[인공지능사관학교: 자연어분석A반] JavaScript (3) / Crawling (2)
오전
1교시: JS
지난 시간 복습
- ECMASript 2015(ES6)
- ECMAScript는 프로그래밍 언어 JavaScript의 표준 명세
- 자바스크립트의 혁명이라 할 수 있는 문법이라고 함
- 이후에도 자바스크립트 최신 문법이 추가되고 있음
- ECMAScript 2015 이후 버전 기준 매년 6월마다 새 버전이 발표된다고
- 변수
- 데이터를 담을 수 있는 공간
- 파이썬 변수 스타일과 동일
- 앞에 변수 키워드를 작성해야 한다는 게 python과의 차이점
- 변수 키워드: var, let, const

- var: ECMASript6 이전 키워드 → 재선언이 가능해 협업 중 변수 관리에 어려움이 있었음
- let:
- 자료형
- 형변환
- 연산자
조건문
- 자바 조건문과 같음
- 포인트: if, else if, else → 공간을 할당할 때는 {}를 통해서 영역을 구분
let num = 10;
if (num>10) {
console.log("큽니다.");
} else if (num<10) {
console.log("작습니다.");
} else {
console.log("같습니다.");
}반복문
- 자바 반복문과 거의 똑같음
- 차이점 딱 하나: 자바스크립트에서는 변수 키워드를 넣는데 자바에서는 타입을 지정한다! →
int i = 0;
- 차이점 딱 하나: 자바스크립트에서는 변수 키워드를 넣는데 자바에서는 타입을 지정한다! →
// PYTHON for i in range(0,10,1):
for (let i = 0; i < 10; i++){
console.log("반복문")
}
// PYTHON while True:
while (true) {
break;
}배열 ★★★
- Python list와 dictionary로 생각해보기
- 언제 list를 쓰고 dictionary를 쓸까?
list = ["정형", "광주", "골프"]
dict = {
"이름": "정형"
, "지역": "광주"
, "취미": "골프"
}
data = {
"제목": ["book1", "book2", ...] # list
, "발행연도": [2011, 1999, ...]
}list[0],dict["이름"]에 모두 "정형"이라는 값이 담겨 있지만
- 배열: 같은 의미의 데이터를 관리하는 공간
- 데이터를 조회할 때 인덱스 번호를 활용
- 인덱스는 0부터 시작
- 객체: 다른 의미의 데이터를 관리하는 공간
let name = ["정형", "최영화", "박병관"];2교시: JS
배열의 길이: .length
- 배열의 길이 활용법
- 반복문의 범위를 지정할 때
- 데이터의 유무 검증
- 배열의 길이가 0이라면 데이터가 없다 → 잘못 요청한 건지 실제로 데이터가 없는지 추가 확인 필요
배열 관련 함수
단순 값 변경 (삭제, 삽입)
- 배열의 맨 마지막 인덱스에 값을 넣는 함수: push
name.push("양하영");
- 배열의 맨 마지막 인덱스의 값을 빼는 함수: pop
let data = name.pop();
- 배열의 맨 앞 인덱스의 값을 넣는 함수: unshift
name.unshift("서현수");
- 배열의 맨 앞 인덱스의 값을 빼는 함수: shift
let data2 = name.shift();
push, shift는 꼭 기억하기
값 조회
- 특정 값의 포함 여부를 검증: includes
- 특징: boolean 형의 데이터가 return → 조건문과 연관지어 생각하자
name.includes("최영화");
반복을 활용한 배열 함수 두 가지
forEach: 배열 전용 for문array.forEach((item,index)=>{})← arrow function 사용

map: 원본 배열을 복제해서 새로운 배열을 만들 때 사용- 특징: 반드시 return이 필요
PYTHON으로 다시 생각해보기:
arr=[1,2,3]에서
for i in range(len(arr)):가 기존 for 문(for(let i=0; i<pizza.length; i++))이라면
→ 인덱스 활용
forEach는for i in arr과 같음
→ 값을 그대로 넣어서 활용
추가: 자바스크립트 화살표 함수
- 화살표 함수(Arrow function)라는 용어는 화살표 함수 표현식(Arrow function expressions)이라고도 함
- ECMAScript 6(ES6)에서 도입
- ES6는 2015년에 발행된 ECMAScript 표준의 여섯 번째 버전으로, 다양한 기능과 개선 사항을 포함하고 있음
- 자바스크립트에서 사용하던 기존의 함수 선언식이나 함수 표현식보다 좀 더 간결하며, 쉽게 사용하기 위해 고안됨
- C++, Python, Java 등 다양한 언어에서 사용하는 람다 함수(lambda function)의 아이디어를 자바스크립트 문법으로 표현
- 함수형 프로그래밍 스타일을 더욱 강화하고, 코드를 더 간결하고 가독성 좋게 작성 가능해짐
- 제한점
- this, arguments나 super에 대한 자체 바인딩이 없고, 메서드로 사용해서는 안 됨
- new.target키워드가 없음
- 일반적으로 스코프를 지정할 때 사용하는 call(), apply(), bind() 메서드를 이용할 수 없음
- 생성자 함수로 사용할 수 없음
- yield를 화살표 함수 내부에서 사용할 수 없음
- 자바스크립트에서 화살표 함수는 함수를 변수에 할당하여 사용하는 함수 표현식의 한 유형입니다. 함수 선언식으로는 정의할 수 없음
// JavaScript - 일반 함수 선언식
function add(a, b) {
return a + b;
};
add(1, 2); // 3
// JavaScript - 일반 함수 표현식
const add = function(a, b) {
return a + b;
};
add(1, 2); // 3
// JavaScript - 화살표 함수
const add = (a, b) => {
return a + b;
};
add(1, 2); // 3- 화살표 함수만의 특별한 구문
- 하나의 매개변수인 경우 소괄호 () 를 생략할 수 있습니다.
- 함수 내부가 단일 표현식(single expression)인 경우 return 키워드를 생략할 수 있습니다. return 키워드를 생략할 경우 중괄호 {} 는 반드시 생략해야 합니다.
- 중복된 매개변수 이름을 선언할 수 없습니다.
