[인공지능사관학교: 자연어분석A반] Node.js (10) / AI-Agent
목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. EJS
B. 2교시
1. EJS (cont.)
2. main.ejs 작성
C. 3교시
1. 회원 정보 조회: 반복문
2. 총정리
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
2. LangGraph
B. 5교시
1. Agent
2. LangGraph 탄생 배경
3. Tavily
4. 전통적인 RAG 문제점
C. 6교시
1. TypedDict
2. Annotation
Ⅲ. CAREER UP
현직자 특강Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
- 회원 가입 CRUD
- router 두 개
- 정적 페이지 리턴 라우터 → sendFile → 데이터를 담아 이돌하는 게 불가능(만든 파일만 돌려줌)
- 값을 꺼내기 위한 라우터 (DB값 꺼내고 페이지 이동)
- 사실 좋은 방법은 아니라고 함 → DB는 함수로 처리하고 페이지는 동적으로 만들어보기
- router 두 개
- dbRouter.js
- post → req.body
- 쿼리문 ? 의미: 아직 값을 모름 → 뒤에서 값 매칭
- conn.query → DB에 연결하고 쿼리문 보내서 결과값 받아오기 → err, rows 변수
- err: 오류 처리할 때 사용
- 404 페이지 보여주기, 500 페이지 ㅗㅂ여주기, 알림창 띄우기 등
- rows
- select → rows.length
- insert, update, delete → rows.affectedRows
2. EJS
- EJS 기초 폴더 만들고 express, ejs 설치
npm i expressnpm i ejs
- EJS 기초 폴더 안에 routes, views 폴더와 app.js 파일 만들기
- views의 역할: 동적 페이지 관리
- 동적 페이지 생성?
- 정적 페이지 리턴 vs. 동적 페이지 리턴
- 정적 페이지 리턴 예: 위키
- 동적 페이지 리턴 예: 로그인 후의 네이버 → Server Programing
- EJS란?
- Embedded JavaScript
- Embedded?: '간직하다, 끼워넣다, 포함되어 있다'는 뜻 → 내부에 무엇인가 포함하고 있는 상태
- HTML 안에 JS를 섞어서 동작하게 만드는 "템플릿" 엔진
- HTML은 조건문이 없음 → EJS가 조건문을 쓸 수 있게 만들어 줌!
- 템플릿 엔진이란? 개발자는 페이지를 하나만 만들고(틀(템플릿)을 제공) 서버가 값을 동적으로 생성
- Pug, Nunjucks, HandleBars 등 다양한 템플릿 엔진이 존재
- 고유한 문법 → 문법을 새롭게 공부해야 함
- EJS는 자바스크립트의 문법과 똑같다! → 따로 공부할 필요 없다는 장점
- Embedded JavaScript
- 특징
- HTML 기반으로 작성
- JS 문법을 그대로 사용한다
- 검색 엔진에 최적화(SEO)
- 사용처
- 로그인 후 메인 페이지, 게시판 글 목록 조회, 검색 결과 등
- 알아두면 좋은 웹 지식
- EJS를 통해서 페이지를 제작(동적 생성) → SSR(Server Side Rendering) ↔ CSR(Client Side Rendering)
- Rendering: 페이지를 만들어내는 행위
- SSR은 HTML 파일을 서버가 제작 후 → 클라이언트에게 보내는 방식
- SSR 장점
- 빠른 초기 로딩 속도 → 클라이언트에서는 바로 출력이 가능
- 예: 완제품 가구 배송 vs. 이케아 가구 조립
- SEO 최적화: 검색 엔진이 HTML 파일을 읽어들일 때 속도가 빠르다 → 내용을 채워서 넘기기 때문에
- 빠른 초기 로딩 속도 → 클라이언트에서는 바로 출력이 가능
- EJS를 통해서 페이지를 제작(동적 생성) → SSR(Server Side Rendering) ↔ CSR(Client Side Rendering)
- CSR(Client Side Rendering) → 페이지를 제작하는 곳이 클라이언트
- 서버가 비어있는 html과 태그를 생성하는 JS 코드를 클라이언트에게 전달 → 클라이언트가 HTML 파일 제작
- React, Angular, Vue 등이 CSR 방식을 채택 → 설계도면(html)과 부품(js)만 보냄
- 비어있는 html → 검색 엔진 최적화가 안 됨
- 서버가 비어있는 html과 태그를 생성하는 JS 코드를 클라이언트에게 전달 → 클라이언트가 HTML 파일 제작
- CSR 장점
