[인공지능사관학교: 자연어분석A반] JavaScript (2) / Crawling
오전
1교시: JS
프로젝트 정도는 괜찮지만(단위 모듈) 보안 문제가 있음
대규모 서비스에는 적합하지 않은 듯
팀 프로젝트, 개인 공부, 포트폴리오 만들 때는 추천
JavaScript
- 웹 페이지를 동적으로, 프로그래밍적으로 제어하기 위해 고안된 언어
- 웹 개발, 프론트엔드 개발에 가장 특화된 언어
- 백엔드는 자바(JAVA)
- 웹 개발, 프론트엔드 개발에 가장 특화된 언어
웹 페이지 = HTML(뼈대) + CSS(디자인) + javascript(동적 기능)
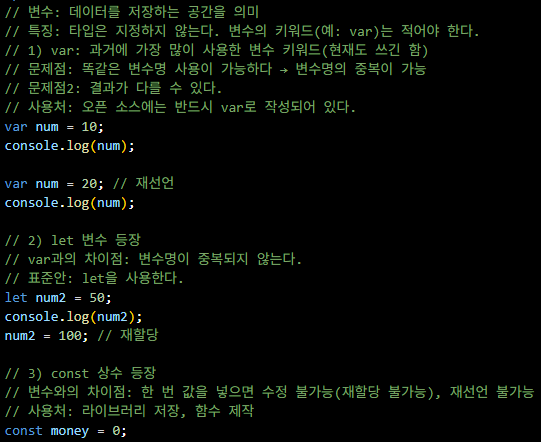
입력과 출력
출력
- JS: 웹 페이지의 기능을 제작할 때 사용하는 언어
- 사용법: 내부 방식으로 작성할 때는
<script>태그를 활용한다.- head 안에 사용
- 라이브러리를 불러올 때
- 외부 방식으로 파일을 불러들일 때
- body 안에 사용
- 코드를 직접 타이핑하거나 어떤 태그를 조작할 때(내부 방식)
- head 안에 사용
- 출력문 3가지
- document: 현재 내가 보고 있는 html 파일의 모든 정보를 담고 있는 객체
- 문서(document)에 안녕하세요 써줘 →
document.write("안녕하세요"); - 모든 html 태그에 접근한다거나 명령어를 내릴 때 document 객체 활용
- 문서(document)에 안녕하세요 써줘 →
- console.log() → 개발자 도구의 콘솔창에 출력하는 방법
- 사용처: 서버와 값을 주고 받는 경우 값을 검증하는 창이 콘솔창
- 실제 가장 많이 사용됨: console → 개발자끼리 소통을 위한 창
- 팁: 개발이 완료되면 콘솔은 다 지운다!!!
- 예시:
console.log("내가 콘솔창에 출력한 글자")
console.error("에러입니다!")
console.warn("경고입니다!")
- alert() → 개발자가 사용자에게 알림 메시지를 보낼 때 사용한다.
alert("안녕하세요!");- 사용처
- 단순 메시지 전송 (도용 방지)
- 사용자의 상태 변화(구매, 취소, 탈퇴 등)
- 사용처
- document: 현재 내가 보고 있는 html 파일의 모든 정보를 담고 있는 객체
입력
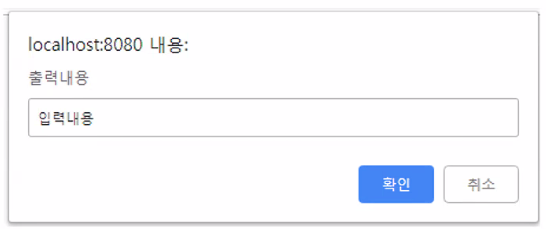
prompt("출력 내용", "입력 내용");- 입력창을 통한 입력문
- 리턴 타입: String
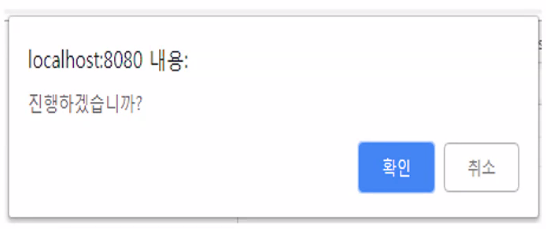
confirm("출력문 작성");- 확인 및 취소를 통한 입력문
- 리턴 타입: boolean
세미콜론의 중요성: 서버로 보낼 때 한 줄로 압축해서 보내니까 찍어서 한 줄이 종료되었음을 항상 알려주는 것이 좋다(자바에서는 필수임)
- 문제점 찾기:
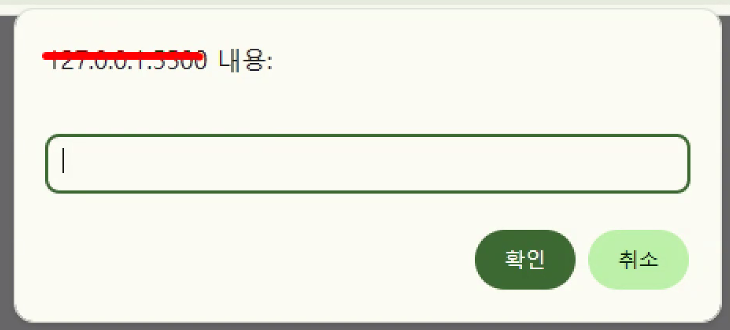
- 무엇을 입력해야 하는지 알려줘야 함 → message
- 첫 번째 매개변수: 사용자에게 알리고자 하는 내용
- 입력 예시를 알려줘야 함 → placeholder
- 두 번째 매개변수: 입력 예시
- 입력문 2가지
- 사용자에게 입력 창을 제공하는 prompt()
- 주의점: 사용자가 입력한 데이터는 문자 형태(String)
prompt("생년월일을 입력하세요.", "ex)6자리로 입력하세요");
- 사용자에게 확인 or 취소를 입력하는 confirm()
- 주의점
- 사용자가 입력할 때 선택지가 두 개라면 대부분 boolean(true or false)
- 데이터에 boolean이 등장하면, 반드시 조건문을 생각하자.
confirm("정말 탈퇴하실 건가요?")
