오전
1교시: CSS
지난 시간 복습
- CSS(Cascading Style Sheets)
- CSS를 활용해 영역을 어떻게 배치하느냐가 가장 핵심
- '배치를 어떻게 할 수 있는지'가 매우 중요한 영역임
- cascading → 스타일이 누적됨 & 선택자가 여러 개 중첩이 되면서 스타일의 우선 순위가 발생하기 때문에 이런 이름이 붙음
- 과거에는 HTML이 정보표현, 디자인 모두 담당 → 유지보수가 어려움, 재사용성 낮음, 스타일 세분화 불가 → 현재 HTML은 뼈대만 담당하고 디자인은 CSS가 담당함
- CSS는 디테일한 부분까지 고려해야 함
- table 선 긋기(border): html은 한 번에 다 그림, css는 table 바깥, 안 모두 따로따로 지정할 수 있음
- 문법은 단 하나:
선택자 {선언(속성)} - 선택자의 우선순위를 파악하는 게 중요
- 우선순위를 무너뜨리는 방법도 있긴 하지만 권장하지 않음
- CSS를 활용해 영역을 어떻게 배치하느냐가 가장 핵심
- 선택자
- 어떤 요소에게 스타일을 부여할 건지를 명시하는 방법
- 요소: tag와 content의 조합
- 우선 순위가 존재
- 범위가 좁을수록 우선순위가 올라감
- 중복되는 속성에서만 우선 순위가 발생
- 어떤 요소에게 스타일을 부여할 건지를 명시하는 방법
지난 시간에 배운 선택자 종류
- 전체 선택자(*)
- 태그 선택자
위 두 가지는 기본적인 속성들에 많이 활용
→ 범위가 너무 넓기 때문에 중요하지 않은 스타일 정도에 활용이 됨(예: font-size, font-style 등)
디테일하게 그룹화를 시킨다거나 특정 내용을 반복시킬 때는 활용되지 않음
- 클래스 선택자(.)
- CSS에서 가장 많이 사용하는 선택자
- 특정 태그들의 "그룹"을 만들 때 활용하는 선택자
- 중복이 가능하다 → 여러 태그들에게 그룹을 시킬 수 있다
- 한 요소가 여러 개의 클래스를 가질 수 있음(많이 가지면 4개까지 가진다고 함 → 복수 개 사용하는 걸 잘 쓰지는 않음)
- 아이디 선택자(#)
- 특정 요소만 가지는 고유한 값의 선택자
- 오직 하나의 태그에게만 이름을 부여
- CSS 디자인 영역에서는 영역을 구분짓는 스타일에 활용 → 영역이라는 건 겹치는 개념이 아님 → 고유한 값 → id
범위가 좁을수록 선택자의 우선 순위가 높아지기 때문에 아이디 선택자의 우선 순위가 가장 높다.
회원 가입 실습: CSS로 변경하기

- table 태그는 영역만 지정하기 때문에 border가 바깥만 적용됨
- tr은 가상의 선이라서 스타일 적용이 불가
- tr는 가상의 선 개념이라 눈에 보이지 않는다고 함
- 따라서 th, td에 스타일 적용해야 함 → 그럼
border: 1px solid black;를 총 3번 써야 하나? → 비효율적 - 태그를 그룹으로 묶어 한번에 처리할 수 있음: 그룹 선택자
class=""속성은 특정 그룹을 만드는 거라 적합하지 않음: 태그들에게 모두 적용할 거니까 태그를 묶어서 한번에 쓰면 됨
table, th, td {
border: 1px solid black;
}
- 모든 tr 중 2개만 뽑아서 배경을 skyblue로 지정 → 이게 바로 class 속성 사용해야 하는 경우임
.tr-bg {
background-color: skyblue;
}- 모든 td 중 center로 align할 일부가 존재 → class 속성
.td-align {
text-align: center;
}HTML 속성으로 디자인 한 부분을 모두 CSS로 변환 → 업무 분배하기 편하고 관리하기 편해졌음 → "유지보수성"
내가 코드를 한 번만 수정하더라도 모든 태그가 이름만 갖고 있다면 한 번에 수정된 내용을 적용할 수 있음
선택자 종류
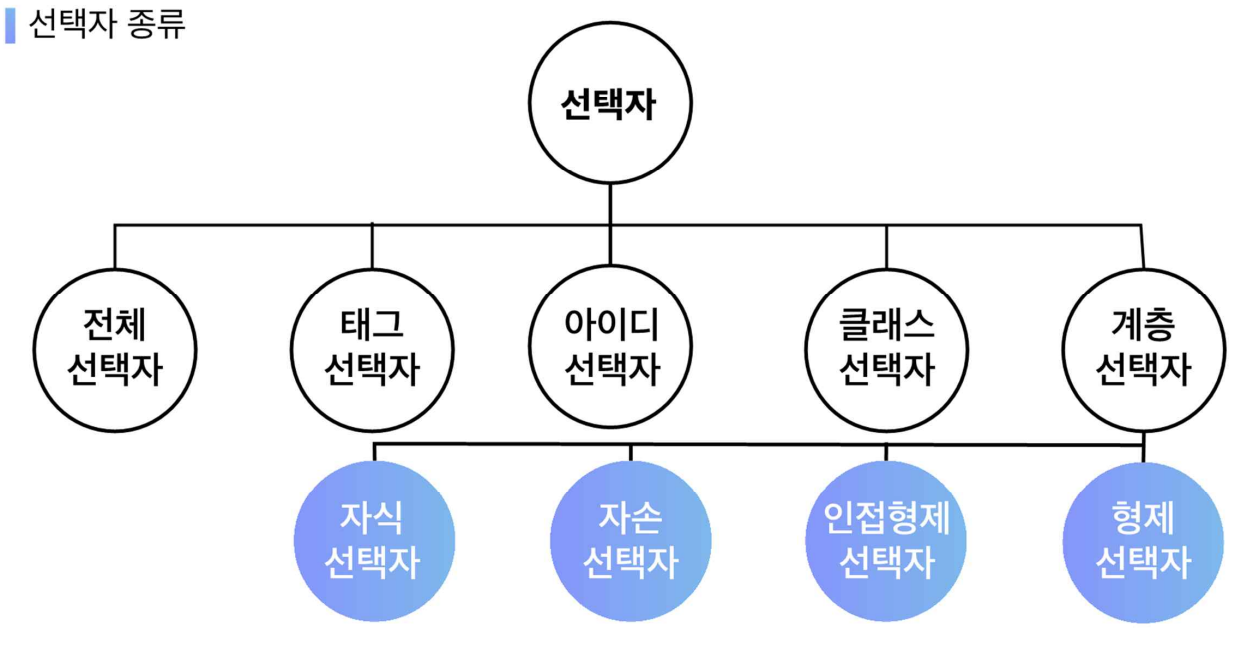
- 전체 선택자
*로 표시- 웹 문서 내 모든 요소 선택
- 타입 선택자(태그 선택자)
- 요소 이름으로 사용하여 요소 선택
- comma(,)를 통해 여러 요소를 한 번에 선택할 수도 있음 → 그룹 선택자: 다양한 요소들을 쉼표(,)로 구분하여 요소 선택
- 아이디 선택자
#기호로 표시되며 특정한 요소 선택- HTML 구조의 공간 분할을 적용할 때
- body태그 내에 고유 이름은 하나만 존재
id=는 여러 개 있을 수 있는데 그 안의 value는 딱 하나씩만 있음
- 정의한 후, 한 페이지에서 한 번만 사용
- 그렇지 않으면 웹 표준 테스트에서 오류
- 한 페이지에 한 번만 들어가는 로고, 상단 메뉴, 하단 정보 등 스타일을 정의할 때 사용
- 클래스 선택자
- 마침표(.) 기호로 표시되며 특정한 요소 선택
- 공통되는 스타일을 적용할 경우
- 여러 개의 태그에 동시에 적용될 수 있음
- 동일한 value 값을 여러 개의 태그에 넣음
- 몇 번이고 재사용 가능
- 반복적으로 사용되는 스타일
- 마침표(.) 기호로 표시되며 특정한 요소 선택
- 계층 선택자
- 특정 위치의 요소를 계층적 구조로 요소 선택
계층 선택자 이해하기
- 부모/자식 관계
2교시: CSS
계층 선택자
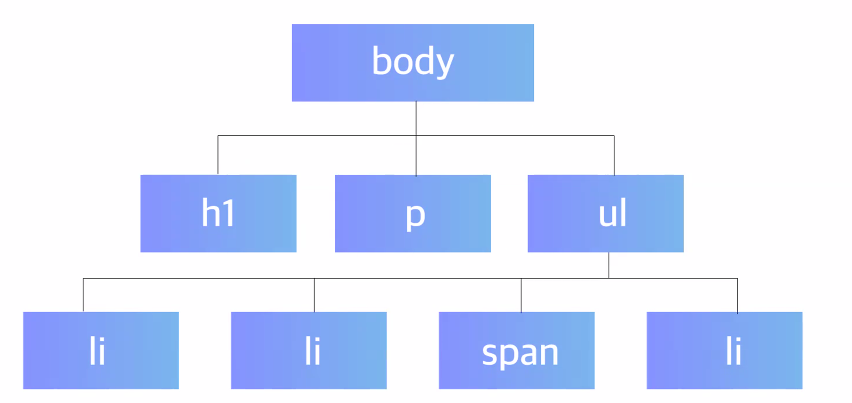
span을 이렇게 쓰면 원래 안 되긴 하지만 설명을 위해 넣었습니다.
