목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. 실습
B. 2교시
1. DB에서 값 가져오기
C. 3교시
1. DB에서 값 가져오기 (cont.)
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
2. 유효성 검사
3. LangChain 구성 요소
B. 5교시
1. State
2. Node
3. Edge
C. 6교시
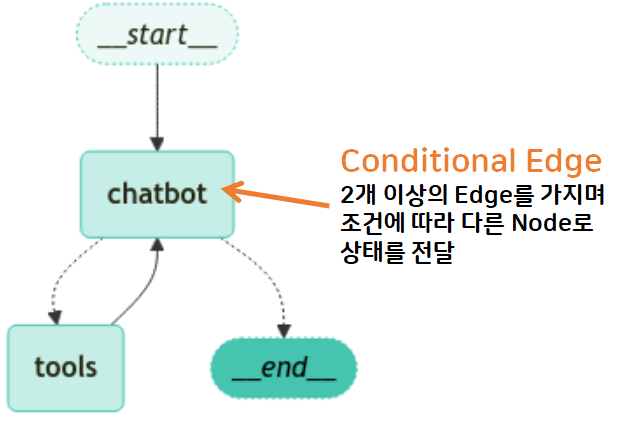
1. Conditional Edge
2. 시작점 설정 및 시각화
Ⅲ. CAREER UPⅠ. 오전 수업
A. 1교시
1. 지난 시간 복습
- EJS(Embeded JavaScript)
- HTML 안에 JS를 섞어서 동작하게 만듦
- embeded → 내포하고 있다, 포함하고 있다!
- 템플릿 엔진
- 개발자는 페이지를 하나만 만들고 → 틀(템플릿) 제공
- 서버가 값을 동적으로 생성
- 장점
- 문법이 쉬움 → 자바스크립트의 문법과 똑같다
- cf. 다양한 템플릿 엔진: Pug, Nunjucks, HandleBars 등 → 고유한 문법이 존재 → 문법을 새롭게 공부해야 함
- 문법이 쉬움 → 자바스크립트의 문법과 똑같다
- 특징
- HTML 기반으로 작성
- JS 문법을 그대로 사용
- 검색 엔진에 최적화(SEO)
- 사용처
- 로그인 후 메인 페이지
- 게시판 글 목록
- 검색 결과 등
- HTML 안에 JS를 섞어서 동작하게 만듦
- 동적 페이지: SSR(Server Side Rendering)과 CSR(Client Side Rendering)
- SSR 장점
- 빠른 초기 로딩 속도 → 클라이언트에서는 바로 출력이 가능
- SEO 최적화: 검색 엔진이 HTML 파일을 읽어들일 때 속도가 빠르다 → 내용을 채워서 넘기기 때문
→ 검색 엔진: HTML 파일을 기준으로 판단 (파일이이 채워져 있고 태그와 내용이 자주 바뀌면 검색 우선 순위를 높임)
- CSR 장점
- 동적 UI 생성에 효율적이다 → 특정 부분만 빠르고 쉽게 수정이 가능하다 (비동기 통신)
→ 서버가 비어있는 html과 태그를 생성하는 JS 코드를 클라이언트에게 전달해 클라이언트가 HTML 파일을 제작하게 만듦 (React, Angular, Vue 등) - 프론트엔트와 백엔드 역할 구분이 명확
- 동적 UI 생성에 효율적이다 → 특정 부분만 빠르고 쉽게 수정이 가능하다 (비동기 통신)
- CSR 예
- React, Angular, Vue, …
- 하이브리드 렌더링(SSR+CSR)
- Next.js, Svelte
- SSR 장점
- 실습
- 서버 구조 차이는 없음
- 기본 서버 세팅은 똑같음
- 차이점:
app.set()세팅 (for EJS)
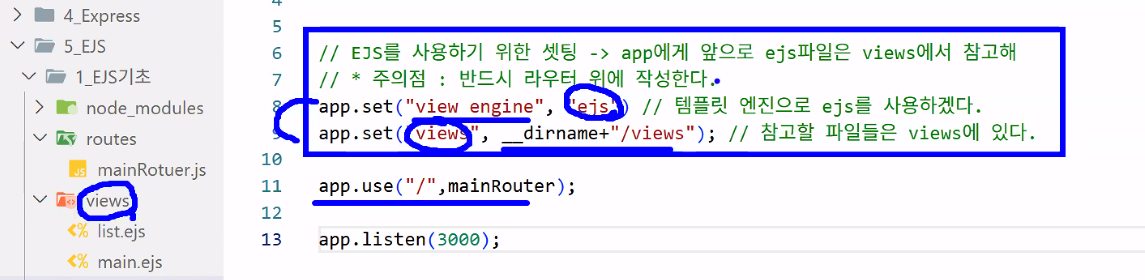
- mainRouter.js
- 템플릿 엔진을 통해서 페이지를 제작할 때는
.render()사용 →
서버쪽에서 파일을 만들겠다는 의미 - render()의 장점: 데이터 전송 가능 → 객체 형태로 원하는 데이터를 보낼 수 있음
- 템플릿 엔진을 통해서 페이지를 제작할 때는
- main.ejs
- 기본 뼈대는 html
<% %>: JS의 문법 작성이 가능한 공간 → 조건문, 반복문<%= %>: 넘겨준 값을 사용하는 공간
