[인공지능사관학교: 자연어분석A반] 음성 분석 / node.js (13)
목차
Ⅰ. 오전 수업
A. 1교시
1. 음성 분석 개요
B. 2교시
1. 실습
2. MelSpectrogram
C. 3교시
1. MelSpectrogram 시각화
2. MFCC
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
2. 게시글 작성 구현
B. 5교시
1. 게시글 작성 구현(cont.)
2. 게시글 수정 구현
C. 6교시
1. 게시글 수정 구현 (cont.)
2. 게시글 삭제 구현
Ⅲ. CAREER UP
현직자 특강
Ⅳ. 하루 돌아보기Ⅰ. 오전 수업
A. 1교시
- 학습 목표
- 아날로그와 디지털의 차이 이해
- 음성 데이터와 관련된 용어 이해
1. 음성 분석 개요
- SUPERTONE PLAY
- 나만의 클로닝 보이스 만들기: Voice Cloning Beta
- 추천 대본을 녹음하면 내 목소리를 복제한 TTS
- 나만의 클로닝 보이스 만들기: Voice Cloning Beta
아날로그와 디지털
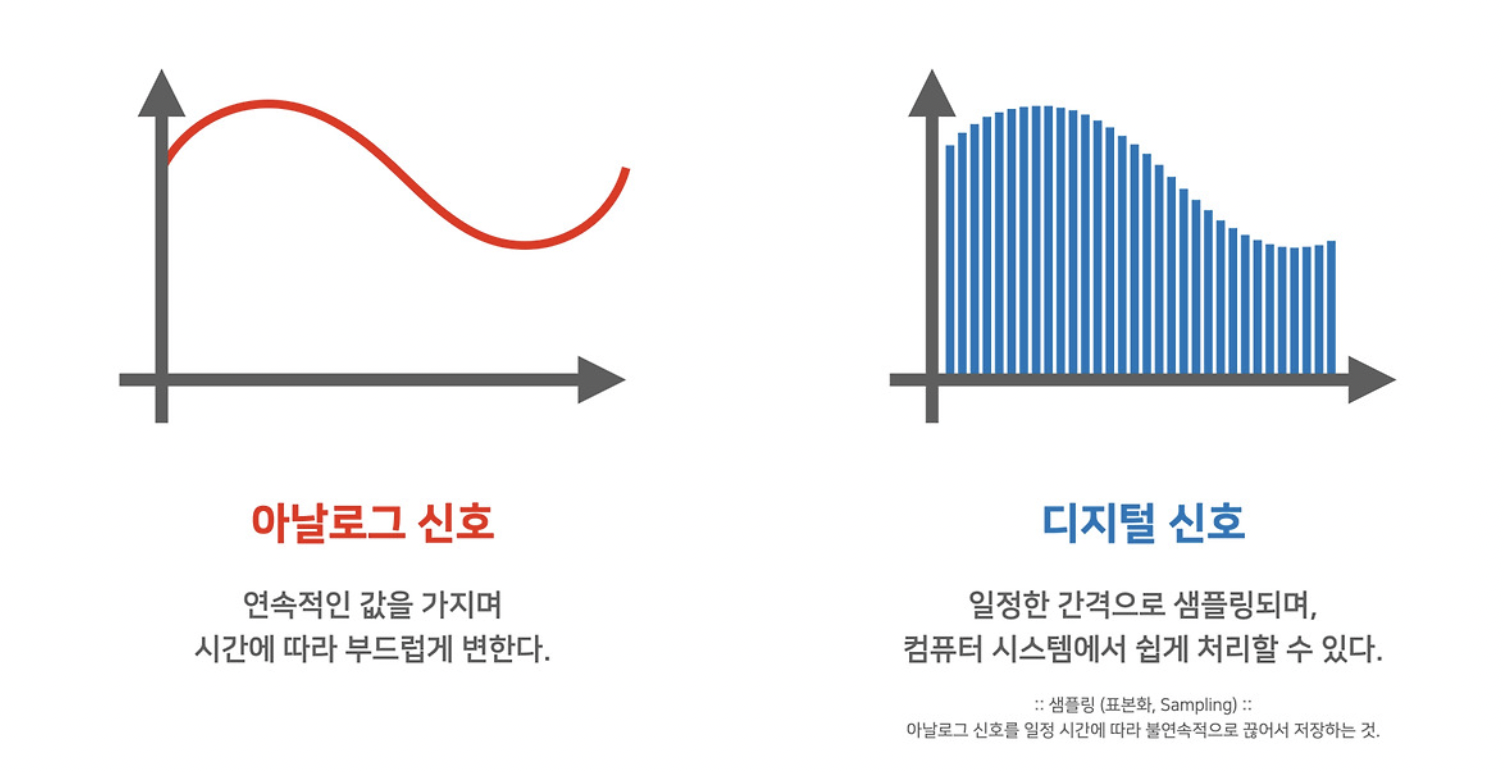
샘플링 레이트(sampling rate)
- 샘플링: 아날로그 오디오 신호를 디지털로 저장하는 과정 → 표본화(표본 추출)
- 연속적인 오디오 신호에서 일부 대표되는 값을 추출
- 레이트: 시간당 생플링 횟수
- 초 단위를 기준으로 저장
- 일반 음원 데이터의 경우 44.1kHz를 기본 샘플링 레이트로 사용
- 1초에 44,100번 샘플링
- cf. 비디오 → 초당 24회 ~ 30회
- 인간의 가청 주파수: 20Hz - 20kHz
- 주의: 샘플링의 Hz와 가청 주파수의 Hz는 의미가 약간 다름
- 나이퀴스트-섀넌 샘플링 이론
- 아날로그 신호를 디지털 신호로 변환할 때, 신호에 포함된 가장 높은 주파수의 두 배 이상의 속도로 샘플링하면 원래 신호를 손실 없이 복원할 수 있다는 원리
- 보통의 사람 목소리 주파수: 0 - 8kHz → 16kHz가 효율적
※ 샘플링의 Hz와 가청 주파수의 Hz는 의미와 적용 범위에서 차이가 있습니다.
- 샘플링 Hz란 무엇인가
- 샘플링 주파수(샘플링 레이트)의 Hz는 1초에 신호를 몇 번 측정(샘플링)하는지를 나타내는 값입니다. 예를 들어 44.1 kHz는 1초에 44,100번 신호를 측정한다는 뜻입니다. 주로 디지털 오디오에서 신호를 연속(아날로그)에서 이산(디지털) 값으로 바꿀 때 쓰입니다.
- 가청 주파수의 Hz란 무엇인가
가청 주파수의 Hz는 실제로 사람이 들을 수 있는 소리의 높고 낮음을 나타내는 값입니다. 1Hz는 1초에 1번 진동하는 소리, 1kHz는 1초에 1,000번 진동하는 소리와 같습니다. 일반적으로 사람의 가청 주파수 범위는 약 20Hz에서 20kHz입니다.- 차이점 요약
- 샘플링 Hz: 초당 신호를 측정하는 횟수 (디지털 오디오 신호 처리의 기준).
