[인공지능사관학교: 자연어분석A반] 학습 내용 보충 - 자연어 처리 모델 학습 파이프라인과 토큰화
모델 학습의 전체 학습 파이프라인
과제(Task)에 상관없이 공통으로 적용됩니다.
- 각종 설정값 정하기
- 모델을 만드려면 가장 먼저 각종 설정값을 정해야 함:
- 어떤 프리트레인 모델을 사용할 것인가?
- 학습에 필요한 데이터는 무엇인가?
- 학습 결과는 어디에 저장할 것인가?
등등
- 본격적인 학습에 앞서 설정값들을 미리 선언해 두는 rjt이 좋다
- 하이퍼파라미터(hyperparameter) 역시 미리 정해둬야 하는 중요한 정보임
- 하이퍼파라미터: 모델 구조와 학습 등에 직접 관계된 설정값
- 예: 러닝 레이트(Learning Rate), 배치 크기(batch size) 등
- 모델을 만드려면 가장 먼저 각종 설정값을 정해야 함:
# 설정값 선언
from ratsnlp.nlpbook.classification import ClassificationTrainArguments
# rstsnlp: 실습 진행용 오픈소스 파이썬 패키지 → 다운로트 툴킷으로 사용
# github.com/ratsgo/ratsnlp
args = ClassificationTrainArguments(
pretrained_model_name="beomi/kcbert-base"
, downstream_corpus_name="nsmc"
, downstream_corpus_root_dir="/content/Korpora"
, downstream_model_dir="/gdrive/My Drive/nlpbook/checkpoint-doccls"
, learning_rate=5e-5
, batch_size=32
,
)- 데이터 내려받기
- 프리트레인을 마친 모델을 다운스트림 데이터로 파인튜닝하기 위해서는 다운스트림 데이터를 미리 내려받아 둬야 함
- NSMC(Naver Sentiment Movie Corpus): 네이버 영화 리뷰 말뭉치 → 상업적으로도 사용할 수 있는 다운스트림 데이터 중 하나
