[인공지능사관학교] Pandas
지난 시간 복습
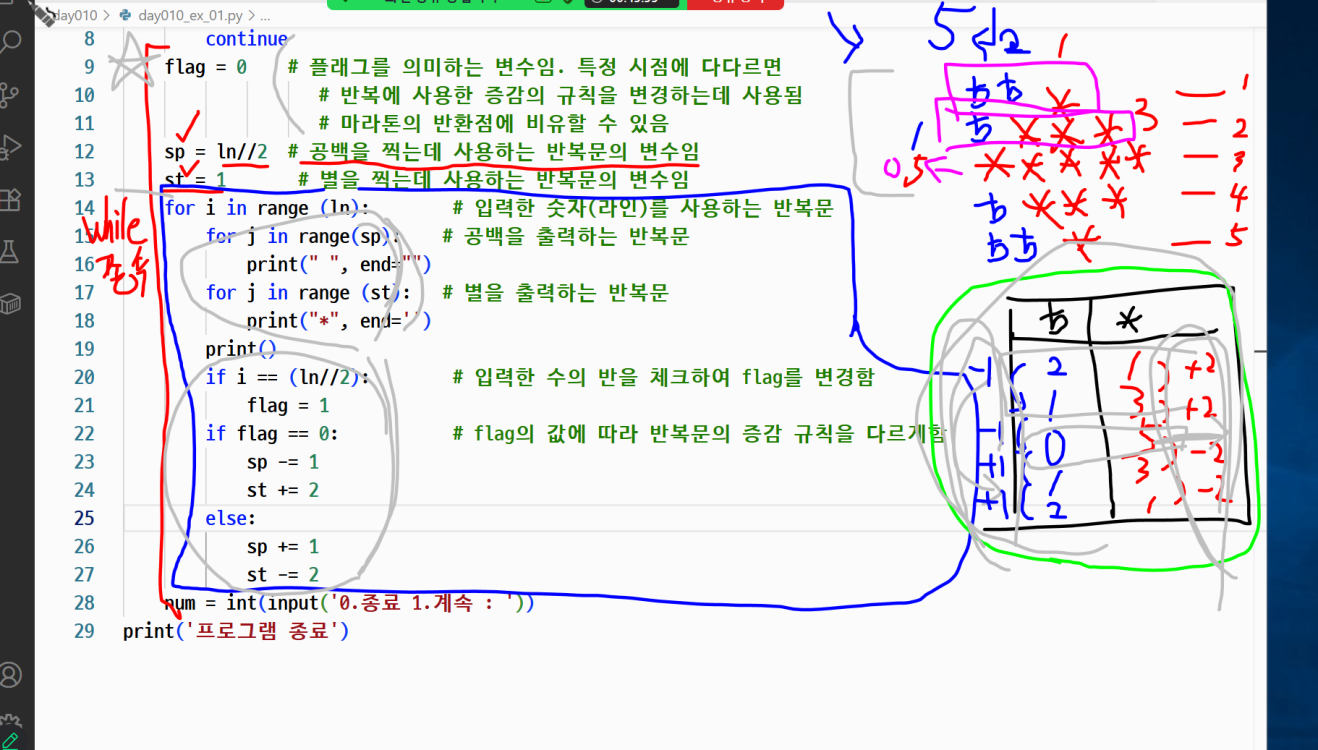
# 마름모 별 찍기
ƀƀ*
ƀ***
*****
ƀ***
ƀƀ*| ƀ 증감 | ƀ | * | * 증감 |
|---|---|---|---|
| 2 | 1 | ||
| -1 | 1 | 3 | +2 |
| -1 | 0 | 5 | +2 |
| +1 | 1 | 3 | -2 |
| +1 | 2 | 1 | -2 |
내가 생각한 방법
def diamond(n):
result = ''
for i in range(n):
for j in range(n):
if abs((n//2)-i)+abs((n//2)-j) <= (n//2):
result += '*'
else:
result += ' '
result += '\n'
return result| n | i | * 개수 |
|---|---|---|
| 3 | 1 2 3 | 1 3 1 |
| 5 | 1 2 3 4 5 | 1 3 5 3 1 |
| 7 | 1 2 3 4 5 6 7 | 1 3 5 7 5 3 1 |
| 9 | 1 2 3 4 5 6 7 8 9 | 1 3 5 7 9 7 5 3 1 |
n = 5일 때
n//2 = 2 → 편의상 k=2로 지칭
(0,0)(0,1)(0,2)(0,3)(0,4)
(1,0)(1,1)(1,2)(1,3)(1,4)
(2,0)(2,1)(2,2)(2,3)(2,4)
(3,0)(3,1)(3,2)(3,3)(3,4)
(4,0)(4,1)(4,2)(4,3)(4,4)
- 굵게 표시한 부분에 별이 들어가야 함
- 굵게 표시하지 않은 부분과의 차이는 뭘까 고민
k-i, k-j를 생각해보았음
(2,2)(2,1)(2,0)(2,-1)(2,-2)
(1,2)(1,1)(1,0)(1,-1)(1,-2)
(0,2)(0,1)(0,0)(0,-1)(0,-2)
