목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. 음성 특징 추출 기술 발전 흐름
3. 음성 관련 프레임워크 및 패키지, 기술 분류
4. 실습
B. 2교시
1. 실습: 오디오 분류
C. 3교시
1. 한국어 베이스 모델로 재학습
2. 내 목소리로 모델 테스트
3. 실습: 자동 음성 인식
Ⅱ. 오후 수업
A. 4교시
1. Cursor AI 활용
B. 5교시
1. Firebase
2. Vercel
C. 6교시
1. 바이브 코딩(vibe-coding) 포인트
Ⅲ. CAREER UP
모의면접 & 자율학습Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
- 음성 데이터 구조 및 전처리 방법
- 아날로그와 디지털
- 아날로그 신호: 연속적인 값 / 시간의 흐름에 따라 부드럽게 변함 / 원하는 사잇값을 원하는 만큼 생성 가능 (연속적인 값이니까)
- 디지털: 일정한 간격으로 샘플링(표본 추출)
- 샘플링 레이트
- 초당 몇 번 샘플링하는지
- 음성 데이터: 초당 44,100번이 표준 (→ 나이퀴스트-샤논 샘플링 이론에 근거)
- 샘플링 Hz와 가청 주파수 Hz 구분하기: 샘플링 Hz는 그만큼 추출하겠다는 것, 가청 주파수 Hz는 그만큼 진동한다는 것
- 아날로그와 디지털
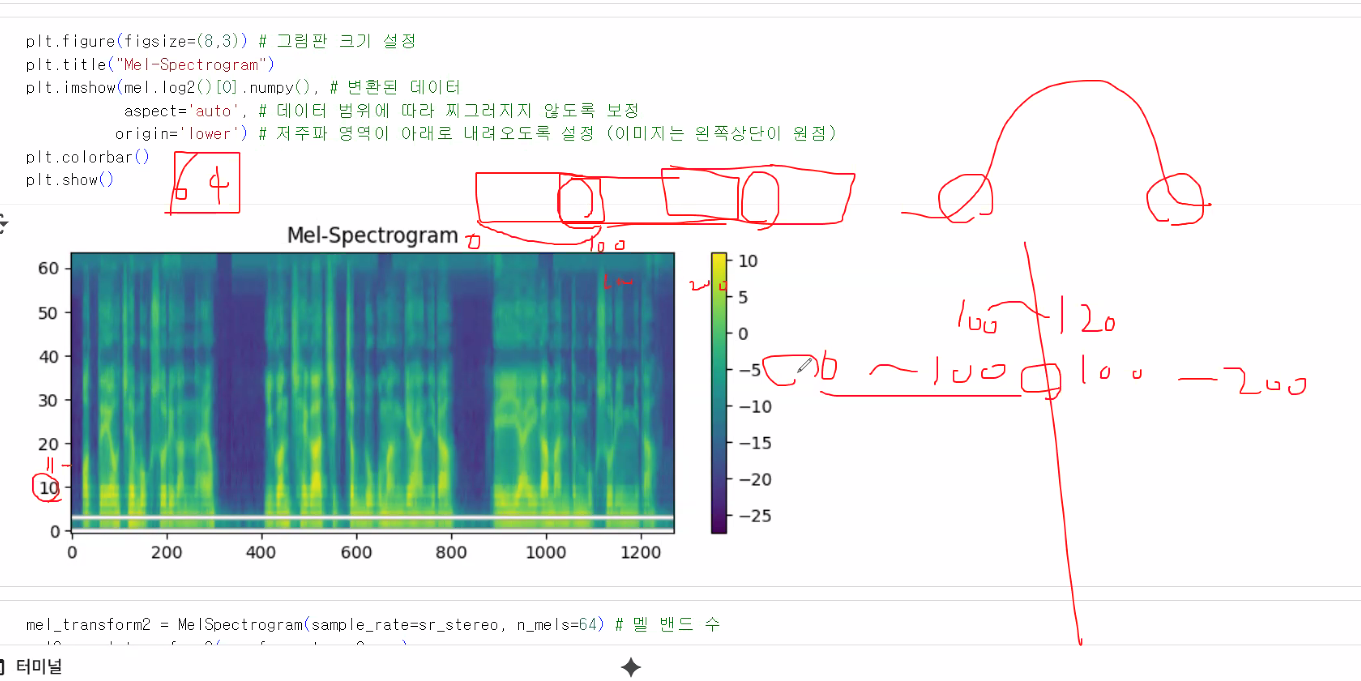
- MelSpectrogram과 MFCC
- MelSpectrogram
- default는 64개의 구간
- 각 구간별 Hz 영역 크기 다름: 초반은 작고 촘촘하게, 후반은 넓은 영역의 Hz를 설정
- 의미 상실 최소화하기 위해 영역별로 겹치는 부분이 있음 → 완전히 독립적인 feature가 아님
- MFCC
- MelSpectrogram base에서 한 번 더 추상화 진행
- MelSpectrogram 데이터를 기반으로 코사인 주기별 데이터 값을 추출한 알고리즘
- MelSpectrogram
최근에는 end-to-end 모델이 많이 나와서 raw waveform으로도 분석이 가능해졌음!
