목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. 실습: 로그인 성공/실패 이동
B. 2교시
1. 실습: 로그인 성공/실패 이동 (cont.)
2. post 방식
C. 3교시
1. 실습: POST 방식 데이터 처리
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
2. RAG: PDF 학습 챗봇
B. 5교시
1. RAG: PDF 학습 챗봇 (cont.)
2. RAG: 웹 페이지 학습 챗봇
C. 6교시
1. RAG: 웹 페이지 학습 챗봇 (cont.)
Ⅲ. CAREER UP
현직자 특강
Ⅳ. 하루 돌아보기Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
지금 배우는 노드 개념은 모두 서버 구성 요소, 개념 정리를 위한 예전 서버 & 라이트한 내용 (현재는 잘 쓰이지 않는 방식임)
왜 현업에서 프레임워크를 쓰는 건지 이해하기 위한 빌드업입니다~
- response 데이터 활용
- 서버 == 가상의 공간
- 서버 생성 시 매개 변수 두 가지는 필수임: req, res
- req: 사용자가 서버에게 보내주는 모든 데이터 → form 태그 안의 데이터, 계정 종류, IP, URL 등 클라이언트에서 발생하는 모든 데이터가 req 변수에 담김
- res: 서버가 클라이언트에게 응답할 때 쓰는 모든 데이터(객체)가 있는 공간
.write()함수- 사용자가 사이트에 방문했을 때 특정 내용을 보내주기 위해 사용:
res.write(); - 주의: 반드시 응답이 끝났음을 알리는
.end()와 함께 써야 함- 데이터 전달이 끝났으니 연결을 끊겠다는 뜻
- 사용자가 사이트에 방문했을 때 특정 내용을 보내주기 위해 사용:
- 통신이 끝나면 무조건 "종료"를 명시해 주세요!
- '서버 쪽에서는 응답이 끝났습니다'라는 걸 클라이언트에게 알려줘야 함
- end(), close(), …
- 연결을 끊지 않으면 다른 사람이 회선을 쓸 수 없음 & 사용자가 다음 행위를 할 수 없음
- 보안상 frontend에서 바로 db로 보내는 건 X → 서버 역할 필요 (backend)
- 보안상 frontend에서 바로 db로 보내는 건 X → 서버 역할 필요 (backend)
- '서버 쪽에서는 응답이 끝났습니다'라는 걸 클라이언트에게 알려줘야 함
옛날 전화선으로 인터넷하던 것 생각하면 쉬움 → 선을 점유하고 있으면 계속 통화중으로 뜸 → 회선은 무한대가 아니니까 모든 응답이 끝나면 반드시 연결을 끊어줘야 함! (요즘은 자동으로 끊어줌)
.writeHead()함수- head 정보를 생성해 인코딩이 되도록 만듦
- fs 모듈
- 파일 관리 시스템 모듈 (내장 모듈)
- 정적 페이지 리턴할 때 사용
- express에 탑재된 기능이라 기억하지 않아도 괜찮음 → 대신 async/await 원리를 꼭 기억하자!
- 파일 관리 시스템 모듈 (내장 모듈)
- async/await → 비동기 non-blocking 특징 이해하기
- 1번 코드가 돌아가는 동시에 2번 코드 실행
- 아직 파일 로드가 안 끝났는데 2번 코드에서 파일을 불러오려고 해서 오류 발생
- 채팅 어플은 다 비동기
- 이미지 업로드 하고 있는 상태에서도 채팅 가능
- 동기 방식으로 채팅 기능 만들면 이미지 업로드하고 있는 동안에는 채팅 못 침
- 1번 코드가 돌아가는 동시에 2번 코드 실행
- get 방식 데이터 처리
- html
- 통신에서 데이터를 넘기는 방식 두 가지: ① form 태그 → 동기 통신 방식 ② ajax 방법(jQuery ajax, fetch 등) → 비동기 통신 방식
- form 태그 →
action="http://localhost:3000" method="get" - name 속성의 중요성
- js
- 클라이언트가 보낸 모든 데이터는 req에 있음
- get 방식은 url에 정보를 넣어 전달 → url만 가져오기 (req.url)
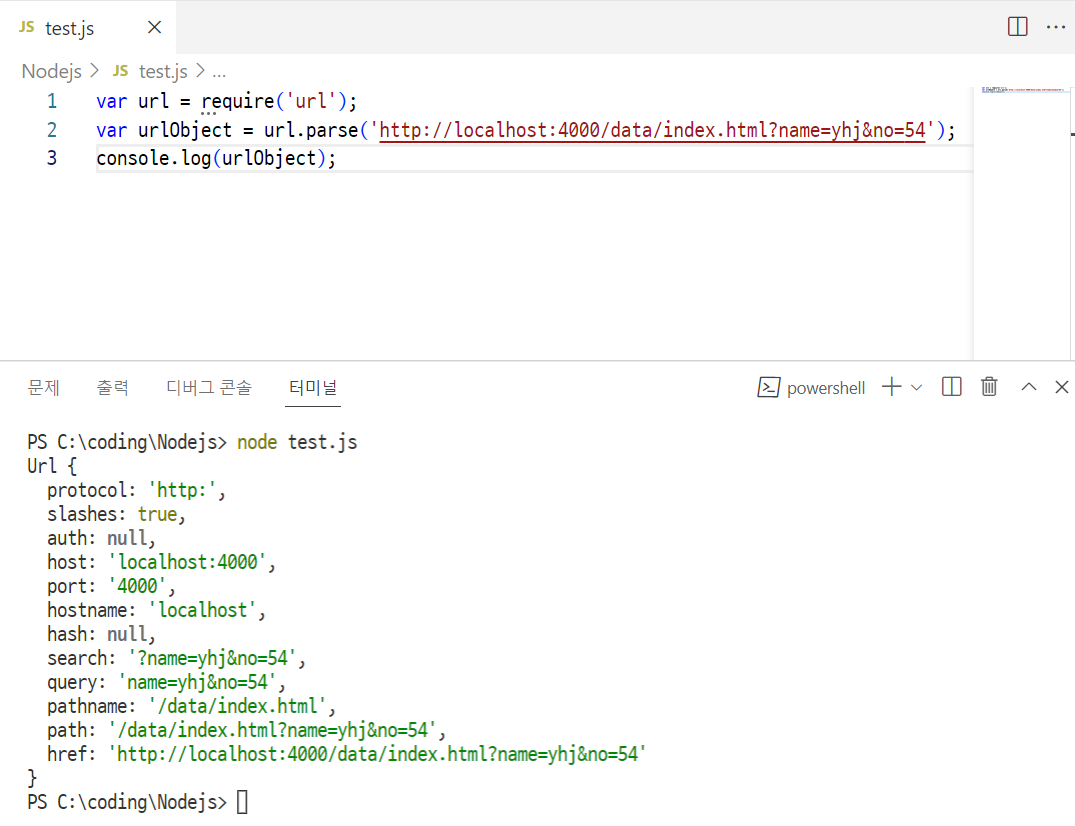
- req.url은 문자열 형식 → 활용 어려움 → 다른 형식으로 변환 필요 → url 모듈 활용:
url.parse(req.url,true).query;
- html
- 총정리!
- get 방식의 데이터 처리법
- 특징: 데이터를 url에 동반해서 보낸다
- 클라이언트: 값을 담아서 form의 action 값에 적힌 구조로 보낸다
- input에는 name이 반드시 필요하다.
- server의 역할
- 특징: 서버는 클라이언트가 보낸 모든 데이터를 req에 저장한다.
- 조회: req.url을 조회한다.