- 동적 UI 생성에 효율적이다 → 특정 부분만 빠르고 쉽게 수정이 가능하다 (비동기 통신)
- 3칸짜리 서랍장인데 2칸만 필요하면 커스텀 가능 (SSR은 3칸짜리 서랍장이 이미 만들어져서 배달됨)
- 프론트엔드와 벡엔드의 역할 구분이 확실히 가능하다.
- 동적 UI 생성에 효율적이다 → 특정 부분만 빠르고 쉽게 수정이 가능하다 (비동기 통신)
- 최신 트랜드: SSR+CSR 하이브리드 렌더링을 선호
- 초기 페이지는 SSR 기법 + 특정 내용을 바꿀 때는 CSR 기법
- Next.js, Svelte 등
- 토스가 이걸로 엄청 유명함: 웹뷰 기반
- 토스는 애플리케이션을 웹으로 만들었음 → 웹으로 만들었을 때의 단점: background 기능 실행, 오프라인 기능 실행, 알림 기능 실행, 카메라 인식 기능 실행 등을 못 씀 → 네이티브 앱 도입
- 웹뷰 + 네이티브 앱 개발(Android, ios) → CSR + SSR + 네이티브 앱 개발(Android, ios)
- 메인 기반이 CSR + SSR라는 특징
- 다른 기업이 네이티브 앱만 개발하는 전통적인 애플리케이션 구현하는 것과 달리 여기는 웹뷰를 먼저 만들고 네이티브 앱 개발을 추가해 완벽한 하이브리드 애플리케이션을 만들었음 → 반응이 빠르고 사용자 입장에서 쓰기 편함
B. 2교시
express 업데이트
이제 body-parser 호출하지 않고 바로app.use(express.urlencoded({extended:true}));하면 된다고 함!
1. EJS (cont.)
- 서버 만들기: app.js
- 기초 뼈대 만들기
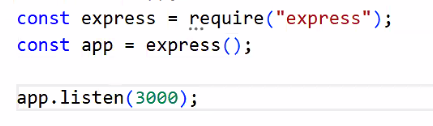
- 기초 뼈대 만들기
- mainRouter.js
- 기초 뼈대 만들기
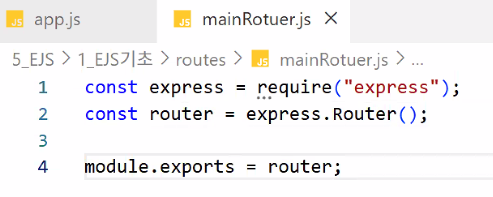
- 메인 페이지 관리 뼈대 만들기
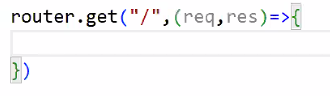
- 기초 뼈대 만들기
- views 폴더 → main.ejs 생성하기
- main.ejs 기반은 HTML → 느낌표+엔터 하면 HTML 뼈대 만들어짐
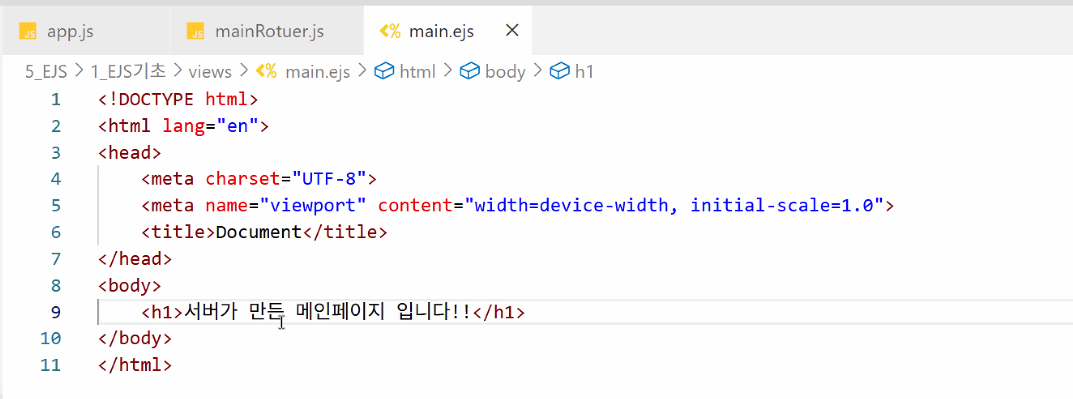
- main.ejs 기반은 HTML → 느낌표+엔터 하면 HTML 뼈대 만들어짐
- app.js: mainRouter.js 연결하기
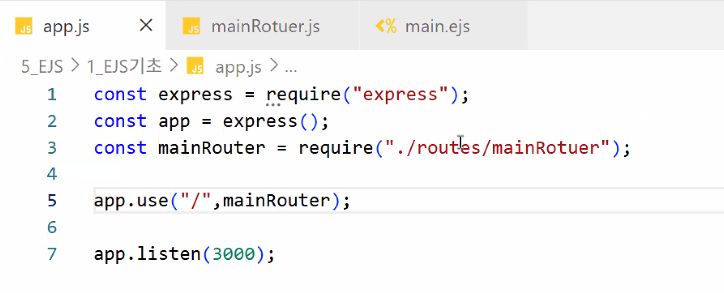
- mainRouter.js:
.render()- 템플릿 엔진을 통해서 페이지를 제작할 때는
.render()사용
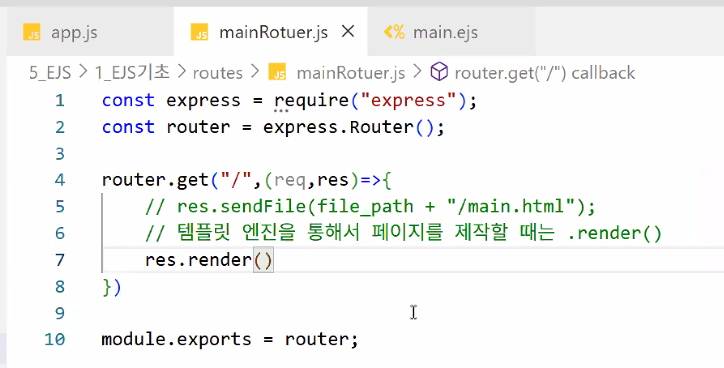
- 템플릿 엔진을 통해서 페이지를 제작할 때는
-
views 폴더 경로 설정하기: app.js
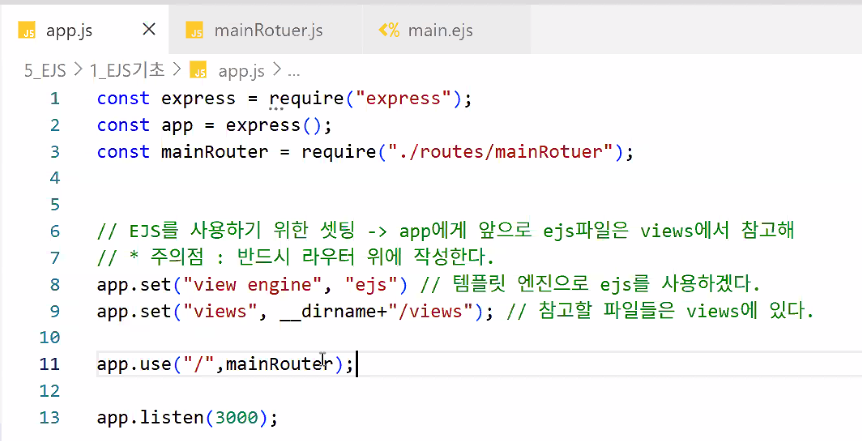
- EJS를 사용하기 위한 세팅 → app에게 앞으로 ejs 파일은 모두 views에서 참고하라고 지시
- 주의점: 반드시 라우터 사용등록 전에 작성
app.set("view engine","ejs");: 템플릿 엔진으로 ejs를 사용하겠다는 의미app.set("views",__dirname+"/views");: 참고할 파일들은 views에 있다는 의미
- EJS를 사용하기 위한 세팅 → app에게 앞으로 ejs 파일은 모두 views에서 참고하라고 지시
-
mainRouter.js
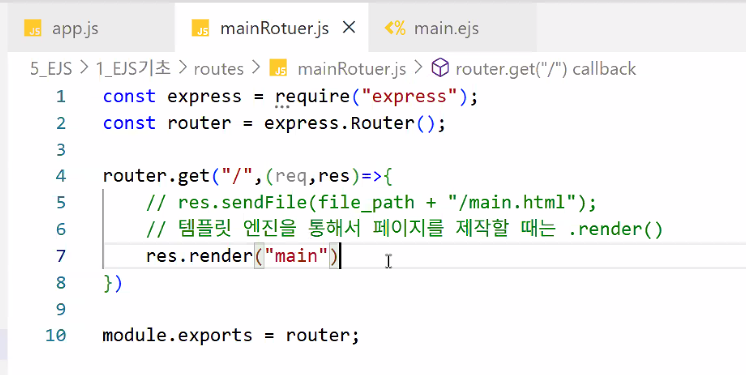
- 확장자, 경로는 app.js에서 이미 설정했기 때문에 필요 없음
2. main.ejs 작성
- EJS 문법 두 가지
<% %>: JS의 문법 작성이 가능한 공간 → 조건문, 반복문<%= %>: 넘겨준 값을 사용하는 공간- HTML에는 변수 개념이 없기 때문에 이걸로 변수를 쓰게 해 주는 것
- 변수 설정하기
- main.ejs

- mainRouter.js
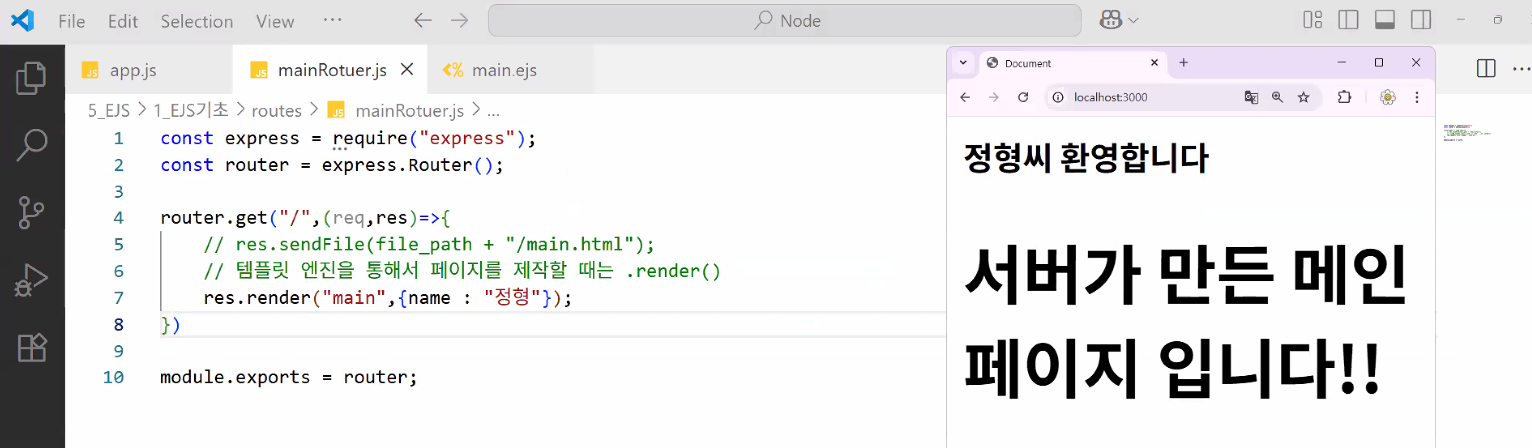
- 서버가 name을 받아 하나의 템플릿(main.ejs)을 사용자마다 바꿔 보여줌
- main.ejs
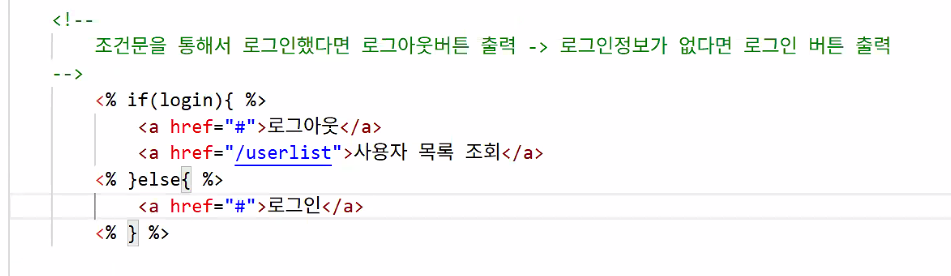
- 로그인/로그아웃 버튼
- 조건문을 통해서 로그인했다면 로그아웃 버튼 출력 & 로그인 정보가 없다면 로그인 버튼 출력
어떻게 접근해야 할까?
- 일단 로직 써보기

- ejs 문법 적용하기

C. 3교시
1. 회원 정보 조회: 반복문
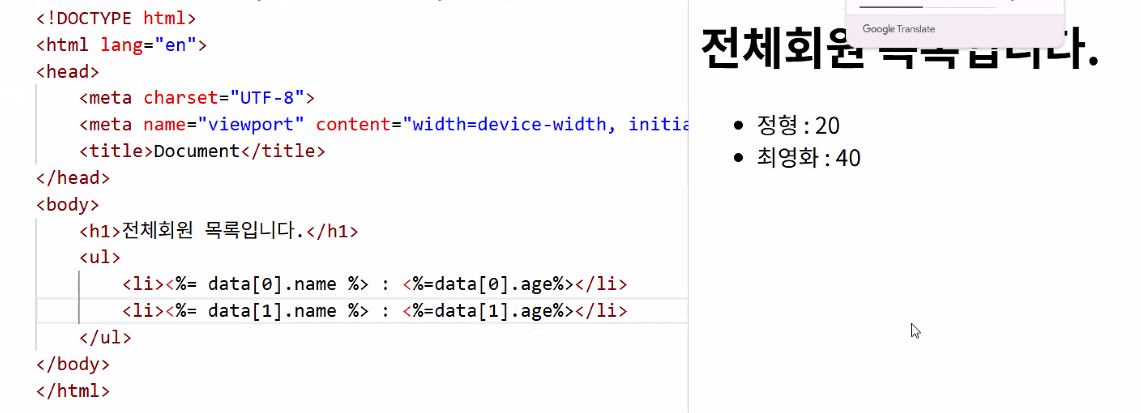
- main.ejs
- 사용자 목록 조회 경로 추가:
<a href="/userlist">사용자 목록 조회</a>
