[인공지능사관학교: 자연어분석A반] HTML (2) / 텍스트마이닝 (9)
오전: WEB
1교시: 하이퍼링크
h 태그: 숫자에 따른 글자 크기 변화와 의미
b 태그와 strong 태그의 기능적 차이
html에서 a 태그와 href 속성의 역할은?
지난 시간 복습
- HTML 정의와 역할
- 하이퍼텍스트 마크업 언어의 약자
- 웹페이지에서 다양한 뼈대를 만듦 → '표시'해주는 역할
- HTML 문법은 태그(Tag)라는 개념 하나로 구성
- 시작태그와 끝태그
- Content(내용)
- 위의 두 가지를 합쳐 "element"
- 속성(Attribute)과 값(value)
- 태그는 약 150개 이상 존재하지만 실제로는 30~40개만 주로 사용됨
- 과거 디자인을 담당하던 태그들 → CSS 등장 이후 미사용
- 속성의 개념과 역할
- 태그에 기능이나 꾸밈을 추가할 때 속성을 사용
- 시작 태그 안에 이름과 값을 넣음
- 속성 종류는 태그보다 훨씬 많음
- 태그에 기능이나 꾸밈을 추가할 때 속성을 사용
- 기본 구조: head와 body
- 헤드는 기능적 코드나 디자인 코드를 넣는 공간
- 바디는 화면에 보이는 모든 컨텐츠(글자, 이미지, 표 등)를 담는 영역
- HTML 태그
- 영역 표시: 큰 영역부터 작은 영역 순으로
- 제목 태그: h1~h6
- 숫자가 커질수록 글자 크기가 작아짐
- 문서의 제목 구조를 의미
- h1은 최상위 제목(페이지에서 단 한 번만 쓰는 것 권장)
- h2~h6은 하위 제목 역할 → h5, h6은 사용 빈도 낮음
- 문단(paragraph) 태그: p
- 문단을 만드는 태그
- 안에 들어 있는 글자가 적어도 한 줄 전체 너비를 차지
- 자동 줄 바꿈과 위아래 공백 생김
- 문장: span
- "span"이라는 단어는 영어로 "범위" 또는 "간격"을 의미
- 자체적으로 특별한 의미가 전혀 없는 인라인 컨테이너
- 아무 기능 없는 껍데기 태그로 특정 문장이나 단어 영역을 표시하 ㄹ때 사용
- 화면에 변화는 없으며, 스타일이나 스크립트 적용 시 특정 부분만 선택 가능하게 함
- 자동 줄 바꿈이 발생하지 않고 글자 옆에 붙는 형태
- br
- 태그 안에서 글자와 글자 사이 줄 바꿈을 할 때 사용
- 태그와 태그 사이 공백을 위해 쓰면 안 됨 → 태그 간 간격 조정은 CSS에서 Margin 속성으로 처리
- b, strong
- 두 태그 모두 글자를 두껍게 표현하지만, 기능적 차이가 있음
- b 태그는 단순 시각적 강조
- strong 태그는 스크린 리더 등에서 악센트 강조로 읽음
- 현재 개발 트랜드에서는 strong 사용을 권장
3. HTML 태그 (cont'd)
하이퍼링크: a tag (anchor)
- 클릭 시 특정 페이지 혹은 특정 사이트로 이동하는 하이퍼링크를 만듦
- 컨텐츠와 특정 사이트 or 페이지를 연결
<a href="url">: 하이퍼링크를 만들 때 사용하는 태그- a: anchor라는 뜻
- 기능을 담당하는 태그로 속성 사용이 필수임: href
- href: hyper-reference
- 링크할 주소를 지정하는 속성
- a 태그 내에 반드시 포함되어야 함
- 주소는 작은 따옴표나 큰 따옴표로 감싸며, 실제 이동할 url을 작성함
- url 작성 시 통신 프로토콜(http/https) 꼭 붙여야 함
- http는 기본 통신 프로토콜이며 https는 보안이 강화된 프로토콜임(s가 security)
- https는 SSL 인증서를 보안이 강화되며(유료), 현재는 거의 모든 사이트에서 표준으로 사용됨
<a href="https://www.naver.com">네이버로 이동</a>
- href: hyper-reference
- 컨텐츠와 특정 사이트 or 페이지를 연결하는 하이퍼링크 태그
- 포인트: 반드시 속성에 href를 작성한다 → href = "이동할 주소"
- 기능을 담당하는 태그는 필수 속성이 존재하는 경우가 많음
- 주의점: url을 작성할 때는 반드시 http/https를 붙여준다!
- href에 주소를 적기 않거나 프로토콜을 생략하면 링크가 작동하지 않음
라이브 서버 단축키: alt+L+O
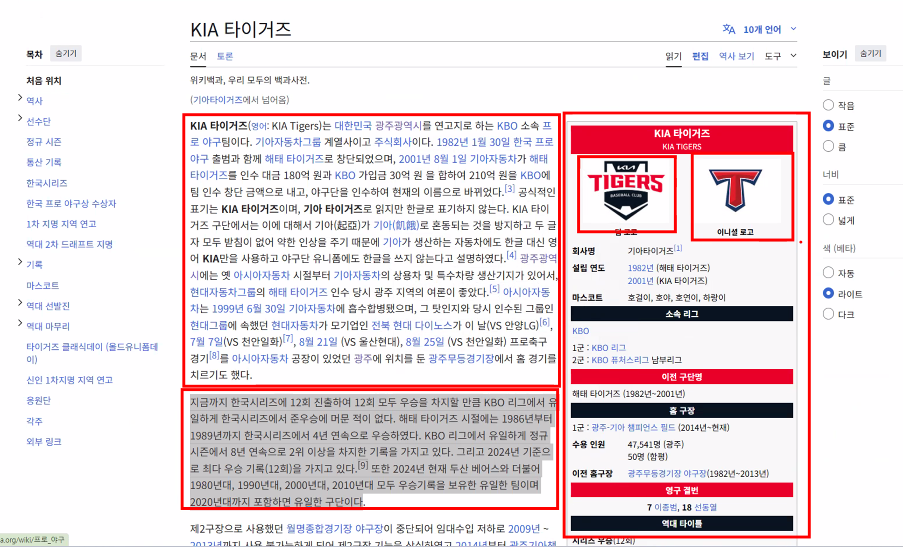
실습: 위키 백과 만들기

- 사용하는 태그
- h1
- p
- strong
- a
- url은
https://ko.wikipedia.org/wiki/%EA%B4%91%EC%A3%BC%EA%B4%91%EC%97%AD%EC%8B%9C사용
- url은
- 사실 페이지 구현에서 가장 어려운 건 문단 배치임
- 나중에 CSS 수업에서 다룰 예정
- 나중에 CSS 수업에서 다룰 예정
- 내용이 정확한 페이지를 만들 경우 영역 먼저 설정하고 내용을 나중에 적는 걸 권장
- tip