- 주의점: url 데이터는 문자 형태의 데이터 → 하나하나에 접근이 불가능 (통으로 되어 있기 때문)
- 해결책: url 모듈을 통해서 문자 → 객체 변환(parse)
- 사용법: 객체는 .key으로 각각의 값에 접근이 가능하다.
- get 방식의 데이터 처리법
2. 실습: 로그인 성공/실패 페이지 이동
- 실습 내용
- 사용자가 로그인 페이지에서 id, pw를 서버에게 전달
- 서버에서는 사용자가 보낸 id가 "test"이고 pw가 "1234"라면 로그인 성공 페이지를 응답
- 그렇지 않고 둘 중에 하나라도 틀렸다면 로그인 실페 페이지로 응답
- 힌트
- get 방식의 데이터 처리 방법: String → Object
- async/await 사용
- 조건문, && (and 연산자)
- 항상 통신이 끝나면 end로 종료하기
- extension 설치: Save Typing
- 입력할 때마다 자동 저장
const http = require("http");
const url = require("url");
const fs = require("fs").promises;
http.createServer(async (req,res)=>{
let data = url.parse(req.url,true).query;
let success = await fs.readFile("./login_success.html");
let failed = await fs.readFile("./login_failed.html");
if(data.id==="test"&&data.pw==="1234"){
res.write(success);
}else{
res.write(failed);
}
res.end();
}).listen(3000);B. 2교시
1. 실습: 로그인 성공/실패 페이지 이동 (cont.)
서버 통신의 가장 중요한 개념은 데이터의 흐름 파악
→ 항상 데이터의 흐름을 따라가며 접근하기
- 서버 만들기
/*
실습 목표: login.html에서 보낸 데이터를 서버에서 조회
* 포인트: get 방식의 조회 방식 학습 → 모든 데이터가 url에 담겨 온다.
*/
const http = require("http");
// url 데이터를 객체 형태로 변환하는 모듈 → GET 방식과 세트
const url = require("url");
const fs = require("fs").promises;
http.createServer((req,res)=>{
}).listen(3000);- frontend 페이지로 가서 데이터 흐름 파악하기
- login.html에서 무엇이 오는지 확인
- form 태그의 데이터를 가지고 사용자가 입력한 id, pw를 받아서 처리
- form 태그
- 사용자가 id, pw라는 이름으로 데이터를 보냄 → action에 적힌 주소로!
- submit 누르면 id, pw가 port 3000번으로 이동
- action의 주소 == 내가 만든 노드 서버
- method == 통신 방식 → get
- login.html에서 무엇이 오는지 확인
- url 모듈을 통해 Str → Obj 변경
- 어떤 데이터를 받아와야 하는지 먼저 생각하기 → req!
- 통신 방식이 get이라 원하는 데이터는 'url'에 있음 →
req.url → "/?id=test&pw=1234"문자열 형태 → 객체로 변환 필요 - url에서 가져오면 문자열인데 난 따로 따로 접근할 수 있게 객체로 변환해서 쓰고 싶음 → url 모듈 활용
const http = require("http");
const url = require("url");
const fs = require("fs").promises;
http.createServer((req,res)=>{
// string을 객체 형태로 변환
let data = url.parse(req.url,true).query;
}).listen(3000);true: queryString으로 확장하겠다는 의미.query: 쿼리 안에 있는 데이터만 쓰겠다는 의미- queryString? URL에서 물음표 뒤에 오는 모든 문자열
url.parse()로 반환된 url 객체에는 port, path 등 url의 정보가 잘 정리된 상태로 저장되어 있음
여기서 우리가 필요한 것은 query의 내용이기 때문에, url.parse().query를 따로 저장해 주는 것
- 스타일 1: 사고의 흐름대로 작성
const http = require("http");
const url = require("url");
const fs = require("fs").promises;
http.createServer(async (req,res)=>{
let data = url.parse(req.url,true).query;
if(data.id == "test" && data.pw == "1234"){
let success = await fs.readFiole("./로그인성공.html");
res.write(success);
}else{
let fail = await fs.readFiole("./로그인실패.html");
res.write(fail);
}
res.end();
}).listen(3000);- 스타일 2: 관리 영역별로 나누어 작성
- 코드를 가독성 좋게 유지하기 위해서 의미가 같은 부분을 모으기
const http = require("http");
const url = require("url");
const fs = require("fs").promises;
http.createServer(async (req,res)=>{
// 변수 관리 영역 (데이터 준비)
let data = url.parse(req.url,true).query;
let success = await fs.readFiole("./로그인성공.html");
let fail = await fs.readFiole("./로그인실패.html");
// 로직 실행 영역
if(data.id == "test" && data.pw == "1234"){
res.write(success);
}else{
res.write(fail);
}
res.end();
}).listen(3000);- 우리가 지금 한 건 '동기 통신'
- form 태그는 기본적으로 동기 통신을 지향
- TIP: 데이터가 넘어오면 항상 console.log(); 찍어보는 습관 가지기
- debugger; 도 추천
- 실습 포인트
- 서버를 제작할 때는 반드시 데이터의 흐름을 파악하자
- 코드를 작성할 때 서버 쪽만 보지 말고 프론트부터 차근차근 따라가자
- 서버에서 값을 받는 경우 반드시 console에 출력해보자
- 코드를 완성하면 블록화 연습을 하자 → 가독성 향상
express는 async/await, parse 모두 알아서 해 주기 때문에 해당 내용 이해만 하고 넘어가기~
2. post 방식
- 보안에 신경쓰기 때문에 get보다 더 보잡
- buffer: 암호화된 데이터 → 복호화 필요
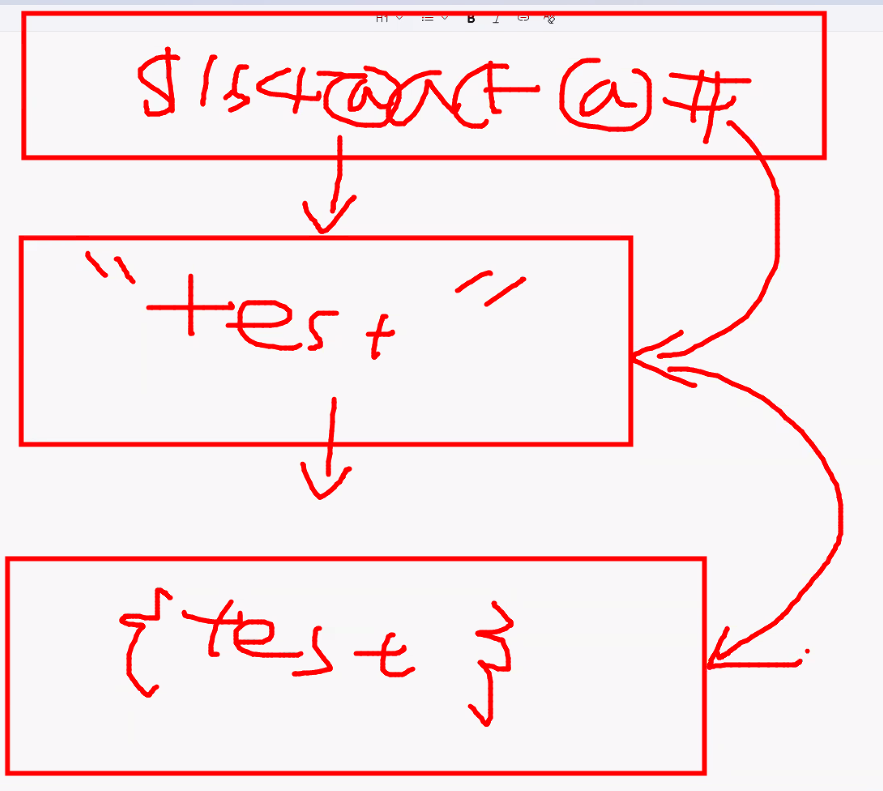
- buffer: 암호화된 데이터 → 복호화 필요
- 로그인은 원래 post로 만드는 것임!
