[인공지능사관학교: 자연어분석A반] 텍스트마이닝 (6)
지난 시간 복습
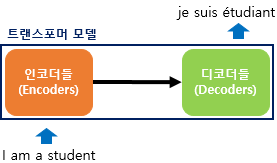
- Transformer
- 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델
- 기존 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현
- RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 번역 성능에서도 RNN보다 우수한 성능을 보임
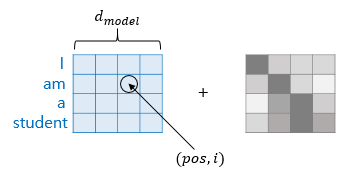
- 포지셔널 인코딩

- 포지셔널 인코딩 값들은 어떤 값이기에 위치 정보를 반영해줄 수 있는 것일까요? sine, cosine 함수
→ 더 알아보기
- 포지셔널 인코딩 값들은 어떤 값이기에 위치 정보를 반영해줄 수 있는 것일까요? sine, cosine 함수
- 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델
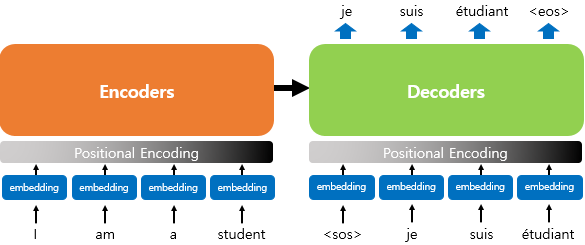
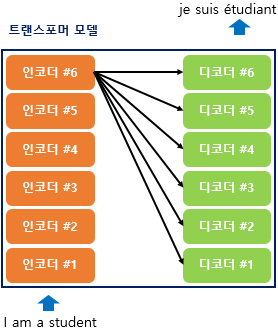
→ 인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는 구조: 디코더는 시작 심볼 <sos>를 입력으로 받아 종료 심볼 <eos>가 나올 때까지 연산을 진행
기존의 seq2seq 모델 → 인코더-디코더 구조로 구성
인코더: 입력 시퀀스를 하나의 벡터 표현으로 압축 / 디코더: 벡터 표현을 통해서 출력 시퀀스를 생성
단점 → 인코더가 입력 시퀀스를 하나의 벡터로 압축하는 과정에서 입력 시퀀스의 정보가 일부 손실된다
이를 보정하기 위해 어텐션을 사용 → 그런데 어텐션을 RNN의 보정을 위한 용도로서 사용하는 것이 아니라 어텐션만으로 인코더와 디코더를 만들어보면 어떨까요? == "Transformar 모델"
※주의: 용어 헷갈리지 말기※ hugging face의 transformers 라이브러리와 Transformer 모델은 서로 다름
- 한국어 언어 모델
- BERT 계열: Encoder 중심 모델
- KoBERT, KoELECTRA
- GPT 계열: Decoder 중심 모델
- KoGPT
- Seq2Seq 계열: Encoder-Decoder 모델
- KoBART
- BERT 계열: Encoder 중심 모델
- 실습: 네이버 영화 리뷰 코퍼스 감성 분석
- 계획
- 감성 분석에 대표적으로 사용되는 KoBERT, KoELECTRA, KoBART 모델 적용
- 영화 리뷰 데이터 전처리 수행
- 데이터 준비 및 전처리
- 결측치 확인: train 5개, test 3개 →
dropna - 한글, 띄어쓰기만 두고 나머지는 삭제: 정규 표현식과 replace 함수 활용
- 공백만 남은 리뷰 삭제 등 →
data[data["document"].str.strip() != '']
- 결측치 확인: train 5개, test 3개 →
- 형태소 분석과 토크나이저 적용
- 한국어 자연어 처리에서 형태소 분석 중요성
- KoNLPy 라이브러리 내 Okt 형태소 분석기 사용
- 토큰화, 어간 추출(추가: 정규화(norm=True)까지 수행하는 것도 좋은 방법)
- 형태소 분석 후 문장 형태로 재조합해 BERT input 형태에 맞춤
- 피클 파일로 전처리 결과를 저장해 재사용
- 전처리 및 토크나이징 과정이 시간 소모적이므로 결과를 피클 파일로 저장해 추후 재사용
- 피클 파일은 데이터프레임, 리스트 등 자료형 구조를 그대로 유지하여 저장 가능
- 이후 학습 시 피클 파일을 불러오면 빠른 데이터 로딩 가능
- 데이터셋 분리
- 데이터 수 제한: 전체 데이터 중 2만 개만 사용해 자원 및 시간 효율화
- 훈련용과 검증용 데이터셋으로 분리
- 허깅페이스 데이터셋 변환
- 판다스 데이터프레임은 허깅페이스 데이터셋 클래스에서 직접 사용이 불가
- 따라서 파이썬 리스트 형태로 변환 후 데이터셋 클래스에 입력해 사용
- Dataset.from_dict({"document": 리스트 형태로 변환한 문서 텍스트", "label": 리스트 형태로 변환한 감성 레이블"
- 데이터셋 크기 및 분할 비율 확인
- 계획
- KoBERT
- KoBERT 모델 개요 및 특징
- 한국어 자연어 모델 처리에 최적화된 BERT 모델
- huggingface 유저인 monologg 님이 만든 모델 사용(
checkpoint = "monologg/kobert") - 한국어 문맥과 의미 파악에 특화된 사전 학습 모델
- 토크나이저 생성
- 모델과 동일한 체크포인트 사용: 모델이 쓴 것과 같은 토크나이저를 사용해야 하기 때문
