오늘 QCC 3번 문제를 처음에는 JOIN으로 접근했었는데 CTE로 풀 때와 어떤 점에서 차이가 있는지 궁금해서 준수 튜터님께 여쭤봤더니 JOIN은 JOIN KEY를 찾는 과정이 들어가서 더 느리고 대용량의 데이터를 다루게 되면 이 차이가 크게 느껴진다고 하셨다.
이 부분에 대해 추가로 공부하고 싶어서 검색하다
좋은 내용 1, 2 및 윈도우 함수 개론을 찾아서 핵심만 정리해보았다!
Avoiding self joins and join on operations
Replacing self joins with unbounded or n-bounded partitioned windows
- example data perimeter
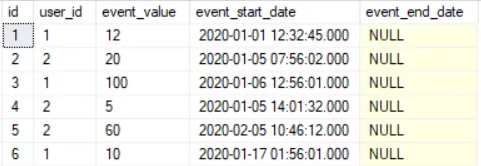
SELF-JOIN
select
ul.id
,ul.user_id
,ul.event_start_date
,coalesce(min(ul_old.event_start_date), '99990101') event_end
from
user_log ul
left join
user_log ul_old
on
ul.event_start_date < ul_old.event_start_date
and
ul.user_id = ul_old.user_id
group by
ul.id
,ul.user_id
,ul.event_start_date-
The result of using a self-join to fill in the missing end date
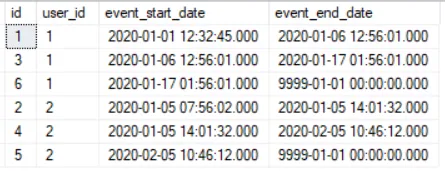
-
Self-join stats
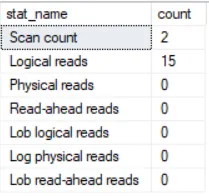
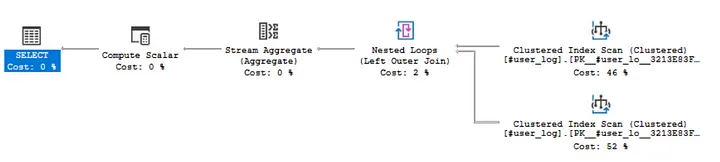
-
Execution plan using a self join
windowed LEAD term
select
id
,user_id
,event_start_date
,lead(event_start_date, 1, '99990101') over (partition by user_id
order by event_start_date asc) event_end_date
from
users_log-
The result of replicating the self-join using a LEAD windowed term

- The result is the same, although the row order has been modified
-
Stats of using a windowed function
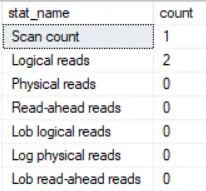
-
Execution plan using a windowed function

Using a windowed function resulted not only in a cleaner and more succinct code but in significant performance improvements as well. Notice the absence of a loop in the windowed version’s execution plan, a critical aspect of performance.
unbounded partitioned windows
Unbounded window functions allow a partition to consist of all records immediately preceding or following a given record, typically the current record and apply an aggregating function to all those records.
→ 용어에 대한 더 자세한 내용은 아래 '윈도우 함수 개론' 참고!
- Visual representation of an unbounded frame
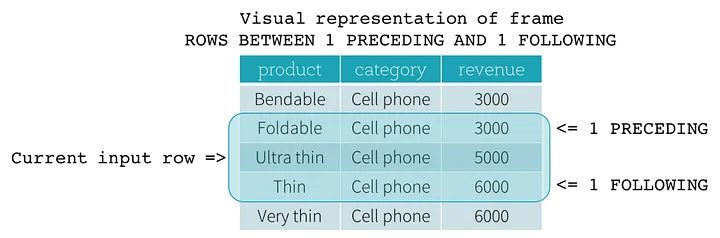
- rows between 1 preceding and 1 following
select
id
,user_id
,event_start_date
,max(event_start_date) over (partition by user_id order by
event_start_date rows BETWEEN 1 following and UNBOUNDED
following) last_event_date
from
#user_log;-
The results
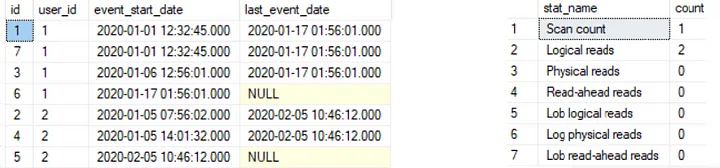
-
The execution plan of the last event date partition window

How about if we want to sum the event value in the preceding and following 2 records?