2. 음성 특징 추출 기술 발전 흐름
- 사람이 직접 관여한 feature에서 원본데이터를 직접 넣는 방향으로 점차 발전
- 핸드크래프트 특징의 효율성
- MFCC 13차원 × 수백 프레임 = 수천 개 feature
- 파형 그대로 넣는 것보다 훨씬 적은 차원으로도 좋은 성능.
- 당시엔 데이터/연산 자원이 부족했기 때문에 꼭 필요했음.
- Mel-Spec이 가장 흔하고, raw waveform은 리서치·대규모 모델에 집중되는 추세
| 시대/세대 | 주요 입력 특징 | 대표 활용 기술 | 장점 | 한계 |
|---|---|---|---|---|
| 1980s~2000s 초반 | MFCC (Mel-Frequency Cepstral Coefficients) | GMM-HMM 기반 ASR, 전통 화자 인식(i-vector) | - 사람 귀 모델링 반영 - 저차원(13~39D) → 계산 가벼움 | - 고주파·잡음에 취약 - 화자·채널 변화에 민감 - 프레임 간 연관성 약 |
| 2010s | Mel-Spectrogram / Log-Mel | DNN, CNN, RNN 기반 음향모델 (DeepSpeech, CNN-HMM hybrid 등) | - 더 풍부한 주파수-시간 정보 보존 - 이미지처럼 CNN 적용 가능 | - 여전히 handcrafted feature (STFT, Mel filterbank 필요) |
| 2016~현재 | Waveform 직접 입력 (raw audio) | End-to-End 모델 (WaveNet, wav2vec, HuBERT, Whisper 등) | - 특징 추출 자동 학습 - 큰 데이터로 “최적 특징”을 스스로 학습 - 잡음·화자 변화에 더 강함 | - 연산량↑, 대규모 데이터·모델 필요 - 작은 데이터셋 학습은 어려움 |
2차원 데이터 MelSectrogram을 이미지로 인식하고 CNN/RNN 연결하는 모델도 있음
3. 음성관련 프레임워크 및 패키지, 기술 분류
- 연구용/교육: Librosa, Torchaudio, SpeechBrain, ESPnet
- 전통적 ASR: Kaldi (지금도 baseline으로 강력)
- 최신 End-to-End ASR: wav2vec2, Whisper
- End-to-End는 아직까지는 속도도 느리고 요구 자원이 많아 분석 시간이 오래 걸려서 실용적이지 않음
- Whisper: 음성을 처리할 수 있는 여러 기술, 알고리즘, 테스크를 모아 하나의 프레임워크로 제작한 것
- TTS: Tacotron2, FastSpeech, HiFi-GAN
- 화자 인식/분할: pyannote.audio
- 분리/강화: Asteroid
- 배포: TFLite, ONNX, NeMo
| 분야 | 주요 목표 | 입력 특징 | 대표 기술/알고리즘 | 활용 사례 |
|---|---|---|---|---|
| 음성 전처리 (Speech Signal Processing) | 신호 정제 & 특징 추출 | Waveform, STFT | VAD(음성구간검출), 잡음제거, Mel-Spectrogram, MFCC | 녹음 전처리, ASR 입력 준비 |
| 자동 음성 인식 (ASR, Automatic Speech Recognition) | “사람이 말한 걸 문자로 바꾸기” | MFCC, Mel-Spec, (최근 Waveform) | HMM-GMM, DNN-HMM, CTC, RNN-Transducer, Transformer, Whisper | 자막 생성, AI 비서, 회의록 |