3교시
배열
반복을 활용한 배열 함수: map
- map 함수는 하나씩 조작해서 새롭게 만듦
조건을 활용한 배열 함수 → 조건문 + 반복문
배열 중요 POINT
배열: 같은 의미를 가진 데이터를 관리하는 공간✨
배열의 맨 마지막 인덱스에 값을 넣는 함수: push✨
배열의 맨 앞의 인덱스의 값을 빼는 함수: shift✨
forEach: 원본 데이터를 조작해서 반복하는 로직을 작성할 때 사용 → 반복문의 대체품✨
map: 원본 데이터를 활용해서 새로운 배열을 만들 때 사용✨
filter: 원본 데이터를 활용해서 새로운 배열을 만드는데, 조건을 추가해서 만들 때 사용✨
객체
추가: 자바스크립트 호이스팅(Hoisting)
- 변수 및 함수 선언이 해당 스코프의 최상단으로 끌어올려지는 것처럼 보이는 현상
- Hoist는 직역하면 들어(끌어)올리다 라는 뜻
- 함수 안에 있는 선언들을 모두 끌어올려서 해당 함수 유효 범위의 최상단에 선언하는 것
- 선언문이 코드 어디에 위치하든, 인터프리터가 실행 전에 해당 변수나 함수를 해당 스코프의 최상단으로 "이동"시켜 처리하는 것처럼 동작
- 기본 원리
- 변수 호이스팅
- var로 선언된 변수는 초기화 (할당)는 해당 위치에서 이루어지지만, 선언 자체는 해당 스코프의 최상단으로 끌어올려집니다.
- let과 const로 선언된 변수는 호이스팅 되지만, 선언과 초기화 사이의 구간 (TDZ, Temporal Dead Zone)에서는 접근이 불가능합니다.
- 함수 호이스팅
- 함수 선언문 (
function myFunction() { ... }) 전체가 호이스팅 됩니다. 즉, 함수를 선언하기 전에도 함수를 호출할 수 있습니다. - 함수 표현식 (
const myFunction = function() { ... })은 변수와 동일하게 처리되어 선언만 호이스팅 됩니다.
- 함수 선언문 (
- 변수 호이스팅
- 예시:
console.log(x); // 결과: undefined (변수 호이스팅)
var x = 10;
console.log(y); // 결과: ReferenceError: Cannot access 'y' before initialization (let 호이스팅)
let y = 20;
myFunction(); // 결과: "Hello" (함수 호이스팅)
function myFunction() {
console.log("Hello");
}
anotherFunction(); // 결과: TypeError: anotherFunction is not a function (함수 표현식 호이스팅)
const anotherFunction = function() {
console.log("World");
}- 주의 사항
- 호이스팅은 코드가 실행되기 전에 발생하는 현상으로, 코드의 흐름과는 다소 차이가 있을 수 있습니다.
- let과 const는 var보다 안전한 변수 선언 방식이며, TDZ를 통해 예상치 못한 오류를 방지할 수 있습니다.
- 호이스팅을 이해하고 사용하면 코드의 가독성을 높이고 예상치 못한 오류를 방지할 수 있습니다.
- 호이스팅 더 알아보기
자바스크립트의 "호이스팅(Hoisting)"은 함수나 변수의 선언부가 실행 시점보다 코드 상단으로 끌어올려지는 것처럼 동작하는 현상입니다. 즉, 코드가 실제로는 순서대로 작성되어 있어도 자바스크립트 엔진이 실행 전에 먼저 선언을 처리하기 때문에, 아래와 같은 코드가 동작합니다. 즉, 변수나 함수를 선언하기 전에 사용해도 에러가 발생하지 않고, undefined 값을 가지거나 초기화되지 않은 상태로 사용됩니다.
console.log(hi); // undefined var hi = 'hello';이 코드에서는 선언(var hi)이 코드의 맨 위로 끌어올려져(undefined로 초기화됨) 있어서 오류가 나지 않습니다. let, const는 이와 달리 "TDZ(Temporal Dead Zone)"에 걸리기 때문에, 선언 전에 참조하면 에러가 납니다.
반면, 파이썬은 이런 호이스팅 개념이 없습니다. 파이썬에서 아래와 같이 변수 선언 전에 사용하면 일반적으로 NameError가 발생합니다.print(a) # NameError a = 10파이썬에서는 변수나 함수를 선언하기 전에 사용하면 NameError가 발생합니다. 파이썬은 코드를 실행하기 전에 미리 선언된 변수나 함수를 "끌어올리는" 대신, 코드가 실행되는 순서대로 변수와 함수를 처리합니다.
- 혼동되기 쉬운 파이썬의 인터프리터 동작
- 파이썬에는 호이스팅과 유사한 현상이 일부 발생할 수 있지만, 이는 호이스팅이라기보다는 인터프리터의 동작 방식과 관련이 있습니다.
- 파이썬의 "호이스팅과 유사한 현상"은 실제로 호이스팅이 아니라, 파이썬 인터프리터가 전체 블록(함수, 클래스 등)을 한 번에 읽고 난 다음에 실행을 시작하는 동작 방식과 관련이 있습니다.
- 예를 들어, 파이썬 클래스 정의 안에서는 클래스 변수나 메서드가 클래스 정의가 끝나고 나서야 쓸 수 있습니다.
- 클래스 정의 내에서 클래스 변수를 사용할 때, 클래스 정의 전체가 로드된 후에야 변수에 접근할 수 있습니다. 그러나 이는 호이스팅과는 다릅니다
- 즉, 파이썬은 코드가 위→아래로 한 줄씩 실행된다는 점에서 명확하게 자바스크립트와 다릅니다. 따라서 파이썬에는 자바스크립트의 "호이스팅"과 같은 자동 선언 이동/초기화 현상은 없습니다.
- 파이썬에서 호이스팅처럼 보이는 부분은 실제로 "코드를 어떻게 읽고 실행하느냐"의 차이에서 오는 착각일 뿐이며, 호이스팅 그 자체는 일어나지 않습니다.
- 결론
- 자바스크립트: 선언만 미리 처리(호이스팅), 함수/var 변수는 선언 전 접근 가능, let/const는 TDZ로 보호됨.
- 파이썬: 한 줄씩 위→아래로 실행, 선언 전 변수 사용 불가(오류 발생), 호이스팅 현상 없음.
- 이 차이가, 두 언어의 "인터프리터 동작 방식"과 실행 환경 차이에서 비롯된다는 점을 기억해두면 좋습니다.