- 주의점
- 사용자에게 입력 창을 제공하는 prompt()
2교시: JS
변수(variable)
- 파이썬, 자바스크립트 vs. 자바, C
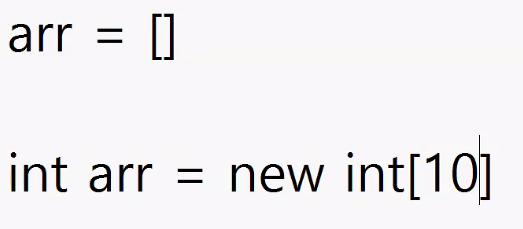
- 최근 등장한 언어들은 입력한 내용에 맞춰서 자동으로 변수 타입과 메모리 크기 자동 설정 → 빠른 개발, 소규모 서비스에 적합
- 자바나 C는 메모리 관리를 효율적으로 하기 위해 변수의 타입과 메모리 크기를 다 미리 지정해 줌 → 대규모 서비스에 적합
- 변수 선언 키워드:
var- 옛날 문법이라서 권장하지는 않음
- variable
- 사전적 의미로는 "변화를 줄 수 있는" 또는 "변할 수 있는 수"
- 프로그래밍에서는 "데이터를 담을 수 있는 공간"
- 변수 선언
- 저장하는 데이터에 따라서 자료형 결정
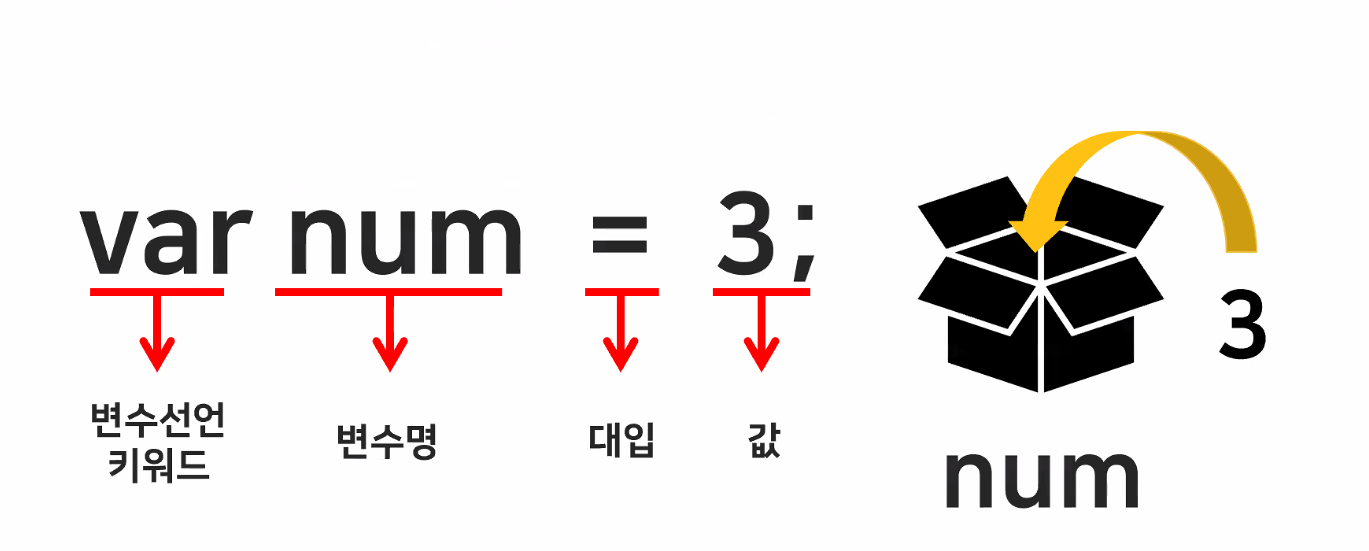
- 저장하는 데이터에 따라서 자료형 결정
-
JAVA vs. Javascript

-
ECMA(European Computer Manufacturers Association)Script6 표준안에서 새로운 변수 키워드 등장:
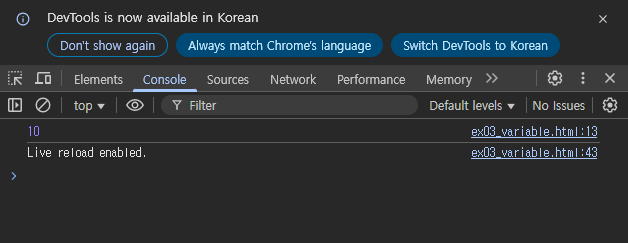
let변수,const상수- let 변수의 특징: 중복을 허용하지 않음
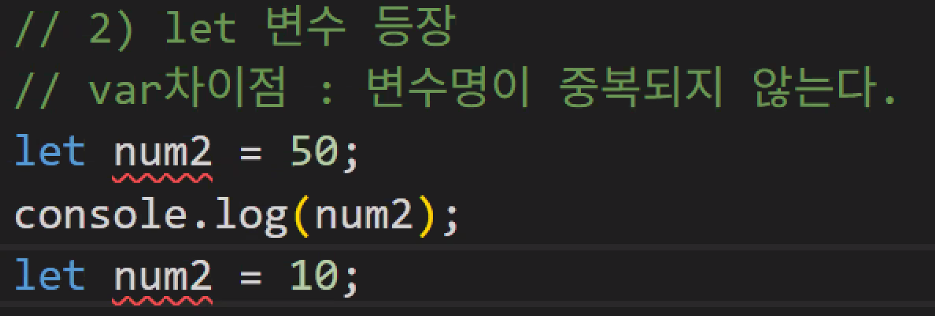
- 중복 사용 시 에러 발생
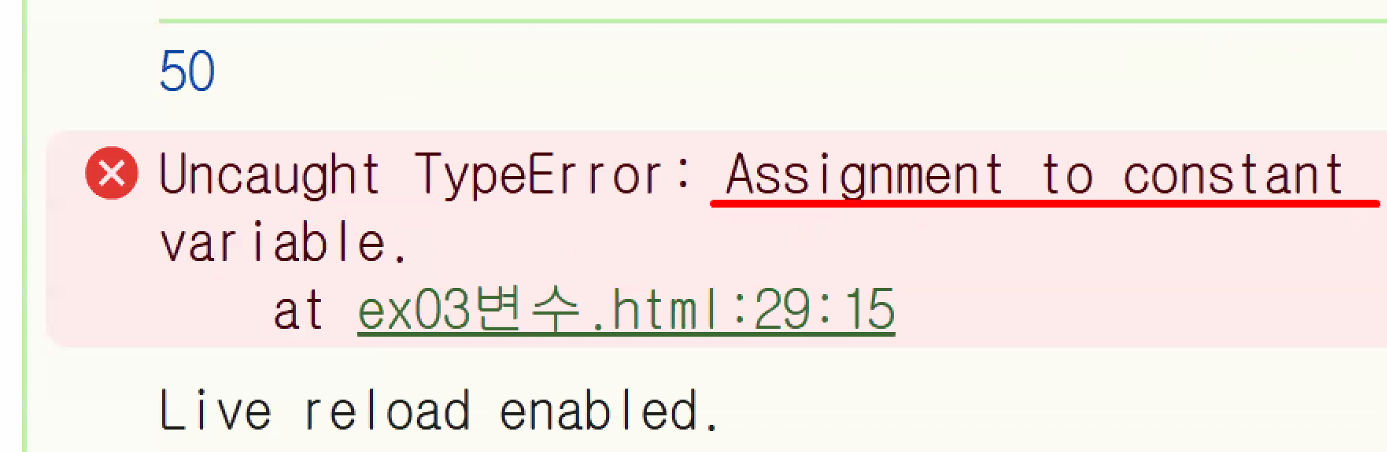
- 중복 사용 시 에러 발생
- const 상수
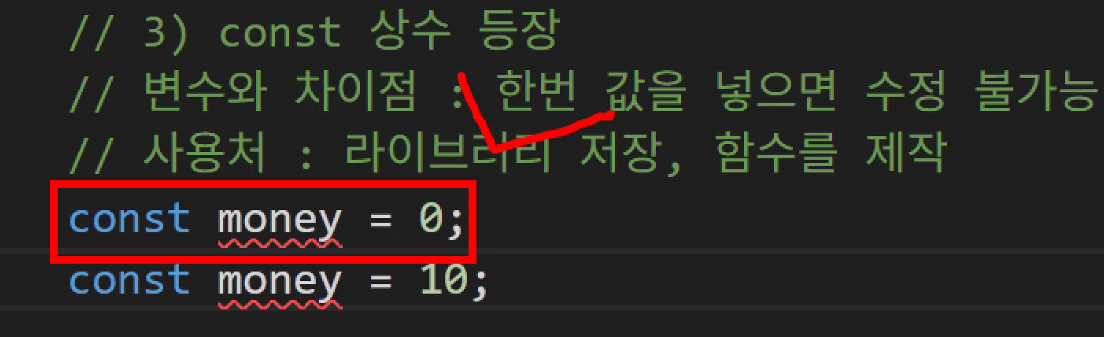
- let 변수의 특징: 중복을 허용하지 않음
- var vs. let vs. const

- 정리
- 개발자 모드로 콘솔창 확인
- 인터프리터 언어의 특징: 한 줄씩 실행
- 정리
실습
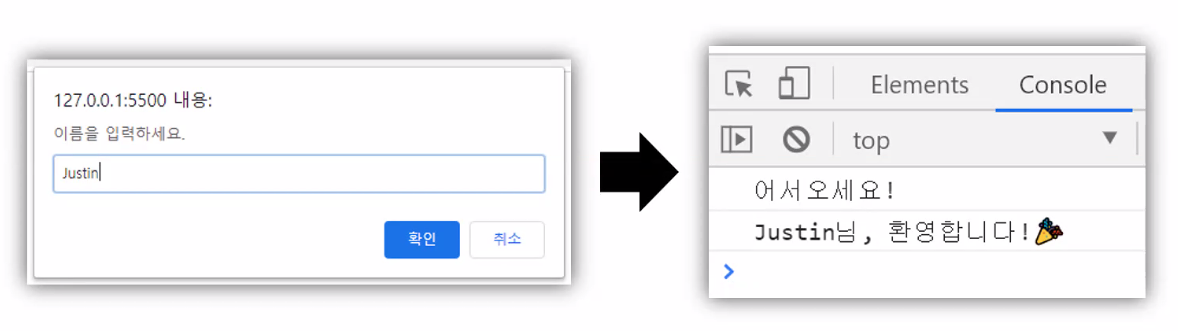
- 사용자가 입력한 값 콘솔에 출력하기
- prompt()
- let
- console.log()
- 실습 목표: 사용자에게 이름을 입력 받고, 입력 받은 값을 콘솔에 출력
- 필요 기능: prompt, let, console.log
- 실습 프로세스
1) 사용자에게 prompt로 값을 입력 받는다.
2) 입력 받은 값을 변수에 저장한다.
3) 변수를 콘솔창에 출력한다.
- 출력 방법 3가지