- 서버 구조 차이는 없음
2. 실습
오늘은 라우터 하나로 전부 처리해봅시다!
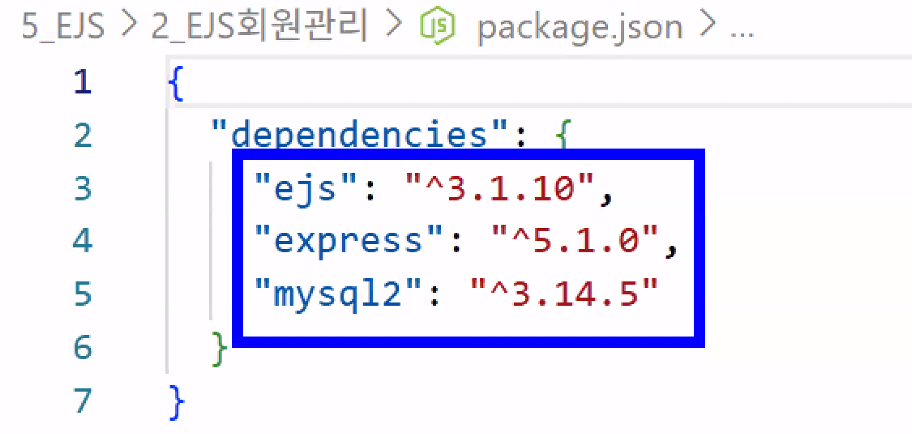
- 2_EJS회원관리 폴더 만들고 터미널에서 npm i express, npm i ejs, npm i mysql2 실행
- 폴더&파일 만들기: config, routes, views, app.js
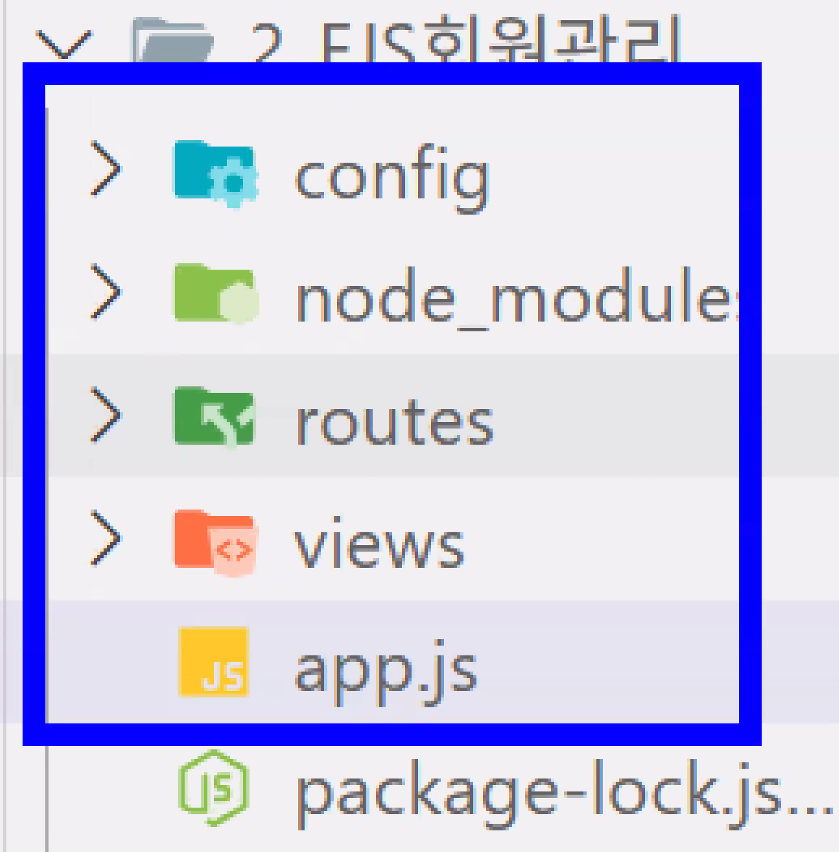
- public은 CSS, img 만들면 그때 추가
- 해야할 일 정리
1) 사용자가 로그인을 진행
2) 회원 정보가 있다면 → DB에 있는 닉네임을 메인에 출력
3) 로그아웃 → 실제 로그아웃: "세션(session)" 개념 필요* nick 님 환영합니다! * 로그아웃/회원목록 리스트 - app.js
- 기본 설정
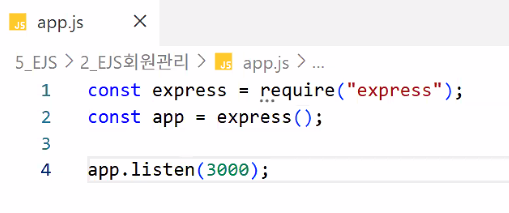
- POST 통신 들을 준비하기: post 데이터 처리
app.use(express.urlencoded({extended:true}));
- EJS 세팅
app.set("view engine","ejs");app.set("views",__dirname+"/views");
- 기본 설정
react를 쓰면 view 폴더 대신 react 폴더 → build
- mainRouter.js
- 기본 설정
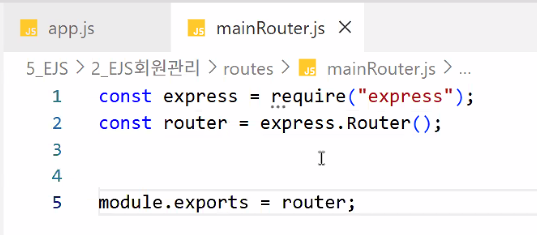
- 경로 설정: main
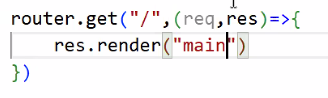
- 기본 설정
- app.js
- mainRouter 연결
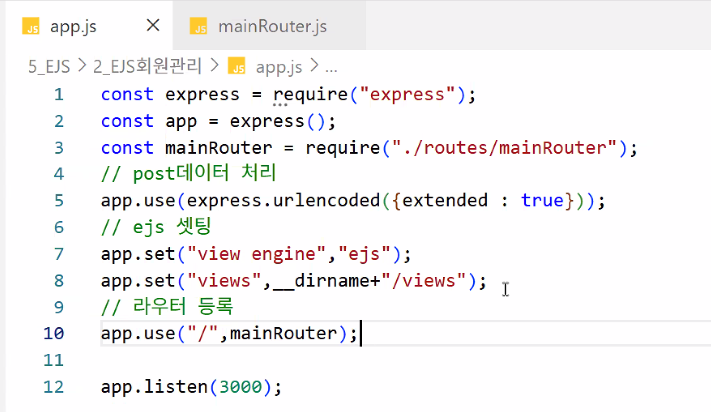
- 주의: post 데이터 처리 이후 Router 등록해야 함! (항상 Router는 맨 마지막에 적기)
- mainRouter 연결
- views 폴더에 main.ejs 만들기
- 로그인 페이지
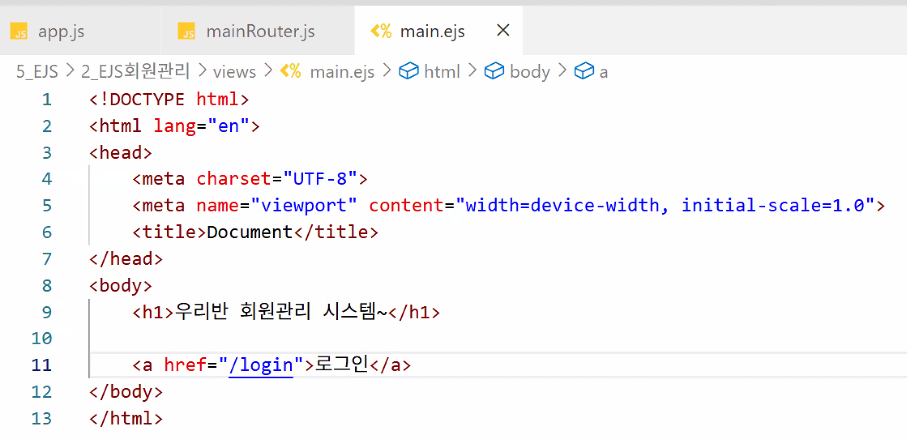
- 로그인 페이지
- mainRouter.js: 로그인 처리하기
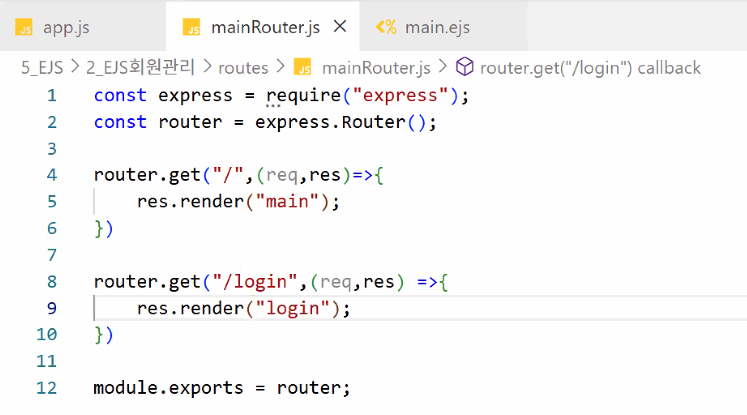
- views 폴더에 login.ejs 만들기
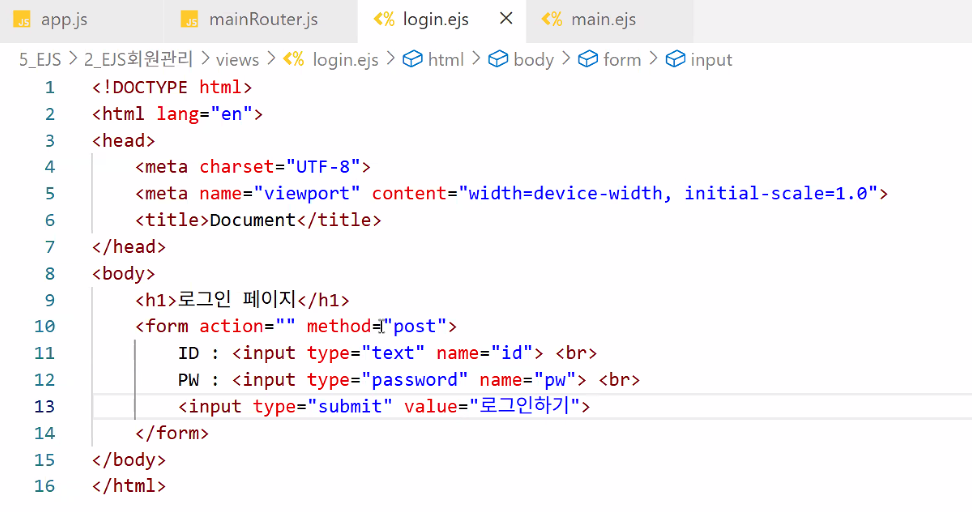
B. 2교시
1. DB와 연결하기
- login.ejs에 있는 form 태그의 action 경로 결정
action="http://localhost:3000/login"- 주의: get과 post는 처리 공간이 다름
- get은 페이지 링크 받아온 것
- post는 로그인 정보 받아온 것
- 통신 방식이 다르면 같은 경로라도 다르게 처리함
- mainRouter.js에 /login 경로의 POST 방식 추가
- 경로가 같아도 통신 형식이 다르기 때문에 별도로 처리됨 → 다른 로직 처리 가능!
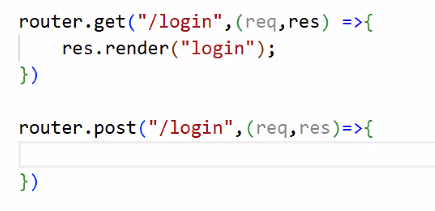
- 프로세스 따라가기 ★★★
- 보낸 데이터 받기
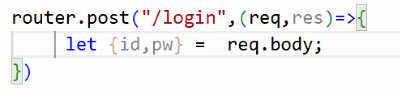
- DB에 해당 id, pw 있는지 확인 → DB와 연결 필요 → config 폴더에 DB 설정 만들기
- 보낸 데이터 받기
- 경로가 같아도 통신 형식이 다르기 때문에 별도로 처리됨 → 다른 로직 처리 가능!
