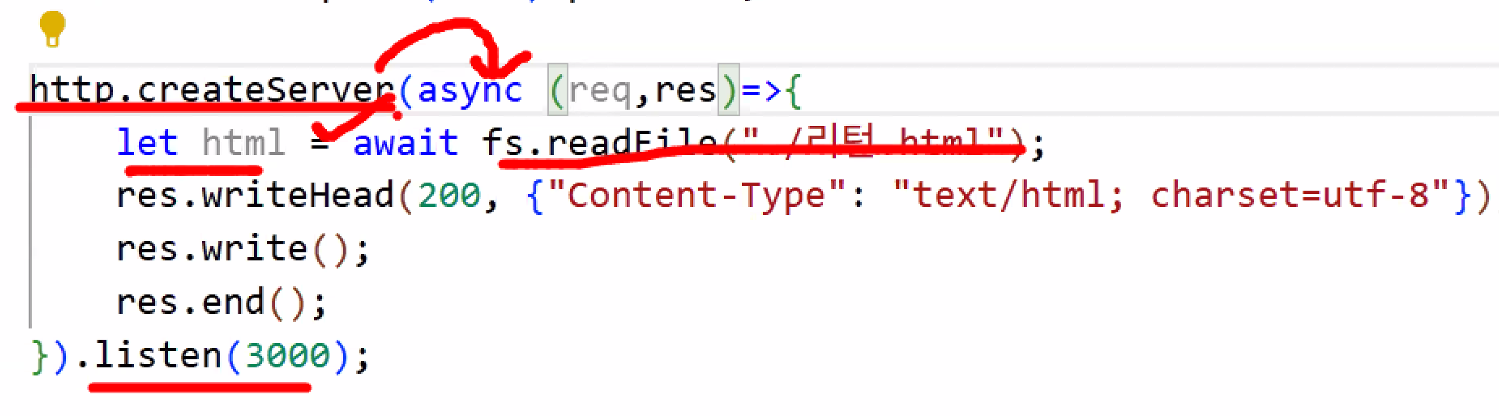
- async는 한 번만 적어주면 되고 await는 기다려야 하는 곳마다 적으면 됨
- cf. fetch-then과 같은 원리
- await를 만나면 해당 코드가 끝날 때까지 밑의 코드를 실행하지 않는다.
const http = require("http");
const fs = require("fs").promises;
http.createServer(async (req,res)=>{
let html = await fs.readFile("./return.html");
res.write(html);
res.end();
}).listen(3000);express 프레임워크 쓰면 알아서 처리해 주니까 너무 많이 신경쓰진 말고 개념 정도만 기억하세요~
C. 3교시
1. form 태그로 데이터 주고받기
- 실습 목표: login.html에서 보낸 데이터를 서버에서 조회
- 포인트: get 방식의 조회 방식 학습 → 모든 데이터가 url에 담겨 온다.
- login.html 만들기
- form 태그 활용
- action="http://localhost:3000"
- method="get"
- 라이브 서버로 열고 id, pw 입력한 뒤 정보 보내기
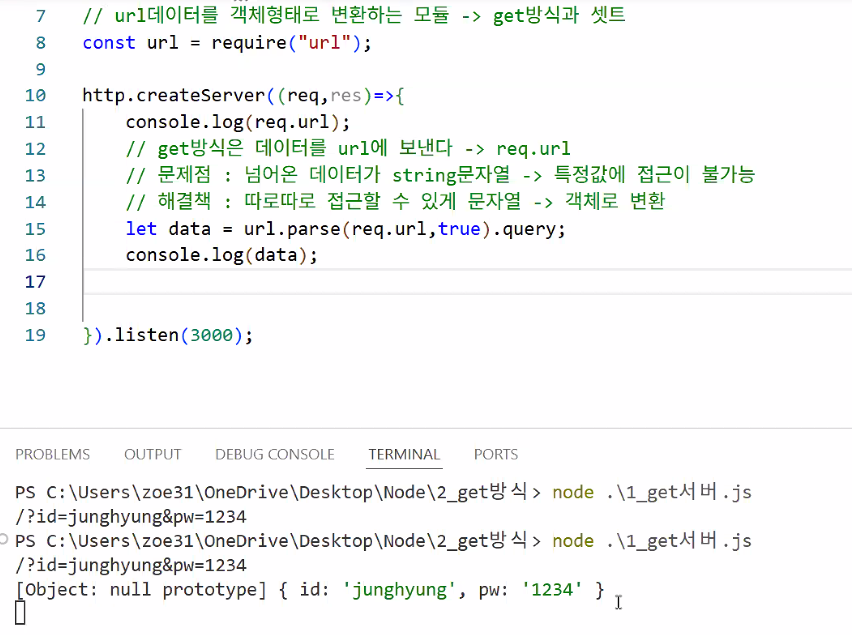
- url만 가져오면 아래와 같이 콘솔창에 출력됨
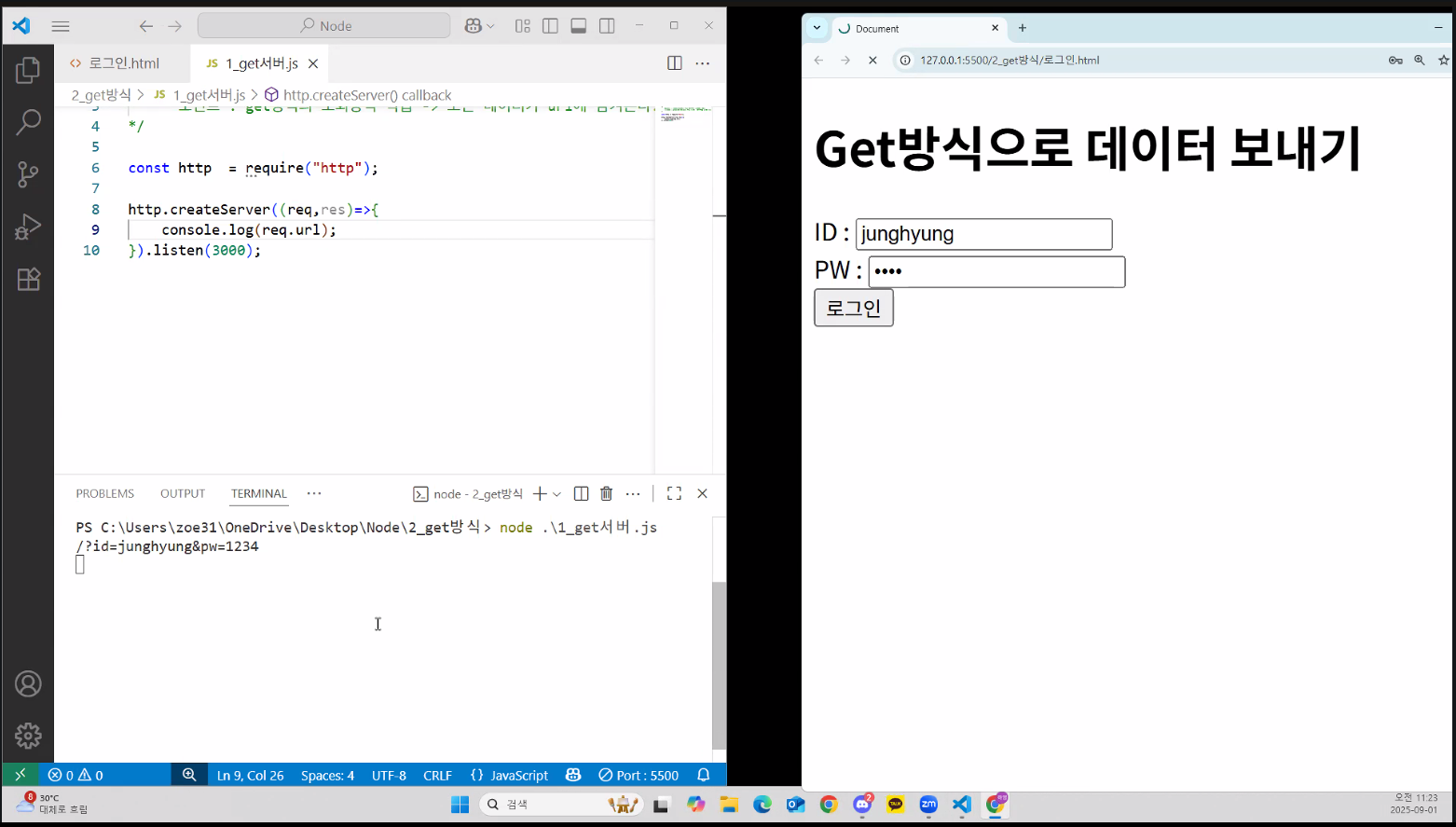
- 이 상태로는 id만 따로 빼 오거나 pw만 따로 빼 오기 힘듦: 문자열 한 줄로 묶여 있기 때문 → Crawling requests 데이터랑 똑같은 원리 → beautifulsoup 같은 기능이 필요!
