[인공지능사관학교: 자연어분석A반] MFU 특강 (2)
성능 분석 및 병목 진단
MFU 및 FLOPs를 통한 병목 지점 파악
→ layer별 FLOPs 적용하기
- 2일차 ipynb
- A100 / 고사용 RAM 체크
- gpu 정보 확인
- Layer별 FLOPs 계산
- convolution 기본 코드(Conv2D 레이어의 FLOPs 계산): FLOPs = 2 × K² × C_in × C_out × H_out × W_out
Transformers
- attention_flops
- Q, K, V projection ★
- 자연어 처리 batch 수 ==
문장 개수*문장 내 단어 수 - cf. 이미지: 이미지 장수
- d_model: 512차원 벡터
- 곱의 의미 파악하기
- 병렬 처리: num_heads(논문에서는 8로 설정)
- 예 d_model 512, d_model 8 → d_head 64
실제 모델에 적용
- pooling ★
- MaxPool
- 자동 FLOPs 프로파일링 도구 활용
- FLOPs로 되어 있지만 출력된 걸 보면 MACs인 것으로 보임
MFU
GPU를 얼마나 잘 활용하고 있는지에 대한 지표
병렬 처리가 잘 되고 있다는 뜻
60~80% 정도가 적당
Transformer
비전에서도 중요한 모델
여러 카메라가 찍은 한 객체에 대해 이미지 내 객체가 동일하다고 인식시키는 문제 RNN 병렬처리 X
tansformer code 분석
https://github.com/WegraLee/deep-learning-from-scratch