- 사용자 목록 조회 경로 추가:
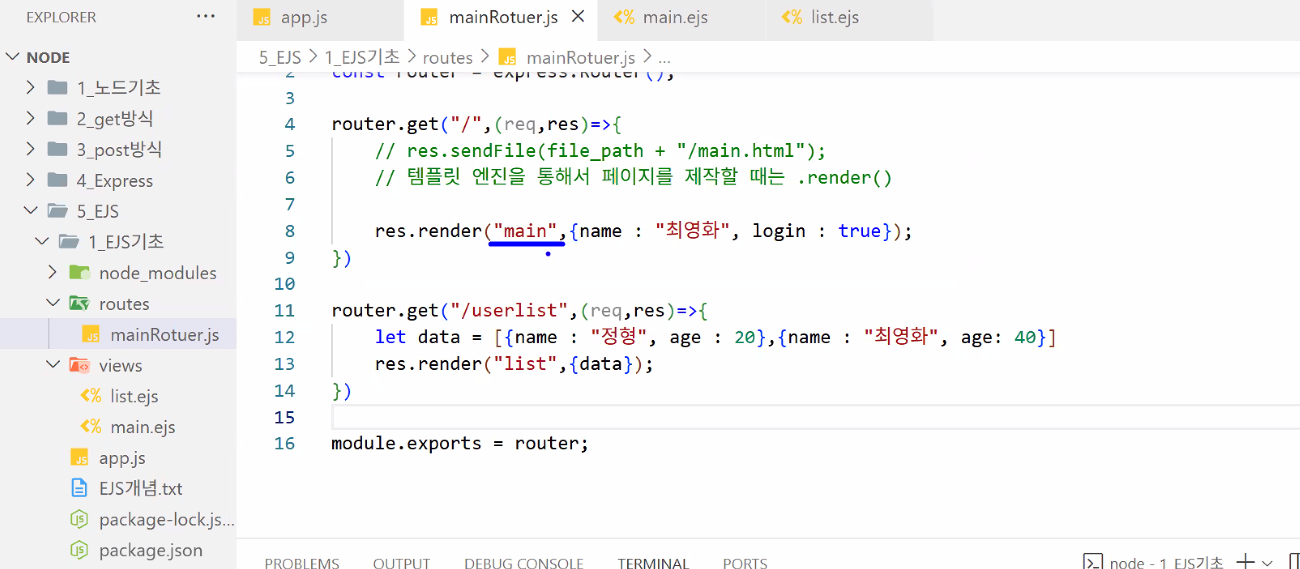
- mainRouter.js
/userlist경로 연결하기
- 오늘은 DB 연결 전이니까 임의의 데이터 만들어주기

- 오늘은 DB 연결 전이니까 임의의 데이터 만들어주기
- views 폴더 → list.ejs 만들기
- 보낸 데이터 확인하기
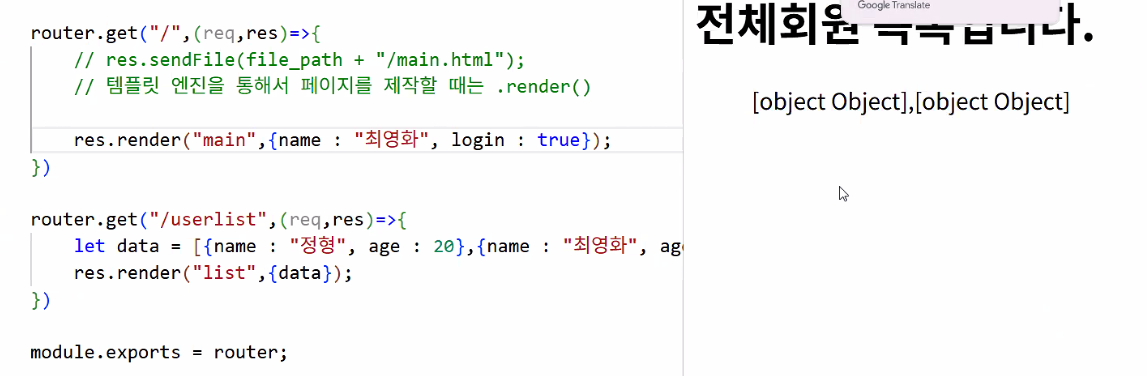
- 기본 개념 파악하기
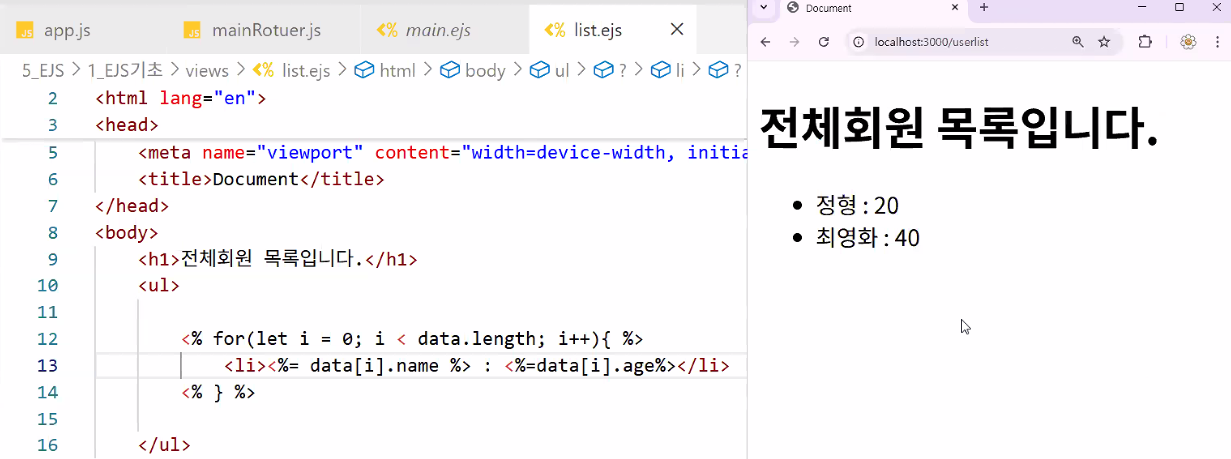
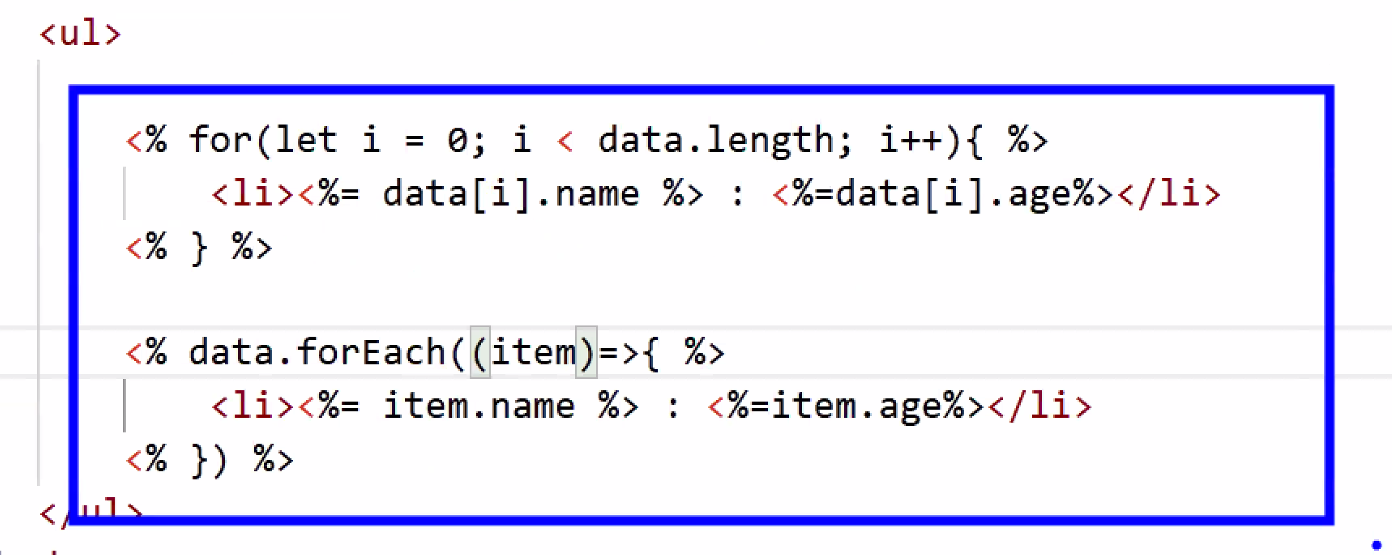
- 반복문 적용하기: for 문
- 최신 문법 적용하기: forEach → 훨씬 간결함!

- 보낸 데이터 확인하기
2. 총정리
- EJS(Embedded JavaScript)
- HTML 안에 JS를 섞어서 동작하게 만드는 "템플릿" 엔진
- 템플릿 엔진: 개발자는 페이지를 하나만 만들고(틀을 제공) 서버가 값을 동적으로 생성 →
render()함수
- 템플릿 엔진: 개발자는 페이지를 하나만 만들고(틀을 제공) 서버가 값을 동적으로 생성 →
- cf. JSP = HTML + JAVA
- 특징
- HTML 기반으로 작성
- JS 문법을 그대로 사용한다
- 검색 엔진에 최적화(SEO)
- HTML 안에 JS를 섞어서 동작하게 만드는 "템플릿" 엔진
- SSR, CSR ★★★
- 실습
- app.js
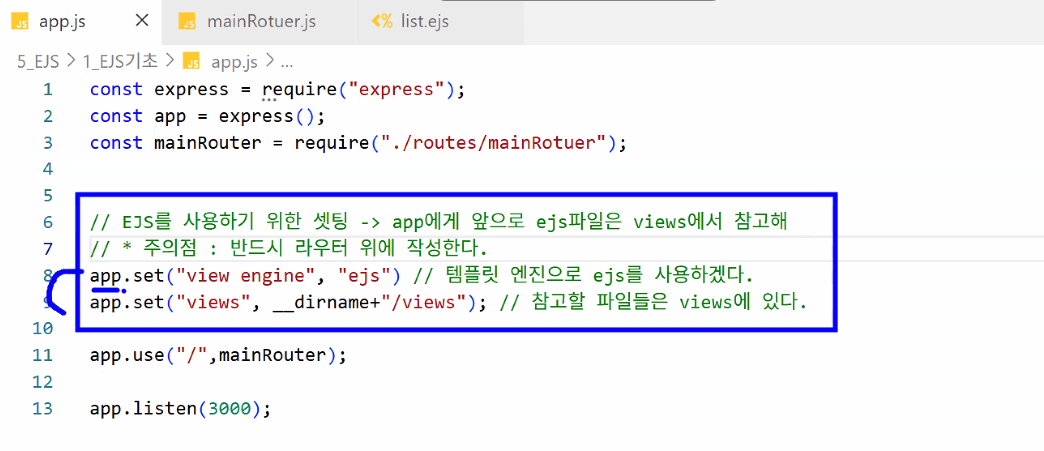
- ejs 사용 시 주의 사항: 1) 모듈 설치하기 2) 설정 두 개 반드시 넣기: app.set()
- view engine 설정은 내가 사용할 템플릿 엔진의 종류 적기
- views 설정은 view 폴더 경로 적기
- mainRouter.js
- main.ejs
<%= %>: 넘겨준 값을 사용하는 공간
→ 예:<strong><%= name %> 님 환영합니다</strong><% %>: JS의 문법 작성이 가능한 공간 → 조건문, 반복문
- list.ejs
- 반복문
- 반복문
- app.js
추가: 세션
값을 공통적으로 공유할 수 있는 가상의 공간을 만들어 주는 것
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
- RAG 평가 지표: RAGAS
- RAG 기술의 성능을 정량적으로 평가하기 위한 오픈소스 프레임워크
- 검색 품질과 응답 품질을 지표로 설정 → 설정 성능을 진단
- 단순 결과보다 검색 품질과 생성 품질을 모두 평가해 문제의 원인을 정확하게 찾을 수 있도록 함
- 목적에 맞는 지표 설정 필요
- 필수 속성 잘 확인하기
실습은 단순 문장으로 했지만 실제 RAG도 청크화 → 제너레이션 과정 거쳐서 평가하면 됨
2. LangGraph
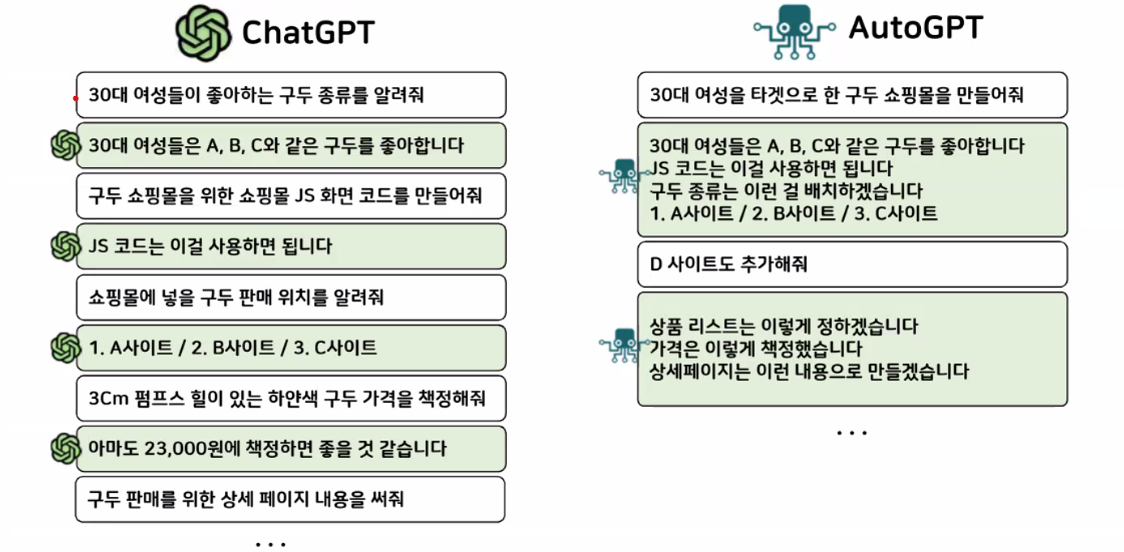
- Agentinc AI
- 복잡한 동적 환경에서 목적을 달성하기 위해 스스로 판단하는 인공지능
- cf. LLM: 한 가지 역할(질문-답변) 반복
→ LLM은 요청-답변 반복 vs. Agentic AI는 스스로 생각
📘 LangChain · LangSmith · LangGraph · Agent 비교표
| 구분 | 정의 | 중점 | 사용 시점 | 결과물 | 비유 |
|---|---|---|---|---|---|
| LangChain | LLM 앱 개발 프레임워크 | 체인, 프롬프트, 메모리, 리트리버, 툴 연동 | 프로토타입 / 기본 앱 제작 | “앱 프로토타입” | 자동차를 설계·조립하는 도구 |
| LangSmith | LLM 앱 관찰·평가·운영 플랫폼 | 디버깅, 평가(Eval), 모니터링 | 앱 운영·최적화 / 품질 관리 | “운영 가능한 서비스” | 자동차를 점검·관리하는 도구 |
| LangGraph | LLM 앱을 그래프 기반으로 설계하는 실행 엔진 | 상태(State) + 조건 분기 + 반복 + 복잡한 워크플로우 | 복잡한 멀티스텝·멀티에이전트 설계 | “복잡한 AI 워크플로우/멀티에이전트 시스템” | 자동차를 도로망(교차로·신호체계) 위에서 움직이게 하는 엔진 |
| Agent | LLM이 스스로 의사결정하며 툴을 활용하는 방식 | 툴 선택·실행, 관찰, 다시 의사결정(반복) | 앱이 더 자율적으로 동작해야 할 때 | “지능형 시스템(챗봇·자동화 AI)” | 자동차가 스스로 어디로 갈지 판단하고 운전하는 AI 운전자 |
→ LLM 모델의 가장 큰 문제점인 hallucination을 완화할 것인지 고민하다가 나온 게 LangGraph!