- 태그의 포함 관계를 이용한 선택자
- 모든 태그에게 id, class 부여하는 건 비효율적이고 관리도 어려움 → 그럼 특정 li만 선택하려면 어떻게 해야 할까?
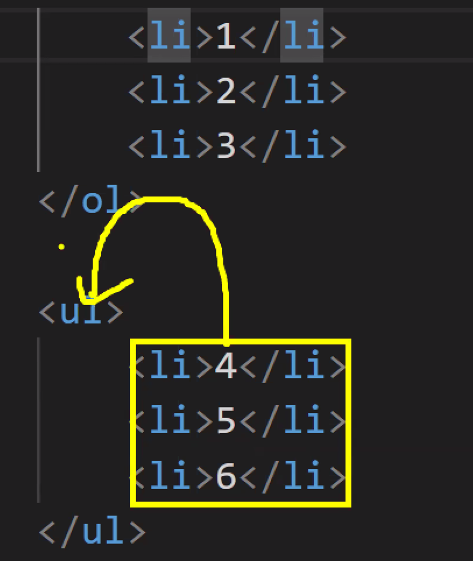
- 계층 선택자 4가지 종류
- 자손 선택자:
- 자식 선택자:
>★★★ - 근접후행 선택자(인접 형제 선택자):
+
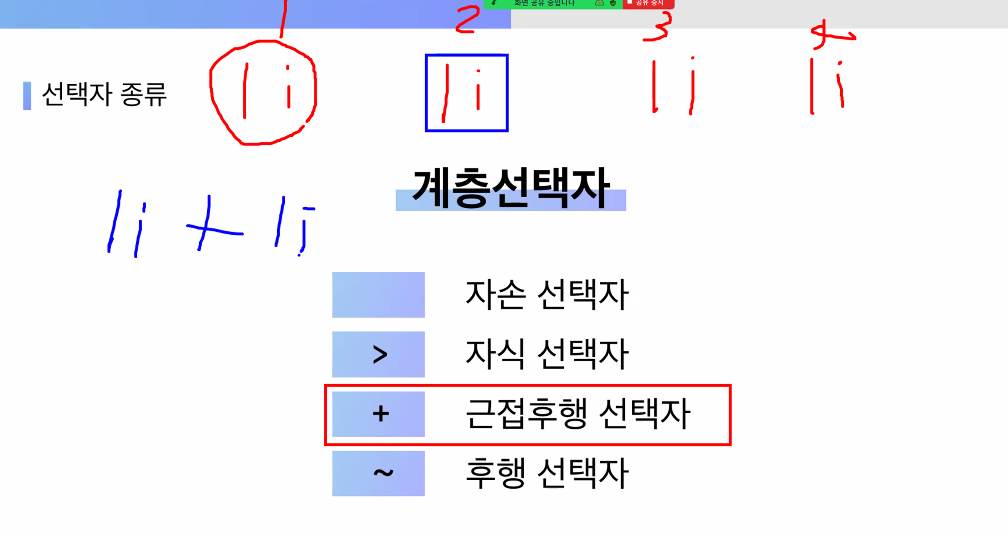
- 후행 선택자(형제 선택자):
~
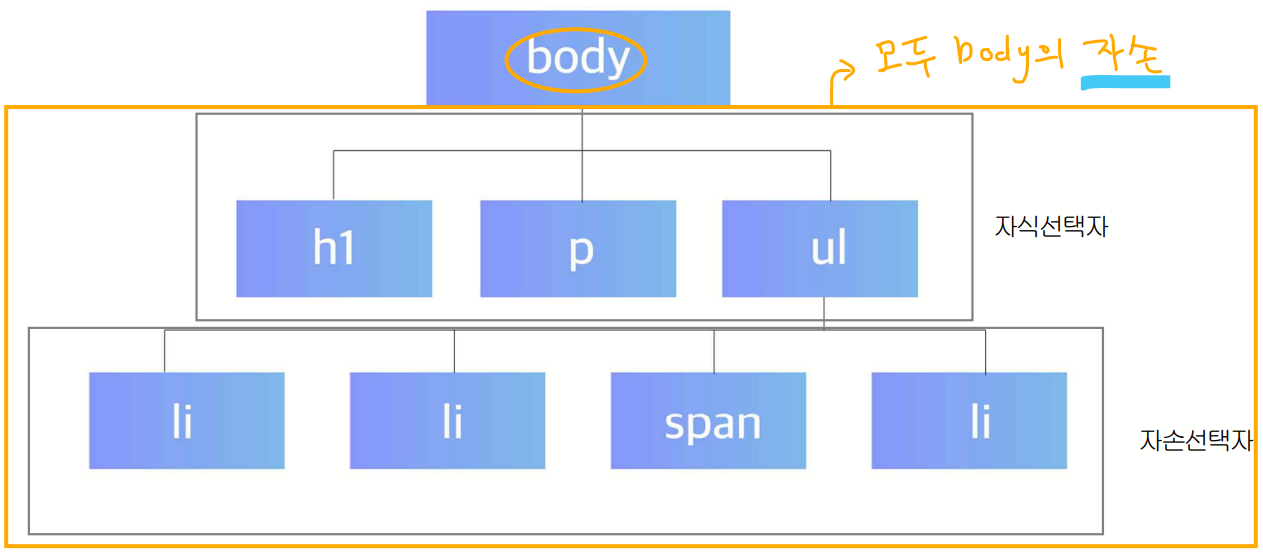
총정리: 선택자는 크게 3가지만 기억하자(id, class, 자식)
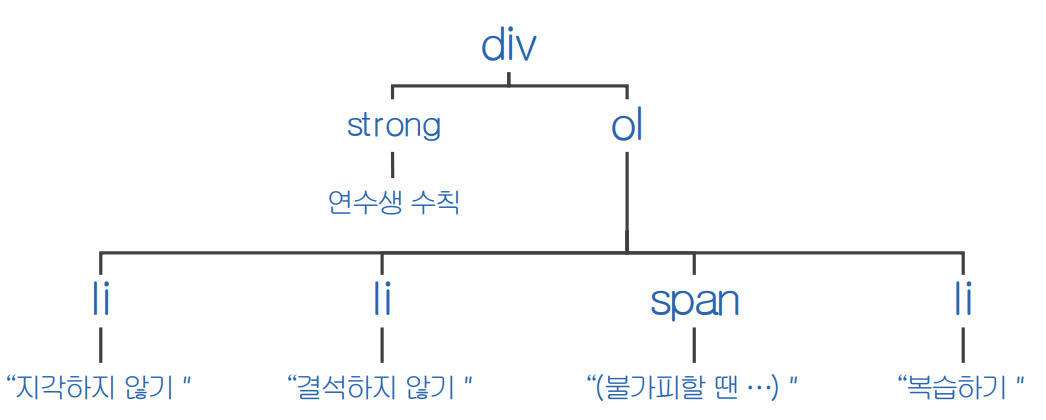
- 계층 선택자: 태그의 포함 관계를 활용하여 접근
- 부모 태그: 나를 포함하고 있는 바로 위의 태그가 부모 태그
- 자식 태그: 부모 밑에 바로 존재하는 태그가 자식 태그
- 사용법 1: 자식 태그로 접근할 때는 첫 번째는 출발지, 마지막이 목적지 (예) body > ol > li
- 사용법 2: 선택자를 적는 공간에는 선택자를 섞어서 쓸 수 있음 (예) body > ol.ol2 > li
- 첫 번째는 기준점, 마지막이 목적지, 나머지는 다 경유지 → 구조를 파고들어갈 수 있음

- 파일 디렉토리와 비슷한 구조
- 첫 번째는 기준점, 마지막이 목적지, 나머지는 다 경유지 → 구조를 파고들어갈 수 있음
- point: id, class, 자식
팁: 웹개발을 했는데 아무리 해도 코드가 적용이 안 될 때
- 캐시된 데이터를 삭제해보자
- 브라우저가 해석하는 거라서 데이터가 쌓이다가 문제가 생겼을 수 있음