https://github.com/WegraLee/deep-learning-from-scratch-2
코드분석 꼭 하기!!
repeat(broadcast) 연산 때문에 행, 열을 각각 추가함
여러 단어가 동시에 진행되는 검이 특징
OOC
Dropout
출력 결과 랜덤한 위치 지움
by mask
뉴런을 지우는 게 아님
regulation
loss = loss_fn() + np.sum(abs(w))손실함수 미분 (a-y)
(a-y)+np.sign()
W = W - 0.01*(dw + 1)
W = 3 0.09
학습 속도 결정이 아님
train data에 대한 의존성을 줄이는 것
weight를 0으로 끌어당기는 힘
규제를 너무 올리면 과소적합(0에 가까워짐)
0.01 정도만 넣어도 다 0으로 감
사용자 의존적
loss = loss_fn() + np.sum((w)^2)손실함수 미분 (a-y)
(a-y)+
W = W - 0.01*(dw + 1)
W = 3 0.09
"당기는" 힘으로 이해하기
최신 논문에서는 dropout을 더 많이 사용
(힘을 넣는 건 몇 가지 문제가 있어서)
- 세 가지 핵심 내용
- Dropout
- 잔차 연결(Skip Connection)
- LayerNormaliaton
디코더 구조
- look-ahead mask
- encoder-decoder attention
Transformer encoder layer 블록 구현 및 분석
vector field