- config 폴더에 db.js 생성
- 연결 정보 생성
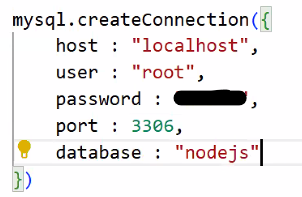
- DB와 연결:
conn.connect(); - exports:
module.exports = conn;
- 연결 정보 생성
- mainRouter.js로 돌아가서 설정 계속 진행
- 프로세스 따라가기
3. 연결 가져오기:const conn = require("../config/db");
4. 연결 확인하기
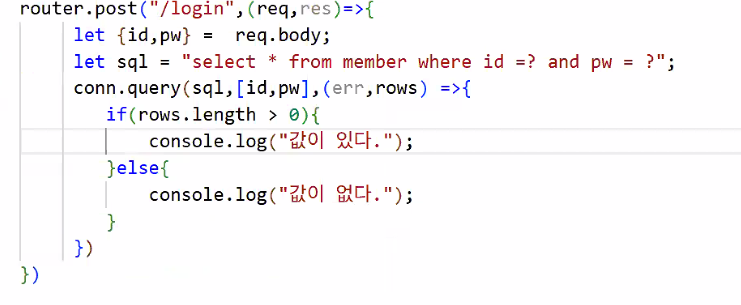
5. 조건문 작성
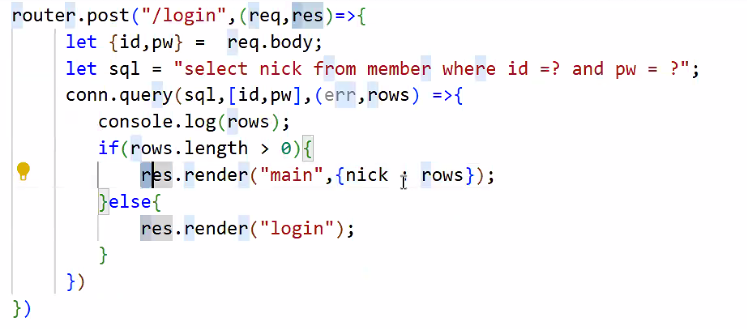
- 프로세스 따라가기
조건문: 삼항연산자로 쓸 수도 있음!
router.post("/login",(req,res)=>{ let {id,pw}=req.body; let sql="SELECT nick FROM member WHERE id=? AND pw=?" conn.query(sql, [id, pw], (err, rows) => { console.log(rows); rows.length > 0 ? res.render("main", {nick: rows}) : res.render("login"); }); });→ 더 깔끔
C. 3교시
1. DB와 연결하기(cont.)
- main.ejs 수정
- DB에서 가지고 온 데이터를 main.ejs에 넣기
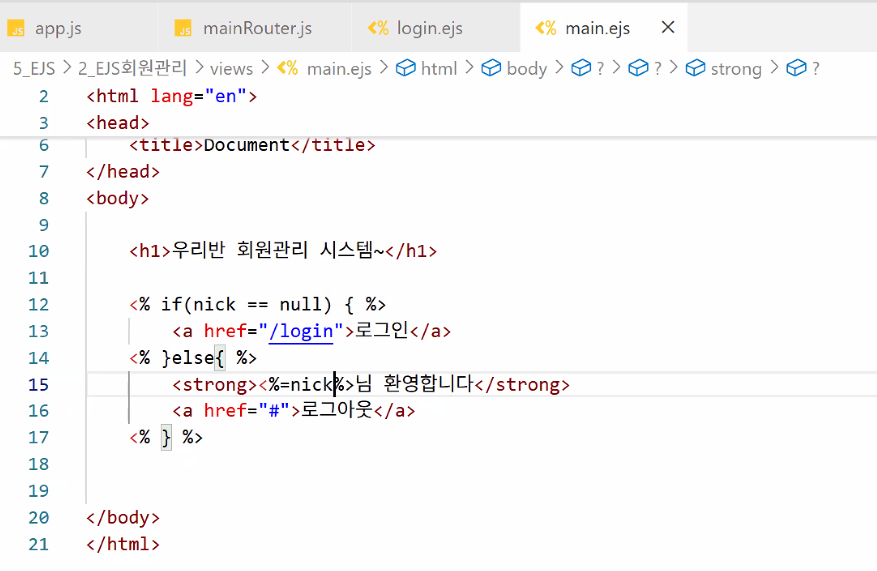
- DB에서 가지고 온 데이터를 main.ejs에 넣기
여기서도 삼항연산자 쓸 수 있는데 주의해야 할 점이 있음!
<%= nick == null ? '<a href="/login">로그인</a>' : `<strong>${nick} 님 환영합니다.</strong><a href="#">로그아웃</a>` %>HTML 이스케이프:
위처럼<%= ... %>로 출력하면 문자열이 이스케이프(escape)되어<a>태그가 "그대로" HTML로 인식되지 않고, 브라우저에는 문자열로 보일 수 있습니다.
해결 방법:
HTML 태그가 그대로 동작하려면<%- ... %>(unescaped output)를 사용하세요.<%- nick == null ? '<a href="/login">로그인</a>' : `<strong>${nick} 님 환영합니다.</strong><a href="#">로그아웃</a>` %>
- mainRouter.js 수정
- nick 변수 만들고 초깃값으로 null 넣기
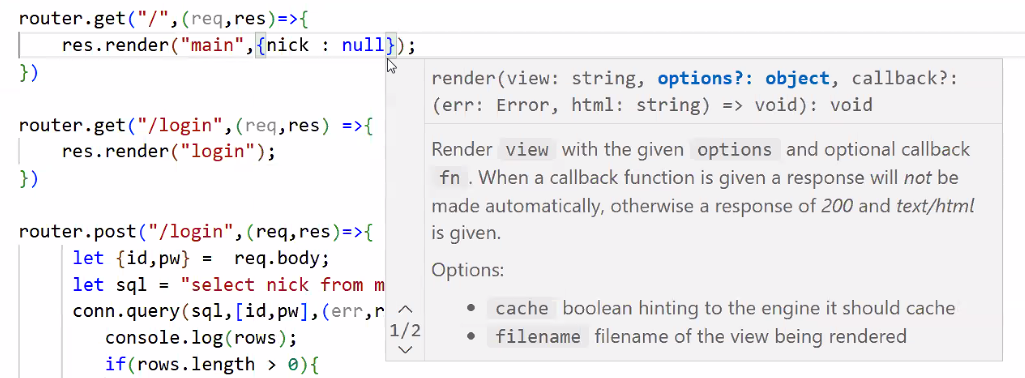
- nick 변수 만들고 초깃값으로 null 넣기
- main.ejs 수정: 닉네임 꺼내기
- 1번 방법
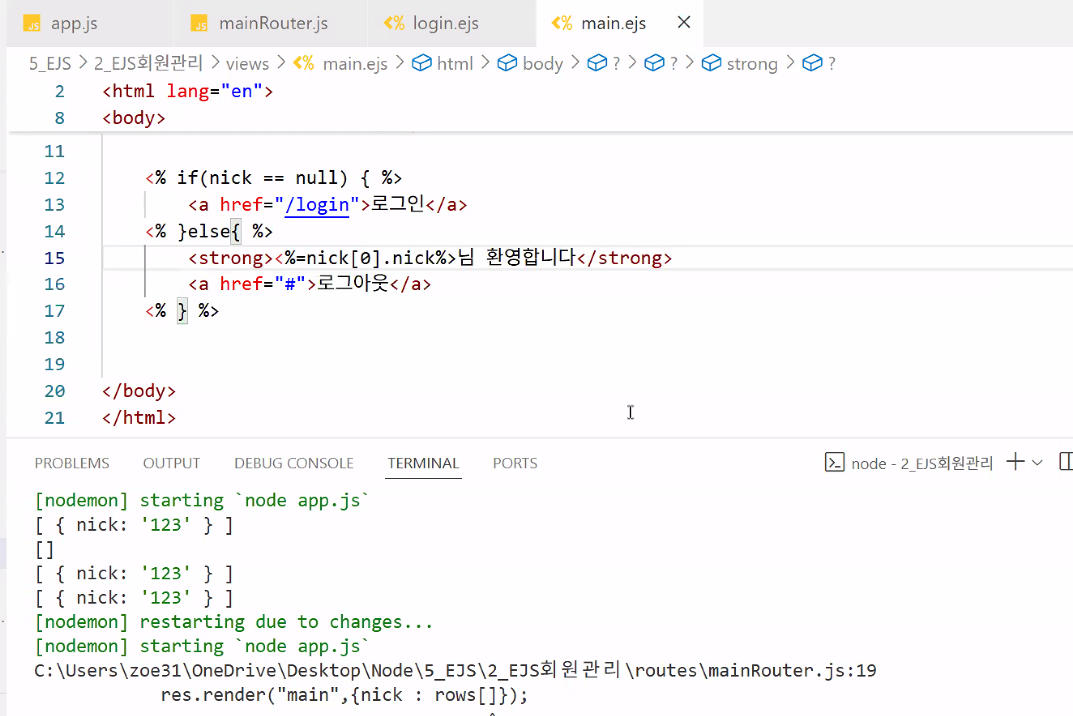
- 결과는 나오지만 직관성이 떨어짐 → nick에서 nick을 가져온다는 게 어떤 의미인지 제 3자 입장에서는 파악하기 어려움
- 2번 방법
- 키 값 이름부터 바꾸기
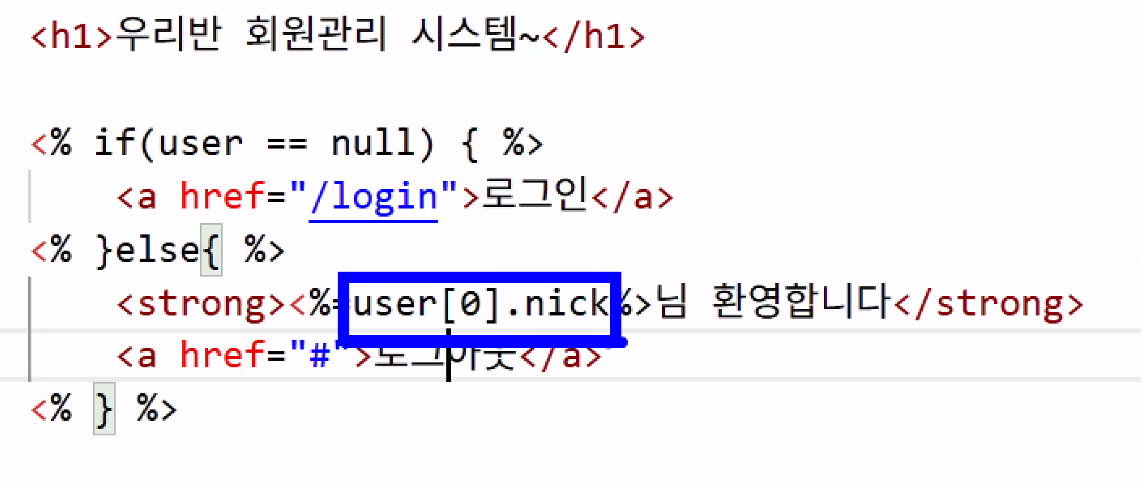
- 조금 낫긴 하지만 여전히 직관성 문제가 있음: 어차피 로그인한 유저는 1명뿐인데 이렇게 적으면 user 객체에서 여러 명의 유저를 가지고 올 수 있는 것처럼 보임 → 의미론적으로 봤을 때 잘못된 코드 작성이라 볼 수 있음(다른 개발자가 봤을 때 이해하기가 힘듦) → 서버로 돌아가서 본질적인 부분부터 다시 고치자!
