[인공지능사관학교: 자연어분석A반] HTML / 텍스트마이닝 (8)
오전: WEB
1교시
- 학습 목표
- WEB 개요
- Front vs. Back
- 웹 개발환경
클라이언트와 서버의 역할은 무엇이며, 통신에서 각각 어떤 기능을 수행할까?
HTML, CSS, JavaScript의 역할과 차이점은 무엇일까?
프론트엔드 개발자와 백엔드 개발자의 차이는 무엇인가? (난이도, 커리어 측면)
1. WEB 개요
- 인터넷(Internet)과 웹(Web)의 차이점
- 인터넷: 통신을 위한 물리적 회선과 네트워크 인프라를 의미
- 프로그래밍 → "통신"이 중요 개념
- 통신의 두 가지 개념: 클라이언트와 서버
- 웹: 인터넷 위에서 서비스되는 포털 사이트나 웹페이지를 의미
- 인터넷: 통신을 위한 물리적 회선과 네트워크 인프라를 의미
- 인터넷 연결 구조와 해저 케이블
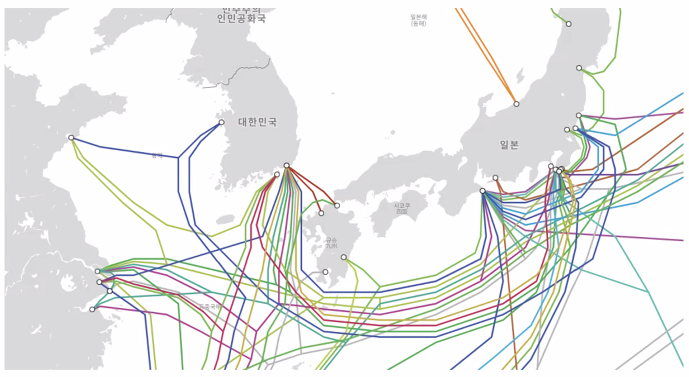
- 인터넷은 해저에 설치된 케이블로 전 세계가 연결되어 있음
- 인공위성보다 해저 케이블이 안정적이고 효율적이어서 주로 사용
- 인터넷 장애는 주로 해저 지진이나 케이블 손상으로 인해 발생
- 수리는 잠수부나 로봇이 수행
- 상어가 공격하는 건 매우 드문 일

- 인터넷은 해저에 설치된 케이블로 전 세계가 연결되어 있음

- 클라이언트와 서버의 개념
※중요※
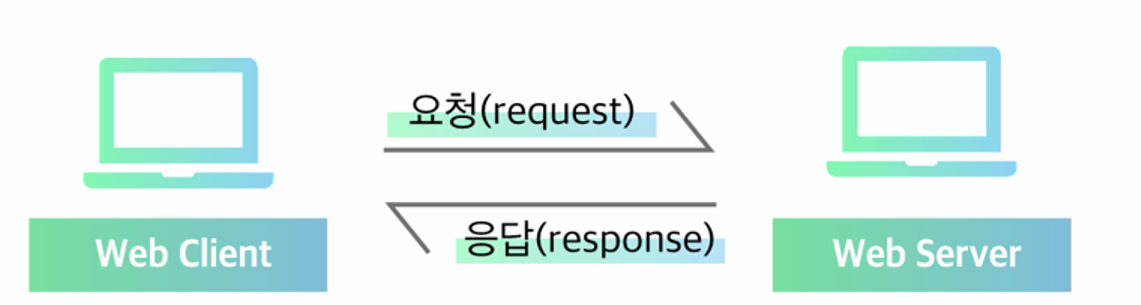
- 웹 클라이언트
- 클릭한 페이지를 요청하는 PC
- 네트워크로 연결된 서버로부터 정보를 제공받는 컴퓨터
- 요청하는 주체, 예를 들어 레스토랑에서 주문하는 고객
- 웹 서버
- 클릭된 페이지를 제공하는 PC
- 클라이언트에게 네트워크를 통해 서비스를 제공하는 컴퓨터
- 요청에 응답하는 주체, 주문받은 음식을 제공하는 서빙 담당자
- 웹 클라이언트
- 웹 통신의 기본 구조
- 클라이언트는 브라우저를 통해 서버에 "요청(request)"을 보냄
- 서버는 요청에 맞는 "응답(response)"을 클라이언트에게 전달
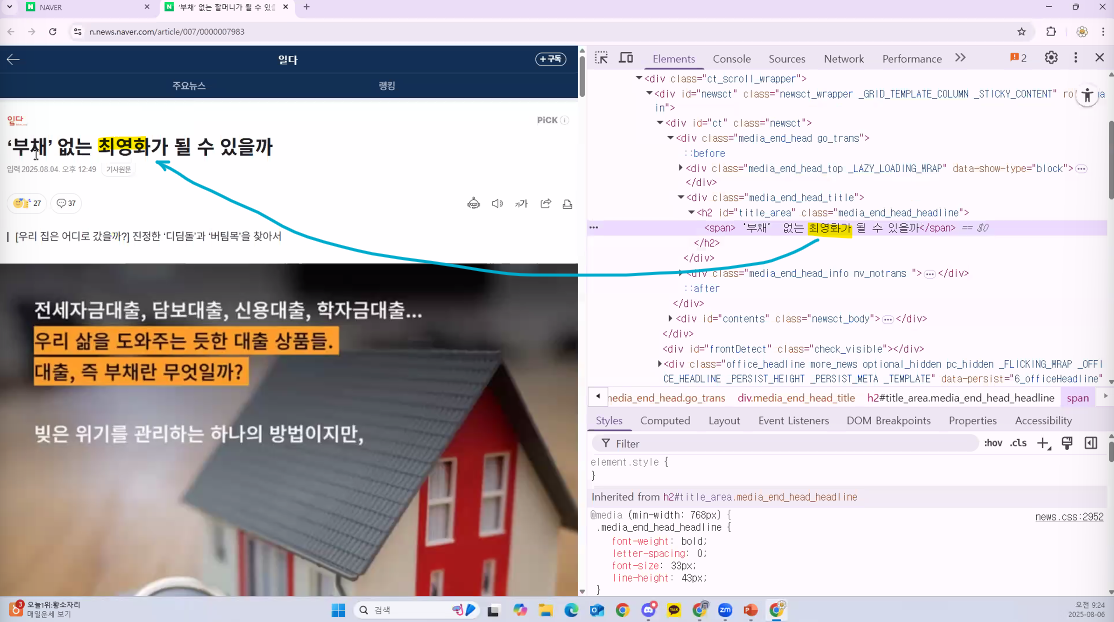
- 웹페이지 구성 언어와 역할
- HTML
- 웹페이지의 구조와 설계 도면 역할
- 글자, 이미지, 버튼 등의 위치외 내용을 정의
→ HTML에서 내용을 바꾸면 웹페이지 화면도 바뀐다!