- 가청 주파수 Hz: 인간이 들을 수 있는 실제 소리의 진동수 (소리의 높낮이 나이, 소리의 종류 결정).
- 관계: 이론적으로 소리 신호(아날로그)를 손실 없이 복원하려면, 샘플링 속도가 소리의 최대 주파수(가청 주파수)의 두 배 이상이어야 한다는 나이퀴스트 정리가 있습니다.
- 즉, 샘플링 Hz는 신호 캡처의 빈도(속도)이고, 가청 주파수 Hz는 실제 소리의 높이를 의미합니다. 둘 다 단위는 동일하지만, 의미와 대상이 다릅니다.
B. 2교시
1. 실습
# 관련 라이브러리 설치
!pip install --q --upgrade torch torchaudio
import torch
import matplotlib.pyplot as plt
from torchaudio.transforms import MelSpectrogram, MFCC-
파이썬에서 가장 많이 쓰이는 오디오 라이브러리는 Librosa 라이브러리이지만 오늘 실습에서는 PyTorch에서 제공하는 torchaudio를 사용
-
MelSpectrogram, MFCC
- 음성 인식 기본 알고리즘
- 음성 데이터가 가지고 있는 특징을 데이터화 → 딥러닝 모델이 학습하기 쉽도록 만듦
- MFCC는 Mel Frequency Cepstral Coefficients의 약어로, 음성 신호의 특징을 추출하는 기술 중 하나
- Mel Spectrogram 은 주파수가 Mel Scale 로 변환되는 Spectrogram → 음성 데이터를 raw data를 그대로 사용하면 파라미터가 너무 많아지기도 하고 데이터 용량이 너무 커지므로 보통 mel spectrogram을 많이 사용
-
한국어.wav
-
안녕하세요.wav
로그적 감각: 베버-페히너의 법칙
베버-페히너 법칙은 물리적인 자극의 변화와 지각되는 감각의 변화 사이의 관계를 설명하는 심리물리학적 법칙으로, 자극의 세기가 강해질수록 동일한 감각 변화를 느끼기 위해서는 더 큰 자극의 변화가 필요하다는 것을 의미합니다. 즉, 덜 강한 자극일 때는 작은 변화에도 민감하게 반응하지만, 강한 자극일 때는 상대적으로 훨씬 큰 변화가 있어야만 그 변화를 감지할 수 있습니다.
- 법칙의 내용
- 베버의 법칙: 동일한 감각 변화를 느끼기 위해서는 처음 자극의 크기에 비례하여 자극의 변화량이 필요하다는 것을 발견했습니다.
- 페히너의 법칙: 베버의 법칙을 수식화하여, 감각의 세기는 자극의 물리적인 양의 로그값에 비례한다는 것을 보였습니다. 즉, '감각의 세기 = 상수 × log (자극의 세기)'로 표현될 수 있습니다.
- 예시
- 무게: 가벼운 물체일 때는 작은 무게 변화에도 민감하게 반응하지만, 매우 무거운 물체를 들 때는 더 큰 무게 변화가 있어야 동일하게 느낄 수 있습니다.
