코딩테스트 연습
알고리즘
# ver 1
def solution(n):
isPrime = [False, False]+[True for i in range(2, n+1)]
for i in range(2, int(n**0.5)+1):
if isPrime[i] == True:
j = 2
while i*j <= n:
isPrime[i*j] = False
j += 1
return len([i for i in range(2, n+1) if isPrime[i]])
# ver2
def solution(n):
if n < 2:
return 0
is_prime = [False, False] + [True] * (n-1)
for i in range(2, int(n**0.5)+1):
if is_prime[i]:
for j in range(i*i, n+1, i):
is_prime[j] = False
return sum(is_prime)- 참고: Fastest Algorithm to Find Prime Numbers
- 에라토스테네스의 체
① 2부터 N까지의 모든 자연수를 나열한다.
② 남은 수 중에서 아직 처리하지 않은 가장 작은 수 i를 찾는다.
③ 남은 수 중에서 i의 배수를 모두 제거한다.(i는 제거하지 않는다.)
④ 더 이상 반복할 수 없을 때까지 2번과 3번의 과정을 반복한다.
※ N이 1,000,000 이내로 주어지는 경우 활용 → 이론상 400만번 정도 연산이고 메모리도 충분함
- 에라토스테네스의 체
-
set을 이용한 풀이도 가능
def solution(n): num=set(range(2,n+1)) for i in range(2,n+1): if i in num: num-=set(range(2*i,n+1,i)) return len(num)-
개선점 1: 반복 범위와 차집합 범위 최적화
- 소수 판별의 효율성을 위해, 에라토스테네스의 체는 sqrt(n)까지만 반복해도 충분
- 이미 i의 배수 중
i*i미만의 값들은 이전 반복에서 이미 제거되었으므로,i*i부터 시작하는 것이 효율적
def solution(n): num = set(range(2, n+1)) for i in range(2, int(n**0.5)+1): if i in num: num -= set(range(i*i, n+1, i)) return len(num) -
개선점 2: 홀수만 사용하여 효율성 향상
- 2를 제외한 모든 짝수는 소수가 아니므로, 3부터 시작해서 2씩 증가하는 수만 집합에 넣으면 메모리와 연산이 감소
- 반복도 3부터 시작해서 홀수만 체크하면 됨
def solution(n): if n < 2: return 0 num = set(range(3, n+1, 2)) num.add(2) for i in range(3, int(n**0.5)+1, 2): if i in num: num -= set(range(i*i, n+1, i)) return len(num) -
개선점 3: 집합 대신 리스트(에라토스테네스의 체 표준 구현) 사용 → 내가 쓴 방식
- 집합(set) 연산은 매번 전체 집합을 읽으므로 비효율적
- 리스트를 사용해 소수 여부를 0/1로 표시하면 훨씬 빠르고 메모리도 적게 든다.
- 반복 범위 역시
int(n**0.5)+1까지만 - 에라토스테네스의 체의 표준 구현이며, 가장 빠르고 효율적
-
SQL
1050. Actors and Directors Who Cooperated At Least Three Times
SELECT
actor_id
, director_id
FROM
ActorDirector
GROUP BY
actor_id
, director_id
HAVING
COUNT(*) > 2
;- 아래와 같이 작성해도 OK
select actor_id, director_id
from actordirector
group by 1, 2
having count(1) >= 3;지난 시간 복습
- 상관분석
- 두 변수 간 선형 관계 분석
- 두 변수는 서로 독립적인 관계(0) 또는 상관 관계일 수 있음
주의:
두 변수 간에 인과관계가 있다면 반드시 상관이 있지만, 상관이 있다고 해서 언제나 인과관계가 성립하는 것은 아닙니다.
- 상관계수 r
- -1 ~ 1 사이의 값
- 음의 상관관계: 부負의 선형관계(x축 증가에 따른 y축 감소)
- 0: 상관관계 없음(선형 관계 없음)
- 양의 상관관계: 정正의 선형관계
- 상관계수가 클수록 두 변수 사이에 직선적 관계가 강하다는 것을 의미
- r=1: 완전한 양의 상관관계 또는 완전정상관(perfect positive linear correlation)
- r=-1: 완전한 음의 상관관계 또는 완전부상관(perfect negative linear correction)
- -1 ~ 1 사이의 값
train_test_split- 데이터 분할 도구
- 랜덤 샘플링 기능이 있어 결과의 일관성 유지를 위해 random_state 설정
- label class를 최대한 균등하게 나누기 위해 stratify 설성
-
KNN
- 유유상종
- 거리 계산을 하는 모델!
