[인공지능사관학교: 자연어분석A반] 기업연계 프로젝트 11일차 / MFU 특강
김정인 강사님 (jikim@imguru.co.kr)
강의 자료
Model FLOPs Utilization
- MFU 개념 및 성능 최적화
- for: GPU 가속 AI 모델 성능 극대화
- H/W 최적화
- 성능 분석
- 모델 최적화
- for: GPU 가속 AI 모델 성능 극대화
- GOAL
- NVIDIA Jetson, TensorRT 등 산업 표준 도구 활용 능력 습특
- AI 모델의 성능 분석 방법론 이해
- 병목 현상 진단 능력 습득
- Layer Fusion, Quantization, Pruning 등 최적화 기법 적용 능력
- MFU 개선 경험 및 노하우 습득
- Github Colab 연동
- 노트북 열기:
https://colab.research.google.com/github/imguru-mooc/mfu-optimization/blob/main/MFU_1_day.ipynb- A100 연결되었는지 확인하기
- '모든 출력 지우기' 후 실습 따라가기
- Colab Pro 팁
- 터미널에서 리눅스 명령어 쓸 수 있어서 편리
- 노트북 열기:
- 실습 환경
- 가상 하드웨어: Google Colab GPU (NVIDIA T4/A100)
- 프레임워크: PyTorch, TensorFlow, ONNX, TensorRT
- 도구: Netron(온라인), PyTorch Profiler, TVM
- 책 추천: "밑바닥부터 시작하는 딥러닝"
- 1권은 합성곱, 2권은 LLM(LSTM까지), 3권은 딥러닝 프레임워크
MFU 개념 및 기초 분석
MFU 정의, 필요성, 연산 이해
MFU 정의 및 필요성
MFU(Model FLOPs Utilization) 정의
- 모델의 이론적 성능 대비 실제 달성한 성능 비율을 나타내는 지표
- GPU의 이론적 최대 FLOPs 대비 모델이 실제 활용하는 FLOPs의 비율로 계산
- FLOPs(Floating Point Operations)
- 모델이 수행하는 부동소수점 연산의 총 개수
- 신경망이 학습 또는 추론 과정에서 곱셈(
×), 덧셈(+), 나눗셈(/), 지수(exp) 등의 실수 연산이 몇 번 수행되었는가를 정량적으로 나타내는 지표 - 하드웨어에 종속되지 않는 객관적인 성능 평가 지표
중요성
- 모델의 실제 연산 효율성을 정확히 파악 가능
- vs. GPU Utilization(활용률)
| 항목 | GPU Utilization | MFU (Model FLOPs Utilization) |
|---|---|---|
| 정의 | GPU가 현재 얼마나 바쁘게 동작 중인지 (%) | GPU가 낼 수 있는 최대 연산 성능 대비 실제 모델이 활용한 비율 (%) |
| 측정 방법 | nvidia-smi 명령어 등으로 실시간 사용률 확인 | FLOPs, 실행 시간, GPU 이론 성능을 기반으로 계산 |
| 단위 | % | % |
| 의미 | GPU가 일하는 시간의 비율 | GPU가 “얼마나 효율적으로” 일했는가 |
| 주요 병목 요인 | 데이터 로딩, I/O, 동기화 지연 | 연산 최적화 부족, 배치 크기, 커널 효율 |
| 활용 목적 | 시스템 상태 확인 | 모델 최적화 및 효율 분석 |
- 최적화 작업의 효과를 정량적으로 측정하는 핵심 지표로 활용
- 다양한 하드웨어 환경에서 일관된 성능 비교 가능
활용 분야
- 대규모 언어 모델(LLM) 훈련
- CNN, Transformer 최적화
- 분산 학습 환경 성능 평가
FLOPs/MACs/파라미터 이해
- 딥러닝 모델의 핵심 지표
FLOPs (Floating Point Operations)
- 모델이 실행하는 부동소수점 연산의 총 수
- 모든 산술 연산(덧셈, 곱셈, 나눗셈 등) 포함
- 모델의 계산 복합성을 나타내는 지표
MACs (Multiply-Accumulate Operations)
- 곱셈과 덧셈을 하나의 연산으로 수행:
- 일반적인 변환 기준: 1 MAC = 2 FLOPs
| 용어 | 의미 | 세는 단위 |
|---|---|---|
| FLOP | Floating Point Operation – 부동소수점 연산 1회(곱, 덧셈 등) | 사칙연산·exp·log 등 1회씩 |
| FLOPs | 총 부동소수점 연산 수 | 전체 연산량 |
| FLOPS | Floating Point Operations per Second – 초당 처리 가능한 연산량 | 하드웨어 처리 속도 단위 |
| MAC | Multiply–Accumulate – “곱하고 더하기”를 한 묶음으로 처리 | a * x + b 1회 |
“1 MAC = 2 FLOPs”라는 관계는 Multiply–Accumulate(곱셈-누산) 연산을 어떻게 세느냐의 기준 차이에서 발생함
- 2가 어디서 온 걸까?