- 밝기: 어두운 환경에서는 작은 밝기 변화에도 즉각 반응하지만, 밝은 환경에서는 더 큰 밝기 변화가 있어야 인지할 수 있습니다.
- 소리: 조용한 곳에서는 작은 소리 변화도 잘 들리지만, 시끄러운 환경에서는 훨씬 큰 소리 변화가 있어야 그 변화를 감지할 수 있습니다.
- 활용 분야
- 이 법칙은 인간의 감각 특성을 설명하며, 데시벨(dB)과 같은 로그 함수 값이 인간의 감성과 밀접하게 연관되어 있다는 것을 보여주므로, 심리학, 생리학뿐만 아니라 마케팅, 디자인 등 다양한 분야에서 활용됩니다.
음원 로딩하기
- torchaudio.load(): 두 개의 리턴값이 발생
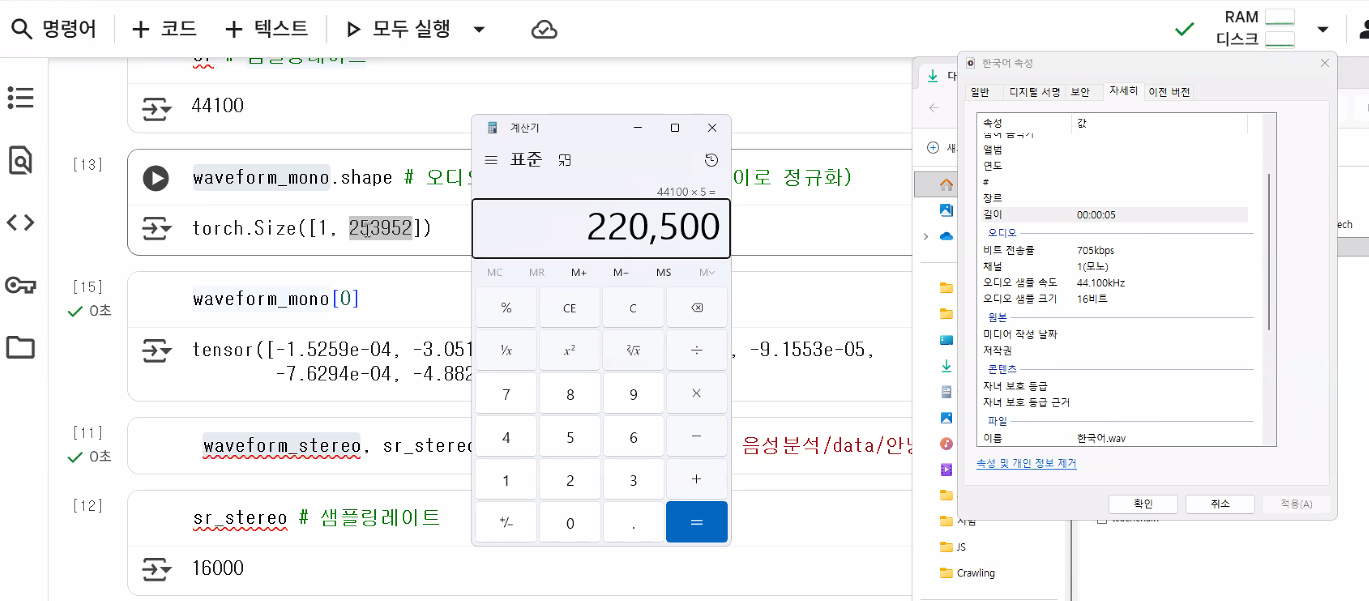
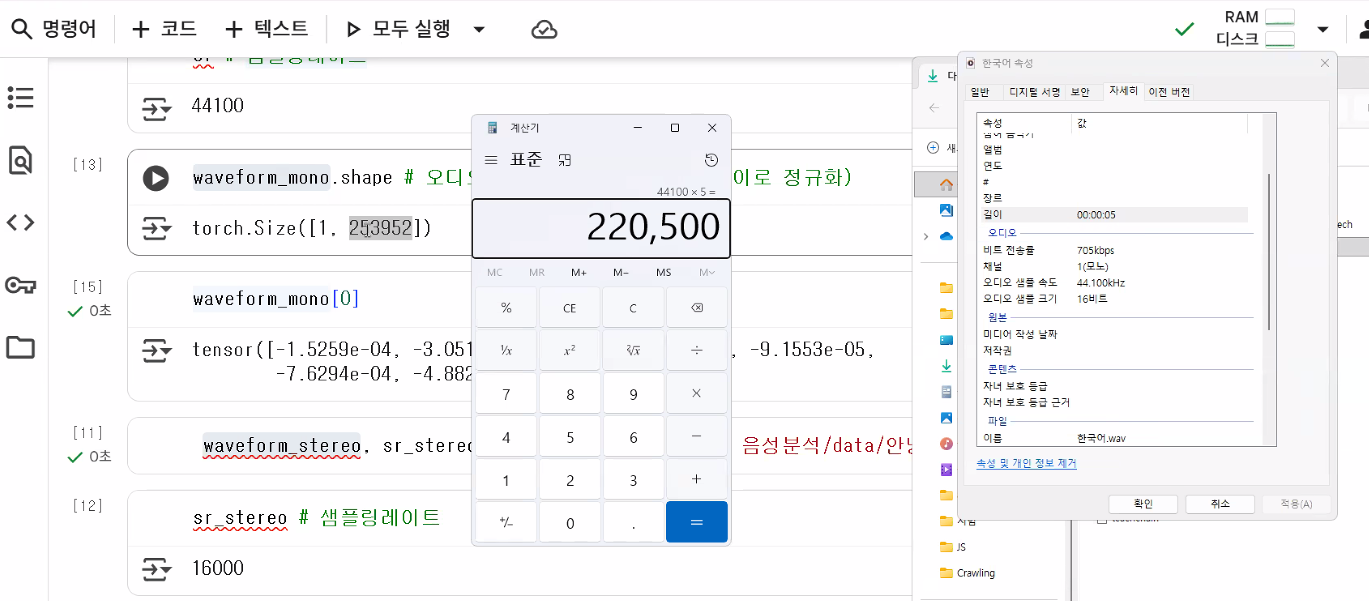
waveform_mono, sr = torchaudio.load("./data/한국어.wav")
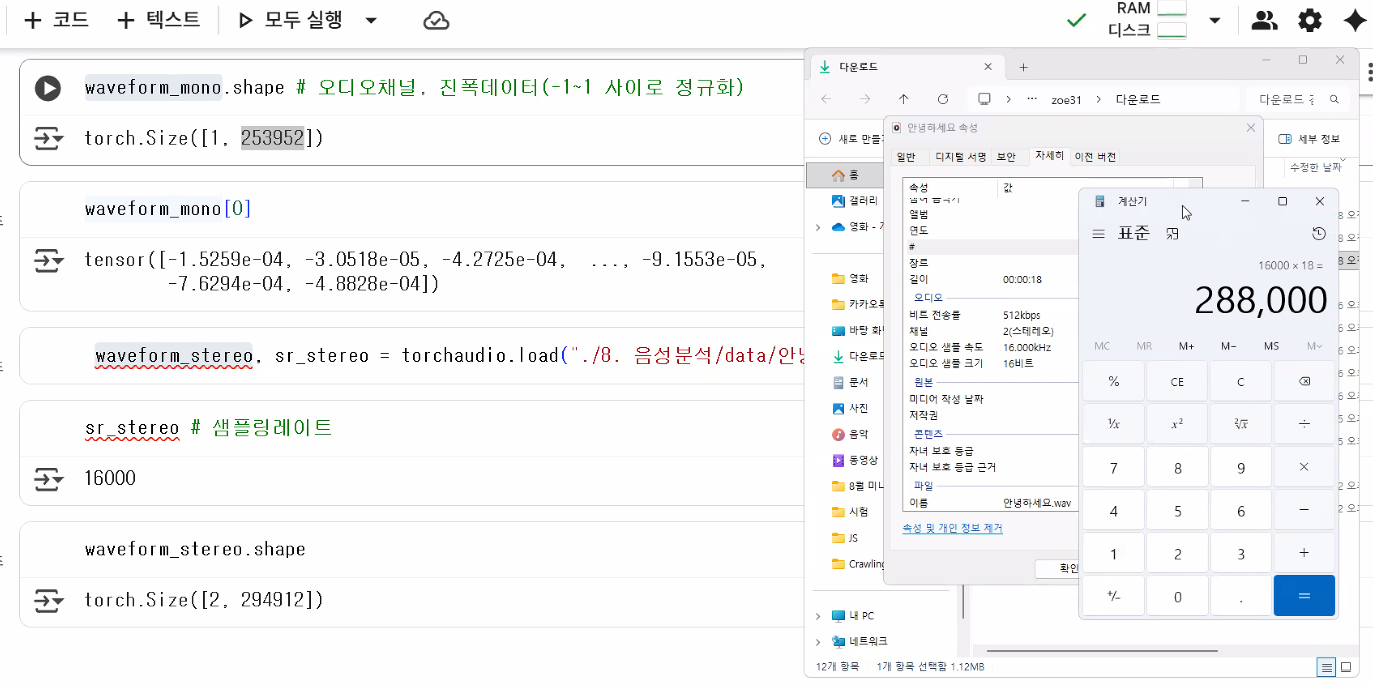
sr # sampling rate44100waveform_stereo, sr_stereo = torchaudio.load("./data/안녕하세요.wav")
sr_stereo16000torchaudio로 오디오 파일을 로드할 때 표시된 경고는, 앞으로 torchaudio.load 함수의 내부 구현과 관련된 변경 사항 및 기존 기능의 사용 중단(deprecation) 안내입니다.
따라서, 위 경고문은 현재 코드는 정상 동작하지만, torchaudio 및 PyTorch 관련 오디오 처리 코드의 미래 호환성 차원에서 torchcodec 사용을 준비하라는 안내입니다.
- 안내문 의미
- torchaudio.load의 내부 동작 변경 예정
- 앞으로 torchaudio.load는 내부적으로 torchcodec 라이브러리의 AudioDecoder를 직접 사용하도록 변경될 예정임을 알리고 있습니다.
- 일부 파라미터가 무시될 예정
- 현재 인자로 사용할 수 있던
normalize,format,buffer_size,backend파라미터 등이 무시될 계획임을 공지하고 있습니다.- torchaudio.io.StreamReader의 사용 중단
- 오디오 디코딩 및 인코딩 관련 기능이 더 이상 torchaudio에 남지 않고, torchcodec 라이브러리에서 통합 관리될 것임을 안내합니다.
관련된 자세한 논의는 PyTorch 공식 깃허브(https://github.com/pytorch/audio/issues/3902)에서 확인할 수 있습니다.- 향후 지원 중단 일정
- 이러한 변화는 torchaudio 버전 2.9부터 적용되며, 예전 방식은 곧 사라질 예정입니다.
