코딩테스트 연습
알고리즘
def solution(d, budget):
answer = 0
d.sort()
for i in d:
if i <= budget:
answer += 1
budget -= i
return answer- 리스트 컴프리헨션을 사용해 풀 수도 있음
def solution(d, budget):
d.sort()
return len([cost for cost in d if (budget := budget - cost) >= 0])- 누적 합 활용
def solution(d, budget):
d.sort() # 부서별 신청 금액을 오름차순으로 정렬
total = 0
# 부서별 신청 금액과 인덱스를 순회
for i, cost in enumerate(d):
total += cost
if total > budget: # 예산이 부족한 경우
return i # 이때까지 지원한 부서의 개수(인덱스) 반환
# 모든 부서를 지원할 수 있는 경우
return len(d)더 알아보기
- sort와 sorted
- 각각 리스트를 정렬하는 데 사용
- 두 함수 모두 key와 reverse 매개변수를 지원:
- key: 정렬 기준을 지정하는 함수
- reverse: True로 설정하면 내림차순 정렬
- sort 함수
- 리스트 원본값을 직접 수정(원본 데이터 가변)
- 리스트명.sort() 형식 → "리스트형의 메서드"
- 리스트를 제자리에서(in-place) 정렬
- sorted 함수
- 리스트 원본 값은 그대로(원본 데이터 불변)이고 정렬 값을 반환
- sorted(리스트명) 형식 → 내장 함수
- 정렬된 새로운 리스트를 반환
- 따라서, sort 함수는 딕셔너리, 튜플, 문자열 등 자료형에는 사용이 불가하며, sorted 함수에서는 해당 자료형에도 적용이 가능하다.
| 특징 | sorted() | sort() |
|---|---|---|
| 반환값 | 정렬된 새로운 리스트 반환 | None 반환 (원본 리스트 변경) |
| 원본 데이터 | 변경되지 않음 | 변경됨 |
| 사용 가능 대상 | 모든 iterable | 리스트만 사용 가능 |
- enumerate
- 파이썬 내장 함수
- 반복 가능한 객체(리스트, 튜플, 문자열 등)를 받아 각 요소의 인덱스와 값을 순회 가능한 객체로 반환
- 반복문에서 현재 요소의 인덱스를 추적하고 싶을 때 유용!
SQL
WITH cte AS (
SELECT
product_id
FROM
Sales
WHERE
sale_date NOT BETWEEN '2019-01-01' AND '2019-03-31'
)
SELECT
DISTINCT p.product_id, p.product_name
FROM
Product AS p
JOIN Sales AS s
USING (product_id)
WHERE
p.product_id NOT IN (TABLE cte)
;→ 너무 어렵게 생각해서 푸는 데 오래 걸렸음
- 아래처럼 쉽게 접근할 수 있다!
select s.product_id, product_name
from Sales s join Product p on s.product_id=p.product_id
group by s.product_id
having min(sale_date) >= date('2019-01-01') and max(sale_date)<=date('2019-03-31')- 서브쿼리와 left join 활용
select product_id,product_name
from Product where product_id not
in
(
select p.product_id from Product p left join Sales s
on p.product_id=s.product_id
where s.sale_date <date('2019-01-01')
or
s.sale_date >date('2019-03-31')
or
s.seller_id is null
);지난 시간 복습
-
타이타닉 데이터
- PassengerId: 인덱스 데이터
- Survived: 정답 데이터(y)
- 데이터의 결과(원인에 의해 영향을 받음)에 해당하는 변수
- 나머지: 문제 데이터(X)
- 데이터의 원인(결과에 영향을 줌)에 해당하는 변수
-
용어 정리
| X | y |
|---|---|
| 문제 데이터 | 정답 데이터 |
| 독립변수(independent variable) | 종속변수(dependent variable) |
| input(입력) | output(출력) |
| Feature(특성) | Label(결과) |
| Attribute | Target |
| Explanatory variable(원인 변수) | Outcome variable(결과 변수) |
| Control | Class |
| Predictor variable(예측 변수) | Response variable(반응 변수) |
| Manuplate | … |
독립 변수가 연속형 자료라면 공변량(Covariance)이라고 부르고, 범주형 자료라면 요인(Factor)이라고 부름
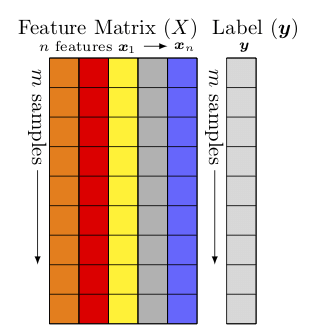
결측치를 채우기 위해 다양한 전처리 과정 필요!