- 어떻게 하면 따로 따로 빼 올 수 있을까 → "객체"로 만들자
- form 태그 활용
- 1_get_server.js 만들기
const http = require("http");
// url 데이터를 객체 형태로 변환하는 모듈 → GET 방식과 세트
const url = require("url");
http.createServer((req,res)=>{
console.log(req.url); // req.url → "/?id=isuhyeon&pw=1234" 문자열 형태 → 객체로 변환 필요
// get 방식은 데이터를 url에 보낸다 → req.url
// 문제점: 넘어온 데이터가 string(문자열) → 특정 값에 접근이 불가능
// 해결책: 따로 따로 접근할 수 있게 문자열을 객체로 변환
let data = url.parse(req.url,true).query; // string을 객체 형태로 변환
console.log(data);
}).listen(3000);- parse / parsing 단어 기억하기!
- 데이터 변환할 때 등장 많이 함
- 프로그래밍에서 parsing이라는 단어가 들어오면 뜻이 두 가지 중 하나임: 1. 보내겠다 2. 형태를 바꾸겠다
- parse라는 단어가 나왔다 == 데이터의 타입을 바꾸겠다는 뜻
- 데이터 변환할 때 등장 많이 함
- 미션
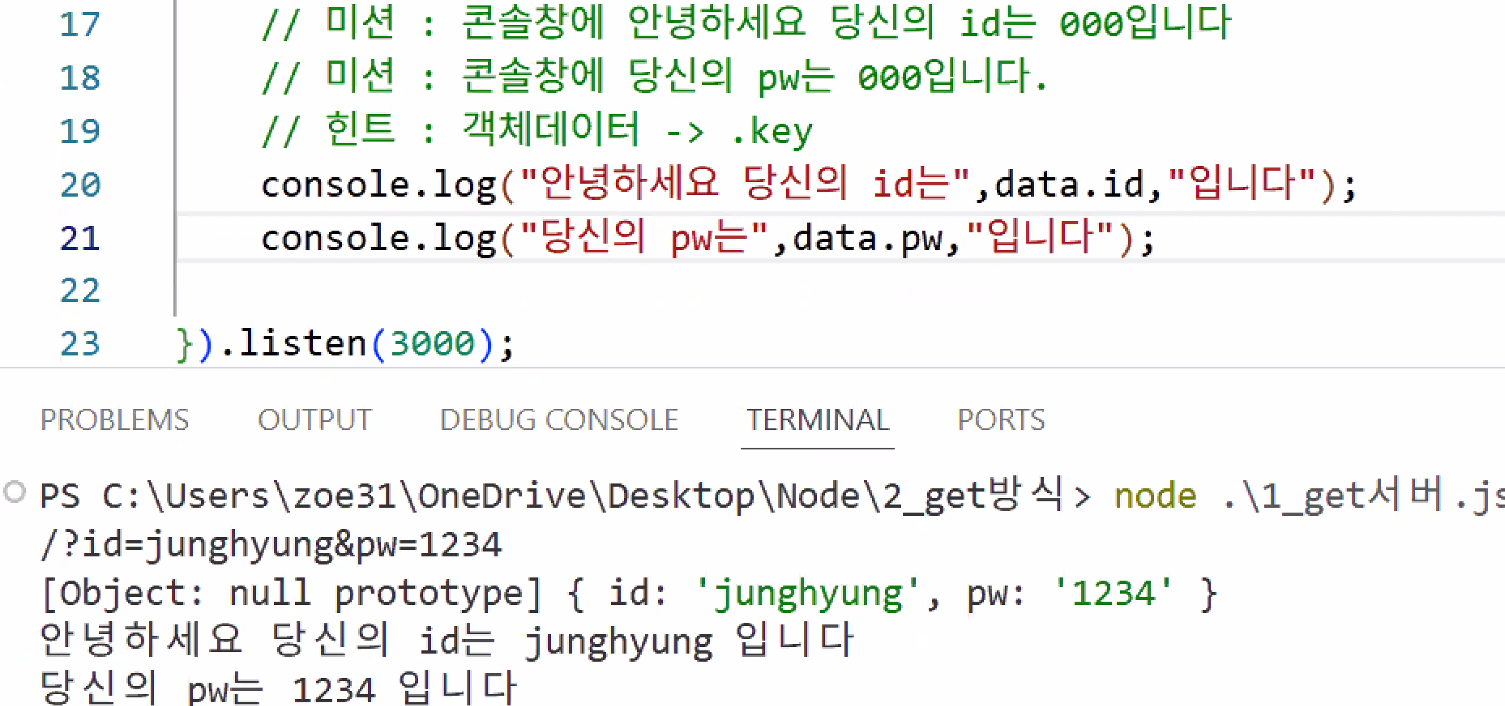
// 미션: 콘솔창에 '안녕하세요. 당신의 id는 000입니다.'
// 미션: 콘솔창에 '당신의 pw는 000입니다.'
// 힌트: 객체 데이터 → .key
console.log(`안녕하세요. 당신의 id는 ${data.id}입니다.`);
console.log(`당신의 pw는 ${data.pw}입니다.`);- 총정리!
- get 방식의 데이터 처리법
- 특징: 데이터를 url에 동반해서 보낸다
- 클라이언트: 값을 담아서 form의 action 값에 적힌 구조로 보낸다
- input에는 name이 반드시 필요하다.
- server의 역할
- 특징: 서버는 클라이언트가 보낸 모든 데이터를 req에 저장한다.
- 조회: req.url을 조회한다.
- 주의점: url 데이터는 문자 형태의 데이터 → 하나하나에 접근이 불가능 (통으로 되어 있기 때문)
- 해결책: url 모듈을 통해서 문자 → 객체 변환(parse)
- 사용법: 객체는 .key으로 각각의 값에 접근이 가능하다.
- get 방식의 데이터 처리법
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
- Zero-Shot Prompting
- 아무 예시 없이 모델 자체가 새로운 답변을 하는 경우
- 사전 예시 없이 단순 요청에 모델이 답변을 생성하는 방식
- 모델은 오로지 '프롬프트 템플릿에 포함된 정보만을 기반으로' 응답을 생성
- Few-Shot Prompting
- 몇 가지 예시를 프롬프트에 포함시켜 모델에게 원하는 출력 형식이나 해결 방식을 학습시키는 방식
- 예시를 제공하여 모델이 어떤 방식으로 답변해야 하는지 안내
- ExampleSelector
- 제공하는 예시가 많을수록 토큰 사용량이 많아지며 사용료가 많이 나오게 됨 → 예시를 많이 주되 사용자의 입력과 유사한 예시 한두 개만을 선택하여 예시로 사용
- 예시와 사용자의 입력에 '텍스트 임베딩(Text Embedding)'을 진행하여 코사인 유사도가 가장 높은 k개의 예시를 선택하여 사용
- Callback: Streaming
- 완전한 응답이 생선되기 전 생성 중인 결과를 실시간으로 출력
- 모델 객체 생성 시 포함: StreamingStdOutCallbackHandler() → 실제 스트리밍을 할 수 있는 기능이 있어서
.invoke()만 하면 흐르듯 출력되는 스트리밍을 진행할 수 있음 - cf. stream 함수(ex01) →
lim.stream()을 반복문에 넣어 토큰 단위로 출력
2. 메모리를 가진 챗봇 구현
- 학습 목표
- 간단한 챗봇을 구성하여 메모리를 가진 챗봇 기능을 구현할 수 있다.
