코딩테스트 연습
알고리즘
def solution(s):
s=s.lower()
return False if s.count('p')!=s.count('y') else True- Counter 클래스 활용
from collections import Counter
def solution(s):
c = Counter(s.lower())
return c['y'] == c['p']- bitwise technique
def solution(src: str) -> bool:
balance = 0
for ch in src:
bits = ord(ch) & 31
if bits == 16: # 'p' or 'P'
balance += 1
elif bits == 25: # 'y' or 'Y'
balance -= 1
return balance == 0SQL
- Write a solution to swap all 'f' and 'm' values (i.e., change all 'f' values to 'm' and vice versa) with a single update statement and no intermediate temporary tables.
- Note that you must write a single update statement, do not write any select statement for this problem.
UPDATE Salary
SET sex =
CASE sex
WHEN 'm' THEN 'f'
ELSE 'm'
END
;-
CASE 문 대신 IF를 사용할 수 있음(MySQL)
update salary
set sex=if(sex='m','f','m');지난 시간 복습
머신러닝이란?
- 기계학습 -> 인간이 가지는 지능을 기계가 가짐으로써 데이터를 기반으로 학습을 하여 새로운 데이터가 들어왔을 때 예측을 진행하는 것
머신러닝 종류 3가지
- 지도학습: 정답 데이터(label)가 있는 상태에서 학습
- 정답 데이터의 형태에 따라 지도학습의 학습 방법이 다름
- 분류: 정답 데이터의 형태가 범주형, 카데고리컬한 데이터(class)
→ class 2개 - 이진분류, class 3개 - 다중분류 - 회귀: 정답 데이터의 형태가 연속형, 수치형
- 분류: 정답 데이터의 형태가 범주형, 카데고리컬한 데이터(class)
- 정답 데이터의 형태에 따라 지도학습의 학습 방법이 다름
- 비지도학습: 정답 데이터 없는 상태에서 학습
- 데이터의 구조, 패턴, 특징을 파악하여 학습
→ 군집화 clustering
- 데이터의 구조, 패턴, 특징을 파악하여 학습
- 강화학습: 보상을 주는 방향으로 학습
- 정답데이터가 있긴 있지만 완벽하지 않음
- 주로 로봇이나 게임을 학습시킬 때 사용
- 로봇 길찾기
머신러닝을 학습하는 7가지 과정
- 문제 정의
- 어떤 목적으로 어떤 데이터를 활용해서 어떤 분석을 할 것인가 명확하게 정의
- 데이터 수집
- 크롤링, DB, 설문조사, 공공데이터포털 등 활용
- 데이터 전처리
- 이상치, 결측치 처리
- 특성공학: grouping 등
- 여기서 말하는 특성 = 입력 특성
- EDA(탐색적 데이터 분석)
- 기술통계량 확인
- 특성간 상관관계
- 데이터 시각화