- 프리트레인을 마친 모델을 다운스트림 데이터로 파인튜닝하기 위해서는 다운스트림 데이터를 미리 내려받아 둬야 함
# 데이터 다운로드
from Korpora import Korpora
# 코포라(Korpora): 오픈소스 파이썬 패키지. 다양한 한국어 말뭉치를 쉽게 내려받고 전처리할 수 있음
# github.com/ko-nlp/korpora
Kopora.fetch(
corpus_name=args.downstream_corpus_name
, root_dir=args.downstream_corpus_root_dir
, force_download=True
)- 프리트레인을 마친 모델 준비하기
- 대규모 말뭉치를 활용한 프리트레인에는 많은 리소스가 필요함
- 허깅페이스(huggingface): 미국 자연어 처리 기업
- 트랜스포머(transformers): 허깅페이스에서 만든 오픈소스 파이선 패키지
- 이 패키지를 쓰면 단 몇 줄만으로 모델을 사용할 수 있음
# kcbert-base 모델 준비
from transformers import BertConfig, BertForSequenceClassification
pretrained_model_config = BertConfig.from_pretrained(
args.pretrained_model_name # kcbert-base 모델(github.com/Beomi/KcBERT)를 준비
, num_labels=2
,
)
model = BertForSequenceClassification.from_pretrained(
args.pretrained_model_name
, config=pretrained_model_config
,
)
# kcgert-base가 로컬 저장소에 없으면 자동으로 내려받고, 있으면 캐시 디렉터리에서 읽어옴- 토크나이저 준비하기
- 자연어 처리 모델의 입력은 대개 토큰(token)임
- 토큰: 문장(sentence)보다 작은 단위. 한 문장은 여러 개의 토큰으로 구성