- CSS의 역할
- 웹페이지의 디자인과 스타일 담당
- 글짜 색깔, 크기, 테두리 모양 등 시각적 요소 조절
- 자바스크립트(JavaScript)의 역할
- 웹페이지의 동적 기능
- 사용자 이벤트 제어
- 마우스 클릭, 키보드 입력 등 사용자 행동에 따른 화면 변화 구현
- 세 언어의 결합으로 하나의 웹사이트 완성
- 자바스크립트가 가장 복잡
- CSS는 디자인 감각이 있어야 하고 배치 조절이 어려움
- HTML은 상대적으로 쉽고 기본적인 구조
- HTML
2. Front vs. Back
- 프론트엔드 개발자

- 사용자에게 보이는 웹페이지 화면과 인터페이스 제작 담당
- HTML, CSS, 자바스크립트 사용
- 기술 변화가 빠르고 코드 수명이 짧음
- 배우기 쉽고 빠르게 익숙해질 수 있음
- 백엔드 개발자

- 서버에서 데이터 처리, 저장, 관리 담당
- 데이터베이스, 보안, 네트워크 등 다양한 지식이 요구됨
- 경력 쌓기와 이직 시 다양한 분야로 확장 가증성 높음
- 난이도가 높고 배우는 내용이 많음
- 안정성과 정확성이 중요
- 실수했을 때 치명적
- 커리어 발전 가능성이 큼
- 추가: AI 기술의 영향
- AI는 프론트엔드와 백엔드 모두에서 일부 작업을 대체(자동화)하고 있음
- 하지만 개발자의 역할은 여전히 중요
3. 웹 개발 환경
- 개발에 필요한 기본 환경

- 웹 브라우저
- 코드 편집기(에디터)
- 주요 코드 편집기 종류
- VScode
- 빠르고 확장성이 뛰어남
- 프론트엔드 개발에 적합
- 이클립스(Eclipse), 인델리제이(IntelliJ)
- 백엔드 개발까지 포함하는 통합 개발 환경(IDE)
- VScode
- VScode 설치 및 사용법
- 설치 시 기본 설정 확인하며 진행하기
- Extension
- Live Server: 작성한 웹 페이지를 브라우저에서 실시간 확인 가능
- Auto Rename Tag: 시작 태그 수정 시 닫는 태그도 자동 변경 가능
참고: 웹 브라우저의 변화
과거 익스플로러 곡점적 사용(윈도우 기본 브라우저였기 때문) → 보안 이슈와 성능 문제로 크롬이 점차 대세로 자리 잡음
스티브 잡스: 플래시 대신 자바스크립트 기반 웹 개발 선포 → 크롬 성장 촉진
익스플로러 공식 종료 후 발표된 엣지 또한 크롬 엔진을 사용하고 있어 최신 웹 개발은 크롬 브라우저를 사용하는 것이 매우 권장됨
1교시 정리
- 핵심 개념
- 웹 개발은 '클라이언트-서버' 통신 구조를 이해하고 HTML, CSS, 자바스크립트로 웹 페이지를 구성하는 과정 → 프론트엔드
- 핵심 단어
- 클라이언트
- 서버
- HTML
- CSS
- 자바스크립트
- 프론트엔드
- 백엔드
- 통신
- VScode
- Chrome
- 요약
- 웹 개발은 클라이언트와 서버 간 요청과 응답의 통신 구조를 이해하는 것에서 시작
- HTML, CSS, JavaScript가 결합되어 웹 페이지의 구조, 디자인, 동작을 완성함
- 프론트엔드 개발자와 백엔드 개발자는 역할, 난이도, 커리어 측면에서 차이가 있음
- AI 기술의 영향도 존재하지만 개발자의 역할의 중요성은 여전함
2교시
- 학습 목표
- HTML 개요
- HTML 기본 구조
- HTML 태그
HTML 태그의 시작 태그와 닫는 태그의 역할과 차이는?
h1부터 h6까지 태그의 의미와 사용처는?
HTML에서 헤드 영역과 바디 영역의 역할은?
1. HTML 개요
- HTML의 정의와 역할
- HTML: 하이퍼텍스트 마크업 언어(Hyper Text MarkUp Language)
- 웹 페이지에 정보를 담아 표시하기 위한 마크업 언어
- 웹 페이지의 뼈대를 담당하는 언어(글자, 이미지, 버튼, …)
- 핵심은 'Markup'
- Hyper Text
- 현재 문서에서 다른 문서로 즉시 접근할 수 있는 텍스트
- Mark Up : '표시하다'라는 의미
- 어딘가에 Mark! 즉 표시를 해 두는 것
- 글자나 컨텐츠에 표시를 해 컴퓨터가 의미를 이해하도록 돕는 역할
- HTML: 하이퍼텍스트 마크업 언어(Hyper Text MarkUp Language)
- 마크업의 필요성과 의미
- 단순 텍스트는 띄어쓰기나 의미 구분이 없어 해석은 가능하지만 정확한 의미 파악이 어려움

- 마크업을 통해 제목, 표, 그림 등 컨텐츠의 의미를 컴퓨터에 명확히 전달 가능

- 단순 텍스트는 띄어쓰기나 의미 구분이 없어 해석은 가능하지만 정확한 의미 파악이 어려움
2. HTML 기본 구조
- HTML 문법: 태그 → "공간 할당", "영역 표시"
- HTML 문법은 태그라는 하나의 문법으로 구성:
<tag> content </tag>→ element(요소)<tag/>: 특정 내용에 표시를 하는 방법
- 태그 이름에 따라 역할과 의미가 구분됨
- HTML 문법은 태그라는 하나의 문법으로 구성:
- Tag, Content, Element
※중요※

- Tag: 표시하는 역할
- Content: 태그 사이에 들어가는 내용