- 최대 길이(max_length), 패딩(padding), 자르기(truncation) 지정 → 최대 길이보다 짧은 문장은 0으로 패딩, 긴 문장은 지정 길이로 자름
- 학습 파라미터 및 트레이너 구성
- 학습 하이퍼파라미터 설정: 학습률, 배치 크기, 가중치 감쇠 등
- 데이터 콜레이터(Data Collator): 모델에 데이터를 배치(batch) 형태로 전달하기 전에 여러 샘플을 묶어서 전처리(결합, 패딩 등)를 자동으로 해주는 함수 또는 객체 → DataCollatorWithPadding: 배치 내 문장 길이에 맞춰 패딩 처리 수행
- 고정 길이 패딩 vs. 배치 내 최대 길이 패딩
- 배치 내 최대 길이 패딩(WithPadding)은 배치마다 길이가 달라 효율적이나 길이 불일치 문제가 생길 수 있음
- 트레이너 실행 및 학습 과정
- 모델, 데이터셋, 데이터 콜레이터, 학습 인자(학습 파라미터) 등을 묶어 트레이너 객체 생성
- 트레이너의 train() 함수 호출해 학습 진행
- 학습 로그는 온라인 저장소(e.g., wandb)로 기록 가능
- KoBERT 모델 개요 및 특징
데이터 콜레이터(Data Collator)는 모델에 데이터를 배치(batch) 형태로 전달하기 전에 여러 샘플을 묶어서 전처리(결합, 패딩 등)를 자동으로 해주는 함수 또는 객체입니다.
핵심 역할
- 여러 개의 샘플을 하나의 배치로 묶음
예를 들어, 길이가 서로 다른 텍스트 시퀀스들이 있을 때 하나의 배치로 만들기 위해 패딩 등을 적용합니다.- 패딩 자동 처리
NLP에서는 시퀀스 길이가 다르기 때문에 모델에 입력하기 전에 가장 긴 시퀀스에 맞춰 나머지 데이터를pad값으로 채워줍니다.- 특정 입력 포맷(예: 딕셔너리 형태)로 가공
각 샘플에 포함된 토큰, 마스크, 레이블 등 다양한 정보를 올바른 방식으로 배치 단위로 묶어줍니다.- 추가적인 샘플링, 마스킹, 텍스트 변형 등 커스텀 전처리 지원
Masked Language Modeling(MLM)처럼 일부 토큰을 마스킹해야 할 때도 데이터 콜레이터에서 처리할 수 있습니다.실제 예시
DataLoader에서 보통
collate_fn이라는 인자로 사용됩니다.from torch.utils.data import DataLoader dataloader = DataLoader(dataset, batch_size=32, collate_fn=custom_data_collator)
- Transformers 라이브러리에서는
DataCollatorWithPadding,DataCollatorForSeq2Seq등 다양한 데이터 콜레이터 클래스를 제공합니다.- 직접 작성하는 경우도 많고, 기본 collator를 그대로 쓰기도 합니다.
요약
데이터 콜레이터는 배치 구성 전 데이터를 "자동으로 같은 길이와 같은 포맷"으로 묶어주는 역할을 합니다.
이를 통해 서로 다른 길이의 데이터를 자연스럽게 배치화해서, 모델이 쉽게 학습·추론할 수 있도록 만들어줍니다.
DataCollator를 사용하여 배치 내에서 동적 패딩을 할 계획이라면, 토크나이저 호출 시에 tokenize_function에 padding 옵션을 넣지 않아도 됩니다.
이유는 DataCollatorWithPadding이 배치별로 가장 긴 길이에 맞춰 동적으로 패딩을 처리해 주기 때문입니다. 만약 토큰화 단계에서 고정 길이 패딩(max_length로)까지 했다가 DataCollator에서도 패딩을 하게 되면 중복 작업이 되고 효율이 떨어질 수 있습니다.
즉, 추천하는 워크플로우는:
- 토크나이즈 시:
truncation=True,max_length=512만 지정하고,padding은 지정하지 않음 (기본값 False).- DataCollatorWithPadding 사용 시:
배치 사이즈마다 가장 긴 시퀀스 길이에 맞춰 자동 패딩 처리.- 예시:
def tokenize_function(batch): texts = [text.strip() for text in batch["item"]] enc = tokenizer(texts, truncation=True, max_length=512) # padding 옵션 없음 enc["labels"] = [float(label) for label in batch["label"]] return enc from transformers import DataCollatorWithPadding data_collator = DataCollatorWithPadding(tokenizer=tokenizer)이렇게 하면, 데이터로더에
data_collator를 넣을 때마다 적절한 패딩이 동적으로 적용되어 효율적인 배치 구성이 가능합니다.
요약:
토크나이저에 padding 주지 않아도 됨
(DataCollatorWithPadding이 배치별 패딩을 담당함)
→ 이 방법이 Hugging Face Transformer 기반 학습 파이프라인에서 일반적으로 권장되는 방식입니다.