주요 라이브러리 설명
- PromptTemplate
- 간단하게 프롬프트 템플릿을 작성할 경우 사용
- ChatOpenAI
- OpenAI에서 chat 모델을 가져다가 쓸 때 사용하는 라이브러리
- 대화 형태로 상호 작용이 필요한 경우 사용
- ChatPromptTemplate
- 채팅 형태의 프롬프트를 작성할 때 사용
- FewShotPromptTemplate
- few-shot prompting을 위한 라이브러리
- examples 속성이 있어 예시를 안쪽에 넣어줄 수 있음
- StrOutputParser
- 출력받는 형태에 대해서 지정
- StreamingStdOutCallbackHandler
- 스트리밍 라이브러리
- 채팅하는 형태처럼 만드려면 스트리밍 기능을 넣어주는 게 좋음
- 모델 생성 시 안에 넣어 줌 (모델 생성 시 포함)
메모리 없는 챗봇
# 구글 마운트 및 경로 설정
%cd /content/drive/MyDrive/Colab Notebooks/LangChain
# api key 설정
import os
with open("./key/.openai_api_key",'r') as f:
api_key = f.read().strip()
os.environ["OPENAI_API_KEY"] = api_key
!pip install -qU openai langchain-openai langchain langchain_community
!pip install -qU tiktoken pypdf chromadb faiss-cpu
!pip install -qU langchain-teddynote
!pip install -qU huggingface_hub langchain_huggingface
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, FewShotPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # 스트리밍 → 모델 생성 시 포함
# 모델 생성
llm = ChatOpenAI(
model = "gpt-4o-mini"
, temperature=0
, max_tokens=100
, streaming=True
, callbacks=[StreamingStdOutCallbackHandler()]
)
# 간단한 챗봇 구성하기
while True:
q = input("입력: ")
if q == "exit":
print("채팅 종료")
break
# 모델 응답
llm.invoke(q)
print() # 개행용 print입력: 안녕, 점심 메뉴를 추천해 줄래?
안녕하세요! 점심 메뉴로 몇 가지 추천해드릴게요.
1. **비빔밥** - 다양한 채소와 고기를 넣고 고추장과 함께 비벼 먹는 건강한 한 끼.
2. **김치찌개** - 뜨끈한 김치찌개에 밥을 곁들여 먹으면 든든하고 맛있어요.
3. **샐러드 볼** - 신선한 채
입력: 첫 번째 메뉴로 유명한 광주 맛집 소개해 줘
광주에는 다양한 맛집이 있지만, 특히 첫 번째 메뉴로 유명한 곳 몇 군데를 소개해드릴게요.
1. **광주식당** - 이곳은 전통적인 광주식 한정식으로 유명합니다. 신선한 재료로 만든 다양한 반찬과 함께 제공되는 메인 요리가 특징입니다.
2. **무등산막걸리** - 이곳은 막걸리와 함께 즐길 수 있는 전통 안
입력: 네가 아까 이야기한 내용에서 두 번째 메뉴가 뭐였지?
죄송하지만, 제가 이전에 이야기한 내용을 기억할 수는 없습니다. 어떤 메뉴에 대해 이야기하고 싶으신지 구체적으로 말씀해 주시면, 그에 대한 정보를 제공해 드리겠습니다.
입력: 아까 점심 메뉴 추천해 준 거 기억나니?
죄송하지만, 이전 대화 내용을 기억할 수는 없습니다. 하지만 점심 메뉴 추천이 필요하시면 기꺼이 도와드리겠습니다! 어떤 종류의 음식을 원하시나요?
입력: exit
채팅 종료→ 메모리가 없는 상태라 이전 대화 내용을 기억하지 못함
이전 대화 내용을 저장하여 연결된 대화를 할 수 있는 챗봇 구성
- ConversationChain
- LLM에 메모리를 추가하는 기능
- 대화형 체인을 구성하기 위한 클래스
- ConversationBufferMemory
- 대화 기록을 저장하는 클래스
from langchain.chains import ConversationChain # 대화형 체인을 구성하기 위한 클래스
from langchain.memory import ConversationBufferMemory # 대화 기록을 저장하는 클래스
# 1. 메모리 객체 생성
memory = ConversationBufferMemory()
# 2. 체인 구성: 대화형 모델과 메모리를 결합
conversation = ConversationChain(llm=llm, memory=memory)
# 챗봇 실행
while True:
q = input("입력 :")
if q == "exit":
print("채팅 종료")
break
# 모델 응답
conversation.invoke(q)
print() # 개행용입력 :안녕, 오늘 점심 메뉴 추천해 줄 수 있니?
안녕! 물론이지! 점심 메뉴로는 여러 가지가 좋을 것 같은데, 어떤 종류의 음식을 좋아해? 예를 들어, 한식, 중식, 일식, 양식 중에서 선호하는 게 있어? 아니면 특별히 먹고 싶은 재료가 있으면 알려줘! 그에 맞춰 추천해 줄게.
입력 :난 양식이 좋아. 그중에서도 스페인 요리를 좋아해.
스페인 요리를 좋아하신다니 멋지네요! 스페인 요리 중에서는 파에야가 정말 유명하죠. 해산물이나 닭고기, 채소를 넣고 쌀과 함께 조리하는 요리인데, 풍미가 가득하고 한 끼 식사로 아주 만족스러워요. 또, 타파스도 추천해 드리고 싶어요. 다양한 작은 요리들을 여러 가지 맛볼 수 있어서 친구
입력 :광주에 파에야 파는 곳이 있을까?
광주에 파에야를 파는 곳이 몇 군데 있어요! 예를 들어, "스페인 레스토랑" 같은 곳에서는 정통 스페인식 파에야를 맛볼 수 있습니다. 해산물 파에야나 닭고기 파에야 등 다양한 옵션이 있을 거예요. 또, "타파스 바" 같은 곳에서도 파에야와 함께 다양한 타파스를 즐길 수 있어서 좋습니다. 구체적인
입력 :두 번째로 추천해 준 메뉴가 뭐얐지?
두 번째로 추천해 드린 메뉴는 타파스였어요! 타파스는 스페인에서 유래된 다양한 작은 요리들을 말하는데, 여러 가지 맛을 한 번에 즐길 수 있어서 정말 좋습니다. 예를 들어, 감자 브라바스, 올리브, 하몽, 그리고 다양한 해산물 요리들이 포함될 수 있어요. 친구들과 함께 나눠 먹기에도 아주 좋은 메뉴랍니다!
입력 :exit
채팅 종료→ 이전 대화 내용을 잘 기억함
- chain 자체를 while문 안에 넣어 메모리가 결합된 형태로 채팅이 진행됨
# 메모리 확인
print(memory.buffer)Human: 안녕, 오늘 점심 메뉴 추천해 줄 수 있니?
AI: 안녕! 물론이지! 점심 메뉴로는 여러 가지가 좋을 것 같은데, 어떤 종류의 음식을 좋아해? 예를 들어, 한식, 중식, 일식, 양식 중에서 선호하는 게 있어? 아니면 특별히 먹고 싶은 재료가 있으면 알려줘! 그에 맞춰 추천해 줄게.