오후
4교시: Crawling
지난 시간 복습
- 통신 기초: 요청과 응답
- request와 response
- request : 클라이언트가 서버로 전달하고자 하는 정보나 메시지를 담는 객체
- response : 서버가 클라이언트로 전송시키는 응답 메시지를 담는 객체
- request와 response
- requests 라이브러리
- 코드에서 웹 브라우저 역할을 해 줌
- response 코드
- 200: 정상
- 400: request에 문제 있음 → 클라이언트 쪽 문제
- 500: response에 문제 있음 → 서버 쪽 문제
- 주의 사항
- requests.get(url).text의 결과는 "문자열"
- 컴퓨터가 인식하기에 HTML 태그가 아님 (데이터 타입이 문자열이니까 그냥 글자로 인식함)
- 변환 작업(parsing) 필요: 문자열 → HTML 문자화
- beautifulsoup 라이브러리를 활용하여 응답 받은 데이터(문자열)를 html 형태로 변환(파싱)
- requests.get(url).text의 결과는 "문자열"
- 요소에서 content만 추출하기:
요소.text - .select: 모든 요소 가져옴 → 리스트 형태 → 요소 하나만 보고 싶으면 인덱싱 해야 함
- .select_one: 맨 앞 요소만 가져옴 → 요소 형태 → 바로 .text 붙일 수 있음
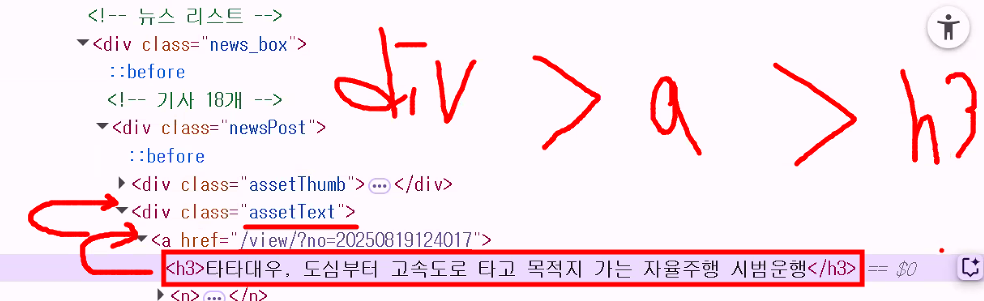
- 절대 경로는 자세히 보면 색상이 좀 다름

페이지 확장하기
- 현재는 첫 번째 페이지에서 수집한 뉴스 데이터
- 다음 페이지의 데이터도 수집하고 싶음
- 크롤링 → 데이터 수집 → 데이터 분석: 대량의 데이터가 필요함
- 아직 동적 크롤링을 배우지 않은 상태이므로 페이지를 넘겼을 때 나오는 주소를 이용 → 규칙을 확인
- 1 페이지 수집 후 2 페이지의 url을 주어 페이지 정보를 요청
- 규칙 확인: page 뒤의 숫자가 변경되고 있음을 확인 → 반복문
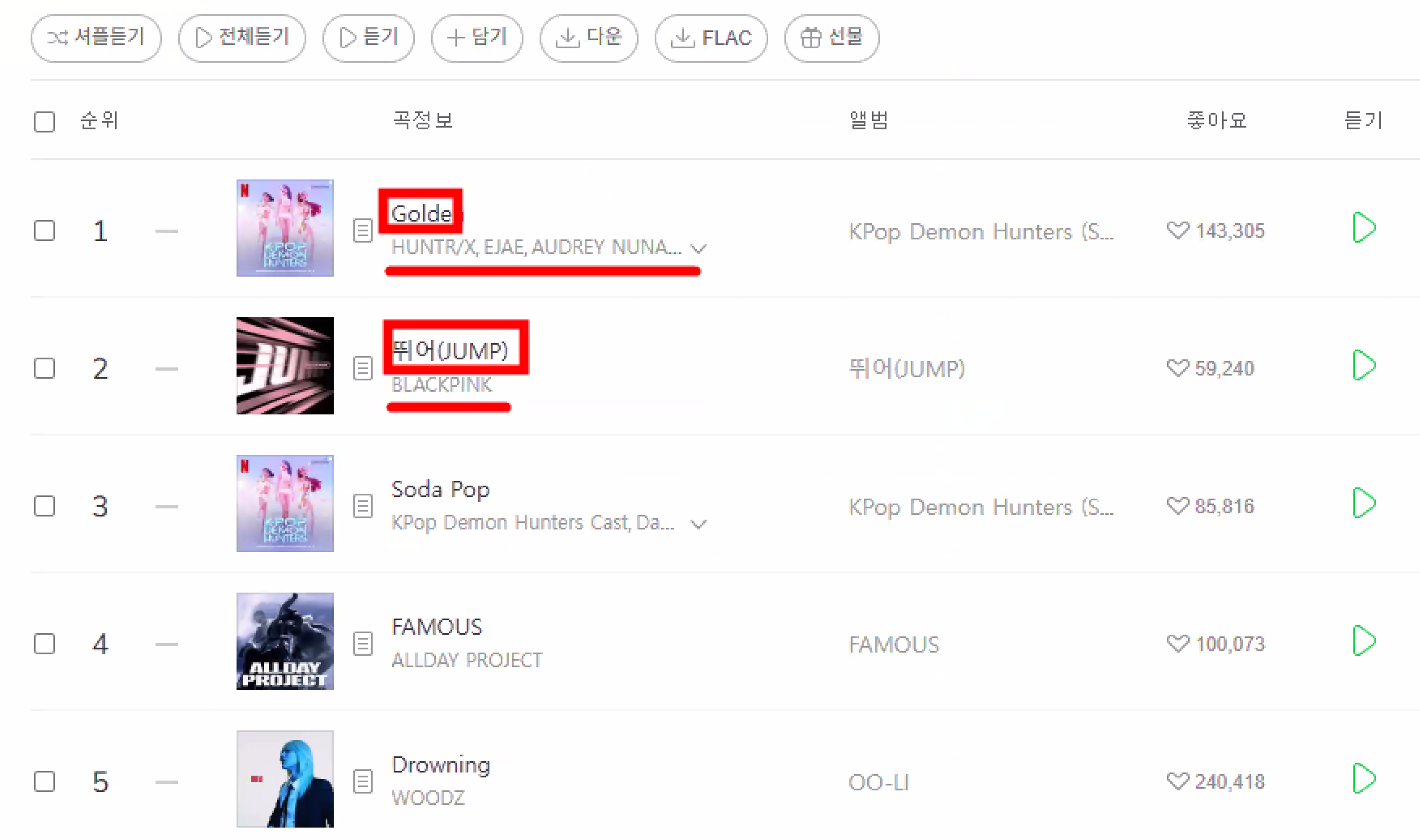
실습: 멜론 차트 top 100
- melon 페이지에서 가수, 노래 제목 top 100을 수집하자!