- 모델 선택 및 하이퍼파라미터 조절
- 목적에 맞는 모델 선택
- 성능을 높이기 위한 하이퍼파라미터 조절
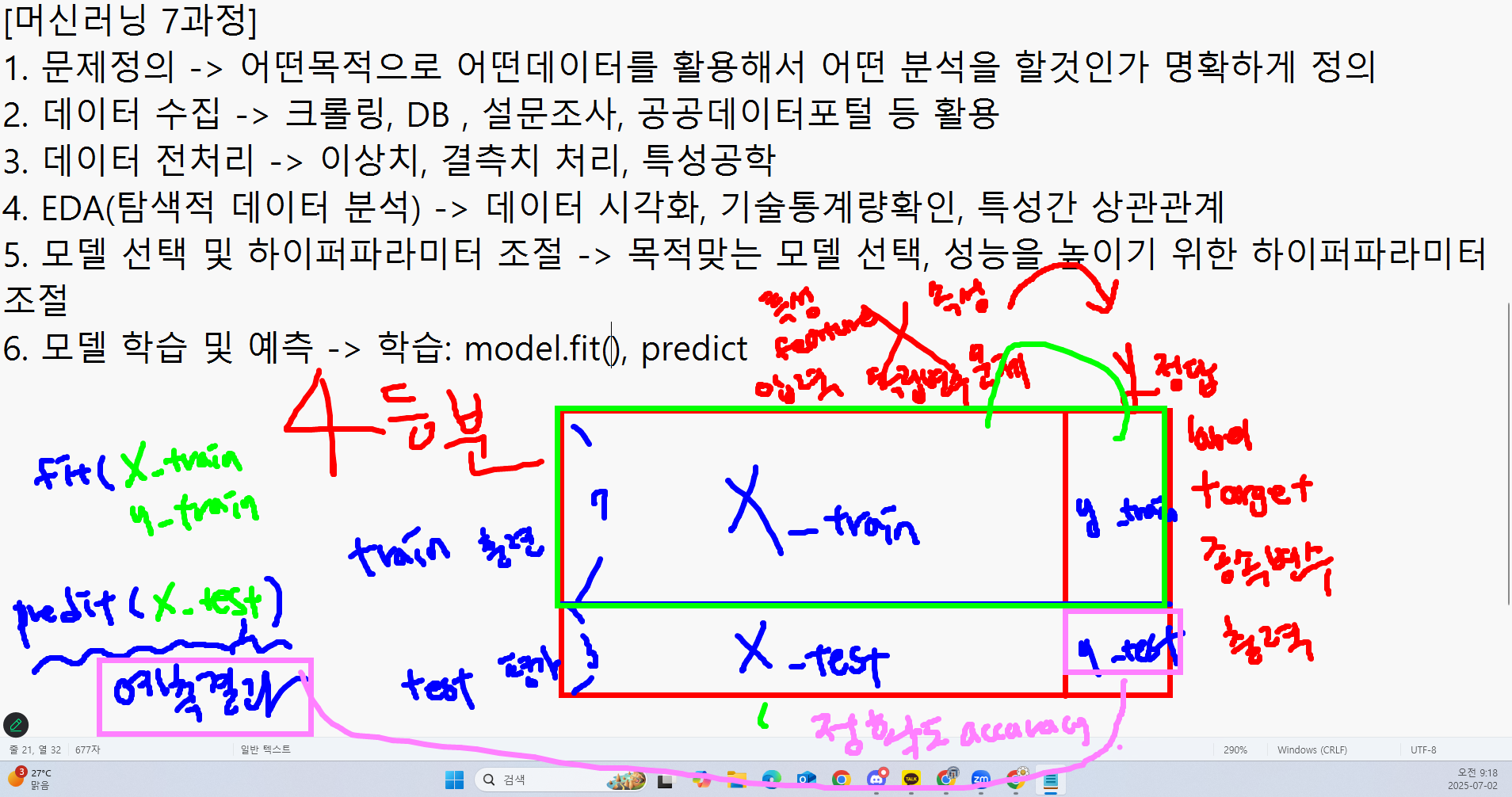
- 모델 학습 및 예측
- 학습:
model.fit(X_train, y_train) - 예측:
model.predict(X_test) - X: 특성(feature), 속성(attribute), 독립변수, 문제 데이터, 입력 데이터
- y: 레이블/라벨(label), 타겟(target), 종속변수, 정답 데이터, 출력 데이터
- 학습:
- 모델 평가
- 예측 결과와 실제 답(y_test) 비교: 정확도(accuracy; 0 - 1 사이의 값을 가지며, 1에 가까울수록 높은 정확도를 보임) 추출
실습: 온습도 관측 데이터
4. EDA(Exploratory Data Analysis)
데이터 기술통계량(Descriptive Statistic) 확인
- 데이터의 특징을 잘 설명하는 통계량을 지칭
- 통계량: 변수의 특징을 설명하기 위해 다양한 연산을 사용해 계산한 숫자
- 요약된 수치 확인 -> 데이터를 다양한 관점, 각도에서 관찰 및 이해하는 과정
- 연속형: 숫자를 정하거나 값들을 더해 통계량 계산
- 변수형: 값이 같은 관측치들을 묶어 개수를 셈
- 데이터를 전처리하는 근거가 되기도 함
- 결측치를 단순 제거하는 것이 아니라 기술통계량을 확인하여 대체할 만한 값들을 탐색 후 결측치 처리
데이터 수집 - 전처리 - EDA 단계는 유기적으로 움직입니다.
df.describe()
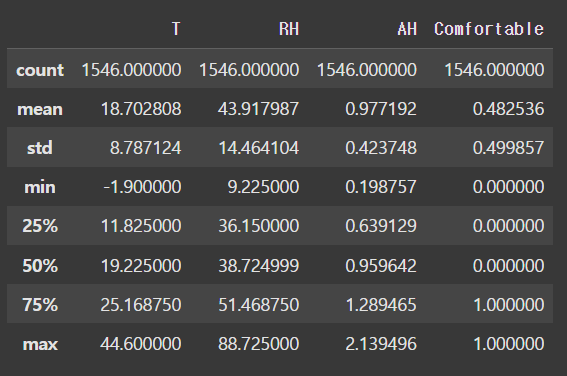
- 행과 열을 전치해서(
data.describe().T) 보면 더 편함
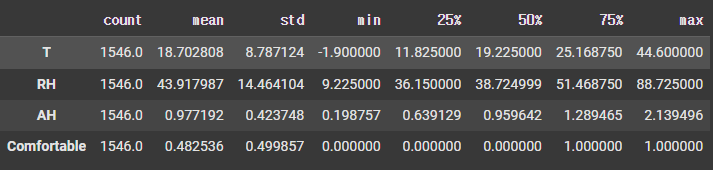
- count: 데이터의 개수
- mean: 평균
- std: 표준편차
- 데이터의 분포 파악: 흩어진 정도
- 분산에 루트(제곱근) 씌운 값 → 단위 문제 해결

- 분산: 확률론과 통계학에서 확률변수가 기댓값으로부터 얼마나 떨어진 곳에 분포하는지를 가늠하는 숫자

- min, max: 최솟값, 최댓값
- 25%, 50%, 75%: 4분위수
- 데이터의 분포를 4등분으로 나눠 확인
- 25%: 1사분위수
- 50%: 중위수, 중앙값, 2사분위수 → 평균과 많이 비교함(대푯값 선택 위해)
- 75%: 3사분위수
- 행과 열을 전치해서(
상관계수 확인하기
- 컬럼간(입력특성간, 정답) 상관관계를 확인
df.corr()
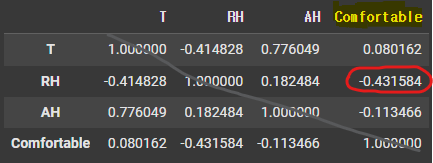
- 상관계수
- 컬럼들끼리 연관성의 비례, 반비례 정도를 수치로 표현
- -1 ~ 1 사이의 값을 가짐
- 절댓값으로 1에 가까울수록 연관성이 높은 값들이다!
- 상관계수 해석(|r| = 절대값)
- 0.0 <= |r| < 0.2 : 상관관계가 없다. = 선형의 관계가 없다.
- 0.2 <= |r| < 0.4 : 약한 상관관계가 있다.
- 0.4 <= |r| < 0.6 : 보통의 상관관계가 있다.
- 0.6 <= |r| < 0.8 : 강한 (높은) 상관관계가 있다.
- 0.8 <= |r| <= 1.0 : 매우 강한 (매우 높은) 상관관계가 있다.