(-1,2)(-1,1)(-1,0)(-1,-1)(-1,-2)
(-2,2)(-2,1)(-2,0)(-2,-1)(-2,-2)
- (x,y)에서 x 절댓값과 y 절댓값을 더해 생각해 봄
- (k-i의 절댓값 + k-j의 절댓값) 숫자가 k보다 작거나 같으면 별, 아니면 빈 칸
4 3 2 3 4
3 2 1 2 3
2 1 0 1 2
3 2 1 2 3
4 3 2 3 4
- (k-i의 절댓값 + k-j의 절댓값) 숫자가 k보다 작거나 같으면 별, 아니면 빈 칸
→ 별과 공백의 증감 규칙이 명확히 드러나지 않아, 직관성이 떨어지고 빈 칸을 추가로 사용하기 때문에 해답 풀이보다 안 좋은 것 같다...
코드 개선
| 코드 | 장점 | 단점 |
|---|---|---|
| 1 | 별/공백 증감 명확, 직관적 | 코드 길고, 출력만 가능, 함수화 어려움 |
| 2 | 함수화, 결과 저장 가능, 코드 간결 | abs 연산이 다소 비효율적, 별 위치 계산이 직관적이지 않을 수 있음 |
- 증감 규칙을 함수로 만들기!
def diamond(n):
if n % 2 == 0 or n < 3:
return None
result = []
sp = n // 2
st = 1
for i in range(n):
result.append(' ' * sp + '*' * st)
if i < n // 2:
sp -= 1
st += 2
else:
sp += 1
st -= 2
return '\n'.join(result)
while True:
n = int(input("3 이상의 홀수의 줄 수를 입력하세요: "))
d = diamond(n)
if d is None:
print("입력한 수가 틀렸습니다.")
continue
print(d)
sel = input("0. 종료, 1. 계속: ")
if sel == '0':
print("프로그램을 종료합니다.")