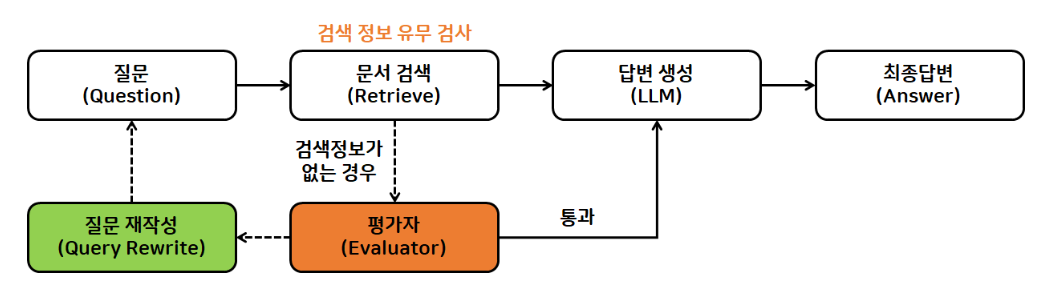
- 흰색 플로우: LLM
- 주황, 초록: RAG
→ 여기에 블록을 좀 더 붙이면 LangGraph
LangChain vs LangGraph 비교표
| 구분 | LangChain | LangGraph |
|---|---|---|
| 주요 목적 | - LLM을 다양한 외부 도구와 쉽게 통합 - 간단한 체인 구조로 애플리케이션 구성 - 빠른 프로토타이핑과 기본 LLM 앱 개발에 유용 | - 복잡한 워크플로우와 정교한 의사결정 프로세스 구현 - 여러 단계 처리·조건부 로직이 필요한 고급 AI 시스템에 적합 |
| 구조 | - 체인/에이전트 기반 구조 - 선형적 처리 과정, 미리 정의된 에이전트 패턴 구현에 용이 | - 그래프 기반 구조 - 노드와 엣지로 유연한 워크플로우 설계 - 복잡한 로직·다단계 프로세스 직관적 모델링 |
| 상태 관리 | - 암시적·자동화된 상태 관리 - 개발 과정 단순화 - 세밀한 상태 제어는 제한적 | - 명시적·세밀한 상태 관리 - 각 단계 상태를 직접 제어·수정 가능 - 상태 변화 정확 추적·관리 |
| 유연성 | - 미리 정의된 컴포넌트 중심 - 기본 기능 빠른 구현에 적합 - 고도 커스터마이즈 로직은 상대적으로 제한 | - 높은 유연성 - 그래프 구조 자유 설계 - 각 노드 동작을 상세 정의 가능 |
| 학습 곡선 | - 직관적 API, 풍부한 예제 - 초보자도 빠르게 학습 - 러닝 커브 완만 | - 그래프 이론·상태 관리 이해 필요 - 러닝 커브 상대적으로 가파름 - 복잡·정교한 시스템 구축 가능 |
| 용도 | - 간단한 LLM 애플리케이션 - RAG 시스템 - 빠른 개발·프로토타이핑 | - 복잡한 AI 시스템 - 다중 에이전트 시스템 - 복잡한 의사결정이 필요한 프로젝트 |
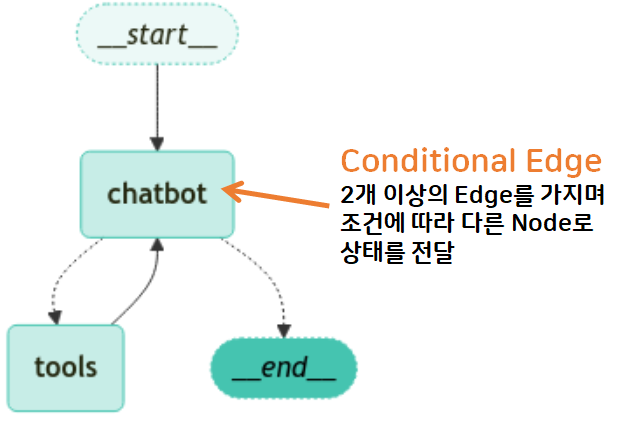
- LangGraph
- 그래프 기반 구조
- 입력 → 여러 개의 edge & node → 결과물 마음에 안 들면 다시 돌아가기: 유연한 workflow
B. 5교시
1. Agent
- Agent는 자동화된 부분이라 눈에 안 보임 → LangGraph를 통해 눈으로 확인! (그래프화)

- 어디로 가는지 파악하기 위해 신호 체계를 주면서 눈으로 볼 수 있게끔 그래프화
- Agent란?
- LLM이 단순 답변을 넘어서 스스로 판단 → 도구 실행 → 결과 활용하는 구조
- 핵심 구조
- 목표(Goal/Task): 사용자의 요청
- 정책(Reasoner/Policy): 어떤 행동을 할지 결정
- 도구(Tools): 계산기, 검색기, DB, 코드 실행 등
- 메모리(State/History): 대화와 실행 로그 기록
- 기본 루프: Agent Loop
- 질문 → 생각 → 도구 실행 → 관찰 → 반복 → 최종 답변
- 예시: 사용자: “3+5 계산해줘” → 에이전트 사고: “계산기가 필요하다” → 도구 실행: 계산기 → 계산기로 계산: 8 →최종 답변: “답은 8입니다”
- LangGraph와의 연결
- 에이전트는 기본적으로 보이지 않는 루프
- LangGraph = 이 루프를 그래프로 시각화하고 제어하는 프레임워크
- Node(노드) = 생각 / 도구 실행 / 판단
- Edge(엣지) = 다음 단계로 이동 규칙
- State(상태) = 현재 맥락 (질문, 도구 결과, 로그 등)
- Interrupt/Checkpoint = 중단·재개, 상태 저장 지원
Agent = 보이지 않는 루프
LangGraph = 그 루프를 보이게 만드는 설계도
2. LangGraph 탄생 배경
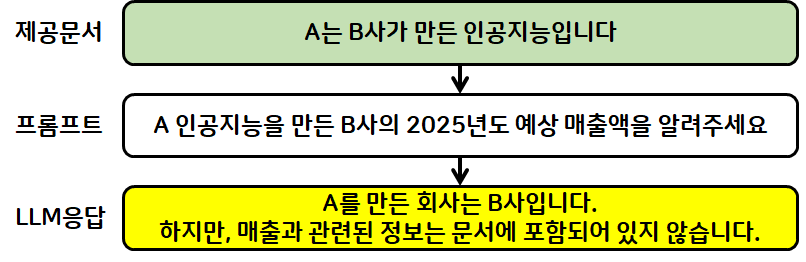
- LLM이 생성하여 답변한 내용에 환각(hallucination)이 포함
- 특히 RAG를 적용하여 얻은 답변이 문서에 없는 경우 사전 지식을 이용하여 답변을 생성하는 문제가 심함
- 문서 검색에서 원하는 내용이 없을 때에는 부족한 정보를 검색하여 답변을 보강하는 기능을 추가
- 주의: 생성형 AI는 "대답"하는 ai지 정답을 알려주는 ai가 아님!