| 화자 인식 (Speaker Recognition) | “누가 말했는가?” | MFCC, i-vector, x-vector, speaker embedding | GMM-UBM, i-vector+PLDA, x-vector+DNN | 보안 인증, 출입 통제 |
| 화자 분할 (Speaker Diarization) | “언제 누가 말했는가?” | MFCC, Embedding | 군집화(K-means, Spectral), x-vector diarization, EEND | 회의 기록, 방송 자막 |
| 화자 분리 (Speech Separation) | “동시에 말한 목소리 분리” | Waveform, STFT (복소수) | ICA, NMF, PIT, Conv-TasNet, SepFormer | 회의 다화자 분리, 보청기 |
| 음성 합성 (TTS, Text-to-Speech) | “글자를 소리로 바꾸기” | 텍스트, phoneme | Concatenative, HMM-TTS, Tacotron, FastSpeech, WaveNet, HiFi-GAN | 음성 안내, 내레이션, AI 성우 |
| 키워드 스팟팅 (Keyword Spotting) | “특정 단어 탐지” | MFCC, Mel-Spec | DTW, GMM/SVM, CNN/DS-CNN, CRNN | “Hey Siri”, “OK Google” |
| 감정 인식 (Speech Emotion Recognition) | “말투로 감정 파악” | MFCC, Mel-Spec, Embedding | SVM, CNN+LSTM, Transformer | 상담 분석, 헬스케어 모니터링 |
| 음성 이해 (SLU, Spoken Language Understanding) | “말의 의미와 의도 해석” | 텍스트+Prosody | Intent classification, Joint ASR+NLU | AI 챗봇, 대화형 AI |
Whisper는 이미지 인식의 Ultralytics와 비슷한 흐름으로 만들어진 시스템
4. 실습
- 학습내용
- 오디오 분류 (audio classification)
- 자동 음성 인식 (Automatic Speech Recognition)
- 개요
- 딥러닝 모델의 손쉬운 공유 및 배포, 사용, 훈련을 가능하게 하는 프레임워크
- 성능이 검증된 pre-trained 모델을 무료로 다운받아서 사용
- 사용자의 작업에 맞게 모델을 fine-tuning 가능
- 제작/파인튜닝한 딥러닝 모델 공유
오디오 분류
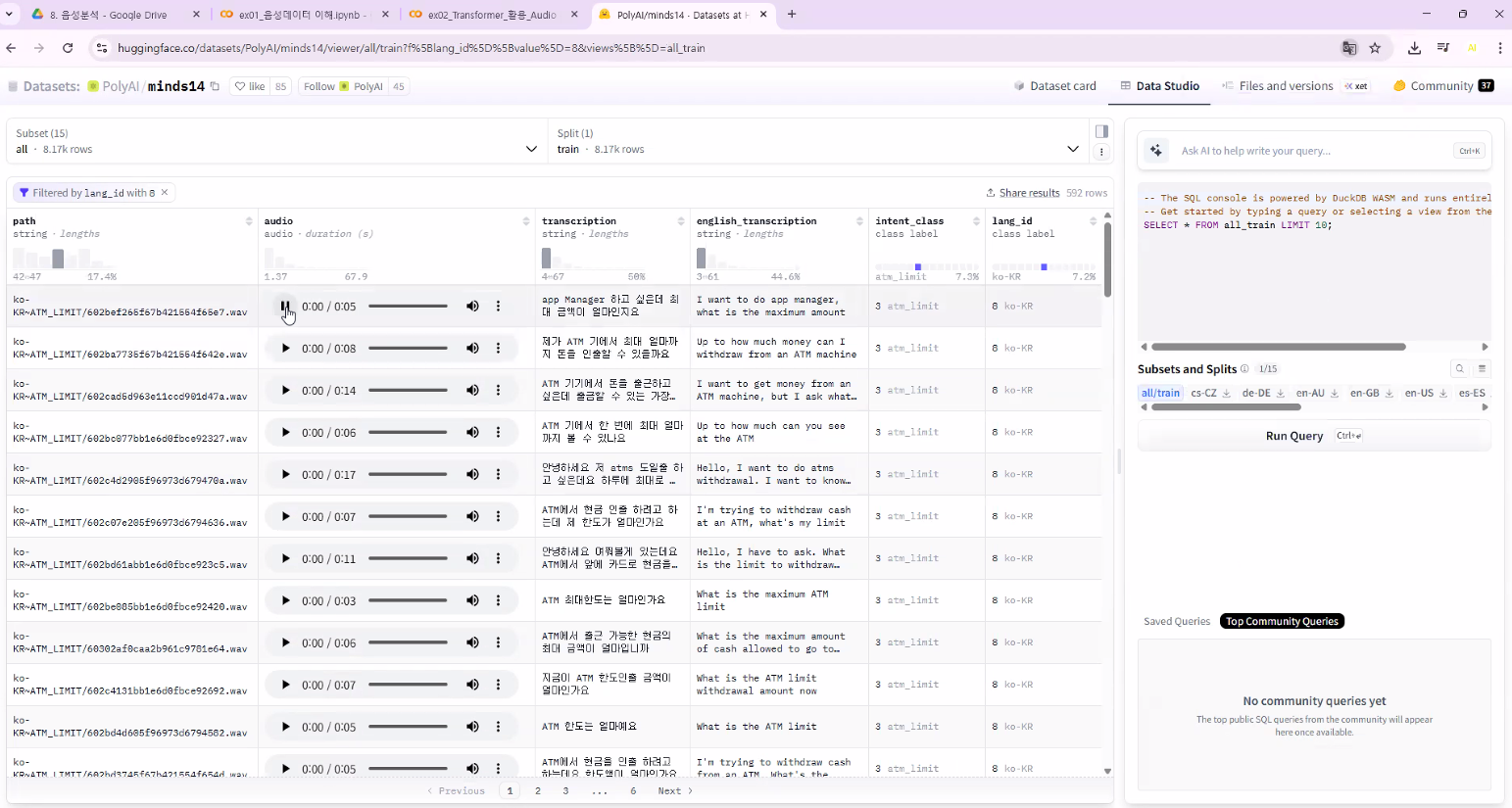
- MinDS-14 데이터셋 활용
- PolyAI/minds14
- 다국어(총 14개) → 한국어도 있음
- 카드사 관련 대화
- Wav2Vec 모델 파인 튜닝
- meta에서 만든 모델
- 자기 지도 학습(Self-supervised learning)을 기반으로 함
자기 지도 학습(Self-supervised learning)
레이블이 없는 대규모 데이터셋에서 학습 과제를 스스로 생성하여 학습하는 인공지능 기법입니다. 데이터 자체에서 암시적인 레이블을 만들거나, 데이터의 일부를 가리고 나머지 부분을 맞춰보는 등의 방식으로 학습하며, 대규모 언어 모델(LLM) 사전 학습 등에 주로 활용됩니다.
→ 단순 태스크의 경우 데이터만 넣어주면 스스로 문제와 답을 만들어 학습할 수 있음 → 지식을 쌓는 과정

허깅페이스 로그인
from huggingface_hub import notebook_login
notebook_login() # huggingface 토큰 입력해서 로그인하기데이터셋 로딩
from datasets import load_dataset, Audio- load_dataset: 데이터 로딩 함수