- 접근하는 법:
- 설정에서 '개인 정보 보호 및 보안'으로 이동
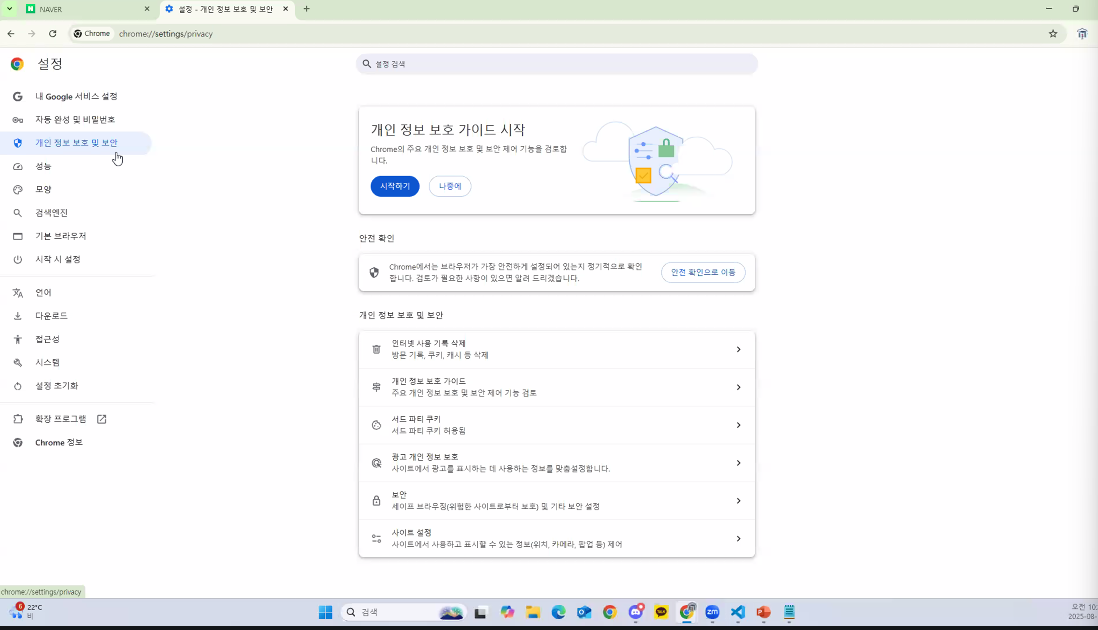
- 설정에서 '개인 정보 보호 및 보안'으로 이동
- 이렇게 했어도 안 되면 선택자 문제임
팁: 선택자의 우선순위를 무시하는 방법
- ※ 주의: 권장사항은 아니다 → 우선 순위가 사라지기 때문
-사용법: 원하는 스타일 뒤에 !important ※ 절대 남발하지 마시오 ※ - 약간 옛날 스타일 개발임
- 요즘은 쓸 일이 별로 없다고 함 쓸 일이 별로 없다고 함
- 자바스크립트를 활용한 React, Angular, Vue 같은 프레임워크가 등장하면서 페이지가 매번 초기화가 되는 개념이 생겼다고 → 단일 페이지 애플리케이션(SPA)
- 요즘은 쓸 일이 별로 없다고 함 쓸 일이 별로 없다고 함
그룹 선택자
- 다양한 요소들을 콤마(,)로 구분하여 요소 선택
h1, span, li{
color: blue;
font-size: 50px;
}반응 선택자
- 사용자의 반응으로 생성되는 특정한 상태를 선택
- 특정한 이벤트가 발생했을 때 동작하는 선택자
- 동작에 따른 화면 변화
- (예) 상단 메뉴에 마우스를 올리면 메뉴가 확장됨
:active→ 마우스로 클릭할 때 선택:hover→ 마우스를 올린 태그를 선택
HTML 반응 선택자(pseudo-class)는 사용자의 특정 행동에 따라 HTML 요소의 스타일을 변경하는 CSS 선택자입니다. 예를 들어, 마우스 커서를 요소 위에 올렸을 때(hover), 클릭했을 때(active) 등 사용자의 동작에 반응하여 스타일을 적용할 수 있습니다.