- 유클리디언 거리 계산 공식 사용
- 장점
- 쉬움
- 단점
- 이웃의 수가 많아지면 시간 오래 걸림
- 분류와 회귀 모두 가능
- 분류(KNeighborsClassifier): 클래스 다수결로 결정
- 회귀(KNeighborsRegressor): 이웃한 label의 평균값을 정답으로 가져감
-
모델 평가: 정확도(accuracy)
- 분류 모델 평가지표 → 정확도
- 0 ~ 1 사이의 숫자
- 1에 가까울수록 높은 성능
- 분류 모델 평가지표 → 정확도
- 모델 평가 방법
sklearn.metrics>accuracy_scoreaccuracy_score(y_test, y_pred)형태.metrics: 평가지표 모음y_pred=model.predict(X_test)
- 모델변수명.score
model.score(평가용 문제, 평가용 정답)
- 과대적합/과소적합/모델 복잡도 곡선
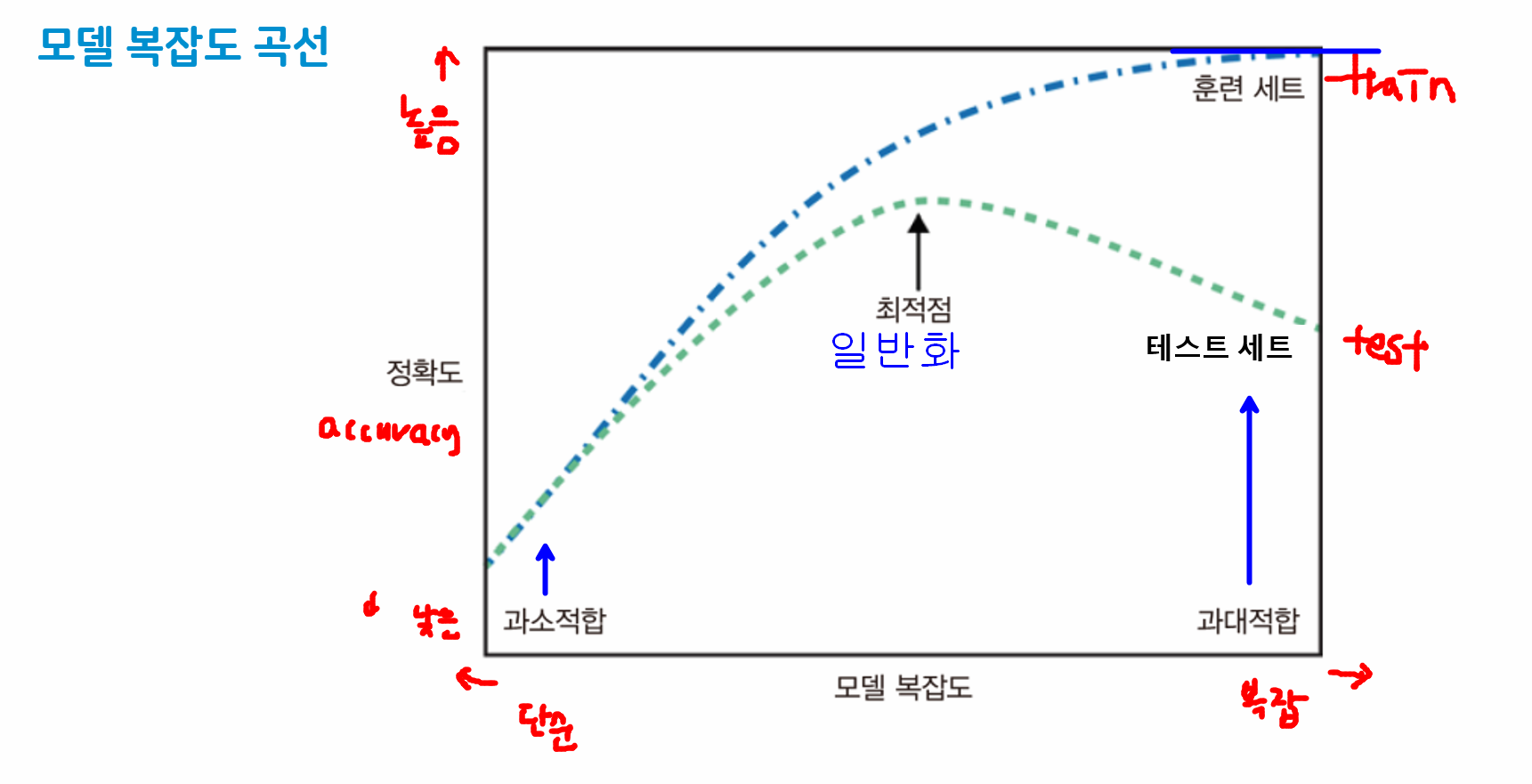
- 의사결정나무
- 장점
- 눈에 잘 보임
- 불순도를 나누는 컬럼 확인 가능
- 단점
- 과대적합이 발생하기 쉬움
- 시각화
- 장점
# 트리모델 시각화
plt.rc('font', family='NanumBarunGothic') # 한글 설정
from sklearn.tree import plot_tree
plot_tree(dt_model, # 모델 이름
feature_names = X_train.columns, # 컬럼 이름 -> 입력 특성
class_names = ['불쾌','상쾌'], #0 - 불쾌, 1 - 상쾌 / 클래스명 지정
fontsize =8,
filled=True)
plt.show()titanic 데이터를 활용하여 생존자 예측 모델 만들기
- Kaggle 타이타닉 데이터 활용
- Kaggle: ML과 데이터 분석 관련 커뮤니티
- train.csv, test.csv, gender_submission.csv
- tarin.csv: X_train, y_train
- test.csv: X_test
- gender_submission.csv: a set of predictions that assume all and only female passengers survive(accuracy=0.76555)
학습 목표
- 타이타닉 데이터를 학습하여 생존, 사망을 예측하는 모델 생성
- 머신러닝 전체 과정 중 전처리에 집중
- kaggle 경진대회에서 높은 순위를 차지해보기
1. 문제 정의
- 타이타닉 데이터를 학습하여 생존자, 사망자 예측
- 정확한 전처리 방법 학습
2. 데이터 수집
- kaggle 사이트에서 데이터 다운로드
- 데이터를 읽어올 때 PassengerId를 인덱스로 설정하여 읽어오기
# 데이터 읽어오기~
# train, test 변수에 담아주기(인덱스 설정: PassengerId)
# 1. 구글 마운트
# 2. 현재 파일의 위치 변경
%cd /content/drive/MyDrive/Colab Notebooks/MachineLearning