head 수
정규화 층
결정 경계
sample에 의해 바뀌지 않게 하려고 sigmoid 도입
로지스틱 회귀에는 sigmoid가 반드시 필요
https://playground.tensorflow.org/
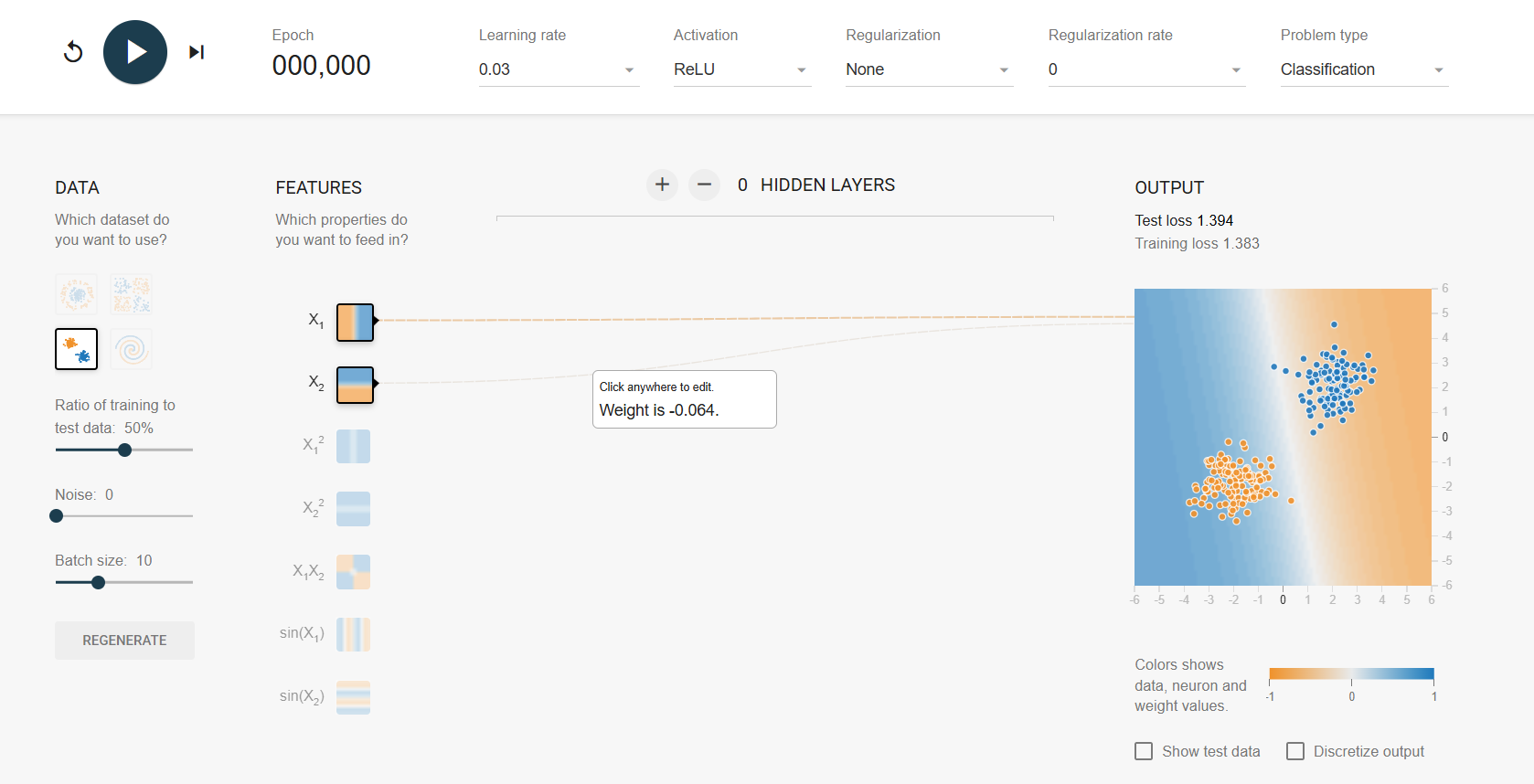
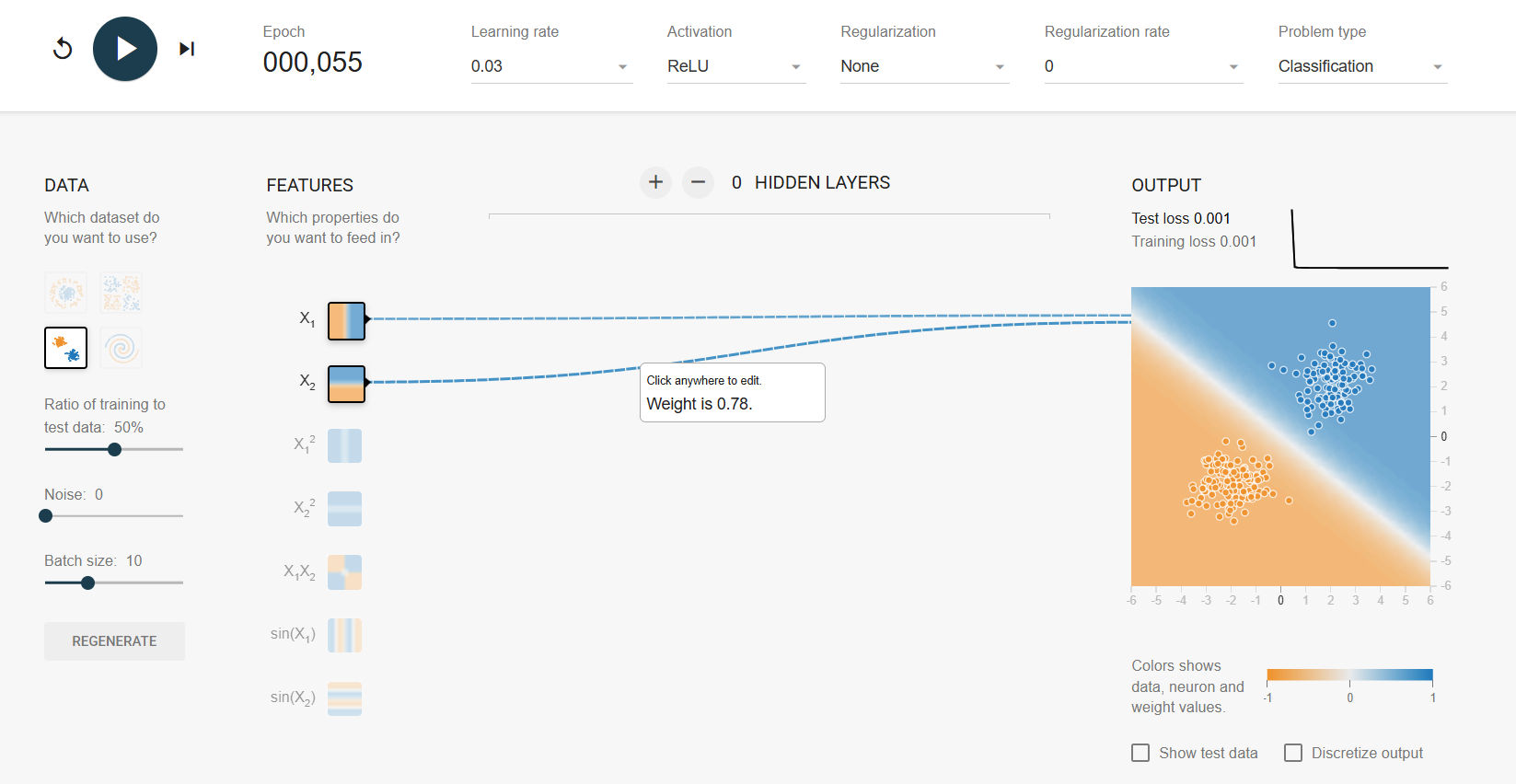
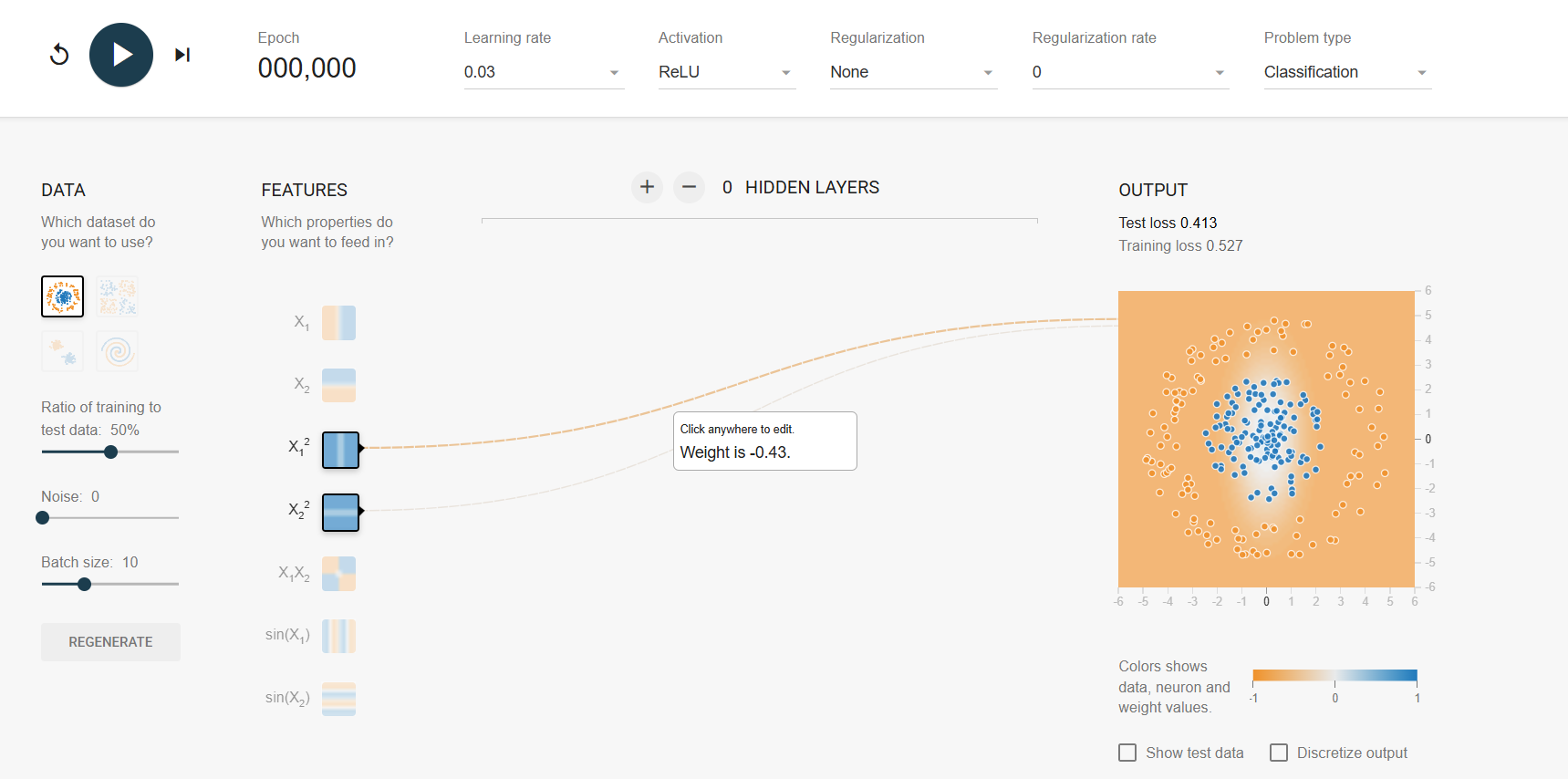
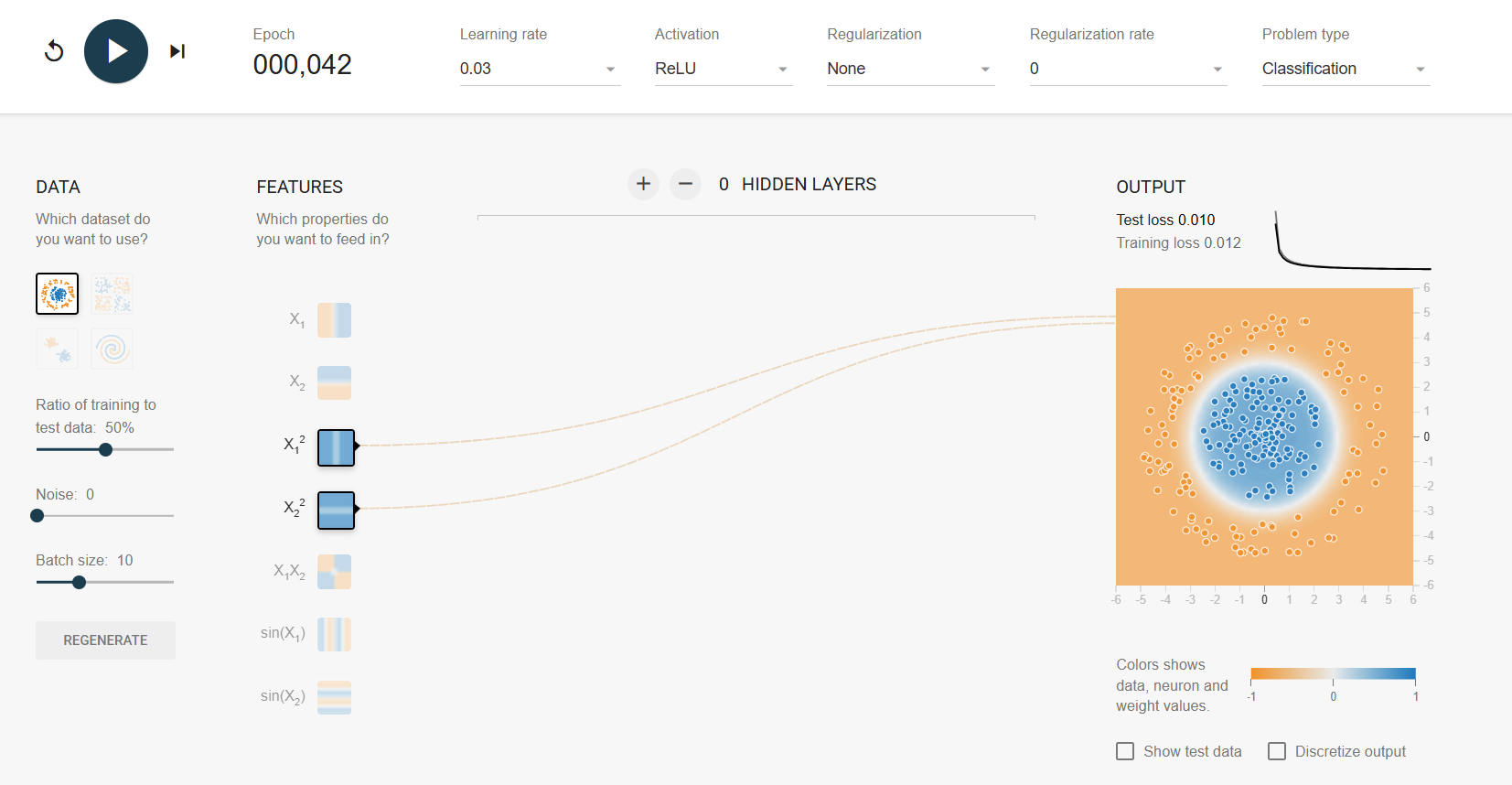
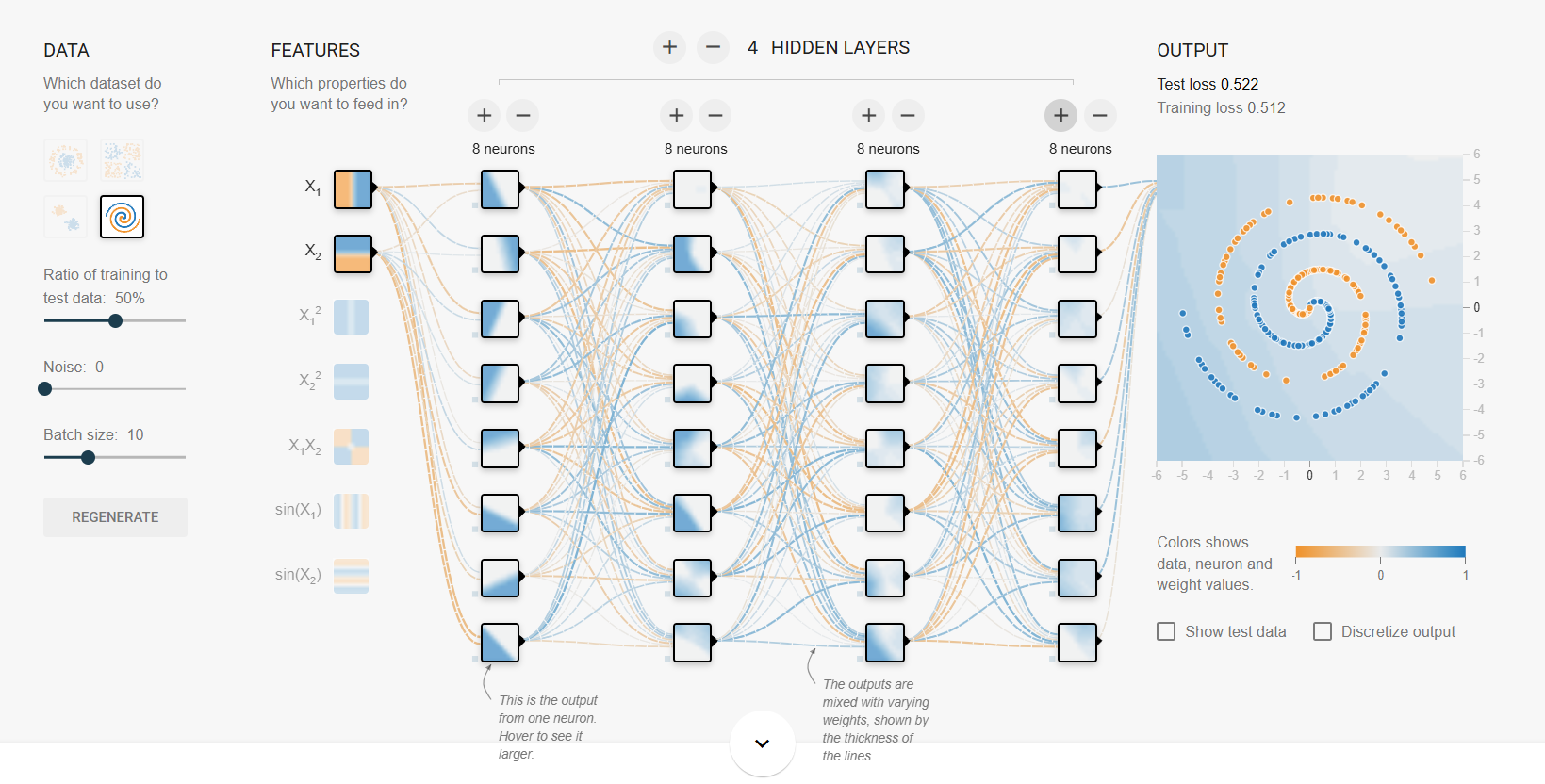
데이터를 움직여야 함
가중치: 데이터가 어디로 움직일지 결정
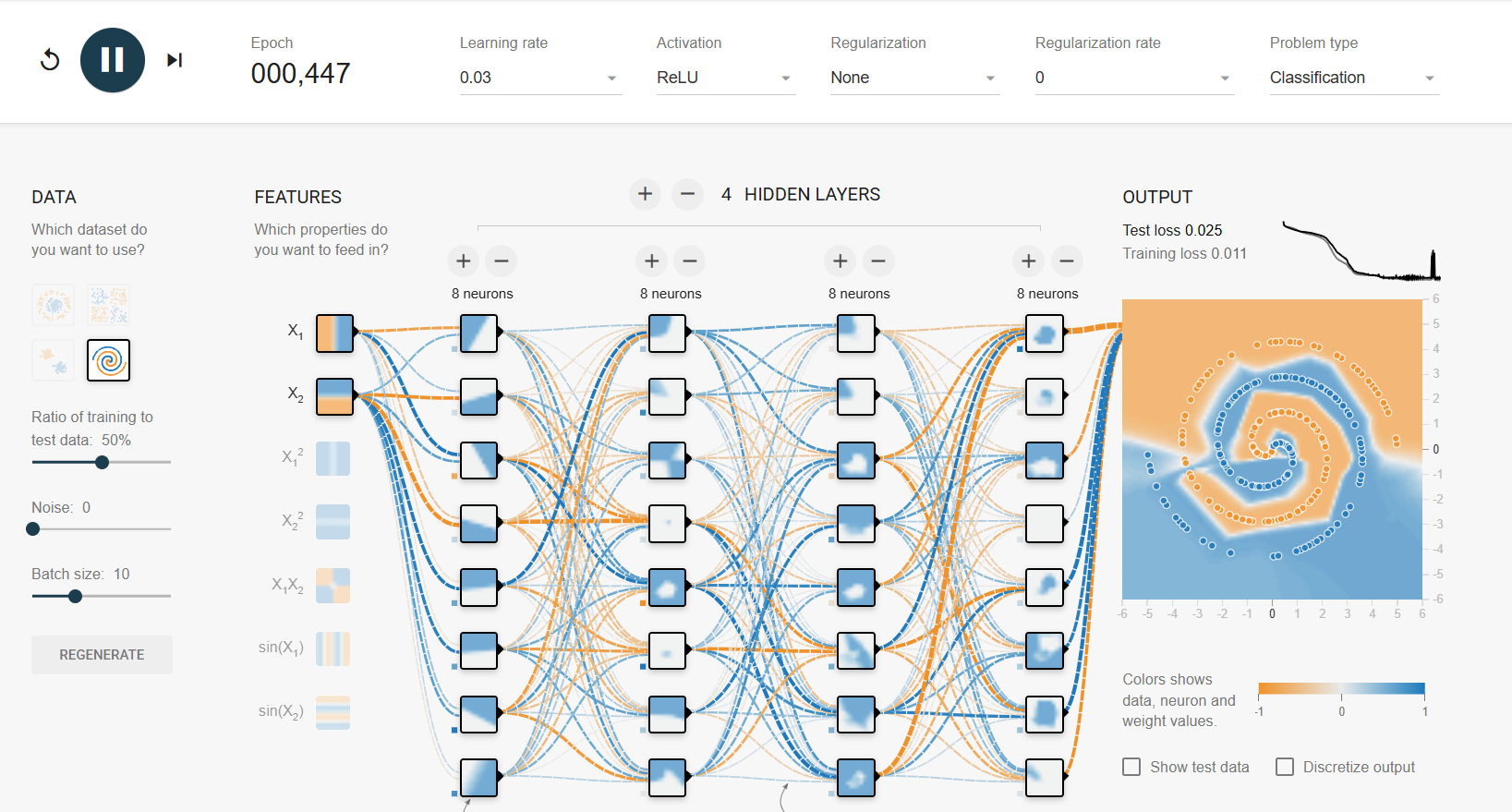