breakSeries
- Pandas의 핵심 데이터 구조 중 하나
- Pandas: 데이터 분석과 조작을 위한 강력한 라이브러리
- 핵심 데이터 구조로는 Series(1차원, np.ndarray와 유사), DataFrame(2차원, DB table과 유사) 존재
- Pandas: 데이터 분석과 조작을 위한 강력한 라이브러리
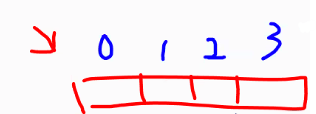
- 1차원 배열 형태의 데이터 구조
- NumPy의 ndarray와 유사하지만 각 값에 인덱스(index)를 지정할 수 있음
- ndarray는 인덱스 편집 불가, Series는 인덱스 편집 가능
('딕셔너리와 리스트의 차이점'처럼) - list, Arr, Series: "유사"한 형태
- NumPy의 ndarray는 출력하면 인덱스 안 보이지만 Pandas의 Series는 출력하면 인덱스까지 함께 출력됨
- ndarray는 인덱스 편집 불가, Series는 인덱스 편집 가능
- NumPy의 ndarray와 유사하지만 각 값에 인덱스(index)를 지정할 수 있음
class pandas.Series(data=None, index=None, dtype=None, name=None, copy=None, fastpath=<no_default>)
- 클래스 이름 앞에 소문자로 된 이름과 점(.)을 붙여 표기: "모듈(또는 패키지) 이름.클래스 이름" 형식
- pandas는 파이썬의 데이터 분석 라이브러리인 모듈 또는 패키지의 이름
- Series는 pandas 모듈 안에 정의된 클래스의 이름
- 즉, pandas.Series는 "pandas라는 모듈 안에 있는 Series라는 클래스"를 의미
소문자.대문자조합의 의미
- 모듈/패키지 이름: 파이썬의 공식 스타일 가이드(PEP 8)에 따르면, 모듈과 패키지 이름은 소문자를 사용합니다. 필요하면 밑줄(_)로 단어를 구분할 수 있음
- 클래스 이름: 클래스 이름은 첫 글자를 대문자로 하고, 여러 단어는 대문자로 구분하는 "CapWords" 또는 "CamelCase" 방식(예: Series, DataFrame)을 사용
- pandas.Series에서 pandas는 소문자 모듈명, Series는 대문자 클래스명
- 점(.)은 "소속"을 나타냄
- 즉, pandas 모듈의 Series 클래스라는 뜻
- 이런 표기법은 파이썬에서 객체의 소속(네임스페이스)을 명확히 표현하는 일반적인 방식임
Series 생성 방법
- 리스트, 배열, 딕셔너리 등을 사용할 수 있음
1. 리스트로 Series 생성
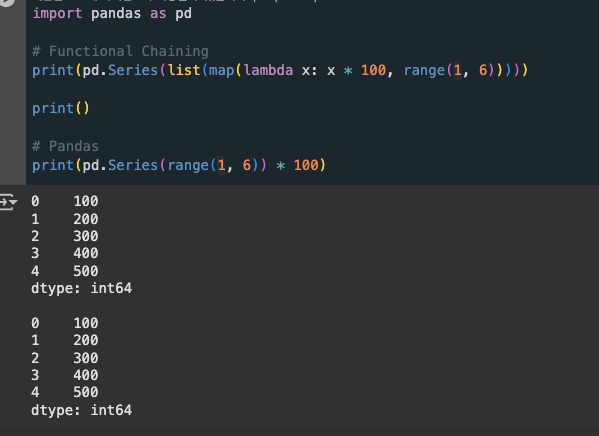
import pandas as pd
data = [10, 20, 30, 40, 50,]
s = pd.Series(data) # Series는 대문자로 시작 == 클래스라는 뜻!
print(s)# [Out]
0 10
1 20
2 30
3 40
4 50
dtype: int64- 왼쪽(0~4)은 인덱스(index), 오른쪽 값(10~50)은 데이터
import pandas as pd
import numpy as np
data = np.array([10, 20, 30, 40, 50,])
s = pd.Series(data)
print(s)A pandas Series is a class. In Python, a class serves as a blueprint for creating objects, defining their attributes (data) and methods (functions). The pandas.Series class encapsulates the structure and behavior of a one-dimensional labeled array.