- 문제점 사례
- RAG를 수행했을 때 문서 내 질문에 대한 답변이 존재하지 않는 경우가 존재
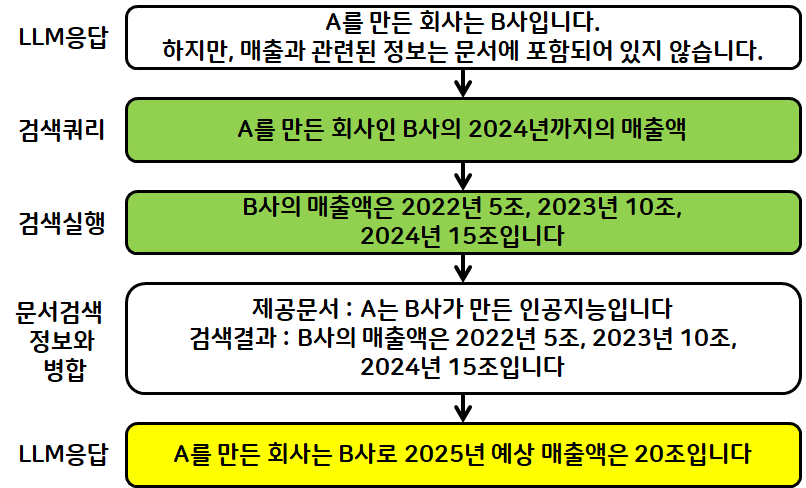
- 부족한 정보를 Web 검색하여 문서에 추가하는 로직을 추가한 경우
- 만약 검색결과에 잘못된 정보가 포함되거나 혹은 검색 결과에 없는 경우
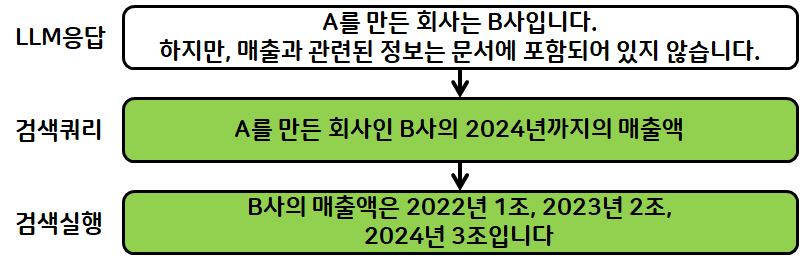
- 잘못된 검색결과가 결국 Hallucination으로 이어진 경우
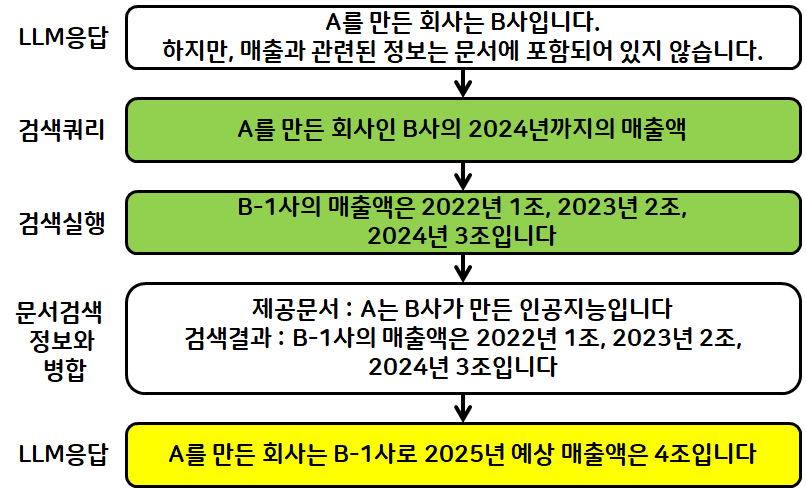
- RAG를 수행했을 때 문서 내 질문에 대한 답변이 존재하지 않는 경우가 존재
- 해결 방안
- 검색이 제대로 나올때까지 반복
- 계속 제대로 된 결과가 안 나온다면 → 토큰 사용량 폭증 문제
- Hallucination을 방지하는 LLM을 추가
- 코드가 점점 길어지고 복잡해짐
- LLM의 일관되지 않은 답변이 마치 나비효과로 이어져 답변 품질저하로 이어짐
- 검색이 제대로 나올때까지 반복
3. Tavily
- 외부 검색 기능(웹 검색)을 활성화: '검색 실행' 단계 → 검색해 주는 API를 추가: TavilySearch API Key 등록
- LangGraph 설계 시 LLM이 답변할 때는 기본적으로 모델이 학습한 데이터까지만을 사용함
- Tavily를 사용하여 LLM 전용으로 설계된 API를 사용하여 모델이 웹문서를 찾아 답변할 수 있도록 도와줌
- 웹 검색 도구(Tavily) API 키 등록
- 인증키 발급 후 불러오기
- 월 1000회 무로 사용 가능
4. 전통적인 RAG 문제점
- 사전에 고정되어야 하는 부분들이 많음
- 사전에 정의된 데이터 소싱(PDF, DB, Table 등) 자원
- 사전에 정의된 고정된 크기의 데이터 분할
- 사전에 정의된 입력
- 사전에 정의된 검색 방법
- 신뢰하기 어려운 LLM 혹은 Agent
- 고정된 프롬프트 형식
- LLM 답변 결과에 대한 문서와의 관련성/신뢰성
- Document Loader(데이터로드) → Answer(답변) RAG 파이프라인이 단방향 구조
- 모든 단계를 한 번에 다 잘해야 함
- 이전 단계로 되돌아가기 어려움
- 이전 과정의 결과물을 수정하기 어려움
해결 방법
- 현재 단계에서 잘못된 것을 확인
- 이전 단계로 되돌아가 수정
- 현재 단계로 돌아와 스스로 문제해결할 수 있도록 하는 흐름을 추가
- RAG 파이프라인을 보다 유연하게 설계
- 각 세부과정을 노드(Node)라고 정의하고 RAG의 8단계를 노드로 패키징
- 이전 노드 → 다음 노드 : 엣지(Edge) 연결
- 엣지는 방향성 갖고 있음
- 조건부 엣지 통해 분기 처리
- 노드와 엣지 연결하는 구조를 가짐으로써 단방향이 아니라 store에서 edge를 split으로 연결해 되돌아갈 수 있음
- 평가자 & Query Transform 추가
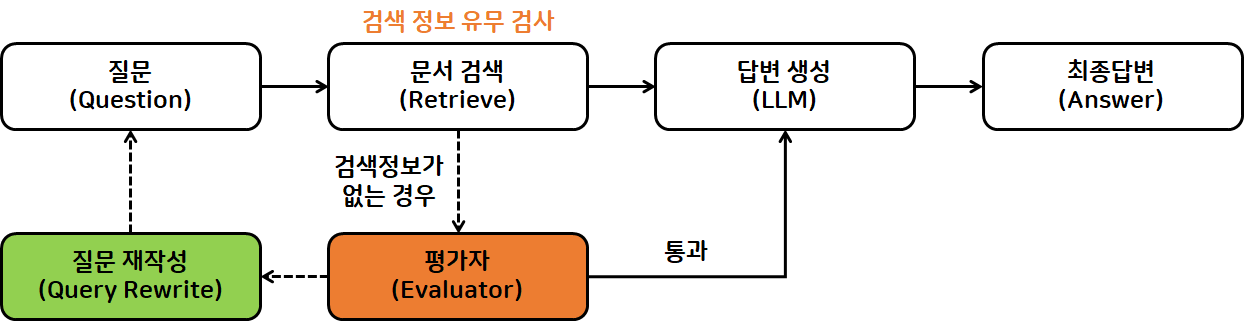
- 사용자 질문 들어오면, 초기 검색 진행
- 문서 검색 결과에 원하는 정보 있으면, LLM이 답변 생성으로 넘김
- 문서 검색 결과에 원하는 정보 없으면, LLM이 평가자(Evaluator)가 되어 질문 재작성 요청
- Query Transform 질문을 재작성하여 재질문
- 재질문에 따라 문서 검색
- 변경된 문서 검색 내용 다시 평가
- 추가 검색기를 통해 문맥(context) 보강
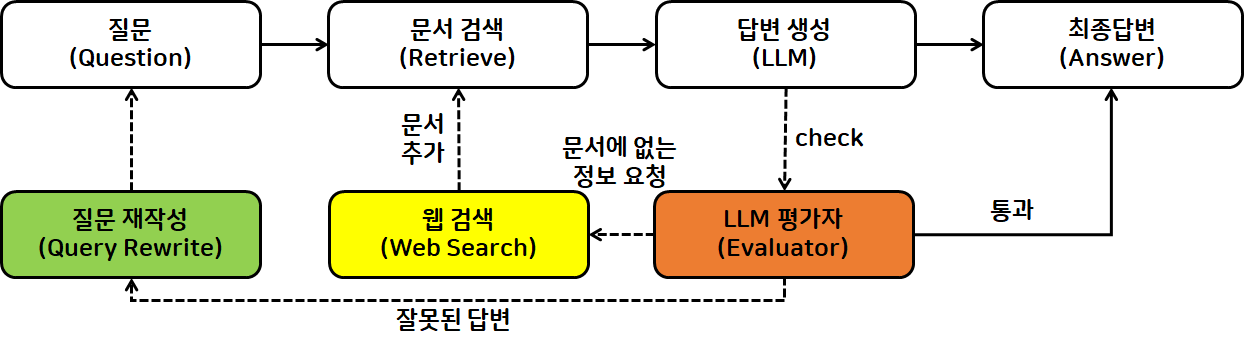
- 생성된 답변에 대해 사람이 모두 hallucination 여부 확인하기 힘듬
- LLM Evaluator로 생성된 답변 평가한 경우, 검색된 문서가 잘못되었다면 질문 재작성 과정으로 이동
- 만약, 문서에는 없는 정보가 요청되었다면 "웹 검색" 노드로 이동
- 웹 검색을 통해 내용을 보강해서 문서검색하거나 질문을 재작성
- 문서-답변 간 관련성 여부를 판단하는 평가자2를 추가하여 검증
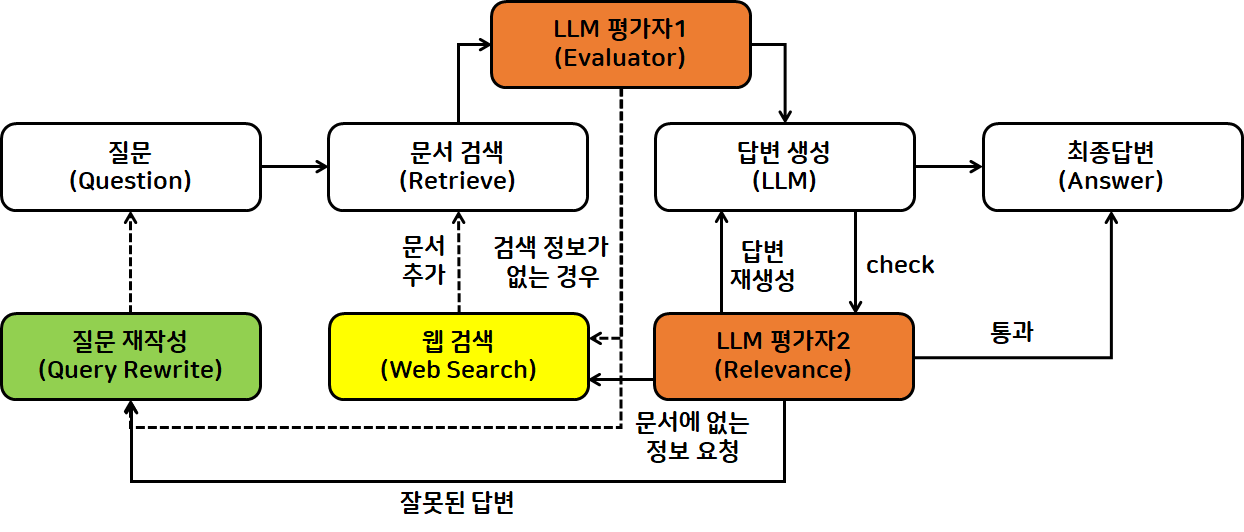
- 문서 검색된 결과를 평가할 수도 있고, 답변 생성된 결과를 평가할 수도 있음
- Hallucination 발생은 어느 정도 감안해야 하지만, 평가자2를 둠으로써 확률적으로 hallucination 줄일 수 있음
- 고전적인 단방향 구조에서 유연한 흐름(뒤로 가는 or 옆으로 빠지는) 만들 수 있음
-
유연한 흐름을 가지도록 LangGraph로 구현한 예시
-
Node, Edge, State를 통해 LLM 활용한 워크플로우에 순환 연산 기능을 추가해 손쉽게 흐름 제어
- Node: 어떤 작업(task) 수행할지 정의
- Edge: 다음으로 실행할 동작 정의
- State(상태): 현재 상태 값을 저장 및 전달하는데 활용
- Conditional Edge(조건부 엣지): 조건에 따라 분기 처리
-
Human-in-the-loop: 필요시 사람이 중간에 개입하여 다음 단계 결정
-
Checkpointer: 과거 실행 과정에 대한 수정 및 리플레이 기능 제공 (메모리 기능)
-
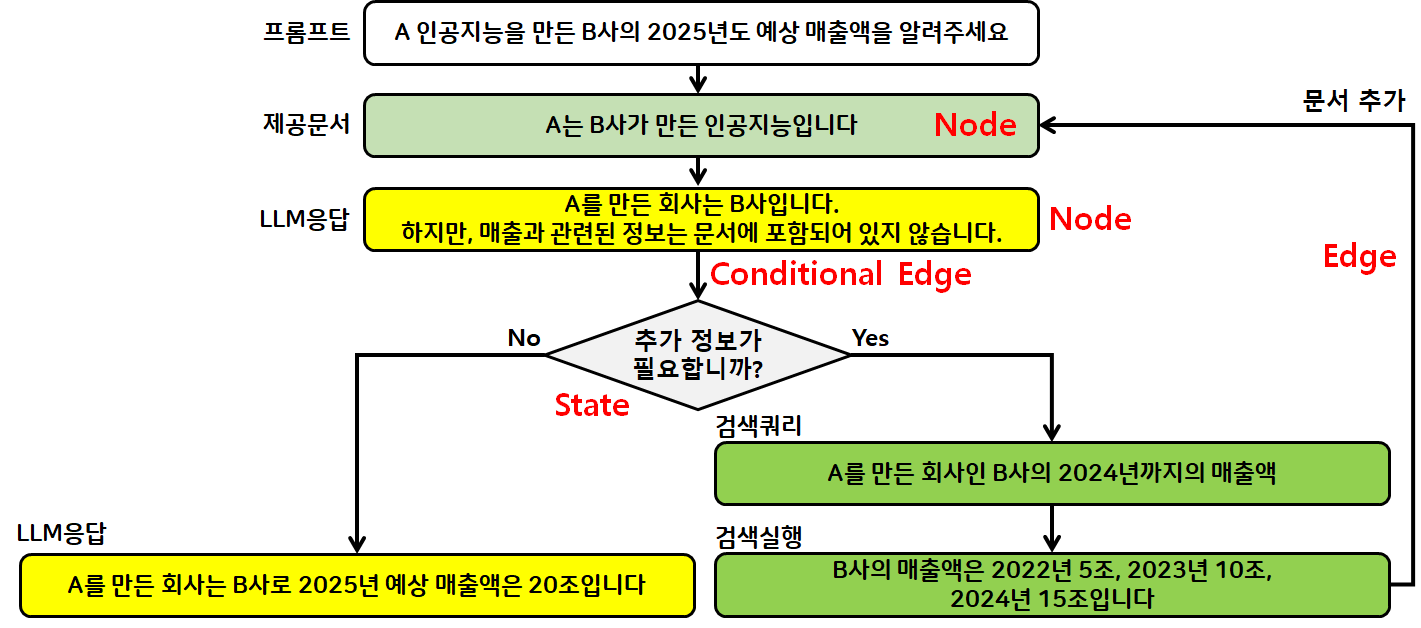
→ node: 작업, edge: 이동(다음으로 실행할 동작), state: 상태
단순 체인 연결이 아닌 hallucination을 제어할 수 있는 기술이 LangGraph라고 생각하면 됨
C. 6교시
1. TypedDict
- LangGraph에서 자주 등장하는 python 문법
- dictionary와의 차이점
- 타입 검사 제공 (경고 메시지를 출력)
- 타입 검사기를 활용할 경우에 한함
- 각 키에 대한 구체적인 타입을 지정
- 생성 시 정의한 구조에 따라 사용해야 함
- 추가적인 키는 타입 오류가 발생
- 타입 검사 제공 (경고 메시지를 출력)
- LangGraph에서 TypedDict를 사용하는 이유
- 엄격한 타입 검사를 통해 타입으로 인해 발생할 수 있는 잠재적인 버그 방지
- 딕셔너리 구조를 활용하기 때문에 명확하게 정의할 수 있어 코드 가독성 향상
dict vs TypedDict 비교
| 구분 | dict | TypedDict |
|---|---|---|
| 정의 방식 | 키와 값을 자유롭게 정의 | 키와 값의 타입을 미리 명시 |
| 타입 검사 | 없음 → 잘못된 타입 넣어도 실행됨 | 엄격한 타입 검사 제공 → 잘못된 타입 시 오류 발생 |
| 유연성 | 자유롭게 키 추가/삭제 가능 | 정의된 구조 안에서만 사용 가능 (추가 키 오류) |
| 가독성 | 구조 파악 어려움 | IDE 자동 완성, 타입 힌트 제공 → 코드 가독성↑ |
| 안정성 | 실수로 잘못된 값 넣어도 실행됨 (런타임 에러 가능) | 컴파일 단계에서 버그 예방 가능 |
| 교육/실습 | 빠르게 테스트할 때 적합 | 실무/협업 코드에 적합, 구조 명확 |
✅ 정리:
- dict → 빠르게 실습할 때 유용