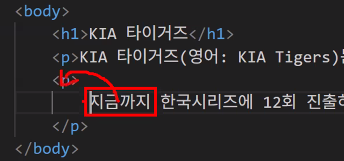
- p 태그를 여러 개 만들고 싶을 때
p*2하면<p></p>두 개 생성됨 - 태그 입력 시 첫 번째 p처럼 한 줄로 적는 것보다 두 번째 p 같이 작성해야 가독성이 좋음 (권장)
→ 태그 안에 태그가 있는 경우에만! (태그 안에 글자만 있는 경우에는 한 줄로 쓰는 게 좋음)
- p 태그를 여러 개 만들고 싶을 때
- tip
1교시 정리
- 핵심 개념
- html은 웹페이지의 구조를 만드는 마크업 언어
- 태그와 속성으로 구성
- a 태그는 하이퍼링크를 만듦
- 반드시 href 속성을 가지고 있어야 함 (url 포함)
- 핵심 단어
- a 태그
- href
- 하이퍼링크
- 요약
- html 기본 구조와 주요 태그 복습
- 하이퍼링크: a 태그와 href 속성
- url 작성 시 http/https 프로토콜 필수
- html 문서 작성 시 가독성 좋은 스타일
- 기본 페이지 구성법
2교시: 리스트, 이미지
ol 태그와 ul 태그의 차이점
이미지 태그에서 절대 경로와 상대 경로의 차이
부모, 자식, 형재 태그 관계
3. HTML 태그 (cont'd)
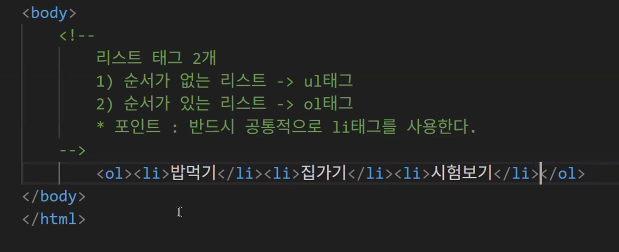
목록 만들기: li, ol, ul
- 리스트 형태를 만드는 태그
- 순서가 있는 리스트
<ol>: Ordered list<li>: list
- 순서가 없는 리스트
<ul>: Unordered list<li>: list
- 순서가 있는 리스트
- 무조건
<li>와 함께 써야 함- 컴퓨터와는 태그만으로 소통 → ol/ul 안의 내용이 각각 무엇인지 컴퓨터에게 알려줘야 함 → li 사용
- 리스트 태그 2개
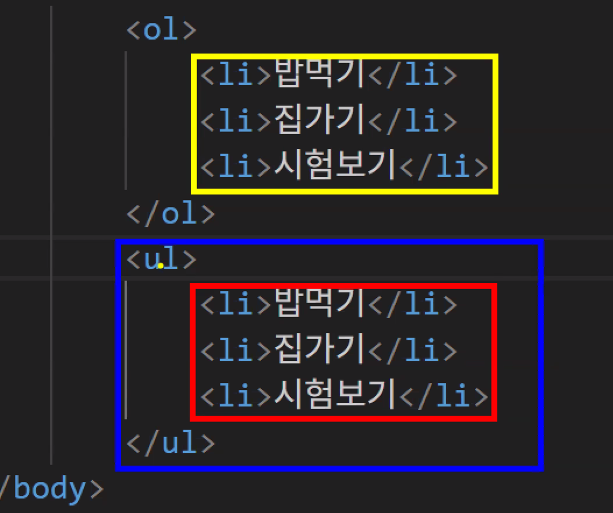
1) 순서가 없는 리스트: ul 태그 → 점이나 순서 없는 표시가 나옴
2) 순서가 있는 리스트: ol 태그 → 번호가 나옴 - 두 태그 모두 리스트를 만든다는 개념은 같음
- ol, ul 차이점: 순서 유무에 따른 리스트 생성
- 포인트: 반드시 공통적으로 li 태그를 사용한다.
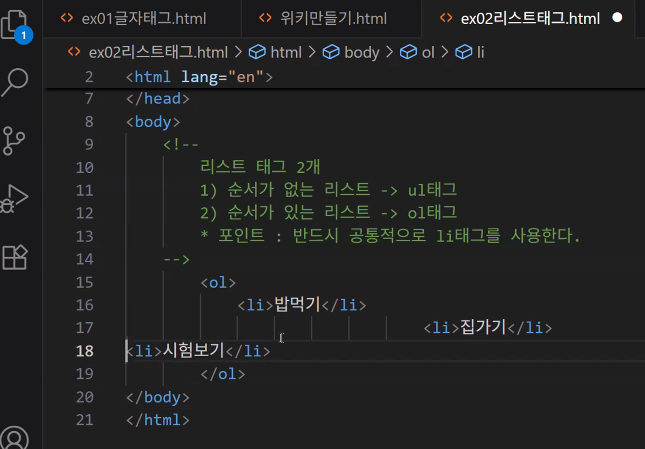
- 포인트 2: 태그 안에 태그를 포함할 때는 탭으로 구분짓는다 → 가독성을 위해서
- ★ 사용처, 팁: 네비게이션 바의 하단 메뉴를 만들 때 사용한다.→ ul로 만들고 css로 마크를 숨긴다. ★
- ol/ul 태그가 리스트 공간 역할을 하며 li 태그가 각각의 리스트 항목 역할을 함
- 태그 내에 태그를 포함할 때는 가독성을 위해 탭으로 들여쓰기하여 계층 구조를 명화히 표현해야 함
추가: 태그 가독성 문제 - 코딩 스타일과 가독성
- 영역부터 먼저 만들고 내용을 채우는 방식 권장
- 코드 작성 시 탭과 들여쓰기를 통해 가독성 향상
- 들여쓰기를 하지 않아도 오류가 발생하지 않으나 한 줄로 적으면 가독성이 매우 떨어짐
- 들여쓰기를 마음대로 해도 오류는 발생하지 않으나 역시 가독성이 매우 떨어짐
- 따라서 태그 포함 관계를 명확히 하기 위해 반드시 들여쓰기를 하는 것이 권장됨
추가: 부모-자식-형제 태그 관계
- 부모 태그는 자신을 감싸고 있는 태그, 자식 태그는 안에 포함된 태그를 의미
- 같은 부모를 가진 태그는 형제 태그 관계
- 위에서 ul이 부모, li가 자식, li끼리는 형제 관계
- 실제 사용 빈도와 사용처
- 실제 웹 개발에서는 ul 태그가 ol 태그보다 훨씬 더 많이 사용됨
- 주료 메뉴 바, 네비게이션 바 등에서 리스트를 만들 때 사용
- CSS로 점 표시를 숨기는 것이 최신 트랜드
- 개발자 설정 모드에서 해당 설정을 해제해 볼 수 있음
- CSS로 점 표시를 숨기는 것이 최신 트랜드
- 리스트 태그는 글자 위주의 사이트나 메뉴 구성에 주로 사용되며 일반 컨텐츠에서는 많이 쓰이지 않음
추가: 웹 디자인 팁
- 웹 디자인에서 심플함의 중요성
- 배경은 흰색 또는 미색 사용
- 글자는 검은색
- 흰색 배경에 검은색 글자 조합이 가장 깔끔하고 무난
- 포인트 색상만 사용하는 것이 깔끔
- 배경 이미지 사용은 권장하지 않음
- 단색 배경(흰색 혹은 옅은 색) 사용하는 것이 좋음
실습: 위키 백과 만들기

이미지: img
- 이미지를 불러오는 태그: img
- 이미지 태그는 여는 태그만 존재하는 홀태그 구조
- img 태그는 닫는 태그가 없으며, 컨텐츠를 포함하지 않고 이미지만 불러옴
- br 태그와 같은 구조
- 필수 속성 존재: src
- src 속성에 불러올 이미지 파일의 경로 지정
- 이미지는 태그의 경로는 링크 연결 개념이 아닌 이미지 파일을 불러오는 역할
- 파일을 불러오는 방법 2가지 → 방식이 다르다는 건 쓰임이 다르다는 의미!