Response[406]- Client에서 문제 발생! → 요청에 문제 발생! → 보통 보안 문제
- 페이지를 접근할 때 브라우저가 아닌 코드로 접근했을 때 발생
- 브라우저 정보가 누락된 상태로 요청 → 브라우저 정보가 필요하기 때문에 거절
- 해결 방법: 브라우저 정보를 포함하여 요청
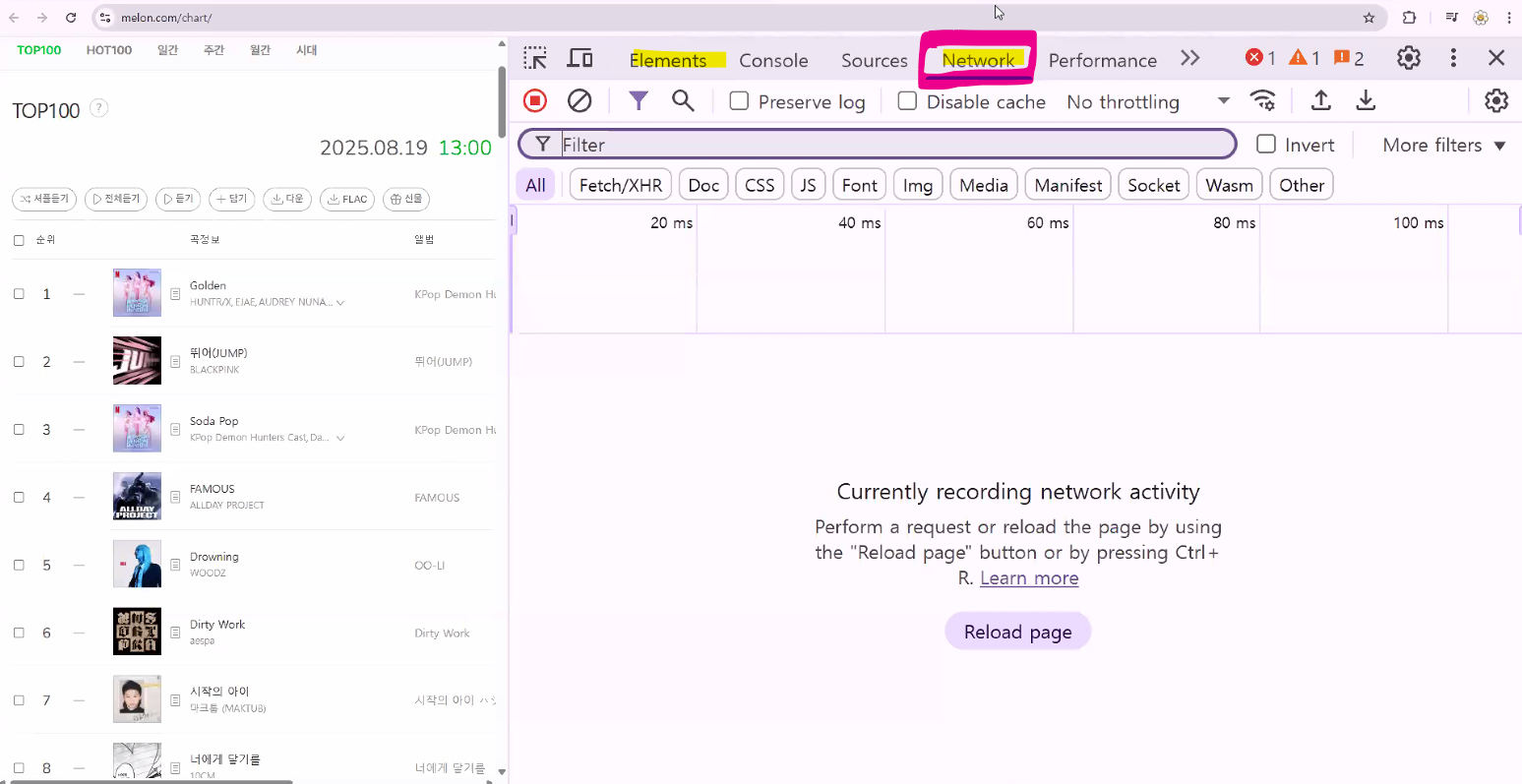
- 개발자 모드(f12) → Network 탭 → 새로 고침 → type이 document인 Name을 클릭 → headers 탭 → user-Agent (브라우저 정보)
- 개발자 도구에서 Network 선택
- 아무것도 안 보이면 새로 고침 하기
- 브라우저 정보
- 개발자 도구에서 Network 선택
5교시: Crawling
실습: 멜론 차트 top 100
Response[406]해결하기- 컴퓨터를 통한 코드 접근이 아닌 브라우저로 접근하는 것처럼 속이는 작업이 필요
- 요청 시 브라우저 정보를 함께 보내기
- 브라우저 정보: 개발자 모드에서 확인
h = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36"}- User-Agent라고 써도 됨
- headers에 브라우저 정보 포함하여 요청
req.get(url, headers=h)
- 컴퓨터를 통한 코드 접근이 아닌 브라우저로 접근하는 것처럼 속이는 작업이 필요
노래 제목 가져오기
- 구분자 확인
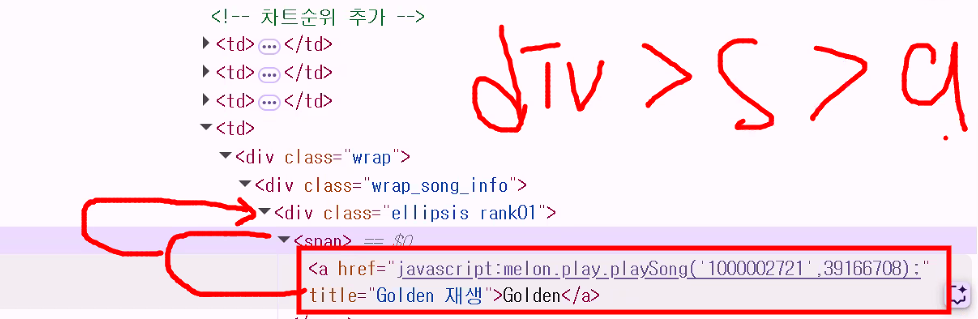
soup.select("div.ellipsis rank01>span>a")를 실행했더니[]가 출력돼요class="ellipsis rank01"는 클래스명이 두 개(ellipsis, rank01)라는 의미- 이걸 바로 select에 선택자로 써 버리면(
soup.select("div.ellipsis rank01>span>a")) 띄어쓰기 뒤의 rank01을 자손 선택자로 인식함: 자손 선택자를 의미하는 기호가 space임 → 두 개의 클래스를 가진 div를 지칭하고 싶으면div.ellipsis.rank01로 적어야 함!