실습: KoELECTRA
- BERT와 비교했을 때 조금 더 좋은 성능을 가짐
- BERT보다 향상된 성능을 보이는 한국어 자연어 처리 모델
- 34GB의 한국어 text 데이터로 학습 진행 → 높은 정확도
- KoELECTRA-Base, KoELECTRA-Small 두 개의 모델을 배포(by monologg)
- Transformers 라이브러리만 설치하면 바로 사용 가능
- 앞선 시간에 '감성 분석' 하면서 이미 사용했었음
- 0.74 정도의 정확도로 다른 모델에 비해 향상된 성능
- 구어체, 사투리 등 다양한 표현에 대한 분류 능력이 우수
분석 순서
- 토큰화: 모델에 맞는 토큰화 도구 사용
- 어떤 토큰화 도구를 써야 하는지 모를 경우
AutoTokenizer를 쓰면 됨
- 어떤 토큰화 도구를 써야 하는지 모를 경우
- 모델 불러오기
- DataCollator
- TrainingArguments
- Trainer
KoBERT와 동일하게 허깅페이스 AutoTokenizer, AutoModelForSequenceClassification 사용
토큰화
# 사용할 모델
checkpoint = "monologg/koelectra-small-v2-discriminator"
# 라이브러리 불러오기: KoELECTRA 모델을 위한 토큰화 작업
from transformers import AutoTokenizer
# 1. KoELECTRA 모델의 토큰화 도구 불러오기 (모델 체크포인트 기반 토크나이저 불러오기)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 1-a. 토큰화 함수 생성: 파라미터는 BERT와 동일하게 설정
# 함수는 데이터셋에 한 줄씩 적용하기 위해 만들었음
def tokenizer_function (example):
return tokenizer(
example["document"] # 데이터셋
, max_length = 128 # 문장의 최대 길이 지정
, padding = "max_length" # 최대 길이보다 짧을 경우 → 0으로 패딩
, truncation = True # 최대 길이보다 길 경우 → 잘라주세요
)
# 1-b. 토큰화 수행 (토크나이저 적용)
train_dataset = train_dataset.map( # map이 인덱싱(한 줄씩 가져옴) 후 토큰화
tokenizer_function
, batched=True
)
val_dataset = val_dataset.map(tokenizer_function, batched=True)- 리뷰 데이터 문장 단위로 토크나이징 수행 (
map함수 활용) - 토크나이징 결과를 데이터셋에 적용하여 모델 입력 형태로 변환
모델 불러오기
from transformers import AutoModelForSequenceClassification
# 2. 모델 불러오기
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)AutoModelForSequenceClassification.from_pretrained()함수로 분류 모델 불러오기- 레이블 수 지정(
num_labels=2)하여 분류 작업에 맞춤
- 레이블 수 지정(
콜레이터, 학습 파라미터, 모델(다운스트림 태스크)
DataCollatorWithPadding
- 한 배치 내의 최대 길이로 패딩
- 만약 위에서 토큰화 함수 생성 시
padding="max_length"로 줬다면 DataCollatorWithPadding 의미가 없음
- 만약 위에서 토큰화 함수 생성 시
- 효율을 보고 싶을 때는 토큰화 함수에서
padding=True로 준 후 collator 사용하기- 토큰화 함수 설정 과정에서
padding=True로 주면 DataCollatorWithPadding에서 각 배치(list)를 모델이 바로 입력(input)할 수 있는 텐서 형태의 딕셔너리로 바꿈: 가장 긴 문장에 맞춰 padding
- 토큰화 함수 설정 과정에서
- Callator 더 알아보기
# 3~5
# 콜레이터, 파라미터, 학습 도구 불러오기
from transformers import DataCollatorWithPadding
from transformers import TrainingArguments
from transformers import Trainer
# 콜레이터
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 학습 파라미터 설정: BERT와 동일하게 사용
training_args = TrainingArguments(
output_dir='./results/koelectra_naver' # ★★★★경로변경 필수★★★★
, learning_rate=2e-5
, weight_decay=0.01
, per_device_train_batch_size=16
, per_device_eval_batch_size=16
, num_train_epochs=1
, eval_strategy="epoch"
, save_strategy="epoch"
, load_best_model_at_end=True
)
# 모델 학습 객체 생성
trainer = Trainer(
model=model # 모델
, args=training_args
, train_dataset=train_dataset
, eval_dataset=val_dataset
, data_collator=data_collator
, # tokenizer는 이미 해서 collater에 묶었기 때문에 생략
)
# 모델 학습
trainer.train()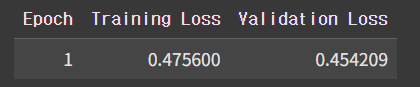
- 학습 인자 및 콜레이터 설정
- 하이퍼 파라미터 설정: 학습률, 배치 크기, 에포크 수 등
- 데이터 콜레이터는 패딩 및 배치 내 데이터 정렬 담당
- output_dir 모델마다 다르게 주는 것 잊지 말기
- 동일 경로로 하면 덮어씌워진다
- 트레이너 객체 생성 및 학습 진행(fine-tuning)
- 모델, 데이터셋, 학습 인자, 데이터 콜레이터를 묶어 트레이너 생성
train()함수 호출로 학습 진행 및 결과 확인wandb설정(API key 입력) 및 학습 과정 모니터링
핵심 개념:
한국어 감성 분석 절차: 데이터 전처리부터 학습까지 with KoBERT, KoELECTRA