# 3. 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns # 시각화 라이브러리 (색감, 그래프 종류가 다양)
# 4. train, test 변수에 담아주기(인덱스 설정: PassengerId)
train = pd.read_csv("./data/titanic/train.csv", index_col="PassengerId")
test = pd.read_csv("./data/titanic/test.csv", index_col="PassengerId")타이타닉 데이터 컬럼 설명 (Titanic Dataset Column Description)
| 컬럼명 | 설명 |
|---|---|
PassengerId | 승객 고유 ID |
Survived | 생존 여부 (0 = 사망, 1 = 생존) ← 예측 대상 변수(Target) |
Pclass | 좌석 등급 (1 = 1등석, 2 = 2등석, 3 = 3등석) |
Name | 승객 이름 (이름, 호칭 포함) |
Sex | 성별 (male, female) |
Age | 나이 (일부 결측치 존재) |
SibSp | 함께 탑승한 형제 또는 배우자 수 (Siblings/Spouses Aboard) |
Parch | 함께 탑승한 부모 또는 자녀 수 (Parents/Children Aboard) |
Ticket | 티켓 번호 |
Fare | 운임 요금 |
Cabin | 객실 번호 (결측치 다수 존재) |
Embarked | 탑승한 항구 (C = Cherbourg, Q = Queenstown, S = Southampton) |
# 데이터 크기 확인
train.shape, test.shape
# 학습: 891명 정보, 생존 여부가 포함
# 평가: 418명 정보
# 데이터에 대한 정보 확인
train.info()
test.info()
# 결측치 여부, Dtype 확인
# 결측치가 있는 컬럼을 확인하여 어떤 방법으로 결측치를 제거할 지 확인
# 머신러닝 -> 문자열 학습 XX -> 수치 데이터로 변경하는 작업 필수! ⭐- 결측치가 존재하는 컬럼
- train: Age(나이), Cabin(객실번호), Embarked(탑승항구)
- test: Age(나이), Fare(요금), Cabin(객실번호)
- 목표
- 단순 기술통계치로 결측치를 채우지 않고, 컬럼의 특성과 상관관계를 확인하여 결측치를 채워보자!
# 나이 데이터 기술통계량 확인
train["Age"].describe()
# 714개 데이터
# 평균 약 29.7, 중위수 28
# 앞쪽으로 쏠려있는 데이터구나~ (노년층에 비해 젊은층이 많이 탑승)
# Cabin 기술통계량 -> 문자열 데이터의 특성으로 통계량 추출
train["Cabin"].describe()
# count: 데이터의 개수
# unique: 중복되지 않은 유일한 값 -> 147개의 다른 값들이 존재
# freq: 빈도수 -> 겹치는 값
# top: G6 방에 4명이 있다(freq가 4인 cabin이 랜덤하게 나옴)
# 상관계수 확인
train.corr(numeric_only=True)3. 데이터 전처리
전처리를 위해 EDA와 전처리를 번갈아가며 진행
Age column 처리
- train -> Age 컬럼의 결측치를 채워보자!