- 키 값 이름부터 바꾸기
- 1번 방법
- mainRouter.js 수정
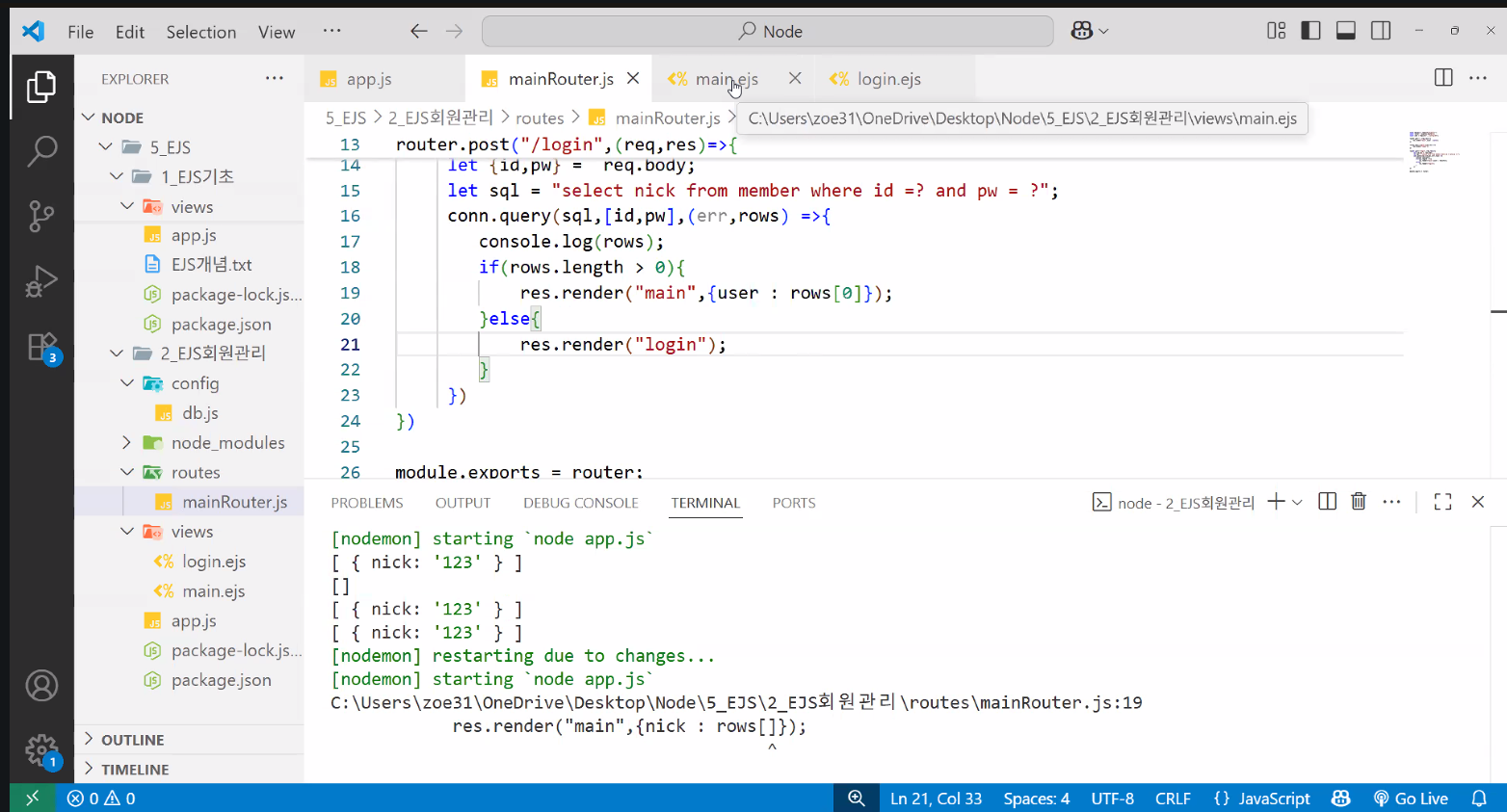
- 배열 자체의 인덱스만 넘기면(
{rows[0]}) 오류가 나지만 객체 구조로 넘기는 경우에는 rows가 '값'이기 때문에 인덱싱이 가능함({user:rows[0]})
- 배열 자체의 인덱스만 넘기면(
- main.ejs 수정
- 사실 한 번 더 줄여야 함! → 지금 형태는 user에 nick말고도 다른 키가 있는 것처럼 보이기 때문 (이렇게 적으면 user에 다른 값들도 있다고 느껴지는데 사실 우리는 nick만 가지고 있으니까 이것도 좋은 형태가 아님)
- mainRouter.js 수정: 최종
- main.ejs 수정: 최종
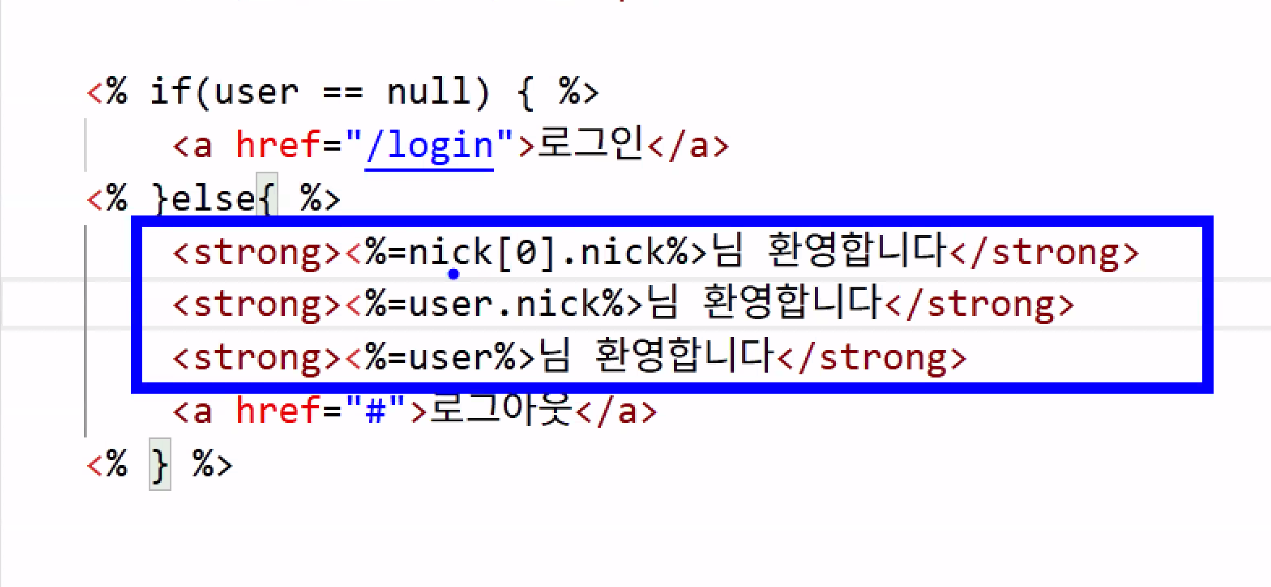
- 보낼 때 정확하게 보내면 꺼내는 게 훨씬 간결하고 직관적임!
의미론적 차이 이해하기
: 변수 이름 수정 & 인덱스 제거 → 점점 볼륨을 줄여 나가는 과정
※ 최대한 간결하게 적어야 함! (가독성)
→ EJS는 원래도 가독성 문제가 있어서 최대한 간결하게 작성해 주는 게 좋음
- 핵심
- 값을 넘길 때 정확한 값을 넘기자
- 출력하는 EJS에서 가장 간단하게 출력하는 게 가독성에 좋음
- 값을 가지고 페이지를 제작할 때는 반드시 초기값을 설정해 주어야 함 → 초기값 설정이 매우 중요
- 설정 없으면 undefined 출력 → undefined은 페이지 생성이 불가능
- 값을 넘길 때 정확한 값을 넘기자
문제점
- 메인 페이지 갈 때마가 로그인 초기화됨
- 페이지 만들 때만 값을 사용: 특정 페이지를 만드는 순간만 데이터 전달 → 지역변수
- 전역변수로 해결?