대푯값(Representative Value)
- 중심경향값으로도 불림
- 내가 가진 데이터들을 가장 잘 표현해주는 값
- 주어진 데이터를 대표하는 값
- 흔히 사용되는 대푯값으로는 평균, 중앙값, 최빈값 등이 있음
- 일반적으로 대푯값을 사용할 때는 평균이나 중앙값을 많이 사용
- 평균 (Mean)
- 자료의 모든 값을 더한 후 변량의 개수로 나눈 값
- 자료 전체의 평균적인 크기를 나타냄
- 중앙값(Median)
- 자료를 크기 순서대로 나열했을 때 중앙에 위치하는 값
- 극단적인 값의 영향을 덜 받는 특징이 있음
- 최빈값(Mode)
- 자료에서 가장 빈번하게 나타나는 값
- 주어진 자료들 중 가장 많은 빈도(frequency)로 나타나는 값
- 특정 값이 얼마나 흔한지 나타냄:
[1, 90, 90, 90, 90, 100]에서 최빈값은 90
- 무엇을 대푯값으로 할 것인지는 연구자가 결정
- 일반적으로 대표값을 사용할 때는 평균이나 중앙값을 사용
- 이상치 발견&판별에도 사용
- 데이터분석가의 판단에 따라 이상치로 볼 것인지 아닌지 결정
- 따라서 데이터를 많이 보고 많이 생각해보는 과정이 필요!
- 데이터분석가의 판단에 따라 이상치로 볼 것인지 아닌지 결정
사분위수(Quartile)
- 관측값을 오름차순으로 정렬한 후 4개의 동일한 값으로 나눈 값
- 관측값의 중심 위치와 분포를 쉽고 빠르게 파악 가능

사분위수 구해보기
[1, 3, 3, 3, 4, 4, 4, 6, 6]- 1단계: 오름차순 정렬하고 중앙값을 구한다

- 2단계: 중앙값을 기준으로 왼쪽 값들의 중앙값을 구한다(1사분위수)
- 3단계: 중앙값을 기준으로 오른쪽 값들의 중앙값을 구한다(3사분위수)
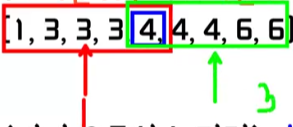
- 1단계: 오름차순 정렬하고 중앙값을 구한다
상자 그림(Boxplot)
- 사분위수를 그래프로 그린 것
- 관측치를 같은 비율로 나누는 지점을 계산하여 각 구간의 간격을 살핌
- 4분위수 범위(IQR, Interquartile Range)를 구하는 이유: 이상치를 확인하기 좋음
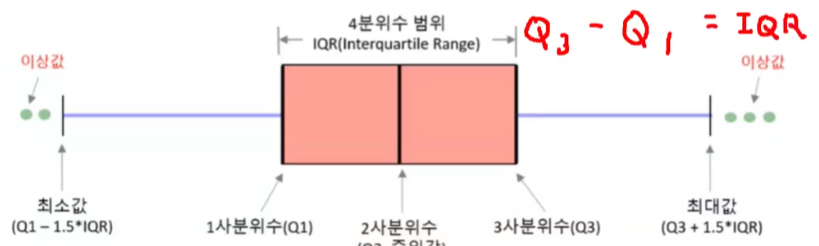
[1, 6, 10, 12, 12, 15, 21, 22, 33, 37, 56]- 1사분위수(Q1): 11
- 2사분위수(Q2, 중위값): 15
- 3사분위수(Q3): 27.5
- 4분위수 범위(IQR): 16.5
- 최솟값(
Q1-1.5*IQR): -13.75 - 최댓값(
Q3+1.5*IQR): 52.25 - 이상치: 56
상관분석/상관관계
- 상관 분석
- 확률론과 통계학에서 두 변수 간에 어떤 선형적 관계를 갖고 있는지를 분석하는 방법
- 상관 관계
- 두 변수는 서로 독립적인 관계(0) 또는 상관된 관계일 수 있음
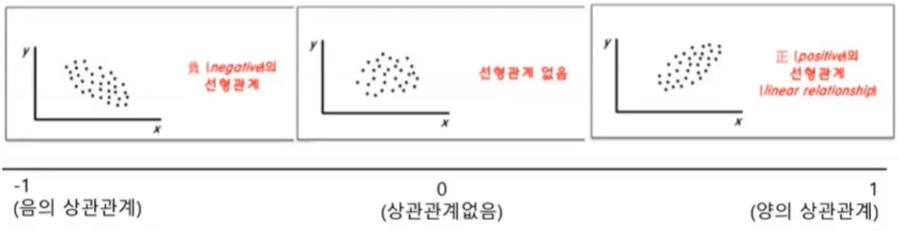
- 두 변수는 서로 독립적인 관계(0) 또는 상관된 관계일 수 있음
5. 모델 선택 및 하이퍼파라미터 조절
- 모델 도구 불러오기
- 모델 객체 생성
학습 전 데이터 준비(데이터 분리)
- 문제 데이터(X), 정답 데이터(y)
- 학습용 데이터(train), 평가용 데이터(test)

# 머신러닝 학습을 위한 데이터 분리
# 문제 데이터(X): T, RH, AH
X = data[['T', "RH", "AH"]]
# 정답 데이터(Y): Comfortable
y = data["Comfortable"]
# 문제와 정답의 데이터 크기 확인(.shape)
X.shape, y.shape
# X: (데이터의 개수, 특성의 수)
# y: (데이터의 개수,)
# train, test 분리(7:3)
X_train = X.iloc[:int(len(X)*0.7)]
y_train = y.iloc[:int(len(X)*0.7)]
X_test = X.iloc[int(len(X)*0.7):]
y_test = y.iloc[int(len(X)*0.7):]
# 데이터 크기 확인
print("학습용 문제 데이터: ", X_train.shape)
print("학습용 정답 데이터: ", y_train.shape)
print("평가용 문제 데이터: ", X_test.shape)
print("평가용 정답 데이터: ", y_test.shape)