2. 인덱스를 지정한 Series
s = pd.Series([100, 200, 300,], index=['a', 'b', 'c'])
print(s)# [Out]
a 100
b 200
c 300
dtype: int64- 인덱스가 a, b, c로 변경됨
3. 딕셔너리로 Series 생성
- 딕셔너리를 사용하면 키(key)가 자동으로 인덱스가 됨
data = {"Apple": 3, "Banana": 5, "Cherry": 2}
s = pd.Series(data)
print(s)# [Out]
Apple 3
Banana 5
Cherry 2
dtype: int64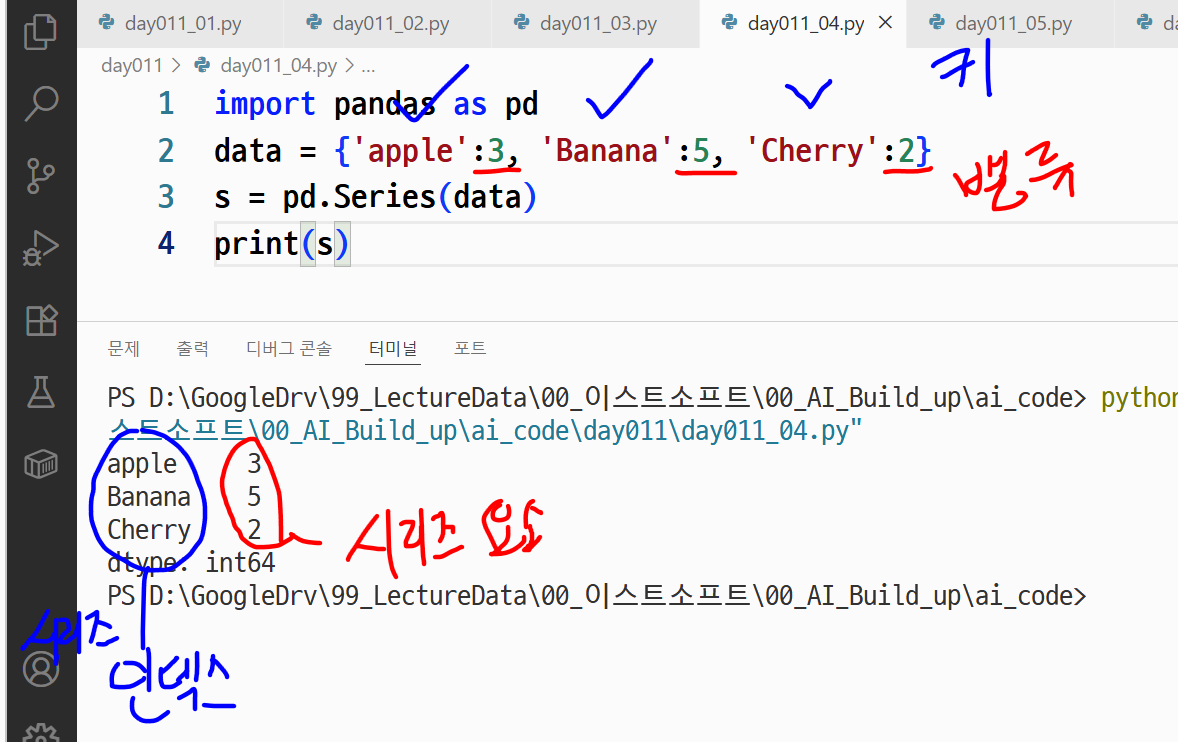
Series에서 데이터 선택
- Series는 리스트처럼 인덱싱, 슬라이싱 가능
특정 요소 선택
print(s["Apple"])# [Out]
3여러 개의 값 선택
print(s[["Apple", "Cherry"]])# [Out]
Apple 3
Cherry 2
dtype: int64- 복수 개의 인덱스를 선택할 때는 꼭 대괄호 2개!: s
[["Apple", "Cherry"]]
조건을 이용한 선택
print(s[s > 3])# [Out]
Banana 5
dtype: int64Numpy vs. Pandas: Index
- NumPy
ndarrayvs. PandasSeries의 인덱스 차이점ndarray와Series는 모두 1차원 배열 구조를 갖고 있지만, 인덱스(index) 사용 방식에서 큰 차이가 있음
NumPy ndarray의 인덱스
- 기본적으로 0부터 시작하는 정수 인덱스(implicit index)를 사용 → NumPy 배열의 인덱스는 항상 정수로 자동 할당
- 즉, 리스트와 동일한 방식으로 값을 참조(읽기 참조)
- 사용자가 별도로 인덱스를 지정할 수 없음
import numpy as np
arr = np.array([10, 20, 30, 40,])
print(arr[0])# [Out]
10Pandas Series의 인덱스
- 사용자가 원하는 인덱스(index)를 직접 지정할 수 있음
- 딕셔너리의 쌍을 구성하는 key와 value 중 key를 구성하는 특성을 설명한 것과 동일함
(맥락이 같음) - 정수뿐만 아니라 문자열, 날짜(또는 시간) 등 다양한 형태의 인덱스 설정 가능
- 날짜 또는 시간 == 시계열!