-
Age Column 처리
- 평균과 중앙값 사이 차이 있음
- 단순 기술통계량이 아닌 상관관계 파악 후 의미 있는 값으로 결측치 채우기
.corr(): 상관관계 파악
-
QnA
- ❔ train과 test를 합쳐서 Age 컬럼의 평균을 구해야 하는 거 아닌가요?
- ❕ 그렇게 생각할 수도 있어요! 그리고 그렇게 활용하셔도 됩니다. (데이터 분석가의 판단에 따라 해당 방법도 선택 가능합니다.) 하지만 test는 "평가용"이라서 보통은 따로 계산합니다.
-
피벗 테이블
- 데이터를 요약해서 볼 수 있는 표
- 내가 원하는 다양한 컬럼들끼리의 조합을 통해 연산된 결과를 볼 때 사용하는 테이블
- Cabin Column 처리
- 결측치가 더 많은 상태
- 결측치 내부의 패턴 파악 후 결정
- EDA 결과 의미 있는 패턴 확인 가능했음
- M 데이터(결측치를 임의의 데이터로 채운 것): 생존자에 비해 사망자가 2배 이상 많은 패턴을 보임 → 가져가기로 결정
- 결측치가 더 많은 상태
- 탐색적 데이터 분석(EDA) 결과
- 1등급 여성은 생존률이 높고 3등급 남성은 사망률이 높다!
- 특성 공학(feature engineering)
- 가족의 수 컬럼으로 합치기
- SibSp + Parch + 1(나)
- 시각화 결과 패턴을 파악 -> 카테고리화(alone/small/large): by cut() 함수
- 카테고리화: 범주의 크기를 줄여 사소한 관찰의 오류를 줄여주기 위함
- 가족의 수 컬럼으로 합치기
- Name Column 처리
- 개수가 많은 특징 있는 데이터를 제외하고 나머지 데이터 그룹으로 묶기: Others
- 텍스트 데이터가 너무 많으면 학습 오류를 줄 수도 있기 때문!
- 개수가 많은 특징 있는 데이터를 제외하고 나머지 데이터 그룹으로 묶기: Others
3. 데이터 전처리
Feature Engineering
- 데이터 정제 및 변환 과정(Clean and Transform)을 통해 Feature를 만드는 과정
- 수집된 데이터에 대해 전처리 과정에서 데이터 정제와 변환(Data Quality & Transformation) 이후 진행
- 변수 선택(Feature Selection)
- 변수 추출(Feature Extraction)
- 차원 축소(Dimension Reduction)
- PCA(주성분 분석), LDA, SVD
- 관측된 데이터로부터 어떻게 Feature를 찾아낼 것이며, 찾아낸 Feature 중 의미 있는 변수들로 성분을 어떻게 축소시킬 것인지가 중요한 이슈
- Feature Engineering을 하는 이유
- 머신러닝 알고리즘의 정확도 향상
- 과적합(Overfitting Problem) 해결
- 계산 속도 향상
- 머신러닝 알고리즘의 불안정성 해결
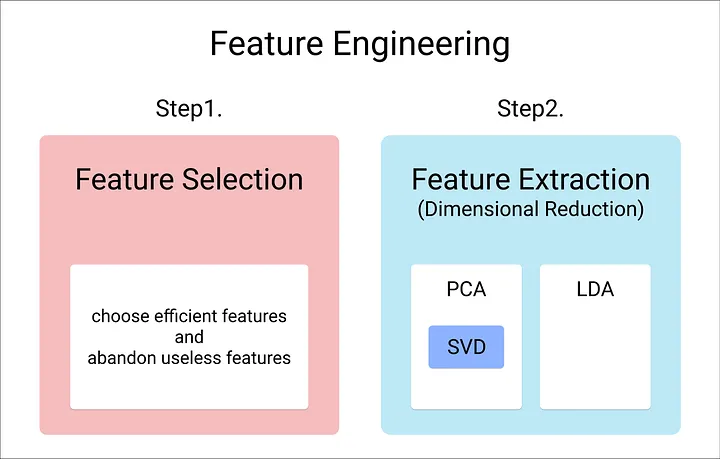
The overall picture for Feature Engineering
Title Column 처리
- 가장 많이 등장하는 데이터 순으로 정렬(value_counts)
- 상위 4개(Mr, Miss, Mrs, Master)와 EDA 결과 의미가 있다고 판단한 "Rev"까지는 살리고 나머지는 Others로 묶기
title = ['Mr', 'Mrs', 'Miss', 'Master',
'Rev', 'Don', 'Dr', 'Mme',
'Ms','Major', 'Lady', 'Sir',
'Mlle', 'Col', 'Capt', 'the Countess',
'Jonkheer']
# 중요한 5개의 호칭을 제외한 나머지 호칭은
# Others로 변환하여 리스트에 저장
convert_title = ['Mr', 'Mrs', 'Miss', 'Master',
'Rev'] + ["Others"]*(len(title)-5)