- Audio: 오디오 리샘플링용 클래스
origin = load_dataset(
"PolyAI/minds14" # 다운받을 저장소 이름
, name = "ko-KR" # 한국어 데이터 필터링
, split = "train" # train 데이터로 인식 → Dataset 클래스로 로딩
)
originDataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 592
})# 필요 없는 컬럼 삭제
remove_data = origin.remove_columns(["path", "transcription", "english_transcription", "lang_id"])
remove_dataDataset({
features: ['audio', 'intent_class'],
num_rows: 592
})# 훈련, 테스트 데이터 분리
audio_data = remove_data.train_test_split(test_size=0.2)
audio_dataDatasetDict({
train: Dataset({
features: ['audio', 'intent_class'],
num_rows: 473
})
test: Dataset({
features: ['audio', 'intent_class'],
num_rows: 119
})
})# 오디오 데이터 확인하기: 진폭
audio_data["train"][0]["audio"]["array"]array([0., 0., 0., ..., 0., 0., 0.], dtype=float32)# 오디오 데이터 확인하기: 샘플링 레이트
audio_data["train"][0]["audio"]["sampling_rate"]8000# 클래스 번호 확인하기
audio_data["train"][0]["intent_class"]6# 오디오 파일 플레이
info = audio_data["train"][0]["audio"].get_all_samples()
infoAudioSamples:
data (shape): torch.Size([1, 68267])
pts_seconds: 0.0
duration_seconds: 8.533375
sample_rate: 8000from IPython.display import display
import IPython.display
display(IPython.display.Audio(
info.data.squeeze().cpu().numpy() # squeeze(): 오디오 파일의 채널 차원 삭제
, rate = info.sample_rate # 오디오 샘플 레이트 입력 (파일의 샘플 레이트와 일치시켜야 함)
))
# 이 Audio class와 앞서 import한 Audio class는 다름
# 앞의 Audio class(datasets의 Audio 클래스)는 리샘플링용
# 이름이 겹치면 안 돼서 직접 import 안 함클래스 번호와 클래스명 매핑
labels = audio_data["train"].features["intent_class"].names
labels['abroad',
'address',
'app_error',
'atm_limit',
'balance',
'business_loan',
'card_issues',
'cash_deposit',
'direct_debit',
'freeze',
'high_value_payment',
'joint_account',
'latest_transactions',
'pay_bill']label2id, id2label = dict(), dict()