Human: 난 양식이 좋아. 그중에서도 스페인 요리를 좋아해
AI: 스페인 요리를 좋아하신다니 멋지네요! 스페인 요리 중에서는 파에야가 정말 유명하죠. 해산물이나 닭고기, 채소를 넣고 쌀과 함께 조리하는 요리인데, 풍미가 가득하고 한 끼 식사로 아주 만족스러워요. 또, 타파스도 추천해 드리고 싶어요. 다양한 작은 요리들을 여러 가지 맛볼 수 있어서 친구
Human: 광주에 파에야 파는 곳이 있을까?
AI: 광주에 파에야를 파는 곳이 몇 군데 있어요! 예를 들어, "스페인 레스토랑" 같은 곳에서는 정통 스페인식 파에야를 맛볼 수 있습니다. 해산물 파에야나 닭고기 파에야 등 다양한 옵션이 있을 거예요. 또, "타파스 바" 같은 곳에서도 파에야와 함께 다양한 타파스를 즐길 수 있어서 좋습니다. 구체적인
Human: 두 번째로 추천해 준 메뉴가 뭐얐지?
AI: 두 번째로 추천해 드린 메뉴는 타파스였어요! 타파스는 스페인에서 유래된 다양한 작은 요리들을 말하는데, 여러 가지 맛을 한 번에 즐길 수 있어서 정말 좋습니다. 예를 들어, 감자 브라바스, 올리브, 하몽, 그리고 다양한 해산물 요리들이 포함될 수 있어요. 친구들과 함께 나눠 먹기에도 아주 좋은 메뉴랍니다!- 모든 대화 내용을 저장하면 메모리 소모가 너무 많음
- 메모리를 아끼기 위한 방법이 필요
- 메모리 절약을 위해 기억할 대화 개수 설정 가능:
ConversationBufferWindowMemory()
from langchain.memory import ConversationBufferWindowMemory # 저장할 대화의 개수 설정
# 메모리 객체 생성 (최근 2개 대화만 저장)
memory_2 = ConversationBufferWindowMemory(k=2)
# 직접 이전 대화 내용을 적립할 수도 있음 → save_context
memory_2.save_context({"input": "너는 누구니"},
{"output": "저는 홍길동입니다"})
memory_2.save_context({"input": "나이는"},
{"output": "25세입니다"})
memory_2.save_context({"input": "직업은"},
{"output": "의적입니다"})
memory_2.save_context({"input": "집은 어디지"},
{"output": "전라남도 장성입니다"})
print(memory_2.buffer)Human: 직업은
AI: 의적입니다
Human: 집은 어디지
AI: 전라남도 장성입니다- 대화 내용 2개를 기억하는 챗봇 구성
# 1. 메모리 객체 생성
memory = ConversationBufferWindowMemory(k=2)
# 2. 체인 구성: 대화형 모델과 메모리를 결합
conversation = ConversationChain(llm=llm, memory=memory)
# 챗봇 실행
while True:
q = input("입력 :")
if q == "exit":
print("채팅 종료")
break
# 모델 응답
conversation.invoke(q)
print() # 개행용입력 :안녕, 꽥꽥 하고 우는 하얀 동물이 뭐지?
안녕! 꽥꽥 하고 우는 하얀 동물은 바로 오리야. 오리는 물가에서 자주 발견되며, 꽥꽥 소리를 내는 것이 특징이야. 하얀 오리는 특히 농장에서 많이 볼 수 있고, 때로는 애완동물로도 기르기도 해. 오리는 물속에서 헤엄치는 것을 좋아하고, 주로 곤충이나 식물의 씨앗을 먹
입력 :방금 전에 어떤 동물 이야길 했더라?
방금 전에 오리에 대해 이야기했어. 오리는 꽥꽥 소리를 내는 하얀 동물로, 주로 물가에서 발견되고 농장에서 많이 볼 수 있어. 물속에서 헤엄치는 것을 좋아하고, 곤충이나 식물의 씨앗을 먹는다고 했지. 더 궁금한 점이 있으면 언제든지 물어봐!
입력 :남극에 살고 있는 동물에 대해 알고 있어?
네, 남극에는 다양한 동물들이 살고 있어! 가장 잘 알려진 동물 중 하나는 펭귄이야. 특히 황제펭귄은 남극에서 가장 큰 펭귄 종류로, 약 1.2미터까지 자랄 수 있어. 이들은 극한의 추위에서도 살아남기 위해 서로 몸을 맞대고 체온을 유지하는 행동을 해.
또한, 남극에는 바다표
입력 :북극에도 동물이 살고 있어?
네, 북극에도 다양한 동물들이 살고 있어! 북극의 대표적인 동물 중 하나는 북극곰이야. 북극곰은 두꺼운 털과 지방층 덕분에 극한의 추위에서도 잘 견딜 수 있어. 이들은 주로 바다 얼음 위에서 사냥을 하며, 물개와 같은 해양 포유류를 주로 먹어.
또한, 북극에는 순록
입력 :북극곰은 뭘 먹을까?
북극곰은 주로 해양 포유류를 먹어. 그들의 주요 먹이는 물개, 특히 고래와 물개가 있는 지역에서 사냥하는 경우가 많아. 북극곰은 얼음 위에서 물개가 숨을 쉬기 위해 올라오는 구멍을 기다리며 사냥을 하기도 해. 이 외에도, 때때로 조류나 죽은 고래와 같은 다른 먹이도 섭취할 수
입력 :네가 첫 번째로 소개한 남극 동물 이름이 뭐였지?
죄송하지만, 제가 남극 동물에 대해 언급한 적은 없어요. 북극에 대한 이야기만 했었죠. 남극에는 펭귄, 바다코끼리, 그리고 다양한 해양 생물들이 살고 있어요. 궁금한 점이 있으면 언제든지 물어보세요!
입력 :exit
채팅 종료→ 마지막 대화로부터 세 번째에 위치한 대화(남극 동물)를 기억하지 못함
B. 5교시
1. ConversationChain 클래스가 더 이상 권장되지 않는 문제
- LangChain 0.2.7 버전부터 사용 중지(deprecated)로, 향후 1.0 버전에서 삭제될 예정
- 아래 Memory 클래스도 마찬가지
| Memory Type | 설명 |
|---|---|
| ConversationBufferMemory | 이전 대화 내용을 그대로 저장하는 메모리 |
| ConversationBufferWindowMemory | 윈도우 크기 k를 지정하면 최근 k개의 대화만 기억하고, 그 이전 대화는 삭제됨 |
| ConversationTokenBufferMemory | 최근 대화 히스토리를 버퍼에 저장하며, 대화 개수가 아닌 토큰 길이를 기준으로 대화내용 플러시 시기를 설정함 |
| ConversationSummaryMemory | 이전 대화 내용을 그대로 기억하지 않고 요약해서 저장함. 긴 대화에서 토큰 사용량을 줄이는 데 유용 |
| ConversationSummaryBufferMemory | ConversationSummaryMemory의 확장판 이전 대화를 요약해 저장하면서 최근 대화는 최대 토큰 범위 내에서 유지하도록 하며, 최대 토큰 길이를 지정할 수 있음 토큰을 줄여 API 활용 시 비용을 최소화하는 효율적인 메모리 |
| VectorStoreRetrieverMemory | 대화 내역을 벡터 저장소에 저장하고, 입력을 기반으로 과거 대화 중 가장 관련성 높은 부분을 검색함 |
- Use :class:
~langchain_core.runnables.history.RunnableWithMessageHistoryinstead./tmp/ipython-input-2383733555.py:5: LangChainDeprecationWarning: The class
ConversationChainwas deprecated in LangChain 0.2.7 and will be removed in 1.0. Use :class:~langchain_core.runnables.history.RunnableWithMessageHistoryinstead.