- 토큰 분리 기준은 그때그때 다름: 문장을 띄어쓰기만으로 나눌 수도 있고, 의미의 최소 단위인 형태소(morpheme) 단위로 나눌 수도 있음
- 토큰화(tokenization): 문장을 토큰 시퀀스(token sequence)로 분석하는 과정
- 토크나이저(tokenizer): 토큰화를 수행하는 프로그램
- 예: BPE(Byte Pair Encoding)나 워드피스(wordpiece) 알고리즘을 채택한 토크나이저
- 자연어 처리 모델의 입력은 대개 토큰(token)임
# kcbert-base 토크나이저 준비
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
args.pretrained_model_name
, do_lower_case=False
,
)
# 토크나이저 관련 파일이 로컬 저장소에 없으면 자동으로 내려받고, 있으면 캐시에서 읽어옴-
데이터 로더(DataLoader) 준비하기
-
파이토치(PyTorch)에 포함되어 있음
-
파이토치로 딥러닝 모델을 만드려면 데이터 로더를 반드시 정의해야 함
-
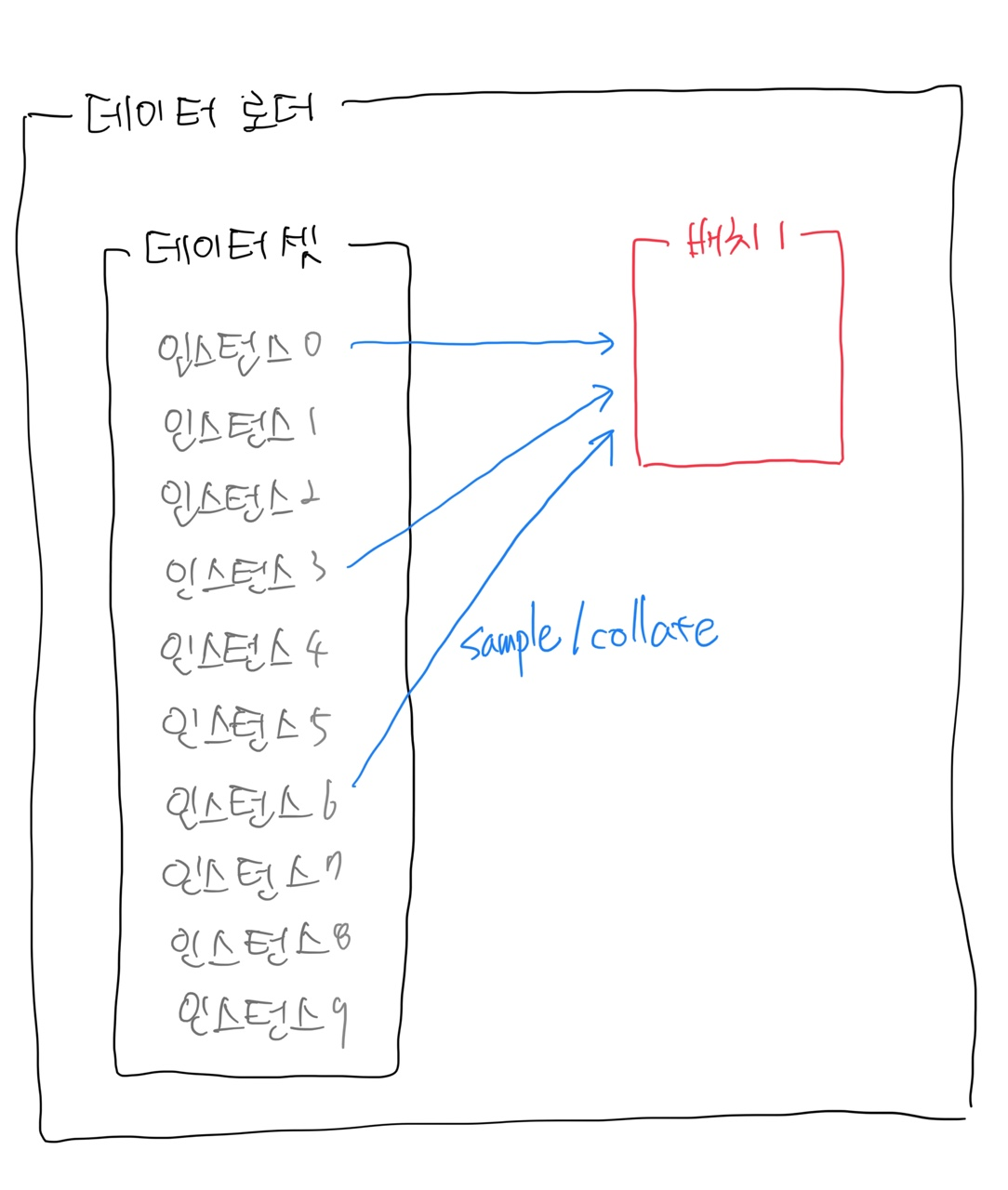
데이터를 배치(batch) 단위로 모델에 밀어 넣어주는 역할
- 전체 데이터 중 일부 인스턴스를 뽑아(sample) 배치를 구성함 → 샘플(sample)/컬레이트(collate)
-
데이터셋(dataset): 데이터 로더의 구성 요소 가운데 하나
- 여러 인스턴스(문서+레이블)를 보유하고 있음
-
데이터 로더가 배치를 만들 때 인스턴스를 뽑는 방식은 파이토치 사용자가 자유롭게 정할 수 있음
- 예: 크기가 3인 배치 구성
→ 배치 1은 0번, 3번, 6번 인스턴스로 구성
→ 배치 2는 1번, 4번, 7번 인스턴스로 구성
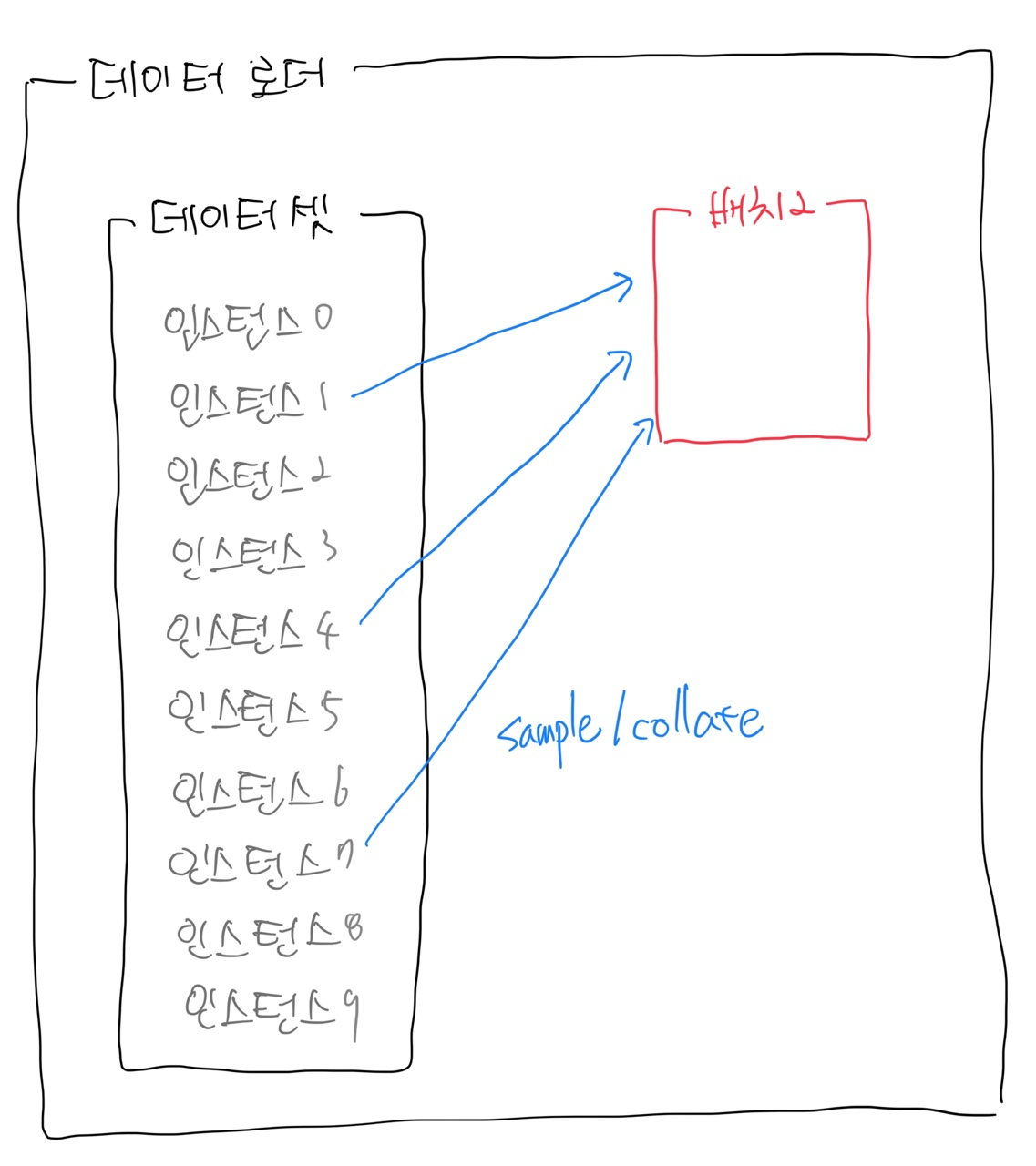
- 예: 크기가 3인 배치 구성
-
배치는 그 모양이 고정적이어야 할 때가 많음 == 동일한 배치에 있는 문장들의 토큰(input_ids) 개수가 같아야 함