- 원인
- PyTorch의 오디오/비디오 디코딩·인코딩 기능이 별도의 torchcodec 패키지로 이동됨에 따라, torchaudio의 기능들이 점점 더 유지보수(downgrade) 단계로 들어가고 있고, 이에 따라 코드 마이그레이션(이전)이 필요한 시점임을 알려줍니다.
- 조치 방법
- 앞으로는 torchaudio.load 대신에 torchcodec.decoders.AudioDecoder를 직접 사용하는 것이 권장됩니다.
- 코드 호환성 및 향후 업그레이드를 위해 안내에 따라 미리 코드 구조를 torchcodec 기반으로 점진적으로 바꿔두는 것이 좋습니다.
waveform_mono.shape # 오디오 채널, 진폭 데이터torch.Size([1, 253952])waveform_stereo.shapetorch.Size([2, 294912])torch.Size([오디오 채널, 진폭 데이터])- 오디오 채널은 mono(1 → 이어폰 양쪽 같은 소리), stereo(2 → 이어폰 한쪽씩 다른 소리)
- 진폭 데이터는 -1 ~ 1 사이의 값으로 정규화가 되어 있음
- 목소리 크기(volume)
waveform_mono[0]tensor([-1.5259e-04, -3.0518e-05, -4.2725e-04, ..., -9.1553e-05,
-7.6294e-04, -4.8828e-04])모노는 단일 채널 오디오이며, 모든 오디오 정보가 한 채널로 들어갑니다. 예를 들어, 노래나 음악이 하나의 마이크로 녹음된 경우 모노로 녹음됩니다. 모노 오디오는 한 스피커로 재생되며, 스피커에서 들리는 사운드는 한 지점에서만 들립니다. 따라서, 모노 오디오는 듣는 사람에게 공간감을 느끼게 해주지 않습니다.
스테레오는 두 개 이상의 채널로 녹음되어 공간감을 더해주는 기술입니다. 스테레오 오디오는 왼쪽(L) 채널과 오른쪽(R) 채널로 분리되어 녹음되어, 스피커의 좌우에 각각 다른 채널이 들어가며, 좌우 각각의 스피커에서 나오는 소리는 서로 다릅니다. 이것이 스테레오 오디오가 생동감 있는 사운드를 만드는 이유입니다.
# 분석 경우에 따라서 스테레오를 모노로 변경할 필요도 있음
waveform_stereo2mono = torch.mean(waveform_stereo, dim=0, keepdim=True)
waveform_stereo2mono.shapetorch.Size([1, 294912])오디오 스테레오를 모노로 변환하는 원리는 스테레오 트랙의 좌우 두 채널 신호를 합쳐 하나의 단일 채널로 만드는 것입니다. 이 과정에서 각 채널의 소리가 더해지거나, 선택적으로 한 채널의 소리만 사용되어 하나의 스피커에서 동일한 소리가 재생되도록 합니다.
- 자세한 원리
- 채널 병합: 스테레오 오디오는 왼쪽(L) 채널과 오른쪽(R) 채널이라는 두 개의 독립적인 음향 채널을 사용합니다. 모노로 변환할 때는 이 두 채널의 신호가 하나로 합쳐집니다.
- 신호 처리:
- 가중치 없는 합산: 가장 일반적인 방법으로, 왼쪽 채널의 신호와 오른쪽 채널의 신호의 크기(게인)를 동일하게 하여 더해주는 방식입니다.
- 채널 분리 및 재조합: 경우에 따라서는 두 채널의 소스를 각각의 모노 파일로 분리한 뒤, 필요한 정보만 선택적으로 사용하거나 재조합하여 모노 신호를 만들기도 합니다.
- 단일 출력: 이렇게 합쳐진 하나의 단일 채널 신호는 스테레오 스피커나 헤드폰의 왼쪽과 오른쪽 모두에 동일하게 전송되어 재생됩니다. 따라서 스테레오에서 느꼈던 좌우 분리된 공간감은 사라지고, 모든 소리가 중앙에서 나는 것처럼 들리게 됩니다.
- 왜 모노로 변환하는가?
- 호환성: 특정 시스템에서는 스테레오 재생이 지원되지 않거나, 모노 출력으로만 재생해야 하는 경우가 있습니다.
- 문제 해결: 스테레오 녹음에서 한쪽 채널만 소리가 나거나 다른 문제가 발생했을 때, 모노로 변환하여 문제를 해결할 수 있습니다.
- 특정 효과: 믹싱 과정에서 의도적으로 스테레오 소스를 모노로 변환하여 사운드의 방향성을 없애거나, 공간감을 줄이는 등 특정 효과를 주기 위해 사용하기도 합니다.
2. MelSpectrogram
- 주파수 특성대에 따라 분포도를 확인 → 구간화
- 주파수 영역대에 따른 에너지(데이터) 크기 확인
- 더 알아보기
MelSpectrogram은 소리를 인간의 청각 특성과 유사하게 해석하기 위해 고안된 스펙트로그램으로, 특히 주파수 변화에 대한 인간의 민감도를 반영합니다.
- Mel Scale과 인간 청각
- 인간 귀는 저주파(예: 500-1000 Hz) 변화에는 예민하게 반응하지만, 고주파(예: 10000-20000 Hz) 변화에는 둔감합니다.
- 음성 신호를 인식할 때 주파수를 linear scale로 인식하는게 아님
- 똑같은 500 Hz 간격의 변화라 해도, 저주파에서는 구분하기 쉽고 고주파에서는 구분하기 어렵게 느껴집니다.
- 낮은 주파수를 높은 주파수보다 더 예민하게 받아들임
- 즉 500 ~ 1000 Hz 가 바뀌는건 예민하게 인식하는데 10000Hz ~ 20000 Hz가 바뀌는 것은 잘 인식 못함
- Mel Scale은 이런 특성을 반영해, 실제 주파수를 멜 단위로 변환합니다.
- 변환 공식은 $$ \text{Mel}(f) = 2595 \log(1 + \frac{f}{700}) $$입니다.
- 인간 귀는 저주파(예: 500-1000 Hz) 변화에는 예민하게 반응하지만, 고주파(예: 10000-20000 Hz) 변화에는 둔감합니다.
- MelSpectrogram 생성 원리
- 음성을 프레임별로 나누어 각각에 대해 푸리에 변환(특히 STFT: Short-Time Fourier Transform)을 적용해 시간-주파수 정보를 얻습니다.
- Linear frequency scale이 아니라, 인간이 더 예민하게 구분하는 저주파 영역에서는 해상도를 촘촘하게, 고주파 영역에서는 해상도를 느슨하게 하는 mel filter bank를 적용합니다.
- 이렇게 변환된 결과는 인간의 청각 민감도를 반영한 Frequency representation이 됩니다.
- 왜 Mel Scale을 쓰는가
- Spectrogram의 y축을 Linear 대신 Mel로 바꾸면, 사람이 실제 소리를 인식하는 방식에 더욱 근접한 지표를 얻을 수 있습니다.