# map 함수를 사용하기 위해서는 dictionary 형태여야 함!
# → zip 함수를 활용해 변환: dict(zip())
# 리스트 형태인 2개의 값들을 합쳐주도록 하자!
title_dict = dict(zip(title, convert_title))
test["Title"].unique()
# trian에는 없는 Dona 데이터 확인 → 딕셔너리에 추가
title_dict["Dona"] = "Others"
# title_dict를 활용하여 실제 Title 컬럼을 변경
# map(): key값을 검색해 해당 value로 변경
train["Title"] = train["Title"].map(title_dict)
test["Title"] = test["Title"].map(title_dict)
# 6개의 데이터만 남은 것을 확인필요 없는 컬럼 삭제
- Ticket
- 규칙을 찾기 어려워 보임 → 필요 없는 컬럼으로 판단 → 삭제
- Name, SibSp, Parch
- 특성공학으로 의미 있는 데이터를 이미 뽑았으니 삭제
train.drop(
["Ticket", "Name", "SibSp", "Parch"],
axis=1,
inplace=True
)
test.drop(
["Ticket", "Name", "SibSp", "Parch"],
axis=1,
inplace=True
)데이터 분리
# X_train, y_train, X_test
# y_test는 캐글이 가지고 있음
# X_train(Survived 컬럼 제외)
X_train = train.drop("Survived", axis=1)
# y_train
y_train = train["Survived"]
# X_test
X_test = test
# 크기 확인
X_train.shape, y_train.shape, X_test.shape((891, 8), (891,), (418, 8))- 아직 모델 학습을 시킬 수 없어요!
- 데이터 타입이 모두 수치형이어야 함
- 머신러닝 → 문자열 학습 X → 수치 데이터로 변경하는 작업 필수!
- 데이터 타입이 모두 수치형이어야 함
인코딩(encoding)
- 범주형(문자형) 데이터 → 수치화(인코딩 필요) → One-hot Encoding 방식을 이용해 수치화
- unique한 값의 개수만큼 행 생성: 해당 값이 있으면 1, 없으면 0
데이터 표현
- 연속형(수치형) 특성
- 숫자로 이루어진 순서가 있는 데이터
- 범주형(문자형) 특성
- 문자 형태로 된 값으로 이루어진 데이터
- Encoding
- 범주형 데이터를 숫자형 데이터로 변환
- Label Encoding, One-hot Encoding 등
- Binning
- 숫자형 데이터를 범주형 데이터로 변환
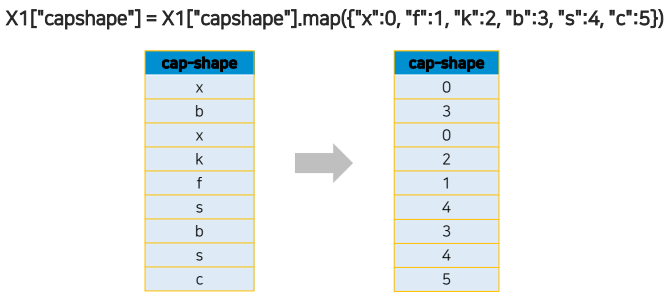
Lable Encoding
- 레이블을 숫자로 mapping
one-hot encoding(원핫 인코딩)
pd.get_dummies(X)- 하나의 컬럼 내에 중복되지 않은 unique()한 값들만큼 컬럼을 생성
- 해당되면 1, 나머지는 0으로 채워 수치화하는 방법
- 분류하고자 하는 범주(종류)만큼의 자릿수를 만들고 단 한 개의 1과 나머지 0으로 채워서 숫자화하는 방식
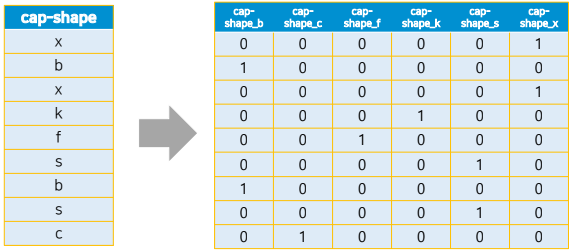
- 하나의 컬럼 내에 중복되지 않은 unique()한 값들만큼 컬럼을 생성
# 주의: 인코딩 → train, test 둘 다 적용해야 함
X_train = pd.get_dummies(X_train, dtype="int") # dtype 안 넣으면 True(1), False(0)로 나옴
X_test = pd.get_dummies(X_test, dtype="int")
# 크기 확인
X_train.shape, X_test.shape- 원핫 인코딩 후 train, test의 입력 특성 개수가 달라짐 -> 왜?
- unique한 값들만큼 컬럼을 추가 -> train에만 있는 데이터가 존재
- 찾아서 test에도 추가해줘야 모델 학습 가능
- set 이용!