console.log(name+"님 환영합니다.");
console.log(name, "님 환영합니다.");
console.log(`${name}님 환영합니다.`);3교시
변수와 문자열 섞어서 출력
- 연산자 활용: 문자열 연결 연산자(+)
- 직관적이지만 권장하지 않음
- 쉼표(,)
- 문자열과 변수를 쉼표로 구분하여 나열하면, 문자열은 그대로 출력되고 변수는 해당 변수의 값이 출력됨
- 함수 내에서 여러 인수를 구분하는 역할
- 각 인수는 별도의 값으로 처리되어 출력됩니다.
- 템플릿 리터럴(Template Literals)
- 백틱(`)으로 감싸고, 변수 앞에 ${}를 사용하여 표현
- 가독성이 좋고 더 현대적인 방식
코딩 테스트에서 코딩 스타일을 판별하는 경우가 많으니 최신 문법을 잘 적용할 것
자료형

- undefined와 null에 대해 이해하는 게 중요

- null은 변수에 null이라는 데이터가 할당되어 있지만 undefined는 변수에 값 할당 자체가 안 되어 있음

- null은 변수에 null이라는 데이터가 할당되어 있지만 undefined는 변수에 값 할당 자체가 안 되어 있음
- 데이터 타입 → null vs. undefined
- null → "없다"라는 의미를 가진 데이터를 넣는다 → 메모리에 할당
- e.g., num = null;
- undefined → 아무런 데이터가 없다 → 메모리에 할당 X
- e.g., let num;
- null → "없다"라는 의미를 가진 데이터를 넣는다 → 메모리에 할당
- 팁: 프론트에서 데이터 3개를 요청 → 서버가 DB에서 데이터를 조회 → 프론트에게 값을 전달:
[1, 10, undefined]- 3번째 값이 넘어오지 않았다는 뜻
- 오류 수정법 2가지
- 프론트에서 받는 변수가 없는 경우
- 서버가 값을 2개만 리턴한 경우
- 공통적으로 undefined가 등장하면 데이터의 통신이 잘못됐다고 인식
형변환

- 형변환: 데이터의 타입을 변경하는 방법
- 포인트: 문자를 숫자로 변형하는 방법을 가장 많이 사용한다. → 웹에서 사용자가 입력한 값은 문자
- 비교 연산자: 동등 연산자 vs. 일치 연산자
==: 문자와 숫자를 비교하는 경우에는 숫자를 문자로 자동 형변환===: 타입까지 비교하는 연산자(권장사항)- BUT 대부분의 개발자는 ==를 사용한다고 함
- Number()
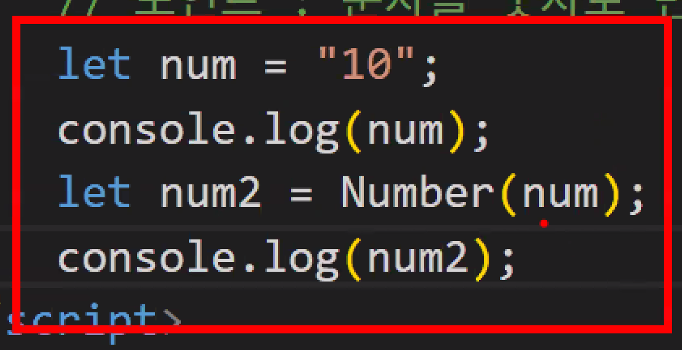
- JS: 관대하지만…😅