- 저주파대 변화에는 더 민감하게, 고주파대 변화에는 덜 민감하게 신호의 특징이 표현됩니다.
- 음성 인식 등 인간 청각과 관련된 딥러닝 모델의 입력 데이터로 적합합니다.
- 정리
- MelSpectrogram은 저주파 변화(500-1000 Hz)는 촘촘히, 고주파 변화(10000-20000 Hz)는 상대적으로 너그럽게 처리하는 Mel Scale을 적용합니다.
- 이는 인간이 주파수를 인식하는 방식(저주파 변화에 민감, 고주파에는 둔감)을 반영한 것입니다.
- 이처럼 MelSpectrogram은 인간의 주파수 인식 특성과 딥러닝의 효율적 특징 추출이라는 두 가지 목표를 함께 달성할 수 있는 특성을 가집니다.
# 음원의 진동수 범위를 64개의 영역으로 나눠서 각 진동에 분포하는 특성을 추출
# 멜 밴드를 64개로 설정하더라도 각 구간이 균등하지 않음
# 초반 구간은 영역이 촘촘하게(좁은 범위) 구성되고 후반 구간은 넓은 범위를 가지게 된다 → 사람의 청력이 가지는 로그적 특성을 반영
mel_transform = MelSpectrogram(sample_rate=sr, n_mels=64) # 멜 밴드 수
mel = mel_transform(waveform_mono)
mel.shapetorch.Size([1, 64, 1270])C. 3교시
1. MelSpectrogram 시각화
# 시각화
plt.figure(figsize=(8, 3)) # 그림판 크기 설정
plt.title("Mel-Spectrogram")
plt.imshow(
mel.log2()[0].numpy() # 변환된 데이터
, aspect = "auto" # 데이터 범위에 따라 찌그러지지 않도록 보정
, origin = "lower" # 저주파 영역이 아래로 내려오도록 설정(이미지는 왼쪽 상단이 원점)
)
plt.colorbar()
plt.show()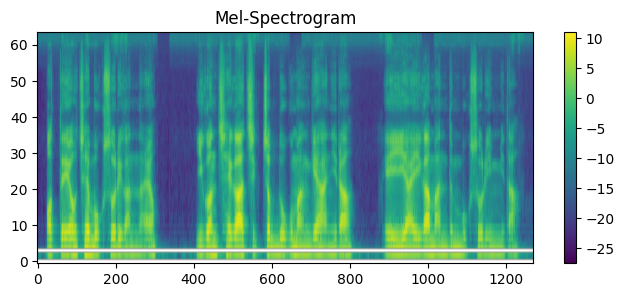
- imshow는 이미지 출력이라 원점이 왼쪽 상단임 → 저주파 영역이 아래로 내려오도록 설정(origin = "lower")
- MelSpectrogram 적용 이후부터는 더 이상 시간 단위 X → 음원의 프레임 단위로 전환!
- window, hop_length → CNN의 window, stride와 비슷한 역할
- 청력 관련 로그(log) 적용 포인트
- dB →
mel.log2()[0].numpy() - 주파수 → mel band
- dB →
mel_transform2 = MelSpectrogram(sample_rate=sr_stereo, n_mels=64) # 멜 밴드 수
mel2 = mel_transform2(waveform_stereo2mono)
mel2.shapetorch.Size([1, 64, 1475])- mel2: 여성목소리 → 고주파 영역에 값이 상대적으로 많이 분포되어 있음
plt.figure(figsize=(8,3)) # 그림판 크기 설정
plt.title("Mel-Spectrogram")
plt.imshow(mel2.log2()[0].numpy(), # 변환된 데이터
aspect='auto', # 데이터 범위에 따라 찌그러지지 않도록 보정
origin='lower') # 저주파 영역이 아래로 내려오도록 설정 (이미지는 왼쪽상단이 원점)
plt.colorbar()
plt.show()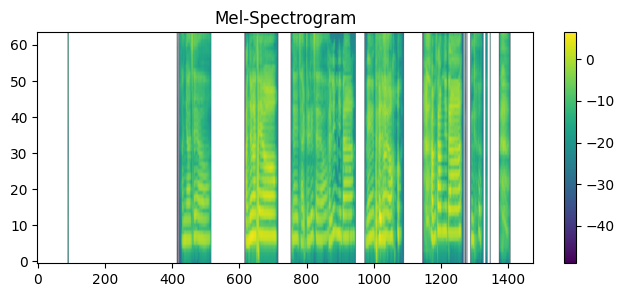
2. MFCC
- Mel-spectrogram 데이터의 특징
- 1차 변환을 거치긴했지만 데이터의 크기가 여전히 크다 → 괜찮은 신경망이 아니면 학습하기 어려울 수 있음(도메인 난이도에 따라 다름)
- 각 멜 밴드 구간의 측정값이 서로 독립성을 가지고 있지 않음 → 통계적 기법을 활용하기에 어려움
- MFCC
- mel-spectrogram 결과를 기반으로 코사인 주기별 값을 추출하는 알고리즘
- 64개의 멜 밴드 → 코사인 주기도 64개로 구성하여 추출
- 초반 13개는 스펙트럼의 큰 윤곽(사람 목소리 음색)등을 가지고 있고 14이후 후반은 스펙트럼의 빠른 진동(노이즈 등)을 가지고 있음
- 음성인식에서는 초반 13개를 사용하는 편
- 용량압축효과, 일부 노이즈제거 효과, 각 코사인주기별 특성추출이기 때문에 독립성을 갖춘 피쳐로 완성됨
mfcc_transform = MFCC(sample_rate=sr, n_mfcc=13)
mfcc = mfcc_transform(waveform_mono)
mfcc.shapetorch.Size([1, 13, 1270])
- MFCC
- MelSpectrogram 먼저 수행 + 추가 후처리 작업 진행한 결과물
- MelSpectrogram은 원본에 비하면 요약된 편이지만 그래도 데이터 양이 많음 & 64개의 feature가 완전히 독립적인 성격을 띄지 않음(3개 정도 겹침)
- 정보의 완벽한 분리가 필요(for 통계 모델) → MFCC의 등장
- MelSpectrogram의 결과를 기준으로 코사인 주기 64가지 적용 → 주기성 데이터를 추출
- 잡음 제거 효과도 있음
- n_mfcc=13: 몇 개의 주기성 데이터를 사용할 것인지
- 1~13: voice
- 14~64: 노이즈, 배경
- 데이터 압축 효과 / feature 독립성(특정 주기에 관련된 것만 측정했기 때문)
- 통계적 특징을 가진 모델을 사용할 때는 MFCC 사용하기
# 시각화
plt.figure(figsize=(8, 3)) # 그림판 크기 설정
plt.title("MFCC")
plt.imshow(
mfcc[0].numpy() # 변환된 데이터
, aspect = "auto" # 데이터 범위에 따라 찌그러지지 않도록 보정
, origin = "lower" # 저주파 영역이 아래로 내려오도록 설정(이미지는 왼쪽 상단이 원점)
)
plt.colorbar()
plt.show()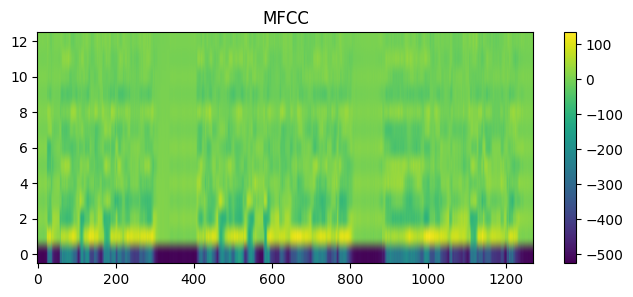
- 분류와 분리 구분하기
- 분류: 화자가 누구인지, 말한 단어가 무엇인지(단어 구분)
- MelSpectrogram, MFCC만 가지고도 충분히 가능함
- 예: "사과" 단어 → 발음하는 음성 데이터마다 사과 라벨링 → 모델이 패턴 파악 후 분류 가능("A 패턴이 나오면 '사과'를 말한 것이다.")