- 예: 데이터셋의 0번, 3번, 6번 인스턴스로 구성된 배치에서 각각의 토큰 개수가 5, 3, 4개이고 제일 긴 길이로 맞춘다면 0번 인스턴스의 길이(5개)에 따라 3번과 6번 인스턴스의 길이를 늘여야 함

- 예: 데이터셋의 0번, 3번, 6번 인스턴스로 구성된 배치에서 각각의 토큰 개수가 5, 3, 4개이고 제일 긴 길이로 맞춘다면 0번 인스턴스의 길이(5개)에 따라 3번과 6번 인스턴스의 길이를 늘여야 함
-
컬레이트(collate): 배치의 모양 등을 정비해 모델의 최종 입력으로 만들어 주는 과정
- 컬레이트 과정에는 파이썬 리스트(list)에서 파이토치 텐서(tensor)로의 변환 등 자료형 변환도 포함됨
- 컬레이트 수행 방식 역시 파이토치 사용자가 자유롭게 구성 가능
-
# 문서 분류 데이터 로더 선언
from ratsnlp import nlpbook
from torch.utils.data import DataLoader, RandomSampler
from ratsnlp.nlpbook.classification import NsmcCorpus, ClassificationDataset
corpus = NsmcCorpus()
train_dataset = ClassificationDataset(
args=args
. corpus=corpus
. tokenizer=tokenizer
. mode="train"
,
)
train_dataloader = DataLoader(
train_dataset
, batch_size=args.batch_size
, sampler=RandomSampler(
train_dataset
, replacement=False
)
, collate_fn=nlpbook.data_collator
, drop_last=False
, num_workers=args.cpu_workers
,
)첵에서 다루는 자연어 처리 모델의 입력은 토큰 시퀀스로 분석된 자연어, 더 정확하게는 각 토큰이 그에 해당하는 정수(integer)로 변환된 형태
즉, 자연어 처리 모델은 계산 가능한 형태 == 숫자 입력을 받는다!