- JS가 알아서 자동 형변환을 하기 때문에 생기는 문제
실습: 형변환
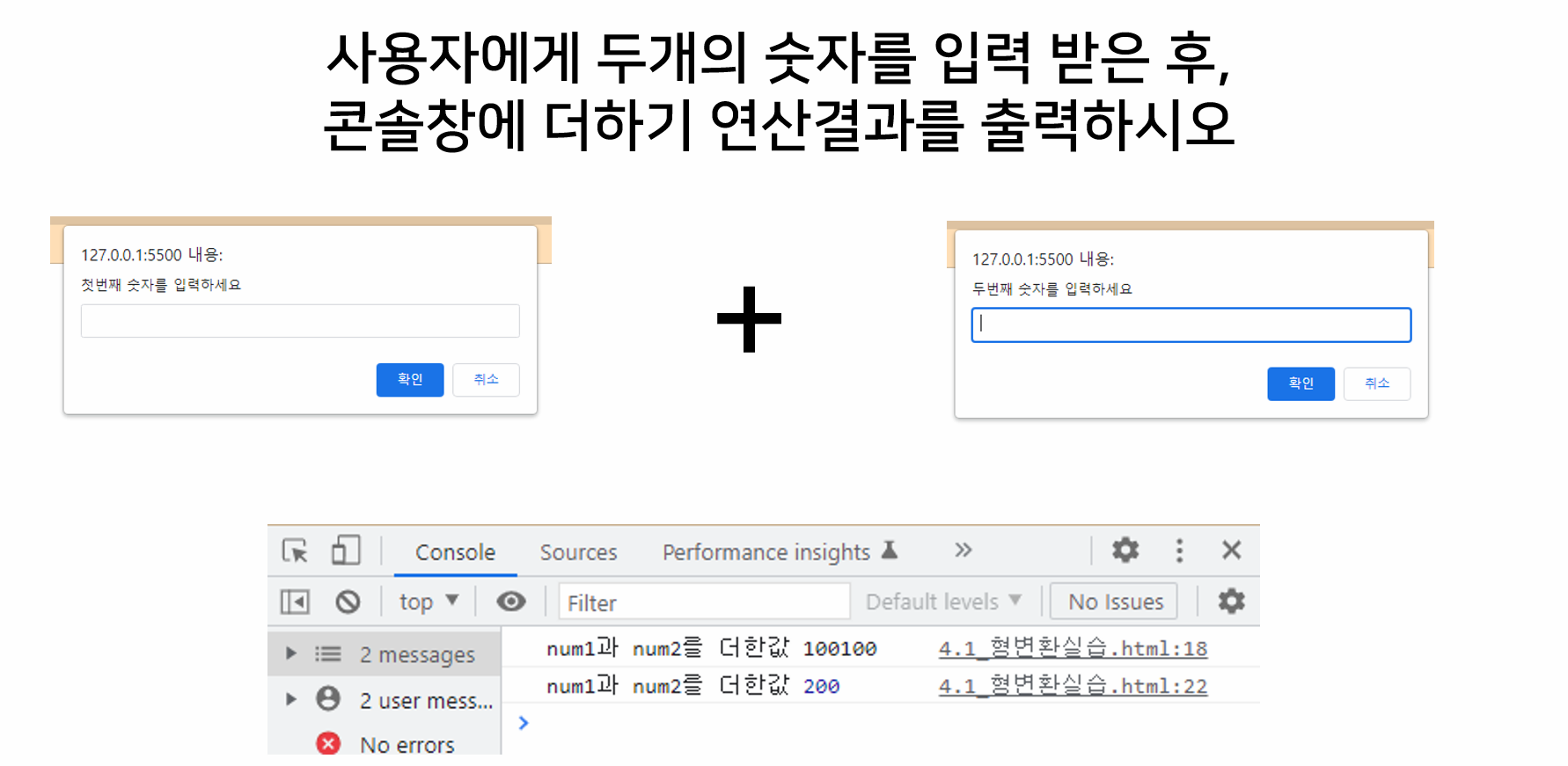
- 실습 목표: 사용자에게 두 개의 숫자를 입력받은 후, 콘솔 창에 더한 값을 출력
- 필요 기능: prompt, let, Number, console.log
- 포인트: 반복하는 코드는 최소화, 변수는 사용할 가치가 있는 효율적인 데이터를 담는 공간 → 변수부터 효율적으로 관리하자!
3가지 스타일
1.
let num1 = prompt("첫 번째 숫자를 입력해 주세요", "예: 42")
let num2 = prompt("두 번째 숫자를 입력해 주세요", "예: 42")
let result = Number(num1) + Number(num2)
console.log(`num1과 num2를 더한 값: ${result}`)→ 단점: 코드 확장성이 좋지 않음. 내가 뭔가를 할 때마다 매번 형변환이 새롭게 됨
let num1 = prompt("첫 번째 숫자를 입력해 주세요", "예: 42")
let num2 = prompt("두 번째 숫자를 입력해 주세요", "예: 42")
console.log(`num1과 num2를 더한 값: ${Number(num1) + Number(num2)}`)→ 단점: 연산을 바꾸면 형변환을 새로 해 주어야 함, 가독성 문제
let num1 = Number(prompt("첫 번째 숫자를 입력해 주세요", "예: 42"))
let num2 = Number(prompt("두 번째 숫자를 입력해 주세요", "예: 42"))
console.log(num1+num2)연산자

== vs. ===
- 비교 연산자
- 동등 연산자
==10 == "10"→ true- 자동으로 자료형 변환
- 일치 연산자
===10 === "10"→ false- 정학히 값과 자료형 비교
- 동등 연산자
오후
4교시: Crawling
학습 목표
- 크롤링이 무엇인지 알 수 있다.
- Requests 라이브러리로 웹 페이지를 가져올 수 있다.
- naver. 페이지를 가져올 수 있다.
Crawling이란?
- Crawl → "기어가다"라는 의미
- Web 상에 존재하는 contents를 수집하는 작업
- Web 페이지를 그대로 가져와서 데이터를 추출해내는 행위
왜 Python일까?
- 직관적인 언어
- 읽고 쓰기가 쉽다
- 인터프리터 언어
- 한줄한줄 처리해주는 장점
빅데이터란?