- 분리: 두 명 이상의 화자 → 데이터 분리 개념
- 예: 통화 데이터에서 특정 소음(유리 깨지는 소리, 큰 소음 등)을 분리
- 분류: 화자가 누구인지, 말한 단어가 무엇인지(단어 구분)
추가: 분류와 분리 구분하기
음성 데이터에서 '분류'와 '분리'는 다르며, 분리의 예시에 대한 설명이 일부 맞지만, 더 상세하고 다양한 예시가 있습니다.
분류: 화자·단어·음성 특성 판별
- 분류란 음성 데이터에서 '누가 말했는지'(화자 분류), '무슨 단어/문장인지'(음성 인식/단어 분류) 등을 판별하는 과정을 의미합니다.
- MFCC, MelSpectrogram 같은 음성 특징만으로 충분히 단어나 화자를 구분하는 데 사용됩니다.
- 예시:
- "사과"라는 한 단어 음성 파일들을 여러 화자가 각각 녹음 → 모델에서 MFCC 등 특징을 추출해서 '사과'라는 단어로 분류.
- 시험 환경에서 다양한 단어/문장 녹음 데이터에서 각 단어/문장을 분류(예: "음성 감정 분류", "음성 명령어 인식").
분리: 여러 소스·여러 화자·소음 분리
- 분리는 하나의 오디오/음성 데이터 내에서 '섞여 있는 소리' 혹은 '여러 명의 음성'을 개별로 분리하는 작업을 뜻합니다.
구체적 예시
- 화자 분리 (Speaker Diarization)
- 두 명 이상이 동시에 혹은 번갈아 대화하는 통화 데이터에서 각 화자의 음성 부분을 따로 분리하는 작업.
- 예: 상담원-고객 대화 오디오에서 상담원/고객별로 말한 구간을 나누어 별도 파일에 저장.
- 음원소스 분리 (Source Separation)
- 음악이나 오디오 파일에서 보컬/드럼/기타 등 각각의 소리를 분리하는 것.
- 예: 밴드 연주 음원에서 보컬만 뽑아서 별도 파일로 만드는 작업, 드럼·피아노만 남기는 작업 등.
- 소음/비소음 분리 (Noise Separation)
- 하나의 음성 데이터에서 대화 음성과 교통소음, 유리 깨지는 소리 등 환경 소음을 별도로 추출·분리하는 과정.
- 예: 인터뷰 녹음 데이터에서 배경에 자동차 경적 소리가 섞여 있을 때, 대화 음성과 소음 경적음을 구분하여 각기 저장.
- 구간 분리 (Speech Activity Detection)
- 오디오에서 침묵과 비침묵(실제 말하는 구간) 분리.
- 예: 긴 오디오 파일에서 사람이 말하는 부분만 잘라내어 데이터로 활용.
종합
- '소음(유리 깨짐, 큰 소음) 분리' 예시는 실제로 음성 분리의 대표적인 사례입니다.
- 보다 구체적이고 일반적인 예시로는 '화자별 음성 추출', '보컬·악기 분리', '대화음성과 주변 소음 분리', '말하는/침묵 구간 분리' 등이 있습니다.
음성 분리(특히 여러 화자, 소음, 악기 등 분리)는 MFCC와 MelSpectrogram 같은 기본 음성 특징만으로는 충분하지 않은 경우가 많으며, 더 고도화된 특징 추출 및 딥러닝 모델이 필요합니다.
- MFCC/MelSpectrogram의 한계
- MFCC와 MelSpectrogram은 주로 '음성의 전체적 특징'을 추출하여 화자 분류, 음성 인식 등에 적합하지만, 복잡하게 섞여 있는 소스(여러 화자, 악기, 소음 등)의 분리에는 정보가 부족할 수 있습니다.
- MFCC는 음성의 특징만 요약하여 합성·역변환이 어렵고, 각 신호 소스의 세밀한 분리 정보는 포함하지 못합니다.
- MelSpectrogram 역시 프레임 단위 특성만 나타나고, 신호의 물리적 분리 정보(특정 소스만 강조, 분리 등)를 학습하기 어렵습니다.
- 실제 분리에는 추가적으로 필요한 것
- 더 복잡한 입력 특성: 다양한 주파수 특성, 시간-주파수 정보를 더 잘 반영하는 STFT(Short-Time Fourier Transform), 파형(waveform), 다채널 입력 등.
- 딥러닝 모델 사용: 컨볼루션 신경망(CNN), 순환 신경망(RNN), Transformer 등은 원본에서 각 소스(화자, 악기, 소음)를 학습·분리하는 구조에 적합합니다.
- 소스별 레이블 학습: 실제 혼합 데이터와 타겟(예: 보컬, 배경음, 소음 등)의 페어 dataset이 필수적입니다.
- 기타 부가적 feature: Delta MFCCs(차분값), Chroma, Spectral Contrast 등 다양한 추가 특징들이 복합적으로 활용됩니다.
- 요약 예시
- 음악에서 보컬만 분리하려면: 혼합 스펙트로그램 + 분리 타겟을 딥러닝(CNN 등)에 입력/학습하는 방식이 필요, MFCC만으로 분리 불가.
- 통화 녹음에서 소음 제거는: AI 기반 음성 강조, Noise Suppression 알고리즘과 부가적인 신호 처리 기법, 또는 마이크 배열 정보까지 사용하는 경우가 많습니다.
결론적으로 실제 '분리'를 위해서는 MFCC/MelSpectrogram 외 추가적인 특징과 딥러닝 모델, 소스 분리 레이블링 데이터가 반드시 필요합니다.