# 문제와 정답의 개수는 동일해야 한다!
# 입력특성의 개수도 동일해야 한다! -> 컬럼의 순서와 이름이 동일해야 함y_train.value_counts()- 클래스가 한쪽으로 치우치지 않았는지 확인
- 학습할 때 내부에 들어가는 클래스의 비율이 맞으면 좋음
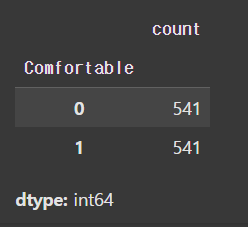
- 학습할 때 내부에 들어가는 클래스의 비율이 맞으면 좋음
- 클래스가 한쪽으로 치우치지 않았는지 확인
# 샘플링을 잘 해주는 것이 중요 -> 자동으로 랜덤 샘플링해서 비율을 나눠 주는 도구가 있어요!
# 데이터 분할 도구 사용하기(train_test_split)
from sklearn.model_selection import train_test_split
# 문제와 정답을 넣으면 4개의 변수에 대입(4개의 변수 미리 지정 → 순서 고정!)
# X_train, X_test, y_train, y_test = train_test_split(문제, 정답, 나누는 비율(0-1 사이의 값->1 넘는 값은 '개수'로 처리됨), 랜덤 규칙, 클래스 비율)
# 랜덤 샘플링 해 주기 때문에 항상 고정된 값을 원한다면 random_state(랜덤 규칙) 설정해 주어야 함(n번째 규칙을 사용하겠다는 뜻)
# stratify = y: 클래스 비율을 일정하게 -> 일반화 성능을 위해
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# random_state: 데이터 분리 시 랜덤 샘플링 가능 -> 매번 다른 결과 출력 -> 일관성 유지를 위해 랜덤 규칙 고정
# stratify: 클래스의 비율을 일정하게 맞춰줌(클래스 불균형 해결)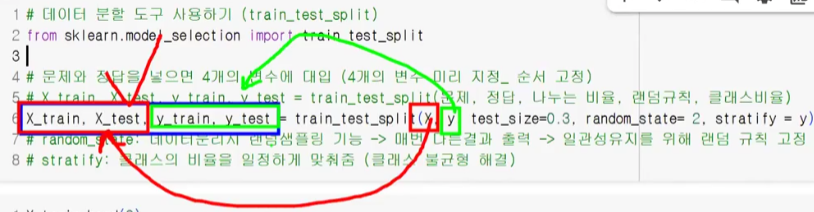
Sklearn(사이킷런) 라이브러리
- 대표적인 머신러닝 라이브러리
- 머신러닝에 필요한 다양한 도구들 지원
- 지도 학습 모델
- 비지도 학습 모델
- 전처리 도구
- 실습용 데이터 등
- Getting Started
train_test_split() 함수
- 데이터 세트(data set or dataset)에서 훈련 데이터와 테스트 데이터로 분리하는 기능
- X: 특성 데이터
- y: 라벨 데이터
- test_size: 테스트 세트의 비율
- random_state: 선택할 데이터 시드
- stratify: 클래스 분포 비율을 맞춤
- 레이블의 분포를 기존 데이터와 유사하게 하는지를 결정
- 레이블 데이터를 할당하는 것으로 설정 가능
- shuffle: 훈련용과 테스트 데이터를 나누기 전 데이터를 섞을 것인지 결정
- False: 섞지 않고 그대로
- True: 데이터 순서를 섞은 다음 데이터를 나눔(기본값)
모델 선택, 하이퍼파라미터 조절
# 모델 1: KNN(K-Nearest Neighbors; 최근접 이웃 모델)
# 모델 불러오기
from sklearn.neighbors import KNeighborsClassifier
# 모델 객체 생성
knn_model = KNeighborsClassifier()
# 하이퍼파라미터 조절 -> 모델 학습 & 평가 결과 보고 조절
for i in range(10):
i += 1
knn_model_n = KNeighborsClassifier(n_neighbors=i)
knn_model_n.fit(X_train, y_train)
print(f"n_neighbors={i}인 경우 accuracy: {knn_model_n.score(X_test, y_test)}")n_neighbors=1인 경우 accuracy: 0.9892241379310345
n_neighbors=2인 경우 accuracy: 0.9913793103448276
n_neighbors=3인 경우 accuracy: 0.978448275862069
n_neighbors=4인 경우 accuracy: 0.9827586206896551
n_neighbors=5인 경우 accuracy: 0.9762931034482759
n_neighbors=6인 경우 accuracy: 0.9762931034482759
n_neighbors=7인 경우 accuracy: 0.9719827586206896
n_neighbors=8인 경우 accuracy: 0.9741379310344828
n_neighbors=9인 경우 accuracy: 0.9655172413793104
n_neighbors=10인 경우 accuracy: 0.9698275862068966# 모델 2: 의사 결정 나무 모델(Decision Tree)
# 모델 불러오기
from sklearn.tree import DecisionTreeClassifier
# 모델 객체생성
dt_model = DecisionTreeClassifier()6. 모델 학습 및 예측
- model.fit(학습용 문제, 학습용 정답)
- model.predict(평가용 문제) -> 시험
# 모델 학습
knn_model.fit(X_train, y_train)
dt_model.fit(X_train, y_train)
# 모델 예측
y_pred_knn = knn_model.predict(X_test)
y_pred_dt = dt_model.predict(X_test)7. 모델 평가
- 위에서 예측한 결과와 실제 정답을 비교하여 성능 확인 → 정확도(accuracy)
- 분류 모델의 평가지표: 정확도(accuracy)
.metrics: 평가지표 모음집- accuracy: 정확도
- 전체 평가 데이터에서 맞춘 데이터의 비율
- 0 ~ 1 사이의 숫자로 출력
- 1에 가까울수록 높은 성능 -> 100% 정확도에 가깝다
# 모델 평가 방법 1
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred_knn)
# 모델 평가 방법 2
knn_model.score(X_test, y_test)
# 예측과 평가를 동시에 진행: 예측값 없이 결과만 바로 보고 싶을 때 사용머신러닝 모델
K-Nearest Neighbors(KNN)
- k-최근접 이웃 알고리즘(모델)
- 유유상종의 개념과 유사 → 끼리끼리!