- 딥러닝이나 신호처리에서 자주 등장하는 연산 예는 곱하기 + 더하기 형태
- 예:
- 이 연산을 세는 방식이 다름!
- FLOPs 기준: 곱셈(1 FLOP) + 덧셈(1 FLOP) = 총 2 FLOPs
- MAC 기준: (곱셈+덧셈)을 하나의 패키지 연산으로 보므로 1 MAC
- 즉, → 이 “2”가 바로 곱하기 1회 + 더하기 1회에서 온 것
- 왜 이렇게 셀까?
- 현대 CPU · GPU 하드웨어는 FMA (Fused Multiply–Add) 명령어를 지원
- FMA는 두 연산을 한 번에 수행하며 오차 없이 결과를 누적함
- 즉, 하드웨어 레벨에서는
a × b + c를 1 사이클 내에 처리하므로 성능 측정(MAC)에서는 1회로 계산하지만, 수학적으로는 곱셈 + 덧셈 → 두 연산으로 표시(FLOPs)하는 것- 변환 관계
- CNN에서 50 M MAC이 계산됨 → 논문에서 FLOPs로 표현하면 약 100 M FLOPs
- 핵심 요약
- MAC: (곱+덧) 하나로 묶어서 1 연산
- FLOP: 각각을 별도 연산으로 센다
- 그래서 1 MAC = 2 FLOPs
- 발생 원인 → “Fused Multiply–Add(FMA)” 구조 때문
파라미터 (Parameters)
- 모델이 학습하는 가중치와 편향의 총 개수
- 모델의 크기와 메모리 요구사항을 결정
- 저장 공간과 배포 시 중요 고려사항
연산량 계산 예시
모델 연산 흐름 분석
실습: MFU 측정 도구 사용법
형상 입력
- Keras (특히 TensorFlow Keras)에서는 입력 데이터 형상이 보통 (배치 크기, 높이, 너비, 채널 수) 순서인 NHWC 형식이 기본
- 예: input_shape=(28, 28, 1) 은 28x28 크기의 1채널 이미지
model.add(Conv2D(32, (3, 3), input_shape=(28, 28, 1)))
- PyTorch에서는 입력 데이터 형상이 (배치 크기, 채널 수, 높이, 너비) 순서인 NCHW 형식이 기본
- 예: (batch_size, 1, 28, 28)
- x = torch.randn(batch_size, 1, 28, 28)
- 왜 차이가 나는가
- Keras/TensorFlow는 주로 CPU와 GPU 모두에서 편리한 NHWC 포맷을 기본으로 사용하며, 또한 TensorFlow 내부 최적화가 NHWC를 선호하는 경향이 있습니다.
- PyTorch는 CUDA를 강력히 지원하며, NCHW가 GPU 메모리 접근에 효율적이라 기본 형상으로 채택합니다.