- 디지털 환경에서 생성되는 수치, 문자, 이미지, 영상 데이터 모두를 포함하는 대규모 데이터
- 5V: 3V였는데 두 개 늘었음(더 넓게 7V까지 이야기하기도 한다)
- 규모(Volume)
- 속도(Velocity)
- 다양성(Variety)
- 정확성(Varacity)
- 가치(Value)
수집 데이터의 형태
- 정형 데이터
- 데이터베이스(DB)
- 스프레드시트,csv
- 형태가 명확히 정해져 있고 모든 데이터가 해당 형태를 따름
- 반정형 데이터
- html, xml
- 형태가 정해져 있긴 한데 자유도가 있어서 데이터마다 조금씩 다른 모양을 가짐(큰 틀은 있는데 내용이 다양)
- 비정형 데이터
- 사진, 음성, 음악, 영상
Client와 Server
- Client
- 클릭한 페이지를 요청하는 PC
- 네트워크로 연결된 서버로부터 정보를 제공받는 컴퓨터
- Server
- 클릭된 페이지를 제공하는 PC
- 클라이언트에게 네트워크를 통해 서비스를 제공하는 컴퓨터
- 요청(requests)과 응답(response)
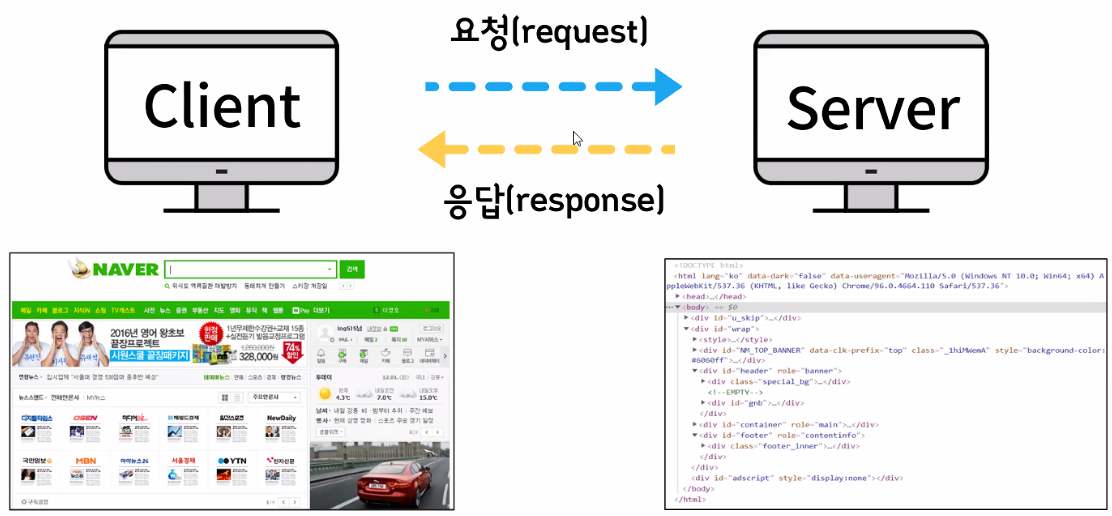
- 웹 브라우저(크롬, 엣지, 사파리, 파이어폭스 등)를 통해서 사이트 확인
URL
- Uniform Resource Locator
- 웹 문서의 수많은 서비스를 제공하는 서버들에 있는 파일의 위치를 표시하는 표준 주소 == 인터넷 주소
Requests 라이브러리
- 접근할 웹 페이지의 데이터를 요청/응답 받기 위한 라이브러리
실습 준비
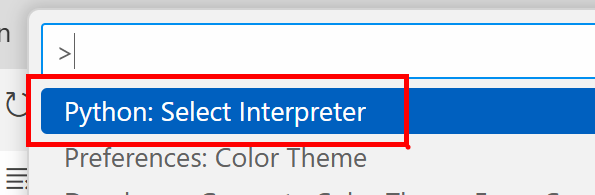
- python 설치하기
- vscode에서 .ipynb 파일 만들기
- extensions에서 Python 설치하기
- ctrl+shift+p → Python:Select Interpreter → 설치한 파이썬과 맞는 인터프리터 선택
- kernel 연결하고
print("hello")실행해보기- 아래와 같은 창이 뜨면 install 하기
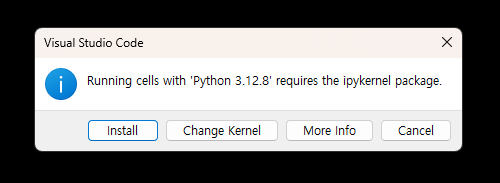
- 아래와 같은 창이 뜨면 install 하기
requests 라이브러리 실습
- 웹 페이지의 데이터를 요청/응답 받기 위한 라이브러리
- 웹 브라우저의 역할을 대신해 서버에 데이터를 요청함
%pip install requests
Jupyter Notebook에서
%pip install -q requests명령의%는 "매직 커맨드(magic command)"입니다. 매직 커맨드는 주피터 노트북이나 IPython 환경에서 사용하는 특별한 명령어로, 보통 한 줄이나 셀 단위로 파이썬 생태계 외의 작업을 수행하게 해줍니다.%pip는 주피터/아이파이썬에서 파이썬 커널을 제대로 인식해 패키지 설치에 혼란이 없도록 도와줍니다.
반면에, VSCode의 일반 터미널(명령 프롬프트, bash 등)에서는 매직 커맨드가 동작하지 않습니다. 일반 콘솔에서는!pip install -q requests또는pip install requests처럼 사용해야 합니다. 여기서!는 "셀에서 터미널 명령어 실행"을 의미하는 아이피썬/주피터식 방식이고, 실제 터미널에서는 아무런 의미가 없습니다. VSCode의 Python Interactive나 일반 터미널에서는 그냥pip install requests를 입력해야 합니다.
%pip ...: 주피터/아이피썬에서만 동작하는 매직 커맨드.!pip ...: 주피터에서 "터미널 명령어 실행" 용도로, 터미널에서는 사용하지 않음.pip ...: 일반 터미널, 커맨드 프롬프트, VSCode 터미널에서 사용하는 표준 명령.- 정리:
%는 주피터 용 특별 명령이므로 일반 콘솔에선 인식되지 않습니다.- VSCode 터미널에서
!pip install ...은 동작하지 않으니,pip install ...만 입력해야 정상 설치가 됩니다.
import requests as req
# 네이버 페이지 정보 가져오기
# url: 웹 페이지의 표준 구조
res = req.get("http://www.naver.com/")
res<Response [200]>requests.get("url")
Response [200]: 페이지의 정보를 잘 입력 받아 응답했다는 뜻Response [400]: client 단에서 문제가 발생했을 경우(request, 요청 과정에서 문제 발생)Response [500]: server 단에서 문제가 발생했을 경우(response, 응답 과정에서 문제 발생)- 웹 페이지의 요소 정보
- requests.get("url").text: 문자열 형태로 웹 페이지의 요소 정보 출력
## 5교시 ### requests 라이브러리 실습 #### 통신의 기초 요청과 응답 - Client: 내가 사용하고 있는 컴퓨터 (요청, request) - Server: HTML 정보를 가지고 있는 컴퓨터 (응답, response)
requests 라이브러리
- 웹 브라우저의 역할을 대신해 서버에 데이터를 요청함
- 웹 페이지에서 데이터를 요청하고 응답받는 데 사용하는 라이브러리
- requests 라이브러리를 통해 정보를 받음
- 우리가 확인하고 알아야 할 문제!