핵심 단어:
KoBERT, KoELECTRA, tokenizer, DataCollator, Trainer
- Point
- 네이버 영화 리뷰 데이터 전처리, 형태소 분석 후 피클 파일로 저장 → 효율적 학습 가능
- KoELECTRA에서 사용한 걸 보세요
- 허깅페이스 transformers 라이브러리로 모델 불러와 토크나이저, 데이터 콜레이터, 트레이너 구성 및 학습하기
- KoBERT, KoELECTRA: 학습 과정은 유사하게 진행됨 → 저장 경로만 잘 바꿔주면 된다
- ELECTRA 모델은 BERT 모델 대비 성능 향상
- 학습 데이터 양과 성능 관계
- 데이터가 적으면 epochs를 많이 돌려도 의미가 적음
- 데이터 양을 늘리는 것이 성능 향상에 중요
학습 후 로컬에 저장한 모델 불러서 사용해보기
pipeline사용- 다양한 테스크를 단순하게 수행할 수 있도록 도와주는 기능
- HuggingFace의 from_pretrained() 기능이 로컬 디렉토리에 저장된 모델도 처리할 수 있도록 설계되어 있음
- 로컬에 저장된 모델을 파이프라인으로 불러와 쉽게 사용 가능: 로컬 저장 경로에서 체크포인트까지 포함된 모델 파일 경로 지정하면 됨
- 자동 완성 기능(ctrl+space) 활용해 경로 및 파일명 정확히 지정하기
from transformers import pipeline
my_model = pipeline(
task="text-classification" # 분류 작업: pretrained 모델의 Task를 따라감
, model="./results/koelectra_naver/checkpoint-1000/" # 저장한 모델의 checkpoint까지 들어가기
, tokenizer=tokenizer
)
# 예측할 텍스트
text = "이 영화 정말 재미있어요!"
# 예측 수행
result = my_model(text)
# 결과 출력: result → [{'label': 'LABEL_1', 'score': 0.8494069576263428}]
print(f'예측 레이블: {result[0]["label"].split("_")[1]}')
print(f'예측 정확도: {round(result[0]["score"], 4)}')예측 레이블: 1
예측 정확도: 0.8635- 예측 데이터 입력 및 결과 확인
- 테스트 할 문장을 입력해 예측 수행
- 예측 결과는 레이블과 정확도 형태로 출력됨
- 정확도는 문장 의미에 따라 다소 차이가 있음
- 예측 결과 예쁘게 출력하는 법
- split 활용
- 조건문 활용
text2 = ["스토리도 별로고 재미도 없고", "그냥 그래요"]
# 예측 수행
result2 = my_model(text2)
# 결과 출력
# result2 → [{'label': 'LABEL_0', 'score': 0.8137917518615723}, {'label': 'LABEL_0', 'score': 0.7861501574516296}]
print("첫 번째 문장")
print(f'예측 레이블: {result2[0]["label"].split("_")[1]}')
print(f'예측 정확도: {round(result2[0]["score"], 4)}')
print("\n두 번째 문장")
print(f'예측 레이블: {result2[1]["label"].split("_")[1]}')
print(f'예측 정확도: {round(result2[1]["score"], 4)}')첫 번째 문장
예측 레이블: 0
예측 정확도: 0.8138
두 번째 문장
예측 레이블: 0
예측 정확도: 0.7862KoELECTRA 모델과 KoBERT 모델 비교
- loss 차이는 무엇을 의미할까?
- loss는 실제 값과 예측 값의 차이로, 값이 작을수록 성능이 좋음
- KoBERT 모델과 KoELECTRA 모델의 loss 차이를 통해 성능이 개선된 것을 확인할 수 있음
from transformers import BertTokenizer
checkpoint_kobert = "monologg/kobert"
tokenizer_kobert_ver1 = BertTokenizer.from_pretrained(checkpoint_kobert)
my_model_kobert_ver1 = pipeline(
task="text-classification" # 분류 작업: pretrained 모델의 Task를 따라감
, model="./results/kobert_naver/checkpoint-1000/" # 저장한 모델의 checkpoint까지 들어가기
, tokenizer=tokenizer_kobert_ver1
)
# 예측 수행
result_kobert_ver1 = my_model_kobert_ver1(text)
print(f'예측 레이블: {result_kobert[0]["label"].split("_")[1]}')
print(f'예측 정확도: {round(result_kobert[0]["score"], 4)}')
# 예측 수행
result2_kobert_ver1 = my_model_kobert_ver1(text2)
# 결과 출력
print("첫 번째 문장")
print(f'예측 레이블: {result2_kobert_ver1[0]["label"].split("_")[1]}')
print(f'예측 정확도: {round(result2_kobert_ver1[0]["score"], 4)}')
print("\n두 번째 문장")
print(f'예측 레이블: {result2_kobert_ver1[1]["label"].split("_")[1]}')
print(f'예측 정확도: {round(result2_kobert_ver1[1]["score"], 4)}')Device set to use cuda:0
예측 레이블: 1
예측 정확도: 0.8152
첫 번째 문장
예측 레이블: 1
예측 정확도: 0.5657
두 번째 문장
예측 레이블: 1
예측 정확도: 0.5787# KoBERT vs. KoELECTRA
txt_ls = ["몇 번이고 다시 보고 싶은 감동적인 이야기 다들 빨리 보러 가세요", "감독의 의도를 모르겠다 원작을 전혀 살리지 못했다"]
korbert_out_ver1 = my_model_kobert_ver1(txt_ls) # BertTokenizer