- 보안에 신경써야 하니까
- GET vs. POST ★★★
- GET 방식
- 데이터를 url에 동반해서 통신
- 보안에 취약 → 보안이 필요 없을 때 사용 (검색하면 보이는 검색어 등)
- 데이터 처리: String → Object
- 사용처: DB에서 변화가 없을 때 → 조회(SELECT)
- POST 방식
- 데이터가 url에 동반되지 않음
- 데이터가 숨어서 넘어감 → 보안이 조금 더 좋음 (개인 정보가 넘어가는 통신은 모두 POST)
- 데이터 처리: buffer → String → Object
- 사용처: DB에서 변화가 발생할 때 → 삽입(INSERT), 갱신(UPDATE), 삭제(DELETE)
- GET 방식
실습: POST 방식 데이터 처리
원리만 기억하기!
(지금은 사용 잘 안 하는 문법임)
- 서버 세팅
const http = require("http");
http.createServer((req,res)=>{
}).listen(3000);- POST로 받아 온 buffer 데이터를 String으로 변환
- data == buffer 데이터
const http = require("http");
http.createServer((req,res)=>{
req.on("data",(data)=>{
console.log(data);
})
}).listen(3000);C. 3교시
1. 실습: POST 방식 데이터 처리
buffer 데이터
- console.log(data);로 data의 형태 확인
<Buffer 69 64 3d 68 65 6c 6c 6f 26 70 77 3d 25 36 30 31 32 33>→ ASCII Code Hex → 컴퓨터는 여기서 한 번 더 이진법으로 변환해서 읽음- '안녕 → ㅇㅏㄴㄴㅕㅇ'으로 보내는 것과 유사
- 암호화되어 내용을 바로 확인할 수 없음 → 복호화 필요
const http = require("http");
http.createServer((req,res)=>{
let body = "";
req.on("data",(data)=>{
console.log(data);
body += data;
console.log(body);
});
}).listen(3000);- 내가 컴퓨터에게 test를 보낸다고 가정하면 "test"로 한 번에 보내는 게 하니라 t, e, s, t를 하나씩 보냄 → 함수가 총 4번 실행됨 (함수는 data가 넘어올 때마다 동작하므로) → 따라서 복합 대입 연산자 쓰면 test로 합쳐짐!
<Buffer 69 64 3d 74 65 73 74 26 70 77 3d 31 32 33 34>
id=test&pw=1234
★★★ POST 데이터는 body라는 공간에 저장한다 ★★★
get → url, post → body
- String으로 변환한 데이터를 객체로 활용하는 영역
- end == 데이터 준비가 끝났다는 뜻
- post 방식에서 String → Object 변환해 줄 모듈 필요:
querystring- get 방식의 url 모듈과 역할이 비슷
- post는 url이 아니라서 url 모듈은 못 씀 → querystring이 parse 진행
const http = require("http");
// post 방식에서 String → Object 모듈 (get 방식의 url 모듈과 역할이 비슷)
const qs = require("querystring");
http.createServer((req,res)=>{
// 1. POST로 받아 온 buffer 데이터를 String으로 변환하는 영역
// * POST 데이터는 body라는 공간에 저장한다 ✨
let body = ""; // let body; 해도 된다고 함
req.on("data",(data)=>{
console.log(data);
body += data;
console.log(body);
});
// 2. String으로 변환한 데이터를 객체로 활용하는 영역
req.on("end",()=>{
// String → Object
let data = qs.parse(body);
console.log(data);
})
}).listen(3000);
- 정리: POST 방식 처리 방법
- POST로 데이터를 보내면 글자를 하나하나 buffer 형태로 전송 → 암호화
- 사실 아스키코드라 암호화까지는 아님
- 중요한 건 POST가 데이터를 "숨겨서" 이동한다는 것
- POST의 보안이 더 좋다는 말은 숨긴다는 개념에서 왔음 → 보안의 가장 기초는 숨기는 것!
- 숨긴다는 행위 자체가 1차 보안: 숨겨야 이후 암호화, 접근 제한 등이 가능 ()
- buffer → string → object
- body라는 공간에 post 데이터가 들어간다 → 핵심! Express와 관계 있음
- Express에서는 자동으로 값이 'body'에 저장됨
- 모든 개발자가 post 데이터를 body로 지칭함
- POST로 데이터를 보내면 글자를 하나하나 buffer 형태로 전송 → 암호화
숨길 필요가 없는 데이터는 숨기지 않는 게 기본 전략입니다. (숨기는 것도 비용이기 때문)
메모리적으로 볼 때 숨기는 건 데이터 낭비임
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
- RAG
- 주어진 컨텐츠나 질문에 대해 더욱 정확한 정보를 제공
- 외부 데이터를 실시간으로 검색(Retrieval)하고 활용(Argumented)하여 답변을 생성(Generation)
- 구체적이고 풍부한 정보를 제공
- 최신 데이터를 검색하여 답변 → 실시간으로 변화하는 정보에 대응
- 외부 데이터에 없다면 알 수 없다고 대답하게 만드는 식으로 환각을 줄일 수 있음
- 청크 단위 분할
- PDF를 학습한 나만의 챗봇 만들기
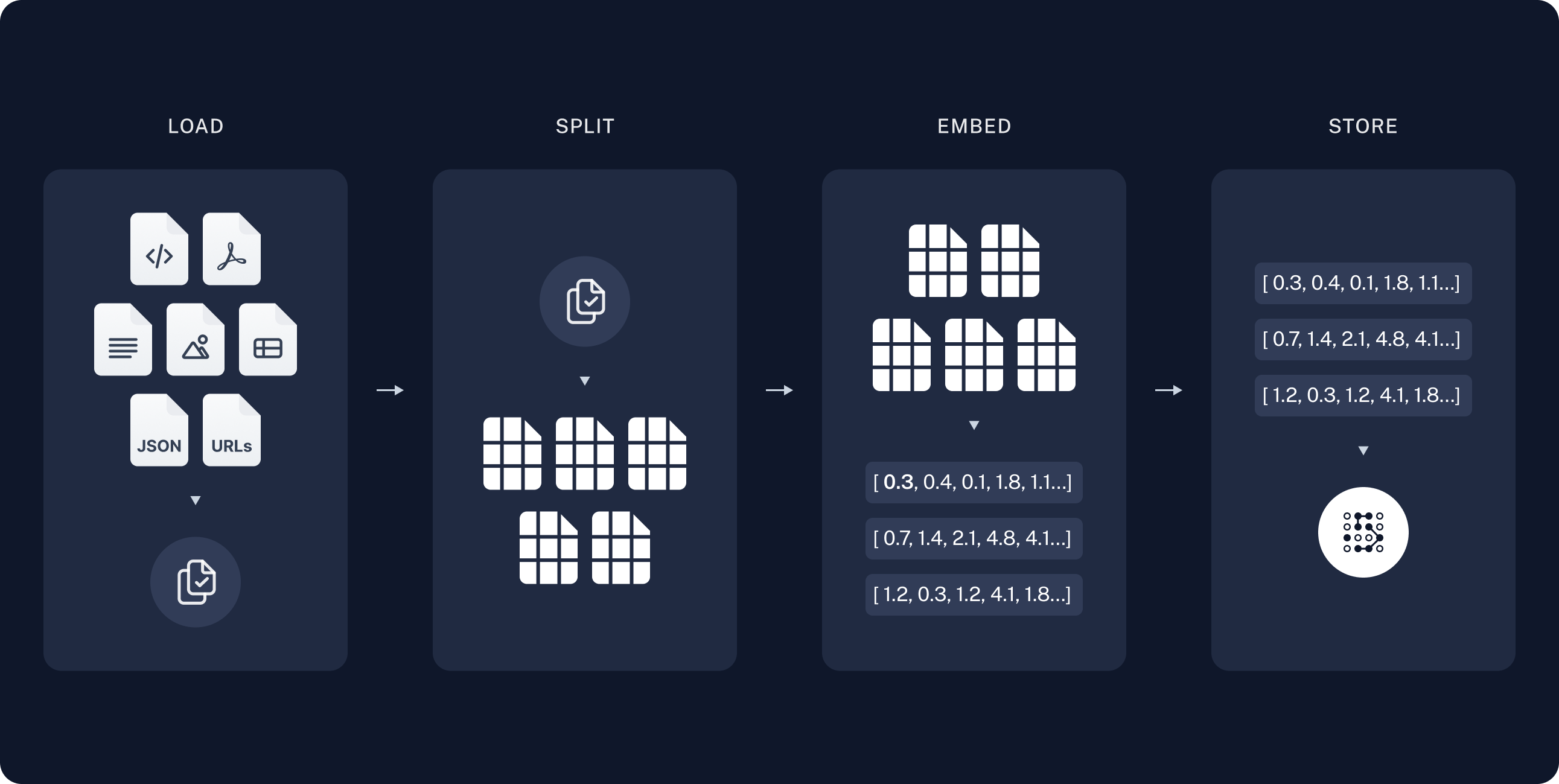
(1) 데이터 로드(Load Data): RAG에 사용할 데이터를 불러오는 단계
(2) 텍스트 분할(Text Split): 불러온 데이터를 작은 크기의 단위(chunk)로 분할하는 단계
(3) 임베딩 (Embedding) / 인덱싱 (Indexing): 텍스트 데이터를 숫자로 이루어진 벡터로 변환하는 단계 → 분할된 텍스트를 검색 가능한 형태로 만듦
(4) 검색(Retrieval): 사용자의 질문이나 주어진 컨텍스트에 가장 관련된 정보를 찾아내는 단계
(5) 생성(Generation): 검색된 정보를 바탕으로 사용자의 질문에 답변을 생성하는 최종 단계
2. RAG: PDF 학습 챗봇
PDF 문서 기반 QA(Question-Answer) 사이트 내용과 함께 보기!