for i, label in enumerate(labels): # 클래스명과 인덱스 순번을 생성
label2id[label] = i # 클래스명 → 번호
id2label[str(i)] = label # 번호 → 클래스명
display(label2id)
display(id2label){'abroad': 0,
'address': 1,
'app_error': 2,
'atm_limit': 3,
'balance': 4,
'business_loan': 5,
'card_issues': 6,
'cash_deposit': 7,
'direct_debit': 8,
'freeze': 9,
'high_value_payment': 10,
'joint_account': 11,
'latest_transactions': 12,
'pay_bill': 13}
{'0': 'abroad',
'1': 'address',
'2': 'app_error',
'3': 'atm_limit',
'4': 'balance',
'5': 'business_loan',
'6': 'card_issues',
'7': 'cash_deposit',
'8': 'direct_debit',
'9': 'freeze',
'10': 'high_value_payment',
'11': 'joint_account',
'12': 'latest_transactions',
'13': 'pay_bill'}데이터 전처리
# 데이터 리샘플링
# wav2vec2 모델은 16,000Hz를 입력으로 받음 → 우리 데이터는 8,000Hz → 리샘플링 필요
resample_audio_data = audio_data.cast_column("audio", Audio(sampling_rate=16000))
# 샘플링 레이트 확인
resample_audio_data["train"][0]["audio"]["sampling_rate"]16000# 음성 데이터의 변화는 없음을 확인(단순 데이터 수만 늘어난 것)
info = resample_audio_data["train"][0]["audio"].get_all_samples()
display(IPython.display.Audio(
info.data.squeeze().cpu().numpy()
, rate = info.sample_rate
))전처리기를 사용한 데이터 포멧 변경
- 모델:
facebook/wav2vec2-xls-r-300m
# 전처리기 다운로드
model_name = "facebook/wav2vec2-xls-r-300m"
from transformers import AutoFeatureExtractor
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name)
def preprocessing_wav2vec2(examples):
# 오디오 클래스에서 진폭 데이터를 배열로 변경하기
audio_arrays = [x["array"] for x in examples["audio"]] # x: 하나의 오디오 클래스
# 전처리기 활용
inputs=feature_extractor(
audio_arrays # 데이터 연결
, sampling_rate=feature_extractor.sampling_rate # 샘플링 레이트 지정
, max_length=96000 # 오디오 파일의 최대 길이 설정: 6초 (1초에 16000개니까 16000 * 6 = 96000)
, truncation = True
) # 패딩 X, 최대 길이 96000 세팅
return inputs