korbert_out = my_model_kobert(txt_ls) # AutoTokenizer → KoBertTokenizer
koelectra_out = my_model_koelectra(txt_ls)
print("KoBERT_ver1")
print("첫 번째 문장")
print(f'예측 레이블: {korbert_out_ver1[0]["label"].split("_")[1]}')
print(f'예측 정확도: {round(korbert_out_ver1[0]["score"], 4)}')
print("\n두 번째 문장")
print(f'예측 레이블: {korbert_out_ver1[1]["label"].split("_")[1]}')
print(f'예측 정확도: {round(korbert_out_ver1[1]["score"], 4)}')
print()
print("KoBERT_ver2")
print("첫 번째 문장")
print(f'예측 레이블: {korbert_out[0]["label"].split("_")[1]}')
print(f'예측 정확도: {round(korbert_out[0]["score"], 4)}')
print("\n두 번째 문장")
print(f'예측 레이블: {korbert_out[1]["label"].split("_")[1]}')
print(f'예측 정확도: {round(korbert_out[1]["score"], 4)}')
print()
print("KoELECTRA")
print("첫 번째 문장")
print(f'예측 레이블: {koelectra_out[0]["label"].split("_")[1]}')
print(f'예측 정확도: {round(koelectra_out[0]["score"], 4)}')
print("\n두 번째 문장")
print(f'예측 레이블: {koelectra_out[1]["label"].split("_")[1]}')
print(f'예측 정확도: {round(koelectra_out[1]["score"], 4)}')KoBERT_ver1
첫 번째 문장
예측 레이블: 1
예측 정확도: 0.7144
두 번째 문장
예측 레이블: 1
예측 정확도: 0.57
KoBERT_ver2
첫 번째 문장
예측 레이블: 1
예측 정확도: 0.8112
두 번째 문장
예측 레이블: 0
예측 정확도: 0.7096
KoELECTRA
첫 번째 문장
예측 레이블: 1
예측 정확도: 0.8216
두 번째 문장
예측 레이블: 0
예측 정확도: 0.7992핵심 개념:
트랜스포머 기반 모델 학습 시 패딩, 콜레이터, 트레이너 구성과 로컬 저장 모델 활용법
핵심 단어:
패딩, 콜레이터, 트레이너, 로스, 파이프라인
- Point:
- 패딩값과 콜레이터 설정을 통한 AutoPadding
- 학습 결과로 나온 loss 값 모델별 비교
- KoELECTRA가 KoBERT보다 성능이 향상됨
- 로컬에 저장된 모델 파이프라인으로 불러오는 법
- 예측 결과 출력 후처리
실습: KoBART
- 2020년 SKT에서 공개한 BART 모델의 한국어 버전
- Seq2Seq 원리를 기반으로 학습 수행
토큰화
- BART 계열 모델은 Transformer 구조와 학습 방식이 다르기 때문에 토큰화 과정도 약간 다름
- 인코더로 들어가서 디코더로 나오는 구조(Seq2Seq) → 토큰화 과정에서 시작 토큰, 끝 토큰을 명확하게 정의해야 학습이 안정적
- 시작과 끝을 명시해 두어야 디코더에서 학습 과정
- Transformer는 Positioning Vector가 있으므로 없어도 학습 가능
- 이미 정확한 위치를 알고 있으니 명시할 이유가 없음
- Transformer는 Positioning Vector가 있으므로 없어도 학습 가능
KoBART의 시작 토큰과 끝 토큰
| 이름 | 의미 | 실제 역할 | 토큰 예시 |
|---|---|---|---|
| BOS | Beginning Of Sentence | 문장의 시작을 알림 | <s> |
| EOS | End Of Sentence | 문장의 끝을 알림 | </s> |
- Seq2Seq 모델에서 시작 토큰과 끝 토큰의 정의와 역할
- KoBART 모델은 Seq2Seq 원리를 기반으로 함 → 인코더, 디코더 구조 사용
- 디코더에 시작 토큰과 끝 토큰을 명확히 지정해야 학습이 안정적으로 진행됨
- 시작 태그, 끝 태그는 HTML 구조에서 데이터의 시작과 끝을 명확히 구분하는 역할을 하며 Seq2Seq 모델에서도 이와 유사한 개념으로 사용됨: 시작 태그는 태그 이름으로 시작, 끝 태그는 슬래시(/)가 붙어 닫는 역할
- HTML 태그 내에 포함된 텍스트를 컨텐츠라고 함: 컨텐츠는 시작 태그와 끝 태그 사이에 위치함
# tranformers: HuggingFace에서 만든 '라이브러리 이름' (Transformer 모델과 관계 없음)
from transformers import AutoTokenizer
# 저장된 파일 불러오기
import pickle
with open("./data/bert_train_data_ratings.pkl", "rb") as f:
train_data = pickle.load(f)
# 앞 1만 개, 뒤 1만 개 추려서 사용
train_data2 = pd.concat([train_data[:10000], train_data[-10000:]], ignore_index=True)
from sklearn.model_selection import train_test_split
from datasets import Dataset # HuggingFace 전용 데이터셋 포맷 변경
# 훈련용:검증용 = 8:2
train_df, val_df = train_test_split(train_data2, test_size=0.2, random_state=1)
# 문제와 정답으로 분리
# Dataset 클래스는 외부 라이브러리인 Pandas 형태를 받지 않음(받아들이지 못함) → 파이썬 리스트로 변환
train_texts = train_df["document"].astype(str).tolist() # pandas.Series → python.list
train_labels = train_df["label"].tolist()
val_texts = val_df["document"].astype(str).tolist()
val_labels = val_df["label"].tolist()