《RAG 프로세스》 1. 사전 작업(Pre-processing): 1-4단계 - 문서 로드 및 Vector DB 저장 - 데이터 소스(문서)를 로드-분할-임베딩-Vector DB(저장소)에 저장하는 4단계 ① 문서 로드(Load) - 문서(pdf, word), RAW DATA, 웹 페이지, Notion 등의 데이터 읽기 ② 분할(Split) - 불러온 문서를 특정 기준(chunk 단위)으로 분할 ③ 임베딩(Embedding) - 문서를 벡터 표현으로 변환(분할된 chunk를 임베딩하여 저장) ④ 벡터DB(VectorStore) - 변환된 벡터를 DB에 저장(임베딩된 chunk를 DB에 저장) 2. RAG수행(RunTime): 5-8단계 - 문서 검색 및 결과 도출 ⑤ 검색(Retrieval) - 유사도 검색(similarity, mmr) - Multi-Query - Mini-Retriever ⑥ 프롬프트(Prompt) - 검색된 결과를 바탕으로 원하는 결과를 도출하기 위한 프롬프트 - RAG를 수행하기 위한 프롬프트 생성 → 프롬프트 엔지니어링을 통해 답변 형식 지정 가능 - 프롬프트의 {context}에는 문서에서 검색된 내용이 입력됨 ⑦ 모델(LLM) - 모델 선택: GPT-3.5, GPT-4, Claude, etc. ⑧ 결과(Output) ← 체인(Chain) - '프롬프트 - LLM - 출력'에 이르는 체인을 생성 - 출력 → 텍스트, JSON, 마크다운※ 검색기(Retriever)?
- 쿼리(Query)를 바탕으로 DB에서 검색하여 결과를 가져오기 위해 '리트리버'를 정의
- 리트리버: 검색 알고리즘
- Dense 리트리버와 Sparse 리트리버로 나뉨
- Dense: 유사도 기반 검색
- Sparse: 키워드 기반 검색
- 텍스트 분할(Text Split)
- 이전 시간에 사용한 'CharacterTextSplitter'는 단순히 지정된 단위로 분할하기 때문에 문맥이 끊길 수 있음
- 문맥의 부자연스러움을 보완하기 위한 새로운 텍스트 분할 도구가 필요 →
RecursiveCharacterTextSpliter
(2) 분할(split): ★ RecursiveCharacterTextSpliter ★
- 청크가 작아질 때까지 주어진 문자 목록의 순서대로 텍스트를 분할
- 문자 목록:
["\n\n", "\n", ,]→ 문단, 문장, 단어 재귀적 분할
- 문자 목록:
- 재귀적 분할
- '문단 → 문장 → 단어' 순으로 확인해 나가면서 분할을 모두 진행
- 더 나은 문맥 단위를 우선시하여 분할 시도 → 문맥이 잘리는 단점을 보완
- 텍스트의 구조를 고려하여 분할 → 문맥의 부자연스러운 분할을 보완
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter_2 = RecursiveCharacterTextSplitter(
chunk_size = 500
, chunk_overlap = 50
, length_function = len
)
# 단계별로 문단 → 문장 → 단어 순으로 분리해나가기 때문에 separater를 작성할 필요가 없다
# 토큰화
chunk_2 = text_splitter_2.split_documents(document)
# 청크 수 출력
print(f"분리된 청크의 수: {len(chunk_2)}")21(3) 임베딩(Embedding)
- 분리된 토큰을 인코딩하고 토큰 간의 연관성을 포함하여 벡터화하는 과정
- 문서의 내용을 수치적인 벡터로 변환하는 과정
- 이 과정을 통해 문서의 의미를 수치화하고, 다양한 자연어 처리 작업에 활용할 수 있음
- 대표적인 사전 학습된 언어 모델: BERT와 GPT
- 문맥적 정보를 포착하여 문서의 의미를 인코딩함
- 토큰화된 문서를 모델에 입력하여 임베딩 벡터를 생성하고, 이를 평균하여 전체 문서의 벡터를 생성
- 생성된 벡터는 문서 분류, 감성 분석, 문서 간 유사도 계산 등에 활용 가능
- 문서의 내용을 수치적인 벡터로 변환하는 과정
지원되는 모델 목록
| MODEL | PAGES PER DOLLAR | PERFORMANCE ON MTEB EVAL | MAX INPUT |
|---|---|---|---|
| text-embedding-3-small | 62,500 | 62.3% | 8191 |
| text-embedding-3-large | 9,615 | 64.6% | 8191 |
| text-embedding-ada-002 | 12,500 | 61.0% | 8191 |
- 임베딩 결과: 벡터 DB에 저장 → FAISS, Chroma 등
- 벡터 DB?