크롤링은 항상 데이터 개수를 확인해야 합니다!
가수명 가져오기
- 노래 제목은 100개인데 가수는 136명
- 하나의 노래를 여러 가수가 부르는 경우가 있기 때문
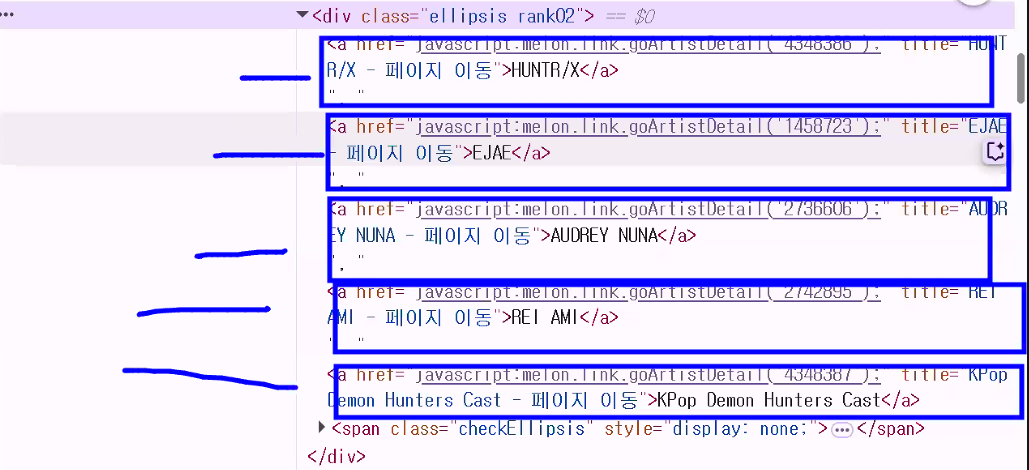
- 따라서 가수는 a 태그로 가져올 게 아니라 부모 태그로 묶어서 가져와야 함
- 하나의 노래를 여러 가수가 부르는 경우가 있기 때문
크롤링은 계속 데이터를 확인해주는 과정을 거쳐 주어야 함
soup.select("div.ellipsis.rank02")로 데이터를 가져오면 가수명이 연속해서 2개 수집되는 문제- div 태그 밑에 a 태그와 span 태그 둘 다 가수명을 가지고 있어 발생
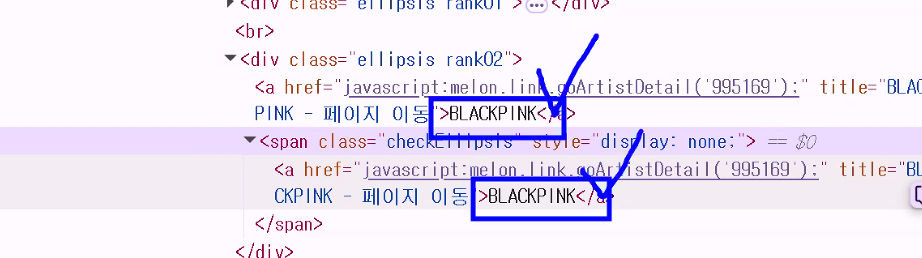
- 둘 중 한 개의 태그만 수집하면 됨 → span 태그로 가져오자!
- div 태그 밑에 a 태그와 span 태그 둘 다 가수명을 가지고 있어 발생
크롤링 작업은 데이터를 끝까지 확인해 보는 것이 중요합니다!
→ 웹 페이지의 구성을 알 수 없기 때문
6교시: Crawling
실습: 환율 데이터 가져오기
- 학습 목표
- 네이버 환율 페이지의 환율 데이터를 수집할 수 있다.
- iframe 개념에 대해서 알고 iframe 환경에서 데이터를 수집할 수 있다.
통화명 가져오기
- 해당 선택자 절대 경로를 가져오기
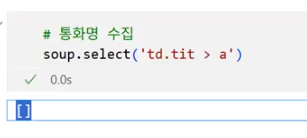
- 잘 가져온 것 같은데 비어 있음 → 그럼 선택자 절대 경로를 가져와보자!
- 개발자 도구에서 태그 위 우클릭 → copy → copy selector
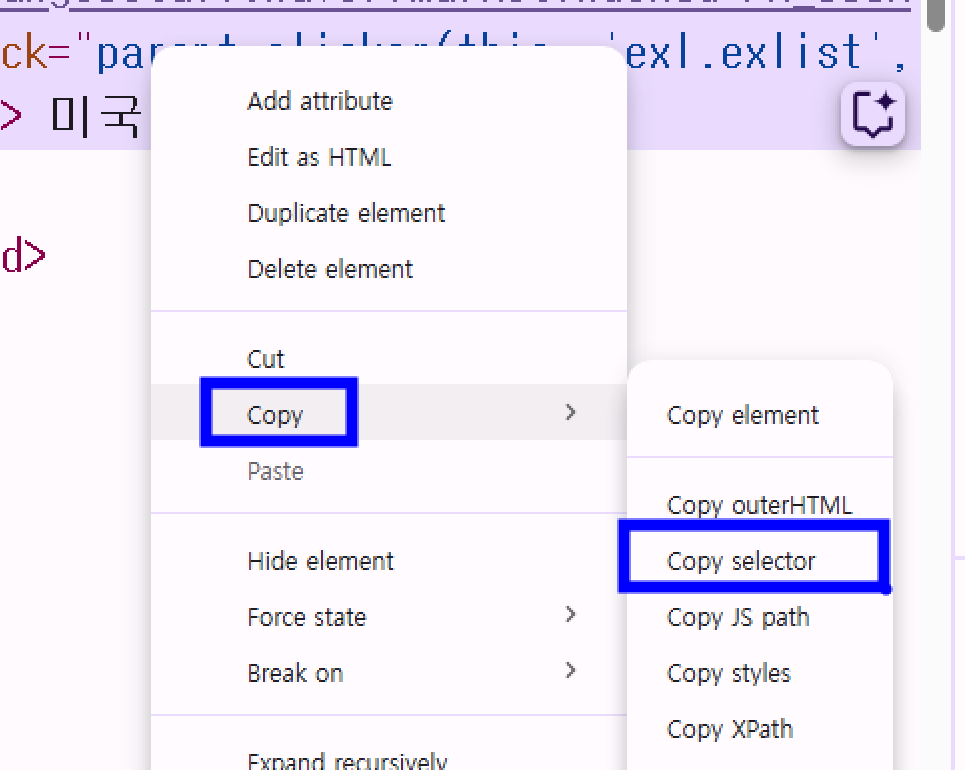
- 미국: body > div > table > tbody > tr:nth-child(1) > td.tit > a
- 유럽연합: body > div > table > tbody > tr:nth-child(2) > td.tit > a

- 그래도 안 되는데요? → iframe 구조 의심
- 응답 코드 200번, copy selector 사용했는데도 수집이 안 된다면 iframe 구조 의심하기!