→ 시계열을 인덱스로 사용할 수 있는 점은 Series를 설명하는 매우 중요한 특징 중 하나 & 필터링(원본 데이터를 내가 원하는 형태로 고도화(품질 개선)시키는 과정)

- 날짜 또는 시간 == 시계열!
- 딕셔너리의 쌍을 구성하는 key와 value 중 key를 구성하는 특성을 설명한 것과 동일함
- 따라서 리스트나
ndarray보다 더 유연한 데이터 참조가 가능
import pandas as pd
s = pd.Series([10, 20, 30, 40,], index = ['a', 'b', 'c', 'd'])
print(s)# [Out]
a 10
b 20
c 30
d 40
dtype: int64원시 데이터 → Series → DataFrame
데이터 고도화 과정에서 "필터링"은 매우 중요
(동기화/연관성 높은 부분만 추출 등)
따라서 Series의 인덱스를 잘 다루는 게 중요함!
비교
| 특징 | Numpy(ndarray) | Pandas(Series) |
|---|---|---|
| 인덱스 종류 | 정수만 가능 | 문자열, 날짜, 정수 등 자유롭게 지정 가능 |
| 인덱스 변경 가능 여부 | 불가능(고정) | 가능 |
| 데이터 선택 방식 | 정수 인덱스(arr[0]) | 사용자 지정 인덱스(s['a']) |
날짜&시간 → "시계열"
Pandas 인덱스의 강점
- 사용자 지정 인덱스 덕분에 데이터 탐색과 분석이 용이
- 날짜, 문자열, 정수를 자유롭게 인덱스로 설정할 수 있는 것이 Pandas의 강점
- e.g. 인덱스가 날짜인 Series
- 날짜(
2024-01-02같은 인덱스)를 기준으로 데이터를 쉽게 조회 가능
- 날짜(
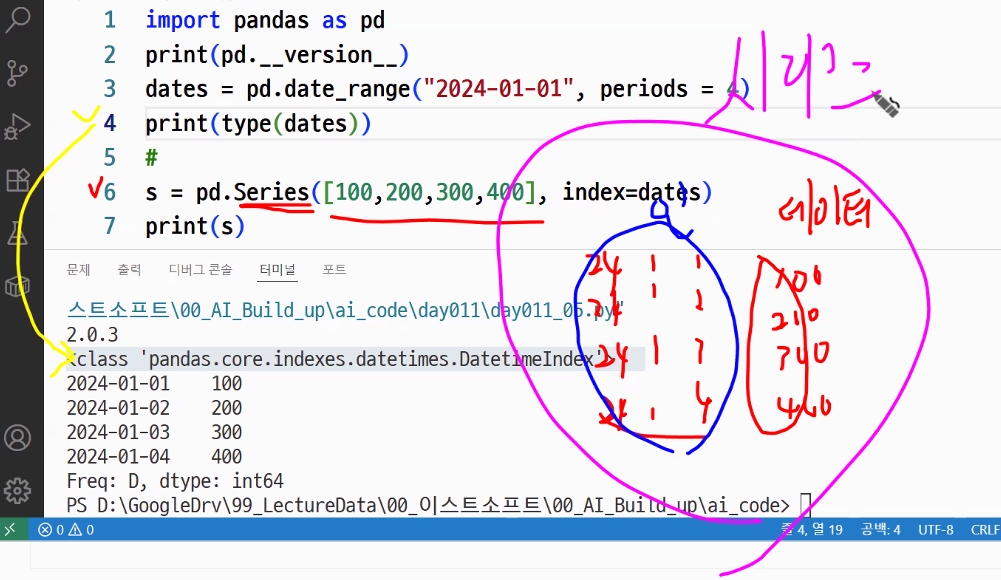
dates = pd.date_range("2024-01-01", periods = 4)
s = pd.Series([100, 200, 300, 400,], index = dates)
print(s)2024-01-01 100
2024-01-02 200
2024-01-03 300
2024-01-04 400
Freq: D, dtype: int64- Numpy의 인덱스는 정수 숫자만 할당될 수 있는데 반해 pandas는 문자열이나 날짜같은것도 인덱스로 할당할 수 있습니다.