- 태그와 내용을 합쳐 요소(Element)라고 함
- 태그 중에는 속성(Attribute)을 가지는 경우도 있음
※중요※

- HTML 태그의 종류와 실제 사용
- HTML 태그는 약 150개 정도 존재
- h1, ul, table, strong, …
- 실제 웹 개발에서 자주 사용되는 태그는 30개 내외
- 대부분의 웹 페이지는 이 30개 내외의 태그만으로 충분히 제작 가능
- HTML 태그는 약 150개 정도 존재
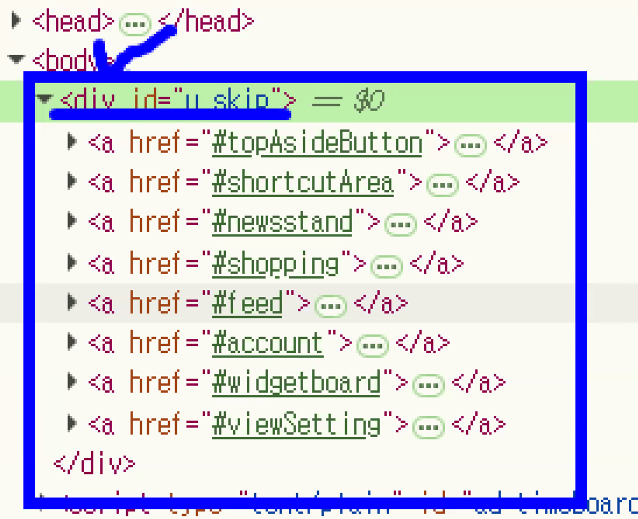
- HTML 문서의 기본 구조
- VScode에서
.html확장자 파일 만들고 코드 입력하는 곳에!입력하고 tab 누르면 탬플릿 자동 완성됨html: 5해도 바로 생성됨
- VScode에서
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
</body>
</html>- head와 body
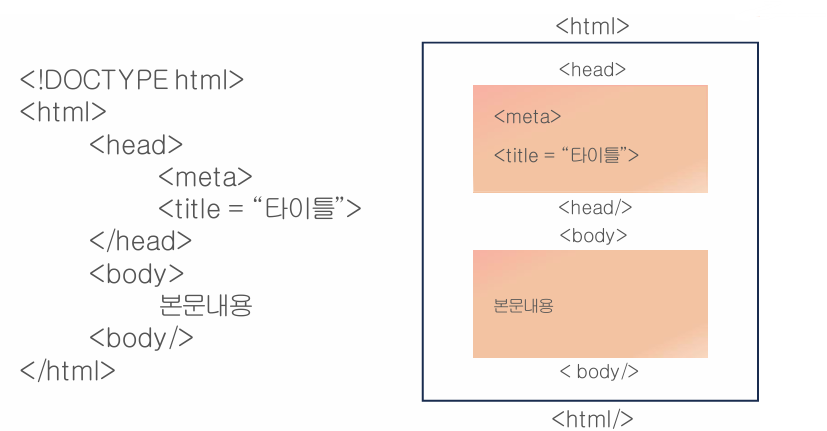
- 헤드(head)는 눈에 보이지 않는 기능을 담당하는 공간
- 라이브러리 불러오기
- 디자인 관련 설정 등
- 바디(body)는 사용자에게 보여지는 실제 컨텐츠를 담당(눈에 보이는 내용을 담당하는 공간)
- 글자, 이미지, 버튼 등
- 헤드(head)는 눈에 보이지 않는 기능을 담당하는 공간
3. HTML 태그
- 태그의 구성과 역할
- 태그는 반드시 시작 태그와 닫는 태그가 쌍으로 존재해야 하며, 닫는 태그는 슬래시(/)를 포함
- 명시적으로
</tag>형태로 닫을 필요가 없는 태그도 있음 (스스로 닫힘)
→ self-closing tags == empty tags == singleton tags
- 명시적으로
- 닫는 태그는 영역의 끝을 명확히 표시하여 컴퓨터가 컨텐츠 범위를 인식하도록 도움
- 태그는 반드시 시작 태그와 닫는 태그가 쌍으로 존재해야 하며, 닫는 태그는 슬래시(/)를 포함
- 태그 이름과 의미
- 태그의 이름에 따라 의미와 역할이 달라짐
- 예:
<b></b>→ 글자를 두껍게 만드는 태그
- 예:
- 태그는 영어 약어로 표현되며, 간단한 알파벳 조합으로 의미를 나타냄
- 태그의 이름에 따라 의미와 역할이 달라짐
- 속성과 속성값
- 태그에 추가 정보를 주는 꾸며주는 말
- 텍스트 입력하기: 텍스트 정보를 담는 태그
- 일반 텍스트 입력
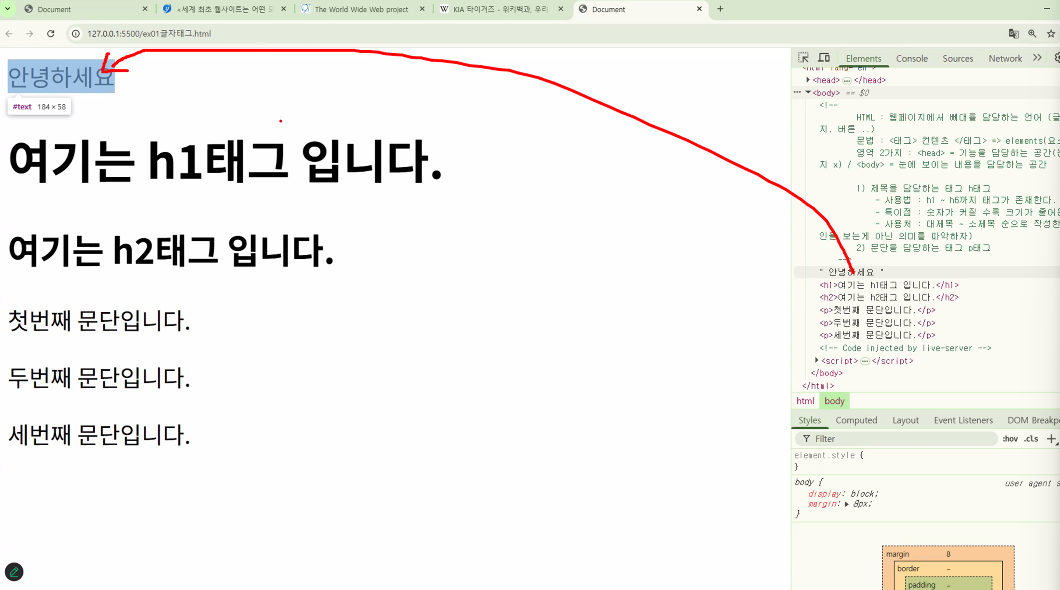
- 제목을 작성하고 싶을 때:
<h1>~<h6> - 문단을 작성하고 싶을 때:
<p> - 문장을 작성하고 싶을 때:
<span>
- 일반 텍스트 입력
- 줄바꿈을 하고 싶을 때:
<br> - 두꺼운 글자를 작성하고 싶을 때:
<strong>,<b>
HTML에서 텍스트 정보를 담는 태그는 주로
<h1>~<h6>, <p>, <span>, <strong>, <em>, <code>등이 있습니다. 이러한 태그들은 텍스트의 역할(제목, 단락, 강조 등)과 의미를 정의하여 웹 페이지의 구조와 내용을 구성합니다.
<h1>~<h6>:
제목을 나타내는 태그입니다. 숫자가 낮을수록 중요도가 높고 글자 크기가 큽니다.
(<h1>- 가장 큰 제목,<h6>- 가장 작은 제목)
<p>:
단락을 나타내는 태그입니다. 텍스트를 문단으로 묶을 때 사용합니다.
<span>:
텍스트의 특정 부분에 스타일을 적용하거나 의미를 부여할 때 사용합니다. 주로 CSS와 함께 사용됩니다.
<strong>:
텍스트를 강하게 강조할 때 사용합니다. 굵은 글씨로 표시됩니다.
<em>:
텍스트를 강조할 때 사용합니다. 이탤릭체로 표시됩니다.
<code>:
컴퓨터 코드를 나타낼 때 사용합니다. 코드 조각을 표시할 때 유용합니다.
<a>:
하이퍼링크를 정의하는 태그입니다. 텍스트를 클릭하여 다른 페이지로 이동할 수 있게 합니다.
<li>, <ol>, <ul>:
목록을 정의하는 태그입니다.<li>는 목록 아이템을,<ol>은 순서가 있는 목록을,<ul>은 순서가 없는 목록을 나타냅니다.
예시:<h1>HTML 텍스트 태그</h1> <p>이것은 단락입니다. 문단을 구분할 때 사용합니다.</p> <p><span>일부 텍스트</span>를 강조할 수 있습니다.</p> <p><strong>중요한 텍스트</strong>는 강하게 표시됩니다.</p> <p><em>이탤릭체로 강조된 텍스트</em>입니다.</p> <p><code>코드 예시</code></p>
제목(header)을 담당하는 태그: h tag
- h tag는 제목을 만드는 태그
- 사용법: h1 ~ h6까지 6가지의 태그가 존재
- 숫자가 작을수록 큰 제목, 숫자가 클수록 작은 제목
- 사용법: h1 ~ h6까지 6가지의 태그가 존재
- 특이점: 숫자가 커질수록 크기가 줄어듦
- ★ 사용처: 대제목 ~ 소제목 순으로 작성 ★
- 페이지 최상단에 위치한 대제목: h1
- 대제목 아래 제목 추가: h2
- 디자인을 보는 게 아닌 의미를 파악하자!