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
- 게시판: 화면에 전체 게시글 구현하기
- mainRouter.js
- 사용자가 메인에 방문하면 DB에 있는 전체 게시글의 정보를 가져와서 메인 페이지에 출력
- 특정 게시글을 조회해서 상세 페이지를 제작
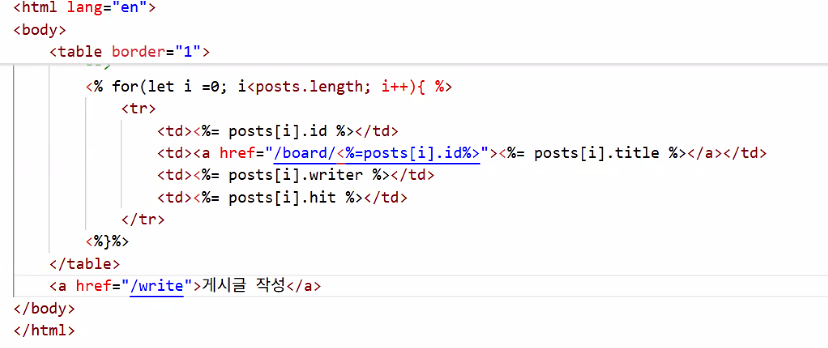
- main.ejs
- 반복문 활용 → 태그 반복 생성
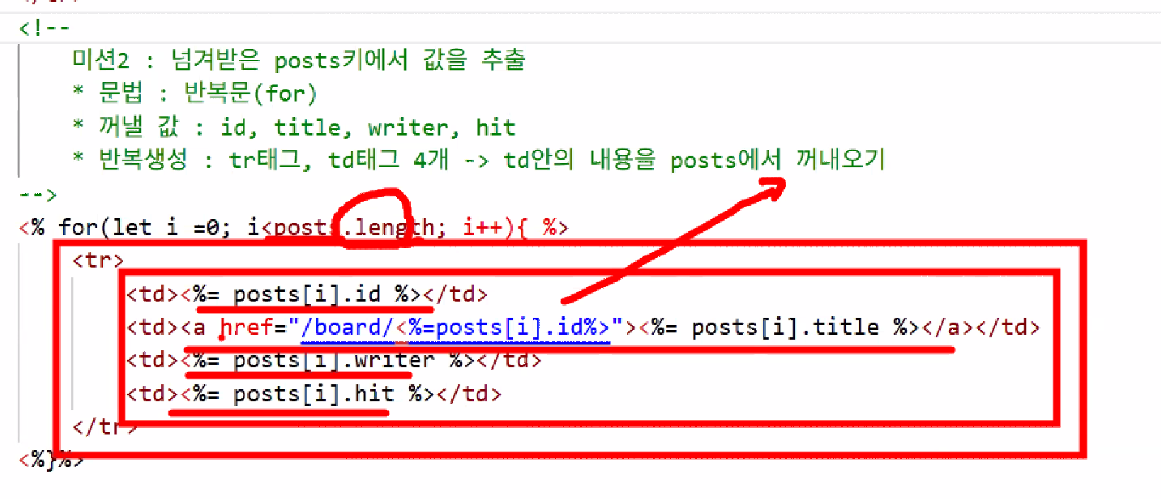
- 반복문 활용 → 태그 반복 생성
- mainRouter.js
- 핵심: 경로 처리
- parameter →
:사용해 url에 변수 설정
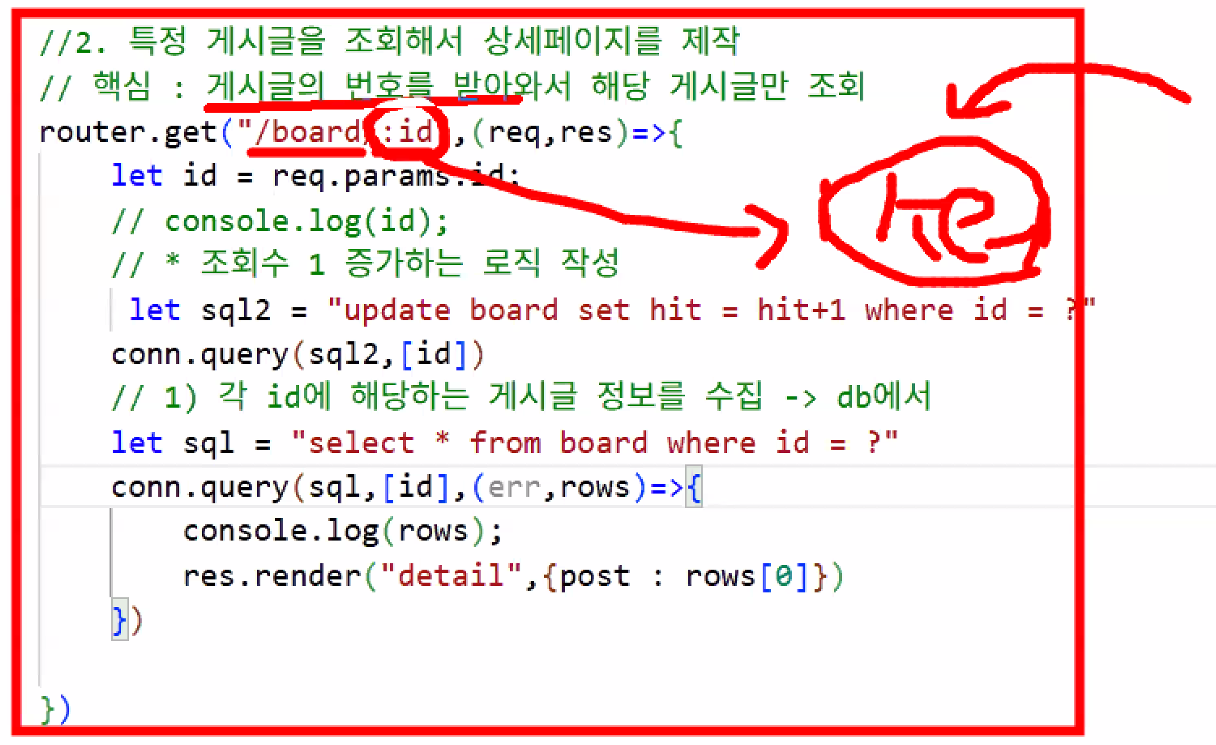
- 클라이언트가 url에 값을 보냈기 때문에 req에서 params 값을 꺼내야 함
- cf. get 방식 통신: res.query / post 방식 통신: res.body
- parameter →
- 게시글 조회 수 업데이트
- SQL → UPDATE, WHERE
2. 게시글 작성 구현
main.ejs
- 게시글 작성하기 버튼 만들기
mainRouter.js
- 게시글 등록 페이지 제작 경로 구현

views > write.ejs
- 게시글 등록 페이지

- 실행 결과

- 실행 결과
id, hit은 우리가 입력하는 거 아님!
id → 테이블에서 PK(Primary Key), NN(Not Null), AI(Auto Increment) 설정했음 → 자동으로 올라감
hit → 조회 수 1 증가하는 로직:UPDATE board SET hit = hit+1 WHERE id=?;
오라클은 숫자를 생성할 sequenc를 만들고 새로운 데이터가 입력될 때 시퀀스의 다음 값을 가져와 컬럼에 할당하는 trigger를 만들어서 컬럼과 연결해야 하는데 mysql은 AI 체크하면 알아서 해줌
오라클DB(12.1버전 이전)에는 auto_increment 기능이 없다. 그래서, 시퀀스/트리거를 생성해서 사용해야 한다.