- 해결 방안: session → 공유 데이터 공간
- 로그아웃 구현은 session이 있어야 가능
- 세션 활용 예시: google 로그인 기록

- 세션 활용 예시 2: 팝업창 일주일간 보지 않기
- 로그아웃 구현은 session이 있어야 가능
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
- LangChain
- LangSmith
- Agent
- LLM이 단순 답변을 넘어서 스스로 판단 → 도구 실행 → 결과 활용하는 구조
- 지능형 시스템
- 기본적으로 보이지 않는 루프
- 워크플로우가 개발자 눈에 보이지 않음 → 시각화 보조 필요 → LangGraph
- LangGraph 탄생 배경
- RAG(Retrieval-Augmented Generation) 이라는 강력한 기능을 갖게 된 우리는 한 번쯤 다음의 갈등을 마주하게 됨:
- LLM이 생성한 답변이 Hallucination인 것 같음
- RAG를 적용하여 받은 답변이 문서에는 없는데 LLM의 “사전 지식”을 가지고 답변한 것 같음
- 문서 검색에서 원하는 내용이 없을 경우 → “인터넷” 혹은 “논문”에서 부족한 정보를 검색하여 지식을 보강하고 싶음
- RAG(Retrieval-Augmented Generation) 이라는 강력한 기능을 갖게 된 우리는 한 번쯤 다음의 갈등을 마주하게 됨:
- 기존 RAG 계발 단계에서 마주하는 고민 사례
- RAG를 수행했을 때 문서 내 질문에 대한 답변이 존재하지 않는 경우가 존재
- 그럼 부족한 정보를 Web에서 검색하여 문서에 추가하는 로직을 추가해 보기로 함
- 하지만 검색결과에 잘못된 정보가 포함되어 있었다면? 혹은 검색 결과에 없다면?
- 이러한 잘못된 검색결과가 결국 Hallucination으로 이어진다면?
- 검색이 제대로 나올때까지 반복해볼까?
- 계속 제대로 된 결과가 안 나온다면 토큰 사용량 폭증
- Hallucination을 방지하는 LLM을 추가해볼까?
- 코드가 점점 길어지고 복잡해짐 & LLM의 일관되지 않은 답변이 마치 나비효과로 이어져 답변 품질 저하로 이어짐
- RAG를 수행했을 때 문서 내 질문에 대한 답변이 존재하지 않는 경우가 존재
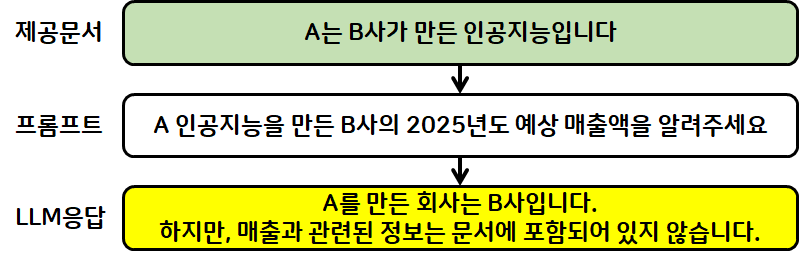
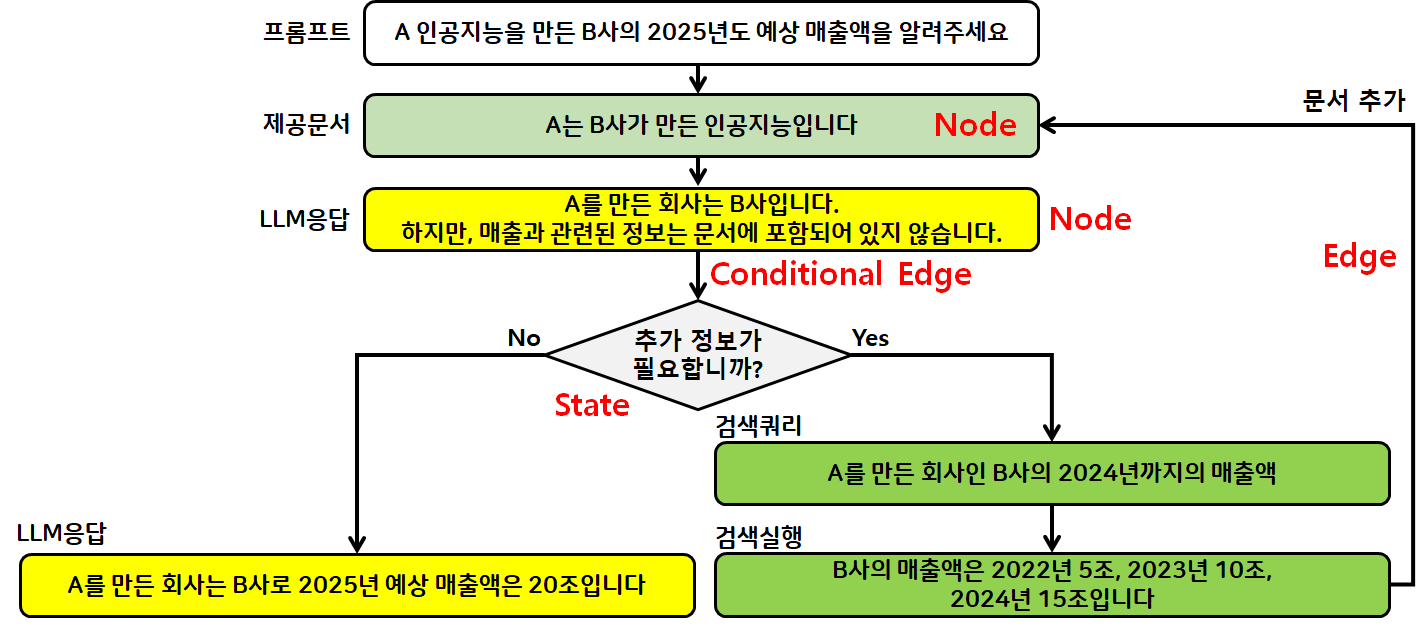
예시:
"'크라임씬 제로'를 스트리망하는 회사의 2024년도 매출액을 알려줘"
↓
문서: '크라임씬 제로'는 넷플릭스에서 스트리밍합니다.
↓
1번 LLM
답변: '크라임씬 제로'를 스트리밍하는 회사는 넷플릭스입니다.
하지만 매출액 정보는 문서에 나와있지 않습니다.
↓
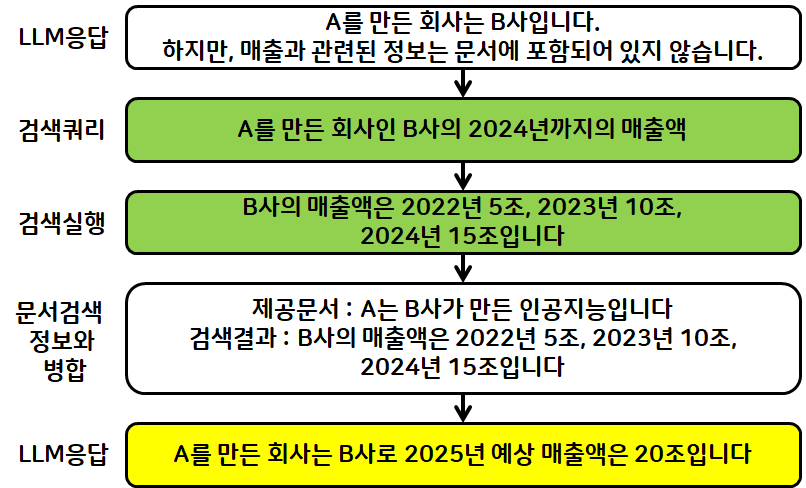
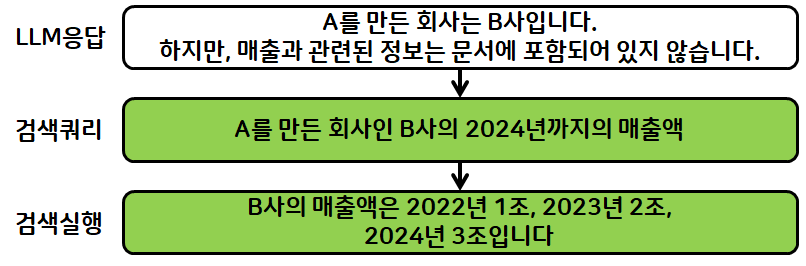
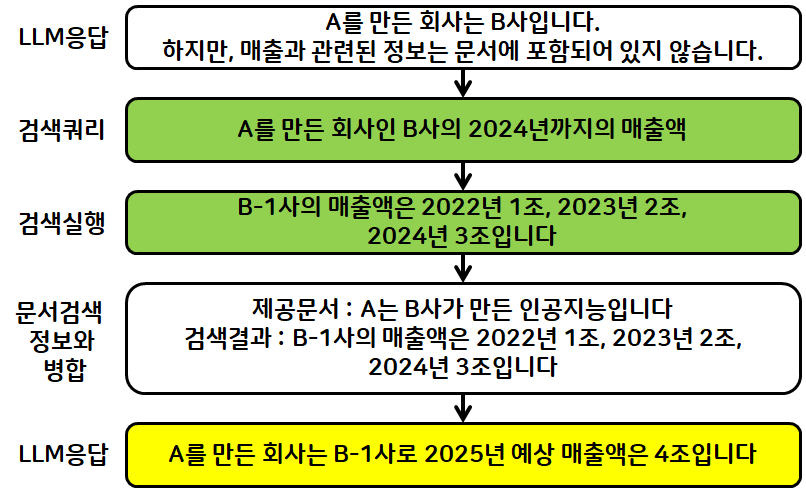
2번 LLM
검색 쿼리 작성
"'크라임씬 제로'를 스트리망하는 회사인 넷플릭스의 2024년도 매출액"
↓
검색 실행
'크라임씬 제로'를 만든 스튜디오슬램의 2024년 매출액은 116억 7천만원입니다.