- 어디에 사용하는지 이해해야 함
- h tag의 시각적 효과와 의미
- h tag는 글자를 크고 두껍게 만들어 시각적으로 제목임을 나타내지만 그 본질은 의미 구분
- h1은 문서의 가장 중요한 대제목, h2는 대제목 아래 소제목, h3은 h2 아래 소제목 등 계층적 구조 표현
- 실제 사용 시 주의점
- 디자인 목적으로 h tag를 임의로 변경하면 의미가 왜곡될 수 있음
- 예: h tag를 쓰면 글자가 크고 두꺼워지니까 제목이 아닌 내용에 h tag를 쓰거나 하면 안 됨
- 의미에 맞게 제목 구조를 잡는 것이 중요
- 디자인은 CSS로 조절하는 것이 바람직
- 보통 h1부터 h3까지가 가장 많이 사용되며, h4~h6은 드물게 사용됨
- 문서 구조를 명확히 해 다른 개발자도 쉽게 이해할 수 있도록 도움
- 디자인 목적으로 h tag를 임의로 변경하면 의미가 왜곡될 수 있음
문단(paragraph)을 담당하는 태그: p tag
- 문단의 개념과 필요성
- 문단은 글을 구분하는 단위 → 내용 구분이 명확해야 함 → 일반 텍스트에서는 줄바꿈 또는 엔터를 한 번 더 넣어 중간에 공백이 들어감
- 웹 페이지 문단의 특징: 문단과 문단 사이 "공백" 존재 → 문단을 명확히 구분해 컨텐츠를 체계적으로 구성
- 일반 텍스트에서 엔터로 문단 구분하듯 HTML에서 여러 문장을 p tag로 나누어 문단을 구분해 작성하면 웹 페이지에서 문단별 구분이 시각적으로 나타남 → 문단 사이에 공백이 생겨 가독성 향상
- 공간을 할당한다는 느낌에 가까움
- 특이점
- 사용 시 위, 아래 공백 추가

- 컨텐츠 길이에 상관 없이 한 줄 전체를 차지함 → "자동 줄바꿈"
- 사용 시 위, 아래 공백 추가
- 사용처: 글자를 적을 문단을 생성할 때 활용
2교시 정리
- 핵심 개념
- HTML은 웹 페이지의 뼈대를 구성하는 마크업 언어
- 태그를 통해 컨텐츠의 의미와 구조를 표시
- 핵심 단어
- HTML
- Tag
- h 태그
- p 태그
- 요약
- HTML은 웹 페이지의 구조(뼈대)를 만드는 언어
- 헤드는 기능과 설정을 담당하고, 바디는 사용자에게 보이는 컨텐츠를 담당함
- 태그는 컨텐츠의 의미를 표시하며 시작 태그와 닫는 태그로 구성
- h 태그는 제목, p 태그는 문잗을 나타냄
3교시
p 태그와 span 태그의 차이점은?
br 태그 사용 시 주의해야 할 점은?
b 태그와 strong 태그의 차이점은?
3. HTML 태그
문단(paragraph)을 담당하는 태그: p tag (cont'd)
- p 태그와 공간
- 문단은 글자를 쓰는 큰 공간을 할당하는 개념 → 글자 크기나 두깨 조절이 아님 (이건 CSS)
- p 태그는 문단 위아래에 자동으로 공백이 추가되어 문단 간 간격을 형성
- 글자가 차지하는 공간보다 더 크게 한 줄 전체를 차지 → 자동 줄바꿈 발생
- 개발자 도구에서 p 태그의 영역을 살펴보면 글자 주변에 살구색 공백이 표시되며 문단 간 간격 확인이 가능
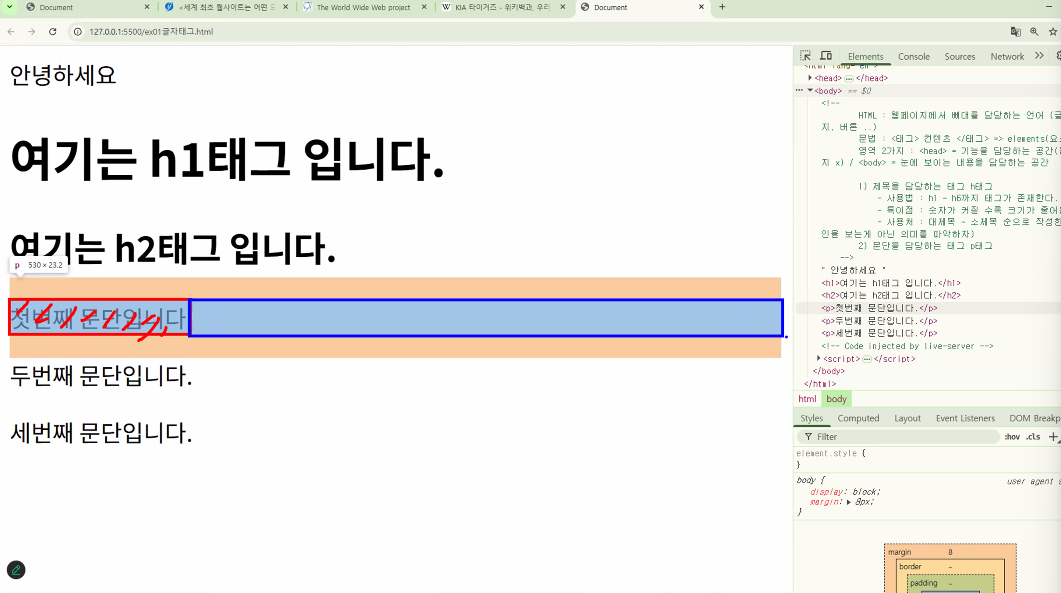
- cf. 일반 텍스트
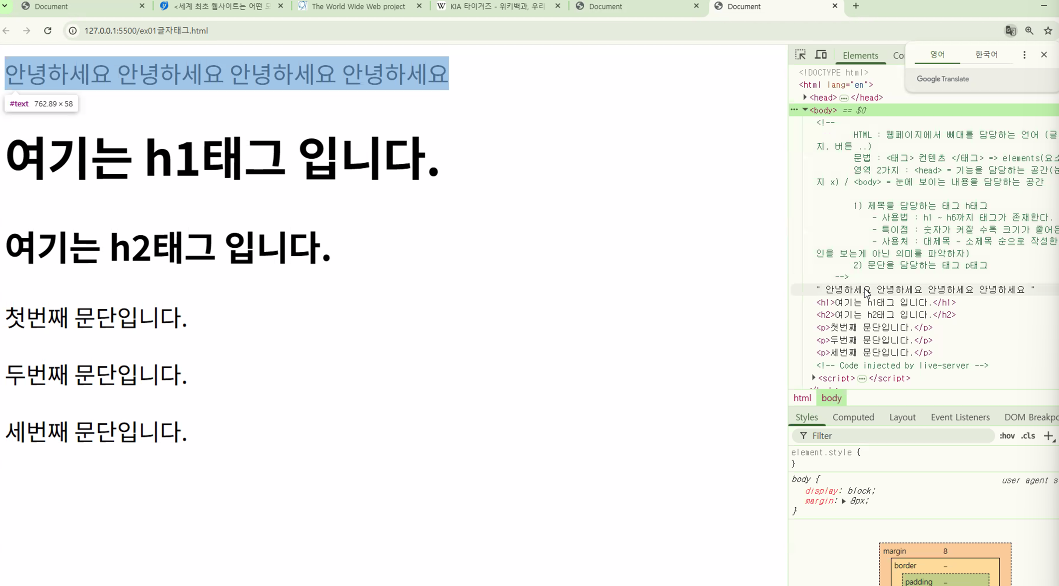
- p 태그는 글자 크기나 두께 변화 없이 문단 간 공백만 생성 → 공백 조절은 CSS에서 담당
- HTML은 뼈대를 만들고, 공백 크기 등 디자인 요소는 CSS에서 조절
특정 단어나 문장을 표시할 때 쓰는 태그: span tag
- 특정 글자 영역 표시
- 문장 내 특정 단어나 문장을 감쌀 때 사용
- 화면 상 변화 없이 영역만 표시하는 비어있는 태그(공 태그)로 CSS 연동이 없는 경우 별다른 기능 없음 → 컴퓨터와 소통을 위한 영역 표시 수단
- span 태그와 CSS 연동 시 특정 영역 스타일 변경 가능(스타일 지정 가능)
- 예: span 태그로 감싼 글자만 색상을 변경
- 글자 크기나 줄바꿈에 영향 없이 글자만큼의 공간만 차지하여 옆으로 붙음

- cf. p 태그는 한 줄 전체 공간을 차지하며 줄바꿈 발생
- 특이점
- 화면에는 아무런 변화가 없다 → 아무런 기능이 없다 → 공태그
- 자동 줄바꿈이 되지 않는다 → 쓴 만큼만 공간을 할당하기 때문
- 사용처: 컴퓨터에게 특정 문장, 단어 등 영역을 표시할 때 사용
- ★ 포인트: 컴퓨터와 대화하는 수단은 태그뿐(컴퓨터는 오직 태그로만 소통이 가능하다) ★
줄을 바꿀 때 활용하는 태그: br tag
- HTML에서 줄바꿈은 태그로만 인식 가능
- 일반 텍스트 내 엔터는 무시됨
- 줄바꿈을 위해 태그 사용해야 함:
<br>
- 열린 태그만 존재하느 홀태그(Void elements, Empty elements) 구조(홀짝 할때의 그 홀임)
- 닫는 태그 없음 → 컨텐츠 공간 없음
- 줄바꿈 전용 태그
- 특이점: 열린 태그만 존재(종료 태그가 없음)
- 컨텐츠가 필요 없기 때문
- 빈 요소는 컨텐츠를 감쌀 필요가 없으므로
<br></br>와 같은 형태의 종료 태그를 사용하지 않음
- break의 약자
- 기능을 담당하는 태그라 여는 태그와 닫는 태그가 하나로 합쳐져 있음: 자체 닫힘(self-closing) 방식
- 사용법: 같은 공간 안에 있는 '글자와 글자 사이'를 분리할 때 사용
- 태그와 태그 사이에 쓰면 안 됨!