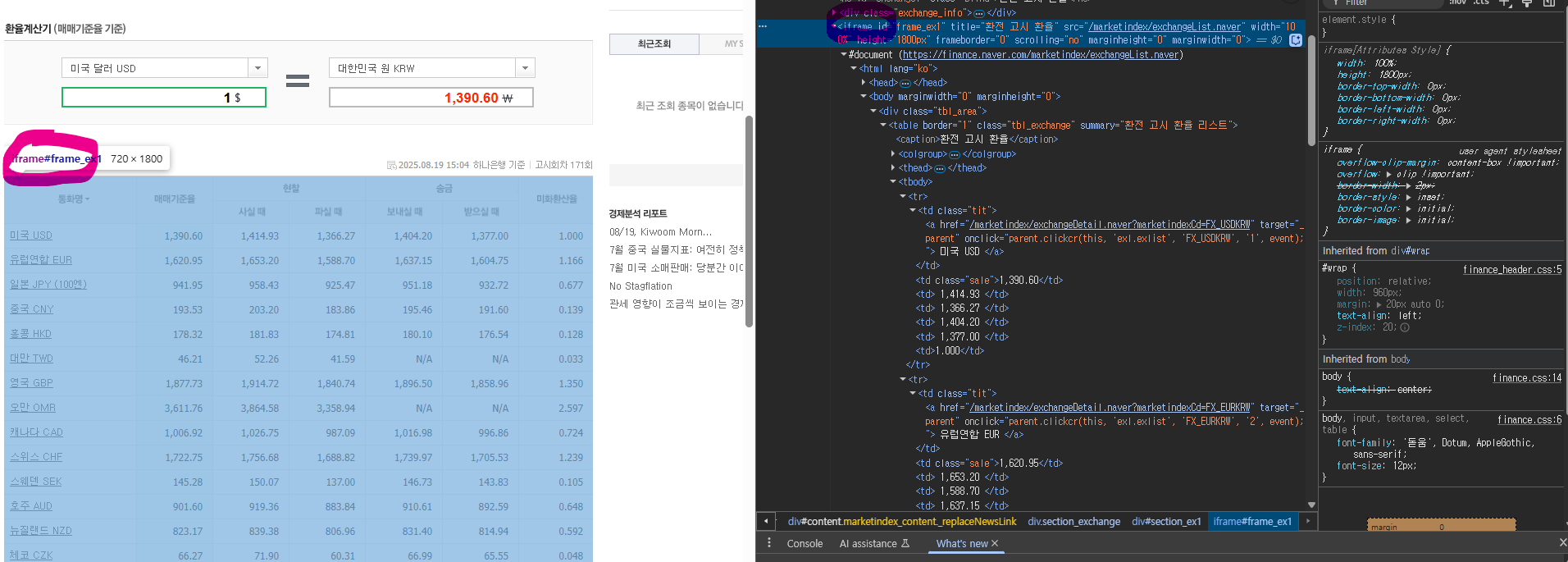
- iframe이 뭐길래 수집이 안 되는 걸까?
- 하나의 메인 페이지에 너무 많은 데이터가 담겨 있게 되면 무거워짐(로딩하는 데 시간이 오래 걸림) → 데이터가 많이 들어 있는 페이지를 따로 모아서 개설 & 메인 페이지에서는 해당 페이지를 끼워서 보여주면 로딩도 빠르고(다른 데 있는 데이터를 가져와서 보여주기만 하니까) 내용 확인도 다 할 수 있음
- 응답 코드 200번, copy selector 사용했는데도 수집이 안 된다면 iframe 구조 의심하기!
- iframe 태그의 src 속성에 있는 상대 주소에 메인 주소 더한 걸로 url 바꿔서 다시 하면 잘 됨
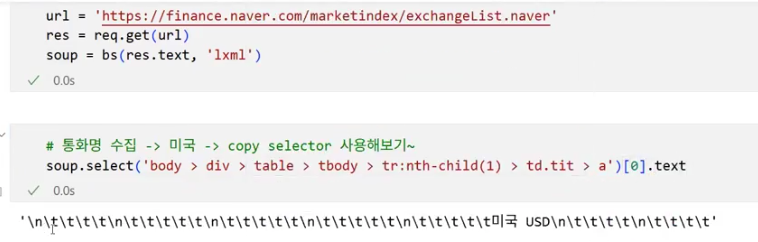
- 실제 데이터(미국 USD) 외에 의미 없는 특수 기호 제거: .strip()

- 실제 데이터(미국 USD) 외에 의미 없는 특수 기호 제거: .strip()
iframe
- 개념: 특정 페이지에 저장되어 있는 데이터를 메인 페이지로 가져와서 보여주는 HTML 태그
- 장점: 유지 보수, 재사용성 좋음
- 페이지를 따로 만들어 두었기 때문에 수정 사항이 생겼을 때 해당 페이지만 바꾸면 됨
- iframe 내에 있는 데이터를 가져오기
- 실제 데이터가 있는 주소로 접근해야 함!
<iframe src="주소">에 실제 데이터가 있는 주소(상대 주소)가 있음- 정보를 받아 오기 위해서는 실제 주소(메인 주소+상대 주소)를 요청하여 정보를 응답받아야 함
- 실제 데이터가 있는 주소로 접근해야 함!