↓
1번 LLM
답변: '크라임씬 제로'를 스트리밍하는 회사는 넷플릭스입니다.
하지만 매출액 정보는 문서에 나와있지 않습니다.
↓
2번 LLM
검색 쿼리 작성
"'크라임씬 제로'를 스트리망하는 회사인 넷플릭스의 2024년도 매출액"
↓
…
- Conventional RAG 문제점
- 사전에 정의해야 하는 부분이 많음
- 데이터 소싱(PDF, DB, Table 등) 자원
- Fixed Size Chunk(고정된 크기의 데이터 분할)
- Query 입력
- 검색 방법
- 신뢰하기 어려운 LLM 혹은 Agent
- 고정된 프롬프트 형식
- LLM의 답변 결과에 대한 문서와의 관련성/신뢰성
- RAG 파이프라인이 단방향 구조(Document Loader(데이터로드) > Answer(답변))이기 때문에 발생하는 문제도 있음
- 모든 단계를 한 번에 다 잘해야 함
- 이전 단계로 되돌아가기 어려움
- 이전 과정의 결과물을 수정하기 어려움
- 사전에 정의해야 하는 부분이 많음
- LangGraph 제안: Agentic RAG vs Conventional(Traditional) RAG
- 각 세부과정을 노드(Node) 라고 정의
- 이전 노드 > 다음 노드: 엣지(Edge) 연결
- 조건부 엣지를 통해 분기 처리
- RAG 파이프라인을 보다 유연하게 설계
- RAG 파이프라인을 보다 유연하게 설계
- 평가자 & Query Transform 추가
- 기존 RAG

- 로직 추가
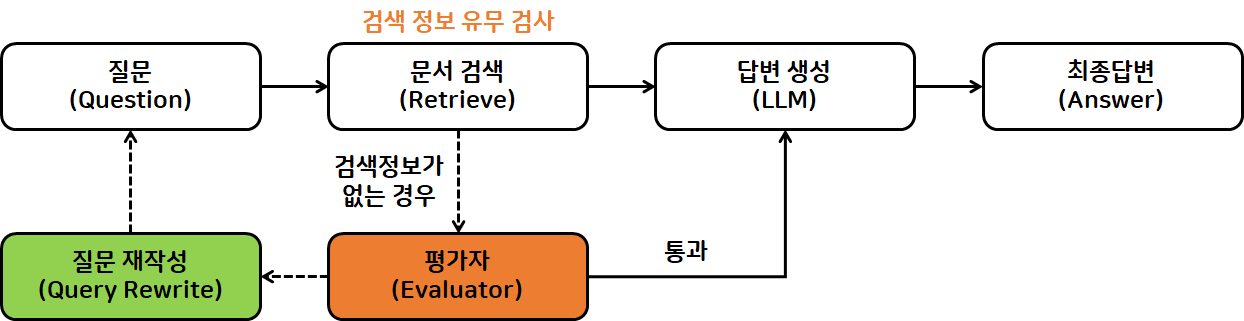
- 기존 RAG
- 추가 검색기를 통하여 문맥(context) 보강
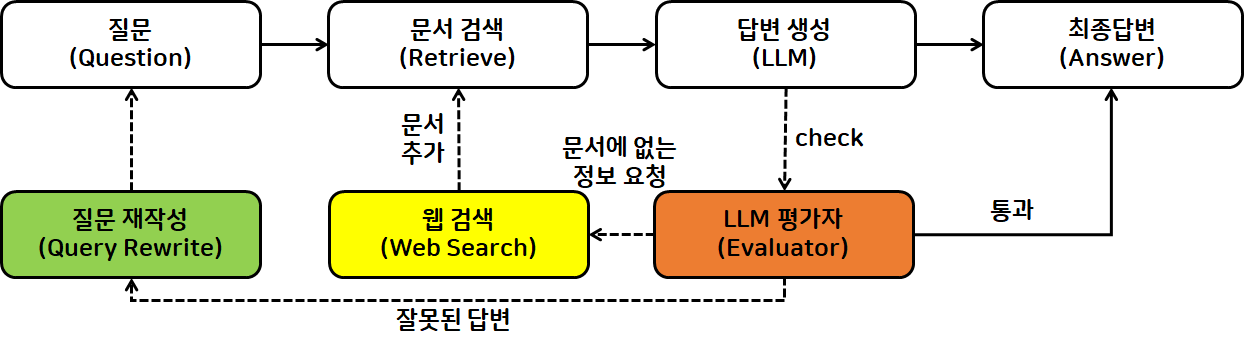
- 외부 검색 기능(웹 검색)을 활성화 → 검색해 주는 API를 추가(e.g. Tavily)
- 문서-답변 간 관련성 여부를 판단하는 평가자2 를 추가하여 검증
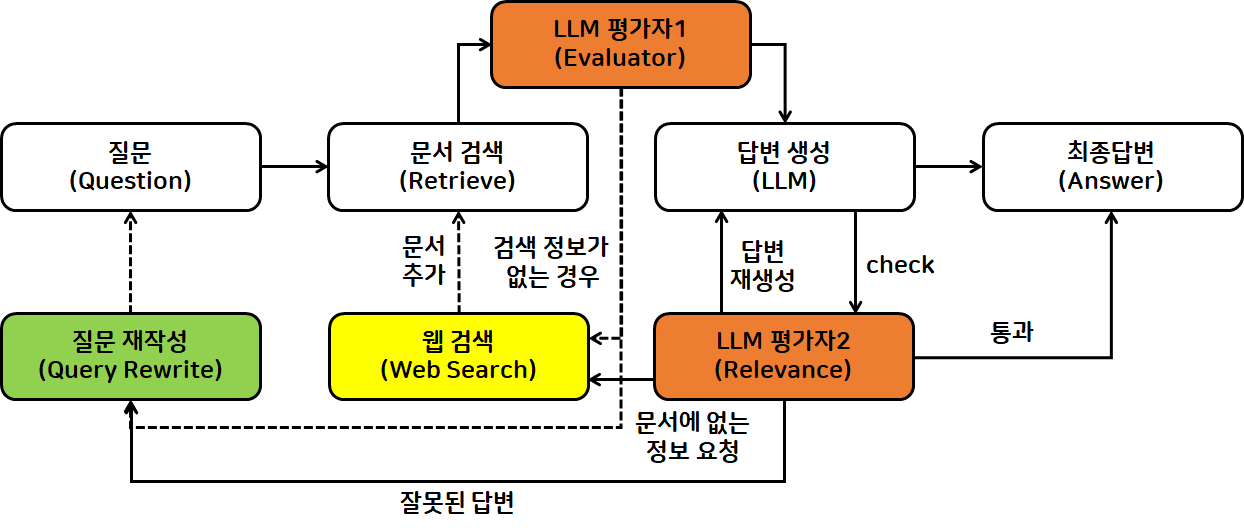
- 구현 예시
- LangGraph
- Node(노드), Edge(엣지), State(상태관리)를 통해 LLM 을 활용한 워크플로우에 순환(Cycle) 연산 기능을 추가하여 손쉽게 흐름을 제어
- 단순 체인 연결이 아닌 hallucination을 제어할 수 있는 기술이 LangGraph
- Node(노드): 어떤 작업(task)을 수행할지 정의
- Edge(엣지): 다음으로 실행할 동작 정의 → '이동'이라 생각하면 쉬움
- State(상태): 현재의 상태 값을 저장 및 전달하는 데 활용
- Node(노드), Edge(엣지), State(상태관리)를 통해 LLM 을 활용한 워크플로우에 순환(Cycle) 연산 기능을 추가하여 손쉽게 흐름을 제어
- RAG 파이프라인의 세부 단계별 흐름제어가 가능
- Conditional Edge: 조건부 (if, elif, else 와 같은..) 흐름 제어 → 조건에 따라 분기 처리
- Human-in-the-loop: 필요시 중간 개입하여 다음 단계를 결정
- Checkpointer: 과거 실행 과정에 대한 “수정” & “리플레이” 기능
- LangGraph 에 자주 등장하는 Python 문법
- TypedDict: 일반 파이썬 dict 에 타입힌팅을 추가한 개념 → 정적 타입 검사를 제공 (즉, 코드 작성 시 IDE나 타입 체커가 오류를 미리 잡아낼 수 있음)
- 타입 검사기: mypy
- Annotated
- 타입 힌트에 추가적인 정보('메타데이터')를 포함하는 기능
- 주요 기능: 추가 정보 제공 / LangGraph에서 Annotated를 사용하여 특별한 동작 정의 / 각 필드에 조건·설명·제약을 붙여서 검증 가능
- TypedDict: 일반 파이썬 dict 에 타입힌팅을 추가한 개념 → 정적 타입 검사를 제공 (즉, 코드 작성 시 IDE나 타입 체커가 오류를 미리 잡아낼 수 있음)
2. 유효성 검사
- 유효한 데이터 생성 확인
- 예외 처리 구문: try - exept 문
- try 실행문에서 오류가 발생했을 시 except 문 실행
- 오류 미발생 시 except 문 건너뜀
- 예외 처리 구문: try - exept 문
# 유효한 데이터 생성
try:
valid_member = Member(
name = "홍길동"
, age = 20
)
print("유효한 고객 데이터", valid_member)
except ValidationError as e:
print("유효성 검사 오류:")
for error in e.errors():
print(f"{error['loc'][0]}: {error['msg']}")유효한 고객 데이터 name='홍길동' age=20errors()안에 있는 것- loc(위치), msg(내용)
errors(): 에러 dict의 리스트를 반환
# 유효하지 않은 데이터 생성
try:
valid_member = Member(
name = "톰" # 너무 짧은 이름
, age = 15 # 범위를 벗어난 나이
)
print("유효한 고객 데이터", valid_member)
except ValidationError as e:
print("유효성 검사 오류:")
for error in e.errors():
print(f"{error['loc'][0]}: {error['msg']}")유효성 검사 오류:
name: String should have at least 2 characters
age: Input should be greater than 18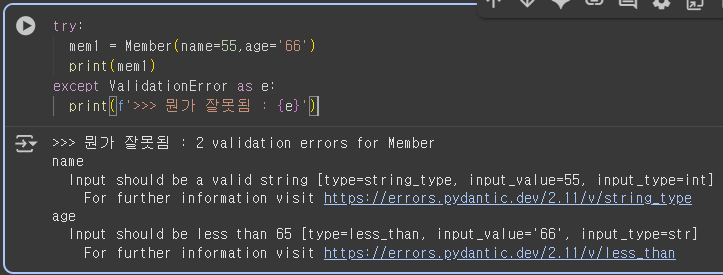
LangGraph 내에서 유효성 검사 사용 위치
- 그래프 입구
- 외부 입력(사용자의 질문, 파일 등)을 처음 받는 곳에서 검증
- 예: 질문의 데이터 타입, 길이, 필수 포함 필드 확인
- 외부 입력(사용자의 질문, 파일 등)을 처음 받는 곳에서 검증
- 그래프 출구 노드
- 그래프가 최종적으로 내보내는 결과를 감싸주면 원하는 형태의 결과값을 출력할 수 있음
3. LangGraph 구성 요소
- State(배달부)
- Node(기능)
- Edge(경로)
여러 개의 노드를 연결하여 흐름을 구성해 나갑니다.