- 나이 데이터? 평균으로 채우는 것이 일반적
- 하지만 나이 데이터 기술통계량을 확인했을 때 앞쪽으로 치우쳐 있던 것을 앞에서 확인함
- 단순 평균으로 채우는 것이 아니라 상관관계를 활용하여 의미 있는 값으로 결측치를 채워보기
- 나이 데이터? 평균으로 채우는 것이 일반적
# 상관계수 확인
train.corr(numeric_only=True)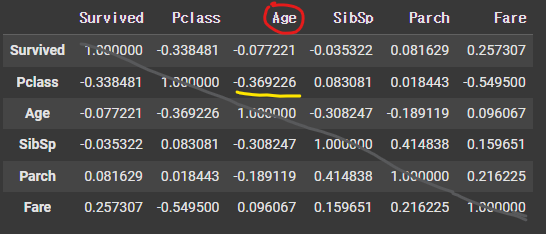
# 특정 컬럼에 영향을 많이 미치는 컬럼 확인 시 절댓값 변경 후 내림차순 정렬
["Age"].abs().sort_values(ascending=False)
# Pclass 컬럼이 Age 컬럼과 상관관계가 가장 높음을 확인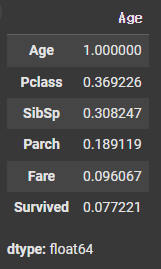
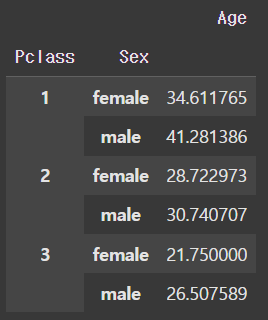
- Age 데이터(컬럼)와 가장 높은 상관관계를 가지는 Pclass 컬럼을 활용
- Sex 데이터와 Pclass 데이터를 함께 사용하여 Age 결측치를 채우기
- 데이터 요약표: pivot table(피벗 테이블)
# 피벗 테이블 -> 데이터의 요약표
pt1 = train.pivot_table(
values = "Age" # 출력할 데이터로 사용할 컬럼
, aggfunc="mean" # 그룹화 결과로 출력할 함수
# sum, mean, count 등 함수 사용 가능
, index = ["Pclass", "Sex"]
# 데이터 요약시 함께 사용할 컬럼
)
-
멀티 인덱싱(다중 인덱싱)을 통해 원하는 데이터 추출
- 멀티 인덱싱: 두 개 이상의 인덱스가 있을 때 데이터를 추출하는 방법
pt1.loc[(앞 인덱스명, 뒤 인덱스명), 컬럼명]- 예: 1등급 여성 나이
pt1.loc[(1, "female"), "Age"]
- 예: 1등급 여성 나이
-
Age 컬럼 결측치를 채우는 함수 생성 -> apply 함수를 사용해 한 번에 적용
- apply 함수
- 행 또는 열에 특정 함수를 일괄적으로 적용할 때 사용
적용할df.apply(함수, axis = 0 또는 1): 열에 넣을 거면 axis = 1, 행에 넣을 거라면 axis = 0
- apply 함수
# 나이 데이터 추출 함수 생성
# 만약 Age 있다 -> 현재 나이 그대로 추출, Age 없다 -> pt1 조건에 맞는 나이 추출
def fill_age (data): # data 매개변수에는 train, test 값이 들어갈 예정
if pd.isnull(data["Age"]): # 비어있니? -> 네
return pt1.loc[(data["Pclass"], data["Sex"]), "Age"] # 비어 있는 사람의 등급과 성별 반환
else: # 원래 나이 있음
return data["Age"] # 현재 사람의 나이를 그대로 반환
# df.apply(함수명, 축 설정)
train["Age"] = train.apply(fill_age, axis=1).astype("int64")
# 각 행(Series 객체)이 함수의 입력값이 됩니다.apply 함수
- 각 행(또는 열)마다 함수를 반복적으로 적용
- 데이터프레임이나 시리즈의 각 행 또는 열에 대해 함수를 한 번씩 적용하고, 그 결과를 새로운 시리즈나 데이터프레임으로 반환하는 방식으로 작동
- 지정한 축(행 또는 열)을 따라 각각의 행(또는 열)을 함수에 전달합니다.
- 함수의 리턴값을 모아 새로운 시리즈 또는 데이터프레임을 만듭니다.
- axis 파라미터에 따라 행/열 단위로 함수가 적용
- axis=0 (기본값): 각 열을 함수에 전달
- axis=1: 각 행을 함수에 전달
- 데이터프레임이나 시리즈의 각 행 또는 열에 대해 함수를 한 번씩 적용하고, 그 결과를 새로운 시리즈나 데이터프레임으로 반환하는 방식으로 작동
- 복잡한 조건이나 여러 컬럼을 동시에 활용하는 가공에 유용
- 반복문보다 코드가 간결하고 가독성이 높음
- test 데이터의 Age 컬럼 채우기
pt2 = test.pivot_table(
values = "Age" # 출력할 데이터로 사용할 컬럼
, aggfunc="mean" # 그룹화 결과로 출력할 함수 -> sum, mean, count 등 함수 사용 가능
, index = ["Pclass", "Sex"] # 데이터 요약시 함께 사용할 컬럼
)
def fill_age2 (data:pd.Series) -> float|int:
"""
한 행(row)의 'Age' 열 결측치를 채워 반환하는 함수입니다.
Args:
data (pd.Series): 결측치를 채울 행입니다.
Returns:
float 또는 int: 각 행의 나이 값.
- 만약 'Age'가 결측치라면, 해당 행의 'Pclass'와 'Sex'에 따라 추정된 나이 값을 반환합니다.
- 그렇지 않으면 원래의 'Age' 값을 반환합니다.
"""
if pd.isna(data["Age"]):
return pt2.loc[(data["Pclass"], data["Sex"]), "Age"]
else:
return data["Age"]
test["Age"] = test.apply(fill_age2, axis=1).astype("int64")- 타입 힌트와 함수 설명문(docstring)
- 매개변수 타입 힌트 →
data: pd.Series또는 생략 권장 - 반환값 타입 힌트 →
-> float | int또는 생략 권장 - 설명문 → 실제로는 아래와 같이 간단하게 씁니다:
"""한 행(row)의 'Age' 결측치를 채워 반환합니다."""
- 매개변수 타입 힌트 →
isna() and isnull()
- isna() and isnull() are functionally identical methods used to detect missing values (NaN or None) within a DataFrame or Series.
- Aliases:
- isnull() is an alias for isna(). This means they point to the same underlying function in the Pandas codebase and produce the exact same results.
- Purpose:
- Both methods return a boolean object (DataFrame or Series of the same shape) where True indicates a missing value and False indicates a non-missing value.