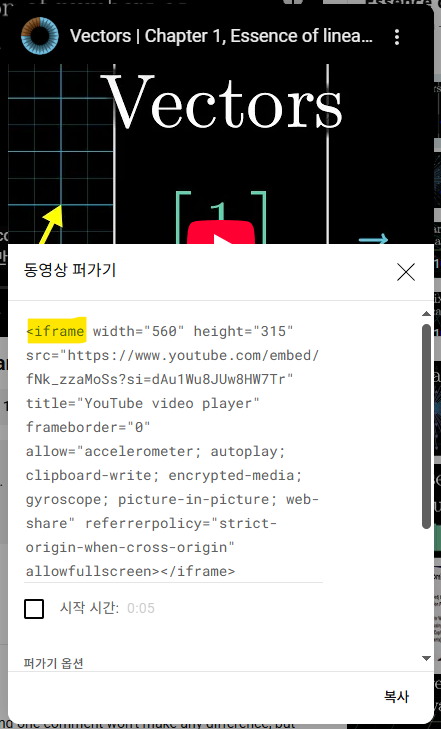
- iframe 사용 예시: 유튜브 동영상 퍼가기 → iframe 태그
과제
- 네이버 환율페이지에서 iframe 내의 테이블 데이터 수집하기!
- 수집해야 하는 내용
- 통화명
- 매매기준율
- 사실 때
- 파실 때
- 보내실 때
- 받으실 때
- 미화환산율
- 7개의 컬럼 수집하여 DataFrame 으로 만든 후 csv(환율.csv) 파일로 내보내기!
# 라이브러리 불러오기
import requests as req
from bs4 import BeautifulSoup as bs
url = "https://finance.naver.com/marketindex/exchangeList.naver"
res = req.get(url)
soup = bs(res.text,"lxml")
# 데이터 확인
soup.select_one("body > div > table > tbody > tr:nth-child(1) > td:nth-child(1)").text.strip() # '미국 USD'
len(soup.select("body > div > table > tbody > tr")) # 58
len(soup.select("body > div > table > tbody > tr:nth-child(1) > td")) # 7
tr = len(soup.select("body > div > table > tbody > tr"))
td = len(soup.select("body > div > table > tbody > tr:nth-child(1) > td"))
# 방법 1
total = []
for i in range(tr):
temp = []
for j in range(td):
temp.append(soup.select_one(f"body > div > table > tbody > tr:nth-child({i+1}) > td:nth-child({j+1})").text.strip())
total.append(temp)
# 리스트 컴프리헨션 ver.
# total = [[soup.select_one(f"body > div > table > tbody > tr:nth-child({i+1}) > td:nth-child({j+1})").text.strip() for j in range(td)]for i in range(tr)]
import pandas as pd
columns = ["통화명", "매매기준율", "사실 때", "파실 때", "보내실 때", "받으실 때", "미화환산율"]
df = pd.DataFrame(total, columns=columns)
df.to_csv("환율.csv", encoding="utf-8-sig", index=False)
# 방법 2: list → dictionary → DataFrame
results = [[soup.select(f"td:nth-child({j+1})")[i].text.strip() for i in range(tr)] for j in range(td)]
currency, tsr, buying, selling, sending, receiving, usa_cr = results
data = {
"통화명":currency
, "매매기준율":tsr
, "사실 때":buying
, "파실 때":selling
, "보내실 때":sending
, "받으실 때":receiving
, "미화환산율":usa_cr
}
df = pd.DataFrame(data)
df.to_csv("환율.csv", encoding="utf-8-sig", index=False)보충
- 나처럼 리스트로 두 단계를 거치는 것보다 처음부터 딕셔너리로 바로 만드는 게 코드도 간결해지고 관리하기 더 편리하다고 함
- 딕셔너리로 바로 만드는 게 가장 간결하고 유지보수하기 편리함
- 필요 시 컬럼명(keys)만 바꾸시면 되고, 행(tr)과 열(td) 개수도 자동 계산되니 확장성도 좋음
import requests as req
from bs4 import BeautifulSoup as bs
import pandas as pd
url = "https://finance.naver.com/marketindex/exchangeList.naver"
res = req.get(url)
soup = bs(res.text, "lxml")
# 행과 열 개수
tr = len(soup.select("body > div > table > tbody > tr"))
td = len(soup.select("body > div > table > tbody > tr:nth-child(1) > td"))
# 컬럼명 리스트 (딕셔너리의 키)
keys = ["통화명", "매매기준율", "사실 때", "파실 때", "보내실 때", "받으실 때", "미화환산율"]
# 딕셔너리로 바로 데이터 수집
data_dict = {
key: [soup.select(f"td:nth-child({i+1})")[j].text.strip() for j in range(tr)]
for i, key in enumerate(keys)
}
# DataFrame 생성 후 CSV 저장
df = pd.DataFrame(data_dict)
df.to_csv("환율.csv", encoding="utf-8-sig", index=False)7-8교시: 네이버 클라우드 특강
취업 이야기
- 네이버 클라우드 현직자가 말하는 면접 자소서 준비 로드맵: 단계별 전략과 실전 사용법
뇌리에 박히게 할 컨셉 정하기
- 나만의 컨셉: "이 순서를 따라해주세요!"
- 내 컨셉을 설득시키는 근거: "경험 정리 이렇게 해주세요!"
- 경험 정리 시 유의 사항: "정리가 잘 됐으면 말할 땐 이렇게!"
- 면접, 자소서 → 항목 안에 나의 모든 이야기를 전부 다 담는 건 어려움
- 클라우드 엔지니어라면: 고객과의 소통, 최적의 아키텍처링, 끊임없이 나오는 클라우드 서비스 & AI 서비스 배워 나가기, 문제 해결(버그/장애 없는 시스템은 없음) 등
- 코멘토, 링크드인 등에서 현업자와 소통
- 뽑히고 싶은 욕심에 너무 많은 것을 짧은 자기소개소 안에서 한 번에 모두 알리려고 해 오려 마이너스
- 확실하게 전달하고 싶은 부분에 대해 컨셉을 확실하게 정하고 가자
1. 나만의 컨셉(=페르소나) 정하기
내 컨셉 이렇게 따라해 주세요!
