[인공지능사관학교] NumPy
NumPy란?
NumPy(Numerical Python) library
- 고성능 수치 계산을 위한 파이썬 라이브러리
- 다차원 배열 객체인 ndarray 제공
- 벡터화된 연산을 통해 빠른 수학 연산 수행 가능
- 특징
- 빠른 연산 속도 (C로 구현됨)
- 강력한 배열 연산 지원 (슬라이싱, 브로드캐스팅)
- 다양한 수학/통계 함수 제공
- 문자열을 다루는 데에는 조금...
C: 1970년대 등장
→ 이후 프로그래머가 아니어도 컴퓨터 프로그래밍을 업무에 적용하려는 사람이 증가
→ 하지만 그들에게 C는 너무 어렵다!
→ JAVA, Python 등장: 1990년대
1990년대 초반 웹이 등장하면서 웹 페이지를 동적으로 만들고 상호 작용할 수 있는 기술이 필요해졌고 다양한 운영체제와 하드웨어 환경에서 실행 가능한 언어의 필요성이 커져 다양한 플랫폼에서 실행될 수 있는 이식성, 웹 환경에서의 활용, 그리고 객체 지향 프로그래밍의 장점을 결합하여 JAVA 탄생
다른 라이브러리 안에 같은 이름을 가진 함수가 존재할 수 있음에 유의
sum()
numpy.sum()
pandas.sum()
→ 메서드 이름은 같아도 구현 방식은 서로 다름! 그래서 속도 차이나 메모리 효율 차이 등이 생김
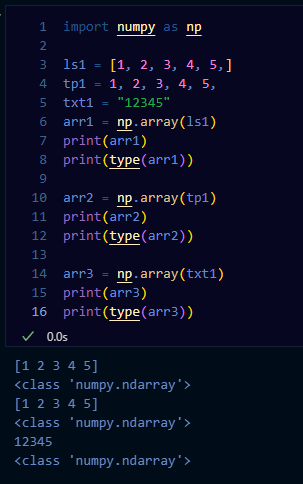
NumPy 배열 생성
리스트로부터 배열 생성
import numpy as np
arr = np.array([1, 2, 3, 4, 5,])
print(arr)
print(type(arr))# [Out]
[1 2 3 4 5]
<class 'numpy.ndarray'>기본 배열 생성 함수
import numpy as np
# 0으로 채워진 배열
zeros_arr = np.zeros((2, 3))
print(zeros_arr)
# 1로 채워진 배열
ones_arr = np.ones((2, 3))
print(ones_arr)
# 특정 값으로 채워진 배열
full_arr = np.full((2, 3), 7)
print(full_arr)# [Out]
[[0. 0. 0.]
[0. 0. 0.]]
[[1. 1. 1.]
[1. 1. 1.]]
[[7 7 7]
[7 7 7]]연속된 숫자 배열 생성
import numpy as np
arr1 = np.arange(1, 10, 2) # 1부터 10-1까지 2씩 증가
print(arr1)
arr2 = np.linspace(0, 1, 5) # 0부터 1까지 5개 값을 균등 분할# [Out]
[1 3 5 7 9]
[0. 0.25 0.5 0.75 1. ]난수 배열 생성
- 실행할 때마다 달라지는 게 포인트
import numpy as np
random_arr = np.random.rand(3, 3) # 0~1 사이의 난수 (3x3 배열)
print(random_arr) # 실행할 때마다 출력 달라짐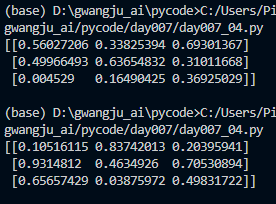
NumPy 배열 연산
기본 연산
import numpy as np
arr = np.array([1, 2, 3, 4, 5,])
print(arr + 10) # 배열의 모든 요소에 10을 더함
print(arr * 2) # 배열의 모든 요소를 2배
print(arr ** 2) # 배열의 모든 요소를 제곱# [Out]
[11 12 13 14 15]
[2 4 6 8 10]
[1 4 9 16 25]배열 간 연산
import numpy as np
arr1 = np.array([1, 2, 3,])
arr2 = np.array([4, 5, 6,])
print(arr1 + arr2) # 요소별 덧셈
print(arr1 * arr2) # 요소별 곱셈# [Out]
[5 7 9]
[4 10 18]왜 리스트가 아닌 NumPy를 사용할까?