1) 파일을 직접 불러오는 파일 로드 방식: 파일을 내가 가지고 있을 때(내 작업 환경에 이미지 파일이 직접 존재할 때)- 장점: 안정성(내가 지우지 않으면 삭제 X)
- 파일을 직접 가지고 있어 안정적이며, 파일 삭제 전까지 항상 사용 가능함
- 단점: 용량을 차지한다. → 파일 관리하는 서버가 따로 존재
- 이미지 파일이 많아질수록 용량이 커지고 서버 비용이 증가할 수 있음
2) 네트워크를 통해서 불러오는 CDN(Content Delivery Network): 파일이 나한테 없을 때(네트워크를 통해 외부 서버에 있는 이미지를 불러오는 방식) - 장점: 용량을 차지하지 않는다. / 코드를 공유할 때 활용한다. ← 인터넷만 되면 누구나 쓸 수 있음
- 코드 공유 시 유용
- 용량 차지하지 않고 인터넷 연결만 있으면 어디서든 이미지 사용 가능
- 단점: 원본이 사라지면 사용이 불가능
- 원본 이미지가 삭제되면 사용할 수 없음
- 네트워크 연결이 필수임
- 장점: 안정성(내가 지우지 않으면 삭제 X)
상대 경로 vs. 절대 경로 ★★★
- 상대 경로: 현재 작업 중인 파일을 기준으로 작성하는 경로 → 파일마다 경로가 바뀜
- 파일이 폴더에 들어간 경우에는 '폴더명/파일명' 순으로 작성한다. (/: 한 번 안으로 들어가겠다는 뜻)
- 현재 파일을 기준으로 폴더를 한 번 나갈 때는 '../'를 작성한다.
- 현재 파일을 기준으로 폴더를 여러 번 나갈 때는 나갈 수만큼 '../'를 작성한다.
- 절대 경로: 루트 폴더를 기준으로 작성하는 경로 + 누구나 접근할 수 있는 경로(url 절대 경로)
- 경로의 맨 앞에 '/'를 넣으면 최상위 폴더인 root 폴더를 찾는다.
- 같은 워크스페이스 안에 존재하는 파일들은 다 같은 root 폴더를 가지고 있다.
- 같은 경로로 파일 호출 가능
- 경로에 url 경로를 넣는다면 모든 파일이 똑같은 경로를 호출한다.
- 경로의 맨 앞에 '/'를 넣으면 최상위 폴더인 root 폴더를 찾는다.
- 절대 경로는 루트 폴더 또는 URL 기준으로 작성하는 경로
- 웹에서는 누구나 접근 가능한 URL 경로를 절대 경로로 사용
- 상대 경로는 현재 작업 중인 파일 위치를 기준으로 작성하는 경로
- 현재 HTML 파일 위치를 기준으로 이미지 파일 위치를 지정함
- 상대 경로 사용 시 폴더 구조 이해 필요
- 이미지 파일이 별도의 이미지 폴더에 있을 경우 경로에 폴더명을 포함하여 지장해야 함
- 같은 폴더 내에 있을 경우 파일명만 적으면 됨
- 경로 작성 시 출발지와 목적지 개념 이해
- 경로는 목적지(불러올 파일 위치)가 마지막에 오며, 앞부분을 출발지와 경유지를 나타냄
- 경로 지정 오류 시 이미지가 나타나지 않음
2교시 정리
- 핵심 개념
- ol, ul은 순서 유무에 따른 리스트 태그
- 이미지 태그는 src 속성으로 파일 경로를 지정해야 함
- 핵심 단어
- ol, ul, li
- 부모-자식 관계
- img, src
- 절대 경로, 상대 경로
- CDN(Content Delivery Network)
- 강의 요약
- ol 태그와 ul 태그의 차이점
- 태그 안에 태그가 포함되어 있을 때 들여쓰기의 중요성
- 이미지 태그의 구조와 src 속성
- 파일 로드 방식과 CDN
- 절대 경로롸 상대 경로의 개념
- 폴더 구조에 따른 경로 지정 방법
3교시
3. HTML 태그 (cont'd)
상대 경로와 절대 경로(cont'd)
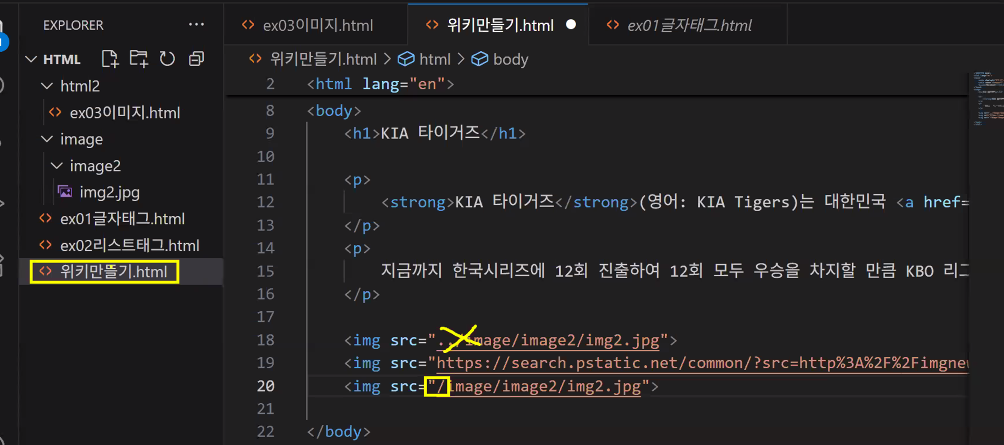
- 상대 경로의 개념과 활용
- 상대 경로: 현재 작업 중인 파일 위치를 기준으로 경로를 작성하는 방법
- 폴더를 들어갈 때는 폴더명과 슬래시(/)를 사용해 구분
- 폴더를 나갈 때는 점 두 개(..)와 슬래시(/)를 사용 → 나가는 횟수만큼 반복
- 예:
HTML>HTML2>HTML3폴더가 있고 HTML3에서 HTML까지 나가서 이미지를 찾는 경로라면../../HTML/image.jpg형태
- 상대 경로는 파일마다 위치가 다르기 때문에 경로가 달라짐
- 작업 중인 파일 위치를 기준으로 경로를 관리하는 것이 핵심
- 상대 경로를 정확히 이해해야 올바른 파일 호출이 가능
- 상대 경로: 현재 작업 중인 파일 위치를 기준으로 경로를 작성하는 방법
- 절대 경로의 개념과 활용
- 절대 경로: 루트 폴더(최상위 폴더)를 기준으로 경로를 작성하는 방법
- 경로 맨 앞에 슬래시(/)를 붙여 루트 폴더로 이동함을 표시
- URL 절대 경로는 인터넷 상의 주소를 그대로 사용하여 어느 환경에서나 동일하게 작용함
- 절대 경로: 루트 폴더(최상위 폴더)를 기준으로 경로를 작성하는 방법
- 상대 경로는 파일 위치에 따라 경로가 달라지지만 절대 경로는 루트 폴더를 기준으로 고정되어 있어 현업에서는 절대 경로 사용이 많음
- 두 가지 경로 방식의 차이점과 사용 상황을 명확히 이해하는 것이 중요
VisualStudioCode 설정: 폴더 경로 표시 형식 변경
표 만들기: table, tr, th, td
- 표 형태를 만드는 태그
- table: 표의 틀을 담당하는 태그
- 여러 개의 속성 존재

- 여러 개의 속성 존재
- tr: 표의 행을 담당하는 태그
- td, th: 표의 열을 담당하는 태그
- table: 표의 틀을 담당하는 태그
- 표는 행(row)과 열(column)로 구성
- 행은 가로줄, 열은 세로칸을 의미
- 표의 첫 번째 행은 보통 컬럼명(헤더)으로 구성되며, 데이터는 그 아래 행에 위치