conversation = ConversationChain(llm=llm, memory=memory)
→ RunnableWithMessageHistory 사용해 보기
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import InMemoryChatMessageHistory
# 기본 컴포넌트 설정
prompt = ChatPromptTemplate.from_messages([
("system", "당신은 천문학 전문가입니다. 사용자와 친근한 대화를 나누며 천문학 질문에 답변해주세요."),
MessagesPlaceholder(variable_name="history"),
("human", "{question}")
])
chain = prompt | llm
# 메모리 저장소 구성
store = {}
def get_session_history(session_id: str) -> InMemoryChatMessageHistory:
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 메모리 기능을 가진 체인 생성
chain_with_history = RunnableWithMessageHistory(
chain, # 기본 체인 (prompt | llm)
get_session_history, # 세션 히스토리를 가져오는 함수
input_messages_key="question", # 사용자 입력 키
history_messages_key="history", # 대화 기록 키
)
# 대화 흐름 분석
config = {"configurable": {"session_id": "astronomy_chat_1"}}
# 첫 번째 대화
response1 = chain_with_history.invoke(
{"question": "안녕하세요, 저는 지구과학을 공부하는 학생입니다."},
config=config
)
# 두 번째 대화 - 컨텍스트 유지
response2 = chain_with_history.invoke(
{"question": "태양계에서 가장 큰 행성은 무엇인가요?"},
config=config
)
# 세 번째 대화 - 참조 관계 이해
response3 = chain_with_history.invoke(
{"question": "그 행성의 위성은 몇 개나 되나요?"},
config=config
)2. RunnableWithMessageHistory
- LangChain의 새로운 채팅 기록 (메모리)
- 실행 시 대화 메시지를 자동으로 포함시켜 주는 기능
- 대화 맥락 유지 기능을 추가해 주는 껍데기(Wrapper) 역할
웹 개념의 '쿠키 세션'을 차용해 사용자마다 이전 기록을 저장하는 아이디(세션 아이디)를 부여하고 DB에 저장
기억한 질문에 대해 메모리를 따로 꾸려서(방을 사용자마다 각각 만듦) 사용자 로그인 시 이전 대화 내용을 기억할 수 있도록 만듦
개념
- 세션(Session-id) 기반으로 메시지를 관리
- 각 사용자별로 대화를 구분하기 위하여 세션 ID 사용
- 세션별로 메시지를 저장하고 필요한 대화 내용을 불러오고 다시 기록
- Load Messages
- 과거에 주고받았던 메시지(질문, 응답 등)를 불러옴
- 이 과거 대화 내용이 “대화의 맥락”이 됨
- Your Runnable(또는 chain)
- 실제로 모델이 응답을 생성하거나, 특정 로직을 수행하는 핵심 부분
- 입력 메시지와 과거 대화 내용을 활용해 결과(응답)를 생성
- Save Response
- 생성된 응답(결과)을 다시 메시지 히스토리에 저장
- 이후 대화를 진행할 때, 이 응답이 과거 대화로 인식됨
- Outputs
- 최종적으로 사용자가 확인할 수 있는 결과(답변, 메시지 등)
- 다음 입력이 들어오기 전까지, 이전 메시지들이 히스토리에 누적되어 맥락이 유지됨
라이브러리 설명
- RunnableWithMessageHistory
- 체인 연결 도구
- 메모리들을 한꺼번에 감싸줌(wrapper)
- 대화 기록과 연동되는 체인을 실행할 수 있게 해주는 도구
- 사용자의 현재 입력과 기존의 대화 내역을 연결해 모델이 응답할 수 있도록 도움
- ChatPromptTemplate
- 메시지를 구성하는 형태의 템플릿 정의
- MessagesPlaceholder
- 프롬프트 내에서 대화 기록이 들어갈 위치를 표시하는 도구
- 과거 대화 기록이 들어갈 자리 표시
- BaseChatMessageHistory
- 대화 기록 "관리" 도구
- 자료형을 지정해 대화의 기록을 관리함
- 전체적인 모든 데이터 기록을 관리
- 대화 기록 "관리" 도구
- ChatMessageHistory
- 새로운 대화 세션 생성 시 사용
- BaseChatMessageHistory의 구체적인 구현체 → 실제 대화 메시지를 저장하고 관리하는 기능 수행
- StrOutputParser
- 체인의 출력 결과를 문자열 형식으로 파싱하는 도구
순서
- 모델 생성
- 메시지 출력 형식 지정 리스트를 생성 → 과거 기록 관리
- MessagesPlaceholder가 여기 위치하게 됨
- 템플릿 객체에 넣기 위해 만드는 것
- 메시지 기반 템플릿 객체 생성
- 체인 구성
- 세션 기록 저장을 위한 딕셔너리 {key: value} → {session_id: ChatMessageHistory}
- 세션을 관리하는 함수 정의
- 대화 기록을 저장하고 관리하는 담당: ChatMessageHistory
- 체인과 세션을 관리하는 함수를 연결
- 무한 루프를 통한 채팅 진행
# 라이브러리 불러오기
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
# 1. 모델 생성
llm_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 2. 메시지 리스트 생성 → 과거 기록 관리
messages = [
("system","너는 신뢰 가능한 AI 조수다.")
, MessagesPlaceholder(variable_name="history") # 과거 대화 기록이 들어갈 자리
, ("human", "{input}")
]
# 3. 메시지 기반 템플릿 객체 생성
prompt = ChatPromptTemplate.from_messages(messages)
# 4. 체인 구성
chain = prompt | llm_model | StrOutputParser()
# 5. 세션 기록 저장을 위한 딕셔너리
# {key: value} → {session_id: ChatMessageHistory}
store = {}
# 6. 세션을 관리하는 함수 정의
# 대화 기록을 저장하고 관리하는 담당: ChatMessageHistory
def get_session_history (session_ids: str): # type hinting
if session_ids not in store: # 만약 store에 세션 id가 없다면 새로운 히스토리 메시지를 생성
store[session_ids] = ChatMessageHistory()
return store[session_ids] # 이미 존재하는 세션 → 딕셔너리에서 히스토리 메시지를 반환
# 7. 체인과 세션을 관리하는 함수를 연결
# RunnableWithMessageHistory
with_message_history = RunnableWithMessageHistory(
chain # llm 체인
, get_session_history # 대화 기록 관리 함수
, input_messages_key="input" # 입력 받는 값 → 2번에서 이미 등장함
, history_messages_key="history" # 메시지에서 정의한 history → 2번에서 이미 등장함
)
# 8. 무한 루프를 통한 채팅 진행
# 챗봇 실행
while True:
q = input("입력: ")
if q == "exit":
print("채팅 종료")
break
# 모델 응답
res = with_message_history.invoke(
{"input": q}
, config = {"configurable":{"session_id":"x-test1234"}} # 세션 아이디를 전달하여 해당 대화 기록을 불러오거나 새로 생성
)
print(res)
print()입력: 안녕하세요, 남극에 사는 동물에 대해 알려주시겠어요?
안녕하세요! 남극은 극한의 환경이지만, 그곳에도 다양한 동물들이 살고 있습니다. 남극의 동물들은 극한의 추위와 얼음으로 덮인 환경에 적응하여 생존하고 있습니다. 주요 동물들을 소개해 드릴게요.
1. **펭귄**: 남극에서 가장 잘 알려진 동물 중 하나입니다. 특히 황제펭귄과 아델리펭귄이 유명합니다. 펭귄은 수영을 잘하며, 바다에서 물고기를 잡아 먹습니다. 그들은 육지에서 번식하며, 알을 낳고 새끼를 기릅니다.
2. **물개**: 남극에는 여러 종류의 물개가 서식합니다. 대표적으로 남극물개, 웨델물개, 그리고 얼음물개가 있습니다. 이들은 바다에서 먹이를 찾고, 얼음 위에서 휴식을 취합니다.
3. **고래**: 남극 주변의 바다에는 여러 종류의 고래가 서식합니다. 대표적으로 남극흰수염고래, 혹등고래, 그리고 범고래가 있습니다. 이들은 주로 크릴과 같은 해양 생물을 먹고 삽니다.