1. 연산 속도가 빠름
- NumPy는 내부적으로 C 언어로 구현되어 있어 일반 리스트(파이썬 기본 제공 리스트)보다 훨씬 빠른 연산 속도를 제공
- 일반 리스트는
for문을 사용해 하나씩 계산 - NumPy는 벡터 연산을 지원 → 한 번에 연산 수행 가능
- 일반 리스트는
# 연산 속도 비교
import numpy as np
import time
# 리스트 연산
list_data = list(range(1000000))
start = time.time()
list_result = [x*2 for x in list_data]
end = time.time()
print("리스트 연산 시간:", end - start)
# NumPy 배열 연산
np_data = np.array(list_data)
start = time.time()
np_result = np_data * 2 # 벡터 연산
end = time.time()
print("NumPy 연산 시간:", end - start)2. 메모리 효율이 높음
- NumPy 배열은 리스트보다 메모리를 더 적게 사용
- 리스트는 여러 개의 객체를 참조하는 구조
- NumPy 배열은 한 번에 연속된 메모리 공간을 사용
# 메모리 비교
import numpy as np
import sys
list_data = list(range(1000))
np_data = np.array(list_data)
print("리스트 크기:", sys.getsizeof(list_data), "bytes")
print("NumPy 크기:", np_data.nbytes, "bytes")NumPy 데이터 관리 효율이나 처리 속도는 램에서만 영향이 있는 건가요? 네
하드디스크 저장은 큰 의미가 없고 런타임에서 램에 로딩되는 것이 영향을 줍니다.
처리 속도의 경우 cpu 처리 속도도 함께 영향을 미칩니다.
추가: C와 Python은 자료 구조의 근본 설계 개념이 다름 → 이로 인해 발생히는 차이점은 '클래스' 설명에서 다시 이야기
3. 강력한 기능 제공
- NumPy: 행렬 연산, 선형 대수, 통계 함수, 난수 생성 같은 기능을 기본 지원
- 리스트로는 어렵거나 복잡한 계산
- NumPy는 짧은 코드로 쉽게 해결 가능
# 행렬 곱셈
import numpy as np
A = [[1, 2], [3, 4]]
B = [[5, 6], [7, 8]]
# 리스트로 행렬 곱셈 (복잡함)
result = [[sum(a*b for a, b in zip(A_row, B_col)) for B_col in zip(*B)] for A_row in A]
print("리스트 행렬 곱셈 결과:\n", result)
# NumPy로 행렬 곱셉 (간단!)
A_np = np.array(A)
B_np = np.array(B)
result_np = np.dot(A_np, B_np)
print("NumPy 행렬 곱셈 결과:\n", result_np)결론
- NumPy는 리스트보다 연산 속도가 훨씬 빠름 → 빠름
- NumPy는 연속된 메모리를 사용해서 가벼움 → 메모리 효율적
- NumPy는 강력한 수학/과학 계산 기능을 제공 → 편리함
따라서 데이터 분석, 머신러닝, 과학 계산에서는 NumPy가 필수
NumPy의 axis
axis란?
- NumPy에서 axis(축)은 배열에서 연산을 수행할 방향을 결정
axis = 0: 열(column) 방향으로 연산 → 위에서 아래로axis = 1: 행(row) 방향으로 연산 → 왼쪽에서 오른쪽으로
- 쉽게 말해 axis = 0이면 세로 방향이고, axis = 1이면 가로 방향이라는 뜻
arr = [[10, 20, 30],
[40, 50, 60],
[70, 80, 90]]각 행의 합(axis = 1)
np.sum(arr, axis = 1): 각 행(row)별로 값을 더함arr,axis = 1: 함수의 파라미터(parameter), 옵션값
- 결과:
[10+20+30, 40+50+60, 70+80+90] = [60, 150, 240]
각 열의 합(axis = 0)
np.sum(arr, axis = 0): 각 열(column)별로 값을 더함- 결과:
[10+40+70, 20+50+80, 30+60+90] = [120, 150, 180]
다른 함수나 메서드에서도
axis = 1일 때 행 계산일까?