- 주의 사항
- 만약 Keras 데이터를 PyTorch에 넣거나 반대로 할 때는 transpose 또는 permute 메서드로 채널 위치를 바꿔야 함
- Keras(NHWC) → PyTorch(NCHW)
x = x.permute(0, 3, 1, 2)
- 만약 Keras 데이터를 PyTorch에 넣거나 반대로 할 때는 transpose 또는 permute 메서드로 채널 위치를 바꿔야 함
| 특징 | Keras 입력 형상 | PyTorch 입력 형상 |
|---|---|---|
| 기본 데이터 순서 | (batch, height, width, channels) (NHWC) | (batch, channels, height, width) (NCHW) |
| 이유 | TensorFlow 최적화 및 CPU 친화 | GPU 최적화, 메모리 접근 효율 |
| 변환 필요성 | Keras → PyTorch 전환 시 permute 필요 | PyTorch → Keras 전환 시 transpose 필요 |
type
- C에만 array 있음(python은 없음)
- C의 기본 타입 4가지: char, int, float, double
- short, unsigned, long, long long 등은 한정자임
char: 1byte => 8bit
int: 4byte => 32bit
↑ 정수
------
↓ 실수
float
doublechar c=200;
printf("%d\n", c); // -56- CPU 가산기(adder)
- CPU의 산술 논리 장치(ALU)에서 숫자를 더하는 기본적인 연산 회로
- CPU 감산기
- 집적부, 게이트가 가산기의 두 배
- 가산기 + 인버터만 있으면 감산기 없이도 뺄셈 구현
- NOT 게이트
char c = 0xff; // 11111111 → -1
short s = 0xfffc; // 1111 1111 1111 1100 → -4
int i = 0xfffffffe; // 1111 … 1111 1111 1110 → -2- 구조체