인덱싱(indexing): 각 토큰을 그에 해당하는 정수로 변환하는 과정
인덱싱은 보통 토크나이저가 토큰화와 함꼐 수행
용어 “인덱싱(indexing)”은 상황과 분야에 따라 다르게 쓰임
- 파이썬 문법에서의 인덱싱:
- 리스트나 문자열 등에서 특정 위치의 값을 추출하는 작업
- 예:
my_list[0]처럼 대괄호로 위치(인덱스)를 지정해 값을 가져오는 것- 자연어 처리(NLP) 모델에서의 인덱싱:
- 각 토큰(단어, subword 등)을 고유한 정수(ID)로 변환하는 과정
- 예:
tokenizer.encode("고양이")를 하면"고양이" → [1023]같이 숫자 인덱스로 변환됨
- 이 과정은 토큰화(tokenization) 이후, 딥러닝 모델이 텍스트가 아닌 수치 데이터를 다루기 위해 필수적으로 이뤄짐
- 정리하면:
- 같은 “인덱싱”이라는 말이더라도 상황마다 의미가 다름
- 프로그래밍 언어에서는 “데이터의 특정 위치를 참조”하는 것,
- NLP에서는 “토큰을 고유한 정수 인덱스(ID)로 변환”하는 것을 각각 지칭 → NLP 맥락에서 “인덱싱”은 주로 모델 입력 전/후 정수 인덱스로의 매핑 작업을 의미
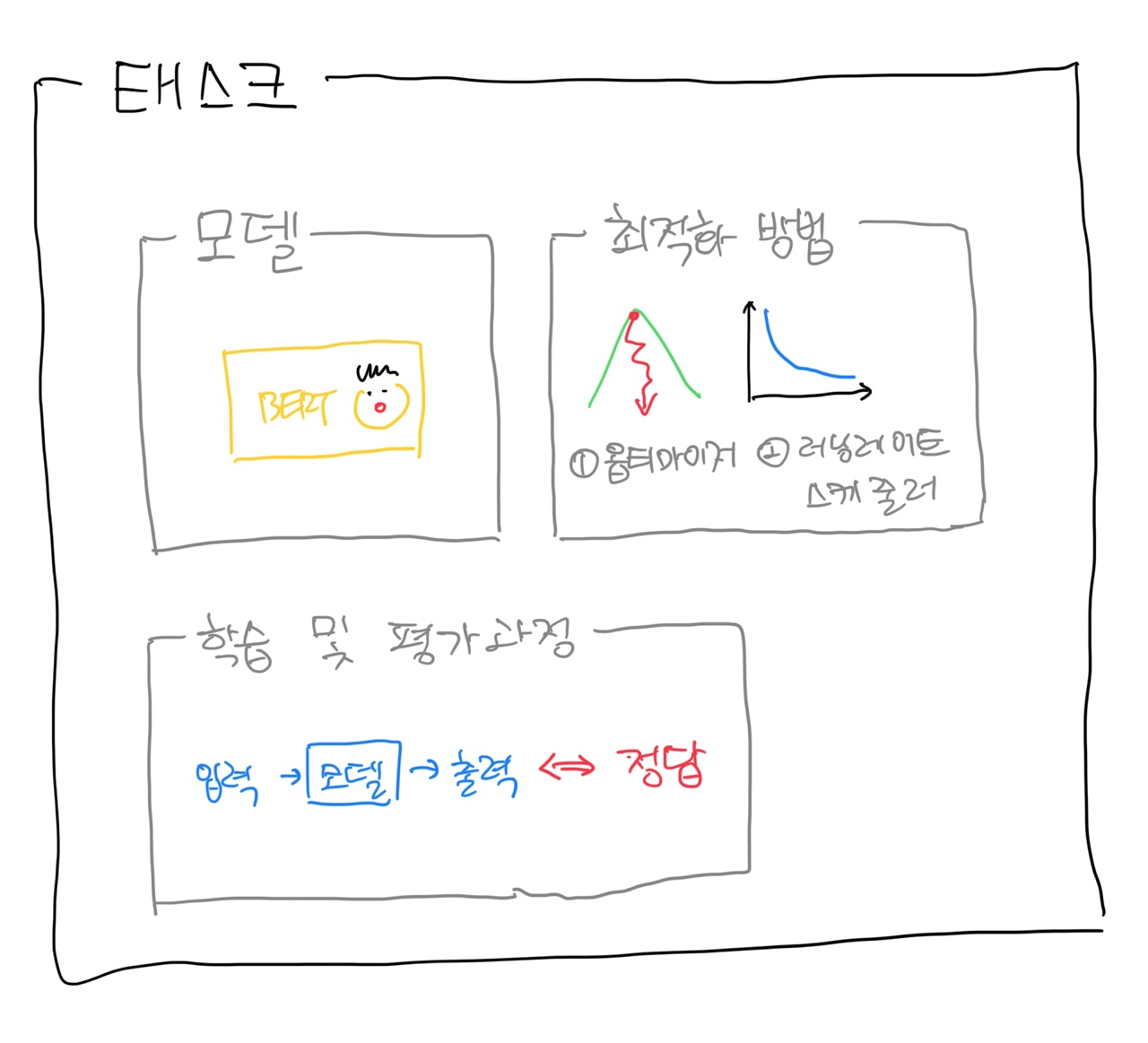
- 태스크 정의하기
- 파이토치 라이트닝(pytorch lighting) 라이브러리
- 딥러닝 모델을 학습할 때 반복적인 내용을 대신 수행해줘 사용자가 모델 구축에만 신경쓸 수 있도록 돕는 라이브러리
- 파이토치 라이트닝이 제공하는 lightning 모듈을 상속받아 task를 정의 → task에는 앞서 준비한 모델과 최적화 방법, 학습 과정 등이 정의되어 있음
- 최적화(optimization)
- 특정 조건에서 어떤 값이 최대나 최소가 되도록 하는 과정
- 모델의 출력과 정답 사이의 차이를 작게 만들기 위해 사용
- 이를 위해 옵티마이저(optimizer), 러닝 레이트 스케쥴러(learning rate scheduler) 등을 정의
- 모델 학습은 '배치 단위'로 이루어짐
- task의 학습 과정은 1회 스텝(step)에서 벌어지는 일을 정의
- 스텝(step): 배치를 모델에 입력한 뒤 모델 출력을 정답과 비교해 차이를 계산하고 그 차이를 최소화하는 방향으로 모델을 업데이트하는 일련의 순환 과정
- 파이토치 라이트닝(pytorch lighting) 라이브러리
- 모델 학습하기
- 트레이너(trainer)
- 파이토치 라이트닝에서 제공하는 객체
- 실제 학습을 수행
- GPU 등 하드웨어 설정, 할습 기록 로깅, 체크포인트 저장 등 복잡한 설정을 알아서 해 줌
- 트레이너(trainer)
GPU(Graphic Processing Unit)
: 그래픽 연산을 빠르게 처리하는 장치