# set(): 중복이 없는 unique한 값들로 구성한 집합
# 집합으로 만들면 연산이 가능해짐(차집합)
set(X_train.columns) - set(X_test.columns)
# 출력: {'Deck_T'}
# Deck_T가 train에만 존재함을 확인- test에 Deck_T 컬럼을 생성해줘야 함
- 컬럼은 생기지만 실제로는 없는 데이터이기 때문에 value는 전부 0으로 채우기
X_test["Deck_T"] = 0
X_test.shape
# (418, 26)- 컬럼의 순서도 맞춰줘야 함!
- X_train과 X_test가 동일한 컬럼&동일한 순서를 가져야 머신러닝 학습 가능
- 방법 1: old-fashioned
# 머신러닝 학습을 위해 X_train에 있는 Deck_T를 # 제일 뒤로 옮겨주도록 하자! # 1. Deck_T 컬럼을 임시변수(temp)에 저장 temp = X_train["Deck_T"] # 2. X_train에서 Deck_T 컬럼을 제거 X_train = X_train.drop("Deck_T", axis=1) # 3. X_train에 temp 병합 # pd.concat([df1, df2], axis=1) X_train = pd.concat([X_train, temp], axis=1)- 방법 2: 더 간단하게 컬럼 순서 변경 가능
# 맞춰주고 싶은 2개의 컬럼명을 가져와서 인덱싱 -> 대입 X_test = X_test[X_train.columns]
- X_train과 X_test가 동일한 컬럼&동일한 순서를 가져야 머신러닝 학습 가능
5~7. 모델링
모델 선택
- knn_model1
- 최근접 이웃 알고리즘
- 하이퍼파라미터 조절 O
- tree_model1
- 의사 결정 나무 알고리즘
- 하이퍼파라미터 조절 X
- tree_model2
- 의사 결정 나무 알고리즘
- 하이퍼파라미터 조절 O
→ 평가 X, 예측 O -> pre1, pre2, pre3
(y_test 값은 kaggle이 가지고 있어 내가 평가 못함)
모델 학습
# 모델 불러오기~
from sklearn.neighbors import KNeighborsClassifier # 최근접 이웃모델
from sklearn.tree import DecisionTreeClassifier # 의사결정나무모델
# knn_model1
knn_model1 = KNeighborsClassifier(n_neighbors= 3)
knn_model1.fit(X_train,y_train)
pre1 = knn_model1.predict(X_test)
# kaggle에 예측결과 업로드
kaggle = pd.read_csv('./data/gender_submission.csv')
# Survived 컬럼에 우리의 예측값 덮어 씌우기
kaggle['Survived'] = pre1
# csv 파일로 저장
kaggle.to_csv('./data/submission/250704_knn_result1.csv', index = False)
교차검증(Cross validation)
- 모델 일반화 성능 평가
- 학습-평가 데이터를 골고루 설정하여 모델의 안정성을 높이고 과대적합을 감소시키는 통계적 기법
- 모델의 안정성 ↑ == 일반화 성능 ↑
- 일반적인 경우

- 해결책: 검증 Data를 하나로 고정하지 않고 Train 데이터의 모든 부분을 사용

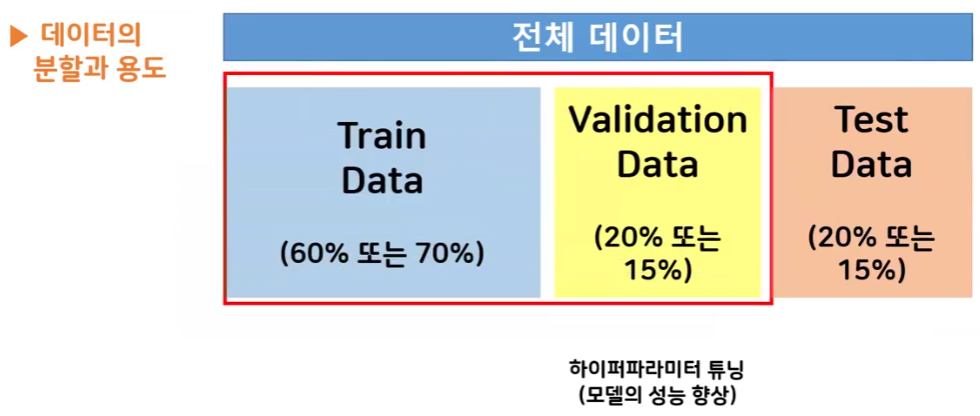
- 학습-평가 데이터를 골고루 설정하여 모델의 안정성을 높이고 과대적합을 감소시키는 통계적 기법
- 과적합을 확인하기 위한 방법
- 과적합이 확인되면 데이터 재검증 또는 하이퍼파라미터 조정
- 모델의 안정성을 확인하기 위한 과정
- train 데이터 내에서 또다시 학습용과 평가용으로 분리하여 검증하는 과정
- K=5 → 5개의 분리된 데이터들이 모두 비슷한 결과를 보이면 모델이 안정화됐다고 판단, 반면 5개으 ㅣ결과가 차이가 심하면 불안정한 모델이라고 판단
교차검증 하는 이유
과적합 확인하기 위해 → + 제어(by hyperparameter tuning)