- 주식 데이터 같은 경우에는 몇 번째였는지 순서가 중요한 게 아니라 어떤 날짜에 가격이 얼마였는지가 중요한데 이런 경우에는 날짜를 인덱스로 쓰는 게 더 좋을 수 있습니다.
pandas.date_range 더 알아보기
결론
- NumPy
ndarray는 고정된 정수 인덱스(0, 1, 2, ...)만 사용 - Pandas
Series는 사용자가 직접 원하는 인덱스(문자, 날짜, 정수 등)를 지정 가능 - 따라서
Series는 더 직관적이고 데이터 검색이 쉬운 구조임
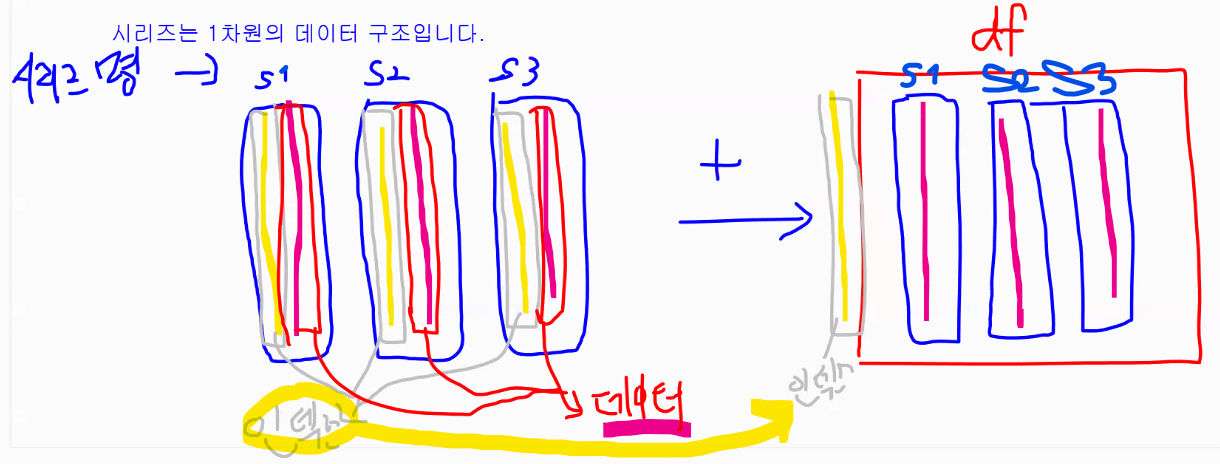
DataFrame
- 2차원 형태의 데이터 구조
- 엑셀의 표처럼 행과 열로 구성된 데이터를 다룰 수 있음
- '엑셀 표의 행과 열'은 '데이터베이스 테이블의 로우와 컬럼'과 등치
- 엑셀 스프레드시트, csv 파일, json 파일 등 → "격자 구조"를 가진 데이터는 모두 데이터프레임이 될 수 있음
- '엑셀 표의 행과 열'은 '데이터베이스 테이블의 로우와 컬럼'과 등치
- 시리즈 몇 개를 결합해서 데이터프레임을 만드는 것도 가능
DataFrame 생성 방법
- 리스트, 배열, 딕셔너리를 이용해 생성 가능
1. 리스트로 DataFrame 생성
data = [[1, "Alice", 25], [2, "Bob", 30], [3, "Charlie", 35]]
df = pd.DataFrame(data, columns=["ID", "Name", "Age"])
print(df)# [Out]
ID Name Age
0 1 Alice 25
1 2 Bob 30
2 3 Charlie 352. 딕셔너리로 DataFrame 생성