# Hugging Face Dataset으로 변환!
train_dataset = Dataset.from_dict({"document": train_texts, "label": train_labels})
val_dataset = Dataset.from_dict({"document": val_texts, "label": val_labels})
# KoBART 모델 토큰화 도구 불러오기
checkpoint_kobart = "gogamza/kobart-base-v2"
tokenizer_kobart = AutoTokenizer.from_pretrained(checkpoint_kobart)
# 토큰화 함수 전에 "시작 토큰, 끝 토큰" 정의
bos_token = tokenizer_kobart.bos_token or "<s>"
eos_token = tokenizer_kobart.eos_token or "</s>"
# tokenizer.eos_token이 있다면 그 값을 사용하고 없다면 </s> 값을 사용하라는 뜻
# 토큰화 함수 생성
def tokenizer_kobart_function(example):
# 비어있거나 공백뿐인 문장을 [NO TEXT]로 대체: 새로운 데이터 예측 시 들어온 데이터가 비어있을 경우를 대비
cleaned_docs = [] # 시작 토큰과 끝 토큰이 포함된 깨끗한 문장 데이터를 저장하는 리스트
for doc in example["document"]:
if not doc or doc.strip() == "":
doc="[NO TEXT]"
else:
doc=doc.strip()
# 수동으로 시작 토큰, 끝 토큰을 문장에 추가
cleaned_docs.append(f"{bos_token} {doc} {eos_token}") # 반복문을 사용해 원본 데이터에서 문장만 추출해 cleaned_docs에 넣음
# bos_token, eos_token: AutoTokenizer가 로드한 사전 학습 모델에 정의되어 있는 특수 토큰
tokenized = tokenizer_kobart(
cleaned_docs
, padding=True
, truncation=True
, max_length=128
, add_special_tokens=False # 자동으로 시작 코튼(<s>)과 끝 코튼(</s>)을 추가하지 않도록 하기 위해: 우리가 직접 추가했기 때문
, return_tensors="pt" # PyTorch 텐서로 반환
)
# label 추가해주기!
tokenized["label"] = example["label"]
return tokenizedQ. 비어있거나 공백뿐인 문장은 train 데이터 전처리 과정에서 진행했는데 왜 또?
A. 예측 시 들어온 데이터가 비어있을 경우를 대비한 것
- 토크나이저에서 시작 심볼과 끝 심볼이 자동 생성 여부
- 토크나이저 내부에 BOS, EOS 심볼(토큰)이 있으면 자동으로 생성되지만 없으면 수동으로 추자해야 함
- 토크나이서 설정에서 토큰 자동 생성 기능을 끌 수 있음(
add_special_tokens=False)- 이 경우 직접 시작-끝 토큰을 문장에 붙여줘야 함
- 데이터 전처리 및 클린 데이터 생성
- 빈 문장이나 공백으로만 이루어진 문장이 새로 들어올 경우를 대비해
[No Text]로 대체하여 데이터의 일관성을 유지- 문자열 양 끝의 공백을 제거하여 정리된 문자열을 얻고 텍스트가 없는 경우 대체어를 넣는 클렌징 작업 진행
- 수동으로 시작 토큰과 끝 토큰을 추가하는 작업 진행
- 수동 작업을 할 경우 토큰 자동 생성 기능 끄기(
add_special_tokens=False)
- 수동 작업을 할 경우 토큰 자동 생성 기능 끄기(
- 클린 데이터셋에는 시작 토큰과 끝 토큰이 포함되어 있지만 정답(레이블)이 붙어있지 않는 상태이므로 별도로 레이블을 추가해주어야 함
- 빈 문장이나 공백으로만 이루어진 문장이 새로 들어올 경우를 대비해
# 토큰화 수행
train_dataset = train_dataset.map(tokenizer_kobart_function, batched=True)
val_dataset = val_dataset.map(tokenizer_kobart_function, batched=True)모델 불러오기
from transformers import AutoModelForSequenceClassification
model_kobart = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels = 2)파라미터, 콜레이터, 학습 도구
from transformers import TrainingArguments, Trainer
from transformers import DataCollatorWithPadding
# 토큰화 결과에 패딩 수행
data_collator_kobart = DataCollatorWithPadding(tokenizer=tokenizer_kobart)
# 파라미터
training_args_kobart = TrainingArguments(
output_dir='./results/kobart_naver'
, learning_rate=2e-5 # 학습률
, weight_decay=0.01 # 학습률 감쇄: 과적합 방지를 위한 weight → 점수가 잘 안 나올 경우 해당 파라미터 없애도 됨
, per_device_train_batch_size=16 # 훈련/검증 데이터 배치 사이즈
, per_device_eval_batch_size=16