- res.text의 결과 → 데이터 타입: 문자열
- 컴퓨터가 인식하기에 HTML 태그가 아님
- 변환 작업 필요: 문자열 → HTML 문자화(parsing)
- beautifulsoup 라이브러리를 활용하여 응답 받은 데이터(문자열)를 html 형태로 변환(파싱)
- res.text의 결과 → 데이터 타입: 문자열
beautifulsoup 라이브러리
- lxml 설치 후 재실행 필요함
# beautifulsoup 라이브러리 설치
%pip install -q beautifulsoup4
%pip install -q lxml
# lxml: 파싱 도구# 문자열 형태의 응답 데이터를 html 문서화 → 파싱
from bs4 import BeautifulSoup as bs
# bs(변경할 데이터, 파싱 방법)
soup = bs(res.text, "lxml")
# html 태그 정보
soup- 네이버 검색 후 페이지의 정보 받아오기
url_src = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EB%8F%99%EB%AA%85%EB%8F%99+%EB%A7%9B%EC%A7%91&ackey=5ybg8oxt"
get_naver = req.get(url_src)
soup_naver = bs(get_naver.text, "lxml")- soup_naver가 가지고 있는 것은 요청한 페이지의 html 정보
- soup_naver에게 특정 정보 달라고 요청하기!
soup.select("태그")

soup_naver.select('a')- 모든 a 태그를 가져온다
- 크롤링에서는 내가 원하는 명확한 데이터를 추출하는 것이 가장 중요
- 모든 a 태그를 가져온다
- 제한을 둬 내가 원하는 컨텐츠 출력 → '선택자' 활용
- 선택자를 활용하여 특정 태그를 지정 → ID 선택자(#), class 선택자(.)
soup_naver.select("a.tab")- class 이름이 tab인 a 태그를 추출하라는 뜻
- 컨텐츠 추출
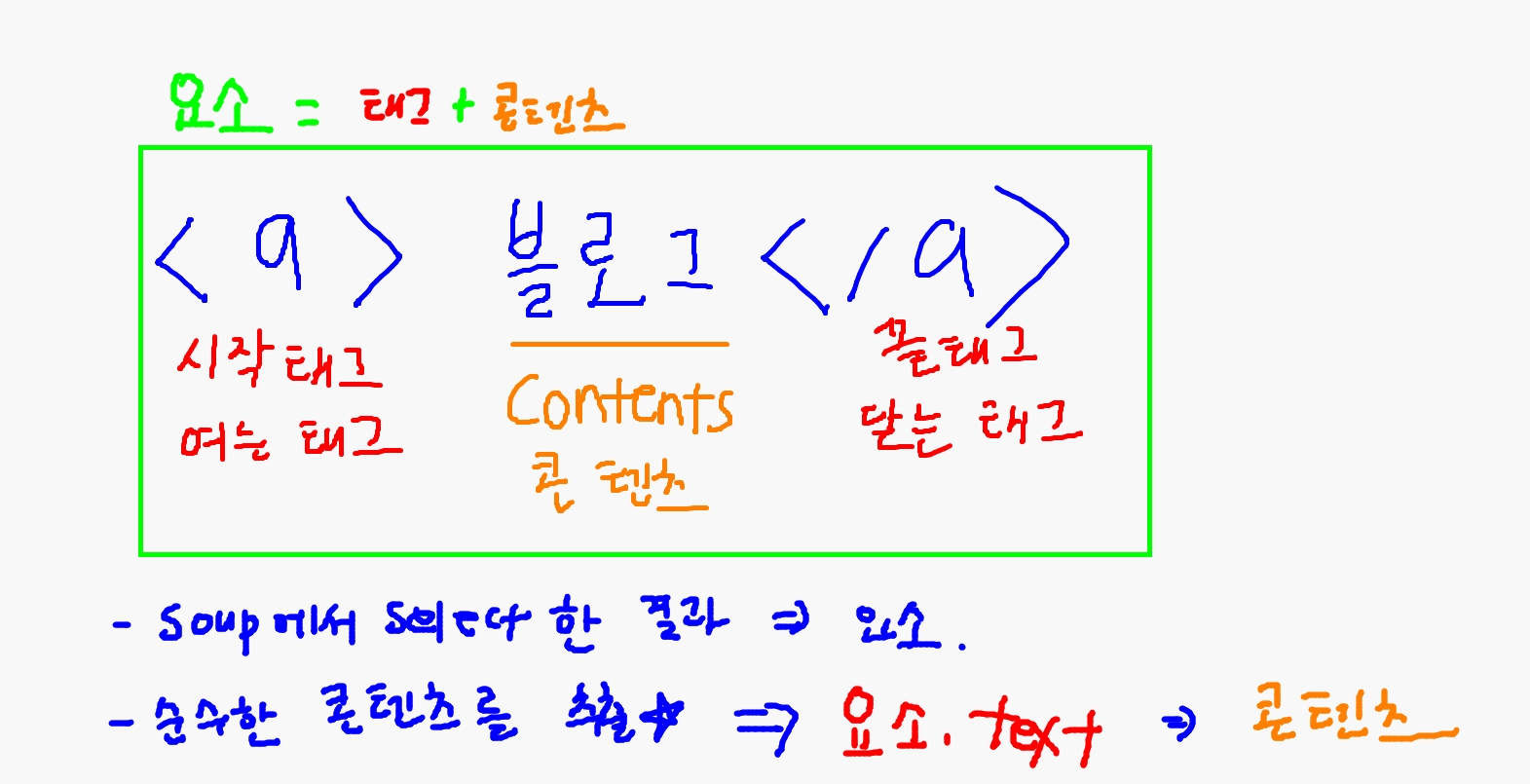
- 태그 정보에서 순수한 글자만 가져오기
- 해당 조건에 걸리는 모든 태그를 추출: .select → list 형태로 추출됨!