typedef struct
{
char ch:2;
}BIT;
BIT b;
b.ch = 3; // -1
if(b.ch == 3) // 여긴 절대 실행 안 됨
…- 3을 2비트 signed 변수에 넣으면 11이 되고, 그 11은 부호비트 1 + 데이터비트 1 로 해석되어 -1이 되는 것
typedef struct
{
char ch:1;
}BIT;
BIT b;
b.ch = 1; // -1
if(b.ch == 1)
…- 1비트짜리 signed bit-field의 경우, 그 하나의 비트가 부호비트이자 데이터비트로 동시에 사용
- 남은 비트가 하나도 없기 때문에 그 유일한 비트가 부호비트이자 값비트로 동작
- 1이면 “음수(-1)”, 0이면 “양수(0)”로 해석
실수
char: 1byte => 8bit
int: 4byte => 32bit
↑ 정수
------
↓ 실수
float: 4byte => 32bit
double: 8byte => 64bitfloat f = 10.25f;→ 1010.01(2)
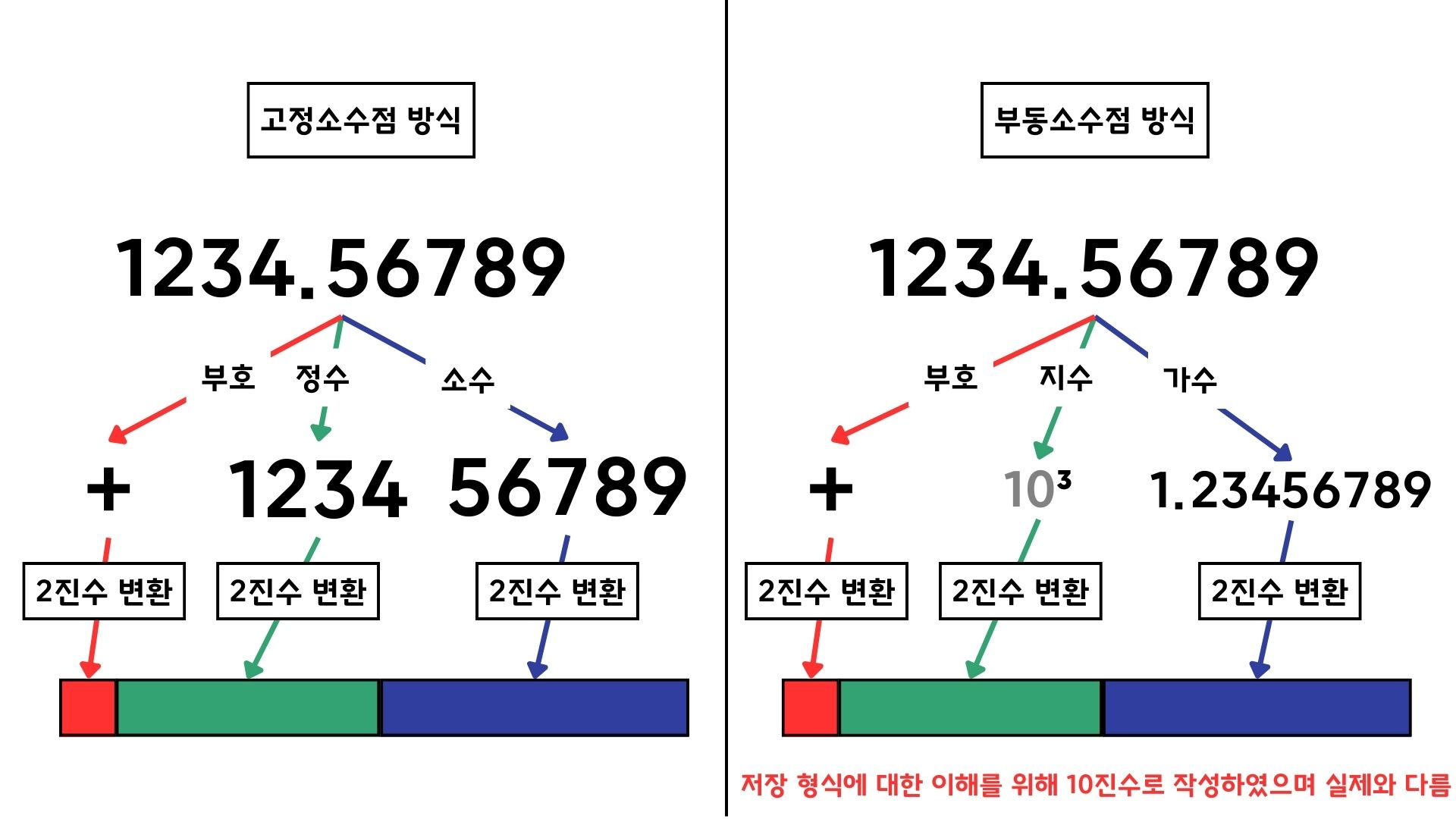
고정소수점 방식의 문제점
- 매우 큰 수를 표현할 수 없다.
- 매우 정밀한 수를 표현할 수 없다.
부동(浮動)소수점
1000000000 →
1010.01 →
- 문제점
- 지수에도 음수가 있다.
- 가수부의 첫 번째 숫자는 항상 1이다.
0.00000000001 →
- 해결
- 127 bias 사용
- 소수점을 한 번 덜 움직인다.
1010.01 →

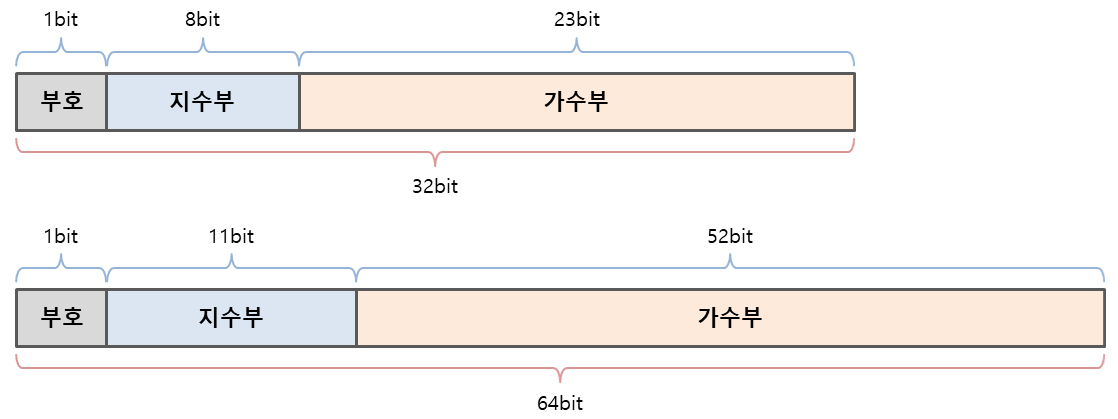
'Mantissa (fraction)'(가수부)는 숫자의 유효 숫자 부분이며, 특히 부동소수점(floating-point) 표기법에서 소수점의 위치를 나타내는 'exponent'(지수부)와 함께 사용됩니다. 컴퓨터는 부동소수점수를 가수부와 지수부로 나누어 저장하며, 가수부는 숫자의 정밀도를 나타냅니다.