미니배치 "제너레이터"
→ yelid
PPT: AI Deep Learning
p.384
유향그래프
합에 대한 미분은 리피트
(덧셈 노드의 미분값은 리피트이다)
리피트에 대한 미분음 합
노드가 값을 기억할 필요 없음(그대로 바로 보내니까)
곱셈 노드는 값을 기억해 두어야 함
곱셈 노드의 뒤에서 온 미분값에
정방향 연산시 반대쪽 값을 곱한다.
곱노드 안쪽은 forward 값을 기억하고 있음!
relu
forward할 때 사용한 x 값 필요 → mask 이용
x의 값이 아닌 음수인 x의 "자리(위치)"를 기억!
sigmoid는 결과만 기업
행렬곱의 미분
Afffine 계층
bias는 sum을 하면 됨
softmax with loss 계층
실제값 & 예측값 기억하면 됨
6장
p.453
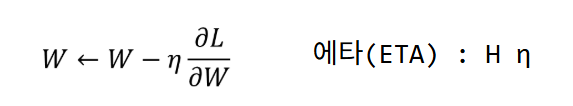
param: dict 형태
모멘텀 옵티마이저
"가속도"(v) 개념 도입
AdaGrad
gradient 제곱
모멘텀은 액셀레이터를 붙였다면(속도를 붙임) AdaGrad는 브레이크를 붙인 것과 같음(방향을 붙임)
RMSprop 브레이크 강도를 조절할 수 있음 (decay_rate 파라미터) → 방향을 더 섬세하게 다룸
가중치 초깃값
활성화 함수: 기울기 소실 문제 해소하려면
- w의 범위를 제한 하면 됨
- 0.01로 제한 했을 경우 가운데로 활성화 값이 모이는 문제가 발생한다.
- 글로로트 초기화 히 초기화
배치정규화
표준정규분포