- 주의점
- 반드시 같은 태그 안에서 문장끼리 엔터 칠 때 활용
- 태그와 태그 사이가 아닌 같은 태그 내 글자 사이에서 줄바꿈 용도로 사용해야 함
- ★ 절대 태그와 태그를 분리할 때 사용하지 않는다 → 쓰면 레이아웃 다 깨짐 ★
- 태그와 태그 사이에 br 태그를 넣어 줄바꿈 처리하는 것은 비표준이며 권장하지 않음
→ 태그와 태그 사이를 분리하고 싶다면 css에서 처리해야 함

- 태그와 태그 사이에 br 태그를 넣어 줄바꿈 처리하는 것은 비표준이며 권장하지 않음
- br 태그는 줄바꿈만 담당하며 공백 크기 조절 불가
- 공백 조절은 CSS에서 처리하며 br 태그는 단순 줄바꿈 역할만 수행
- 디자인 조절이 어려워 페이지 변동 시 레이아웃 깨질 위험 존재
- 반드시 같은 태그 안에서 문장끼리 엔터 칠 때 활용
더 알아보기: 스스로 닫히는, 닫지 않아도 되는 태그들
- 명시적으로
</tag>형태로 닫을 필요가 없는 태그
- 종료 태그(
</tagname>) 없이 시작 태그만으로 구성된 요소들 → 빈 요소(Empty Element) 또는 Void Element라고 부르며, 셀프 클로징 태그(Self-Closing Tag)라는 용어와 연관되어 사용됨
- self-closing tags == empty tag == singleton tags
- 빈 요소(Empty Element)
- HTML 요소 중 내부에 어떠한 컨텐츠(텍스트나 다른 자식)도 포함할 수 없는 요소를 의미
- 일반적인 요소(예:
<p>내용</p>)가 시작 태그와 종료 태그 사이에 내용을 가지는 것과 달리 빈 요소는 그 존재 자체로 특정 기능을 수행(예: 줄바꿈)하거나 객체(예: 이미지)를 나타냄- 태그 내부에 텍스트나 컨텐츠를 갖지 않음
- 시작 태그와 종료 태그 사이에 들어갈 내용이 없기 때문에 '비어 있다'고 표현
- 요소의 의미와 기능은 태그 이름 자체와 태그에 포함된 속성(Attributes)에 의해 완전히 정의됨
- 자체적으로 닫아줘도 되지만 브라우저는 동일하게 해석하니 편한 방식으로 사용(optional slash)
<br>와<br/>: 브라우저에겐 동일하게 보임
<tagname>형식: HTML5에서는 슬래시 없이 작성하는 것이 더 간결하고 표준적인 방식으로 간주될 수 있음<tagname/>형식: 이 형식을 흔히 셀프 클로징(self-closing)이라고 함. XML, XHTML 문법 규칙에서 유래- 단 XTML에서는 self-closing tag를 닫아주는 것이 규칙이라고 함
- HTML 빈 요소와 셀프 클로징
- 중요한 건 어떤 형식을 사용하든 코드 가독성을 위해 프로젝트 내에서 일관된 스타일을 유지하는 것
글자를 두껍게 만드는 태그 두 가지: b tag, strong tag → 쓰임새가 다름
- b: 글자를 두껍게 하는 태그
- 단순 시각적 처리
- 의미적 강조 없음
- strong: 글자를 두껍게 하는 태그
- 의미적 강조 포함
- 스크린 리더 등 보조 기술에서 강조 인식 가능
- 의미적 강조 포함
- 차이점
- b tag는 단순 디자인(현재 사용 빈도 줄어듦)
- strong tag는 스크린 리더와 같은 보조 기술에서 해당 부분을 강조해 읽음(표준개발)
- 웹 표준 검사기로 표준개발 태그인지 검사 가능
<strong>태그와<b>태그는 겉보기에는 비슷하지만,<strong>태그는 의미적으로 중요한 부분을 강조하는 반면,<b>태그는 단순히 텍스트를 굵게 표시하는 데 사용 → b 태그는 디자인 목적이며, strong 태그는 의미 강조 목적임- 시각적으로 b 태그와 strong 태그는 차이 없음
- 현재 웹 표준 개발에서는 접근성 측면에서 strong 태그 사용 권장
- b 태그 사용은 점차 줄어드는 추세
- 더 알아보기
3교시 정리
- 핵심 개념
- HTML 태그는 컴퓨터와 소통하기 위한 영역 표시 수단
- p 태그는 문단, span 태그는 특정 영역 표시
- br 태그는 줄바꿈 역할
- 핵심 단어
- p 태그
- span 태그
- br 태그
- b 태그
- strong 태그
- 요약
- p 태그는 문단을 만들며 한 줄 전체 공간을 차지하고 위아래 공백을 자동 생성함
- span 태그는 특정 글자 영역을 표시하며 줄바꿈 없이 글자 크기만큼의 공간을 차지
- br 태그는 줄바꿈을 위한 홀태그이며 태그 내 글자 사이에서만 사용
- b 태그는 단순 시각적 강조, strong 태그는 의미적 강조
오후: NLP
4교시: 개체명 인식(NER)
BIO 태그 방식이 개체명 인식에서 중요한 이유는 무엇일까?
서브워드 토크나이징 후 레이블 정렬 문제를 해결하는 방법은?
word_ids 기반으로 테이블 정정이 필요한 이유는?