, num_train_epochs=1 # 학습 반복 수
, eval_strategy="epoch" # 검증/저장 시기,주기
, save_strategy="epoch" # 매 에폭(epoch)마다 모델을 저장
, load_best_model_at_end=True # 베스트 모델 저장 여부
)
# 모델 학습 객체 생성
trainer_kobart = Trainer(
model=model_kobart # 모델
, args=training_args_kobart
, train_dataset=train_dataset
, eval_dataset=val_dataset
, data_collator=data_collator_kobart
, # tokenizer는 이미 해서 collater에 묶었기 때문에 생략
)
trainer_kobart.train()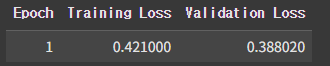
핵심 개념:
Seq2Seq 모델에서 시작 토큰과 끝 토큰은 학습 안정성과 데이터 구분을 위해 필수적으로 명확히 정의해야 함
핵심 단어:
시작 토큰, 끝 토튼, 태그, 데이터 전처리, 토크나이저, 레이블, 모델 로딩
- Point:
- 시작 토큰과 끝 토큰의 정의
- 수동으로 토큰 추가하는 법
- HTML 태그 구조를 통한 시작 토큰, 끝 토큰 이해
- 데이터 내 텍스트 구분 방식
- 토큰화 함수 정의 과정에서 빈 문장 처리 및 클린 데이터셋 생성하는 법
예측
- pipeline 사용 대신 "직접 추론" 수행
- pipeline 사용할 때에는 자동으로 넣어줬지만 직접 추론 시에는 토크나이저를 직접 불러와 input data를 만들어주어야 함
- 동일한 토크나이저를 사용해 일관된 토큰화 진행
- padding, truncation을 True로 설정해 DataCollatorWithPadding이 패딩을 진행할 수 있도록 함
- 경사하강법 및 토치 형태의 결과를 내는 데 사용하기 위해 데이터 리턴 타입을 'pt'로 지정해야 함
- pipeline 사용할 때에는 자동으로 넣어줬지만 직접 추론 시에는 토크나이저를 직접 불러와 input data를 만들어주어야 함
# 모델 불러오기
model_kobart = AutoModelForSequenceClassification.from_pretrained("./results/kobart_naver/checkpoint-1000/")
# 입력 문장: bos, eos 토큰이 붙어야 한다
text = "<s> 이 영화 정말 재미있어요! </s>"
# 토크나이저 설정: 텍스트 토크나이징(배치 형태 유지)
input_kobart = tokenizer_kobart(
text
, padding=True
, truncation=True
, max_length=128
, add_special_tokens=False
, return_tensors="pt" # return tensors를 pytorch 형태로 변환
)
# BERT 계열 모델: token_type_ids → 자동으로 입력에 들어가게 설정되어 있음
# BART 계열 모델: token_type_ids 사용 안 함 → 제거 과정을 거쳐줘야 함
if "token_type_ids" in input_kobart:
del input_kobart["token_type_ids"]
import torch
import torch.nn.functional as F
# 모델 예측
with torch.no_grad():
pred = model_kobart(**input_kobart) # 입력 딕셔너리를 풀어서 함수 인자로 넘기기
# 실제값과 예측값의 차이를 구하기
probs = F.softmax(pred.logits, dim=-1) # gogamza 님의 모델이 다중분류로 설정되어 있어서 (실제로는 이진분류지만) 소프트맥스 써야 함
# 결과 확인: 확률의 최댓값을 추출
pred_label = torch.argmax(probs, dim=-1).item()
# 정확도
confidence = probs[0, pred_label].item()
print(f"예측 결과: {pred_label}")
print(f"정확도: {confidence:.4f}")예측 결과: 1
정확도: 0.9856- BERT 모델은 인코더만 사용하는 구조로 토큰 타입 아이디(token_type_ids)가 자동으로 입력에 들어가게 설정되어 있음
- BART 모델은 인코더와 디코더 모두 사용하므로 토큰 타입 아이디(token_type_ids)가 필요 없음 → 토큰 타입 아이디 자동 입력을 제거햐 주어야 함:
if "token_type_ids" in input_kobart:
del input_kobart["token_type_ids"]- 모델 예측 및 loss 계산, 평가 지표 산출
- 실제값과 예측값 차이 계산을 위해 torch.nn.functional import하기
- 출력층 활성화 함수로 소프트맥스(softmax) 사용
- 모델의 출력값에 소프트맥스를 적용하여 활률값 계산
- 확률값 중 최댓값 추출 및 정확도 계산
argmax()를 사용해 최대 확률을 가진 클래스 선택- 정확도(accuracy)와 신뢰도(confidence, 컨피던스) 계산 및 저장
- BART 모델은 input_ids 등의 입력 토큰 텐서를 반드시 받아야 함
- BART는
input_ids,attention_mask가 기본 입력이며,decoder_input_ids등은 자동으로 내부에서 처리합니다. input_ids없이 모델 호출하면ValueError가 발생합니다.