- 데이터의 특성 중 가까운 이웃을 따라가는 방법
- 새로운 데이터 포인트와 가장 가까운 훈련 데이터셋의 데이터 포인트를 찾아 예측
- 거리 계산을 하는 모델(유클리디언 거리 계산 공식)
- k값에 따라 인접한 이웃의 수 결정
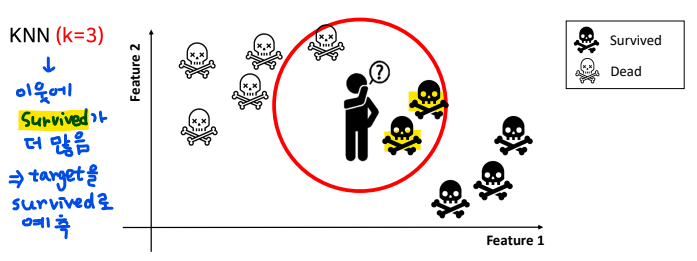
- 다수결로 새로운 클래스를 결정
- 기본 k값은 5
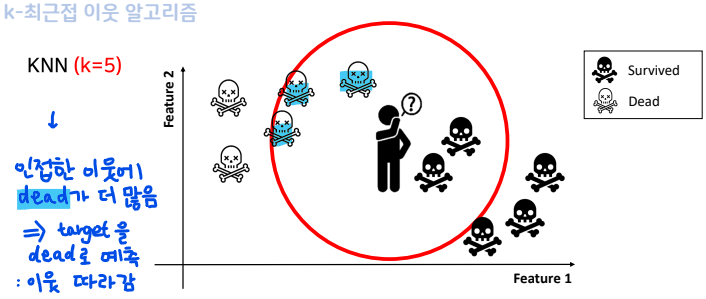
- 분류와 회귀 모두 사용
- 분류(KNeighborsClassifier): 다수결로 새로운 클래스 결정(categorical data니까)
- 회귀(KNeighborsRegressor): label의 평균값을 정답으로 가져감
개념 정리
- k값: 이웃의 수를 결정하는 하이퍼파라미터
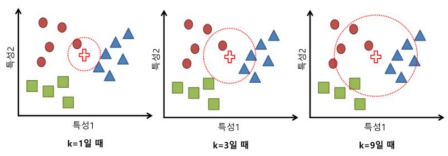
- k값이 작을수록 모델의 복잡도가 상대적으로 증가
- noise 값에 민감
- 새로운 데이터를 잘 예측하지 못함
- k값이 커질수록 모델의 복잡도가 낮아짐
- 제대로 된 성능을 내지 못함
- k값이 작을수록 모델의 복잡도가 상대적으로 증가
주요 매개변수(Hyperparameter)
- scikit-learn의 경우:
KNeighborsClassifier(n_neighbors=이웃의 수)※ 이웃의 수 == k값
유클리디언 거리 공식(Euclidean Distance)
- 데이터 포인트(sample) 사이 거리 값 측정 방법
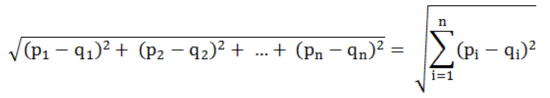

cf. 피타고라스
장단점
- 이해하기 매우 쉬운 모델
- 큰 조정 없이도 나쁘지 않은 성능을 발휘하는 기초 모델
- 새로운 테스트 데이터 세트가 들어오면 훈련 데이터 세트와의 거리를 계산
- 훈련 데이터 세트가 크면(특성, 샘플의 수) 예측이 느려짐
- 거리를 측정하기 때문에 데이터의 스케일(scale) 조정이 필요할 수 있음
- 직접적인 예측에 사용되기보다는 주로 데이터를 파악하기 위한 용도로 가볍게 사용
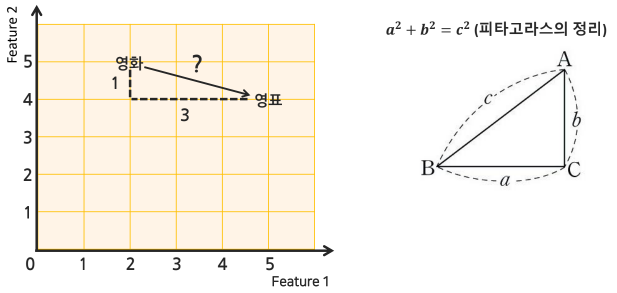
Decision Tree(의사결정나무 모델)
- 스무고개 하듯이 예/아니오 질문을 반복하며 학습
- e.g. 아키네이터
- 특정 기준(질문)에 따라 데이터를 구분
- 분류와 회귀에 모두 사용
- 불순도가 낮아지는 방향으로 학습
- 의사 결정 방향 → 불순도가 낮아지는 방향
- 의사 결정 방향 → 불순도가 낮아지는 방향
- 나무가 커질수록 모델이 복잡해짐 → 과대적합
- 의사결정나무는 과대적합되기 쉬움(제어가 거의 없어서)
불순도
- 다양한 범주(Factor)들의 개체들이 얼마나 포함되어 있는가를 의미
- 여러 가지의 클래스가 섞여 있는 정도
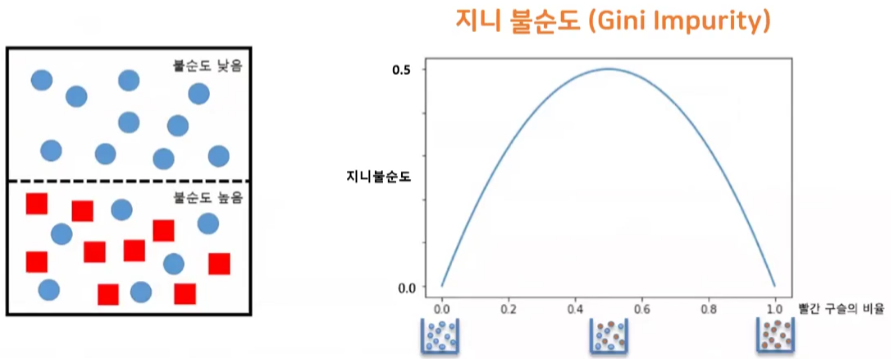