4. **남극 크릴**: 남극의 해양 생태계에서 중요한 역할을 하는 작은 갑각류입니다. 많은 해양 동물들이 크릴을 주요 먹이로 삼습니다.
5. **남극 새**: 남극 대륙 자체에는 새가 많지 않지만, 주변의 섬들에는 다양한 새들이 서식합니다. 예를 들어, 남극갈매기와 남극제비갈매기가 있습니다.
6. **바다표범**: 남극의 바다에는 여러 종류의 바다표범이 서식합니다. 이들은 얼음 위에서 휴식을 취하고, 바다에서 물고기를 잡아 먹습니다.
남극의 동물들은 극한의 환경에서 생존하기 위해 특별한 적응을 가지고 있으며, 그들의 생태계는 매우 독특합니다. 더 궁금한 점이 있으면 언제든지 질문해 주세요!
입력: 북극에는 어떤 동물이 사나요?
북극 지역은 극한의 환경이지만, 다양한 동물들이 이곳에서 생존하고 있습니다. 북극의 동물들은 극한의 추위와 얼음으로 덮인 환경에 적응하여 살아가고 있습니다. 주요 동물들을 소개해 드릴게요.
1. **북극곰**: 북극의 상징적인 동물로, 주로 얼음 위에서 사냥을 하며 물개와 같은 해양 포유류를 주로 먹습니다. 북극곰은 두꺼운 지방층과 털로 덮여 있어 극한의 추위에서도 잘 견딥니다.
2. **바다표범**: 북극 지역에는 여러 종류의 바다표범이 서식합니다. 대표적으로 링세일표범, 하프물범, 그리고 그린란드표범이 있습니다. 이들은 얼음 위에서 휴식을 취하고, 바다에서 물고기를 잡아 먹습니다.
3. **북극여우**: 북극여우는 두꺼운 털로 덮여 있어 추위에 잘 견디며, 주로 작은 설치류, 새, 그리고 과일 등을 먹습니다. 여름철에는 털 색이 갈색으로 변해 환경에 잘 녹아듭니다.
4. **순록**: 북극 지역의 타이가와 툰드라에서 서식하는 동물로, 주로 식물과 이끼를 먹습니다. 순록은 이동성이 강해 계절에 따라 이동합니다.
5. **북극토끼**: 북극토끼는 두꺼운 털로 덮여 있으며, 주로 풀과 이끼를 먹습니다. 겨울철에는 흰색 털로 변해 눈과 잘 어우러집니다.
6. **고래**: 북극 해역에는 여러 종류의 고래가 서식합니다. 대표적으로 벨루가고래, 혹등고래, 그리고 북극고래가 있습니다. 이들은 주로 물고기와 크릴을 먹습니다.
7. **해양 조류**: 북극 지역에는 다양한 해양 조류가 서식합니다. 대표적으로 북극갈매기, 알카, 그리고 북극제비갈매기가 있습니다.
북극의 동물들은 극한의 환경에서 생존하기 위해 특별한 적응을 가지고 있으며, 그들의 생태계는 매우 독특합니다. 더 궁금한 점이 있으면 언제든지 질문해 주세요!
입력: 북극에 여우는 안 사나요?
북극에는 **북극여우**(Arctic fox)가 서식합니다. 북극여우는 북극 지역의 대표적인 동물 중 하나로, 극한의 추위에 잘 적응해 있습니다. 이들은 두꺼운 털로 덮여 있어 체온을 유지할 수 있으며, 겨울철에는 털 색이 흰색으로 변해 눈과 잘 어우러집니다. 여름철에는 갈색이나 회색으로 변해 주변 환경에 잘 녹아듭니다.
북극여우는 주로 작은 설치류, 새, 그리고 과일 등을 먹으며, 때때로 사냥한 먹이를 저장해 두기도 합니다. 이들은 매우 적응력이 뛰어나고, 북극의 혹독한 환경에서도 생존할 수 있는 능력을 가지고 있습니다.
따라서 북극에는 여우가 살고 있으며, 북극여우는 그 지역의 생태계에서 중요한 역할을 하고 있습니다. 더 궁금한 점이 있으면 언제든지 질문해 주세요!
입력: 남극에 사는 동물 알려주셨을 때 세 번째로 이야기해주신 동물 이름이 뭐였을까요?
남극에 사는 동물에 대해 이야기할 때 세 번째로 언급한 동물은 **고래**입니다. 남극 주변의 바다에는 여러 종류의 고래가 서식하며, 대표적으로 남극흰수염고래, 혹등고래, 그리고 범고래가 있습니다. 이들은 주로 크릴과 같은 해양 생물을 먹고 삽니다. 더 궁금한 점이 있으면 언제든지 질문해 주세요!
입력: exit
채팅 종료추가: history 변수
history 변수는 대화의 맥락(과거 메시지 기록)을 저장하고, 프롬프트에 동적으로 삽입하는 역할을 합니다. 이 history가 실제로 어디에서 데이터가 할당되고 전달되는지 이해하기 위해 각 흐름을 단계별로 설명합니다.
- history의 흐름 요약
- MessagesPlaceholder(variable_name="history")
- 프롬프트에 history라는 이름으로 과거 대화 메시지가 들어갈 자리를 지정
- 하지만, 이 시점에서는 내용을 채우지 않음
- RunnableWithMessageHistory
- chain에 세션별로 history 값을 실제로 전달하는 객체
- get_session_history
- session_id별로 각각의 ChatMessageHistory 인스턴스를 반환하는 함수
- ChatMessageHistory
- 해당 세션의 실제 과거 메시지(=history)를 저장하는 객체
- invoke 시점:
- RunnableWithMessageHistory가 invoke될 때, 내부적으로 get_session_history 함수로부터 해당 세션의 ChatMessageHistory 객체를 받아 그 안에 저장된 history를 “history” 변수로 프롬프트(template)에 넘김
- 코드 라인별 핵심 연결
- MessagesPlaceholder(variable_name="history")
- 프롬프트 템플릿에서 'history'라는 자리표시자로 삽입됨
- RunnableWithMessageHistory
- 세션별로 history(=대화기록)를 동적으로 꺼내서 history 자리표시자 자리에 끼워 넣음
- 이때 get_session_history 함수를 통해 history 데이터를 얻음
- invoke 호출
- config에 session_id 값을 주면, 이 값으로 store 딕셔너리에서 ChatMessageHistory 객체를 가져오고, 이 객체가 가진 메시지들이 history로 전달됨
- chain에게 프롬프트를 전달할 때, 'input'은 사용자의 새 질문, 'history'는 get_session_history에서 가져온 메시지 배열로 전달
- 실제 동작 그림
- 사용자가 입력(q)을 하면,
- with_message_history.invoke 호출 → config의 session_id로 적절한 ChatMessageHistory 객체를 꺼냄
- 이 ChatMessageHistory의 메시지 리스트가 'history'라는 이름으로 프롬프트에 삽입됨
- history가 MessagesPlaceholder(variable_name="history") 위치에 들어감
- 프롬프트와 함께 llm에 전달되어 응답이 생성됨
- 새로 받은 질문/응답 쌍은 해당 history에 덧붙여짐
- 핵심 요약
- history는 ChatMessageHistory 객체 안에 저장되어 있고,
- get_session_history 함수 및 RunnableWithMessageHistory가 프롬프트에 넣어주는 역할을 함
- 프롬프트 템플릿의 history 부분 → 실제 리스트가 런타임에서 대입되는 자리(placeholder)
- 즉, history 값은 사용자 입력마다 session_id를 바탕으로 get_session_history에서 ChatMessageHistory 객체를 받아, 그 안에 저장된 메시지들을 프롬프트의 history 자리에 동적으로 넣어주기 때문에, 코드상 명확하게 값을 세팅하는 부분이 직접적으로 보이진 않지만, 내부 함수 호출의 결과로 전달되고 있음!