1. State(상태)

- 특징
- 노드와 노드 간 정보를 전달할 때 'State(상태) 객체'에 담아 전달함
- Typed Dict를 사용
- 새로운 노드에 값 덮어쓰기 방식을 활용

- 모든 값을 채우지 않아도 상관 없음 → "느슨하다"고 표현함
- Key별로도 느슨하게 정보를 전달할 수 있음
- 노드와 노드 간 정보를 전달할 때 'State(상태) 객체'에 담아 전달함
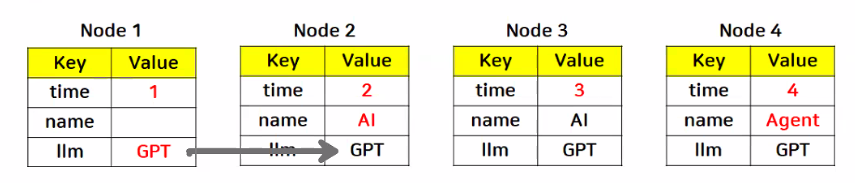
- 노드별 상태값 변화
- 각 노드에서 새롭게 업데이트 되는 값은 기존 Key값을 덮어쓰는 방식
- 추가로 값을 넣지 않으면 이전 노드의 상태를 그대로 전달하여 조회 가능
from typing import TypedDict
# 정보를 전달할 때 타입을 지정해서 전달
class GraphState(TypedDict):
time: int # 시간
name: str # 사용자 이름
llm: str # 모델 이름
# 키별로 느슨하게 정보를 전달하는 방법
from typing import NotRequired
class GraphState(TypedDict):
time: NotRequired[int] # '삼'. '3', '세 번째' 등의 결과를 받을 수 있게 됨
name: str
llm: strB. 5교시
1. State
RAG 사례
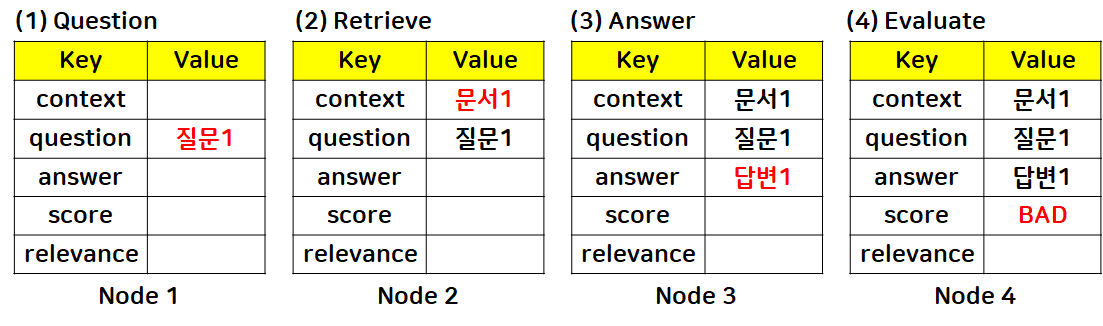
→ 첫 번째 행동이 끝났을 때((4) Evaluate: score BAD까지 완료된 후) 선택할 수 있는 행동들이 다양함
1. 질문 재작성: Question node로 edge 연결
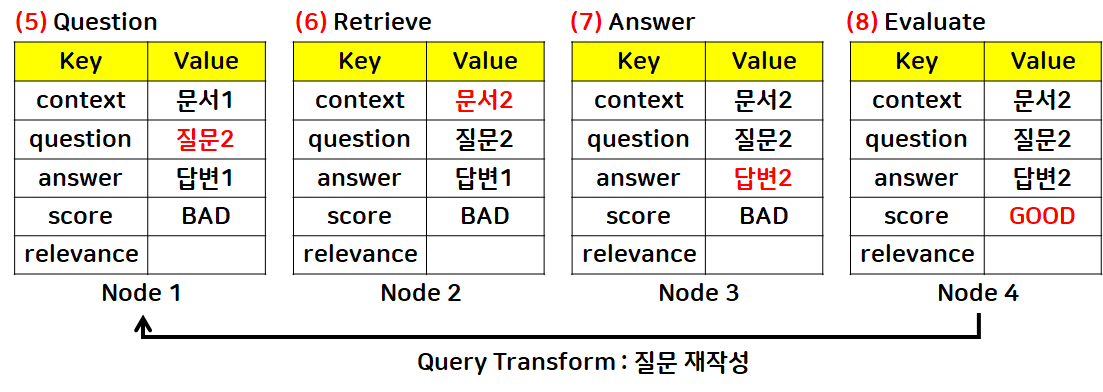
- 노드1: 질문 재작성 요청
- 질문 재작성 요청 받은 후, 질문2로 갱신
- 문서, 답변도 갱신되어 score가 “Good”이 됨
- 노드4 → 노드1로 Query Transform 흐름을 연결해 hallucination 해소
- 문제 검색 재요청: Retrieve node로 edge 연결
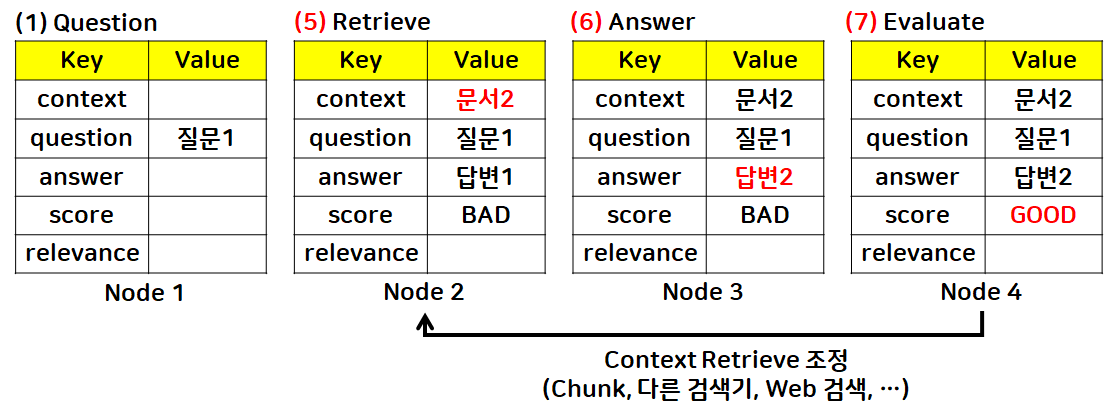
- 노드2: 문서 검색 재요청
- 다른 검색기를 사용해 문서 검색 다시 진행
- 답변 재생성 요청: Answer node로 edge 연결
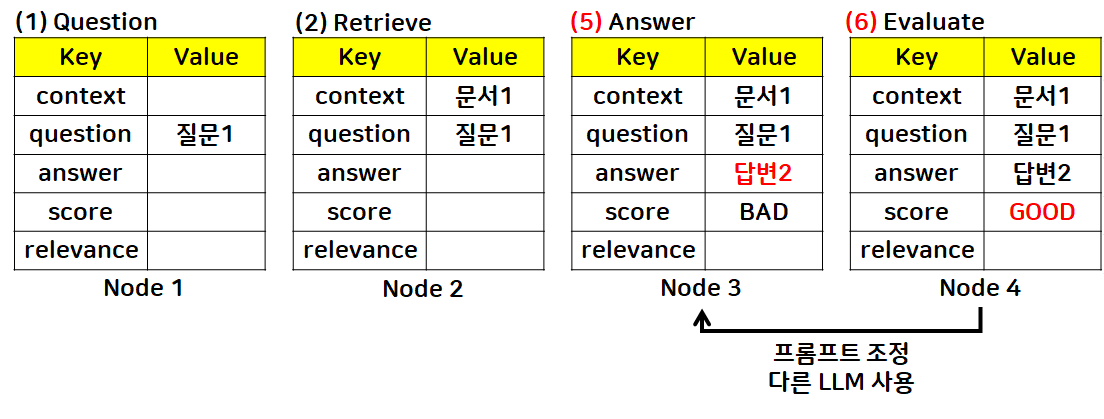
- 노드3: 답변 재생성 요청
- 다른 LLM 모델 사용해서 답변 다시 생성
- Edge만 연결하면 알아서 동작
# LangGraph에서 사용할 상태(State) 설계도
class GraphState2(TypedDict):
context:str
question:str
answer:str
score:str
relevance:strrelevance?