- 지니 불순도(Gini Impurity)
- 데이터의 불순도 혹은 혼잡도를 측정하는 지표(주어진 데이터 집합의 불확실성 또는 순도를 수치화)
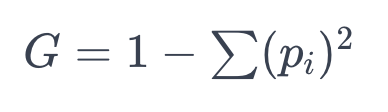
- : 특정 클래스에 속하는 항목의 비율
- 값이 크다 -> 지니 불순도는 낮아짐 -> 데이터 집합의 순도가 높다
- 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지를 뜻함
- 한 데이터 집합에 다양한 클래스(또는 레이블)가 얼마나 섞여 있는지 나타냄
- 결정 트리 모델의 노드 분할 기준
- 의사결정트리가 데이터를 어떻게 분할할지 결정하는 데 중요한 역할
- 각 질문들이 얼마나 좋은 질문인지 수치로 파악 가능
- 범위: 0 ~ 0.5 사이 값
- 0에 가까울수록 잘 분류된 것(좋은 질문)
- 0.5라면 데이터가 5:5 비율로 섞여서 분류된 것(좋지 않은 질문)
- 데이터의 불순도 혹은 혼잡도를 측정하는 지표(주어진 데이터 집합의 불확실성 또는 순도를 수치화)
용어
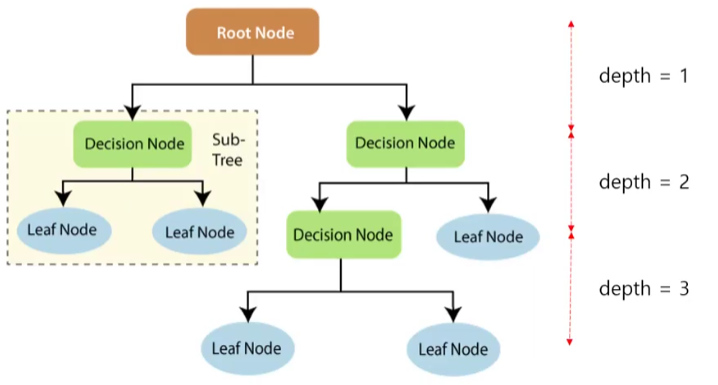
- Root Node(루트 노드): 나무가 시작되는 노드
- Decision Node: 나무 중간에 위치한 노드. 루트 노드/잎사귀 노드가 아닌 모든 노드가 해당됨
- Leaf Node(잎사귀 노드): 각 가지 끝에 위치한 노드
- depth(깊이): 가지를 이루고 있는 노드의 분리 층수
- Sub-tree
사용법
# 필요한 라이브러리 임포트
from sklearn.tree import DecisionTreeClassifier
# 결정 트리 분류 모델 생성 함수 호출, 결정 트리 분류 모델 객체 생성
tree_model = DecisionTreeClassifier(하이퍼 파라미터, random_state)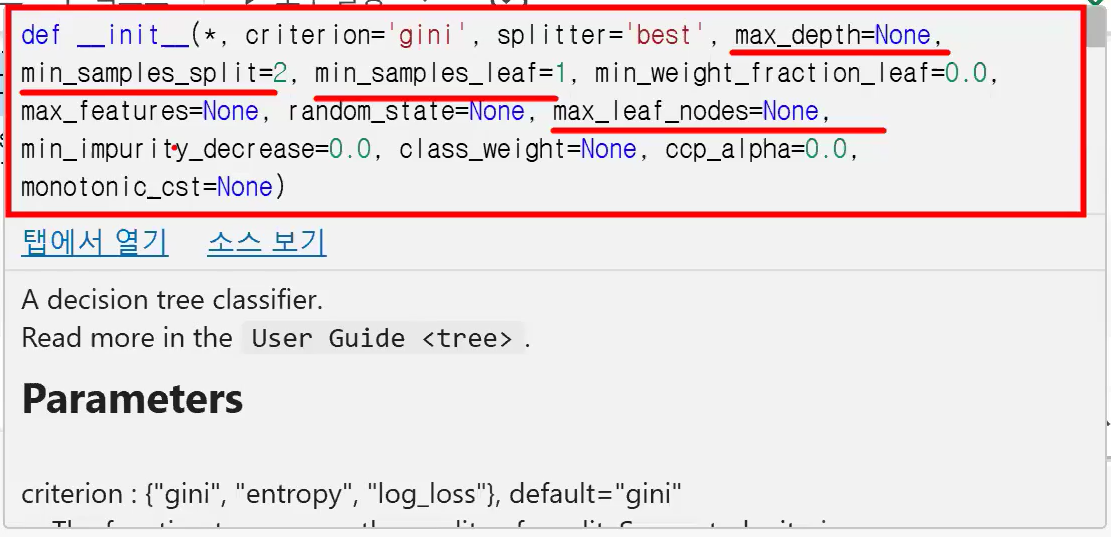
- 기본 설정은 제어를 하나도 안 하는 상태 → 과대적합 가능성
- 그래서 보통 사전 가지치기 진행함
주요 매개변수(hyperparameter)
- criterion
- 기준/불순도 측정 방법(gini)
- max_depth ★★★
- 트리의 최대 깊이 결정
- 사전 가지치기
- 과대적합 제어
- 작게 설정될수록 분할되는 노드가 많아져서 과대적합 가능성 증가
- min_samples_split
- 노드 분할을 위한 최소 샘플 수
- e.g. 10으로 설정하면 불순도가 높더라도 10개를 갖는 순간 분할을 멈춤
- 나누기 전 기준
- min_samples_split이 20인데 샘플이 15개(동그라미 7개, 네모 8개) → 나누지 않음 / min_samples_split이 10이면 7과 8로 나눔
- 과대적합 제어
- 작게 설정될수록 분할되는 노드가 많아져서 과대적합 가능성 증가