- TypedDict → 구조를 명확히 정의하고, 버그 방지와 협업 시 안정성 확보에 유리
실습
- 타입 검사기 설치 필요:
!pip install -q mypy
%%writefile ./data/testDict.py
# dict 설계
dict1 = {
"name":"홍길동"
, "age":20
, "job":"강사"
}
# 값 변경
dict1["age"] = "35"
# 새로운 키 추가
dict1["region"] = "광주"Writing ./data/testDict.py%%writefile ./data/testTypedDict.py
class Person(TypedDict):
name: str
age: int
job: str
typed_dict1 : Person = {
"name":"홍길동"
, "age":20
, "job":"강사"
}
# 자료형 불일치하는 값 넣기
typed_dict1["age"] = "35"
# 새로운 키 정의
typed_dict1["region"] = "광주"Writing ./data/testTypedDict.py- 검사
!mypy ./data/testDict.pySuccess: no issues found in 1 source file!mypy ./data/testTypedDict.pydata/testTypedDict.py:1: error: Name "TypedDict" is not defined [name-defined]
data/testTypedDict.py:6: error: Incompatible types in assignment (expression has type "dict[str, object]", variable has type "Person") [assignment]
Found 2 errors in 1 file (checked 1 source file)2. Annotation
- Annotated
- 타입 힌트에 추가적인 정보('메타데이터')를 포함하는 기능
name: Annotated[str, "이름"]age: Annotated[int, "나이"]
- 타입 힌트에 추가적인 정보('메타데이터')를 포함하는 기능
- 주요 기능
- 추가 정보 제공
- LangGraph에서 Annotated를 사용하여 특별한 동작 정의
- 각 필드에 조건/설명/제약을 붙여서 검증 가능
- 라이브러리 / 클래스 설명
- pydantic: 데이터 유효성 검사 및 관리 라이브러리
- 주요 역할: 타입 힌트를 실제로 강제
- ValidationError: 유효성 검증에서 실패했을 때 발생하는 예외 클래스
- Field: 설정 도구
- 최소 길이, 최대 길이, 값의 범위 등을 지정
- pydantic: 데이터 유효성 검사 및 관리 라이브러리
from typing import Annotated
from pydantic import Field, BaseModel, ValidationError
# pydantic: 데이터 유효성 검사 및 관리 라이브러리 → 주요 역할: 타입 힌트를 실제로 강제
# ValidationError: 유효성 검증에서 실패했을 때 발생하는 예외 클래스
# Field: 설정 도구 → 최소 길이, 최대 길이, 값의 범위 등을 지정
class Member (BaseModel):
name: Annotated[str, Field(min_length=2, max_length=16, discription="이름")]
# gt(greater than)는 최솟값+1, lt(less than): 최댓값-1
age: Annotated[int, Field(gt=18, lt=65)] # 19-64
# greater than or equal (go; 이상), less than or equal (lo; 이하)Field 속성 정리표
- 문자열 전용
| 속성 | 설명 | 예시 |
|---|---|---|
min_length | 최소 길이 | Field(min_length=3) |
max_length | 최대 길이 | Field(max_length=20) |
pattern | 정규식 패턴 검사 | Field(pattern="^[a-z0-9_]+$") |
- 숫자 전용
| 속성 | 설명 | 예시 |
|---|---|---|
gt | greater than (초과, >) | Field(gt=0) |
ge | greater or equal (이상, >=) | Field(ge=1) |
lt | less than (미만, <) | Field(lt=100) |
le | less or equal (이하, <=) | Field(le=99) |
multiple_of | 특정 배수만 허용 | Field(multiple_of=5) |
- 공통속성
| 속성 | 설명 | 예시 |
|---|---|---|
default | 기본값 지정 | age: int = Field(20) |
default_factory | 함수로 기본값 생성 | created: datetime = Field(default_factory=datetime.utcnow) |
title | 필드 제목 (문서화용) | Field(..., title="사용자 이름") |
description | 필드 설명 | Field(..., description="나이 (19~64세)") |
example / examples | 예시 값 (문서화용) | Field(..., example="홍길동") |
alias | 입력 시 다른 이름 허용 | full_name: str = Field(..., alias="fullName") |
const=True | 값이 항상 동일해야 함 (상수) | Field("KR", const=True) |
deprecated=True | 더 이상 사용되지 않음 표시 | Field(..., deprecated=True) |
exclude=True | 직렬화(dict(), json())에서 제외 | Field(..., exclude=True) |
frozen=True | 값 변경 불가 (읽기 전용) | Field(..., frozen=True) |
LangGraph 사용 예시
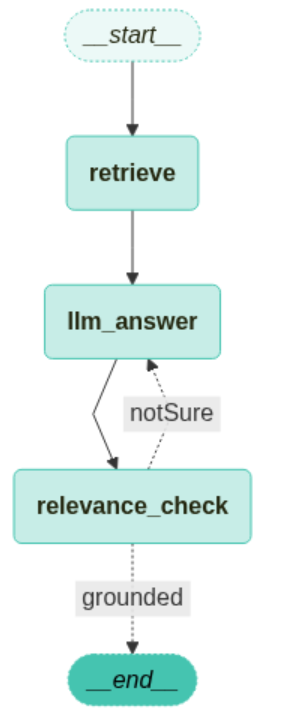
Ⅲ. CAREER UP
현직자 특강
네이버클라우드 로그
- cloud log analytics (CLA)
- 대시보드 제공 → 간편한 조회 가능
- 장애 대응책 확인
- 특정 장애 n회 이상 알람 제공 등의 서비스
- 전체 로그 검색 & 옵션
- 특징
- 로그 실시간 수집
- 정확하게는 '준실시간'
- 텍스트 형태로 생성되는 모든 로그 파일 수집
- 로그 검색
- 로그 데이터 저장 및 다운로드
- KISA, 금융감독원 → 로그 1년 이상 적재 의무화
- 로그 관리와 분석을 위한 다양한 기능 제공 & 추가 기능 제공 예정
- 키워드 기반 알람 전송
- 사용자 정의 대시보드
- 로그 실시간 수집
- 주요 기능 제공
- 로그 수집 에이전트 설치 필요함!