select
id
,user_id
,event_start_date
,sum(event_value) over (partition by user_id order by
event_start_date rows BETWEEN 2 preceding and 2 following)
last_event_date
from
#user_log;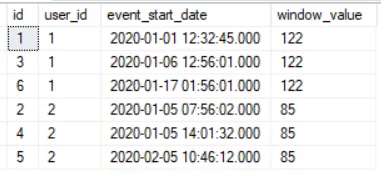
- using a windowed function to sum 5 row’s values
- 2 preceding, the current and 2 following records
Avoiding using operations and functions on joins
-
A fictional generated users table
-
CASE 1: only selecting the name column
select name from users where trim(name) = 'Kaseem Moses'- trimming the user name considering the IT department incorrectly inserted some spaces
- The execution plan for a trimmed operation selection

Notice that despite not being able to directly find Kaseem Moses, it still managed to select and scan the NIX_users_name index and applying the trimming operation.
-
CASE 2: all fields are selected
select * from users where trim(name) = 'Kaseem Moses'- The execution plan for a trimmed operation full selection

Notice how the SQL Server stopped being able to use the nonclustered index. Although in both cases the query estimated 163 results, it actually returned 1 row. It clearly overestimated the resultset, resulting in it thinking the lookup keys would perform poorly, relying on the primary key instead.
- The execution plan for a trimmed operation full selection
To sum up
- The heavy workload of the self-join cardinality can sometimes be avoided by using windowed functions;
- Aggregating functions can be combined with the bounding terms effectively allowing creating a narrower, uni, or bi-directional partition window;