- 데이터를 벡터(숫자 배열) 형태로 저장
- 저장된 데이터를 기반으로 하여 빠르게 검색할 수 있도록 벡터를 효율적으로 저장하는 공간
- 코사인 유사도를 활용하여 가장 가까운 데이터를 검색 → "의미 기반 검색"이 가능해짐
- chatbot(특히 RAG), 추천 시스템 등에서 많이 사용
- 텍스트를 벡터로 변환
OpenAIEmbeddings: 모델 임베딩 도구와 맞춰주기 위함
- 벡터저장소를 생성하여 검색 기능이 가능하도록 설정
Chroma: python 언어에 친화적 벡터 DB- lim, langchain 프레임워크와 통합이 잘 됨
- 데이터 저장 + 벡터 검색 동시에 제공
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# 텍스트를 임베딩 후 DB에 저장
vec_db =Chroma.from_documents(documents=chunk_2, embedding=OpenAIEmbeddings())→ Chroma에게 내 document(chunk_2)를 임베딩(도구: OpenAIEmbeddings())한 다음 저장해달라고 요청하는 것
→ vec_db가 벡터 저장소 역할을 함
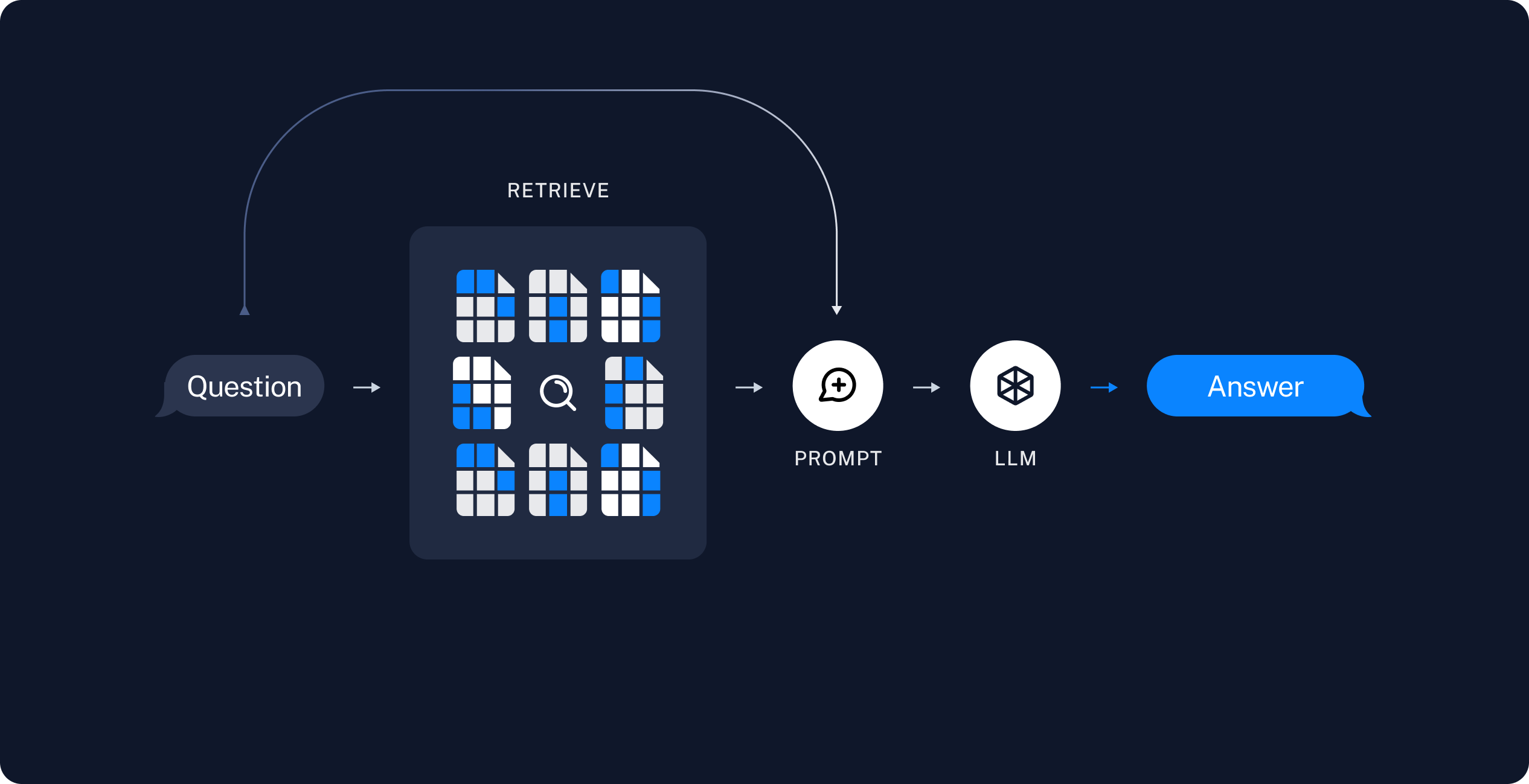
(4) 검색(Retrieval)
- 사용자의 입력을 바탕으로 쿼리를 생성하고 연관성 높은 정보를 검색하여 찾기
- 검색기(retriever)
- 저장된 벡터 데이터베이스에서 사용자의 질문과 관련된 문서를 검색
- search_kwargs={"k":2} 설정
- '가장 유사한 데이터 두 개를 검색하여 추출해주세요'라는 뜻
# 검색 기능 설정
retriever = vec_db.as_retriever(search_kwargs={"k":2})B. 5교시
1. RAG: PDF 학습 챗봇 (cont.)
(5) 생성(Generation)
- LLM에게 검색 결과와 함꼐 사용자의 입력을 전달하고, 모델은 사전 학습된 지식과 검색 결과를 결합하여 주어진 질문에 가장 적절한 답변을 생성
RetrievalQAWithSourcesChain: '검색 → 응답'을 자동으로 처리해 주는 체인 클래스
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQAWithSourcesChain
chat_prompt = ChatPromptTemplate.from_messages([
("system", "{summaries}")
, ("human", "{question}")
])- ChatPromptTemplate을 통하여 역할을 지정
- 검색된 내용에 대해 PDF 내용 전체를 가져오는 것보다 어느 정도 요약해서 가져올 수 있도록 설정하기: "summaries" 역할 부여
# 모델 생성
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# 체인 생성 → 프롬프트, 모델, 벡터 DB
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm # LLM
, retriever=retriever # 벡터 DB
, chain_type_kwargs={"prompt":chat_prompt} # 프롬프트 템플릿
)
chain.invoke("위 파일은 어떤 내용인가요?"){'question': '위 파일은 어떤 내용인가요?',
'answer': '위 파일은 AI(인공지능)를 개인적인 용도와 업무에서 어떻게 활용할 수 있는지에 대한 내용을 다루고 있습니다. AI를 사용해보면서 익히는 태도의 중요성을 강조하며, 다양한 상황에서 AI를 활용하는 방법을 제시하고 있습니다. 또한, AWS와 같은 기업이 내부 교육 프로그램을 통해 직원들이 AI 관련 역량을 개발하고 인증을 취득하도록 지원하는 내용도 포함되어 있습니다. 이 파일은 AI의 실질적인 활용과 교육에 대한 정보를 제공하고 있습니다.',
'sources': ''}query = input("질문을 입력하세요.")
result = chain.invoke({"question":query})
print(result["answer"])질문을 입력하세요.위 파일이 시사하는 내용은?
위 파일은 AI(인공지능)의 중요성과 그 활용 가능성에 대해 설명하고 있습니다. 첫 번째 내용에서는 개인적인 용도로 AI를 활용하는 방법을 제시하며, AI를 직접 사용해보면서 그 가능성을 이해하는 것이 중요하다고 강조하고 있습니다. 이는 AI가 일상생활에서도 유용하게 사용될 수 있음을 시사합니다.
두 번째 내용에서는 기업에서 AI 역량을 갖춘 인재의 중요성을 강조하고 있습니다. 많은 기업들이 AI 역량을 갖춘 인재를 채용하는 것을 최우선 과제로 삼고 있지만, 적합한 인재를 찾는 데 어려움을 겪고 있다는 조사 결과를 제시합니다. 또한, AI 역량을 보유한 인력은 평균적으로 더 높은 급여를 받을 수 있으며, 기업들이 이러한 인재에게 더 많은 급여를 지급할 의향이 있음을 보여줍니다. 이는 AI 역량이 기업의 경쟁력 강화에 중요한 요소로 자리 잡고 있음을 시사합니다.query = input("질문을 입력하세요")
result = chain.invoke(query)
print(f"📌질문: {result['question']}")
print(f"🤖답변: {result['answer']}")질문을 입력하세요미래 필수 역량 5가지 정리해주세요.