NumPy에서axis=1이 행(row) 단위 연산인 것은 다른 함수나 메서드에서도 일관되게 적용되는 기준입니다.
즉 axis=0이면 열(column) 기준, axis=1이면 행(row) 기준으로 동작하는 것은 다양한 NumPy 함수(sum, mean, max, min, std, argmax 등)에서 동일하게 적용됩니다.
다양한 함수에서 axis 동작 예시
| 함수 | axis=0 (열 기준) | axis=1 (행 기준) |
|---|---|---|
| np.sum() | 각 열의 합 | 각 행의 합 |
| np.mean() | 각 열의 평균 | 각 행의 평균 |
| np.max() | 각 열의 최댓값 | 각 행의 최댓값 |
| np.min() | 각 열의 최솟값 | 각 행의 최솟값 |
| np.std() | 각 열의 표준편차 | 각 행의 표준편차 |
| np.argmax() | 각 열에서 최댓값의 위치(인덱스) | 각 행에서 최댓값의 위치(인덱스) |
import numpy as np
arr = np.array([[1, 2, 3,],
[4, 5, 6,],
[7, 8, 9,],])
print(np.max(arr, axis=0)) # 각 열에서 최댓값 찾기
print(np.max(arr, axis=1)) # 각 행에서 최댓값 찾기
print(np.argmax(arr, axis=0)) # 각 열에서 최댓값의 인덱스
print(np.argmax(arr, axis=1)) # 각 행에서 최댓값의 인덱스# [Out]
[7 8 9] # 각 열에서 최댓값 (열 기준)
[3 6 9] # 각 행에서 최댓값 (행 기준)
[2 2 2] # 각 열에서 최댓값의 인덱스 (0, 1, 2번째 행에서 각각 찾음)
[2 2 2] # 각 행에서 최댓값의 인덱스 (각 행에서 최댓값 위치)결론
- NumPy에서
axis=0은 열(column) 기준,axis=1은 행(row) 기준으로 동작 - 대부분의 NumPy 함수(
sum(),mean(),max(),min(),std(),argmax()등)에서 동일한 방식으로 적용됨
즉, 어떤 함수를 사용하든 axis=0이면 열(column) 단위 연산, axis=1이면 행(row) 단위 연산으로 처리됨
NumPy의 조건연산
NumPy 배열에서 특정 조건의 값 변경하기: 필터링
- NumPy에는 특정 조건을 만족하는 원소를 빠르게 선택하고 변경할 수 있는 기능이 존재
- 리스트에서는
for문을 사용해야 함 - NumPy는
조건 연산(불리언 인덱싱)을 이용하면 간단하게 해결 가능
- 리스트에서는
Boolean Indexing
불리언 배열
- 배열 생성
np.random.randint(0, 16, (4, 4)): 0~15 사이의 정수를 무작위로(4, 4)배열로 생성
- 짝수 찾기(
arr % 2 == 0)%연산자를 사용해 짝수인지 확인arr % 2 == 0의 결과는 True/False로 이루어진 불리안 배열이 됨
- 짝수를 0으로 변경(
arr[arr % 2 == 0] = 0)arr[arr % 2 == 0]: 짝수인 원소만 선택- 선택된 원소를
0으로 변경
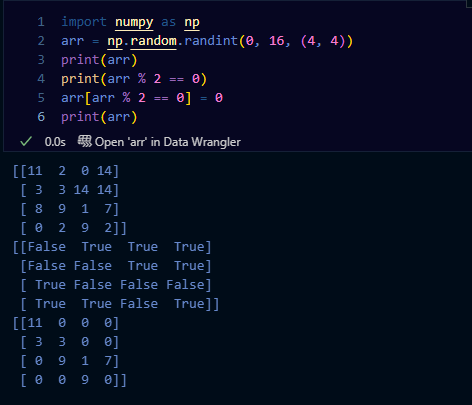
응용이 많이 되니 꼭 알아두기!