data = {"ID": [1, 2, 3], "Name": ["Alice", "Bob", "Chalie"], "Age": [25, 30, 35]}
df = pd.DataFrame(data)
print(df)# [Out]
ID Name Age
0 1 Alice 25
1 2 Bob 30
2 3 Charlie 35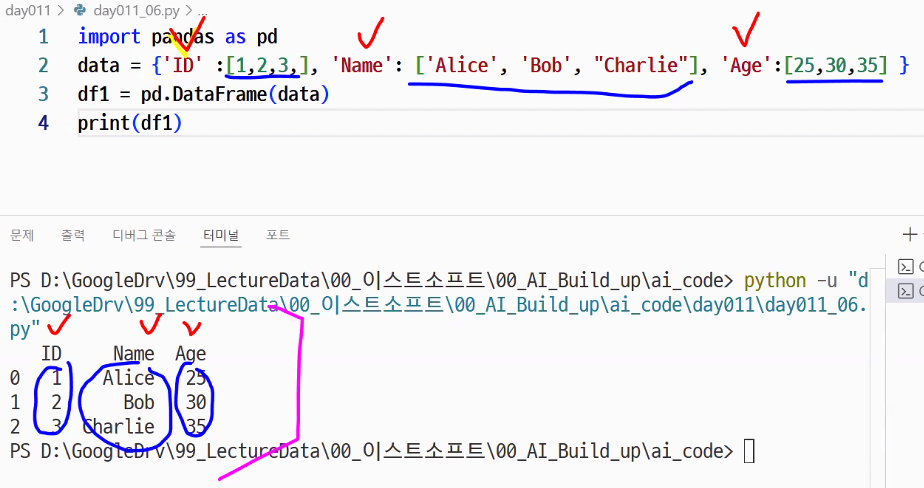
DataFrame 다루기
- DataFrame을 생성한 후에는 열 선택, 행 선택, 데이터 추가 및 삭제 등을 할 수 있음
1. 특정 열 선택
print(df["Name"])# [Out]
0 Alice
1 Bob
2 Chalie
Name: Name, dtype: object2. 특정 행 선택
print(df.iloc[1])# [Out]
ID 2
Name Bob
Age 30
Name: 1, dtype: objectPython Pandas 파이썬 판다스 loc과 iloc의 차이
✔ loc
1. 데이터프레임의 행이나 컬럼에 label이나 boolean array로 접근
2. location의 약어로, 인간이 읽을 수 있는 label 값으로 데이터에 접근하는 것
✔ iloc
1. 데이터프레임의 행이나 컬럼에 인덱스 값으로 접근
2. integer location의 약어로, 컴퓨터가 읽을 수 있는 indexing 값으로 데이터에 접근하는 것
import pandas as pd
df = pd.DataFrame({
"bid_id": [1, 2, 3],
"bidder_id": ["Gadi", "Conda", "Lion"],
"city": ["Seoul", "LA", "Sydney"],
"item": ["TV", "jewelry", "book"]}).set_index("bid_id")