- 즉, 표는 기본적으로 행과 열의 구조를 가지며 컬럼과 데이터로 나누어짐
- 표 →
<table>, 행 →<tr>, 열: 컬럼명 →<th>, 열: 데이터 →<td>
- 표 →
- 표 작성에 필요한 4가지 주요 태그
<table>- 전체 표 영역을 감싸는 태그
- 가장 큰 공간을 담당함
<tr>- 표의 한 줄(행)을 나타내는 태그
- 여러 개의 tr이 모여 표를 구성
<th>- 표의 컬럼 헤더를 나타내는 태그
- 글자가 두껍고 중앙 정렬이 기본값임
<td>- 표의 데이터 셀을 나타내는 태그
- 일반 데이터가 들어가는 칸
- 표는 큰 영역부터 작은 영역 순서로 작성
- table을 만들고 그 안에 tr로 줄을 나누고 각 줄 안에 th 또는 td로 칸을 나눔
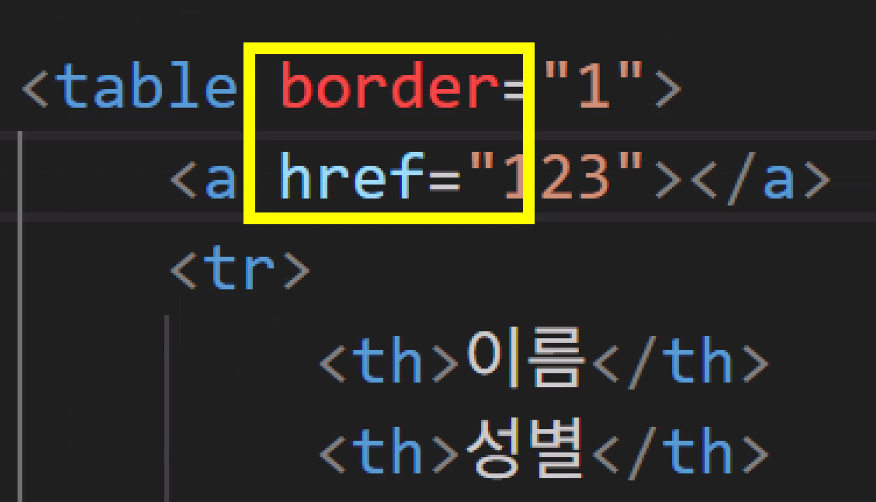
- 표 디자인과 스타일링: CSS 등장 이전 방식
- 기본 테두리(border) 설정
- table 태그에 border 속성을 지정하면 표에 테두리가 추가됨(예: border="1")
- 하지만 border 속성은 과거 방식으로 CSS 등장 이후 권장되지 않음 → 코드 작성 시 경고 표시(빨간색)
- 태두리 스타일 구성 요소와 CSS와의 차이점
- 테두리는 선의 굵기, 색깔, 종류(실선, 점선 등) 설정 가능
- CSS에서는 좀 더 세밀한 디자인 조절이 가능
- 표 배경색 지정
- 표의 한 줄 전체에 배경색을 넣고 싶을 때는 tr 태그에 색상을 지정하는 것이 hd에 지정하는 것보다 효율적
- 배경색 역시 css에서 관리하는 디자인 요소로 html 속성(bgcolor)으로 지정하는 것은 권장되지 않음
- 표 텍스트 정렬 속성
- 텍스트 정렬은 align 속성으로 지정할 수 있으나 이 또한 디자인 요소로 CSS에서 처리하는 것이 권장됨
- 기본 테두리(border) 설정
- 여러 줄에 일일이 속성을 지정하는 것은 비효율적이며, CCS 사용이 현대적 방법
실습: 표 만들기

- 4개의 태그가 필요
1) table: 전체 테이블의 영역을 담당하는 태그 (가장 큰 태그)
2) tr: 가로 줄을 만드는 태그(table row) → 행을 제작하는 태그
3) th, td- th: 컬럼을 쪼개는 태그
- td: 칸(데이터)을 쪼개는 태그
3교시 정리
- 핵심 개념
- 상대 경로는 현재 파일 위치 기준으로 폴더 진입과 나가기를 점과 슬래시로 표현
- 절대 경로는 루트 폴더 기준으로 고정된 경로를 사용
- html 표는
<table>,<tr>,<th>,<td>네 가지 태그로 구성되며 행과 열로 데이터를 구조화함
- 표의 테두리와 배경색 등 디자인 요소를 다루는 속성은 옛날 방식으로 현대적 방식은 CSS를 이용해 처리
- 핵심 단어
- 상대 경로
- 절대 경로
- 루트 폴더
- html 표
- 요약
- 상대 경로는 현재 파일 위치 기준으로 폴더 진입과 나가기를 점과 슬래시로 표현
- 절대 경로는 루트 폴더 기준으로 고정된 경로를 사용
- html 표는
<table>,<tr>,<th>,<td>네 가지 태그로 구성되며 행과 열로 데이터를 구조화함- 표 디자인은 과거 방식인 html 속성 대신 CSS 사용을 권장
오후: NLP
4교시: 질의응답 - 토큰화
지난 시간 복습
- 질의응답 태스크
- 주어진 질문에 대한 답변 제공
- 추출척 질의응답
- 주어진 문맥에서 답변을 추출
- 문맥 데이터(context)에서 답을 찾아 그대로 답변해 주는 것
- 주요 필드 설명
- title: 해당 데이터의 주제
- context: 본문 → 질문에 대한 답을 찾을 배경 지식
- news_category: context 카테고리
- question: 모델이 답해야 하는 질문
- answers
- answer_start: context에서 정답의 시작 위치
- text: 정답 텍스트
- QA 전처리 핵심 요약
- 질문 데이터(Questioin)와 본문 데이터(Context)를 가지고 학습
- 2개를 하나로 묶어서 토크나이징
- 어디서부터 질문이고 어디서부터 본문인지 알아야 함 → 토큰으로 알리기
- 정답 문자열의 시작/끝 토큰의 위치를 계산해야 함
start_positions,end_position
offset_mapping: 현재 단어가 본문에서 몇 번째 문자 범위인지 알려주는 정보
| 항목 | 설명 |
|---|---|
| 🎯 목적 | 질문 + 지문(context)을 토큰화하고, 정답의 시작/끝 위치를 토큰 인덱스로 변환 |
| 📎 입력 구성 | [CLS] question [SEP] context [SEP] 형태 |
| 🧭 위치 변환 | 정답의 문자 위치 → 토큰 위치 변환 (offset_mapping 사용) |
| ⚠️ 주의점 | context가 잘릴 경우 정답이 사라질 수 있음 → 이때 start=0, end=0 처리 |
토큰화
offset_mapping의 형태
- 본문에서 정답의 실제 위치를 추출할 때 사용
- 학습에는 필요가 없음 → pop을 이용해 제거
# offset_mapping
[
(0, 0), # [CLS] → 특수 토큰
(0, 5), # "대한민국"
(5, 6), # "의"
(7, 9), # "수도"
(9, 11), # "는"
(12, 15), # "어디"
(15, 17), # "인가"
(17, 18), # "?"
(0, 0), # [SEP] → 특수 토큰
(0, 5), # "대한민국"
(5, 6), # "의"
(7, 9), # "수도"
(9, 11), # "는"
(12, 14), # "서울"
(14, 16), # "이다"
(16, 17), # "."