📌질문: 미래 필수 역량 5가지 정리해주세요.
🤖답변: 미래에 필수적인 역량으로는 다음과 같은 다섯 가지를 들 수 있습니다:
1. **AI 활용 능력**: AI 기술이 빠르게 발전함에 따라, 이를 일상적인 업무에 혁신적으로 활용할 수 있는 능력이 중요해지고 있습니다. AI를 어떻게 활용할 수 있을지 고민하고, 다른 사람의 활용 방식을 관찰하며 적극적으로 탐색하는 태도가 필요합니다.
2. **창의적 문제 해결 능력**: 단순히 다른 사람의 방식을 모방하는 것이 아니라, 이를 기반으로 새로운 아이디어를 창출할 수 있는 능력이 중요합니다. 창의적 사고를 통해 문제를 해결하고 혁신을 이끌어낼 수 있어야 합니다.
3. **고급 개발 역량**: 단순한 코딩 작업의 중요성은 줄어들고 있으며, 개발자는 무엇을 개발할지 깊이 고민하고, 설계 및 아키텍처를 개선하는 역량이 필요합니다. 코드의 품질을 보장하고 유지하는 능력도 중요합니다.
4. **지속적인 학습과 호기심**: AWS의 '배우고 호기심을 가지라'는 원칙처럼, 지속적으로 배우고 새로운 것에 호기심을 가지는 태도가 중요합니다. 이는 AI 시대에 누구나 가져야 할 핵심 역량입니다.
5. **협업과 커뮤니케이션 능력**: 복잡한 문제를 해결하기 위해 다양한 분야의 사람들과 협업하고 효과적으로 소통할 수 있는 능력이 필요합니다. 팀워크와 커뮤니케이션은 성공적인 프로젝트 수행에 필수적입니다.# 간단한 형태의 챗봇 구성해보기 (while문)
while True:
# 사용자 입력
query = input("입력: ")
# 조건문을 활용한 종료
if query == "exit":
print("채팅을 종료합니다👋")
break
# 결과출력
result = chain.invoke(query)
print(f"📌질문: {result['question']}")
print(f"🤖답변: {result['answer']}")
print('-'*50)입력: 안녕?
📌질문: 안녕?
🤖답변: 안녕하세요! 어떻게 도와드릴까요?
--------------------------------------------------
입력: 넌 어떤 내용을 학습했니?
📌질문: 넌 어떤 내용을 학습했니?
🤖답변: 저는 다양한 주제와 분야에 대한 정보를 학습했습니다. 예를 들어, 인공지능, 머신러닝, 자연어 처리, 데이터 과학, 기술 트렌드, 역사, 문화, 과학, 수학 등 여러 분야에 걸쳐 있습니다. 또한, 최신 기술 발전, 산업 동향, 사회적 이슈 등에 대한 정보도 포함되어 있습니다. 이를 통해 사용자에게 유용한 정보를 제공하고 질문에 답변할 수 있도록 설계되었습니다.
--------------------------------------------------
입력: 내가 준 pdf 내용에 대해 알고 있니?
📌질문: 내가 준 pdf 내용에 대해 알고 있니?
🤖답변: 네, 제공된 PDF의 내용에 대해 알고 있습니다. 이 문서는 AI와 관련된 역량 개발의 중요성을 강조하며, AWS와 같은 기업들이 내부 교육 프로그램을 통해 직원들이 AI 관련 인증을 취득하도록 지원하는 내용을 포함하고 있습니다. 또한, 개인적인 용도로 AI를 활용해보는 것이 중요하다는 점을 언급하며, 이를 통해 AI의 실제 활용 가능성을 업무와 일상생활에서 더욱 명확하게 이해할 수 있다고 설명하고 있습니다.
--------------------------------------------------
입력: AWS에서 말하는 필수역량 5가지 말해줘
📌질문: AWS에서 말하는 필수역량 5가지 말해줘
🤖답변: AWS에서 강조하는 필수 역량은 다음과 같습니다:
1. **AI 이해 및 활용 능력**: AI가 무엇인지 기본적으로 이해하고, 이를 실제 업무에서 어떻게 활용할 수 있는지를 학습하는 것이 중요합니다.
2. **생성형 AI 활용 능력**: 생성형 AI에 대한 전문 지식과 이를 활용하는 역량이 필요합니다.
3. **핵심 소프트 스킬**: 기술적 역량뿐만 아니라 커뮤니케이션, 문제 해결 능력 등과 같은 소프트 스킬도 필수적입니다.
4. **지속적인 학습 및 역량 개발**: 변화하는 기술과 비즈니스 환경에 적응하기 위해 지속적으로 학습하고 역량을 개발하는 자세가 필요합니다.
5. **AI 공인 프랙티셔너 인증**: 역할에 따라 최소한 AI 공인 프랙티셔너(AI Practitioner) 인증을 취득하는 것이 요구됩니다.
이러한 역량들은 AWS뿐만 아니라 현대의 많은 기업들이 중요하게 여기는 요소들입니다.
--------------------------------------------------
입력: 이 문서에서 '생성형 AI 활용 능력'이 왜 중요하다고 했어?
📌질문: 이 문서에서 '생성형 AI 활용 능력'이 왜 중요하다고 했어?
🤖답변: 문서에서는 '생성형 AI 활용 능력'이 중요하다고 언급한 이유로, 이는 대부분의 사람들이 아직 갖추지 못한 기술이며, 미래에 필수적인 역량이 될 것이라고 설명하고 있습니다. 생성형 AI의 기본 개념을 익히고 프롬프트 엔지니어링을 학습하는 것이 중요하며, 이러한 기술을 통해 창의성을 발휘하고 새로운 방식으로 사고하며 비판적 사고를 통해 문제를 해결하는 역량이 점점 더 중요해지고 있다고 강조하고 있습니다. AI 도구를 활용하여 원하는 결과를 얻지 못했을 때, 그 이유를 분석하고 접근 방식을 조정할 수 있는 능력이 필요하다고도 설명하고 있습니다.
--------------------------------------------------
입력: AWS는 AI 도구를 통해 개발자 생산성을 어떻게 높이려고 해?
📌질문: AWS는 AI 도구를 통해 개발자 생산성을 어떻게 높이려고 해?
🤖답변: AWS는 AI 도구를 통해 개발자의 생산성을 높이기 위해 여러 가지 전략을 추진하고 있습니다. 그 중 하나는 AI 코딩 도구인 '아마존 Q 개발자(Amazon Q Developer)'를 활용하는 것입니다. 이 도구를 통해 두 가지 주요 목표를 달성하고자 합니다. 첫째, 개발 속도를 높여 고객을 위한 솔루션을 더욱 빠르게 구축할 수 있도록 지원합니다. 둘째, 더 높은 품질의 코드를 빠르게 작성하여 전반적인 업무 효율성을 향상시키는 것입니다. 이러한 도구들은 개발자들이 더 효율적으로 작업할 수 있도록 돕고, 결과적으로 생산성을 크게 향상시킬 수 있습니다.
--------------------------------------------------
입력: AWS가 내부 교육에서 강조한 자격증이나 과정은 뭐였어?
📌질문: AWS가 내부 교육에서 강조한 자격증이나 과정은 뭐였어?