- 반응 선택자: 사용자가 특정 행동을 했을 때 디자인을 변경하는 선택자
1) 마우스를 올렸다 땠을 때: hover → Javascript의 onmouseover + onmouseout
2) 마우스를 클릭했다 땠을 때: active - 주요 반응 선택자
:hover→ 사용자가 마우스 커서를 요소 위에 올렸을 때 스타일을 적용:active→ 사용자가 요소를 클릭했을 때 스타일을 적용:focus→ 요소에 포커스가 맞춰졌을 때 스타일을 적용 (주로 입력 필드에서 사용):visited→ 이미 방문한 링크에 스타일을 적용:link→ 아직 방문하지 않은 링크에 스타일을 적용
- hover 설정 후 글자 위가 아닌 공간에 커서를 올려도 글자가 바뀌는 이유 → h1이 웹 페이지의 가로 공간을 모두 차지하는 속성을 가지기 때문!
- 개발자 도구로 확인하면 가로 공간을 모두 차지하고 있는 걸 볼 수 있음(파란색)

- margin(살구색)과는 다른 개념
- 개발자 도구로 확인하면 가로 공간을 모두 차지하고 있는 걸 볼 수 있음(파란색)
추가 공부
<style>
a:hover {
color: red;
text-decoration: underline;
}
button:active {
background-color: lightgray;
}
input:focus {
border: 2px solid blue;
}
</style>
<a href="#">링크</a>
<button>버튼</button>
<input type="text" placeholder="입력하세요">위 예시에서 <a> 태그는 마우스 커서가 위에 올라가면 빨간색 글씨에 밑줄이 생기고, <button> 태그는 클릭하면 배경색이 회색으로 변하고, <input> 태그는 포커스가 맞춰지면 테두리가 파란색으로 변함 → 반응 선택자를 사용하면 웹 페이지를 더욱 동적이고 사용하기 편리하게 만들 수 있다!
스타일 시트 명시도 계산
| 가중치 | 스타일 적용 | 예시 |
|---|---|---|
| 0 | 전체 선택자 | *{color:red'} |
| 1 | 타입 선택자 | p{color:red'} |
| 10 | 클래스 선택자 | .txt{color:red'} |
| 100 | 아이디 선택자 | #main{color:red'} |
#box p span( /* 100+1+1=102 */
color: yellow;
}
#box .my_color span{ /* 100+10+1 = 111 */
color: red;
}공간분할태그
- 경계를 분할하거나 영역을 나눌 때 사용하는 태그
<div>,<p>,<span>- div 요소
- p 요소
- span 요소
- div 요소
flex 속성을 사용하면 블록 요소 옆에다 블록 요소를 배치할 수 있게 도와줌
기본적으로 block 요소 옆에 block 요소를 배치하는 일은 어려움 → 이미 차지하고 있는 공간을 깨고 들어가는 것이기 때문에 공간 배치가 어렵다
하지만 배치를 했을 때 깔끔하게 떨어진다는 장점도 있음(가로, 세로 지정할 수 있기 때문에 정확히 쪼개 쓸 수 있음)
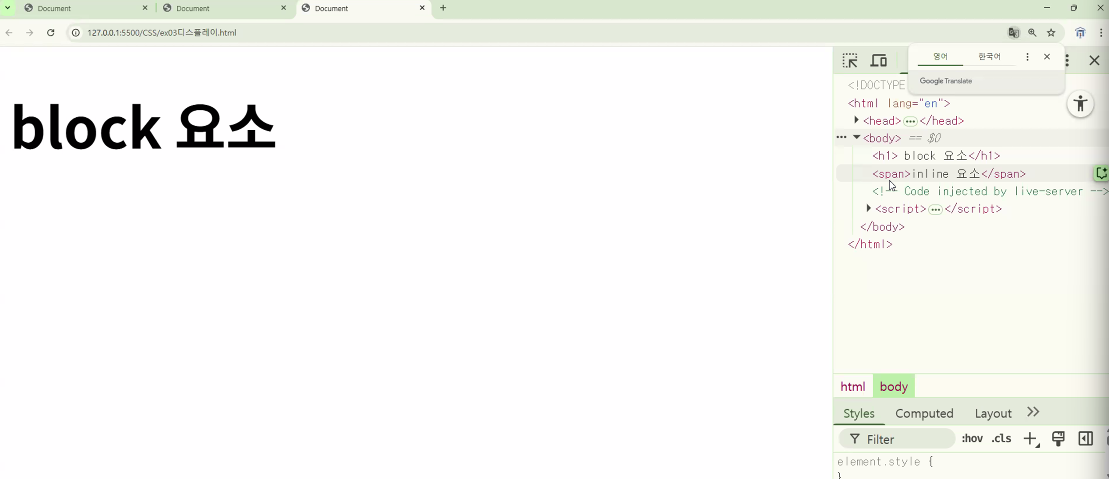
가시속성: display

display: block- 웹 페이지의 가로 공간을 모두 차지하는 속성
- (예) div, p, h1, ul, ol, table, …
- 웹 페이지의 가로 공간을 모두 차지하는 속성
display: inline- 컨텐츠(내용)이 끝나는 지점까지 너비를 가지는 속성
- (예) span, a, strong, textarea, …
- 단, 너비와 높이를 설정할 수 없다
- 컨텐츠(내용)이 끝나는 지점까지 너비를 가지는 속성
display: none- 해당 HTML 요소를 보이지 않게 지정
- 태그를 숨겨두었다가 특정 이벤트가 발생하면 보여줄 때 사용
- 언제 쓰나요? 마우스 올리면 하위 메뉴 보여주는 경우
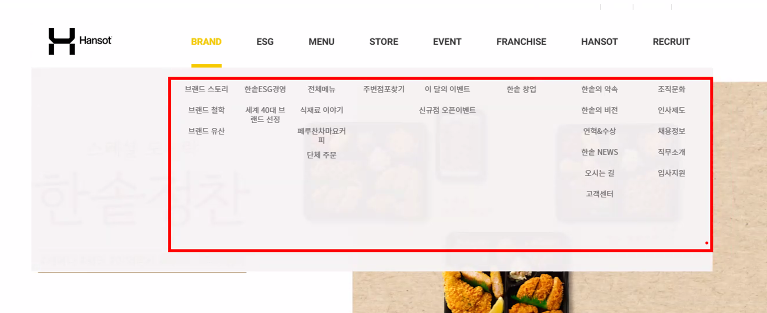
- 마우스가 메뉴에 없으면 안 보임
- 마우스가 메뉴에 없으면 안 보임
- 해당 HTML 요소를 보이지 않게 지정
3교시: CSS
display
- 화면에 보여지는 방식을 지정한 속성
- 자동으로 지정됨: 블록 or 인라인
- 블록: 웹 페이지의 가로 공간을 모두 다 차지하는 속성 → 옆으로 배치하는 게 어렵긴 하지만 실제 영역 배치를 보면 대부분이 블록임 → 가로, 세로 조정이 가능하기 때문
- 인라인: 내가 쓴 content의 크기만큼만 공간을 할당받음 → 가로, 세로 너비를 조정할 수 없음
- 자동으로 지정됨: 블록 or 인라인
- 그럼
display: None은 언제 쓰나요?