- 노드 분할을 위한 최소 샘플 수
- min_samples_leaf
- 리프 노드가 가져야 할 최소 샘플 수
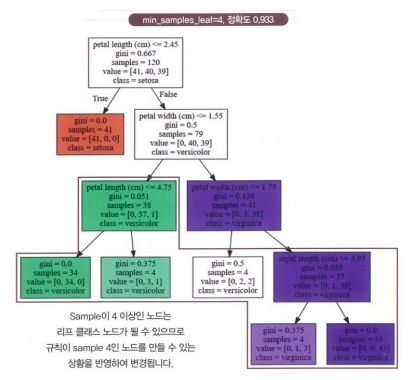
- 나눈 뒤 확인
- 샘플이 15개(동그라미 7개, 네모 8개)이고 min_samples_leaf가 5개 → 나눔
- 샘플이 7개(동그라미 3개, 네모 4개)이고 min_samples_leaf가 5개 → 나누지 않음
- 과대적합 제어
- 작게 설정될수록 분할되는 노드가 많아져서 과대적합 가능성 증가
- max_leaf_nodes
- 리프 노드의 최대 개수
- 과대적합 제어
- 크게 설정될수록 분할되는 노드가 많아져서 과대적합 가능성 증가
장단점
- 장점
- 쉽다
- 직관적이다
- 단점
- 과대적합이 발생하기 쉬움
- 극복을 위해 트리의 크기를 사전에 제한하는 튜닝이 필요: 사전 가지치기
- max_depth = 3
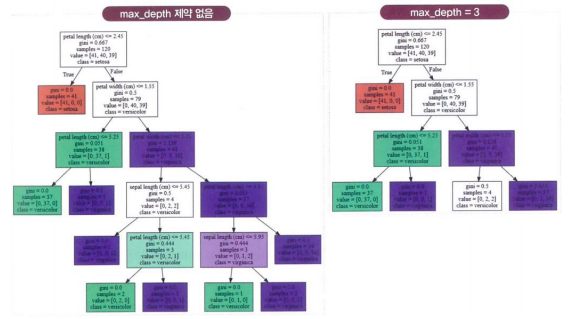
- min_samples_split = 4
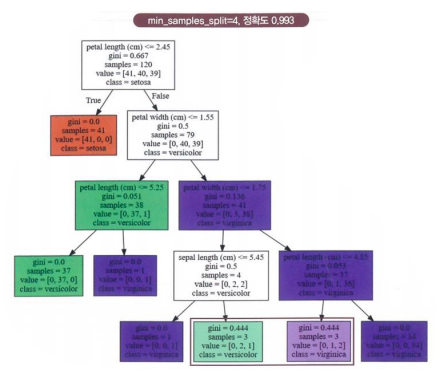
- min_sample_leaf = 4
- max_depth = 3
사전 가지치기(pre-pruning)
- 사전 가지치기를 이용한 모델의 성능 향상
- 기본 모델
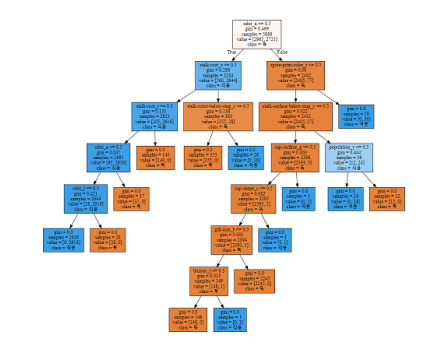
- max_depth=3
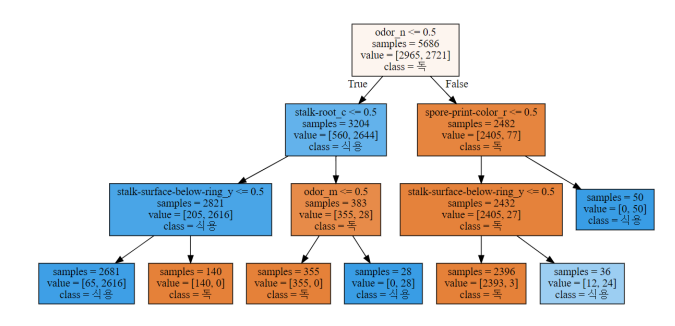
- max_leaf_nodes=6
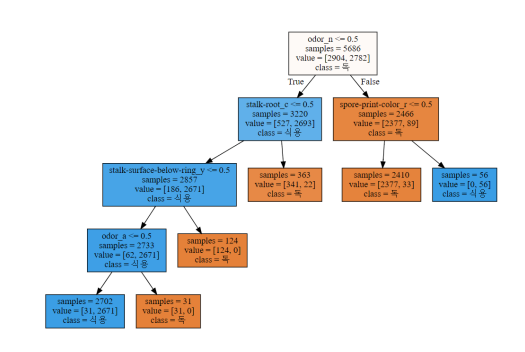
- min_samples_split=3000
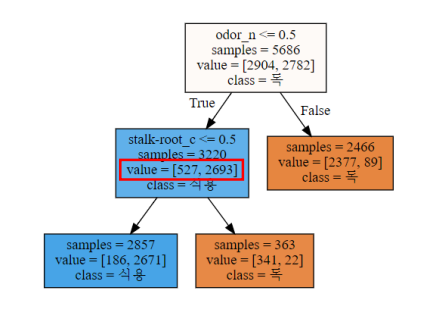
- min_samples_leaf=700
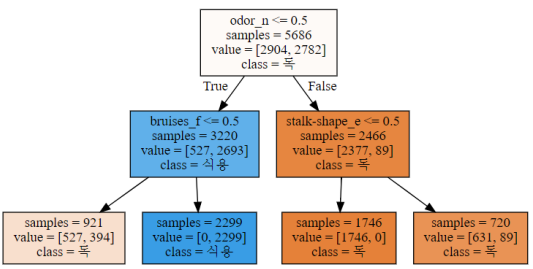
- 기본 모델
과대적합, 과소적합, 일반화
- 모델의 신뢰도를 측정하고, 성능을 확인하기 위한 개념
- 과대적합(Overfitting)
- 학습 데이터(훈련 데이터)인 train에 너무 과도하게 학습
- 학습 데이터에만 잘 동작, 평가 데이터인 test(혹은 새로 들어온 데이터)에서는 예측 성능 저하
- 너무 상세하고 복잡한 모델링을 하여 훈련 데이터에만 과도하게 정확히 동작하는 모델
- 과소적합(Underfitting)
- Train 데이터를 충분히 반영하지 못함
- train, test 데이터 모두에서 예측 성능이 저하되는 현상
- 학습을 제대로 하지 못한 것
- 모델링을 너무 간단하게 하여 성능이 나오지 않는 모델
- 일반화(Generalization)
- Train 데이터로 학습한 모델이 test 데이터에 대해서도 정확히 예측하는 현상
- 우리의 목표! 지향점!