- Origin of Two Names:
- The existence of both names is likely a historical artifact related to the influence of R on Pandas.
- In R, NA (Not Available) and NULL have distinct meanings and are handled by different functions.
- In Python's Pandas, built upon NumPy, NaN (Not a Number) is the primary representation for missing numerical values, and None for missing object values, both of which are treated as "missing" by isna() and isnull().
- Best Practice:
- While both are interchangeable, it is generally recommended to use isna() for consistency with other Pandas functions like dropna() and fillna(), which also use the "na" prefix to refer to missing data.
train 데이터 Embarked 컬럼
- 결측치 채우기: 결측치 2개
# 어떤 승선항에서 얼마나 탑승했는지 확인
# count와 value_count 함수 차이 이해하기
print(train["Embarked"].count())
print('-'*10)
print(train["Embarked"].value_counts())889
----------
Embarked
S 644
C 168
Q 77
Name: count, dtype: int64
# 결측치가 단 2개뿐이고 S 데이터가 압도적으로 많기 때문에 결측치 2개를 S로 채우기
# 데이터가 많을수록 한두 개의 데이터는 큰 영향을 미치지 않기 때문# fillna(지정값): 지정값으로 결측치를 전부 채워주는 함수
train["Embarked"] = train["Embarked"].fillna('S')test 데이터 Fare 컬럼
- 결측치 1개
test["Fare"].describe()
# 평균 35, 최댓값은 512로 4분위수를 통해 분포를 보니 앞쪽으로 몰려있는 형태
# 전체 평균으로 결측치를 채우기에는 신뢰성이 떨어질 것 같음
# 상관관계 확인
test.corr(numeric_only=True)["Fare"].abs().sort_values(ascending=False)
# Fare 컬럼과 상관관계가 높은 Pclass 컬럼을 활용하여 결측치 채우기~ (성별도 함께)
pt3 = test.pivot_table(values="Fare", index = ["Pclass", "Sex"], aggfunc="mean")
# 비어 있는 값이 1개이니까 함수 생성하지 않고 결측치가 있는 행 출력 -> 직접 대입
# 불리언 인덱싱 -> Fare 비어 있는 행 추출
test[test["Fare"].isna()]