- The bounding terms apply the aggregating function to the entirety of the partition;
- Whenever possible, avoid using functions or operations to join clauses as they can cause indexes to not be properly selected;
추가로 읽어보면 좋을 내용
Performance comparison between using Join and Window function to get lead and lag values
How to Use MySQL LEAD and LAG Analytical Functions
- LEAD and LAG functions
- powerful analytical tools
- good for analyzing time series data, detecting patterns, and improving querying capabilities → can extract valuable insights from large datasets
Understanding Window Functions in MySQL
- Window functions
- perform calculations across a set of rows that are related to the current row
- can be incredibly useful when working with large datasets
- can help simplify complex queries
function_name() OVER (
[PARTITION BY partition_expression, ... ]
[ORDER BY order_expression [ASC|DESC], ... ]
[ROWS frame_specification]
)function_name
- can be any aggregate function
(집계함수)- such as SUM, AVG, COUNT, MIN, or MAX
OVER
- 앞의 함수를 보조하여 섬세한 그룹핑을 지원하면서도 구문은 더 간단하게 만들어 주는 축약형
집계함수() OVER(PARTITION BY 그룹핑 기준 ORDER BY 정렬기준 ROWS | RANGE)- OVER 안에 상세 옵션이 들어가며 필요 없으면 생략 가능
- 아무 옵션 없이 빈 괄호만 적으면 전체 행을 대상으로 집계하라는 뜻
- PARTITION BY 절
- GROUP BY와 유사한 그룹핑을 수행
- ORDER BY 절
- 통계를 낼 정렬 순서를 지정
- OVER 안에 ORDERY BY 절을 사용하면 정렬을 수행하면서 집계를 계산
(정렬을 지정하여 집계를 낼 범위와 순서를 통제)
- frame절
- 더 정밀한 범위를 지정할 때
- frame은 현재 파티션의 하위 집합이며 frame절은 하위 집합을 정의하는 방법을 지정
더 알아보기: WINDOWING FRAME CLAUSE