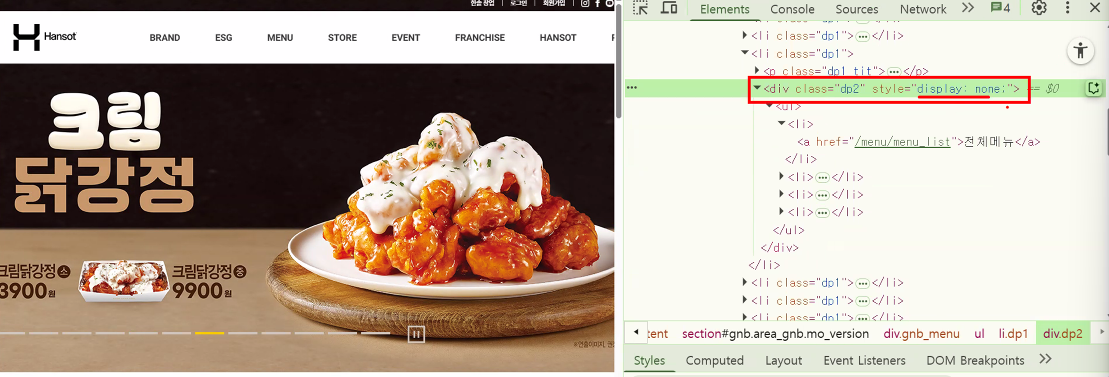
- 마우스를 올리면 바뀜
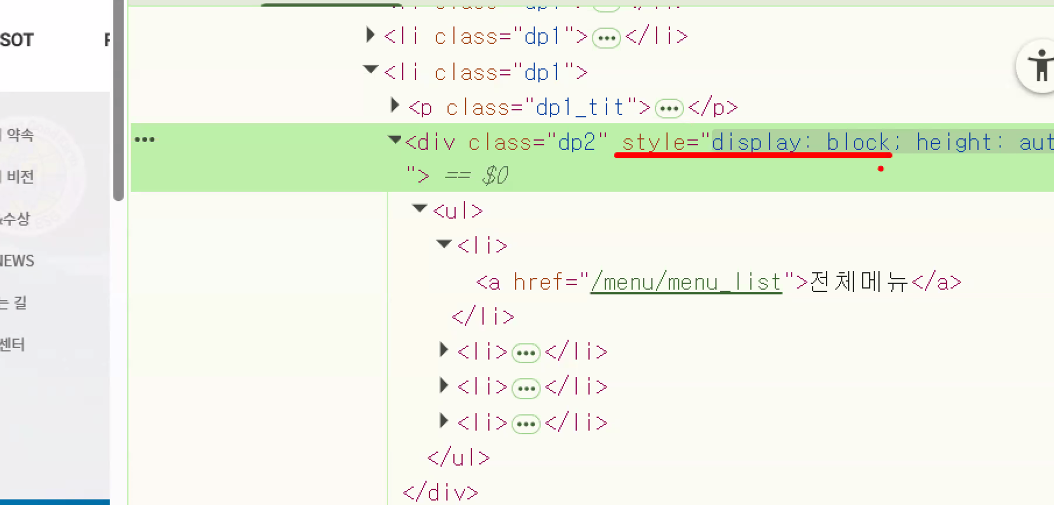
예시
span {
display: none;
}
/*
미션: h1 태그에 마우스를 올렸을 때 span 태그의 display를 inline으로 변경
* 핵심: 반드시 선택자는 마지막이 대상
* none 사용처: 메뉴 바 사용 → 마우스를 올리면 하위 메뉴가 등장, 떼면 사라진다
*/
h1:hover+span {
display: inline;
}- 간단한 디자인 처리는 CSS만으로도 가능(자바스크립트 언어를 사용하지 않아도 가능)
CSS 위치속성
영역배치! → 예쁘게 꾸미는 건 사실 감각임 & 고객경험을 활용한 UI/UX
진짜 어려운 건 "배치"
- 모든 요소는 ' 사각형 '으로 구성되어 있다. → box model
- 왜 공간이 네모일까? 공간 활용도가 가장 높음
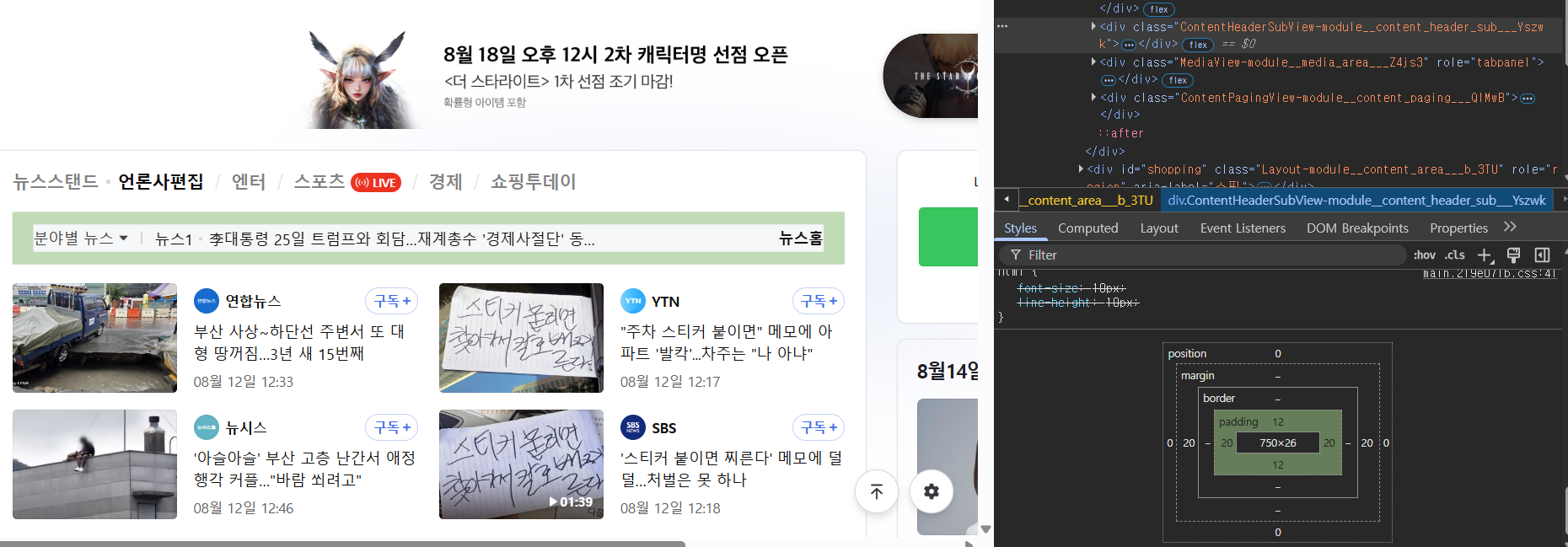
박스 모델(box model)
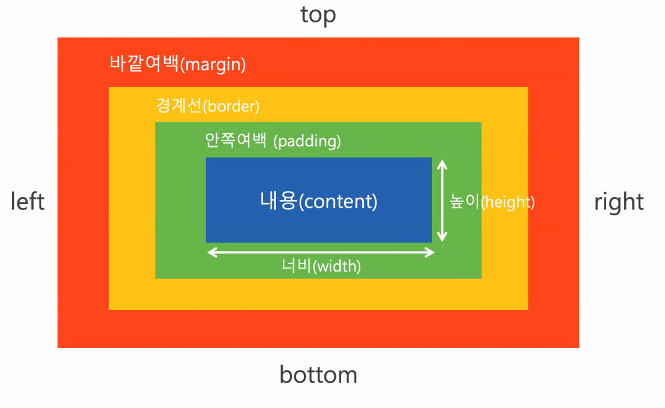
- margin: 태그와 태그 사이 공백을 주는 역할
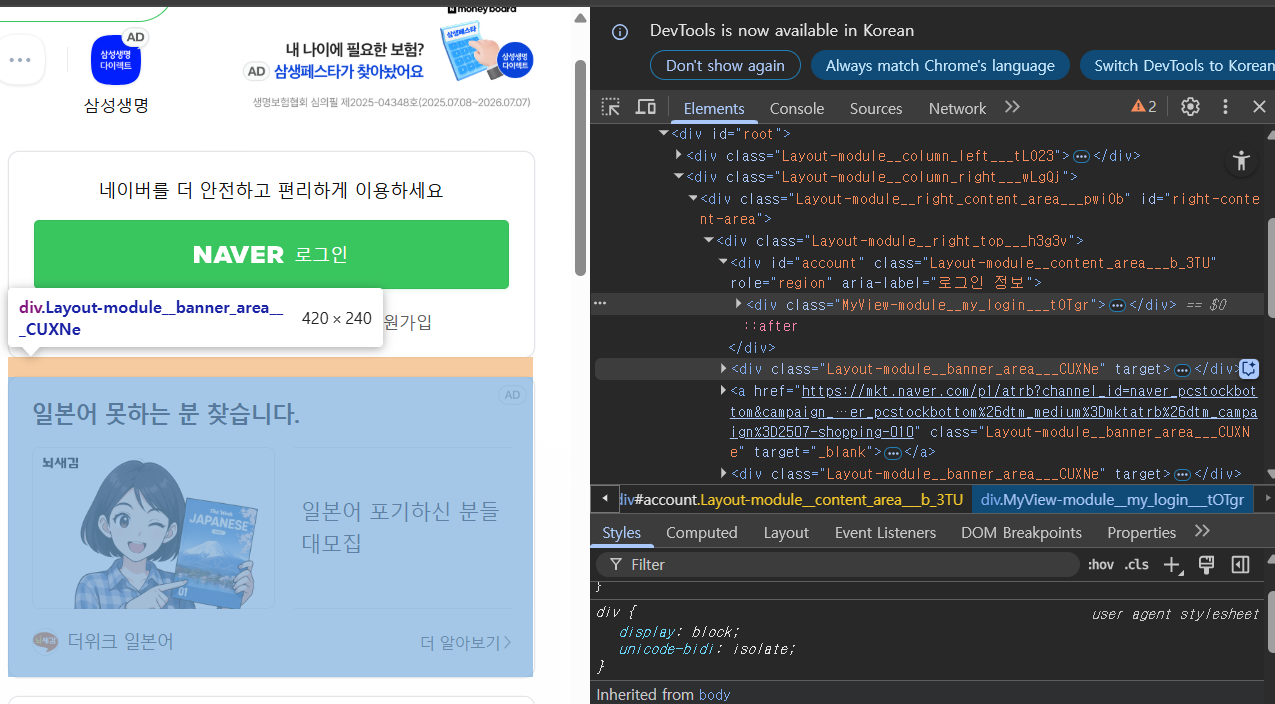
- 개발자 모드에서 박스 모델 형태로 margin 확인 가능
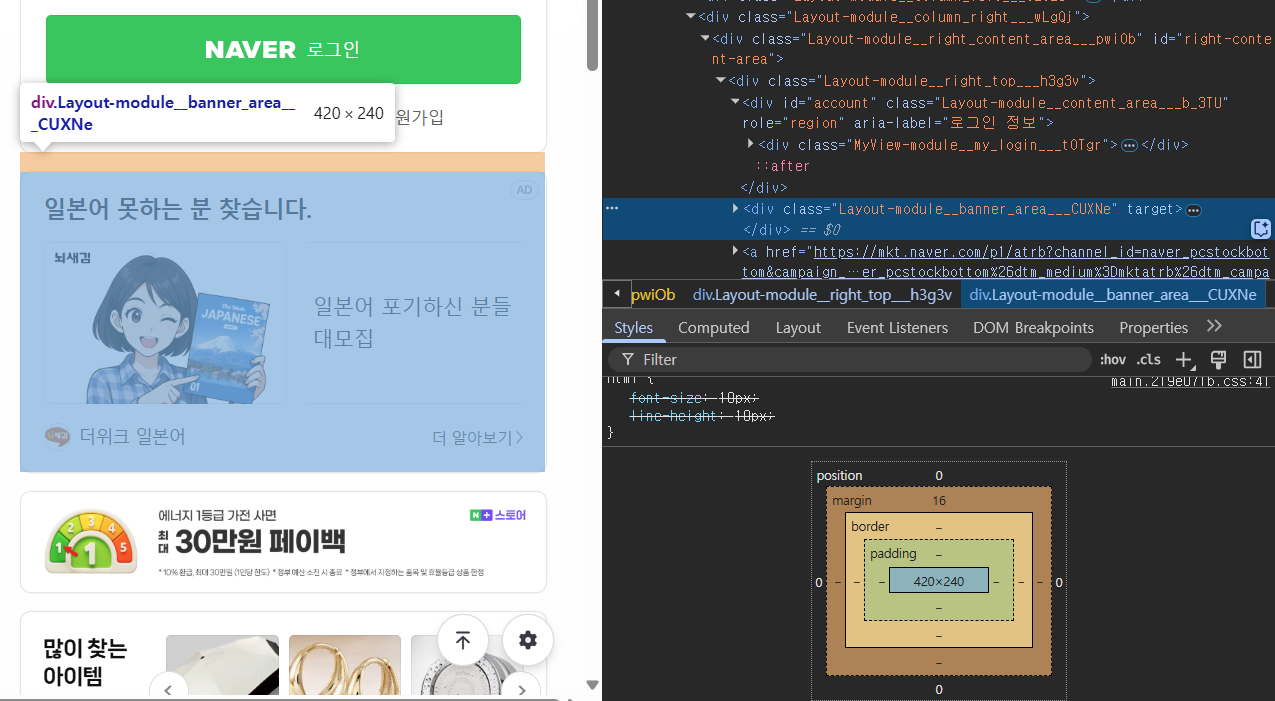
- margin을 0으로 바꾸면 이렇게 됨:
- 개발자 모드에서 박스 모델 형태로 margin 확인 가능
- padding

- 개발자 모드에서 확인하기
- 개발자 모드에서 확인하기
오후
4교시
번역(Translation)
- 번역: 한 언어를 다른 언어로 변환하는 과정
- 음성 간 통역, 텍스트-음성 같은 경우도 번역이라고 할 수 있음
- 우리가 할 것
- 영어 텍스트를 한글 텍스트로 번역하기
- OPUS 말뭉치로 학습한 MarianMT 모델을 OPUS100 데이터 세트를 활용하여 파인튜닝 진행하기
데이터 불러오기
- OPUS100 데이터 세트
- 영어 중심의 다국어 병렬 말뭉치 세트
- 100개의 언어를 가지고 있어 OPUS100이라는 이름이 붙었음
- 영어 - 한국어 번역해 둔 하위 집합을 로드하여 사용
- 영어 중심의 다국어 병렬 말뭉치 세트
from datasets import load_dataset
books = load_dataset("opus100", "en-ko", split="train")
booksDataset({
features: ['translation'],
num_rows: 1000000
})- 일부 데이터만 샘플링
books = books.shuffle(seed=12).select(range(1000))
booksDataset({
features: ['translation'],
num_rows: 1000
})- 훈련 및 검증 데이터로 분할