C. 6교시
1. RAG (Retrieval - Argumented Generation)
- 기존의 LLM을 확장 → 주어진 컨텐츠나 질문에 대해 더욱 정확한 정보를 제공하는 방법
- 즉, 모델이 학습 데이터에 포함되지 않은 외부 데이터를 실시간으로 검색(Retrieval)하고 활용(Argumented)하여 답변을 생성(Generation)하는 기술
- 실습
- PDF 파일 검색
- 웹 페이지 검색
기본 구조
- 검색 단계(Retrieval)
- 사용자의 질문이나 컨텍스트를 입력받아 이와 관련된 외부 데이터를 검색하는 단계
- 증강 단계(Argumented)
- 검색된 데이터를 토큰화, 인코딩, 임베딩 후에 벡터 DB에 저장하여 검색기를 붙이는 단계
- 생성 단계(Generation)
- 벡터 DB에 저장된 데이터와 LLM을 사용하여 사용자의 질문에 답변을 생성하는 단계
장점
- 풍부한 정보 제공: 검색을 통한 답변으로 보다 구체적이고 풍부한 정보를 제공
- 실시간 정보 반영: 최신 데이터를 검색하여 답변함으로써 모델이 실시간으로 변화하는 정보에 대응할 수 있음
- 환각 방지: 외부 데이터의 검색을 통해 답변을 진행함으로써, 환각 현상이 발생할 위험을 줄
이고 정확도를 향상시킴
프로세스
- 사전 준비 단계
- 문서 가져오기
- 텍스트 분할
- 임베딩
- 벡터 DB 저장
- 실행 단계
- 검색기 설정
- 프롬프트 구성
- llm 생성
- 체인 생성 및 실행
2. PDF를 학습한 나만의 챗봇 만들기
- 데이터 로드(Load Data)
- RAG에 사용할 데이터를 불러오는 단계
- 텍스트 분할(Text Split)
- 불러온 데이터를 작은 크기의 단위(chunk; 청크)로 분할하는 단계
- 임베딩 (Embedding) / 인덱싱 (Indexing)
- 텍스트 데이터를 숫자로 이루어진 벡터로 변환하는 단계
- 분할된 텍스트를 검색 가능한 형태로 만드는 단계
- 검색(Retrieval)
- 사용자의 질문이나 주어진 컨텍스트에 가장 관련된 정보를 찾아내는 단계
- 생성(Generation)
- 검색된 정보를 바탕으로 사용자의 질문에 답변을 생성하는 최종 단계
# 구글 마운트 및 경로 설정(파일 위치 변경)
%cd /content/drive/MyDrive/Colab Notebooks/LangChain
# api key 설정
import os
with open("./key/.openai_api_key",'r') as f:
api_key = f.read().strip()
os.environ["OPENAI_API_KEY"] = api_key
!pip install -qU openai langchain-openai langchain langchain_community
!pip install -qU tiktoken pypdf chromadb faiss-cpu
!pip install -qU langchain-teddynote
!pip install -qU huggingface_hub langchain_huggingface1. 데이터 로드
- RAG에 사용할 데이터 불러오기: PDF 파일
# pdf 파일 불러오는 라이브러리
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/미래 필수 역량.pdf")
document = loader.load()2. 텍스트 분할
- 작은 크기의 단위(Chunk)로 분한
- Chunk: 하나의 문서를 일정한 길이로 잘라낸 조각
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n\n" # 둔단 단위
, chunk_size = 500
, chunk_overlap = 50
, length_function = len
)- 분할 도구: CharacterTextSplitter
- 가장 기본적인 텍스트 분할 도구 → 단순히 지정된 단위로 분할
- 주어진 텍스트를 설정한 단위로 분할: 문단(\n\n), 문장(\n), 단어, 형태소
- 단점: 의미적 관계 미포함 → 문맥이 끊길 수 있음
- 가장 기본적인 텍스트 분할 도구 → 단순히 지정된 단위로 분할
- 파라미터
- seperator: chunk 분할 기준 → \n\n → 문단 단위로 분할
- chunk_size: 분리되는 문장의 최대 크기
- 500으로 설정하면 500 이하로 다 잘리게 됨
- cunck_overlap: 앞 chunk, 뒤 chunk 중복되는 크기 → 0은 '중복 X' 의미
- overlap: 겹쳐지는 것 → 정보가 희석되는 걸 막기 위해 앞, 뒤 청크에 조금 연계성을 주기 위함
- length_function: chunk의 크기를 계산하는 기준
chunks = text_splitter.split_documents(document)
# 분리 결과 확인
for idx, text in enumerate(chunks):
print(f"*****결과{idx+1}***** \n {text}")*****결과1*****
page_content='홈• 인공지능• 일문일답 | AI 혁명 속 승자가 되는 법··· AWS 교육 임원이 말하는 미래 필수 역량
By Lucas Mearian
Senior Reporter
일문일답 | AI 혁명 속 승자가 되는 법···AWS 교육 임원이 말하는 미래 필수 역량
인터뷰
2025.03.03 • 11분
교육 산업 생성형 AI IT 직업
AWS 교육 및 수료증 프로그램에 대한 수요가 급증하고 있다. 일부 과정은 수강생이 전년 대비 9
배까지 증가했다. 아마존웹서비스(AWS)의 교육·인증 제품 및 서비스 디렉터 제니 트라우트먼은
이러한 수요 증가는 최근 급변하는 기술 역량에 대한 시장의 요구를 반영한다고 설명한다.
CREDIT: JENNY TROUTMAN / JENNY TROUTMAN'S LINKEIN' metadata={'producer': 'Skia/PDF m133', 'creator': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36', 'creationdate': '2025-03-05T04:57:45+00:00', 'title': '일문일답 | AI 혁명 속 승자가 되는 법··· AWS 교육 임원이 말하는 미래 필수 역량 | CIO', 'moddate': '2025-03-05T04:57:45+00:00', 'source': './data/미래 필수 역량.pdf', 'total_pages': 6, 'page': 0, 'page_label': '1'}
*****결과2*****
page_content='AI와 기술 역량이 빠르게 변화하면서 취업이나 커리어 발전을 위해 필요한 역량도 몇 년 전과 비교해 크게
달라졌다. 특히 직무 능력 외에 의사소통, 문제 해결, 협업, 리더십 능력 등으로 대표되는 ‘소프트 스킬’의
중요성이 그 어느 때보다 커지고 있다고 AWS의 교육·수료(training and certification) 제품 및 서비스
디렉터 제니 트라우트먼이 밝혔다.
(이하 생략)# 청크의 수 출력
print(f"분리된 청크의 수: {len(chunks)}")분리된 청크의 수: 6GPT는 "언어 모델" → '지능'이 아님!
사람들이 입력한 걸 잘 붙여서 말을 만드는 것뿐
예: GPT가 알려주는 코드는 스택오버플로우 같은 곳에 사람들이 쓴 코드를 가져온 것
레시피 같은 것도 다른 사람들이 쓴 글을 가져와 쓰는 것
인공지능의 '지능(AGI)'에 대한 담론 읽어보기
책 "The AI con"에서는 인공'지능'이라는 말이 마케팅 용어라고 꼬집음 → AI가 스스로 생각할 수 있는 힘이 있는 것처럼 현혹
cf. Chain-of-Thought(CoT) 같은 방법을 사용한 AI의 추론(reasoning)을 따라가는 방법과 지능 헷갈리지 않기
Ⅲ. CAREER UP
A. 현직자 특강
- 네이버 클라우드 네트워크 교육
- 이론+실습(선택)
- 기본 10만원 크레딧
- 추가 10만원 크레딧
- 크레딧 소진 후 개인 비용 부과되니 주의
- 실습 후 서버, GPU 끄기
- 실습 교안 외부 유출 금지
- Notion Link로 전달 예정
- 커리큘럼
- 클라우드 기초
- 네이버클라우드 주요 서비스
- 클라우드 심화
- Kubernetes, DevOps 구성
- Cloud Native와 자동화
- GPU 서버
- CLOVA AI 서비스
- Naver CLOUD Associate
- 클라우드 기초
네트워크 기본 개념 다지기
기본 개념
- 네트워크: 여러 대의 컴퓨터, 서버, 장치들이 서로 데이터를 주고받을 수 있도록 연결된 구조
- 예: 도시의 도로망 → 자동차(데이터)가 이동할 수 있도록 길(네트워트)이 연결되어 있음
- 기본 구성 요소
- IP 주소
- 서브뎃
- 라우터
- 스위치
- 온프레미스 환경 네트워크?