1. 직무 소개
2. 직무 필요 역량
- 문제 해결 능력
- 꼼꼼한 업무 태도
- 계획성 있는 업무 처리
- 동료와의 유연한 협업
- 업무 프로세스 개선 능력
- 성장하려는 자세
- 나만의 장점(내 컨셉) → 경험 정리로 연결
- 꼼꼼한 업무 태도
- 계획성 있는 업무 처리
- 장점에 대한 경험
- 비언어적 요소
- 컨셉 정하기 & 컨셉을 어필하기 위한 나만의 근거 세우기
- 근거를 최대한 "구체적으로"
- 컨셉을 세우려면 '직무'를 알아야 함
- 해당 직무에서 필요한 역량들 고민하기
- 그 안에서 나의 진짜 장점 찾기 → 장점을 뒷밭침하는 경험 쌓기
- 예: SI 회사에 AI 개발자로 취업
- SI 개발자의 직무는 무엇일까? → SI가 무엇인지부터 파악
- SI: System Integration (시스템 통합)
- 고객이 원하는 상품(시스템)을 만들어 주는 회사 → 아웃소싱하는 회사라 생각하면 됨
- 예: 삼성 SDS, LG CNS, SK AX (3대 SI 회사)
- 고객이 요청한 시스템에 따라서 기능 요구 내역을 파악 후 거기에 따라서 개발하는 사람이 SI 개발자 → 그럼 어떤 역량이 필요할까?
- 끊임없이 발전하려는 자세! (계속해서 새로운 모델, API가 나오기 때문)
- 예2: 클라우드 개발자에게 고객이 AWS와 네이버클라우드를 엮어 멀티 클라우드 환경의 인프라를 구축해 달라고 요청 → 이 과정에서 "제가 AWS를 못 쓰니까 AZURE랑 네이버클라우드로 가시죠"라고 하면 안 됨!
- 고객의 요구사항들이 새로운 모델이나 새로운 기술을 요구하기 때문에 끊임없이 배우고 성장하고 성장하는 태도가 필요함
- 고객의 요구에 맞는 능력 갖추기: 호기심, 배우려는 자세
- 협업 능력
- 단순히 팀원의 말을 잘 들어주는 협업을 이야기하는 게 아님
- 업무 모듈화
- 칸반 기반 업무 단위 모듈화 → 칸반 보드
- 슬랙, 팀즈 등 다양한 협업 툴 사용
- 코드 리뷰
- 협업의 체계를 만들기 → '좋은 마음'만으로는 안 됨
- 문제 해결 능력
- 오류가 안 나는 프로그램은 없음 → 문제가 발생했을 때 문제를 빠르게 해결하는 능력 필요
- 꼼꼼함
- 예: 네트워크 단의 문제인지 애플리케이션 단의 문제인지 인프라 단의 문제인지 서버 단의 문제인지 모름 → 각각의 단위들마다 모니터링 툴 사용, 로그 분석
- 어디서 문제가 일어났는지 파악하기 위해서는 꼼꼼함이 필요
- 주석 달기
- 로그 기록
- 스펙, 레이어 구성 등 기록
- 시스템 아키, 서비스 아키에 대한 정보들이나 상세 정보를 꼼꼼하게 적어두기 → 문제를 빠르게 해결할 수 있는 힘이 됨
자소서던 면접이던 기본적으로 직무를 알아야 함 → 직무를 완벽하게 이해했다면 필요한 역량을 도출할 수 있음 → 필요 역량들을 나열하고 그중 두 개 정도 뽑아서 최대한 구체적으로 어필하는 것이 좋음
- 경험 적는 법: 역량을 어필하기 위함
- 과정을 구체적으로 적기
- 최대한 구체적인 경험을 베이스로 작성
- 나의 장점을 뒷받침해주는 사례로 작성
- 예: 업무 효율을 추구하고 협업의 체계를 만들기 위해 칸반 보드를 활용하여 클라우드 기반으로 빠르게 확인할 수 있게 했습니다.
- 경험을 적을 때 과정을 구체적으로 (무엇을 했는지 명확하게) 보여주는 게 가장 중요함
- 서론 꼭 쓰기
- 글을 처음 보는 사람이 이해할 수 있어야 함
- 두괄식과는 조금 다름 → 언제, 어디서, 어떤 주제로, 무엇을 한 건지 앞에 적으라는 뜻! (그래야 뒷 내용이 이해됨)
- 개괄식
- 과정을 구체적으로 적기
직무를 설정하고, 그 직무에 필요한 역량을 설계하고, 그 안에서 내가 어필하고자 하는 장점을 정해서 작성하기 → 장점에 대한 나만의 경험을 '구체적으로' 적기
- 비언어적 요소
- 표정, 말투, 태도, 호응 등
- 인상을 결정하는 요소
- 기업 인재상에 대해
- 표면적으로는 중요할 것 같은데 솔직히 기준으로 잡지는 않을 것 같아요! → 정답
- 뽑는 주체가(면접관이) '실무 담당자' or 실제 일할 팀이라서
- KBS 다큐멘터리 "인재 전쟁"
- 면접은 사실 그날 들어온 면접관의 마음에만 들면 OK
2. 내 컨셉을 설득시키는 근거: 경험 정리
"왜?"를 계속 질문하기
- 경험 정리를 위한 소재 찾기
- 개인/팀 프로젝트
- 예: 캡스톤
- 교내/교외 공모전
- 동아리 활동
- 아르바이트 경험(편의점, 물류센터, etc.)
- 현장 실습/인턴 etc.
- 개인/팀 프로젝트
- 소재가 가장 중요
- 그때그때 꼼꼼하게 기록해두기: 프로젝트 진행 중 틈틈히 기록 → 포트폴리오를 위해!
- 주제가 무엇이었는지
- 어떤 점이 어려웠는지
- 누구와 했는지
- 내 역할은 무엇이었는지
- 뭐가 힘들었고 어떻게 해결했는지
- 뭘 깨달았는지
- 무엇이 아쉬웠는지
- 공모전 많이 나가보기
- 상 못 받아도 괜찮음
- 경험을 쌓은 게 더 중요
- 과정들을 겪으며 "왜?"라는 질문을 하고 이에 답하는 게 핵심
3. 경험 정리 시 유의 사항
너무 다 전달하려고 하지 말자!
→ 확실한 것만 말하고 핵심만 말하기
하루 돌아보기
👍 잘한 점
- 수업 참여 열심히 했음
👎 아쉬웠던 점
- 미니 프로젝트 진척이 더뎌서 아쉬움
- 더 잘 나올 수 있을 것 같은데 내 능력이 부족하다😥
🔬 개선점
- 프로젝트 진행 내용 정리
- 모르는 부분 바로 물어보기