모델 일반화를 높여주기 위해
K-fold cross-validation
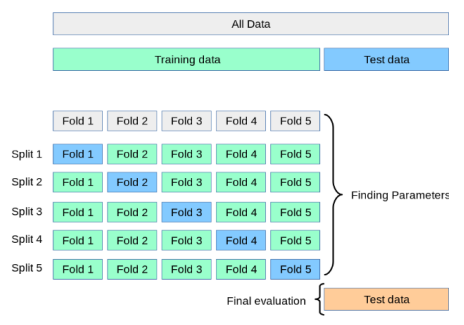
1. Train 데이터를 K개의 그룹으로 나눈다.
2. K-1개의 그룹을 학습에 사용한다.
3. 나머지 1개의 그룹을 이용해 평가를 수행한다.
4. 2번과 3번 과정을 K번 반복한다
5. 모든 결과의 평균을 구한다.
- K=5일 때 K-fold cross-validation 동작 방법
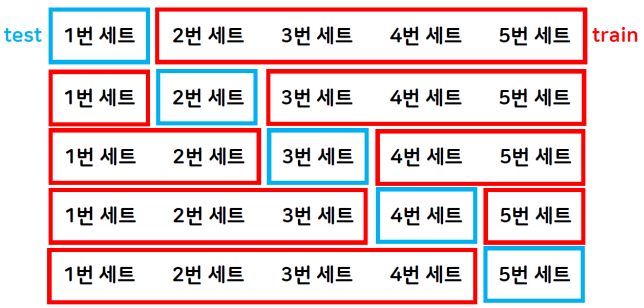
장단점
- 모든 데이터셋을 학습과 평가에 활용하기 때문에 안정적이고 정확함
- 통계적 기법으로 과대적합을 감소시켜 일반화에 도움이 됨
- 모델이 훈련 데이터의 변경에 대해 얼마나 민감한지 파악 가능
- 데이터셋의 크기가 충분히 크지 않은 경우에도 유용하게 사용 가능
- 여러 번 학습하고 평가하는 과정을 거치기 때문에 계산량이 많아짐
사용법
from sklearn.model_selection import cross_val_score
score = cross_val_score(
학습을 완료한 모델
, X_train
, y_train
, cv=나눌 개수(default는 5)
)
score데이터 스케일링(Data Scaling)
학슴 목표:
- 데이터 스케일링의 개념 이해
- 데이터 스케일링의 종류 파악
데이터 스케일링이란?
- 데이터 특성(Feature)들의 값 범위를 일정한 수준으로 맞춰 주는 작업
- 특성마다 다른 범위를 가지면서 편차가 큰 데이터 → 모델들이 잘못된 결과를 도출할 가능성 있음
- 특히 KNN, 선형 회귀, 로지스틱 회귀 등 거리나 수치 기반 모델
- 예: 신체검사 데이터에서 시력과 키 특성을 함께 학습시킬 경우 키의 데이터 범위(cm)가 시력에 비해 크기 때문에 데이터 거리 값을 기반으로 학습할 때 잘못된 영향을 끼칠 수 있음
- 분포를(변동 범위를) 비슷하게 맞춤 -> 영향을 비슷하게 맞춤!