df.iloc[0] # 첫 번째 행 접근
df.iloc[:,0] # 첫 번째 열 접근
df.loc[1] # 레이블 이름이 1인 행에 접근
# loc[1]에서 1은 레이블 이름이므로 인덱스 번호와는 구분된다는 사실을 알아야 한다.
# 인덱스로 이 데이터에 접근하려면 df.iloc[0] 이라고 접근해야 한다.
df.loc[:, "city"] # 레이블 이름이 city인 열에 접근추가: 접근 방식
Pandas에서 [] 접근 방식은 주로 레이블 기반 접근을 지원하는 loc와 위치 기반 접근을 지원하는 iloc에 비해 기능이 제한적입니다. loc는 데이터프레임의 행과 열에 레이블(라벨 이름)을 사용하여 접근하는 반면, []는 주로 컬럼 선택에 사용됩니다.
-
[]접근:
주로 컬럼 선택에 사용됩니다. 예를 들어,df['col_name']은 'col_name'이라는 컬럼을 선택합니다.
단일 컬럼 선택 외에도 리스트를 사용하여 여러 컬럼을 선택하거나, 불리언 시리즈를 사용하여 특정 행을 선택할 수 있습니다.
행 선택 시에는 레이블(인덱스) 기반 접근을 지원하지 않고, 위치 기반 접근만 가능합니다 -
loc 접근:
레이블 기반 인덱싱을 지원합니다. 즉, 행과 열의 인덱스 이름(라벨)을 사용하여 데이터에 접근합니다.
예를 들어,df.loc[row_label, col_label]과 같이 행과 열의 인덱스 이름을 지정하여 데이터에 접근할 수 있습니다.
슬라이싱도 가능하며, 슬라이싱 범위는 종료 인덱스를 포함합니다 (종료 인덱스 - 1이 아님).
불리언 인덱싱도 지원합니다. -
[]와 loc의 차이점 요약:
[]는 주로 컬럼 선택에 사용되며, 행 선택 시에는 위치 기반 접근만 가능합니다.
loc는 레이블 기반 인덱싱을 지원하여 행과 열의 인덱스 이름을 사용하여 데이터에 접근합니다. -
사용 예시:
import pandas as pd
import numpy as np
# 데이터프레임 생성
data = {'col1': [1, 2, 3], 'col2': [4, 5, 6], 'col3': [7, 8, 9]}
df = pd.DataFrame(data, index=['row1', 'row2', 'row3'])
# [] 사용 예시
print(df['col1']) # 'col1' 컬럼 선택
print(df[['col1', 'col2']]) # 'col1', 'col2' 컬럼 선택
# print(df['row1']) # 오류 발생, row 선택은 불가능
# loc 사용 예시
print(df.loc['row1']) # 'row1' 행 선택
print(df.loc[['row1', 'row2']]) # 'row1', 'row2' 행 선택
print(df.loc['row1', 'col1']) # 'row1' 행의 'col1' 값 선택
print(df.loc['row1':'row2', 'col1':'col2']) # 'row1'에서 'row2'까지, 'col1'에서 'col2'까지 슬라이싱3. 새로운 열 추가
df["Score"] = [90, 85, 95]
print(df)# [Out]
ID Name Age Score
0 1 Alice 25 90
1 2 Bob 30 85
2 3 Chalie 35 954. 행 삭제
df = df.drop(1) # 인덱스 1(두 번째 행) 삭제
print(df)# [Out]
ID Name Age Score
0 1 Alice 25 90
2 3 Chalie 35 95DataFrame의 인덱스 조작
- 인덱스를 직접 설정하거나 변경할 수 있음
1. 새로운 인덱스 설정
df.index = ['a', 'b']
print(df)# [Out]
ID Name Age Score
a 1 Alice 25 90
b 3 Chalie 35 952. 인덱스 리셋
df = df.reset_index()
print(df)# [Out]
index ID Name Age Score
0 a 1 Alice 25 90
1 b 3 Chalie 35 95