→ MySQL의 AUTO_INCREMENT는 오라클 12.1 버전부터 GENERATED AS IDENTITY 컬럼 속성으로 지원되지만, 그 이전 버전에서는 SEQUENCE 객체를 생성하고 트리거를 사용하여 비슷한 기능을 구현해야 합니다. Oracle 12.1 이상에서는 GENERATED AS IDENTITY를 사용하면 MySQL의 AUTO_INCREMENT와 동일하게 자동으로 숫자를 증가시킬 수 있습니다.
B. 5교시
1. 게시글 작성 구현(cont.)
mainRouter.js
- write.ejs가 보낸 값 받기
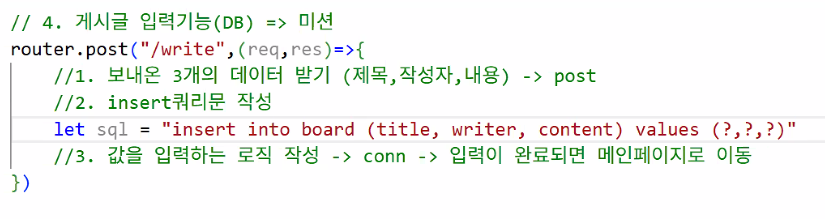
- 코드
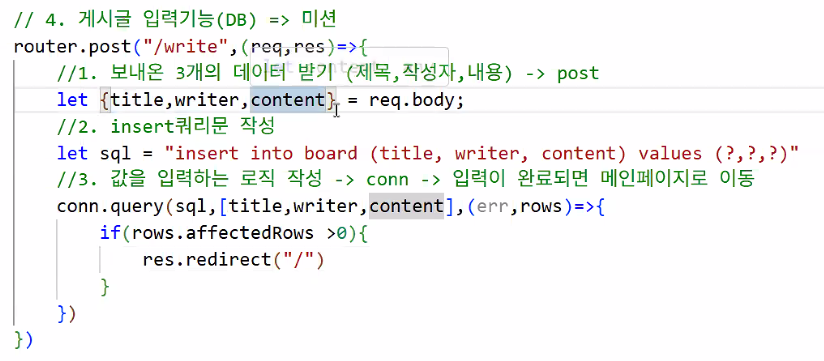
- 코드
2. 게시글 수정 구현
detail.ejs
- '수정하기' 만들기
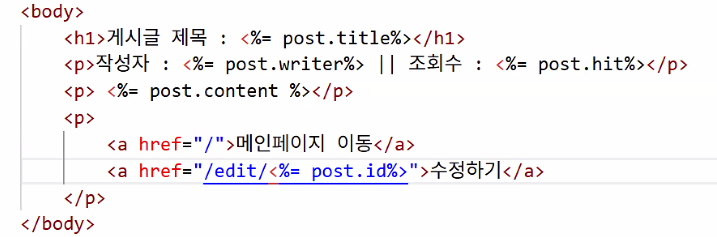
- point: 게시글마다 수정 화면이 나와야 하니까
<%=post.id%>
- point: 게시글마다 수정 화면이 나와야 하니까
mainRouter.js
- 게시글 수정 폼 제작
- DB 연결 필요: 해당 게시글 내용 받아오기
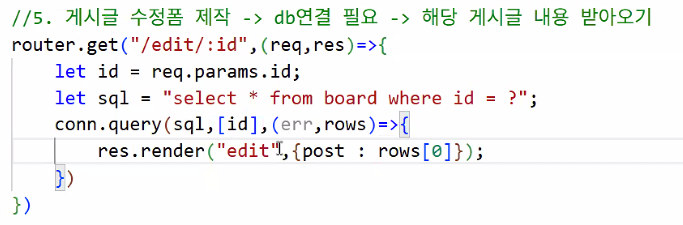
- DB 연결 필요: 해당 게시글 내용 받아오기
edit.ejs

C. 6교시
1. 게시글 수정 구현 (cont.)
edit.ejs
- action 경로 지정
action="/edit/<%=post.id%>"
mainRouter.js
- 입력받은 값 받아오기: id, 수정한 내용들
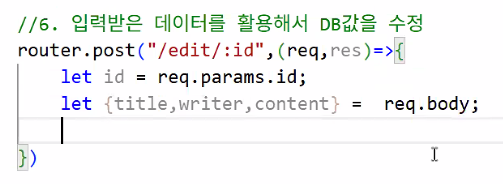
- 쿼리문 작성 & redirect 경로 작성

2. 게시글 삭제 구현
detail.ejs
- 삭제하기 버튼 만들기
- 조건 1: POST 방법 써야 함 → FORM 태그
- 조건 2: 페이지가 없고 바로 삭제됨 → 인라인으로 조건 넣기
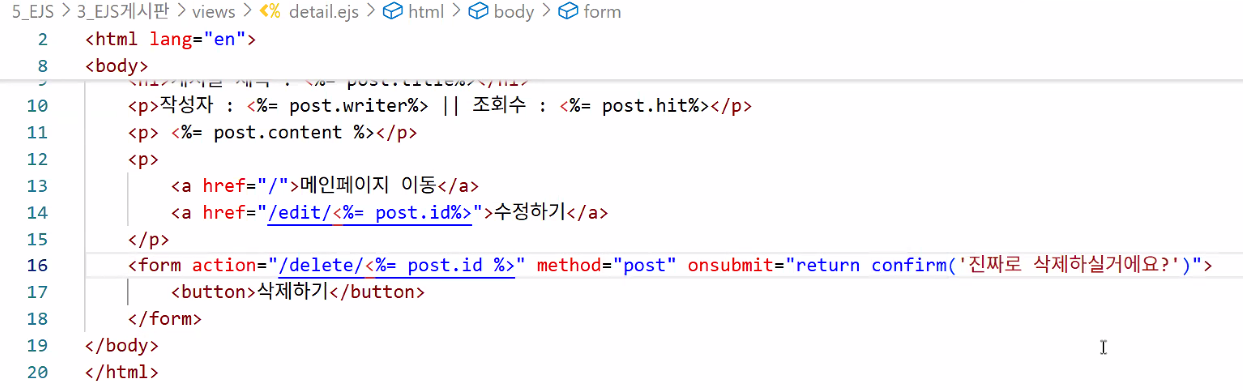
mainRouter.js
- 삭제 로직 만들기

Ⅲ. CAREER UP
네이버클라우드 교육
모니터링 및 Auto Scale + Load Balancer
- Cloud Insight
- 지표 대시보드(성능/운영)
- 상황 정의, 상황별 대처
- 통찰력 확보
- 신속한 장애 대응
- 지표 대시보드(성능/운영)
- plug-in → custom metrics
imissmycafe.com
calmyleon.com
soundscape.world