- 특성마다 다른 범위를 가지면서 편차가 큰 데이터 → 모델들이 잘못된 결과를 도출할 가능성 있음
- 데이터의 입력특성의 값 분포, 범위를 일정한 수준으로 맞춰주는 작업
- 거리 계산으로 알고리즘을 진행하는 모델들에게 적용
- KNN, 선형회귀
- 거리 계산으로 알고리즘을 진행하는 모델들에게 적용
- 단위 조절, 단위 변환이라고도 함
특징
- 거리, 수치 기반 모델 적용 시 특성들을 비교 분석하기 쉽게 만들어 예측에 도움을 줌
- 특히 회귀 모델에서 학습의 안정성과 속도를 개선시킴
- 회귀 모델: 연속적인 실수를 예측
- 특히 회귀 모델에서 학습의 안정성과 속도를 개선시킴
- 트리기반 모델 등 거리값에 관계없는 모델들은 굳이 Scaling을 해줄 필요 없음
- 반드시 Scaling을 해야 하는 게 아님! (데이터의 분포가 고르다면 안 해도 됨)
주의점
- 훈련(train) 데이터와 평가(test) 데이터에 동일한 변환을 적용해야 함
- 훈련 데이터를 기준으로 변경
- 평가용 데이터 누설 방지
- 예측값의 범위가 달라질 수 있기 때문
- 훈련 데이터를 기준으로 변경
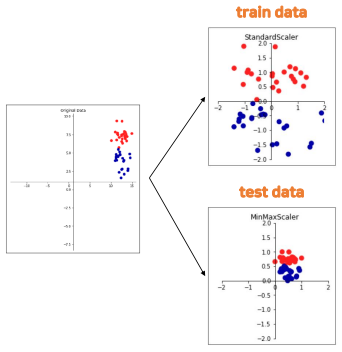
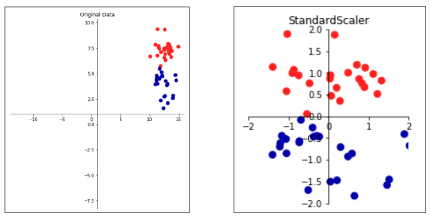
Standard Scaler
- 변수의 평균, 분산을 이용해 정규분포 형태로 변환 (평균 0, 분산 1)
- 분산: 데이터가 퍼져 있는 정도 → 클수록 들쭉날쭉 불안정함
- 이상치가 있다면 평균과 분산에 영향을 미쳐 변환된 데이터의 분포는 매우 달라짐
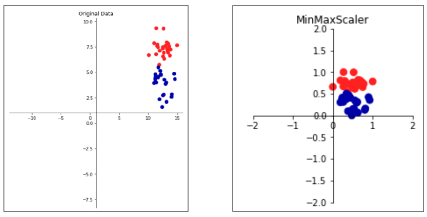
MinMax Scaler
- 데이터를 0 ~ 1 사이 값으로 변환
- 음수인 값이 있다면 -1 ~ 1 사이로 변환
- 이상치가 있다면 사용하기 힘듦
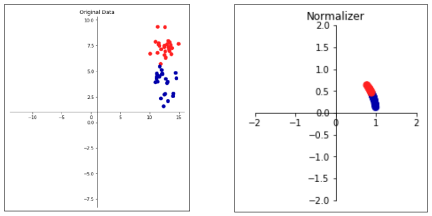
Normalizer
- 데이터를 지름이 1인 원에 투영시킴
- 데이터의 거리는 상관없고 방향(각도)만 중요할 때 사용
- 예: 단어의 유사도 판단