- 저장은 매월 1GB 무료 저장 공간 제공
- 60일 이후 자동 내보내기
- 60일 이후 로그 데이터는 자동 영구 삭제됨
- 가능한 로그 종류
- SYSLOG
- Apache 로그
- MySQL 설치형 서비스의 로그
- Error Log
- Slow Log를 True로 설정했을 시 저장 (default는 False임)
- Tomcat 로그 (Catalina Log)
- Window 서버 Event Log
- MSSQL 설치형 서비스의 Error Log
- 위의 모든 로그를 한 곳에 저장 & 하나의 대시보드에서 확인 → 간편함!
- 주의: 개인 정보가 포함된 로그(식별 가능한 개인 정보가 들어 있는 로그)의 경우 마스킹을 반드시 하고 클라우드에 올려야 함
- 로그 관리 방법
- 더 오랜 기간 데이터를 보관하고 싶을 경우 Object Storage로 내보내기
- 자동 내보내기 설정이 작년에 추가되었음!
- Cloud Activity Tracer
- 사용자의 계정 활동 기록 (접근 기록) 정보 제공
- 계정 활동의 가시성 / 손쉬운 로그 수집 및 조회 / 감사용 정보로 활용
- 주의: 별도로 끌 수 없음 (무조건 기록됨)
- 로그인 순간부터 모든 활동을 기록함
- 텍스트 기반 (대시보드 X)
- 90일까지 보관
- Tracer 기능
- 콘솔 작업 내용 모두 기록되고 있음
- 협업 시 보호 기능 활용
실습
- 서버 생성하기
- ACG 확인
어떤 로그를 기록해야 할까요?
1. /var/log/secure
- 로그인 시도
- sudo 명령어 사용 기록 → 루트 권한 관련 내용
- /var/log/messages
- Out Of Memory 등의 메시지
-
Cloud Log Analytics