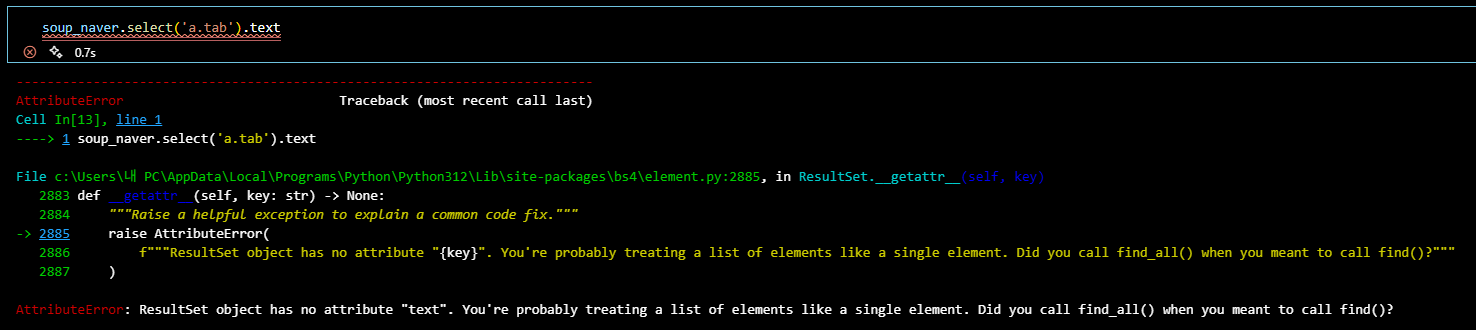
→ .select 한 거에 바로 .text 하면 오류 (값이 요소가 아닌 리스트이기 때문) 요소.text→ contents만 추출- 따라서 list에서 1개의 요소를 추출 후에 .text (인덱싱)
- 해당 조건에 걸리는 모든 태그를 추출: .select → list 형태로 추출됨!
- 태그 정보에서 순수한 글자만 가져오기
soup_naver.select("a.tab")[0].text'블로그'- select_one
- 모든 태그의 가장 첫 번째 요소만 추출
- cf. select: 모든 요소를 추출 → 리스트 형태로 추출
- id 태그 사용 시
- 첫 번째 요소만 필요할 때 사용함
- 모든 태그의 가장 첫 번째 요소만 추출
soup_naver.select_one("a.tab").text'블로그'data = soup_naver.select("a.tab")
# 텍스트 형태로 모든 태그들을 추출 → 반복문
for i in data:
print(i.text)블로그
카페
이미지
지식iN
인플루언서
동영상
쇼핑
뉴스
숏텐츠
어학사전
지도
도서
지식백과
학술정보
전체
블로그
카페
이미지
지식iN
인플루언서
동영상
쇼핑
뉴스
숏텐츠
어학사전
지도
도서
지식백과
학술정보실습
- 네이버 온도 페이지에서 현재 온도 추출하기
weather_url = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EB%82%A0%EC%94%A8&ackey=przzv2x9"
weather_req = req.get(weather_url)
soup_weather = bs(weather_req.text, "lxml")
soup_weather.select("div.temperature_text")[<div class="temperature_text"> <strong><span class="blind">현재 온도</span>33.3<span class="celsius">°</span></strong> </div>,
<div class="temperature_text"> <strong><span class="blind">예측 온도</span>25<span class="celsius">°</span></strong> </div>,
<div class="temperature_text"> <strong><span class="blind">예측 온도</span>33<span class="celsius">°</span></strong> </div>,
<div class="temperature_text"> <strong><span class="blind">예측 온도</span>25<span class="celsius">°</span></strong> </div>,
<div class="temperature_text"> <strong><span class="blind">예측 온도</span>33<span class="celsius">°</span></strong> </div>]temperature = soup_weather.select_one("div.temperature_text").text
temperature' 현재 온도33.3° 'strong 태그에 접근해 바로 글자 가져오는 방법 알아보기
6교시
실습: 현재 온도 추출하기
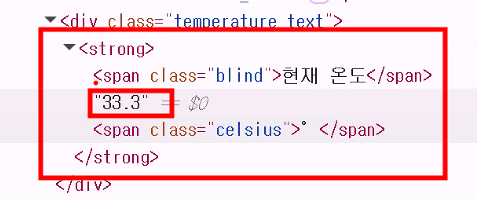
<Response [200]>꼭 확인한 뒤에 변수에 넣기!
url = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EB%82%A0%EC%94%A8&ackey=przzv2x9"
req.get(url)<Response [200]>- 내가 가져기고 싶은 contexts와 가장 가까운 태그부터 시작하기
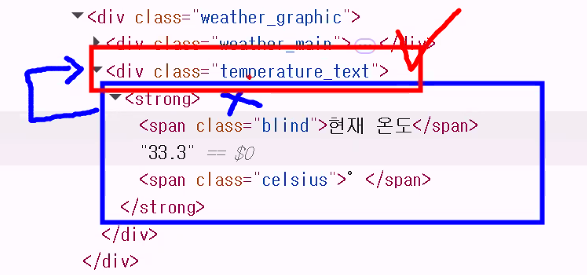
- strong은 너무 많은데요… → 관계 활용: 부모 태그를 찾자
res = req.get(url)
soup = bs(res.text, "lxml")
soup.select("strong")
soup.select("div.temperature_text>strong")[0].text'현재 온도34.7°'- 순수 온도 정보만 추출하고 싶은 경우: span 태그 없애기
# 순수 온도 정보만 추출
t = soup.select("div.temperature_text>strong")[0]
# 추출하여 제거하고 싶은 태그 정보를 가져온다
e = soup.select("span.blind")[3]
e.extract()<span class="blind">현재 온도</span># 온도와 symbol만 남은 것을 확인
t.text'34.7°'실습: 뉴스 데이터 수집
- ZDNET에서 뉴스 제목 가져오기
- 네이버 뉴스는 보안이 강해져서 requests로 가져오기 힘듦
import requests as req # 웹 페이지 정보를 요청/응답받는 라이브러리
from bs4 import BeautifulSoup as bs # 응답 받은 데이터를 html화(parsing)
# 웹 페이지 정보 받아오기
url_news = "https://zdnet.co.kr/news/?lstcode=0000&page=1"
req.get(url_news)<Response [200]>req_news = req.get(url_news)
# 데이터 변환하기
soup_news = bs(req_news.text, "lxml")
# 뉴스 제목 추출하기
data = soup_news.select("div.assetText h3")
# 텍스트 형태로 모든 태그들을 추출 → 반복문
for i in data:
print(i.text)"AI 에이전트 지원"…오라클, 구글 '제미나이 2.5' OCI에 탑재
KCA, ESG 실행과제 검토...8월 중 추진계획 수립
웹케시, 2분기 영업익 8.3%↓…하반기 수익성 회복 총력
쿠콘, 2Q 영업이익 6.3%↑…데이터·페이 균형 성장에 신사업 '가속'
'AI 퍼스트' 외쳤다 낭패 본 美 기업, 싸늘한 여론에 CEO "인력 대체 의미 아냐"
이은우 KAIST 감사 "과학문화 활동비 1% 의무화 해야"
KT노사, 임금 3% 인상안 잠정합의
파마리서치바이오, 보툴리눔 톡신 '리엔톡' 태국 품목허가 획득
저커버그의 'AGI 집착'…메타, 내부 불만 커지는 조직 재편
온코닉테라퓨틱스 '자큐보', 中 임상 3상 성공 및 품목 허가 신청
정부, AI 연구에 GPU 1천장 푼다…삼성SDS·KT클라우드·엘리스 선정
[ZD 위클리 코인] UBCI 4.61% 하락…알트코인 7.85%↓
포티넷, '포티레콘' 대규모 업그레이드…위협 노출 관리·대응 강화
차백신연구소, 대표이사에 한성일 부사장 내정
무보·하나은행·현대차, 자동차 부품 기업 금융지원…美 관세 대응
中 투자 감소·수출 규제 여파…반도체 장비社도 골머리
길리어드, CAR-T 세포치료제 '예스카타' 국내 허가
케이뱅크, 가상자산 법인계좌 100좌 돌파…작년 대비 2배 이상 늘어
현대판 노아의 방주?…쥐 75마리, 우주에 간다 [우주로 간다]
[부음] 이민재 이투데이 기자 본인상크롤링에서 가장 중요한 건 "필요한 정보만" 가져오는 것!