지난 시간 복습
- 개체명 인식과 데이터셋
- 토큰 분류
- 문장 내 개별 토큰에 레이블을 할당하는 작업
- 개체명을 인식하는 과정
- 예: 사람, 날짜, 법률 용어 등
- KLUE-NER 데이터셋
- 한국어 개체명 인식에 만이 사용되는 KLUE 데이터셋의 일부
- NER 태스크에서 사용되는 다양한 개체명(날짜, 조직 등)포함된 뉴스 기반 데이터셋
- 토큰 분류
- BIO 태그 체계
- B: 개체명 시작 토큰, I: 개채명 내부 토큰, O: 개체명 외부 토큰
- 서브워드 단위 토크나이징으로 인해 단어가 쪼개질 수 있어 시작과 내부 토큰 구분이 필요
토큰화 함수의 목적
- 서브워드 토크나이징
- 최신 모델들(BERT, ELECTRA, GPT 등)은 단어보다 작은 단위인 서브워드로 토크나이징 수행
- 예: 삼성전자 → 삼성, ##전자 또는 삼, ##성, ##전, ##자
- 토큰화
- is_split_into_words=True 속성 사용했기 때문에 별도로 토큰화 X
- NER 레이블(BIO)이 각각 토큰에 맞게끔 정렬이 되도록 처리해야 함 → 토크나이징 후 레이블 불일치 문제
- 원래 7개였던 토큰이 서브워트 토크나이징 후 9개로 증가하면서 레이블 개수가 맞지 않음
- CLS, SEP 토큰이 추가되며 의미 없는 토큰에도 레이블이 붙어 계산 오류 발생
- 문제 해결을 위해
word_ids기반으로 레이블 정정word_ids는 각 토큰이 "원래 몇 번째 단어에 속하는지" 알려주는 인덱스- CLS, SEP 등 특수 토큰은
word_ids가 없음 → -100 값을 부여해 학습에서 무시하도록 처리:if word_idx is None: labels.append(-100) - word_ids가 같은 경우 동일 단어로 인식 → 레이블을 일관되게 매칭
- 원래 7개였던 토큰이 서브워트 토크나이징 후 9개로 증가하면서 레이블 개수가 맞지 않음
예시
- 원래 KLUE-NER 데이터
tokens = ['강', '릉', '휴', '게', '소', '에', '서'] # tokens
labels = ['B-LC', 'I-LC', 'I-LC', 'I-LC', 'I-LC', 'O', 'O'] # ner_tags- tokenizer를 거치면 → subword: 시작 태그, 끝 태그 추가됨
subwords = ['[CLS]', '강', '##릉', '##휴', '##게', '##소', '##에', '##서', '[SEP]']- 이걸 단순히 앞에서부터 subwords에 그대로 붙이면?
| Subword | 붙은 라벨 |
|---|---|
[CLS] | B-LC ❌ |
강 | I-LC ❌ |
##릉 | I-LC ✅ |
##휴 | I-LC ✅ |
##게 | I-LC ✅ |
##소 | O ❌ |
##에 | O ✅ |
##서 | - 없음 ❌ |
[SEP] | - 없음 ❌ |
- ✅ 해결법: word_ids() 기반 라벨 정렬!
| Subword | word_ids | 정렬된 라벨 |
|---|---|---|
[CLS] | None | -100 |
강 | 0 | B-LC ✅ |
##릉 | 1 | I-LC ✅ |
##휴 | 2 | I-LC ✅ |
##게 | 3 | I-LC ✅ |
##소 | 4 | I-LC ✅ |
##에 | 5 | O ✅ |
##서 | 6 | O ✅ |
[SEP] | None | -100 |
# 토큰화 함수 정의
def tokenizer_function(example):
# 토큰화 → 학습에 필요한 input_ids, word_ids 값 등을 포함
tokenized_inputs = tokenizer(
example["tokens"] # 이미 띄어쓰기 된 토큰 리스트
, max_length=128
, truncation=True
, padding="max_length"
, is_split_into_words=True # 이미 글자 단위로 분리되어 있으므로 토큰화하지 말라는 의미 (NER 작업)
)
# NER 학습을 위하여 토큰화된 결과의 레이블을 BIO 인덱스로 변환
# word_ids: 각 토큰이 원래 입력의 몇 번째 단어에 해당하는지 인덱스 번호를 알려줌
word_ids = tokenized_inputs.word_ids()
labels = [] # subword 후의 태그 정보
previous_word_idx = None # 비교를 위한 변수: 이전 단어와 인덱스 번호 비교용
for word_idx in word_ids: # subwords를 labels에 매칭
if word_idx is None: # 현재 값이 padding이나 특수 토큰(시작 토큰, 끝 토큰)인 경우 학습 대상에서 제외하기 위함
labels.append(-100) # 학습이 필요 없는 대상은 무시 (-100: 내부적으로 무시하겠다는 의미로 적어주는 게 약속임)
elif word_idx != previous_word_idx: # 현재 인덱스와 이전 인덱스가 다름 → 새로운 단어라는 의미
labels.append(example["ner_tags"][word_idx])
else: # 같은 단어의 후속 단어(현재 인덱스와 이전 인덱스가 같음 → 한 개의 단어에서 쪼개진 경우): 그대로 유지
# 지금은 음절 단위로 넣어서 의미가 없지만 단어 단위로 넣었을 때는 의미가 있으
if label_list[example["ner_tags"][word_idx]].startswith('I'):
labels.append(example["ner_tags"][word_idx])
else:
labels.append(-100)
# 다음 루프 때 비교하기 위해 현재 word_idx를 저장(업데이트)
previous_word_idx = word_idx
# 길이 맞춰주기 → 설정한 max_length의 길이에 맞게끔 padding
labels += [-100]*(len(tokenized_inputs["input_ids"])-len(labels))
# 잘 매칭된 NER 정답 레이블을 학습용 딕셔너리에 추가
tokenized_inputs["labels"] = labels
# 반환
return tokenized_inputs- NER 레이블과 BIO 태그 정렬
- NER 레이블이 BIO 토큰에 맞게 정렬되도록 반복문으로 처리
- 음절 단위로 이미 분할된 데이터이기 때문에 별도의 토큰 분할 필요하지 않음
is_split_into_words=True설정 주기
labels.append(-100)의 역할과 적용- 의미 없는 토큰(특수 토큰 등)에 -100을 넣어 학습에서 제외
- 레이블 배열에 -100을 추가하여 패딩 및 길이 맞춤 처리 수행
- max_length에 맞춘 패팅 처리
- 토크나이즈된 인풋 길이가 설정한 최대 길이보다 짧을 경우 부족한 부분에 -100 값을 넣어 길이 맞춤
- 패딩된 레이블 배열을 다시 토크나이즈된 인풋에 대입해 학습용 데이터 완성
- 토큰화 과정 중 조건문 사용 이유?