- huggingface의 train_test_split
books = books.train_test_split(test_size=0.2, seed=12)
booksDatasetDict({
train: Dataset({
features: ['translation'],
num_rows: 800
})
test: Dataset({
features: ['translation'],
num_rows: 200
})
})- 데이터 확인
books["train"][0]{'translation': {'en': 'Calling me uneducated!', 'ko': '나보고 문화가 없다니'}}books["train"][1]{'translation': {'en': 'So if the Dr.iver of the train was in on it, then the passenger did get off.',
'ko': '그러니까, 기관사는 그대로 있고 승객은 사라졌다?'}}- translation 값 안에 두 가지가 들어있는 것을 확인
- en → 영문
- input에 해당
- ko → 한국어
- target에 해당
- en → 영문
토크나이저 불러오기
from transformers import AutoTokenizer
checkpoint="Helsinki-NLP/opus-mt-tc-big-en-ko"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)전처리 함수 만들기
- 원어(영어)와 번역어(한글)을 별도로 토큰화
- MarianMT 계열 모델은 prefix 사용 안 함
- 학습 시 prefix를 사용하지 않았기 때문
- cf. T5 계열 모델 사용 시 prefix를 붙여주는 게 좋음 → 붙이면 모델 안정성 높아짐(학습 시 prefix를 붙이고 학습했기 때문)
# T5 계열 모델을 사용시 prefix
# MarianMT 계열 모델은 prefix 사용 X
def preprocess_function(example):
# 원어(영어)
inputs = [ex["en"] for ex in example["translation"]]
# 번역어(한국어)
targets = [ex["ko"] for ex in example["translation"]]
# 토큰화
model_inputs = tokenizer(
inputs
, text_target = targets
, max_length=128
, truncation=True
) # 나머지는 DataCollator에서 할 거임
return model_inputs
# 데이터셋에 전처리 함수 적용
tokenized_books = books.map(preprocess_function, batched=True)추가: batched=True 설정 더 알아보기
batched=True는 여러 샘플을 한 번에 토크나이징함으로써 tokenization 속도를 크게 향상시킵니다.