- 전체 결과셋의 일부만 들여다본다고 해서 윈도우 절이라 함
SELECT
FROM TABLE
WINDOW w AS (PARTITION BY mo_num
{ORDER BY column} [ROWS|RANGE]
BETWEEN [UNBOUNDED PRECEDING|expr PRECEDING|expr FOLLOWING|CURRENT ROW]
AND [UNBOUNDED FOLLOWING|expr PRECEDING|expr FOLLOWING|CURRENT ROW]);- start와 end
- 행 범위를 지정하여 집계를 뽑을 정확한 범위를 기술
- 앞뒤 순서를 결정하려면 정렬부터 해야 하므로 ORDER BY 절이 있어야 함
- 각각 다음 세 가지 종류를 지정할 수 있음
https://dev.mysql.com/doc/refman/8.4/en/window-functions-frames.html
https://thinpig-data.tistory.com/entry/%EC%88%9C%EC%9C%84%EC%97%90-%EB%8C%80%ED%95%B4-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90-feat-OVER-RANK-ROWNUMBER
https://www.devart.com/dbforge/mysql/studio/mysql-lead-and-lag-analytical-functions.html
https://yji7.tistory.com/22
cf. 기존 집계 구문(집계 함수 + GROUP BY)
→ 은근히 제약이 많아 복잡한 집계를 내는 데 한계가 있음
예시
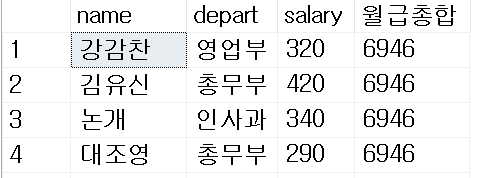
- 만들고 싶은 모양
쿼리 1: 에러(말이 안 되는 쿼리)
/* 공존할 수 없는 필드와 집계함수로 에러가 뜨는 쿼리다. */
SELECT name, depart, salary, SUM(salary) FROM tStaff;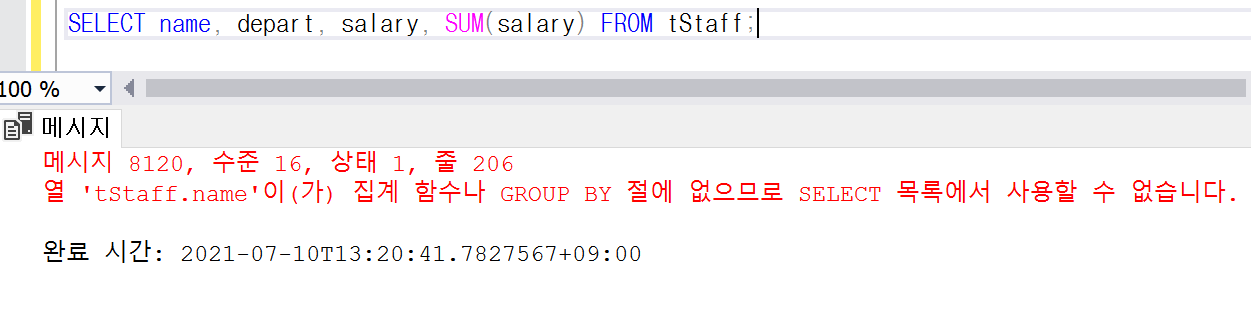
쿼리 2: GROUP BY를 쓰긴 했지만 필드 기준이라 원하는 결과가 아님
/* 에러가 뜨지 않지만 원하는 결과는 뽑을 수 없다. */
SELECT depart, SUM(salary) FROM tStaff GROUP BY depart;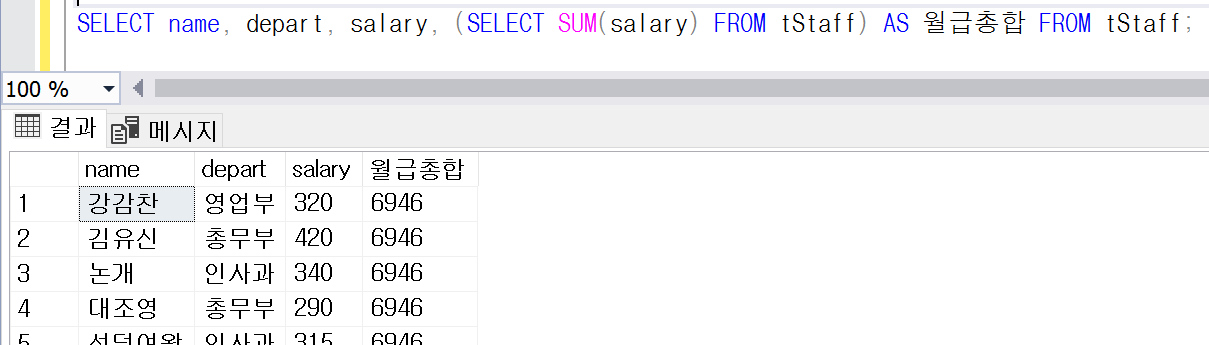
쿼리 3: 서브쿼리를 이용해 출력에 성공했지만 복잡함
/* 서브쿼리를 활용하면 원하는 결과를 볼 수 있다. */
SELECT name, depart, salary, (SELECT SUM(salary) FROM tStaff) AS 월급총합 FROM tStaff;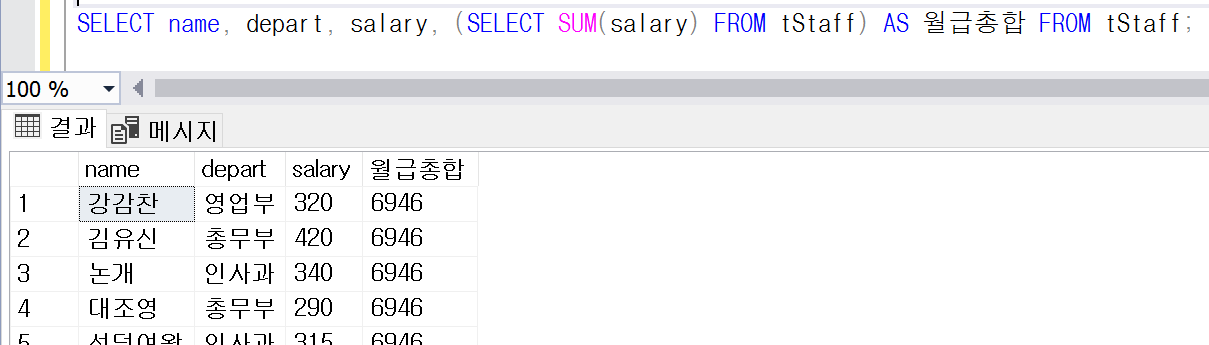
쿼리 4: OVER()를 쓰면 이렇게 쉬워짐
/* OVER()를 사용하면 복잡한 서브쿼리 없이도 동일한 결과를 출력할 수 있다. */
SELECT name, depart, salary, SUM(salary) OVER() AS 월급총합 FROM tStaff;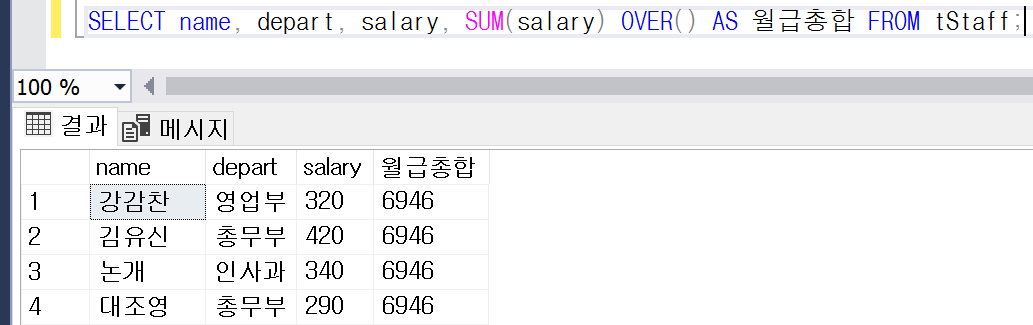
윈도우 함수 개론