🤖답변: AWS가 내부 교육에서 강조한 자격증은 'AWS 공인 AI 프랙티셔너(AWS Certified AI Practitioner)'입니다. 이 자격증은 직원들이 AI 관련 역량을 개발하고, 역할에 따라 최소한 이 인증을 취득하도록 장려하고 있습니다. 또한, 'AWS 공인 머신러닝 엔지니어 어소시에이트(AWS Certified Machine Learning Engineer Associate)' 시험도 강조되고 있으며, 이 과정의 베타 참가자 수가 기존 평균 대비 크게 증가했습니다.
--------------------------------------------------
입력: exit
채팅을 종료합니다👋2. RAG: 웹 페이지 학습 챗봇
- WebBaseLoader
- 웹에서 정보를 추출할 수 있도록 도와주는 라이브러리
- BeautifulSoup
- 웹에서 수집한 문자열을 HTML로 파싱
# 라이브러리 불러오기
from langchain_community.document_loaders import WebBaseLoader
import bs4
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS, Chroma # Vector DB
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_teddynote.messages import stream_response
from langchain_openai import ChatOpenAI
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.chains import RetrievalQAWithSourcesChain| 라이브러리/모듈 | 기능 설명 |
|---|---|
bs4 | 웹페이지를 파싱하고 HTML/XML 구조에서 텍스트 데이터를 추출하는 라이브러리 (BeautifulSoup) |
langchain_community.document_loaders.WebBaseLoader | 웹사이트에서 텍스트를 로딩하고 LangChain의 문서 객체로 변환 |
langchain_text_splitters.RecursiveCharacterTextSplitter | 텍스트를 문단 → 문장 → 단어 등 계층적으로 나누어 청크 단위로 분할 |
langchain_openai.OpenAIEmbeddings | OpenAI 모델을 사용하여 텍스트를 벡터(임베딩)로 변환 |
langchain.vectorstores.FAISS | 벡터 데이터베이스 중 하나로, 벡터 간 유사도 기반 검색 수행 |
langchain_core.prompts.PromptTemplate | 입력값을 프롬프트 템플릿에 채워 넣어 LLM 호출용 프롬프트 생성 |
langchain_core.runnables.RunnablePassthrough | 입력을 변경하지 않고 그대로 다음 단계로 전달하는 연결용 Runnable |
langchain_core.output_parsers.StrOutputParser | LLM의 출력 결과를 문자열로 파싱해 후처리 용도로 사용 |
langchain_teddynote.messages.stream_response | 스트리밍 방식으로 LLM 응답을 처리하는 기능 (Teddynote 확장 모듈) |
langchain_openai.ChatOpenAI | OpenAI의 GPT 모델을 LangChain에서 채팅형 LLM으로 사용 |
문서 로드(Load)
# 웹 페이지를 읽어주는 로더
url = "https://n.news.naver.com/article/437/0000440499?sid=103"
loader = WebBaseLoader(
web_paths=[url]
, bs_kwargs=dict(
parse_only = bs4.SoupStrainer(
"div"
, attrs={"class":["newsct_article _article_body","media_end_head_title"]}
)
)
)
# 우리의 문서
docs = loader.load()C. 6교시
1. RAG: 웹 페이지 학습 챗봇 (cont.)
분할(Split)
# RecursiveCharacterTextSplitter 객체 생성 (청크 최대 개수 1000, 겹치는 부분 100자)
# 문서를 Chunk 단위로 분리하기 (docs)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000
, chunk_overlap=100
, length_function=len
)
chunks = text_splitter.split_documents(docs)임베딩(Embedding)
# RecursiveCharacterTextSplitter 객체 생성 (청크 최대 개수 1000, 겹치는 부분 100자)
# 문서를 Chunk 단위로 분리하기 (docs)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000
, chunk_overlap=100
, length_function=len
)
chunks = text_splitter.split_documents(docs)벡터 DB 저장 및 검색기 설정
# 벡터화(임베딩) → FAISS DB 활용 → DB 저장
# 검색기 설정 (유사 2개 데이터 활용)
vec_db = FAISS.from_documents(documents=chunks, embedding=OpenAIEmbeddings())
retriever = vec_db.as_retriever(search_kwargs=dict(k=2))프롬프트
# 단순 프롬프트 (해당 웹 페이지 정보에서 찾을 수 없다면 '주어진 정보에서 찾을 수 없습니다.' 출력)
prompt = ChatPromptTemplate.from_template("""
너는 웹 페이지 안의 정보를 알려주는 AI 챗봇이야.
주어진 정보:
{summaries}
질문: {question}
만약 주어진 정보에 내용이 없다면 '주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다.'라고 답변해줘.
""")모델 생성
# LLM 객체 생성
llm = ChatOpenAI(
model_name="gpt-4o-mini"
, temperature=0
)체인 생성
# 체인 객체 생성
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm, retriever=retriever, return_source_documents=True,
chain_type_kwargs={"prompt": prompt}
)쳇봇 구성 및 결과 출력
while True:
# 사용자 입력
query = input("입력: ")
# 조건문을 활용한 종료
if query == "exit":
print("채팅을 종료합니다👋")
break
# 결과출력
result = chain.invoke(query)
print(f"📌질문: {result['question']}")
print(f"🤖답변: {result['answer']}")
print('-'*50)입력: 광주의 날씨는 어떤가요?
📌질문: 광주의 날씨는 어떤가요?
🤖답변: 광주의 날씨는 아침 기온이 13도, 낮 기온은 25도 정도로 예상되며, 당분간 초여름 같은 더위가 계속될 것으로 보입니다. 또한, 내일(13일)도 봄볕이 뜨겁게 내리쬐고, 야외 활동 시 자외선 차단제를 바르는 것이 좋습니다.
--------------------------------------------------
입력: 위 기사는 언제 기사인가요?
📌질문: 위 기사는 언제 기사인가요?
🤖답변: 주어진 정보에서 찾을 수 없습니다.
--------------------------------------------------
입력: 시드니의 날씨는 어떤가요?
📌질문: 시드니의 날씨는 어떤가요?
🤖답변: 주어진 정보에서 찾을 수 없습니다.
--------------------------------------------------
입력: exit
채팅을 종료합니다👋추가: 보충 공부
RetrievalQAWithSourcesChain 사용 시 주의 사항
- StuffDocumentsChain을 초기화할 때, document_variable_name과 연결된 변수가 prompt에 있어야 함
- document_variable_name에 지정된 이름(기본 변수명: "summaries")이 prompt의 input_variables와 LLMChain에도 반드시 포함되어야 함
- 예를 들어 document_variable_name="summaries"라면, prompt를 만들 때 input_variables에 반드시 "summaries"가 있어야 하고, 템플릿 내에도 {summaries}를 써야 함
- prompt 템플릿 내에서 해당 변수를 사용해야 정상적으로 chain이 동작
- 만약 다른 변수명을 쓴다면, document_variable_name과 prompt 내의 변수명, input_variables 모두 동일하게 맞춰야 함
- 변수 이름을 아예 context로 맞추고 싶다면, 체인 생성 시 document_variable_name="context"를 명시하기
- document_variable_name에 지정된 이름(기본 변수명: "summaries")이 prompt의 input_variables와 LLMChain에도 반드시 포함되어야 함
- RetrievalQAWithSourcesChain는 기본적으로 단일 질의와 문서 요약 등의 변수를 요구하고, 대부분 PromptTemplate(텍스트 기반)을 기대함
- ChatPromptTemplate은 챗봇처럼 역할과 사용자 메시지(시스템, 유저, 어시스턴트)로 분리된 대화형 프롬프트를 지원하지만, RetrievalQAWithSourcesChain이 바로 이를 인식하지 못할 수 있음
- 기본 PromptTemplate 방식이 더 호환성이 높음
- ChatPromptTemplate은 RetrievalQAWithSourcesChain 대신, 직접 LLM과 Retriever를 연결하거나 ConversationalRetrievalChain 등에서 더 자연스럽게 쓸 수 있음
- 만약 시스템 프롬프트가 필요한 경우, LangChain의 ConversationalRetrievalChain을 사용하거나, 직접 LLM 호출과 Retriever를 연결해서 커스텀 체인을 만들면 ChatPromptTemplate도 활용할 수 있음
- ChatPromptTemplate은 챗봇처럼 역할과 사용자 메시지(시스템, 유저, 어시스턴트)로 분리된 대화형 프롬프트를 지원하지만, RetrievalQAWithSourcesChain이 바로 이를 인식하지 못할 수 있음
- chain_type_kwargs 옵션
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={
"prompt": prompt,
"document_variable_name": "summaries" # 또는 프롬프트에서 정의한 변수명
}
)
# 프롬프트에서 {context}를 쓸 경우
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={
"prompt": prompt,
"document_variable_name": "context"
}
)
커스텀 챗프롬프트
- 직접 연결 방식이 커스텀 챗프롬프트에 더 적합
- retriever, postprocessor 등 다양한 단계를 원하는 대로 조합할 수 있음
- 체인 직접 연결 방법
- 파이프라인(|) 연산자를 활용해
prompt | retriever | llm | output_parser등으로 컴포넌트를 순서대로 연결하여 자신만의 체인을 만들 수 있음 - 기존 체인보다 자유도가 높아, 프롬프트 구조나 출력 파서 등 원하는대로 맞춤 설정이 가능
- LCEL(LangChain Expression Language) 방식이나 SequentialChain 등으로 여러 단계를 쉽게 이어 붙일 수 있음
- 파이프라인(|) 연산자를 활용해
- 예시
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_template("""
너는 웹 페이지 안에 있는 정확한 정보를 알려주는 AI 챗봇이야.