병렬 연산을 잘 해서 딥러닝 모델 학습에 널리 쓰임
cf. TPU(Tensor Processing Unit)
: 텐서 처리 장치
구글에서 발표한 데이터 분석 및 딥러닝용 하드웨어
# 문서 분류 모델 학습
from ratsnlp.nlpbook.classification import ClassificationTask
task = ClassificationTask(model, args)
trainer = nlpbook.get_trainer(args)
trainer.fit(
task
, train_dataloaders=train_dataloader
,
)토큰화: 문장을 작은 단위로 쪼개기
- 토큰화(tokenization): 문장을 토큰 시퀀스로 나누는 과정
- 수행 대상에 따라 세 가지 방법 존재
- 문자
- 단어
- 서브워드
- 트랜스포머 모델은 토큰 시퀀스를 입력받으므로 텍스트 형태의 문장에 토큰화를 수행해 줘야 함
- 토크나이저(tokenizer): 토큰화를 수행하는 프로그램
- 대표적인 한국어 토크나이저: 은전한닢(mecab), 꼬꼬마(kkma) 등
- 언어 전문가들이 토큰화해 놓은 데이터를 학습해 최대한 전문적인 분석 결과와 비슷하게 토큰화를 수행
- 토큰화뿐만 아니라 품사 부착(Part-of-Speech tagging)까지 수행
- 이로 인해 토큰화 개념을 넓은 의미로 해석할 때 '토큰 나누기' + '품사 부착'까지 일컽는 경우도 있음
- 대표적인 한국어 토크나이저: 은전한닢(mecab), 꼬꼬마(kkma) 등
- 토큰화 방식 1: 단어(어절) 단위 토큰화
- 공백으로 분리: 가장 쉬운 방법
- 별도로 토크나이저를 쓰지 않아도 된다는 장점
- 어휘 집합(vocabulary)의 크기가 매우 커질 수 있다는 단점 → '갔었어', '갔었는데요'처럼 표현이 살짝만 바뀌어도 모든 경우의 수가 어휘 집합에 포함되어야 하기 때문
- 학습된 토크나이저를 사용
- 의미있는 단위(갔었)로 토큰화 → 어휘 집합이 급격하게 커지는 것을 다소 막을 수 있음
- 보통 언어 하나로 모델을 구축할 때 어휘 집합 크기는 10만 개를 훌쩍 넘는 경우가 다반사 → 어휘 집합 크기가 커지면 그만큼 모델 학습이 어려워질 수 있음
- 공백으로 분리: 가장 쉬운 방법
- 토큰화 방식 2: 문자 단위 토큰화
- 한글로 표현할 수 있는 글자는 모두 1만 1,172개
- 알파벳, 숫자, 기호 등을 고려해도 어휘 집합 크기가 1만 5,000개를 넘지 않음
- 해당 언어의 모든 문자를 어휘 집합에 포함하여 미등록 토큰 문제로부터 자유로움
- 미등록 토큰(unknown tokens): 어휘 집합에 없는 토큰. 주로 신조어 등에서 발생