해당 문맥(context)과 질문(question) 간의 "관련성"을 평가한 결과 값을 의미합니다. 즉, context와 question이 얼마나 잘 맞는지, context가 실제로 question에 대한 답을 포함하는지 판단한 점수(문자열)로 저장relevance의 의미
- relevance는 주로 retrieval, RAG, 또는 QA 워크플로우에서 "검색된 context가 입력 질문에 충분히 연관되어 있는가?"를 평가하는 기능입니다.- 보통 OpenAI 등의 LLM이나 별도 평가 함수(GroundednessChecker 등)를 사용하여 context와 question의 연관성을 평가해서 "yes"/"no" 또는 점수(예: 0~1)로 기록합니다.
- relevance 값은 이후 플로우 제어(예: 관련성이 낮으면 context 재검색, 높으면 답변 생성 등)에 활용됩니다.
예시
- 예를 들어, context가 "AI 관련 논문 요약"이고 question이 "AI가 사회에 미치는 영향은?"이라면 relevance가 높을 수 있습니다.
- relevance가 너무 낮으면, 답변 생성 대신 context를 재검색하거나 워크플로우를 다른 방향으로 유도할 수 있습니다.
참고 코드 패턴
class GraphState(TypedDict): context: str question: str answer: str relevance: str
- relevance는 각 노드에서 평가된 관련성 정보를 담으며, 다음 플로우 제어에 활용됩니다.
즉, relevance는 context와 question의 "연관성 평가 결과"이며, LangChain/Graph 워크플로우에서 답변 신뢰도 제어에 중요한 역할을 담당합니다.
2. Node
- Node(노드)는 함수로 정의 → 함수는 입력, 실행문, 출력(return)을 가짐
- 입력: State 객체를 받음
- 실행문: 내부 실행할 코드
- 출력: 반환 return → 대부분 State 객체임
# retrieve node 정의
def retrieve_Node(state: GraphState2) -> GraphState2:
# Question에 대한 검색 문서를 retriever로 수행
# retrieve_docs = 검색기이름.invoke(state["question"])
retrieve_docs = "문서1"
# 원래는 주석 처리한 부분처럼 써야 하지만 흐름 파악을 위해 간단하게 작성
# 검색한 문서를 context 키에 저장하여 반환
return GraphState2(context=retrieve_docs)
# llm_answer node 정의
def llm_answer_Node(state: GraphState2) -> GraphState2:
state['answer'] = '답변1'
# '답변1'이라는 예시 데이터를 받았다고 가정
return state
# relevance_check node 정의
def relevance_check_Node(state: GraphState2) -> GraphState2:
state['relevance'] = 'grounded'
# '관련이 있음'이라는 예시 데이터를 받았다고 가정
return state- Graph에 노드를 추가해야 사용할 수 있음
add_node("노드이름",노드함수명)
from langgraph.graph import StateGraph
# 그래프 생성
graph_builder = StateGraph(GraphState2)
# 노드 추가
graph_builder.add_node("retrieve", retrieve_Node)
graph_builder.add_node("answer", llm_answer_Node)
graph_builder.add_node("relevance", relevance_check_Node)<langgraph.graph.state.StateGraph at 0x794560487740>- 입력은 그래프 실행 초기에 직접 State를 넣어줄 예정
3. Edge
- 노드와 노드 간 연결
add_edge("시작노드명","다음노드명")
graph_builder.add_edge("retrieve", "answer")
graph_builder.add_edge("answer", "relevance")<langgraph.graph.state.StateGraph at 0x794560487740>C. 6교시
- LangGraph 구성 요소: State, Node, Edge → 각각 배달부, 기능, 경로라고 생각하면 됨
- State(상태)
- 노드와 노드 간의 정보를 전달할 때 상태를 객체에 담아서 전달 → 타입을 지정해주는 TypedDict에 모아서 함께 전달
- 새로운 Node의 값을 덮어쓰기 방식을 사용
- 값이 들어오지 않으면 이전 상태를 그대로 유지
- Node
- Edge
- 조건 설정 가능 → 조건부 엣지
- State(상태)
1. Conditional Edge(조건부 엣지)
- 조건에 따라 분기 처리
- 노드에 조건부 엣지를 추가하여 상황에 따른 경로를 설정
- 노드는 '기능' → 함수로 각각의 기능을 정의
add_conditional_edges(source, path, path_map)- source: 조건 검사를 시작할 노드
- path: 현재 상태를 평가하고 다음 노드를 결정하는 함수
- 예:
lambda state: state["relevance"]
- 예:
- path_map: 조건부 엣지에 연결된 다음 노드 목록
- 조건
- grounded → '관련이 있다'라는 뜻 → 종료
- NotGounded → '관련이 없다'라는 뜻 → 재검색 실행 ('retrieve' node로 이동)
- NotSure → '모호하다'라는 뜻 → 다시 답변을 생성('answer' node로 이동)
from langgraph.graph import END
# 관련성이 있는지 확인하는 함수
def is_relevance(state: GraphState2):
return state["relevance"]
# retrieve 노드에 조건부 엣지를 추가
graph_builder.add_conditional_edges(
source="relevance" # 조건을 시작할 노드 이름
, path=is_relevance # 람다 함수로 처리해도 됨: lambda state: state["relevance"]
, path_map={
"grounded": END # 관련성이 있으면 END → 끝내세요~
, "NotGounded": "retrieve" # 관련성이 없으면 → 재검색하세요~
, "NotSure": "answer" # 결과가 모호하면 → 다시 답변 생성하세요~
}
)<langgraph.graph.state.StateGraph at 0x794560487740>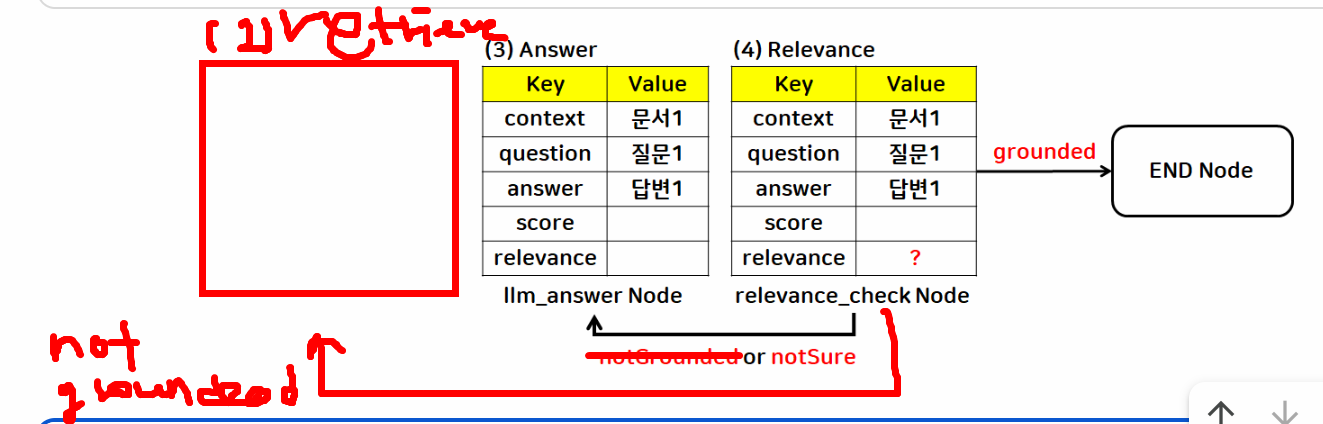
2. 시작점 설정 및 시각화
set_entry_point("노드명"): 해당 노드를 graph의 시작점으로 설정- 흐름만 보려고 하는 거니까 질문은 이미 받았다고 치고 시작하기~
# 시작점 설정
# 질문 후 검색 결과를 받았다고 가정 하에 진행
graph_builder.set_entry_point("retrieve")
from langchain_teddynote.graphs import visualize_graph
# 그래프 컴파일
graph = graph_builder.compile()
# 시각화
visualize_graph(graph)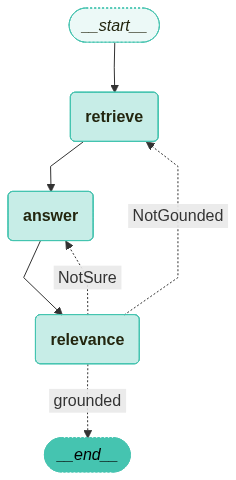
- 실선 화살표: edge
- 점선 화살표: conditional edge (조건부 엣지)
다음주에는 실제로 전체 다 연결해볼 것
복습 꼭 하고 공부해서 오기!
추가: 아래 위키독스 꼭 읽어보기
LangGraph 가이드북 - 에이전트 RAG with 랭그래프
CH17 LangGraph ★★★
Ⅲ. CAREER UP
복습 & 시험 공부