해당 웹 페이지 정보에서 찾을 수 없다면 '주어진 정보에서 찾을 수 없습니다.'를 출력해줘.
""")
llm = ChatOpenAI(model="gpt-4")
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
result = chain.invoke({"input": "...여기에 입력..."})코드 작성 시 확인해야 할 부분들
- 체인 연결(Piping) 방식 이슈
- prompt, retriever, llm 모두 Runnable 객체이거나 RunnablePassthrough 등 명확한 입력/출력 인터페이스를 가져야 정상 실행됨
- 체인 방식 및 타입 불일치
- PromptTemplate과 ChatPromptTemplate의 출력이 바로 retriever에 입력될 수 없거나, 그 반대의 경우가 많음
- 각 스텝의 입력/출력 타입을 확인하기
- 일반적으로는 RunnablePassthrough, StrOutputParser 등도 체인 내에 포함시켜야 맞는 경우가 많음
- PromptTemplate과 ChatPromptTemplate의 출력이 바로 retriever에 입력될 수 없거나, 그 반대의 경우가 많음
- 스트리밍 핸들러 문제
- StreamingStdOutCallbackHandler()는 stdout에 직접 로그를 출력하는 핸들러로, 이 핸들러가 str 처리와 인터페이스가 맞지 않으면 오류 발생
- input/output 처리 방식
- input("입력: ")로 받아온 query가 chain에 바로 적용될 때, 입력값이 내부적으로 dict 형식일 것을 요구하는 경우가 있으니 주의가 필요함
- chain.invoke() 함수는 단일 쿼리(str) 또는 dict를 받는데, 프롬프트 템플릿이 키를 요구한다면 {"question": query} 형태로 전달해야 함
- 프롬프트 → retriever → LLM → 파서 입력/출력 타입 맞추기
Ⅲ. CAREER UP
현직자 특강
인프라
- 서버
- 특징: 안정성, 성능, 보안, 확장성
- 24시간, 365일 운영
- 동시 사용자 수 처리 → CPU, 메모리, 스토리지(로그 기록)
- 해킹, 침입 방지를 위한 보안 체계
- 사용자 늘어나면 서버 추가 또는 클라우드 스케일링
- 특징: 안정성, 성능, 보안, 확장성
- 네트워크
- 여러 컴퓨터와 장비들이 데이터를 주고받을 수 있도록 연결
- 끊기면 서버, 스토리지 활용 불가능
- 스위치, 라우터, 방화벽 등의 장비 필수
- LAN/WAN
- LAN: 좁은 범위 → VPC
- WAN: 넓은 범위
- 특징: 속도, 안정성, 보안, 확장성
- 전송 속도 측정(Mbps, Gbps)
- 지연(latency), 패킷 손실 최소화
- 암호화, 접근 제어
- 사용자가 능러나면 네트워크 장비 확장 필요
- 스토리지
- 데이터 보관 장치/시스템
- 용량, 속도
- 특징: 성능, 용량, 안정성, 가용성
- 백업의 중요성
- 백업(backup): 데이터를 여러 곳에 복제해 보관하는 것 → 안정성 확보
- RTO: 시간
- RPO: 시점
- 시스템 복구 시점 저장
- 풀백업 시점 복구 -> 증분된 최신 시점까지 복구
일반 vm 서버 설명
- VPC(Vircual Private Cloud)
- XEN = 2세대
- KVM = 3세대
- XEN -> KVM 넘어가는 추세
- SSD/HDD Server
- PAYG(Pay As You Go)
| 네이버클라우드 | AWS |
|---|---|
| High CPU-g2 | C |
| Standard-g2 | S |
| High Memory-g2 | M |
- 2배수, 4배수, 8배수?
| 네이버클라우드 | CPU | memory |
|---|---|---|
| High CPU-g2 | 2 | 3 |
| Standard-g2 | 2 | 8 |
| High Memory-g2 | 2 | 16 |
- 예시

- Linux OS
- RHEL은 금융에서만 사용
- Default Storage == root
- kernal update 시 crush 발생할 수 있으니 유의
- yum update
- apt -
- Window OS
- 내 서버 이미지(server image) AMI
- OS+SSD 한 번에 저장 → 현재 시점 기준으로 backup
- init-script를 이용하면 일부 자동화 가능
GPU SERVER 설명
- GPU spec
- Bare Metal Server
- 일반 vm보다 더 고성능 → H/W 그대로 쓰기 때문
- 이웃 간 간섭 발생 가능성
- PUG
- Block Storage
- vm
-/dev/d
-/dev/c - 외장하드
- vm
STORAGE
1GB 당 40IOPS 보장
10GB = 4000IOPS
defalut가 4000IPOS이기 때문
110GB = 4400IOPS
NAS → 공유
리눅스는 NFS
윈도우는 CIFS
OBJECT STORAGE
hot data/cold data 구분 → archive storage 이관 가능
365일 동안 보관되어 있는 데이터 → 366일차에 이관 : 비용 절약 효과
block → 하드디스크/ssd
생명 주기 정책
실습
- 서버 생성 후 상태 변화 순서 기억하기
- 생성중 -> 부팅중 -> 설정중 -> 운영중
Q. 제공되는 os 이미지 말고도 아무거나 깔 수 있는 거겠죠?
A. 판매 종료/서버 이미지 제공 X os의 경우 지원하지 않습니다.
e.g., CentOS 7 -> Naver Cloud
Migration 방안이 없음
Q. aws에선 커스텀 이미지 탭에서 훨씬 다양한 배포판들을 선택가능하지 않나요?
A. 그 부분이 aws만의 장점입니다.
- 실습 끝나면 서버 정지시키고 서버, 스토리지, 공인 IP 반납해야 함! (안 그러면 요금 계속 나감)
하루 돌아보기
👍 잘한 점
- 수업 열심히 참여 & 질문 많이 했음
👎 아쉬웠던 점
- RAG 이해가 잘 안돼서 수업 이해도가 떨어졌음
🔬 개선점