- 토큰화 후 레이블을 붙이는 과정에서 레이블이 잘못 붙으면 잘못된 학습을 하기 때문
- 예:
["Hugging", "##Face", "is", "cool"]→[B-OG, B-OG, O, O]로 붙었다면?- subword인데 전부 B 키워드가 붙어버리면 모델이 헷갈리게 됨
- 그래서 subword 중에 첫 번째 토큰에만 B 레이블을 붙이는 방식
tokenized_dataset = klue_ner.map(tokenizer_function, batched=False)5교시: 개체명 인식(NER)
- 로그인 및 모델 저장
- 로그인 토큰을 불러와 API_key 변수에 저장
- 앞뒤 공백 제거 후 api 키 변수에 할당
- 로그인 후 모델 업로드
- 모델 저장을 위해 trainer에게 model_id와 훈련된 정보 전달
- 토크나이저도 동일하게 진행
- 저장된 모델을 pipeline으로 불러와 결과 확인
- checkpoint 이름과 task 이름 지정해 모델 로드 및 실행
- 로그인 토큰을 불러와 API_key 변수에 저장
- 불러온 모델 사용 결과 확인
- 결과가 완벽하지 않은 이유는 학습 데이터가 적기 때문
- 학습 데이터가 250개로 적어 학습이 제대로 이루어지지 않았음
- 결과보다는 학습 과정에 집중하기
- 실제 프로젝트 진행 시에는 데이터 양을 늘려 학습하기
- 결과가 완벽하지 않은 이유는 학습 데이터가 적기 때문
모델 설정
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
checkpoint
, num_labels=len(label_list)
, id2label = id2label
, label2id = label2id
)평가 함수 정의
- 개체명 인식에서 사용하는 평가지표: seqeval
!pip install -q seqeval
!pip install -q evaluate
# 평가 함수 정의
from evaluate import load
import numpy as np
metrics = load("seqeval")
def compute_metrics(eval_pred):
logits, labels = eval_pred
pred = np.argmax(logits, axis=2) # logit.shape → [batch_size, seq_length, num_labels]
# 예측 값, 실제 값 → BIO 형태의 문자열 담을 리스트
true_preds = []
true_labels = []
for pred_seq, label_seq in zip(pred, labels):
# -100 값을 제외한 결과를 담아줄 임시 리스트: 한 문장의 예측값, 실제값을 저장
temp_true_preds = []
temp_true_labels = []
# labels에서 -100 값은 평가에서 제외
for p, l in zip(pred_seq, label_seq):
if label != -100:
temp_true_preds.append(label_list[p])
temp_true_labels.append(label_list[l])
true_preds.append(temp_true_preds)
true_labels.append(temp_true_labels)
return metrics.compute(
predictions=true_preds
, references=true_labels
, zero_division=0
)Trainer 설정 및 학습
from transformers import TrainingArguments, Trainer
args = TrainingArguments(
output_dir="./results/klue-ner-koelectra" # 로컬에 저장된 걸 기준으로 허깅페이스에 업로드하기 때문에, 로컬 저장은 필수
, learning_rate=2e-5
, per_device_train_batch_size=8
, per_device_eval_batch_size=8
, num_train_epochs=20
, weight_decay=0.01
)
trainer = Trainer(
model=model
, args=args
, train_dataset=tokenized_dataset["train"]
, eval_dataset=tokenized_dataset["validation"]
, compute_metrics=compute_metrics
, tokenizer=tokenizer
)
trainer.train()
허깅페이스 로그인 및 업로드
%cd /content/drive/MyDrive/Colab Notebooks/NLP
# 허깅페이스 로그인
from huggingface_hub import login
# 파일 형태의 api_key 불러오기
with open("./key/huggingface_api_key", 'r') as f:
api_key = f.read().strip()
login(token=api_key)
# 허깅페이스 업로드
repo_id = "사용자명/klue-ner-koelectra"
trainer.save_model(repo_id)
model.save_pretrained(repo_id)
tokenizer.save_pretrained(repo_id)
trainer.push_to_hub(repo_id)파이프라인으로 업로드한 모델 불러와 결과 확인
# pipeline 사용하여 결과 확인
text = "이몽룡과 성춘향은 남원 광한루에서 자주 만났다"
# task: token-classification
# 안 쓰면 자동으로 설정됨 → 정확성을 위해 직접 작성해주기
from transformers import pipeline
checkpoint_mymodel = "be2be2/klue-ner-koelectra"
my_model = pipeline(task="token-classification", model=checkpoint_mymodel)
result = my_model(text)
result[{'entity': 'B-PS',
'score': np.float32(0.33359873),
'index': 1,
'word': '이',
'start': 0,
'end': 1},
{'entity': 'I-PS',
'score': np.float32(0.3832988),
'index': 2,
'word': '##몽',
'start': 1,
'end': 2},
{'entity': 'I-PS',
'score': np.float32(0.3448925),
'index': 3,
'word': '##룡',
'start': 2,
'end': 3},
{'entity': 'B-PS',
'score': np.float32(0.30707076),
'index': 5,
'word': '성',
'start': 5,
'end': 6},
{'entity': 'I-PS',
'score': np.float32(0.34509343),
'index': 6,
'word': '##춘',
'start': 6,
'end': 7},
{'entity': 'I-PS',
'score': np.float32(0.32579824),
'index': 7,
'word': '##향',
'start': 7,
'end': 8},
{'entity': 'I-PS',
'score': np.float32(0.110316806),
'index': 9,
'word': '남원',
'start': 10,
'end': 12},
{'entity': 'I-OG',
'score': np.float32(0.13733202),
'index': 10,
'word': '광',
'start': 13,
'end': 14},
{'entity': 'I-OG',
'score': np.float32(0.17323461),
'index': 11,
'word': '##한',
'start': 14,
'end': 15},
{'entity': 'I-OG',
'score': np.float32(0.23224503),
'index': 12,
'word': '##루',
'start': 15,
'end': 16}]- task는 어떻게 확인하나요?
- checkpoint 폴더의 config.json에서 확인 가능
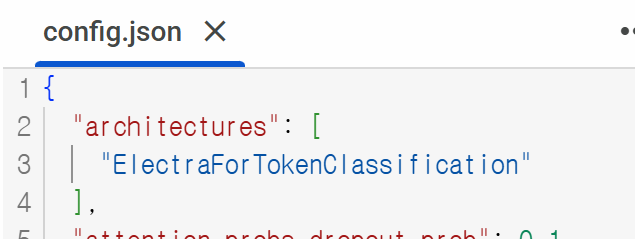
- checkpoint 폴더의 config.json에서 확인 가능
6교시: 추출적 질의응답
- 추출적(Extractive) 질의 응답: 주어진 문맥에서 답변을 추출
- 추출형 QA 시스템은 주어진 문맥에서 질문의 답변이 포함된 텍스트의 특정 부분을 추출
- 예를 들어, BERT 기반의 QA 모델은 입력된 문맥과 질문을 받아 답변의 시작과 끝 위치를 식별
- 주로 SQuAD와 같은 데이터셋을 통해 학습
- cf. 생성적(Abstractive) 질의 응답: 문맥에서 질문에 올바르게 답하는 답변을 생성
- 생성형 QA 시스템은 주어진 문맥을 기반으로 새로운 답변을 생성
- 질문에 대한 답변을 문맥 내에서 생성해 내거나, 문맥 없이도 답변을 생성
- 예를 들어, GPT-3와 같은 모델은 입력된 질문을 기반으로 자유 텍스트 형태의 답변을 생성할 수 있음
추출적 질의응답에서 정답의 시작과 끝 위치를 찾는 이유는?
QA 전처리 과정에서 질문과 본문을 하나로 묶어 토크나이징 하는 이유는?
오프셋 매핑(offset mapping)이 역할은?