- 하지만 각 문자 토큰은 의미 있는 단위가 되기 어렵고 토큰 시퀀스의 길이가 상대적으로 길어짐 → 언어 모델에 입력할 토큰 시퀀스가 길면 모델이 해당 문장을 학습하기 어려워지고 결과적으로 성능이 떨어지게 됨
- 토큰화 방식 3: 서브워드(subword) 단위 토큰화
- 단어와 문자 단위 토큰화의 중간에 있는 형태
- 둘의 장점만 취함
- 어휘 집합 크기가 지나치게 커지지 않으면서도 미등록 토큰 문제를 피하고, 분석된 토큰 시퀀스가 너무 길어지지 않게 함
- 대표적인 서브워드 단위 코튼화 기법: "바이트 페어 인코딩"
- 단어와 문자 단위 토큰화의 중간에 있는 형태
바이트 페어 인코딩(BPE, Byte Pair Encoding)
- 원래는 정보를 압축하는 알고리즘으로 제안되었는데 최근에는 자연어 처리 모델에 널리 쓰이는 토큰화 기법
- GPT 모델은 BPE 기법으로 토큰화 수행함
- BERT 모델은 BPE와 유사한 워드피스(wordpiece)를 토크나이저로 사용
- BPE
- 1994년 제안된 정보 압축 알고리즘
- 데이터에서 가장 많이 등장한 문자열을 병합해 데이터를 압축하는 기술
- 사전 크기 증가를 억제하면서도 정보를 효율적으로 압축할 수 있는 알고리즘
- BPE 기반 토큰화 기법은 말뭉치에서 자주 나타나는 문자열(서브워드)을 토큰으로 분석하기 때문에 분석 대상 언어에 대한 지식이 필요 없음
예시:
데이터aaabdaaabac
↓
BPE는 데이터에 등장한 글자(a,b,c,d)를 초기 사전으로 구성
↓
연속된 두 글자를 한 글자로 병합
ZabdZabac
↓
한 번 더 압축 가능: ab(Za도 가능하지만 둘의 빈도수가 같으므로 알파벳 순으로 앞선 ab를 먼저 병합)
ZYdZYac
↓
ZY 역시 병합 가능: 이미 병합된 문자열 역시 한 번 더 병합할 수 있음
XdXac
- BPE 수행 이전
- 원래 데이터를 표현하기 위한 사전 크기: 4개(a,b,c,d)
- 데이터 길이: 11
- BPE 수행 후
- 사전 크기: 7개(a,b,c,d,Z,Y,X)
- 데이터 길이: 5
- BPE는 사전의 크기를 지나치게 늘리지 않으면서도 데이터 길이를 효율적으로 압축할 수 있음
- BPE를 활용한 토큰화 절차
- 어휘 집합 구축: 자주 등장하는 문자열을 병합하고 이를 어휘 집합에 추가하는 과정을 우너하는 어휘 집합 크기가 될 때까지 반복
- 토큰화: 토큰화 대상 문장의 각 어절에서 어휘 집합에 있는 서브워드가 포함되었을 때 해당 서브워드를 어절에서 분리
BPE 어휘 집합 구축
- 말뭉치 준비
- 말뭉치의 모든 문장을 공백으로 나눈 후 빈도 계산: 프리토크나이즈(pre-tokenize)
- 공백 외 다른 기준도 가능
- 프리토크나이즈 결과 예시
| 토큰 | 빈도 |
|---|---|
| hug | 10 |
| pug | 5 |