bitmap 형식의 이미지 처리 → 특정 RGB값만 제거 등
정리
| 표현식 | 의미 |
|---|---|
arr % 2 == 0 | 짝수인 요소 찾기(True/False 배열) |
arr[arr % 2 == 0] | 짝수인 요소만 선택 |
arr[arr % 2 == 0] = 0 | 짝수를 0으로 변경 |
- 핵심 요점
arr[arr % 2 == 0]: 짝수만 선택arr[arr % 2 == 0] = 0: 해당 값들을 0으로 변경- NumPy의 불리언 인덱싱을 활용하면 반복문 없이 빠르게 처리 가능
조건연산 예시
import numpy as np
np.random.seed(42) # 시드값 42로 난수 고정
arr1 = np.random.randint(0, 16, (4, 4))
print("시드 42로 생성한 배열:")
print(arr1)
np.random.seed(42) # 다시 시드 42로 고정
arr2 = np.random.randint(0, 16, (4, 4))
print("\n다시 시드 42로 생성한 배열:")
print(arr2)
- 시드값
42로 고정하면 결과가 동일함
Q. 시드값 42가 의미하는건 뭔가요?
A. 랜덤값을 만들 때 기준이 되는 값입니다.
동일한 조건에서 다음번 작업에 똑같은 요소(원소)로 구성된 배열을 랜덤으로 만들 고자 할 때 유리합니다.
Q. 난수 고정 값을 다른 경우에 42로 고정해도 결과가 똑같이 나오나요?
A.np.random.seed(42)에서42는 고정값(seed)이기 때문에, 같은 시드값을 사용하면 항상 같은 결과가 나오게 됨.
따라서 다른 값으로 시드를 고정해도 동일한 시드값을 사용하는 한 그 시드값에 대응하는 난수 시퀀스는 항상 동일한 결과가 나옴.
→ 모든 컴퓨터에서 항상 동일한 값!
결론
- 같은 시드값을 사용하면 항상 동일한 난수 시퀀스 생성
- 시드값을 다르게 설정하면 다른 난수 시퀀스가 생성됨
np.random.seed()는 재현 가능한 결과를 얻을 때 유용 → 실험 결과를 다시 실행해야 할 때, 동일한 데이터를 재사용할 때
배열의 모양 변경(reshape)
reshape() 함수
- 배열의 형태(shape)를 바꾸는 데 사용
- 1차원 배열을 2차원 배열로 전환
- 2차원 배열을 3차원 배열로 변환
- 단, 변경 후 배열의 크기는 원래 배열의 크기와 동일해야 함
== 원래 배열의 원소(요소) 수가 변하지 않아야 함 - 기본 문법:
arr.reshape(new_shape)
# 1차원 배열을 2차원 배열로 변경
import numpy as np
arr = np.arange(12) # 0~11까지의 정수로 이루어진 1차원 배열
print("원본 배열:")
print(arr)
reshaped_arr = arr.reshape(3, 4) # 3행 4열의 2차원 배열로 변경
print("\nReshaped 배열:")
print(reshaped_arr)# [Out]
원본 배열:
[ 0 1 2 3 4 5 6 7 8 9 10 11]
Reshaped 배열:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]# 2차원 배열을 1차원 배열로 변경
reshaped_arr = reshaped_arr.reshape(-1)
# -1을 사용하면 자동으로 1차원으로 변경
print("\n1차원 배열로 변경:")
print(reshaped_arr)# [Out]
1차원 배열로 변경:
[ 0 1 2 3 4 5 6 7 8 9 10 11]※ 주의: reshape(-1)은 자동으로 차원 크기를 계산해줍니다. (원래 배열의 크기와 일치해야만 적용 가능)
reshape에서 2차원 배열에서 1차원으로 변경할 때 -1에 대한 설명