질의응답(Question Answering)
- 질의응답 태스크는 주어진 질문에 대한 답변을 제공해 주는 태스크
- 태스크 유형
- 추출적(extractive) 질의 응답: 주어진 문맥에서 답변을 추출 → 문맥 데이터(context)에서 답을 찾아 그대로 답변해 주는 것
- KLUE-MRC 데이터셋 사용
- 기계 독해 데이터셋이라는 뜻에서 MRC가 붙었음
- MRC(Machine Reading Comprehension; 기계 독해): AI 알고리즘이 스스로 문서를 분석하고 질문에 대한 최상의 답을 찾아내는 것
- 스쿼드(SQuAD, Standford Question Answering Dataset): 컴퓨터가 사람처럼 주어진 문서를 읽고 이해한 후 질문에 대한 정답을 찾아내는 MRC(기계 독해 이해력) 테스트의 하나. 스텐퍼드 대학에서 만들었음
- train, test 분리 후 사용
- 기계 독해 데이터셋이라는 뜻에서 MRC가 붙었음
# 데이터 불러오기
from datasets import load_dataset
dataset = load_dataset("klue", "mrc", split="train[:1000]")
print(dataset)Dataset({
features: ['title', 'context', 'news_category', 'source', 'guid', 'is_impossible', 'question_type', 'question', 'answers'],
num_rows: 1000
})# 훈련용, 평가용(테스트용) 분리
dataset = dataset.train_test_split(test_size=0.2, seed = 6)
datasetDatasetDict({
train: Dataset({
features: ['title', 'context', 'news_category', 'source', 'guid', 'is_impossible', 'question_type', 'question', 'answers'],
num_rows: 800
})
test: Dataset({
features: ['title', 'context', 'news_category', 'source', 'guid', 'is_impossible', 'question_type', 'question', 'answers'],
num_rows: 200
})
})dataset["train"][0]{'title': '서울 강북 재개발부터 광주·울산까지 ...불붙은 청약 1순위 마감 행렬',
'context': '청약 1순위 자격 완화 속에 저금리로 마땅한 투자처를 찾지 못한 시중의 부동자금이 분양시장에 몰리면서 청약 열기가 한층 뜨거워지고 있다. 기존 주택시장이 활기를 띠고 있는 지방부터 회복 속도가 더뎠던 서울 강북권 재개발 아파트까지 내 집 마련에 나선 실수요자와 분양권 매매 차익을 기대한 투자자들의 청약이 늘어난 결과라는 분석이다.26일 금융결제원에 따르면 서울 왕십리 뉴타운 3구역 센트라스 아파트는 지난 25일 1순위 청약접수 결과 1029가구 모집에 1만804명이 몰려 평균 10.5 대 1의 경쟁률로 모든 주택형이 마감됐다. 지하철 2호선 상왕십리역이 단지와 연결돼 도심은 물론 강남권 출퇴근이 쉬워 실수요 청약자들이 많았다는 지적이다. 2013년 분양 당시 중대형 아파트 미분양으로 몸살을 앓았던 인접 1구역 텐즈힐 단지가 최근 대부분 팔린 것도 긍정적인 요인으로 작용했다고 인근 중개사무소 관계자들은 설명했다.같은 날 경기 화성 동탄2신도시 A34블록에서 분양한 동탄2신도시 ‘에일린의 뜰’도 1순위 청약에서 443가구 공급에 5714명이 접수해 평균 12.8 대 1의 경쟁률을 보였다. 전용 74㎡는 청약 경쟁률이 최고 109.6 대 1에 달했다.지방에서도 1순위 마감 행진이 이어지고 있다. 전세가율(매매가 대비 전세금 비율)이 80%에 육박할 정도로 전셋값 상승세가 가파른 광주광역시에서 공급된 이안 광주 첨단 아파트는 292가구 모집에 광주 청약 1순위자만 1만6494명이 신청해 평균 경쟁률이 56.5 대 1에 달했다. 1가구를 모집한 전용 84㎡는 236명이 몰렸다. 울산 신정동 신정지웰도 2.7 대 1의 청약 경쟁률로 모든 주택형이 1순위에서 마감됐다.분양 계약 성적도 좋은 편이다. 지난 16일 13.7 대 1에 달하는 청약 경쟁률을 기록한 서울 마포 한강2차 푸르지오 오피스텔은 분양 계약 시작 1주일 만에 448실 모두 주인을 찾았다. 박원갑 국민은행 수석부동산전문위원은 “치솟는 전셋값과 주택 거래 증가, 저금리가 동시에 맞물리면서 청약 경쟁이 치열해지고 있다”면서도 “공급 물량이 크게 늘어난 만큼 입지와 분양가 등에 따라 청약 쏠림 현상이 나타날 것”으로 내다봤다.',
'news_category': '부동산',
'source': 'hankyung',
'guid': 'klue-mrc-v1_train_15439',
'is_impossible': False,
'question_type': 1,
'question': '에일린의 뜰 청약시 109명중 1명이 당첨된 전용 면적은 얼마인가?',
'answers': {'answer_start': [562], 'text': ['74㎡']}}- 데이터셋 내 주요 필드 설명
- title: 해당 데이터의 주제
- context: 질문 답변에 필요한 본문 내용 → 질문에 대한 답을 찾을 배경 지식
- news_category: context 카테고리(본문 내용의 분류 정보)
- question: 모델이 답해야 하는 질문
- answers
- answer_start: context에서 정답의 시작 위치
- text: 정답 텍스트
질의응답 데이터 전처리
- 질문과 본문을 하나의 시퀀스로 묶어 토크나이징 진행
- 입력은 질문과 본문이 하나로 묶인 형태로 모델에 전달
- 모델은 CLS, SEP 토큰으로 질문과 본문 구분
- 토크나이저는 KoELECTRA-small 사용
- 정답 위치(start, end 포지션)를 문자 위치에서 토큰 위치로 변환
- 정답이 본문 어디에서 시작하고 끝나는지 토큰 단위로 변환해 표시하여 학습에 활용
- 본문 길이가 너무 길어 max_length에 정답이 포함되지 않는 경우 0,0으로 처리해 학습 데이터에서 제외
- 정답이 본문에 없으면 학습에서 제외 처리
- 오프셋 매핑(offset mapping): 각 토큰의 시작과 끝 문자 위치를 숫자 형태로 변환한 값
- 정답 위치와 토큰 위치를 매칭하는 데 사용
- 전처리 과정에서 질문과 본문의 경계를 명확히 인지하도록 토크나이저가 내부적으로 처리
- 학습 시 질문과 본문을 함께 인코딩하여 모델이 문맥 내에서 답변 위치를 찾도록 함
- QA 전처리 핵심 요약
- 질문 데이터(Questioin)와 본문 데이터(Context)를 가지고 학습
- 2개를 하나로 묶어서 토크나이징
- 어디서부터 질문이고 어디서부터 본문인지 알아야 함 → 토큰으로 알리기
- 정답 문자열의 시작/끝 토큰의 위치를 계산해야 함
start_positions,end_position
| 항목 | 설명 |
|---|---|
| 🎯 목적 | 질문 + 지문(context)을 토큰화하고, 정답의 시작/끝 위치를 토큰 인덱스로 변환 |
| 📎 입력 구성 | [CLS] question [SEP] context [SEP] 형태 |
| 🧭 위치 변환 | 정답의 문자 위치 → 토큰 위치 변환 (offset_mapping 사용) |
| ⚠️ 주의점 | context가 잘릴 경우 정답이 사라질 수 있음 → 이때 start=0, end=0 처리 |
offset_mapping: 현재 단어가 본문에서 몇 번째 문자 범위인지 알려주는 정보
from transformers import AutoTokenizer
checkpoint = "monologg/koelectra-small-discriminator"
tokenizer = AutoTokenizer.from_pretrained(
checkpoint
)6교시 정리
- 핵심 개념
- 추출적 질의응답은 문맥 내에서 질문에 대한 답변의 시작과 끝 위치를 찾아내는 과정
- 요약
- 추출적 질의응답 태스크 개념
- SQuAD
- 전처리 과정에서 질문과 본문을 하나로 묶어 토크나이징하고 정답 위치를 토큰 단위로 변환
하루 돌아보기
👍 잘한 점
- 웹 수업 대답 열심히 했음
- Token Classification 수업 중 궁금한 부분 질문 많이 함
👎 아쉬웠던 점
- 서로 다른 두 개의 수업을 하루에 들으니까 뭔가 집중이 애매하게 깨지는 느낌
- 웹 강의가 시작된 김에 TIL 작성 방식을 좀 바꿔보았는데 아직 손에 안 익어서 오래 걸림
🔬 개선점
- 오전에는 웹에 집중! 오후에는 자연어 처리 집중!