※ 주의:soup_news.select("h3")으로 하면 뉴스 제목이 아닌 h3도 같이 추출됨
- 이시각 헤드라인
- ZDNet Power Center
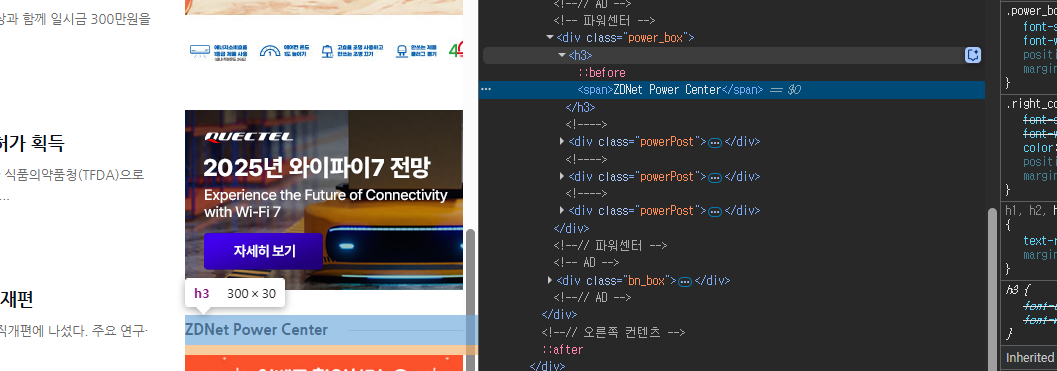
데이터 확장하기
- 타이틀과 함께 원문의 링크까지 추출
- 링크는 a 태그에 함께 들어가 있음
- href 속성 → 속성은 어떻게 추출할끼?
- 속성 추출 방법
soup_news.select("div.assetText>a")[0]<a href="/view/?no=20250818150244">
<h3>LG전자, MS사업본부 50세 이상 직원 희망퇴직 실시</h3>
<p>LG전자가 50대 이상 직원 및 최근 3년간 성과가 낮은 직원을 대상으로 희망퇴직 신청을 받고 있다. 18일 업계에 따르면 LG전자는 TV 사업을 담당하는 MS사업본부 구성원 ...</p>
</a># 속성 추출 방법
soup_news.select("div.assetText>a")[0]["href"]'/view/?no=20250818150244'- 속성 추출 방법:
요소["속성명"]- 뉴스 링크 → href 속성을 통해 추출: 수집 경로가 "상대 경로"
- 누구나 접속 가능한 서버의 주소가 필요: "절대 경로"
- 절대 경로 + 상태 경로 → 전체 인터넷 주소
\"https://zdnet.co.kr"+soup_news.select("div.assetText>a")[0]["href"]'https://zdnet.co.kr/view/?no=20250818150244'# 반복문을 통해 전체 뉴스 링크 수집
a_list = soup_news.select("div.assetText>a")
url_list = []
for i in range(len(a_list)):
url_list.append("https://zdnet.co.kr"+a_list[i]["href"])
url_list['https://zdnet.co.kr/view/?no=20250818150244',
'https://zdnet.co.kr/view/?no=20250818153419',
'https://zdnet.co.kr/view/?no=20250818153227',
'https://zdnet.co.kr/view/?no=20250818145716',
'https://zdnet.co.kr/view/?no=20250818150649',
'https://zdnet.co.kr/view/?no=20250818152949',
'https://zdnet.co.kr/view/?no=20250818152403',
'https://zdnet.co.kr/view/?no=20250818151448',
'https://zdnet.co.kr/view/?no=20250818151834',
'https://zdnet.co.kr/view/?no=20250818151804',
'https://zdnet.co.kr/view/?no=20250818145640',
'https://zdnet.co.kr/view/?no=20250818144836',
'https://zdnet.co.kr/view/?no=20250818150843',
'https://zdnet.co.kr/view/?no=20250818150837',
'https://zdnet.co.kr/view/?no=20250818150018',
'https://zdnet.co.kr/view/?no=20250818145133',
'https://zdnet.co.kr/view/?no=20250818144808',
'https://zdnet.co.kr/view/?no=20250818144431',
'https://zdnet.co.kr/view/?no=20250818143843',
'https://zdnet.co.kr/view/?no=20250818143407',
'https://zdnet.co.kr/view/?no=20250818143843',
'https://zdnet.co.kr/view/?no=20250818101120',
'https://zdnet.co.kr/view/?no=20250818105408',
'https://zdnet.co.kr/view/?no=20250817225838']7, 8교시: 미니 프로젝트
하루 돌아보기
👍 잘한 점
- 맞춤법 모델을 이용해 틀린 문장 생성 모델 & 맞춤법 모델 파인튜닝까지 잘 했음
- 오늘 학습한 내용 복습 바로바로 함
👎 아쉬웠던 점
- 생각해보니까 맞춤법 퀴즈는 굳이 딥려닝을 쓰지 않고 구축한 데이터베이스만으로도 구현 가능한 거라서 뭔가 프로젝트로 내세우기에는 자연어 분석이나 딥러닝 관련해 인상깊은 모습을 보여줄 수 없을 것 같아서 아쉽
- 맞춤법 모델을 더 보완하는 건?
- 근데 논문 읽어봤는데 기간 안에 하긴 어려울 것 같음
🔬 개선점
- 다른 분들 모델 사용해서 남은 기간 열심히 해보자