이는 내부적으로 텍스트 리스트를 한 번에 처리해 for 루프 등에서 개별적으로 처리할 때보다 훨씬 적은 반복과 함수 호출, I/O를 사용하게 되며, 특히 "빠른(fast) 토크나이저"의 경우 Rust 기반 코드의 병렬화와 최적화 덕분에 속도가 대폭 빨라집니다.
- 실제 속도 비교:
- 빠른 토크나이저에서
batched=True를 사용할 경우 약 10초,batched=False일 경우 59초가 소요되어 실제로 5~6배 이상 속도 차이가 발생합니다.
- 빠른 토크나이저에서
- 작동 방식:
- 각 샘플(문장)을 따로 처리하지 않고 여러 개를 한 번에 리스트 형태로 전달하여 파이썬의 반복횟수를 줄이고, 내부적으로 C/Rust 코드에서 병렬 처리 및 최적화가 이루어집니다.
- 파이프라인 효율성:
- 배치 단위로 패딩, 트렁케이션 등 부가 작업도 한 번에 처리할 수 있어 추가 속도 향상에 기여합니다.
따라서 batched=True 옵션은 토크나이저가 한 번에 더 많은 데이터를 효율적으로 처리할 수 있게 하여, 텍스트 데이터가 많을수록 속도 개선 효과가 더욱 커집니다.
batched=True는 map 함수에서 한 번에 여러 샘플(예시)을 한꺼번에 전처리 함수에 전달하도록 하여, 함수가 리스트 또는 딕셔너리 형태(배치 단위)로 데이터를 처리하게 만듭니다. 즉, 하나씩 처리하는 게 아니라 여러 개를 동시에 처리하므로 처리 속도가 훨씬 빨라집니다.
-
tokenizer와의 관련성:
huggingface tokenizer는 batch 처리를 지원합니다. 예를 들어, 하나의 문장이 아니라 여러 문장 리스트를 동시에 토크나이즈할 수 있는데, batched=True가 있어야 전처리 함수에서 예시들이 리스트로 들어와 batch로 토크나이징됩니다. 이런 식으로 전처리할 때padding,truncation등을 batch 전체 기준으로 맞춰 줄 수 있어 효율적입니다. -
datacollator와의 관련성:
DataCollator는 모델 입력 직전에 여러 샘플을 하나의 tensor 배치로 만드는 역할을 합니다. 이 단계에서는 이미 tokenized 된 데이터(예: 여러 샘플의 input_ids)를 받아서 길이가 다르면 가장 긴 샘플 기준으로 padding해서 최종적으로 동일 길이 Tensor(batch)를 만듭니다.
따라서 batched=True는 토크나이저가 여러 샘플을 한 번에 처리할 수 있도록 해주고, DataCollator는 이미 토크나이즈된 여러 샘플들을 Tensor 배치 구조로 변환·패딩합니다.
| 단계 | 기능 | batch와의 관련성 |
|---|---|---|
| map(..., batched=True) | tokenizer가 여러 샘플을 한 번에 전처리 | 전처리 속도가 빠르고, batch별 패딩 등 처리 가능 |
| datacollator | 이미 토크나이즈된 샘플들을 Tensor batch(고정 길이)로 변환 | 각각의 샘플을 padding 등으로 맞춰 주는 역할 |
정리하자면, batched=True는 데이터셋 map 함수에서 여러 샘플을 한 번에 처리해 tokenizer의 batch 기능을 활용하는 것이며, DataCollator는 tokenized 데이터를 이용해 모델 입력으로 쓸 Tensor batch를 만들어주는 별도의 역할을 합니다. 둘 다 batch와 관련 있지만, 적용 시점과 목적이 다릅니다.
DataCollator
- 배치를 생성하며 padding 값을 생성
- 데이터 정렬 중 각 배치의 최대 길이로 문장을 동적 padding
- max_length에 비해 메모리 사용이 효율적이라는 장점
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(
tokenizer=tokenizer
, model=checkpoint
)평가 지표
- BLEU
- Bilingual Evaluation Understudy
- 기계 번역 품질 평가 지표
- 사람이 번역 품질을 평가하는 데 드는 시간과 비용을 줄이기 위해 만들어진 평가 지표
- BLEU의 한계
- 의미 보존을 반영하지 못함
- 예: "I am happy." / "I feel great." → 의미가 같아도 단어가 달랐을 때 더 낮은 점수를 반영
- 문법, 의미의 자연스러움보다는 단어 일치도에 치중
- 전처리와 토큰화 방식이 다르면 점수가 크게 변동 → 이 문제를 해결하기 위하여 새로운 평가 지표 등장: SacreBLEU
- 의미 보존을 반영하지 못함
5교시
평가 지표 함수: SacreBLEU
- Metric: sacrebleu
- 아래 입력값 에시는 sacrebleu 사이트에 명시된 사용법을 따른 것으로, 직접 입력해 바로 결과를 확인할 수 있습니다.
Gradio sacrebleu 창에 복사-붙여넣기:
predictions (모델이 번역한 문장 리스트)
[
"This plugin lets you translate web pages between several languages automatically.",
"I like deep learning."
]references (각 예측 문장에 대응하는 정답 문장들의 리스트의 리스트)
[
["This plugin allows you to automatically translate web pages between several languages."],
["I love deep learning.", "I like deep learning."]