Linear Model (선형 모델)
- 입력 특성에 대한 선형 함수를 만들어 예측 수행
- 입력 특성: 정답을 예측하게끔 하는 문제 데이터
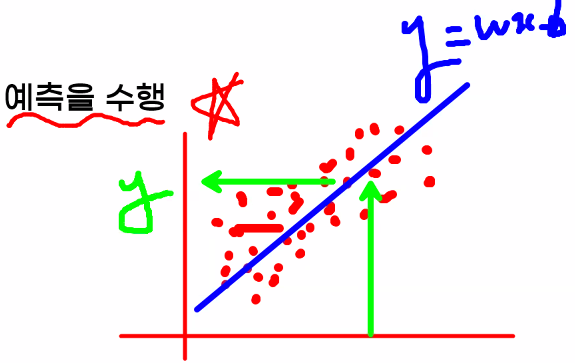
- 각각의 입력 특성들이 결과에 영향을 미치는 가중치를 계산 → 한 개의 직선을 만듦
- 입력 특성: 정답을 예측하게끔 하는 문제 데이터
- 다양한 선형 모델이 존재
- 분류와 회귀에 모두 이용 가능
- 회귀 분석: 예측값이 평균과 같이 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법

- y: 종속 변수
- w: 가중치(weight), 계수(coefficient) → 기울기
- x: 독립 변수
- b: 편향(bias), 절편(intercept)
model.coef_ # 모델 w 파라미터
model.intercept_ # 모델 b 파라미터MSE(Mean Squared Error; 평균제곱오차)
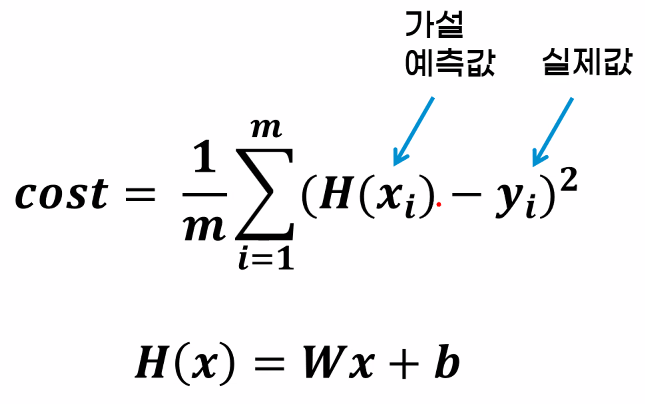
- 데이터 포인트를 가장 잘 나타내는 선 → 평균제곱오차가 최소인 w와 b(==직선) 찾기
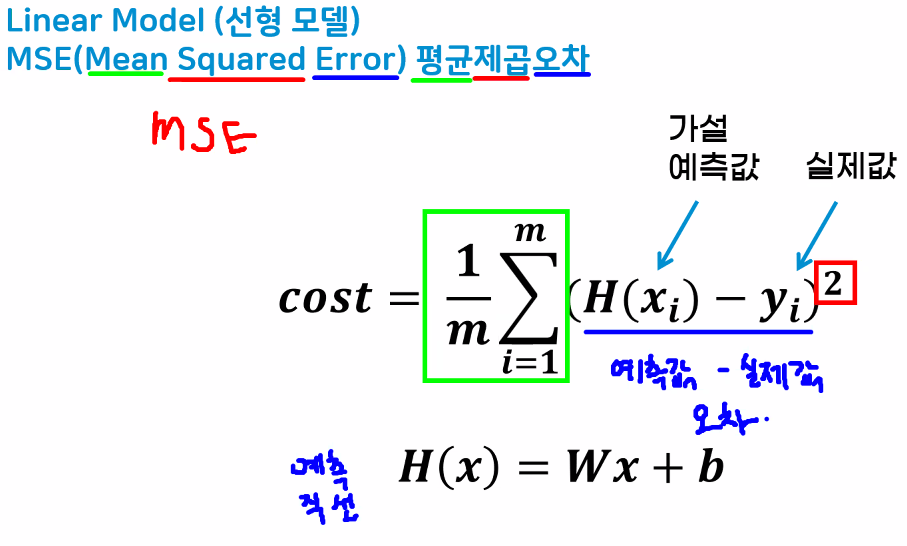
비용함수(Cost function)
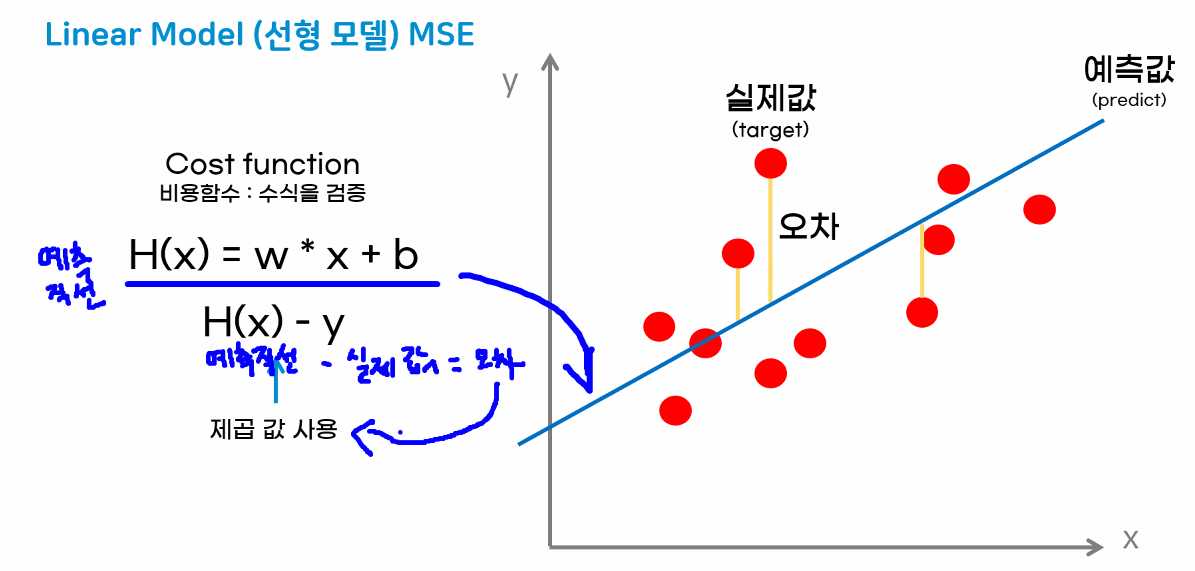
- 제곱 값을 사용하는 이유: 오차 합/평균 구할 때 상쇄되는 문제를 해결
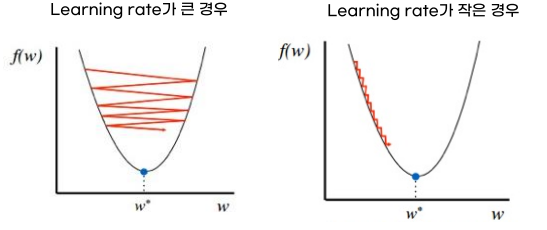
경사하강법(Gradient Descent Algorithm)
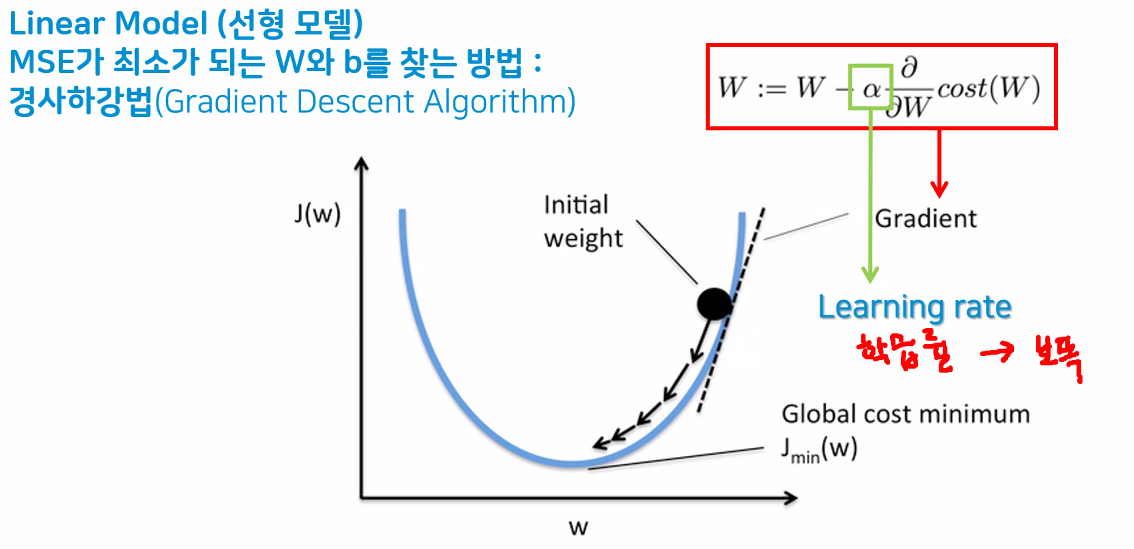
- MSE가 최소가 되는 w와 b를 찾는 방법
- 비용함수의 기울기(경사)를 구해 기울기가 낮은 쪽으로 계속 이동하여 값을 최적화하는 방법
- learning rate가 큰 경우
- 비효율적 학습
- learning rate가 작을 경우
- 시간이 오래 걸림
- 정해진 반복 횟수 내에 최적점에 도달하지 못할 수 있음