(0, 0), # [SEP]
(0, 0), (0, 0), ... # 패딩
]QA 토크나이징 결과 구조
| Key | 설명 |
|---|---|
input_ids | 토큰 ID로 변환된 문장 |
token_type_ids | 0(question), 1(context)로 구분 |
attention_mask | 실제 토큰이면 1, 패딩이면 0 |
offset_mapping | 각 토큰이 원래 문장의 어느 문자 구간인지 (start, end 인덱스) |
def preprocess_function (example):
# 질문의 앞뒤 공백 제거
question = [q.strip() for q in example["question"]]
inputs = tokenizer(
question # 질문
, example["context"] # 본문
, max_length=384
, truncation="only_second" # question은 자르지 않고 context만 자르겠다는 뜻
, padding="max_length"
, return_offsets_mapping=True # 각 토큰이 원문에서 어느 문자 범위였는지 반영
)
# offset_mapping: 원본 본문 → 실제 문자 위치 정보
offset_mapping = inputs.pop("offset_mapping") # offset_mapping은 학습에서는 사용 x → 오류 발생 최소화를 위해 제거
answers = example["answers"]
# 모델이 학습할 수 있도록 정답의 시작 위치, 끝 위치 list에 저장하기
start_positions = []
end_positions = []
# 정답의 시작 위치, 끝 위치 담기
for i, offset in enumerate(offset_mapping): # i는 미니배치 내에서 몇 번째 샘플인지를 의미
answer = answers[i] # i번째 샘플의 정답
# 정답의 시작 위치
start_char = answer["answer_start"][0]
# 정답의 끝 위치
end_char = start_char + len(answer["text"][0])
# sequence_ids → 각 토큰이 question(0)인지 context(!)인지 정보를 가지고 있음
# sequence_ids = [None, 0, 0, 0, 0, 0, 0, 0, None, 1, 1, 1, 1, 1, 1, 1, 1, 1, None, None, ..., None]
sequence_ids = inputs.sequence_ids(i)
idx = 0
# context 시작 위치를 찾기
while sequence_ids[idx] != 1: # question
idx += 1
context_start = idx
# context 끝 위치를 찾기
while sequence_ids[idx] == 1: # context
idx += 1
context_end = idx - 1
# 정답에 해당하는 시작, 끝 토큰 인덱스(start_positions, end_positions)를 찾아서 담아주기
# 정답이 토큰화 후 결과 context 안에 들어있어야지 positioning을 할 수 있음
# 정답이 context 영역 안에 존재하는지 확인 (존재하지 않으면 (0,0)값 넣기)
if offset[context_start][0] > end_char or offset[context_end][1] < start_char: # offset → i번째 샘플의 "토큰별 (시작, 끝) 문자 위치 튜플 리스트"
start_positions.append(0)
end_positions.append(0)
else: # 정답이 context 안에 있는 경우
idx = context_start
# 정답의 시작 값 찾기(start_positions)
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx-1) # 반복문 종료 시점은 정답보다 한 칸 후 → 이전 토큰 시점을 저장해야 함
# 정답의 끝 값 찾기(end_positions)
idx = context_end # 끝에서부터 앞으로 계산
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx+1) # 반복문 종료 시점은 정답보다 한 칸 앞: 역방향 계산 → 이전 토큰 시점을 저장
# Hugging Face 모델 학습용 딕셔너리 형태로 넣어주기
inputs["start_positions"] = start_positions
inputs["end_positions"] = end_positions
return inputs-
추가: while 루프로 인덱스 찾기 말고도 파이썬에서 다른 간단하고 직관적인 방법들이 존재함
-
리스트 컴프리헨션 + enumerate 사용
- 가장 간단하고 파이썬스러운 방법입니다.
indices리스트에 1의 위치만 모으고, 시작/끝을 바로 뽑으면 됩니다.
sequence_ids = [None, 0, 0, 0, 0, 0, 0, 0, None, 1, 1, 1, 1, 1, 1, 1, 1, 1, None, None] indices = [i for i, x in enumerate(sequence_ids) if x == 1] context_start = indices[0] context_end = indices[-1] -
index(), rindex() 사용
index(): 처음 등장하는 인덱스list.reverse()+index()또는len-1-list[::-1].index(1)로 마지막 인덱스 구하기
context_start = sequence_ids.index(1) context_end = len(sequence_ids) - 1 - sequence_ids[::-1].index(1) -
numpy 사용
- 데이터가 크거나 성능이 필요하면 numpy의
np.where이용 가능합니다.
import numpy as np arr = np.array(sequence_ids) indices = np.where(arr == 1)[0] context_start = indices[0] context_end = indices[-1] - 데이터가 크거나 성능이 필요하면 numpy의
-
itertools 사용
from itertools import dropwhile # 시작 인덱스 context_start = next(i for i, x in enumerate(sequence_ids) if x == 1) # 끝 인덱스 context_end = len(sequence_ids) - 1 - next(i for i, x in enumerate(reversed(sequence_ids)) if x == 1)
-
요약: 원하는 스타일에 따라 선택하자
- 가장 직관적이고 간단하게 하고 싶으면 리스트 컴프리헨션
- 한 번씩만 찾고 싶으면 index와 슬라이싱
- 성능 최적화면 numpy
- 복수 정답까지 고려하고 싶다면 작성한 for문 밖에 for문을 하나 더 작성하면 됨
start_char = answer["answer_start"][0]에서[0]의 숫자를 0, 1, 2로 증가시키는 for 문!
5교시: 함수 적용, 모델 훈련
오프셋 매핑(offset_mapping)이 학습에 사용되지 않는 이유는?
정답의 시작 위치와 끝 위치를 찾는 과정에서 컨텍스트 내 포함 여부를 어떻게 판단하나요?
while 문 반복 조건에서 idx 값과 정답 위치의 관계는 어떻게 설정되나요?
함수 설명
-
입력 데이터에서 앞뒤 공백 제거 후 토크나이저에 적용하여 토큰화 진핸:
question = [q.strip() for q in example["question"]] -
오프셋 매핑과 정답 위치 처리
- 오프셋 매핑의 정의와 역할
- 오프셋 매핑을 텍스트 내 실제 위치 정보를 담아 토크나이저 처리 후 정답 위치를 찾기 위한 시작 위치와 끝 위치를 제공
- 토크나이저가 텍스트를 분할하면 원문 위치 정보가 사라지므로 오프셋 매핑으로 위치를 보존
- 오프셋 매핑의 학습 처리 제외
- 오프셋 매핑은 위치 정보 제공 목적이므로 학습에 직접 사용하지 않음
- 따라서 입력 데이터에서 오프셋 매핑 관련 정보는 변수에 저장 후 제거(pop) → 학습 입력에서 제외하기
- 오프셋 매핑의 정의와 역할
| 입력 구성 | offset_mapping | idx | sequence_ids |
|---|---|---|---|
[CLS] → 특수 토큰 | (0, 0) | 0 | None |
| "대한민국" | (0, 5) | 1 | 0 |
| "의" | (5, 6) | 2 | 0 |
| "수도" | (7, 9) | 3 | 0 |
| "는" | (9, 11) | 4 | 0 |
| "어디" | (12, 15) | 5 | 0 |
| "인가" | (15, 17) | 6 | 0 |
| "?" | (17, 18) | 7 | 0 |
[SEP] → 특수 토큰 | (0, 0) | 8 | None |
| "대한민국" | (0, 5) | 9 | 1 |
| "의" | (5, 6) | 10 | 1 |
| "수도" | (7, 9) | 11 | 1 |
| "는" | (9, 11) | 12 | 1 |
| "서울" | (12, 14) | 13 | 1 |
| "이다" | (14, 16) | 14 | 1 |
| "." | (16, 17) | 15 | 1 |
[SEP] | (0, 0) | 16 | None |
| 패딩 | (0, 0) | 17 | None |
- 정답 위치의 컨텍스트 포함 여부 확인
- 정답의 시작 위치와 끝 위치가 컨텍스트 범위 내에 존재하는지 먼저 확인
- 포함되지 않으면 시작과 끝 위치에 0,0 값을 넣어 학습에서 제외 처리
- 포함되면 이후 위치 탐색 및 저장 작업 진행
정답 위치 탐색 알고리즘
- 정답 시작 위치 탐색 과정
- 오프셋 매핑 리스트를 순차적으로 탐색하며 인덱스가 정답 시작 위치보다 작거나 컨텍스트 끝 위치에 도달하면 반복 종료 조건으로 설정
- 반복문 내에서 현재 위치가 정답 시작 위치와 일치하는지 확인하며, 일치 시 해당 위치를 저장
- 반복 종료 시점에 위치 저장을 위해 인덱스에 -1을 적용해 이전 토큰 위치를 시작 위치로 지정함
- 정답 다음 인덱스에서 종료되기 때문
- 정답 끝 위치 탐색 과정
- 정답 끝 위치 탐색은 역방향으로 진행 ← 컨텍스트 끝 위치부터 시작
- 반복문 조건은 현재 인덱스가 컨텍스트 시작 위치에 도달하거나 정답 끝 위치보다 크거나 같을 때까지 진행함
- 정답 끝 위치를 찾으면 인덱스에 +1을 적용하여 실제 끝 위치를 저장함
- 시작 위치와 끝 위치는 딕셔너리 형태로 토크나이저 입력에 각각
start_position,end_position키로 저장- 딕셔너리 형태는 학습 프레임워크에서 요구하는 데이터 구조에 맞추기 위함
더 알아보기:
inputs가 딕셔너리인 이유와,inputs["start_positions"] = start_positions와 같이 데이터를 할당하는 의미
1. Hugging Face의 사전처리 결과 (inputs)
Hugging Face의tokenizer를 호출하면 반환값은 파이썬 딕셔너리 타입입니다.