# 3등급 남자 -> 11.826350
test["Fare"] = test["Fare"].fillna(pt3.loc[(3, "male"), "Fare"])Cabin 컬럼
- Cabin 결측치 제거 (train, test 둘 다 존재)
- 결측치보다 실제 데이터가 더 적음
- 컬럼 자체를 삭제시키는 것도 하나의 방법
- 하지만 데이터를 최대한 살리는 것도 데이터 분석가의 역할
- 일단은 결측치에 임의의 값을 넣어 시각화 후 판단
- 결측치의 패턴 파악
- Cabin 컬럼은 데이터의 개수에 비해 결측치가 많음
- 앞의 알파벳이 존재 -> 패턴을 찾아보자!
- 결측치보다 실제 데이터가 더 적음
# 비어 있는 값 확인
train["Cabin"].isna().value_counts()
# 실제 데이터 내에서 패턴 확인
train["Cabin"].unique()
# 전체적으로 중복된 데이터 별로 없음
# 이런 경우 있는 데이터들 중에서도 패턴을 찾아내는 것이 중요!
# 첫 번째 알파벳이 공통적으로 발견 -> 배의 특정 층 의미
# G로 시작하는 데이터 별로 없음 -> G 등 하층의 객실에 묵은 사람의 결측치가 많지 않을까?
Cabin 데이터에서 영문자 추출
# 추출 전 결측치에 임의의 문자 'M'으로 채운 후에 새로운 패턴 확인 -> 새로운 컬럼 생성: Deck <특성공학>
train["Deck"] = train["Cabin"].fillna('M')
test["Deck"] = test["Cabin"].fillna('M')
# 임의의 문자로 채운 이유 -> 결측치의 비중이 크기 때문에 시각화를 통해 패턴을 찾기 위함
# 알파벳 한 글자 추출 -> 문자열 인덱싱
train["Deck"] = train["Deck"].str[0]
test["Deck"] = test["Deck"].str[0]
# 결측치가 있는 Cabin 컬럼 삭제
train.drop("Cabin", axis=1, inplace=True)
test.drop("Cabin", axis=1, inplace=True)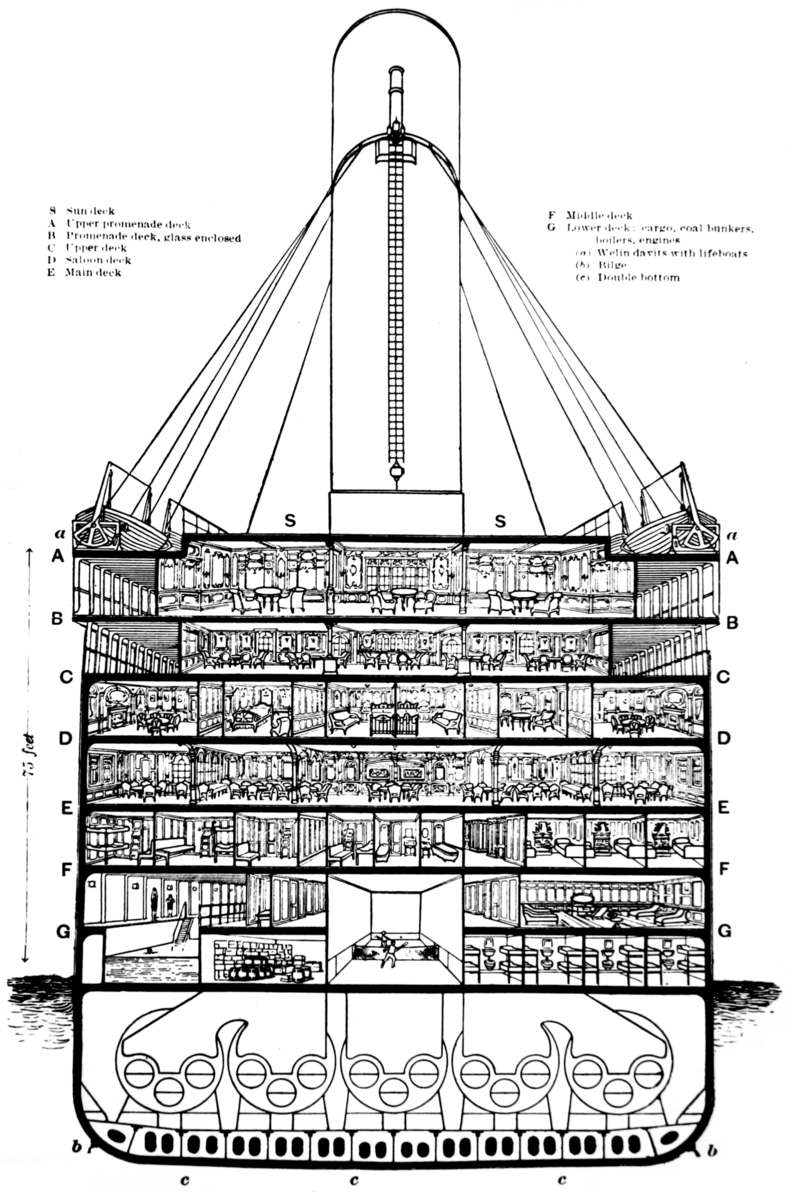
4. 탐색적 데이터 분석(EDA)
- train 데이터를 활용하여 분석
- test 데이터를 탐색하는 것은 모델의 일반화에 도움이 되지 않음
Deck 컬럼 시각화
- Deck 컬럼의 결측치를 임의의 데이터(M)로 채웠기 때문에 시각화를 통해 컬럼 사용 유무 확인
# Deck 값에 따른 생존 여부 확인
# 피벗테이블을 활용해서 다중인덱스로 결과 확인 -> count
train.pivot_table(values="Name", index=["Deck", "Survived"], aggfunc="count")
# 결과는 똑같은데 다른 방법 -> groupby() 사용해보기
# groupby():그룹별로 데이터를 집계, 요약해주는 함수
train.groupby(["Deck", "Survived"])["Name"].count()
train[["Deck", "Survived", "Name"]].groupby(["Deck", "Survived"]).count()
# 시각화로 학인
plt.figure(figsize=(6,8))
sns.countplot(
data=train
, x="Deck"
, hue="Survived"
)
plt.show()