encoded_data = resample_audio_data.map(
preprocessing_wav2vec2 # 전처리용 사용자 정의 함수 연결
, remove_columns="audio" # 오디오 코덱 클래스 삭제 (배열로 변경해 저장했기 때문에 더 이상 필요하지 않음)
, batched=True # 배치 단위 처리 허용
)
encoded_dataDatasetDict({
train: Dataset({
features: ['intent_class', 'input_values', 'attention_mask'],
num_rows: 473
})
test: Dataset({
features: ['intent_class', 'input_values', 'attention_mask'],
num_rows: 119
})
})# transformers로 학습 시 사용되는 정답 컬럼 이름으로 변경
encoded_data = encoded_data.rename_column("intent_class", "labels")
encoded_dataDatasetDict({
train: Dataset({
features: ['labels', 'input_values', 'attention_mask'],
num_rows: 473
})
test: Dataset({
features: ['labels', 'input_values', 'attention_mask'],
num_rows: 119
})
})B. 2교시
1. 실습: 오디오 분류
audio_data["train"]Dataset({
features: ['audio', 'intent_class'],
num_rows: 473
})C. 3교시
1. 한국어 베이스 모델로 재학습
2. 내 목소리로 모델 테스트
3. 실습: 자동 음성 인식
Ⅱ. 오후 수업
A. 4교시
1. Cursor AI 활용
- Cursor AI
- 자체 개발된 통합 개발 환경(IDE)에 AI 기능이 내장되어 있어, 코드 작성부터 구조 분석, 리팩토링, 디버깅까지 폭넓은 작업을 지원
- Visual Studio Code(VS Code)를 기반으로 만들어진 AI 코드 편집기
- vscode와 똑같은 환경 → import from vscode 했기 때문
- Firebase
- oracle, MySQL → 관계형 데이터베이스
- NoSQL → 데이터를 객체({key:value}) 형태로 저장
- firebase는 NoSQL
- cf. supabase는 관계형 데이터베이스
- Firebase 프로젝트 생성
- Realtime Database 선택
B. 5교시
1. Firebase
- 프로젝트 개요 → 앱 추가 → web 클릭
- script 태그 사용 클릭
2. Vercel
- Vercel
- 가입 후 cursor > terminal > new terminal >
npm i -g vercel - terminal에서
vercel login- enter 입력하면 웹사이트에서 연동 화면 뜸
- 연동 후 아래와 같이 진행
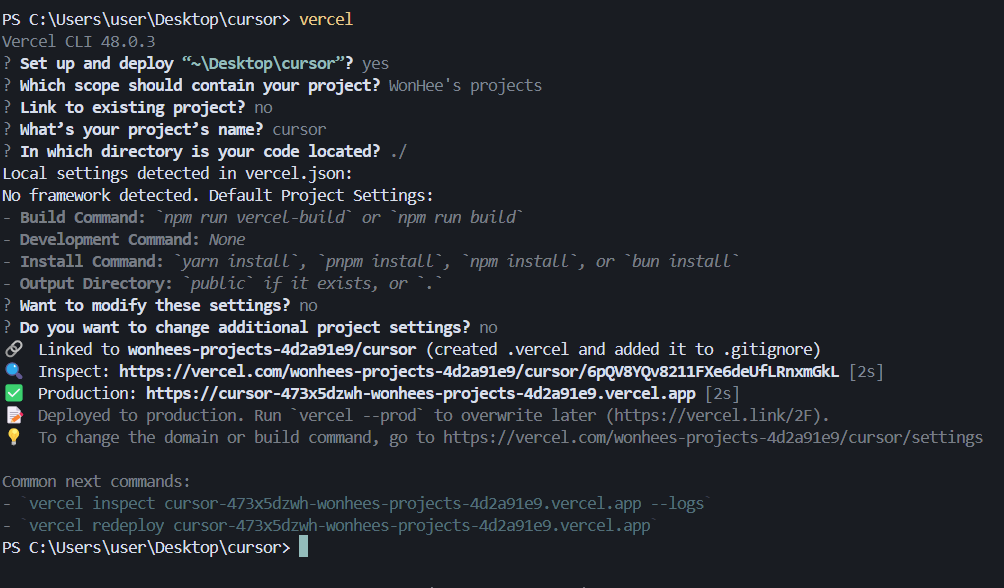
C. 6교시
1. 바이브 코딩(vibe-coding) 포인트
- 정확한 명령
- 데이터를 유지할 때 Firebsase 활용하기
- realtime database 사용
- config 설정값을 js 파일의 상단에 넣어주기
- html에서
<script type="module">넣어주기
- 완성된 사이트를 배포할 때는 vercel을 활용하기
- vercel 명령어
Ⅲ. CAREER UP
모의면접 & 자율학습

2 B R 0 2 B