- 일반화 성능이 최대화되는 모델을 찾는 것이 목표
모델의 복잡도 곡선
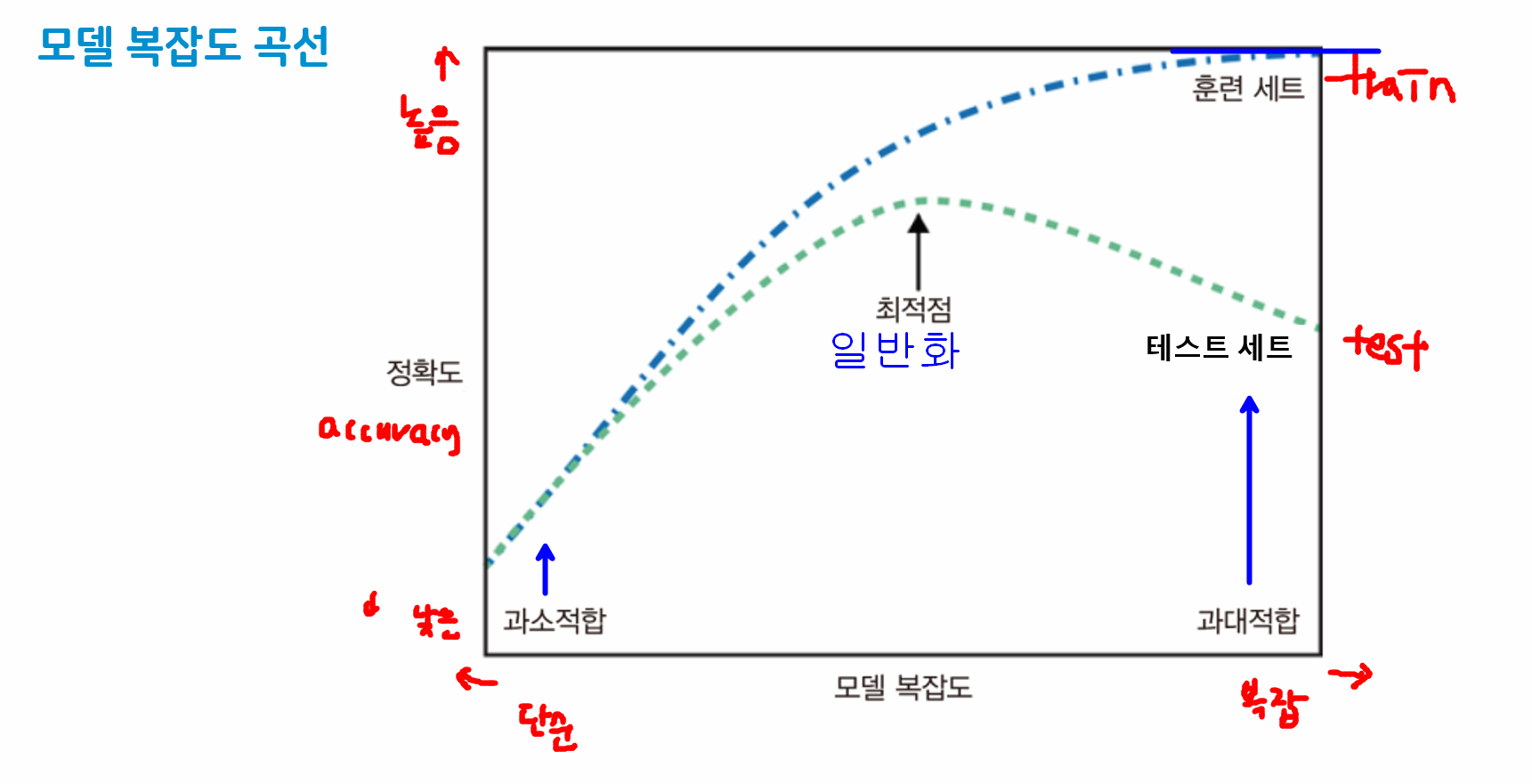
직접 그려보기
# 1부터 99까지의 이웃의 수를 하이퍼파라미터로 가지는 모델 -> 모델의 복잡도 곡선
# 시각화 -> train 정확도, test 정확도
# train, test 정확도를 담을 비어 있는 list 생성
train_list = []
test_list = []
# 1부터 99까지 1씩 증가하는 리스트
# range(시작값, 끝값+1, 증감수)
n_set = range(1, 100)
# 반복문을 활용하여 1~99까지 이웃에 따른 정확도 저장
for k in n_set:
# 모델 객체 생성
model = KNeighborsClassifier(n_neighbors=k) # 하이퍼파라미터 변경
# 모델 학습
model.fit(X_train, y_train)
# 모델 평가(train, test)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
# 정확도 저장(train_list, test_list)
train_list.append(train_score)
test_list.append(test_score)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(n_set, train_list, label="train")
plt.plot(n_set, test_list, label="test")
plt.xlabel("n_neighbors")
plt.ylabel("accuracy")
plt.legend()
plt.show()모델의 복잡도 해결
- 일반적으로 데이터 양이 많으면 일반화에 도움이 됨
- 주어진 훈련 데이터의 다양성이 보장되어야 함
- 다양한 데이터 포인트를 골고루 나타내기
- 편중된 데이터를 많이 모으는 것은 도움이 되지 않음
- 규제(Regularization)을 통해 모델의 복잡도를 적정선으로 결정

2 B R 0 2 B