| pun | 12 |
| bun | 4 |
| hugs | 5 |
- 초기 어휘 집합(b,g,h,n,p,s,u → BPE를 문자 단위로 수행한 것)으로 다시 작성
| 토큰 | 빈도 |
|---|---|
| h,u,g | 10 |
| p,u,g | 5 |
| p,u,n | 12 |
| b,u,n | 4 |
| h,u,g,s | 5 |
- 토큰을 2개(바이그램; bigram)씩 묶어서 나열
| 토큰 | 빈도 |
|---|---|
| h,u | 10 |
| u,g | 10 |
| p,u | 5 |
| u,g | 5 |
| p,u | 12 |
| u,n | 12 |
| b,u | 4 |
| u,n | 4 |
| h,u | 5 |
| u,g | 5 |
| g,s | 5 |
- 바이그램 쌍이 같은 것끼리 빈도를 합쳐줌
| 토큰 | 빈도 |
|---|---|
| h,u | 15 |
| u,g | 20 |
| p,u | 17 |
| u,n | 16 |
| b,u | 4 |
| g,s | 5 |
- 가장 많이 등장한 바이그램 쌍(u,g)을 합쳐 어휘 집합에 추가: b,g,h,n,p,s,u,
ug
| 토큰 | 빈도 |
|---|---|
| h,ug | 10 |
| p,ug | 5 |
| p,u,n | 12 |
| b,u,n | 4 |
| h,ug,s | 5 |
- 다시 바이그램 쌍 빈도로 나열
| 토큰 | 빈도 |
|---|---|
| b,u | 4 |
| h,ug | 15 |
| p,u | 12 |
| p,ug | 5 |
| u,n | 16 |
| ug,s | 5 |
- 가장 많이 등장한 바이그램 쌍(u,n)을 합쳐 어휘 집합에 추가: b,g,h,n,p,s,u,ug,
un
| 토큰 | 빈도 |
|---|---|
| h,ug | 10 |
| p,ug | 5 |
| p,un | 12 |
| b,un | 4 |
| h,ug,s | 5 |
- 다시 바이그램 쌍 빈도로 나열
| 토큰 | 빈도 |
|---|---|
| b,un | 4 |
| h,ug | 15 |
| p,ug | 5 |
| p,un | 12 |
| ug,s | 5 |
- 가장 많이 등장한 바이그램 쌍(h,ng)을 합쳐 어휘 집합에 추가: b,g,h,n,p,s,u,ug,un,
hug
사용자가 정한 크기가 될 때까지 위 과정을 계속 반복: BPE 어휘 집합은 고빈도 바이그램 쌍을 병합하는 방식으로 구축
- 어휘 집합 구축 결과(b,g,h,n,p,s,u,ug,un,
hug)는vocab.json파일로 저장 - 바이그램 쌍 병합 이력은
merge.txt자료로 만들어 BPE 토큰화 과정에서 서브워드 병합 우선순위를 정하는 데 사용- merge.txt:
u g
u n
h ug
- merge.txt:
BPE 토큰화