- double은 e가 11자리
double: 8byte => 64bitdouble f = 10.25;아날로그를 완벽하게 디지털로 옮기지 못하는 문제
float f = 0.1f;0.0001100110011… →
float f = 0.1f;
float sum = 0.0f;
int i;
for (i=0; i<10000; i++)
sum += f;
printf("%f\n", sum);- float 자료형의 "정밀도 한계" 때문에 주의가 필요
- 주의할 점
- 0.1f는 2진 부동소수점으로 정확히 표현될 수 없는 값입니다.
- 따라서 10000번 더해도 0.1 * 10000 = 1000이 딱 정확하게 나오지 않을 수 있습니다.
- 실제 출력 결과는 약간의 오차가 포함된 값이 나올 가능성이 큽니다.
- 그 이유
- IEEE 754 규격의 32비트 float는 소수점 이하 정확도가 약 6~7자리입니다.
- 0.1처럼 10진수에서 정확한 표현이 불가능한 값은 근사값으로 저장됩니다.
- 반복 더하기 과정에서 누적된 오차가 결과에 영향을 줍니다.
- 대처 방법
- 더 높은 정밀도의 double 타입으로 선언하여 오차를 줄입니다.
- 주의할 점
double f = 0.1;
double sum = 0.0;
for (int i = 0; i < 10000; i++)
sum += f;
printf("%lf\n", sum);부동소수점 오차에 의해 정확한 1000 출력이 보장되지 않음!
IEEE 754
- 1985년 미국 전기전자학회 (IEEE)에서 제정한 부동 소수점 연산 기술 표준(tandard for Floating-Point Arithmetic)
배열과 행렬
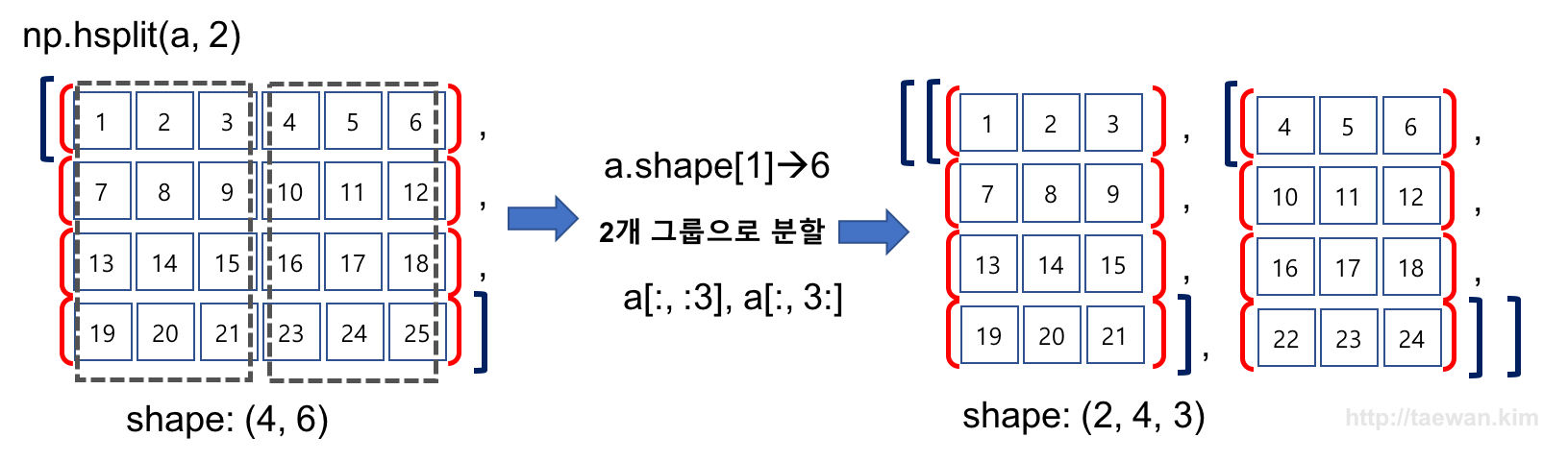
import numpy as np
a = np.array([1,2,3,4])
a.ndim // 1
a.shape // (4,)
len(a) // 4
a.shape[0] // 4
a[0] // 1 → index는 차원을 줄이는 연산
a[0:1] // [1] → slicing은 값을 줄임a = np.array([[1,2],[3,4]])
a.ndim // 2
a.shape // (2,2)
len(a) // 2
a.shape[0] // 2
a[0] // [1,2] → index는 차원을 줄이는 연산
a[0:1] // [[1,2]] → slicing은 값을 줄임a = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])
a.ndim // 3
a.shape // (2,2,2)
len(a) // 2
a.shape[0] // 2
a[0] // [[1,2],[3,4]] → index는 차원을 줄이는 연산
a[0:1] // [[[1,2],[3,4]]] → slicing은 값을 줄임a = np.arange(16).reshape(1,1,4,4)
a.ndim // 4
a.shape // (1,1,4,4)
len(a) // 1
a.shape[0] // 1