장단점
- 장점
- 결과예측(추론) 속도가 빠름
- 대용량 데이터에도 충분히 활용 가능
- 특성이 많은 데이터 세트에 훌륭한 성능을 냄
- 단점
- 특징이 적은 저차원 데이터에는 다른 모델의 일반화 성능이 더 좋을 수 있음
- LinearRegression Model은 복잡도를 제어할 방법이 없어 과대적합 되기 쉬움
- 모델 정규화(Regularization)을 통해 과대적합 제어
CAREER UP
EST AID 소개
-
주식회사 이스트에이드
- zum, vonvon, mevu, pikicast, DeepDiveAD 서비스 중
- 비즈니스 AI 프로필 앱 mevu -> 개인 프로필로 확장
- egloos AI 베타 오픈
- zum: ai 5분 이슈 캐스트 서비스
- zum, vonvon, mevu, pikicast, DeepDiveAD 서비스 중
하루 돌아보기
👍 잘한 점
- 짝궁에게 원핫 인코딩에 대해 설명해주며 개념을 다시 다졌음
- 교차 검증에 대해 배우기 전에 스스로 train 데이터 안에서 다시 한번 쪼개서 돌려보는 시도를 했다는 점
👎 아쉬웠던 점
- 인코딩 및 데이터 스케일링에서 하나씩만 배워서 아쉬웠음
- 따로 정리함
🔬 개선점
- 저녁 8 - 10시 사이에 강의 녹화본이 올라오면 그걸 보면서 복습하는 시간을 가졌었는데 녹화본 올라오는 시간이 일정하지 않아 오히려 불편한 부분이 있어 다음 주부터는 아래와 같이 진행하기로 결정
- 강의 끝나면 바로바로 복습하고 정리
- 강의 듣다가 궁금해진 부분/더 알고 싶은 부분은 표시만 해 두고 저녁에 따로 채워넣기
- 강의 중 놓친 부분은 일단 표시해 두고 그 다음날 보충
- 원래 자연어처리 관련 논문 같은 걸 읽으려고 했는데 강의 내용 복습과 자연어처리 과정 시작 전 제공된 강의들 복습하는 데 시간이 많이 걸려서 계획대로 하지 못했음
- 지급된 강의 복습은 이번 주말에 끝내고 다음 주부터는 본 강의에만 집중하기
- 한 번에/한 주에 전부 읽지 않아도 좋으니 최대한 관련 논문이나 뉴스 챙겨보기

2 B R 0 2 B