- BART는
- KoBART와 KoELECTRA 모델 특징 및 활용
- KoBART는 Seq2Seq 구조로 토크나이저 사용 시 시작 토큰(BOS)과 끝 토큰(EOS)을 명시적으로 추가해야 함
- ELECTRA 모델은 최근 가장 많이 사용되는 자연어 처리 모델
- 모델별 입력 데이터 처리 방식과 토크나이저 설정 차이를 명확하게 인지하는 것이 중요
- 학습 및 추론 과정에서 파이프라인을 사용할 때와 직접 추론 시 차이점 이해하기
- 직접 추론할 경우 파이프라인에서 자동 처리되는 부분을 직접 구현해야 함
실습: 뉴스 카테고리 분류
학습 목표
- HuggingFace 내에 업로드되어 있는 모델들을 활용하여 파인 튜닝(fine-tuning)
파인 튜닝(fine-tuning)
- 사전 학습된 대규모 언어 모델(LLM)을 특정 작업이나 특정 도메인에 맞게 미세 조정(추가 학습)하는 기법(과정)
- LLM이 특정 작업에서 성능을 최적화하기 위해 추가 학습을 진행
- 기존 학습된 모델은 일반적인 문제나 데이터에 최적화되어 있음 → 특정 데이터에 맞춰 재학습
이전까지는 사전 학습된 모델을 활용하는 정도 수준이었지만
앞으로는 직접 데이터로 학습하는 파인 튜닝 실습을 진행할 예정
앞으로 진행할 실습 종류 (특정 작업)
- 문서 카테고리 분류: 뉴스 카테고리 분류
- 토큰 분류: 개체명 인식
- 질의응답
- RAG 기술
- 인과적 언어 모델링
- 마스킹된 언어 모델링
- 번역
- 요약
- 객관식 문제
뉴스 카테고리 분류
- KLUE / YNAT 데이터셋 사용
- 연합뉴스 데이터셋
- 뉴스 제목을 학습하여 카테고리 분류
from datasets import load_dataset
# 연합뉴스 데이터셋 불러오기
klue_train = load_dataset("klue", "ynat", split="train")
klue_eval = load_dataset("klue", "ynat", split="validation")
klue_train[0]{'guid': 'ynat-v1_train_00000',
'title': '유튜브 내달 2일까지 크리에이터 지원 공간 운영',
'label': 3,
'url': 'https://news.naver.com/main/read.nhn?mode=LS2D&mid=shm&sid1=105&sid2=227&oid=001&aid=0008508947',
'date': '2016.06.30. 오전 10:36'}- features
- guid: 데이터 식별자
- title: 뉴스 제목 데이터
- label: 카테고리(정답 데이터)
- url: 뉴스 url
- date: 날짜
- title, label만 사용
# 실습에 사용하지 않는 불필요한 컬럼 제거
klue_train = klue_train.remove_columns(["guid", "url", "date"])
klue_eval = klue_eval.remove_columns(["guid", "url", "date"])
# 카테고리 내용 확인
klue_train.features["label"]ClassLabel(names=['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치'])✅ 카테고리 (label)
| 숫자 라벨 | 문자형 라벨 |
|---|---|
| 0 | IT과학 |
| 1 | 경제 |
| 2 | 사회 |
| 3 | 생활문화 |
| 4 | 세계 |
| 5 | 스포츠 |
| 6 | 정치 |
- 사람이 보기 쉽도록 'label_str' 컬럼 추가
klue_label = klue_train.features["label"]
# 숫자로 된 label 값을 해당 문자열로 변환하여 새로운 컬럼 label_str 저장
def make_str_label(data):
data["label_str"] = klue_label.int2str(data["label"])
return data
klue_train = klue_train.map(make_str_label, batched=True, batch_size=1000)
klue_eval = klue_eval.map(make_str_label, batched=True, batch_size=1000)
klue_train[0]{'title': '유튜브 내달 2일까지 크리에이터 지원 공간 운영', 'label': 3, 'label_str': '생활문화'}# 학습용/검증용/평가용 데이터셋 분할
# 학습용에서 10000개 → test 용으로 사용하자!
train_dataset = klue_train.train_test_split(test_size=10000, shuffle=True, seed=4)["train"]
# klue_train, klue_test = klue_train.train_test_split(test_size=10000, shuffle=True, seed=42).values()
split_eval = klue_eval.train_test_split(test_size=1000, shuffle=True, seed=4)
split_evalDatasetDict({
train: Dataset({
features: ['title', 'label', 'label_str'],
num_rows: 8107
})
test: Dataset({
features: ['title', 'label', 'label_str'],
num_rows: 1000
})
})- sklearn.model_selection에서 안 가져와도 train_test_split 가능
- 대신 파라미터 이름이 약간 다름: random_state → seed
valid_dataset = split_eval["train"]
test_dataset = split_eval["test"]- klue_train에서 분리한 10,000개는 일단 보류
핵심 개념:
파인튜닝은 사전 학습된 언어 모델을 특정 도메인과 작업에 맞게 추가 학습하는 과정
핵심 단어:
파인튜닝, 트랜스포머 모델, 뉴스 카테고리 분류, 허깅페이스
- Point:
- 앞으로 진행될 자연어 처리 실습 with 트랜스포머 모델
- 뉴스 카테고리 분류를 위한 데이터셋 준비 및 데이터 전처리
- 허깅페이스 라이브러리를 이용한 파인튜닝 실습
하루 돌아보기
👍 잘한 점
- 코드 이해 안 가는 부분 질문
- 잘못 적으신 게 맞아서 수정해주셨음
👎 아쉬웠던 점
- 모델을 이것저것 배우다 보니 좀 헷갈림
- KoBART 모델에서 warning message가 뜨는데 이게 신경쓰여서 시간을 좀 많이 소모했음
- 토크나이저 설정과 모델 로딩 시 레이블 수 불일치 메시지가 출력되는 현상
- 분명히 num_labels=2로 설정되어 있고 id2label, label2id 모두 2개인데 왜 계속 3개를 넣었다고 하는 걸까?
- 결국 해결은 못하고 시간만 썼다…
🔬 개선점
- 안 되는 일에 너무 집착하지 말자