-1을 사용하면 배열의 크기를 자동으로 계산
(-1은 자동으로 다른 차원에 맞는 크기를 계산)
즉, 어떤 차원을-1로 지정하면 나머지 차원에 맞게 자동으로 크기를 결정
→ 배열 크기를 잘 모르거나, 자동으로 계산해 주기를 원할 때 유용
→ 1차원 배열을 2차원 배열로 변환하거나 2차원 배열을 1차원 배열로 변환할 때 편리하게 사용 가능
배열 인덱싱(Indexing)
- 배열의 특정 원소를 선택하거나 수정하는 데 사용
- 특정 원소 선택: 읽기 참조 →
print(arr[0]) - 특정 원소 수정: 쓰기 참조 →
arr[0] = 99
- 특정 원소 선택: 읽기 참조 →
- 기본 문법:
arr[index]→ index는 배열의 위치를 나타냄 - 리스트 인덱싱과 유사
- 2차원 배열에서는 행과 열을 인덱싱해야 함
# 1차원 배열 인덱싱
import numpy as np
arr = np.array([10, 20, 30, 40, 50,])
print(arr[0]) # 첫 번째 원소 선택
print(arr[2]) # 세 번째 원소 선택
# 2차원 배열 인덱싱
arr = np.array([[10,20,30],
[40,50,60],
[70,80,90]])
# 첫 번째 행, 두 번째 열의 값
print(arr[0, 1]) # 출력: 20
# 두 번째 행, 첫 번째 열의 값
print(arr[1, 0]) # 출력: 40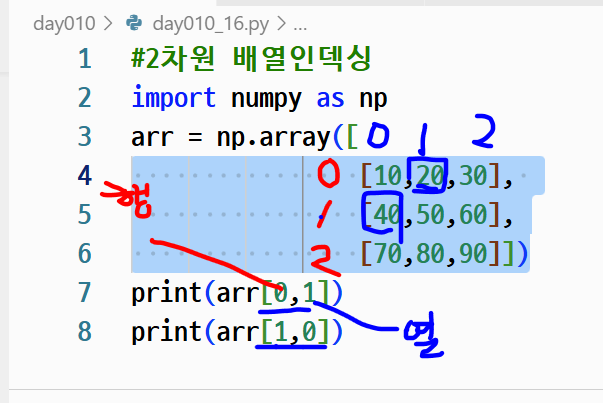
배열 슬라이싱(slicing)
- 슬라이싱: 배열의 일부분을 선택하는 방법
- 시작 인덱스와 끝 인덱스를 지정하여 필요한 부분만 추출 가능
- 기본 문법:
arr[start:end]→ start는 포함, end는 미포함- cf.
np.linspace(start, end, num)에서 end는 default가 포함임
(numpy.linspace 참고)
- cf.
# 1차원 배열 슬라이싱
import numpy as np
arr = np.array([10, 20, 30, 40, 50])
print(arr[1:4]) # 1번부터 3번까지(20, 30, 40)
# 2차원 배열 슬라이싱
arr = np.array([[10,20,30],
[40,50,60],
[70,80,90]])
# 첫 번째 행의 전체 값
print(arr[0, :]) # 첫 번째 행의 모든 열 선택
# 두 번째 열의 모든 값
print(arr[:, 1]) # 두 번째 열의 모든 행 선택
# 첫 번째, 두 번째 행과 첫 번째, 두 번쨰 열
print(arr[:2, :2])# [Out]
[20 30 40]
[10 20 30]
[20 50 80]
[[10 20]
[40 50]]배열의 조건 인덱싱(Boolean Indexing)
- 배열의 원소가 특정 조건을 만족하는지 확이하고, 그에 맞는 원소만 선택하는 방법
- 짝수만 골라내기 같은 작업을 할 때 유용
# 조건 인덱싱으로 짝수만 선택
import numpy as np
arr = np.array([10, 15, 20, 25, 30])
even_arr = arr[arr % 2 == 0]
print(even_arr)# [Out]
[10 20 30]# 조건을 만족하는 값 변경
arr[arr % 2 == 0] = 0 # 짝수만 0으로 변경
print(arr)# [Out]
[0 15 0 25 0]정리
reshape(): 배열의 모양을 변경할 때 사용- 원소(요소) 개수 확인 필수
- Indexing: 배열의 특성 원조나 부분을 선택할 때 사용
- Slicing: 배열의 일부분을 선택할 때 사용
- Boolean Indexing: 배열에서 조건을 만족하는 원소만 선택하거나 수정할 때 사용
indexing, slicing은 리스트와 동일!