예를 들어, 아래와 같이 나옵니다(예시):inputs = tokenizer( question, example["context"], max_length=384, truncation="only_second", padding="max_length", return_offsets_mapping=True ) print(inputs.keys()) # dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping'])각 키는:
input_ids: 토큰화된 숫자 IDtoken_type_ids: segment 구분 정보(question/context)attention_mask: 마스킹 정보offset_mapping: 원본 문자 위치 정보즉, tokenizer의 Output은 딕셔너리 구조입니다.
- start_positions / end_positions를 딕셔너리에 넣는 이유
inputs["start_positions"] = start_positions는
기존의 tokenizer 결과 딕셔너리에
정답의 시작위치, 끝위치 인덱스 정보를 추가하는 것입니다.
이렇게 하는 목적은?
- 모델 학습 시 Hugging Face Trainer 같은 자동화된 학습 도구는 “start_positions”, “end_positions” 등이 필드로 있는 딕셔너리 구조를 기대합니다.
- 즉, 모델은
- “input_ids”, “attention_mask”, … (입력값)
- “start_positions”, “end_positions” (타겟 레이블값)를 함께 필요로 합니다.
- 요약
- tokenizer 출력이 이미 딕셔너리이므로 필요한 추가 정보(정답 위치)도 key-value쌍으로 넣는 것.
- 여러 필드(입력/정답)들을 한 번에 모델로 넘기려면 딕셔너리에 다 담아서 Trainer/모델에 넘깁니다.
즉, inputs는 tokenizer와 이후 처리 결과를 담은 딕셔너리이기 때문에, start_positions, end_positions도 키-값 쌍으로 추가하는 게 자연스럽습니다.
함수 적용
tokenized_sq = dataset.map(preprocess_function, batched=True)- 매핑 함수
- 데이터셋에 적용하여 전처리 및 위치 정보 삽입을 자동화함
모델 훈련
# 훈련 준비
# 모델 불러오기
from transformers import AutoModelForQuestionAnswering
model = AutoModelForQuestionAnswering.from_pretrained(checkpoint)
# 트레이너 생성, 학습 파라미터 설정
from transformers import TrainingArguments, Trainer
# 학습 파라미터
training_args = TrainingArguments(
output_dir="./results/klue-mrc_koelectra_qa_model"
, eval_strategy="epoch"
, learning_rate=2e-5
, per_device_train_batch_size=16
, per_device_eval_batch_size=16
, num_train_epochs=3
, weight_decay=0.01
, push_to_hub=False
)
# 트레이너
trainer = Trainer(
model=model
, args=training_args
, train_dataset=tokenized_sq["train"]
, eval_dataset=tokenized_sq["test"]
, processing_class=tokenizer
)
# 학습
trainer.train()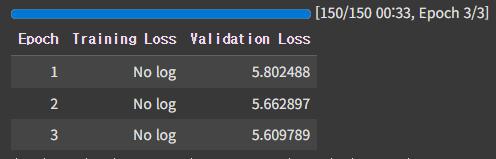
- 학습 모델 및 트레이너 설정
- 사전 학습된 모델을 불러와 MRC(기계독해→질의응답) 용으로 재설정
- 트레이너 생성 시 모델, 학습 파라미터, 데이터셋, 토크나이저 등을 함께 설정
5교시 정리
- 핵심 개념
- 오프셋 매핑은 토크나이저 처리 후 원문 내 정답 위치를 정확히 찾기 위한 시작과 끝 위치 정보를 제공
- 핵심 단어
- 오프셋 매핑
- 컨텍스트 위치와 정답 위치
- 요약
- 오프셋 매핑 정보를 통해 토크나이저 처리 후에도 원문 내 정답 위치를 정확히 파악하고 학습에 필요한 시작과 끝 위치를 저장
- 정답 위치가 컨텍스트 내에 포함되는지 확인 후 포함 시 반복문으로 시작과 끝 위치를 탐색하여 저장
6교시: QA / 텍스트 요약(Text Summarization)
질의응답(Question Answering)
- 학습 결과를 허깅페이스에 업로드
# 학습한 결과를 허깅페이스에 업로드
%cd /content/drive/MyDrive/Colab Notebooks/NLP
# 허깅페이스 로그인
from huggingface_hub import login
# 파일 형태의 api_key 불러오기
with open("./key/huggingface_api_key", 'r') as f:
api_key = f.read().strip()
login(token=api_key)
# 허깅페이스 업로드
repo_id = "유저명/klue-mrc-koelectra-qa-mode"
trainer.save_model(repo_id)
model.save_pretrained(repo_id)
tokenizer.save_pretrained(repo_id)
trainer.push_to_hub(repo_id)- 업로드한 모델 불러와서 사용해보기
# task="question-answering"
from transformers import pipeline
checkpoint_mymodel="be2be2/klue-mrc-koelectra-qa-mode"
question_answerer = pipeline(
task="question-answering"
, model=checkpoint_mymodel
, tokenizer=checkpoint_mymodel
)
question = "RAG의 장점은 ?"
context = """RAG는 또한 새로운 데이터로 LLM을 재훈련할 필요성을 줄여 계산 및 재정 비용을 절감한다.
효율성 향상 외에도 RAG는 LLM이 응답에 출처를 포함할 수 있도록 하여 사용자가 인용된 출처를 확인할 수
있도록 한다. 이는 사용자가 검색된 콘텐츠를 교차 확인하여 정확성과 관련성을 확인할 수 있으므로
투명성이 향상된다."""