]Gradio sacrebleu 인터페이스에서는 아래처럼
- predictions 입력란에 첫 JSON 리스트 복사해서 붙여넣고
- references 입력란에 두 번째 JSON 중첩 리스트 복사해서 붙여넣으면
자동으로 BLEU 점수가 계산되어 나옵니다.
요점:
- 텍스트 문장들은 반드시 큰따옴표로 감싸야 하며
- 여러 문장은 JSON 리스트 (
[...]) 형식이어야 하며 - references는 문장별 여러 정답을 리스트 안에 리스트로 넣어야 합니다.
!pip install -q sacrebleu
!pip install -q evaluate
import evaluate
metric = evaluate.load("sacrebleu")
import numpy as np
# BLEU 평가 지표를 활용하기 위한 format → 양식 맞춰주기
# 정답 데이터: List[List[str]]
def postprocess_function (preds, labels):
# 모델의 결과값에 양 끝의 공백을 제거
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
# 평가 함수
def compute_metrics(eval_preds):
preds, labels = eval_preds
# 전처리: preds가 가끔 array 형태로 나오는 경우가 있어서 그것까지 고려
if isinstance(preds, tuple):
preds = preds[0]
# 인코딩된 데이터를 사람이 볼 수 있는 텍스트로 변환 → decode
decode_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# 예측값은 padding이 따로 붙지 않기 때문에 디코딩만 하면 끝남
# 문제는 정답이다… → 특수 토큰(-100)을 처리해야 함
# 정답 데이터 decode
# 각 값들에 특수토큰(시작 토큰, 패딩 등)이 -100으로 변환되어 있는 상태
# 각 모델이 가지고 있는 특수 토큰을 의미하는 id(pad_token_id에 들어 있음)로 재변환
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decode_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# 문자열로 변환한 데이터를 BLEU에 맞게 list[list[str]] 변환
decode_preds, decode_labels = postprocess_function(decode_preds, decode_labels)
# BLEU 점수 계산
result = metric.compute(predictions=decode_preds, references=decode_labels)
result = {"bleu": result["score"]}
# 생성된 결과에서 [PAD] 토큰을 제외한 실제 길이를 계산
prediction_len = [np.count_nonzero(pred!=tokenizer.pad_token_id) for pred in preds]
# 평균값을 출력
result["gen_len"] = np.mean(prediction_len)
# 소수점 4번째 자리 수까지만 출력
result = {k: round(v, 4) for k, v in result.items()}
return result- SacreBLEU 평가 지표
- BLEU 평가 지표보다 정규화, 표준화된 버전
- 0-100 사이의 점수를 출력
- 0-10 : 아주 낮음 (랜덤 수준)
- 10-30 : 낮음 (거의 이해 어려움)
- 30-50 : 중간 (대략 이해 가능)
- 50-70 : 좋음 (대부분 자연스러움)
- 70-100 : 아주 좋음 (사람 수준에 가까움)
- BLEU 평가 지표를 활용하기 위해서는 포맷을 맞춰 주어야 함
- 양식 맞춰주기:
List[List[str]][문장1, 문장2, 문장3, …]이 아니라[[문장1], [문장2], [문장3], …]
- 왜 이런 형태? 다음과 같은 상황에 대비하기 위함
[[문장1-1, 문장1-2, …], [문장2-1, 문장2-2, …], [문장3-1, 문장3-2, …], …]형태의 정답 데이터를 받는 경우 → 하나의 문장에 대한 복수 정답 인정- 이 경우 가장 높은 점수를 최종 점수로 반환함
- 양식 맞춰주기:
6교시
훈련 모델 불러오기
from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
training_args = Seq2SeqTrainingArguments(
output_dir="./results/my_awesome_opus_books_model"
, eval_strategy="epoch"
, save_strategy="epoch"
, learning_rate=2e-5
, weight_decay=0.01
, per_device_train_batch_size=16
, per_device_eval_batch_size=16
, save_total_limit=3
, num_train_epochs=2
, predict_with_generate=True
, logging_strategy="steps"
, logging_steps=2 # 평가 지표를 기준으로 훈련이 끝났을 때 가장 성능이 좋은 모델을 자동으로 로드
, load_best_model_at_end=True
, fp16=True
, push_to_hub=False
)
trainer = Seq2SeqTrainer(
model=model
, args=training_args
, train_dataset=tokenized_books["train"]
, eval_dataset=tokenized_books["test"]
, data_collator=data_collator
, processing_class=tokenizer
, compute_metrics=compute_metrics
)
trainer.train()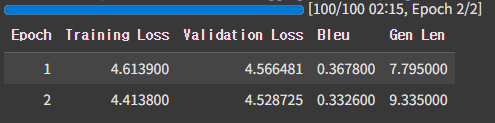
학습한 결과를 허깅페이스에 업로드
- repo_id 형식
- {username}/{base_model}-{task/특징}-{language(s)}-{도메인}-{버전}
%cd /content/drive/MyDrive/Colab Notebooks/NLP
# 허깅페이스 로그인
from huggingface_hub import login
# 파일 형태의 api_key 불러오기
with open("./key/huggingface_api_key", 'r') as f:
api_key = f.read().strip()
login(token=api_key)
# 허깅페이스 업로드
repo_id = "★유저아이디★/opus-translation-en-ko"
trainer.save_model(repo_id)
model.save_pretrained(repo_id)
tokenizer.save_pretrained(repo_id)
trainer.push_to_hub(repo_id)허깅페이스에서 모델 불러오기
# pipeline 사용해서 불러오기
# task: translation_xx_to_yy
from transformers import pipeline
checkpoint_mymodel="be2be2/opus-translation-en-ko"
translation = pipeline(
task="translation_xx_to_yy"
, model=checkpoint_mymodel
, tokenizer=checkpoint_mymodel
)
text = "So if the Dr.iver of the train was in on it, then the passenger did get off."
result = translation(text)
result[{'translation_text': '- 네, 괜찮아요?'}]데이터를 조금밖에 넣지 않아서 성능이 좋지 않음😅
미니 프로젝트 회의
- 선정 근거 찾기
- 통계청
- 뉴스
- 기타 → survey는 어떨까?
- 서비스 프로세스
- 화면 2개
- 서비스단
a. 문단 입력창
b. 상황 선택창 → 프롬프트? 정해진 상황 선택지? → 선택지로 - 데이터 로그 구축?
- 굳이??
- 문단 단위 / 문장 단위 → 문단으로 입력 받고 문장으로 쪼개서 모델에 넣고 다시 문단으로 붙여주기
- 어투
- 문어체: 이메일, 공문서, 계약서, 보고서
- 연령대별: 세대간 의사소통 불편 해소 측면
- 아동 대상: 발달 단계별(나이데에 맞는 말투? 언어 구사력?)
- 데이터셋 조사
하루 돌아보기
👍 잘한 점
- 웹 수업 대답 많이 했음
- 자연어분석 수업 질문 많이 했음
- 번역 평가 지표와 요약 평가 지표 차이점
- 미니 프로젝트 준비
👎 아쉬웠던 점
- 내일 머신러닝, 딥러닝 시험인데 공부를 하나도 못했다🫠
- AWS Skill Builder 활용을 잘 못하고 있는 것 같음
🔬 개선점
- AWS Skill builder 하는 시간 고정시키기
- 자격증 공부 틈틈히 하기
- 정보처리기사 실기
- 리눅스마스터
- 머신러닝, 딥러닝 계속 복습하기