- 기업이 직접 서버실(Data Center) 안에 장비를 설치하고 운영
- 서버, 스위치, 라우터, 방화벽, 케이블 등 모든 걸 물리적으로 관리
- 장점
- 단점
- 기업이 직접 서버실(Data Center) 안에 장비를 설치하고 운영
- 클라우드 네트워크?
- 물리적 vs. 논리적 네트워크
- 클라우드 사업자(AWS, Naver Cloud 등)가 물리적 장비(서버, 라우터, 스위치) 운영
- 사용자는 '논리적(가상) 네트워크'를 정의해 사용: vpc 생성 → 내가 원하는 대역의 IP, 서브넷 직접 지정 가등
- 네트워크를 코드처럼 다루는 시대 → Infrastructure as Code
- 공용 vs. 사설 네트워크
- 공용 네트워크: 인터넷을 통해 누구나 접근 가능한 공간 → 퍼블릭 IP를 가진 웹 서버
- 사설 네트워크: 외부에서 직접 접근 불가, 내부 서비스만 통신 → DB 서버, 내부 API 서버
- NAT(Network Address Translation), 인터넷 게이트웨이 같은 요소로 외부 연결 제어
- 물리적 vs. 논리적 네트워크
NAVER CLOUD 사용 환경
- 리전(REGION)
- 주요 거점에 구축된 하나 이상의 존(zone)들의 집합
- 사용자와 가까운 리전일수록 응답 속도 빠름
- Latency ↓
- 리전마다 제공 서비스 다를 수 있음
- NCP 리전
- 한국, 미국 서부, 싱가포르, 일본, 독일
- 제약
- 일부 글로벌 리전은 SSD Server, GPU Server, Auto Scaling, Object Storage, NAS 미지원
- 존(ZONE)
- 리전 내부에서 물리적으로 분리된 데이터센터/네트워크
- 존 단위로 독립 운영 → 장애 발생 시 다른 존 영향 없음
- 단일 존 vs. 멀티 존
- 한국, 싱가포르, 일본 리전: 멀티 존 제공
- 한국: KR-1, KR-2
- 싱가포르: SGN-4, SGN-8
- 서버 이중화 재해 복구 (HA & DR)
- HA(High Availabillity)
- VM 서버가 자동으로 다른 호스트 서버로 이동: Live Migration
- 단일 서버 운영 시 위험 → 이중화 권장
- DR(Disaster Recovery)
- 다른 존을 DR 존으로 설정 → 정기 백업
- 메인 존 장애 시 DR 존에서 서비스 복구
- 멀티 존 지원 리전에서만 구축 가능
- HA(High Availabillity)
- 플랫폼(PLATFORM)
- 서비스별 운영 환경 구분 요소
- Classic → 지금은 가입 x(예전 B2B 구세대 플랫폼)
- Shared Network 기반
- CSP가 사설 IP 할당
- ACG로 접근 제어
- VPC (Virtual Private Cloud)
- 고객 전용 사설 네트워크
- 사용자가 직접 네트워크 설계 & IP 할당
- 논리적으로 완전 분리, 온프레미스 DC와 유사 구조
- 리전당 최대 3개 VPC 생성 가능
NAVER CLOUD NETWORK
- VPC (Virtual Private Cloud)
- 격리된 네트워크 환경
- 다른 사용자의 네트워크과 상호 간섭되는 일 없음
- 클라우드 상 안전하고 투명한 IT 인프라 환경
- 용도별 네트워크 구성
- 네트워크 서브넷(Subnet) 기능 → 네트워크의 용도별 세분화
- 강력한 보안 기능
- ACG(Access Control) → 서버에 포함되어 있음. 도어락 역할
- NACL(Network Access Control List) → 관할 구역(서브넷 구간)을 지키는 보안관 느낌 (IP 기반 통제)
- 격리된 네트워크 환경
- VPC (Virtual Private Cloud) 대표 아키텍처
- Subnet
- ACG/NACL
- VPC Peering
- VPC를 더 논리적으로 만드는 방법
- 망분리 요건 충족
- VPG
- Hybrid/Multi cloud
Naver Cloud Experience
- 네이버클라우드 체험 및 크레딧 적용
- 신규 가입 할인 크레딧 신청
- 내일 다시 진행할 예정
- 신규 가입 할인 크레딧 신청
- 공공 존 / 기관 존 / 금융 존 분리
- 왜 분리? → 함께 있다고 생각해보면
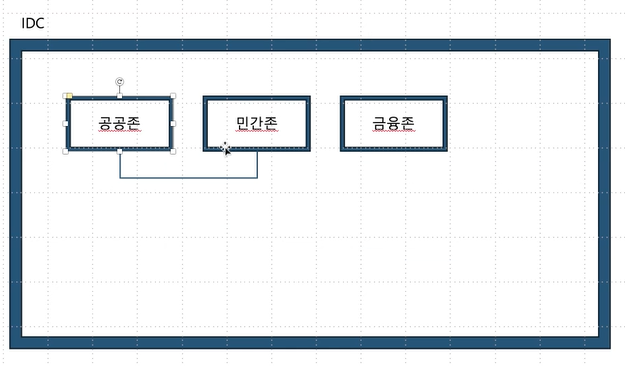
→ 서로 연결될 위험!
- 왜 분리? → 함께 있다고 생각해보면
-
- 포트폴리오 작성 시 도움
- 크레딧 및 할인 관리
- 네이버 클라우드 플랫폼 교육
- 클라우드 코스 교육
- 대시보드 확인해보기
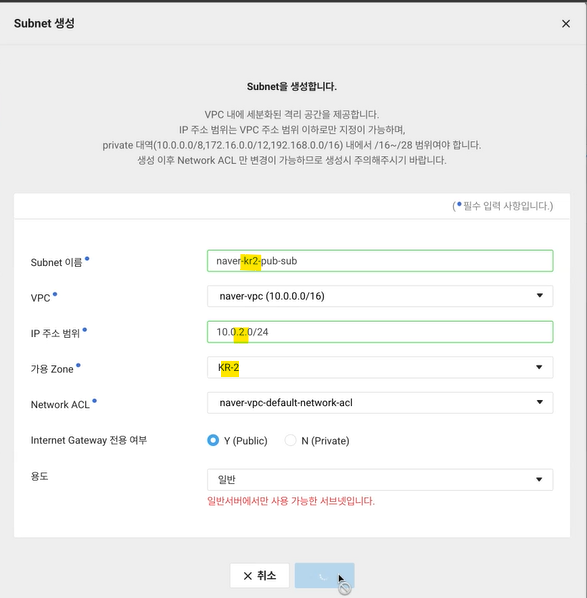
- 가용 존: KR-2에 만들고 싶다면
하루 돌아보기
👍 잘한 점
- 수업 참여 열심히 함
- 질문 많이 했음
👎 아쉬웠던 점
- 미니 프로젝트 기간 중에 복습하지 못했던 부분 다시 보고 있는데 시간이 좀 지나서 그런지 생각보다 많이 진도를 못 나갔음
- 다음주 리눅스마스터 시험인데 준비를 거의 못했다😭
🔬 개선점
- 기출문제 풀기
- 균형 있게 시간 조절하기