result = question_answerer(question=question, context=context)
result{'score': 0.0010380235617049038, 'start': 64, 'end': 73, 'answer': 'RAG는 LLM이'}- 학습 데이터가 적으면 답변 정확도가 낮아지므로 충분한 데이터 학습이 필요
- 우리는 800개만 넣어서 성능이 좋지 않음
ex01 ~ ex05 리뷰
- 다양한 다운스크림 태스크 실습
- KoBERT, KoELECTRA, KoBART 모델을 활용한 뉴스 카테고리 분류, 감성 분석, 질의 응답 등의 실습 징행
- ex01: transformers 라이브러리 맛보기
- ex02: 네이버 영화 리뷰 → 감성 분류(sentiment-analysis / text-classification)
- KoBERT
- KoELECTRA
- KoBART
- ex03: KLUE-YNAT 뉴스 카테고리 분류 → text-classification
- ex04: KLUE-NER 개체명 인식 → token-classification
- ex05: KLUE-MRC 질의응답 → question-answering
텍스트 요약(Text Summarization)
- 요약(Summaries): 문서나 기사에서 중요한 정보를 모두 포함하되 짧게 만드는 과정
- 번역과 함께 seq2seq(시퀀스 투 시퀀스) 문제로 구성할 수 있는 대표적인 작업 중 하나
- 중요한 정보를 모두 포함해 간결하게 만드는 과정
- 뉴스 데이터, 논문 등 다양한 텍스트 데이터 분석 프로젝트에 활용
- 요약의 유형
- 추출적(extractive) 요약: 문서 내에서 관련성이 높은 정보 추출
- 문서 내 관련성 높은 정보를 그대로 추출하는 방식
- 생성적(abstractive) 요약: 관련성 높은 정보를 확인해 새로운 텍스트를 생성
- 관련 정보를 바탕으로 '새로운 텍스트'를 생성하는 방식
- 이번 파일의 실습 내용: abstractive summarization
- 추출적(extractive) 요약: 문서 내에서 관련성이 높은 정보 추출
- 데이터셋
- 생성 요약(abstractive summarization)을 위한 BillSum 데이터셋 활용
- 미국 연방 법원 데이터(train)로 학습하고 캘리포니아 법안 데이터(ca_test)로 테스트해 일반화 성능 평가 가능
- 생성 요약(abstractive summarization)을 위한 BillSum 데이터셋 활용
| split 이름 | 설명 |
|---|---|
"train" | 미국 연방 법안으로 구성된 훈련용 데이터 (대부분의 모델 학습에 사용됨) |
"ca_test" | 캘리포니아 주 법안으로 구성된 테스트용 데이터 (도메인 일반화 성능 평가용) |
from datasets import load_dataset
load_dataset("billsum") # 일반화 정도를 확인하기 좋은 데이터셋
# 우리는 캘리포니아 주 법안만 활용하여 학습/평가로 분리
billsum = load_dataset("billsum", split="ca_test") # 1237개 데이터 활용
billsum["train"][0]{'text': 'The people of the State of California do enact as follows:\n\n\nSECTION 1.\n(a) The Legislature finds and declares that the oversight boards to individual successor agencies were established pursuant to the Redevelopment Agency Dissolution Act, which prescribes that all oversight boards in the County of Los Angeles will be consolidated into a single countywide oversight board by July 1, 2016.\n(b) The Legislature further finds that collapsing all functions of the 71 oversight boards in the County of Los Angeles into a single countywide oversight board would create administrative gridlock and be a severe impediment to the expeditious disposition of properties owned by former redevelopment agencies.\n(c) In recognition of these findings and to ensure that the duties of the 71 oversight boards and successor agencies in the County of Los Angeles will be met in a timely manner, it is the intent of the Legislature to continue all oversight boards in the County of Los Angeles in existence until the respective successor agency requests dissolution of its oversight board and transfer of fiduciary duties to the countywide oversight board.\nSEC. 2.\nSection 34179 of the Health and Safety Code is amended to read:\n34179.\n(a) Each successor agency shall have an oversight board composed of seven members. The members shall elect one of their members as the chairperson and shall report the name of the chairperson and other members to the Department of Finance on or before May 1, 2012. Members shall be selected as follows:\n(1) One member appointed by the county board of supervisors.\n(2) One member appointed by the mayor for the city that formed the redevelopment agency.\n(3) (A) One member appointed by the largest special district, by property tax share, with territory in the territorial jurisdiction of the former redevelopment agency, that is of the type of special district that is eligible to receive property tax revenues pursuant to Section 34188.\n(B) On or after the effective date of this subparagraph, the county auditor-controller may determine which is the largest special district for purposes of this section.\n(4) One member appointed by the county superintendent of education to represent schools, if the superintendent is elected. If the county superintendent of education is appointed, then the appointment made pursuant to this paragraph shall be made by the county board of education.\n(5) One member appointed by the Chancellor of the California Community Colleges to represent community college districts in the county.\n(6) One member of the public appointed by the county board of supervisors.\n(7) One member representing the employees of the former redevelopment agency appointed by the mayor or chair of the board of supervisors from the recognized employee organization representing the largest number of former redevelopment agency employees employed by the successor agency at that time. If city or county employees performed administrative duties of the former redevelopment agency, the appointment shall be made from the recognized employee organization representing those employees. If a recognized employee organization does not exist for either the employees of the former redevelopment agency or the city or county employees performing administrative duties of the former redevelopment agency, the appointment shall be made from among the employees of the successor agency. In voting to approve a contract as an enforceable obligation, a member appointed pursuant to this paragraph shall not be deemed to be interested in the contract by virtue of being an employee of the successor agency or community for purposes of Section 1090 of the Government Code.\n(8) If the county or a joint powers agency formed the redevelopment agency, the largest city by acreage in the territorial jurisdiction of the former redevelopment agency may select one member. If there are no cities with territory in a project area of the redevelopment agency, the county superintendent of education may appoint an additional member to represent the public.\n(9) If there are no special districts of the type that are eligible to receive property tax pursuant to Section 34188 within the territorial jurisdiction of the former redevelopment agency, the county may appoint one member to represent the public.\n(10) If a redevelopment agency was formed by an entity that is both a charter city and a county, the oversight board shall be composed of seven members selected as follows: three members appointed by the mayor of the city, if that appointment is subject to confirmation by the county board of supervisors; one member appointed by the largest special district, by property tax share, with territory in the territorial jurisdiction of the former redevelopment agency, that is the type of special district that is eligible to receive property tax revenues pursuant to Section 34188; one member appointed by the county superintendent of education to represent schools; one member appointed by the Chancellor of the California Community Colleges to represent community college districts; and one member representing employees of the former redevelopment agency appointed by the mayor of the city, if that appointment is subject to confirmation by the county board of supervisors, to represent the largest number of former redevelopment agency employees employed by the successor agency at that time.\n(b) The Governor may appoint individuals to fill any oversight board member position described in subdivision (a) that has not been filled by May 15, 2012, or any member position that remains vacant for more than 60 days.\n(c) The oversight board may direct the staff of the successor agency to perform work in furtherance of the oversight board’s duties and responsibilities under this part. The successor agency shall pay for all of the costs of meetings of the oversight board and may include those costs in its administrative budget. Oversight board members shall serve without compensation or reimbursement for expenses.\n(d) Oversight board members are protected by the immunities applicable to public entities and public employees governed by Part 1 (commencing with Section 810) and Part 2 (commencing with Section 814) of Division 3.6 of Title 1 of the Government Code.\n(e) A majority of the total membership of the oversight board shall constitute a quorum for the transaction of business. A majority vote of the total membership of the oversight board is required for the oversight board to take action. The oversight board shall be deemed to be a local entity for purposes of the Ralph M. Brown Act, the California Public Records Act, and the Political Reform Act of 1974. All actions taken by the oversight board shall be adopted by resolution.\n(f) All notices required by law for proposed oversight board actions shall also be posted on the successor agency’s Internet Web site or the oversight board’s Internet Web site.\n(g) Each member of an oversight board shall serve at the pleasure of the entity that appointed that member.