- 키워드 기능, 알람 기능 사용하려면 프리미엄 선택해야 함!
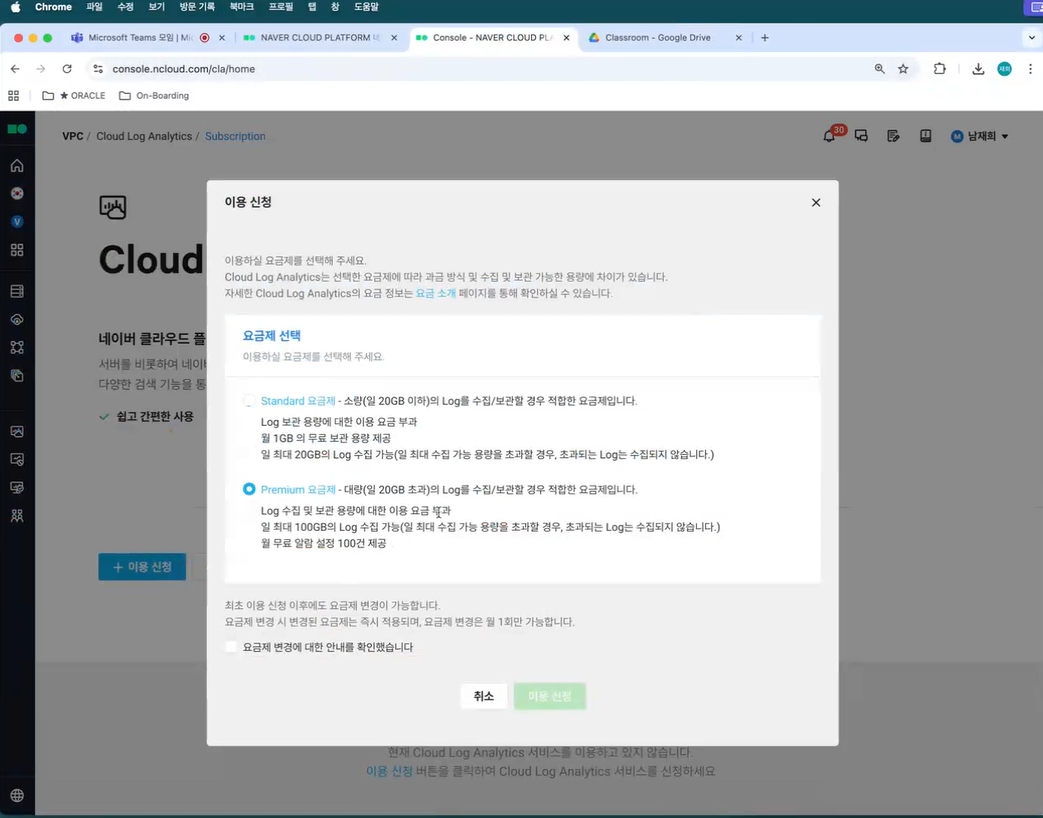
- 키워드 기능, 알람 기능 사용하려면 프리미엄 선택해야 함!
-
공인 IP가 필요함
-
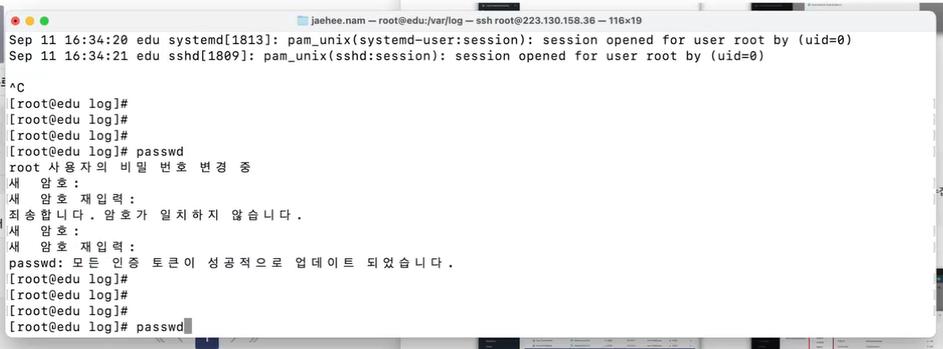
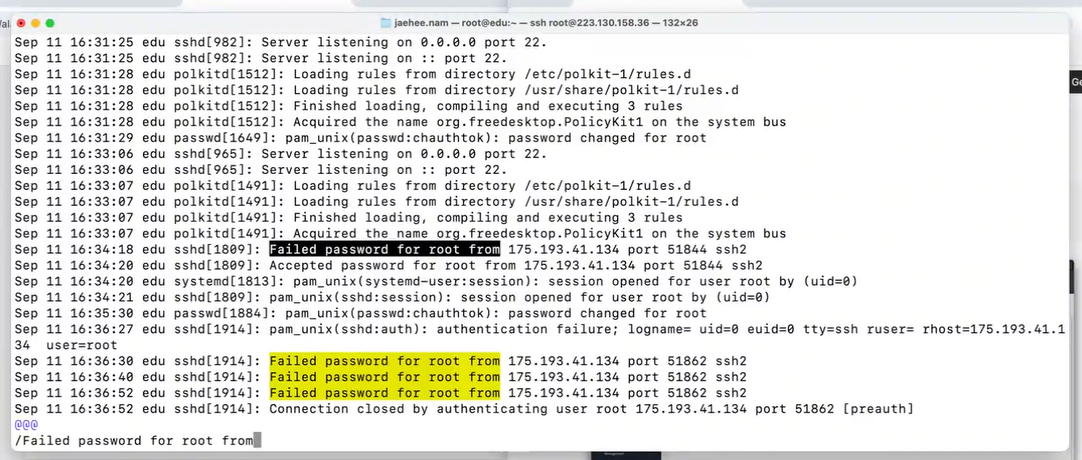
비밀번호 바꾸고 log 확인해보기
- 잘못된 비밀번호로 들어오려고 시도한 기록을 확인 가능
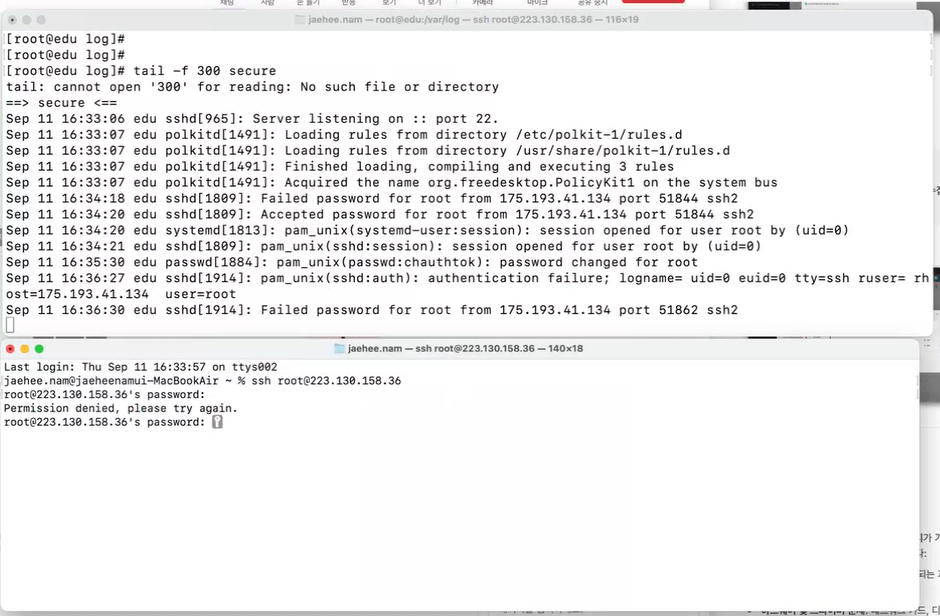
- 잘못된 비밀번호로 들어오려고 시도한 기록을 확인 가능
-
ScaleOut
- Agent 수동 설치
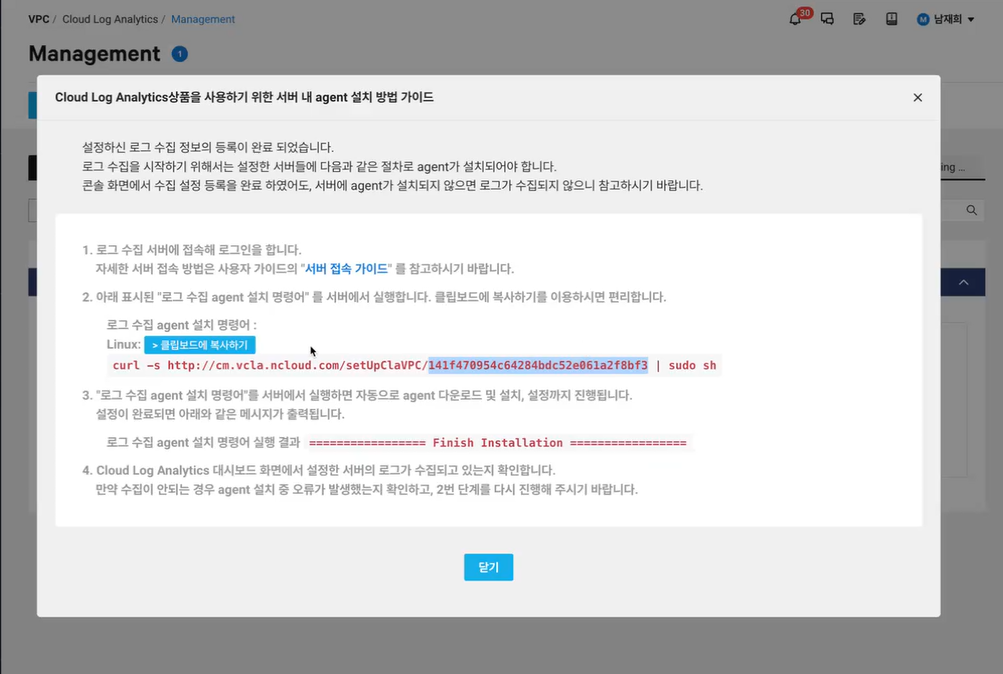
- 서버마다 다름
- 아래 부분이 현재는 수정되었다고 함
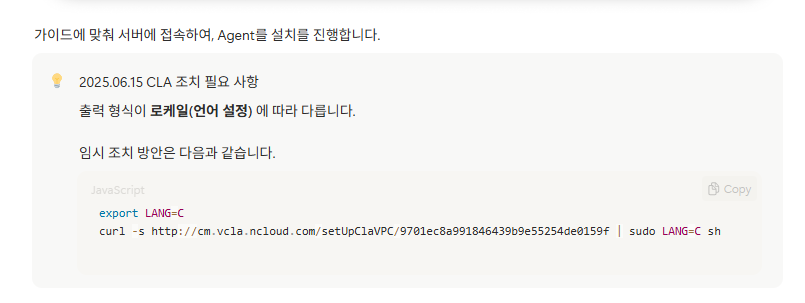
- Agent 수동 설치
-
특정 키워드가 들어 있는 로그 기록하기
- 통보 대상 관리
- 알람 발송
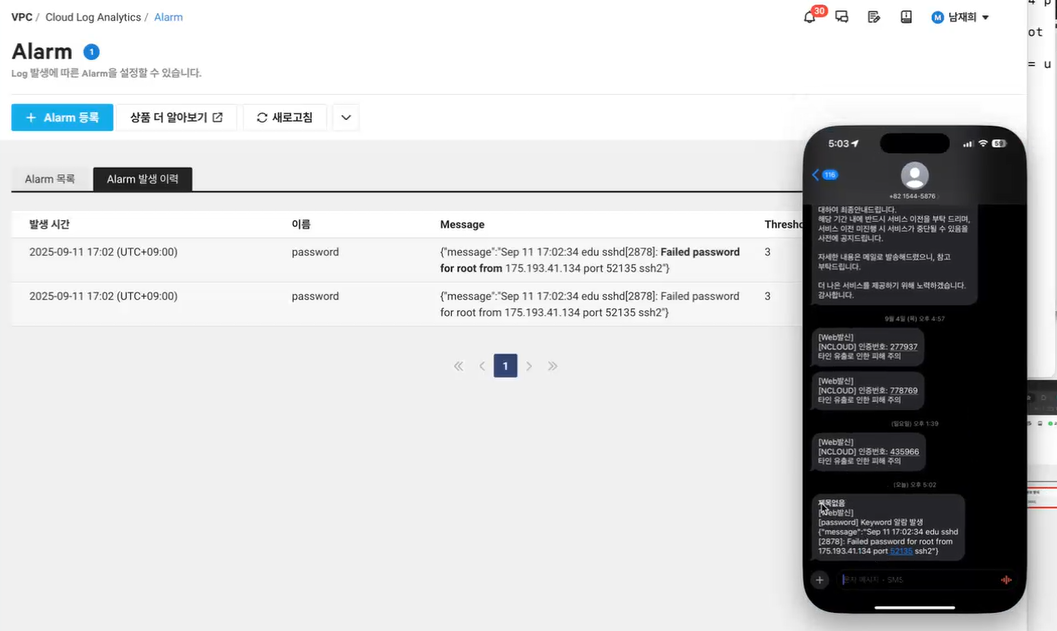
- 알람 발송
- apache 확인
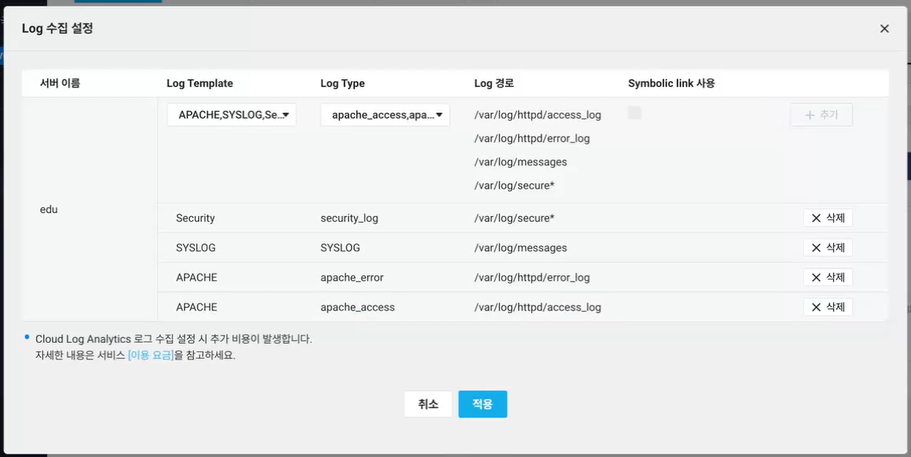
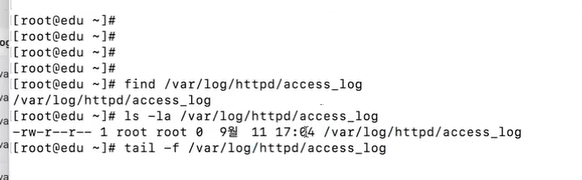
- 알림도 일정 횟수 이상 쌓이면 비용이 든다고 함 → 실습 끝나면 다 삭제하기
- 서버 정지 내역 기록 확인
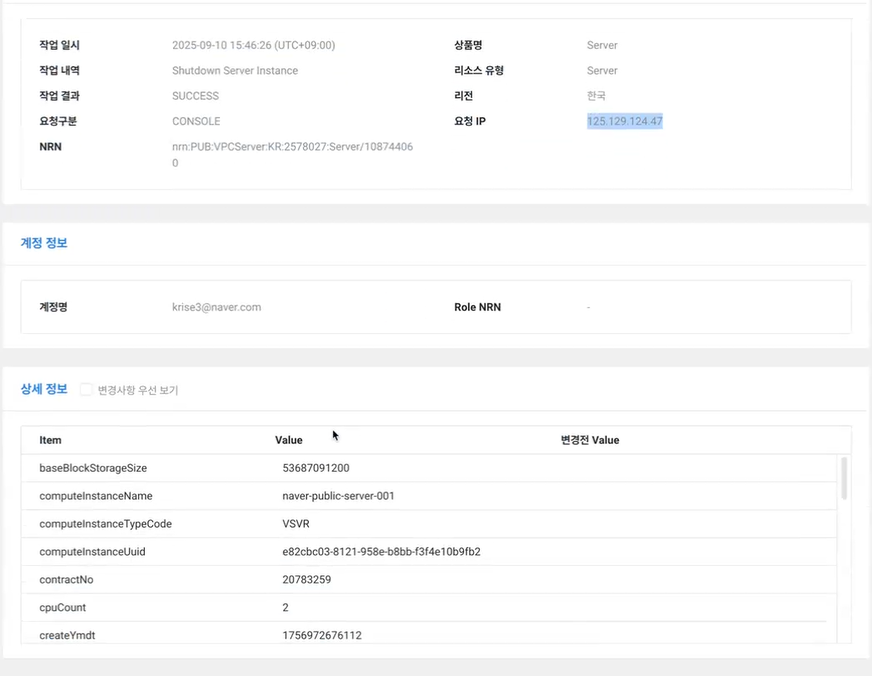
- 기록 가능한 모든 내역이 기록되어 있음
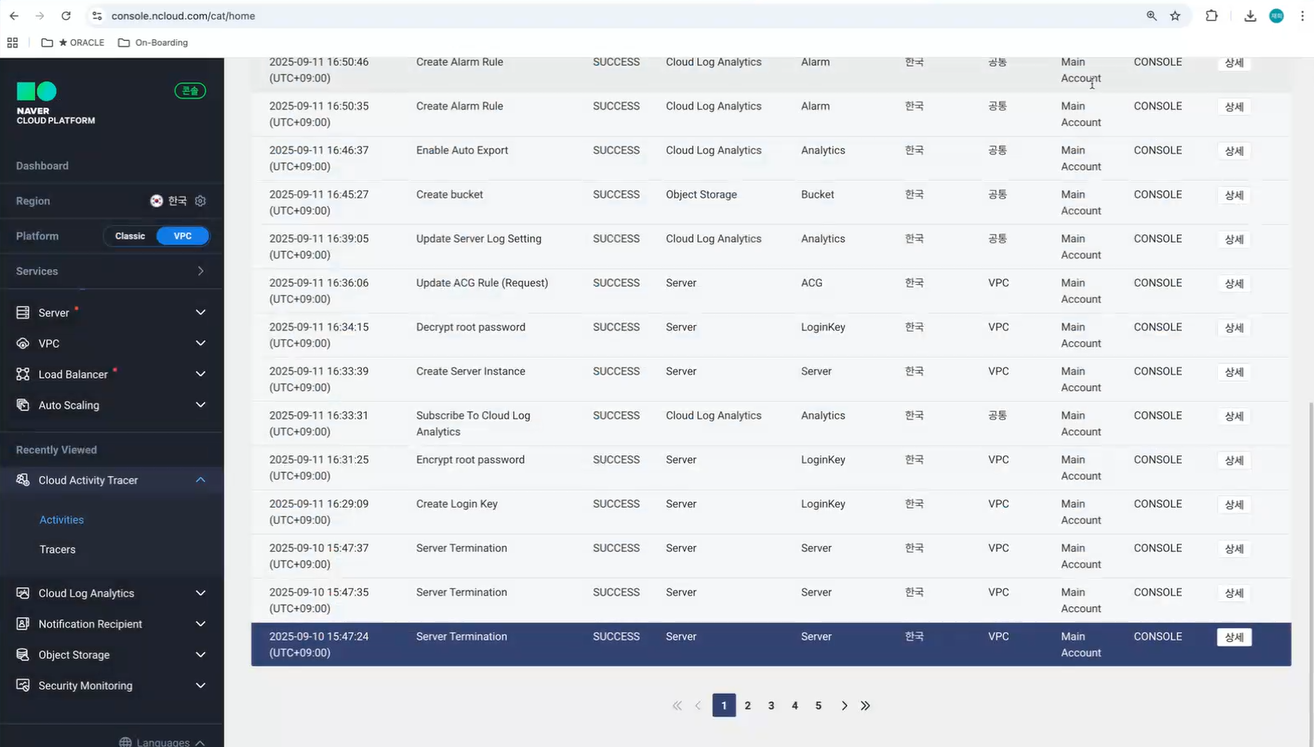
- 기록 가능한 모든 내역이 기록되어 있음