# M 데이터가 생존자에 비해 사망자가 2배 이상 많음 -> 컬럼 사용 결정!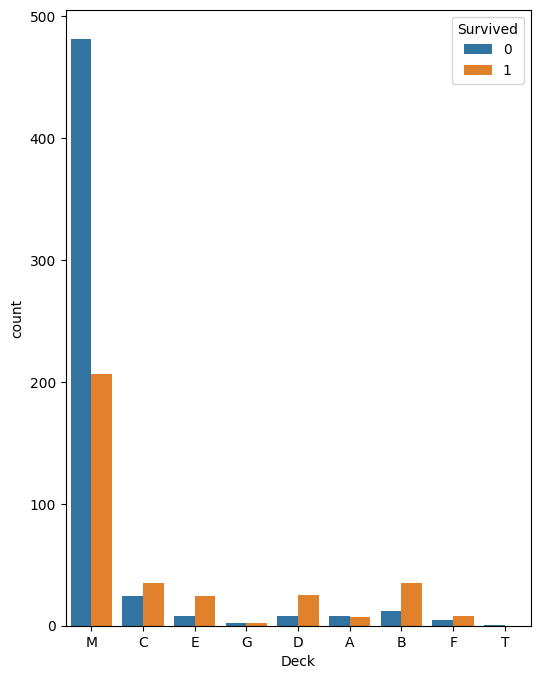
- 범주 데이터: countplot
- 연속형 데이터: violine plot
- 데이터의 밀도와 범위 확인
# 바이올린 플롯: 바이올린 형태로 생긴 데이터의 분포와 밀도를 보기 쉽게 곡선으로 표현한 그래프
# 데이터가 많이 존재하는 부분은 두껍게, 적게 분포하는 부분은 얇게 표현 -> 밀도, 분포만 간단하게 보는 그래프입니다.
sns.violinplot(
data=train
, x="Age"
, y="Sex"
, hue="Survived"
, split=True
)
plt.grid()
plt.show()
# 20대부터 40대까지의 분포가 넓음 -> 탑승자가 많음
# 어린아이 중에서는 남아가 여아보다 생존율이 높음
# 데이터의 막대 그래프를 이어 그린 형태로 분포, 밀도 확인하기 좋음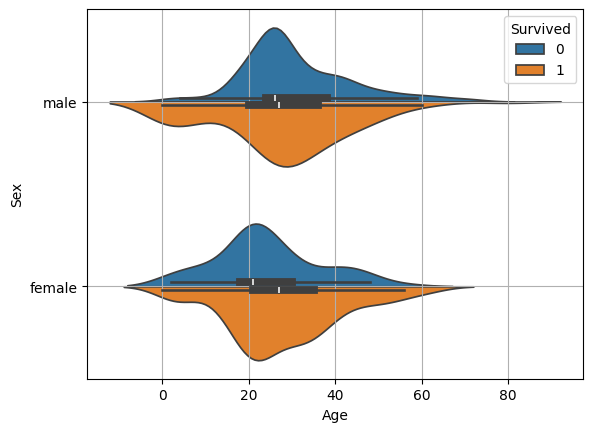
특성 공학
- 새로운 컬럼 추출: Family_Size
- 두 개의 컬럼은 결국 비슷한 데이터(함께 탑승한 사람들)
- Parch: 함께 탑승한 부모자식의 수
- SibSp: 함께 탑승한 형제, 자매, 배우자의 수
- 두 개 컬럼을 합쳐서 '가족의 수' -> 새로운 컬럼을 생성
- 반드시 train, test 모두 진행해야 함!
- 두 개의 컬럼은 결국 비슷한 데이터(함께 탑승한 사람들)
train["Family_Size"] = train["SibSp"] + train["Parch"] + 1
test["Family_Size"] = test["SibSp"] + test["Parch"] + 1
# 가족의 수 -> 생존 여부와 함께 그래프 시각화
fig6 = plt.figure(figsize=(10,3))
sns.countplot(
data=train
, x="Family_Size"
, hue="Survived"
)
plt.show()
# 1명 -> 사망률이 높음
# 2~4명: 소가족 -> 생존률 높음
# 5명 이상: 대가족 -> 사망률 높음
# 범주의 크기를 줄여 사소한 관찰의 오류를 줄여주자!
# 9개의 범주 -> 3개의 범주로 변경(binning) -> 비슷한 특징을 가지는 데이터들을 그룹으로 묶어주기!
# 사소한 관찰의 오류를 줄여주는 카테고리화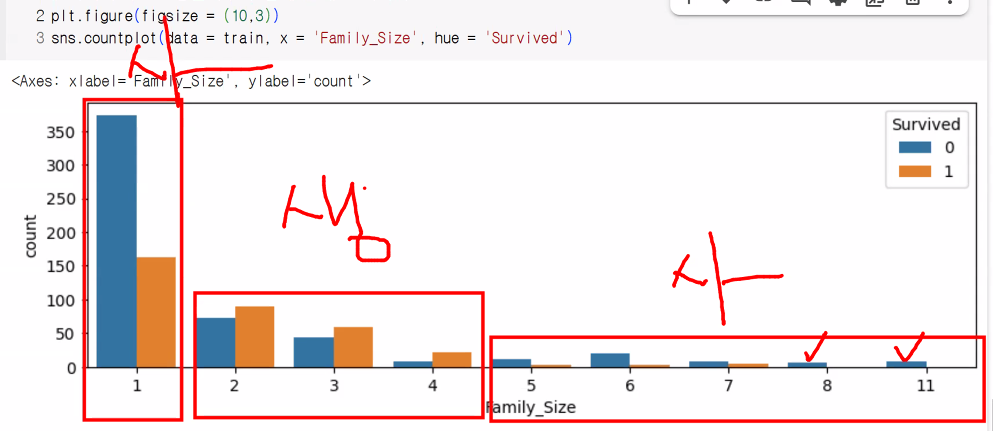
# cut 함수를 사용하여 카테고리화
# 1: "Alone", 2: "Small", 5~: "Large"
b = [0,1,4,11] # 구간 설정 -> 앞 순자는 불포함, 뒤 숫자는 포함
l = ["Alone", "Small", "Large"]
train["Family_Size"] = pd.cut(train["Family_Size"], bins=b, labels=l)
test["Family_Size"] = pd.cut(test["Family_Size"], bins=b, labels=l)
data binning
- 사소한 관찰 오류의 영향을 줄이는 데 사용하는 데이터 전처리 기술
- 정의된 기준에 따라 각각의 개별적인 데이터값을 특정한 bin(구간, interval) 또는 group으로 묶는 과정
- discrete binning 또는 bucketing이라고도 함
- text 데이터 다루기: Name 컬럼
- 호칭들만 추출해서 확인(Mr, Mrs, Miss, Dr, ...)
# 호칭만 추출하는 과정을 함수화하여 df에 적용 (apply())
def split_name (data:pd.DataFrame) -> str:
'''
이 함수는 Name 컬럼에서 호칭만 추출하는 함수입니다.