\n(h) The Department of Finance may review an oversight board action taken pursuant to this part. Written notice and information about all actions taken by an oversight board shall be provided to the department by electronic means and in a manner of the department’s choosing. An action shall become effective five business days after notice in the manner specified by the department is provided unless the department requests a review. Each oversight board shall designate an official to whom the department may make those requests and who shall provide the department with the telephone number and email contact information for the purpose of communicating with the department pursuant to this subdivision. Except as otherwise provided in this part, if the department requests a review of a given oversight board action, it shall have 40 days from the date of its request to approve the oversight board action or return it to the oversight board for reconsideration and the oversight board action shall not be effective until approved by the department. If the department returns the oversight board action to the oversight board for reconsideration, the oversight board shall resubmit the modified action for department approval and the modified oversight board action shall not become effective until approved by the department. If the department reviews a Recognized Obligation Payment Schedule, the department may eliminate or modify any item on that schedule prior to its approval. The county auditor-controller shall reflect the actions of the department in determining the amount of property tax revenues to allocate to the successor agency. The department shall provide notice to the successor agency and the county auditor-controller as to the reasons for its actions. To the extent that an oversight board continues to dispute a determination with the department, one or more future recognized obligation schedules may reflect any resolution of that dispute. The department may also agree to an amendment to a Recognized Obligation Payment Schedule to reflect a resolution of a disputed item, however, this shall not affect a past allocation of property tax or create a liability for any affected taxing entity.\n(i) Oversight boards shall have fiduciary responsibilities to holders of enforceable obligations and the taxing entities that benefit from distributions of property tax and other revenues pursuant to Section 34188. Further, the provisions of Division 4 (commencing with Section 1000)\nof Title 1\nof the Government Code shall apply to oversight boards. Notwithstanding Section 1099 of the Government Code, or any other law, any individual may simultaneously be appointed to up to five oversight boards and may hold an office in a city, county, city and county, special district, school district, or community college district.\n(j)\nCommencing\nExcept as specified in subdivision (q), commencing\non and after July 1, 2016, in each county where more than one oversight board was created by operation of the act adding this part, there shall be\nonly\none oversight board appointed as follows:\n(1) One member may be appointed by the county board of supervisors.\n(2) One member may be appointed by the city selection committee established pursuant to Section 50270 of the Government Code. In a city and county, the mayor may appoint one member.\n(3) One member may be appointed by the independent special district selection committee established pursuant to Section 56332 of the Government Code, for the types of special districts that are eligible to receive property tax revenues pursuant to Section 34188.\n(4) One member may be appointed by the county superintendent of education to represent schools if the superintendent is elected. If the county superintendent of education is appointed, then the appointment made pursuant to this paragraph shall be made by the county board of education.\n(5) One member may be appointed by the Chancellor of the California Community Colleges to represent community college districts in the county.\n(6) One member of the public may be appointed by the county board of supervisors.\n(7) One member may be appointed by the recognized employee organization representing the largest number of successor agency employees in the county.\n(k) The Governor may appoint individuals to fill any oversight board member position described in subdivision (j) that has not been filled by July 15, 2016, or any member position that remains vacant for more than 60 days.\n(l) Commencing on and after July 1, 2016, in each county where only one oversight board was created by operation of the act adding this part,\nthen\nthere will be no change to the composition of that oversight board as a result of the operation of subdivision (b).\n(m) Any oversight board for a given successor agency shall cease to exist when all of the indebtedness of the dissolved redevelopment agency has been repaid or a successor agency has dissolved the oversight board pursuant to subdivision (q).\n(n) An oversight board may direct a successor agency to provide legal or financial advice in addition to that provided by agency staff.\n(o) An oversight board is authorized to contract with the county or other public or private agencies for administrative support.\n(p) On matters within the purview of the oversight board, decisions made by the oversight board supersede those made by the successor agency or the staff of the successor agency.\n(q) Notwithstanding subdivision (j), an oversight board within the County of Los Angeles shall continue to independently operate until its successor agency adopts a resolution dissolving its oversight board and its oversight board approves that resolution, after which time the successor agency shall be overseen by the oversight board established pursuant to subdivision (j).\nSEC. 3.\nThe Legislature finds and declares that a special law is necessary and that a general law cannot be made applicable within the meaning of Section 16 of Article IV of the California Constitution because of the unique circumstances of the County of Los Angeles.',
'summary': 'Existing law dissolved redevelopment agencies and community development agencies as of February 1, 2012, and provides for the designation of successor agencies to wind down the affairs of the dissolved redevelopment agencies, subject to review by oversight boards, and to, among other things, make payments due for enforceable obligations and to perform obligations required pursuant to any enforceable obligation. Existing law authorizes, in each county where more than one oversight board was created, only one oversight board to be appointed on and after July 1, 2016.\nThis bill would require an oversight board within the County of Los Angeles to continue to independently operate past the July 1, 2016, consolidation date, until its successor agency adopts a resolution dissolving the board and the board approves that resolution, as provided.\nThis bill would make legislative findings and declarations as to the necessity of a special statute for the County of Los Angeles.',
'title': 'An act to amend Section 34179 of the Health and Safety Code, relating to redevelopment.'}- text: 모델의 입력이 될 법안 텍스트
- summary: text를 기반으로 요약한 모델의 타겟
전처리
from transformers import AutoTokenizer
checkpoint="google-t5/t5-small"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# T5 모델을 사용하기 위해서는 프롬프트를 미리 정의해 주어야 함
# T5 모델의 특징: 입력 데이터 앞쪽에 prefix를 붙여 토큰화
prefix = "summarize long sentences"
# 전처리
def preprocess_function (examples):
# 요약 task는 원본 문장과 요약 후 문장의 max_length가 다르므로 별도로 토큰화
# list 안으로 각 문장 앞에 prefix 붙이는 작업
inputs = [prefix + doc for doc in examples["text"]]
model_inputs = tokenizer(
inputs
, max_length=1024
, truncation=True
)
# 요약글의 토큰화 도구 생성
# 요약글 == 정답 → 레이블을 토큰화할 때는 text_target 인수 이름에 대입
labels = tokenizer(
text_target=examples["summary"]
, max_length=128
, truncation=True
)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_billsum = billsum.map(preprocess_function, batched=True)- T5-small 모델
- 요약에 적합
- 입력 텍스트 앞에 명령 프롬프트를 추가해줘야 함
- prefix 변수에 "summarize long sentences" 프롬프트를 넣어 입력 데이터 앞쪽에 붙이기
- 모델에게 수행할 작업을 명확히 알려주는 역할
- 원본 텍스트와 요약 텍스트의 길이가 다르므로 각각 별도의 토크나이저로 처리
- 요약 텍스트: 레이블 역할
- 토크나이저로 변환해 모델 학습에 사용
평가 지표 만들기
- 평가를 위한 평가 지표 생성: 요약에 대한 평가
- ROUGE
- 학습한 모델이 요약한 내용이 실제 요약본과 얼마나 유사한지 유사도를 파악해 줌
- 생성된 텍스트와 실제 요약 텍스트 간 유사도를 측정하는 지표
- 번역과 요약 평가에 널리 사용
- 학습한 모델이 요약한 내용이 실제 요약본과 얼마나 유사한지 유사도를 파악해 줌
6교시 정리
- 핵심 개념
- 생성적 요약은 관련 정보를 바탕으로 새로운 텍스트를 생성하는 테스크이며 시퀀스 투 시퀀스(Seq2Seq) 모델을 사용함
- 핵심 단어
- 요약
- 추출적 요약
- 생성적 요약
- T5 모델
- ROUGE
- 요약
- 생성적 요약의 개념: 관련 정보를 바탕으로 '새로운 텍스트'를 생성
- BillSum 데이터셋은 일반화 성능 평가 및 모델의 실제 환경 적응도 확인에 적합
- T5 모델과 ROUGE 평가 지표
하루 돌아보기
👍 잘한 점
- 오전 웹 강의 적극적으로 참여
- 오후 NLP 헷갈리는 부분 바로바로 질문함
- 내가 모르면 남들도 모른다는 마음가짐으로 기죽지 말고 질문하기
👎 아쉬웠던 점
- 질의 응답 preprocessing_function 세부 내용 솔직히 아직 완벽히 이해는 못했음
🔬 개선점
- 간단한 문장 하나로 preprocessing_function 내부 로직 하나씩 확인해보기
- colab notebook 'brush_up_ex05'