a[0] // [[1,2],[3,4]] → index는 차원을 줄이는 연산
a[0:1] // [[[1,2],[3,4]]] → slicing은 값을 줄임전치
- 1차원
a = np.array([1,2,3,4])
a // [1,2,3,4]
a.T // [1,2,3,4] → 1차원 배열은 전치 X
a.reshape(-1,1) // reshape을 통해 전치처럼 보이게 할 수 있음- 2차원
a = np.array([[1,2],[3,4],[5,6]])a → (3,2)
a.T → (2,3): [[1,3,5],[2,4,6]]
- 3차원
a = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])
a.transpose(2,1,0) // [[[1,5],[3,7]],[[2,6],[4,8]]]`
a.transpose(2,0,1) // [[[1,3],[5,7]],[[2,4],[6,8]]]`- 채널별 디스플레이
(1,32,32,3) → (1,3,32,32)
행렬의 곱
a = np.array([1,2,3])
b = np.array([1,1,1])
a*ba = np.array([1,2,3])
b = np.array([1,1,1])
np.sum(a*b)a = np.array([1,2,3])
b = np.array([1,1,1])
np.dot(a,b)배열에 인접한 개수가 같으면(공리에 맞으면) 행렬의 곱 가능: "첫 번째 행렬의 열 개수와 두 번째 행렬의 행 개수가 같아야 합니다"
(3,)(3,) → ()
a = np.array([1,2,3])
b = np.array([[1,1],[2,2],[3,3]])
np.dot(a,b) // [14,14](3,)(3,2) → (2,)
a = np.array([[1,1],[2,2],[3,3]])
b = np.array([1,2,3])
np.dot(a,b) // [3,6,9](3,2)(2,) → (3,)
a = np.array([[1,1],[2,2],[3,3]])
b = np.array([[1],[2]])
np.dot(a,b) // [[3],[6],[9]](3,2)(2,1) → (3,1)
a = np.array([[1,1],[2,2],[3,3]])
b = np.array([[1,1],[2,2]])
np.dot(a,b) // [[3,3],[6,6],[9,9]](3,2)(2,2) → (3,2)
x = np.array([[1,1],[2,2],[3,3]])
w = np.array([[1,1],[2,2]])
np.dot(a,b) // [[3,3],[6,6],[9,9]](3,2)(2,2) → (3,2)
(입력 데이터 수,특성 수)(특성 수, 뉴런 수)
합성곱
- 1차원 합성곱
x =np.array(
N = len(x) = 6
F = len(x) = 3
output = N - F + 1
output = 6-3+1- 패딩
x =np.array(
N = len(x) = 6
F = len(x) = 3
output = N +2P - F + 1
output = 6+2-3+1- 스트라이드(stride)
N = len(x) = 3