Args:
data (pd.DataFrame): 호칭을 추출할 Name 컬럼이 있는 데이터프레임
Returns:
str: 호칭
'''
return data["Name"].split(',')[1].split('.')[0].strip()
# 쉼표를 기준으로 나누기 후 인덱싱 (뒤) ->
# 온점을 기준으로 나누기 후 인덱싱 (앞) ->
# 문자열에서 공백을 지워주는 함수: .strip()
train["Title"] = train.apply(split_name, axis=1)
test["Title"] = test.apply(split_name, axis=1)
plt.figure(figsize = (20, 12))
sns.countplot(
data=train
, x="Title"
, hue="Survived"
)
plt.show()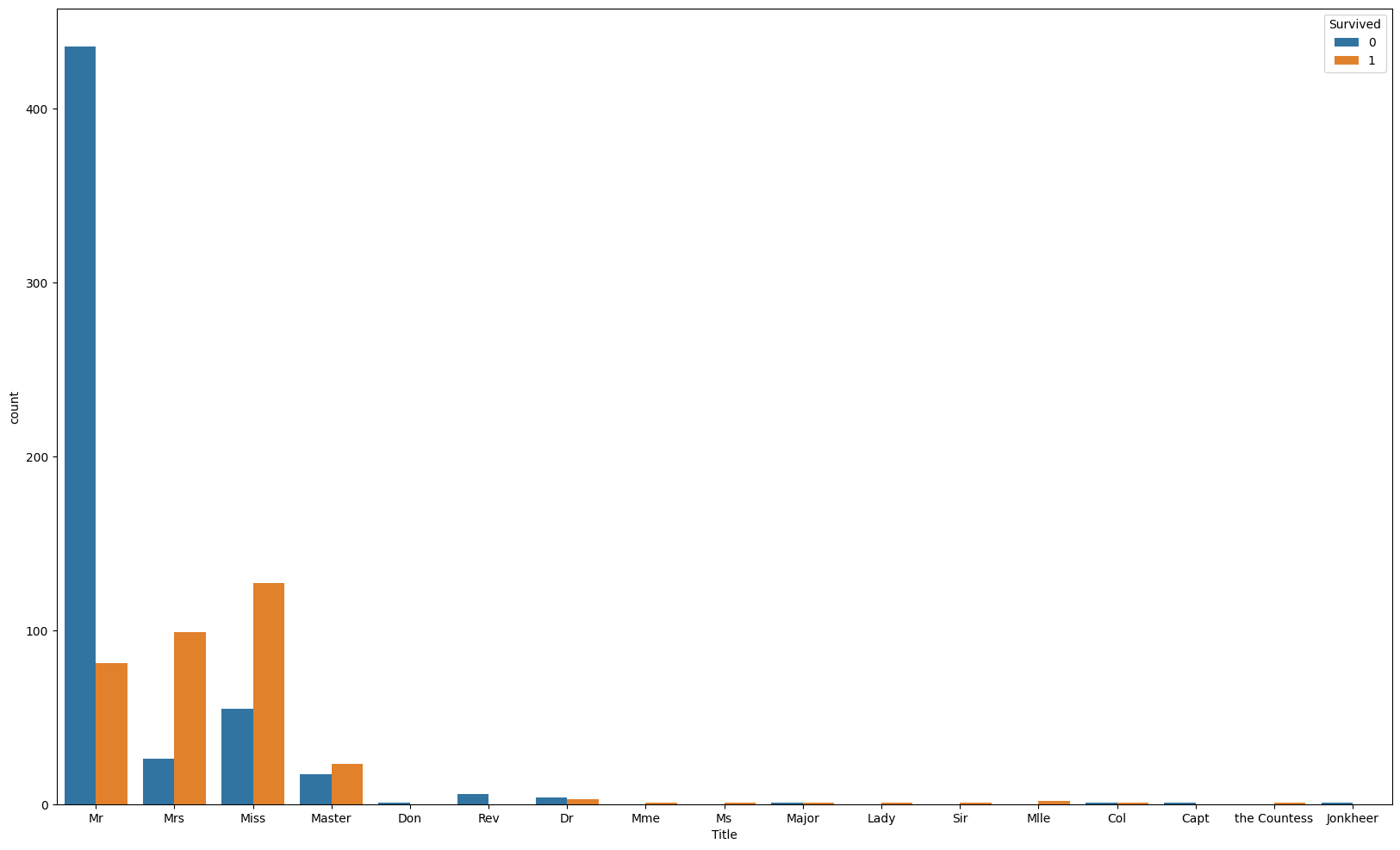
하루 돌아보기
👍 잘한 점
- Pre-Training 과정을 복습하고 수업을 갔기 때문에 타이타닉 데이터 분석을 했었던 걸(데이터 시각화 강의에 있음) 잘 기억해서 강사님의 질문에 대답을 많이 했음
👎 아쉬웠던 점
- violine plot에 대한 이해가 부족했음
- 강사님께 질문해 해결
- 시각화 그래프/plot 그리는 게 많이 헷갈렸음
- 블로그에 해당 내용 정리함
🔬 개선점
- 단순 개념 기록과 별개로 회고 진행하기
- 도움이 될 만한 블로그 글: 개발자로서 '성공'하고 싶다면…
- Github 익숙해지기
- 위 블로그 작성자가 운영중인 Github와 같이 작성해 보면 좋을 듯
너무 조급해 하지 말고 작은 것부터 하나씩 천천히 쌓아나가자!

2 B R 0 2 B