F = len(x) = 2
output = N + 2P -F +1
output = (3 + 2*0.5 -2) + 11 2 3
4 5 6
7 8 9
1 1
1 1
12 16
24 28
- 필터(filter)
- 그림의 채널을 필터가 그대로 따라야 함 (의존 관계)
- 바이어스는 필터 개수에 의존관계 보임
N = len(x) = 3
F = len(x) = 2
output = N + 20 -F +1
output = (3 + 2*0.5 -2) + 1ReLU
-
f(x) = max(0,x)
-
i = -1;, 11111111 → 255 -
forward
[1, -2, 3, -4, 5]→- mask
[0, 1, 0, 1, 0]
-
미분
dout[mask]=0[3,0,-5,0,-7] ← [3,4,-5,6,-7]- forward였을 떄 음수였던 것만 지움
CIFAR-10
- ConvNetJS CIFAR-10 demo
- relu (32x32x16)
- 음수가 지워져서 시각적으로 어두워짐
모멘텀
- Adam (Adaptive Moment Esimation): Momentum 와 RMSProp 두가지를 섞어 쓴 알고리즘
- 모멘텀은 관성 개념을 추가해서 지역 최솟값에 갇히지 않고 '탈출'할 수 있도록 한다. 이 두가지가 모두 적용된 옵티마이저가 바로 Adam
합성곱 코드
(N*OH*O11W, C*FH*FW)(1*3*3, 1*2*2)- 합성곱도 미분해야 함 →
- weight도 학습됨 → 필터를 만드는 과정!
- 어도비가 이걸 잘 만들어서 유명했음(AI 등장 전)
행렬곱 미분
col col_W
dw = col.T∙dout
Broadcast
- 리피트 연산
np.repeat(b,3,axis=0)- cf.
np.sum(b,axis=0)
img2col / col2img
flops = 2 * H_out * W_out * K_h * K_w * C_in * C_out 에서 2를 곱하는 이유는, CNN의 부동소수점 연산에서 곱셈과 덧셈이 한 세트로 이루어지기 때문입니다.
각 출력 요소를 계산하기 위해,
- 커널 요소와 입력 요소를 곱하고,
- 이 곱한 값을 누적해서 더하는 덧셈 연산이 필요합니다.
따라서 각 출력 원소당 1회의 곱셈 + 1회의 덧셈 = 2회 연산(FLOPs) 이 발생합니다.
이걸 식으로 정리하면,
- : 출력 공간 크기
- : 필터(커널) 크기
- : 입력 채널 수
- : 출력 채널 수
각 연산이 출력 원소마다 위 식에 곱해지고, 곱셈-덧셈 쌍이 2회이므로 최종적으로 2 * ... 곱셈이 붙는 것입니다.
즉, 2는 매번 곱셈과 덧셈(MAC: Multiply-Accumulate)이 둘 다 일어나면서 추가되는 부동소수점 연산 수를 반영한 계수입니다.
요약하면:
flops에서 2배는 부동소수점 곱셈과 덧셈을 각각 1회씩 수행하는 것을 합친 것- CNN에서 연산량 산출 시 곱하기와 더하기 연산을 모두 고려해야 해서 2를 곱함
이 점을 이해하면 CNN 연산량 계산 시 2 * ...가 심플한 표준 공식을 만든 이유임을 알 수 있습니다.
